 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Estimation of Air Pollution with Remote Sensing Data: Revealing Greenhouse Gas Emissions from Space
Aug 31, 2021
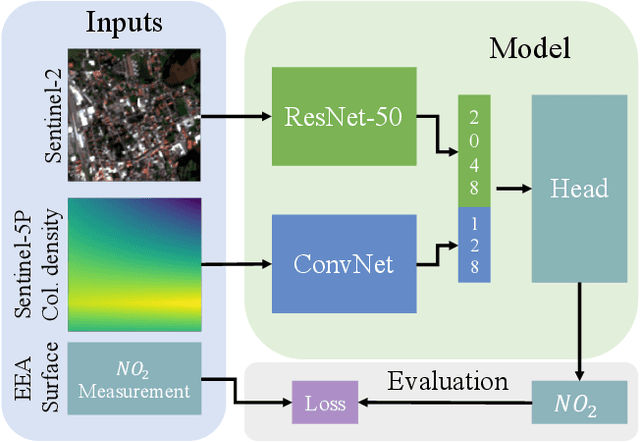

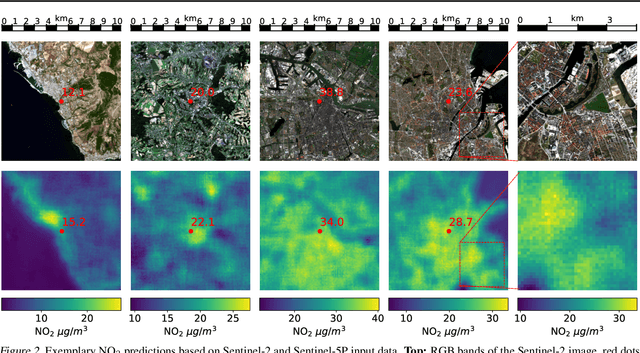
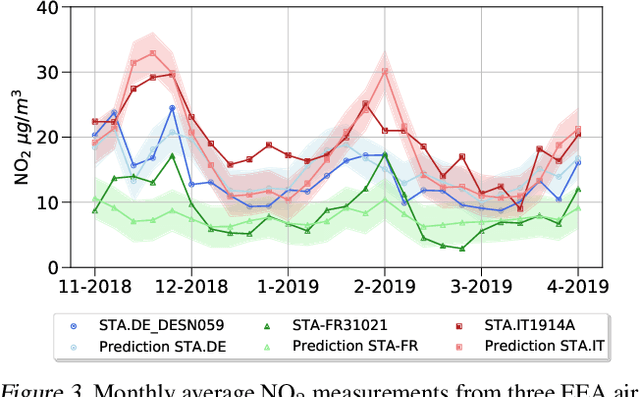
Air pollution is a major driver of climate change. Anthropogenic emissions from the burning of fossil fuels for transportation and power generation emit large amounts of problematic air pollutants, including Greenhouse Gases (GHGs). Despite the importance of limiting GHG emissions to mitigate climate change, detailed information about the spatial and temporal distribution of GHG and other air pollutants is difficult to obtain. Existing models for surface-level air pollution rely on extensive land-use datasets which are often locally restricted and temporally static. This work proposes a deep learning approach for the prediction of ambient air pollution that only relies on remote sensing data that is globally available and frequently updated. Combining optical satellite imagery with satellite-based atmospheric column density air pollution measurements enables the scaling of air pollution estimates (in this case NO$_2$) to high spatial resolution (up to $\sim$10m) at arbitrary locations and adds a temporal component to these estimates. The proposed model performs with high accuracy when evaluated against air quality measurements from ground stations (mean absolute error $<$6$~\mu g/m^3$). Our results enable the identification and temporal monitoring of major sources of air pollution and GHGs.
Robust Neural Abstractive Summarization Systems and Evaluation against Adversarial Information
Oct 14, 2018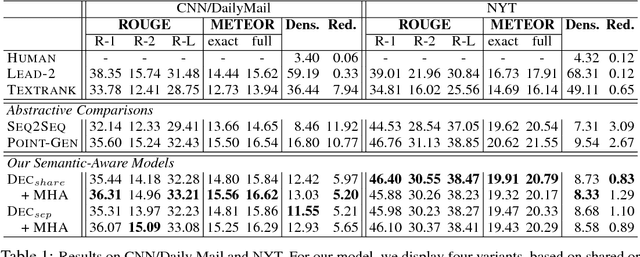
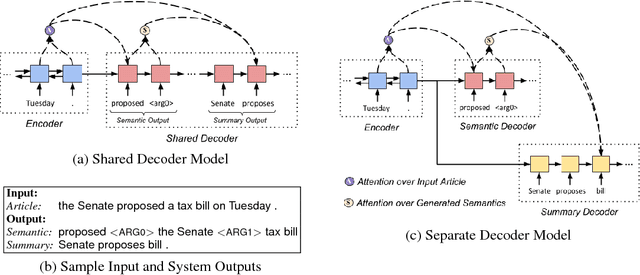
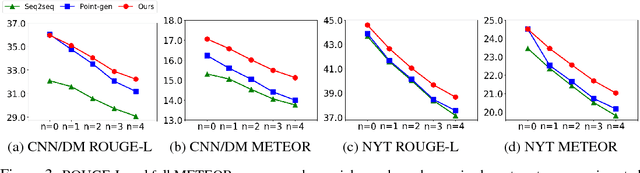
Sequence-to-sequence (seq2seq) neural models have been actively investigated for abstractive summarization. Nevertheless, existing neural abstractive systems frequently generate factually incorrect summaries and are vulnerable to adversarial information, suggesting a crucial lack of semantic understanding. In this paper, we propose a novel semantic-aware neural abstractive summarization model that learns to generate high quality summaries through semantic interpretation over salient content. A novel evaluation scheme with adversarial samples is introduced to measure how well a model identifies off-topic information, where our model yields significantly better performance than the popular pointer-generator summarizer. Human evaluation also confirms that our system summaries are uniformly more informative and faithful as well as less redundant than the seq2seq model.
Online and Adaptive Parking Availability Mapping: An Uncertainty-Aware Active Sensing Approach for Connected Vehicles
May 01, 2021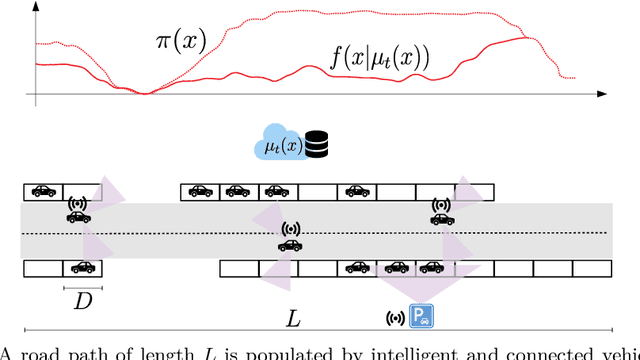
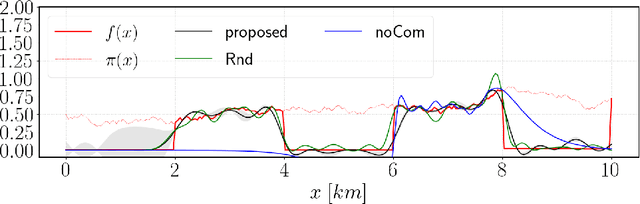
Research on connected vehicles represents a continuously evolving technological domain, fostered by the emerging Internet of Things (IoT) paradigm and the recent advances in intelligent transportation systems. Nowadays, vehicles are platforms capable of generating, receiving and automatically act based on large amount of data. In the context of assisted driving, connected vehicle technology provides real-time information about the surrounding traffic conditions. Such information is expected to improve drivers' quality of life, for example, by adopting decision making strategies according to the current parking availability status. In this context, we propose an online and adaptive scheme for parking availability mapping. Specifically, we adopt an information-seeking active sensing approach to select the incoming data, thus preserving the onboard storage and processing resources; then, we estimate the parking availability through Gaussian Process Regression. We compare the proposed algorithm with several baselines, which attain inferior performance in terms of mapping convergence speed and adaptivity capabilities; moreover, the proposed approach comes at the cost of a very small computational demand.
Information-Guided Robotic Maximum Seek-and-Sample in Partially Observable Continuous Environments
Sep 26, 2019
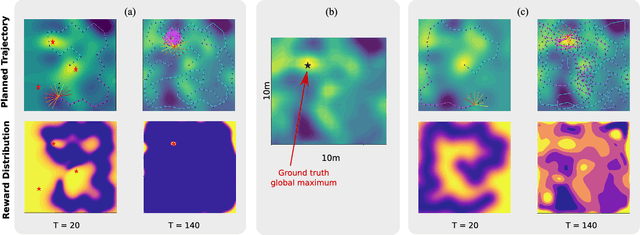

We present PLUMES, a planner to localizing and collecting samples at the global maximum of an a priori unknown and partially observable continuous environment. The "maximum-seek-and-sample" (MSS) problem is pervasive in the environmental and earth sciences. Experts want to collect scientifically valuable samples at an environmental maximum (e.g., an oil-spill source), but do not have prior knowledge about the phenomenon's distribution. We formulate the MSS problem as a partially-observable Markov decision process (POMDP) with continuous state and observation spaces, and a sparse reward signal. To solve the MSS POMDP, PLUMES uses an information-theoretic reward heuristic with continous-observation Monte Carlo Tree Search to efficiently localize and sample from the global maximum. In simulation and field experiments, PLUMES collects more scientifically valuable samples than state-of-the-art planners in a diverse set of environments, with various platforms, sensors, and challenging real-world conditions.
* 8 pages, 8 figures, To appear in the proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2019 Macau
Why and How Governments Should Monitor AI Development
Aug 31, 2021In this paper we outline a proposal for improving the governance of artificial intelligence (AI) by investing in government capacity to systematically measure and monitor the capabilities and impacts of AI systems. If adopted, this would give governments greater information about the AI ecosystem, equipping them to more effectively direct AI development and deployment in the most societally and economically beneficial directions. It would also create infrastructure that could rapidly identify potential threats or harms that could occur as a consequence of changes in the AI ecosystem, such as the emergence of strategically transformative capabilities, or the deployment of harmful systems. We begin by outlining the problem which motivates this proposal: in brief, traditional governance approaches struggle to keep pace with the speed of progress in AI. We then present our proposal for addressing this problem: governments must invest in measurement and monitoring infrastructure. We discuss this proposal in detail, outlining what specific things governments could focus on measuring and monitoring, and the kinds of benefits this would generate for policymaking. Finally, we outline some potential pilot projects and some considerations for implementing this in practice.
Continuous-discrete multiple target tracking with out-of-sequence measurements
Jun 09, 2021
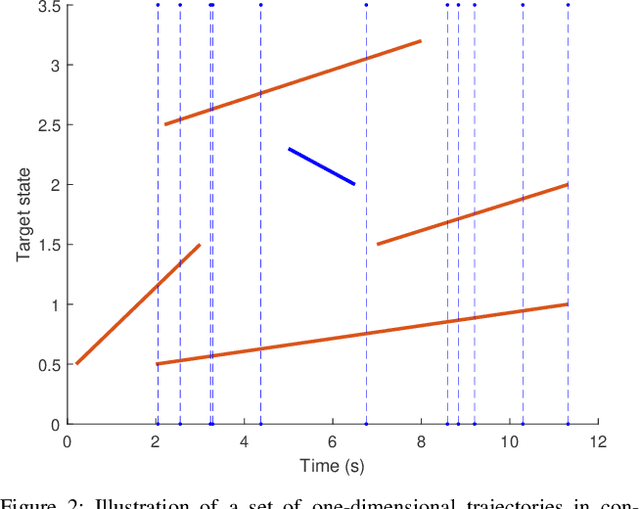
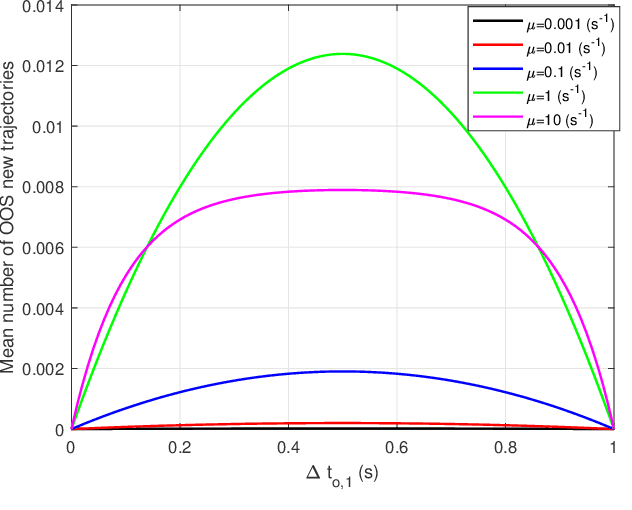
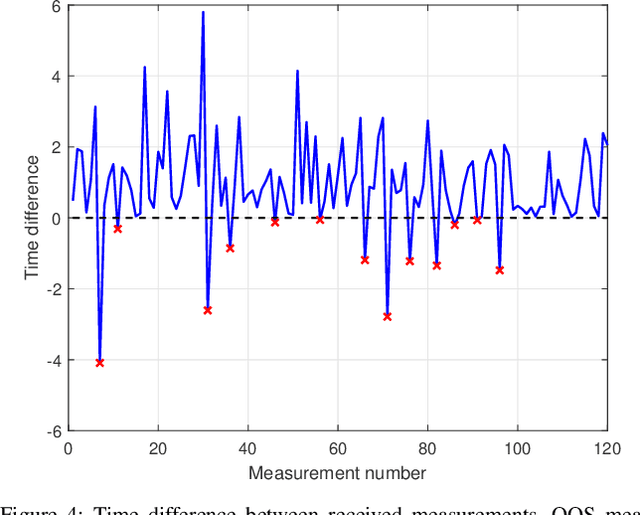
This paper derives the optimal Bayesian processing of an out-of-sequence (OOS) set of measurements in continuous-time for multiple target tracking. We consider a multi-target system modelled in continuous time that is discretised at the time steps when we receive the measurements, which are distributed according to the standard point target model. All information about this system at the sampled time steps is provided by the posterior density on the set of all trajectories. This density can be computed via the continuous-discrete trajectory Poisson multi-Bernoulli mixture (TPMBM) filter. When we receive an OOS measurement, the optimal Bayesian processing performs a retrodiction step that adds trajectory information at the OOS measurement time stamp followed by an update step. After the OOS measurement update, the posterior remains in TPMBM form. We also provide a computationally lighter alternative based on a trajectory Poisson multi-Bernoulli filter. The effectiveness of the two approaches to handle OOS measurements is evaluated via simulations.
A Search Engine for Discovery of Biomedical Challenges and Directions
Aug 31, 2021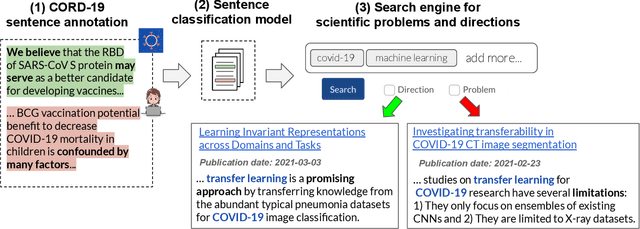


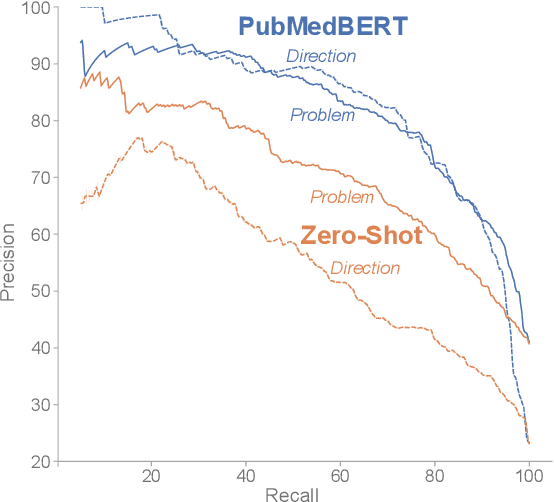
The ability to keep track of scientific challenges, advances and emerging directions is a fundamental part of research. However, researchers face a flood of papers that hinders discovery of important knowledge. In biomedicine, this directly impacts human lives. To address this problem, we present a novel task of extraction and search of scientific challenges and directions, to facilitate rapid knowledge discovery. We construct and release an expert-annotated corpus of texts sampled from full-length papers, labeled with novel semantic categories that generalize across many types of challenges and directions. We focus on a large corpus of interdisciplinary work relating to the COVID-19 pandemic, ranging from biomedicine to areas such as AI and economics. We apply a model trained on our data to identify challenges and directions across the corpus and build a dedicated search engine for this information. In studies with researchers, including those working directly on COVID-19, we outperform a popular scientific search engine in assisting knowledge discovery. Finally, we show that models trained on our resource generalize to the wider biomedical domain, highlighting its broad utility. We make our data, model and search engine publicly available. https://challenges.apps.allenai.org
Pruning with Compensation: Efficient Channel Pruning for Deep Convolutional Neural Networks
Aug 31, 2021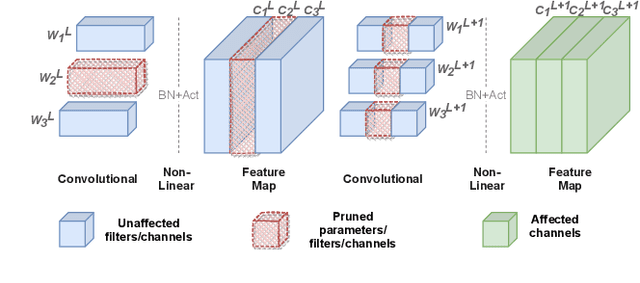
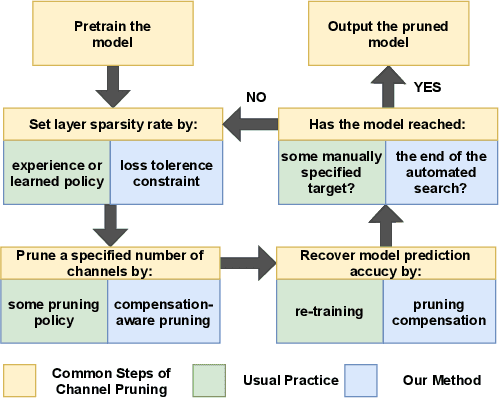
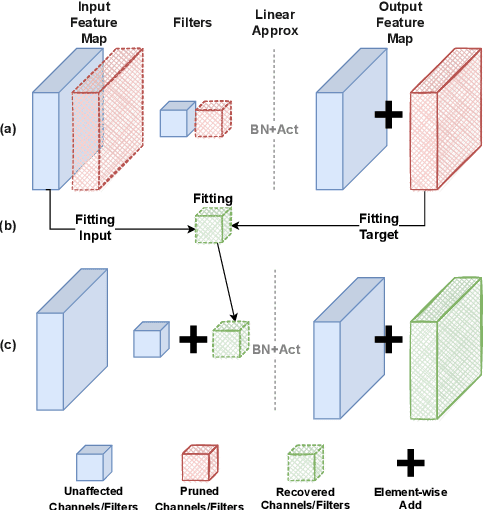
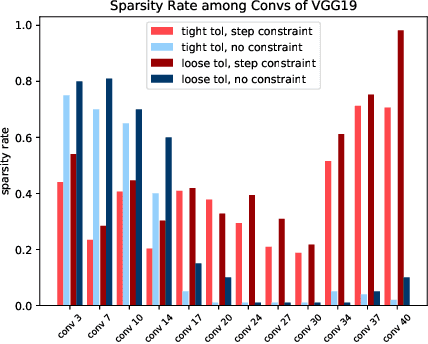
Channel pruning is a promising technique to compress the parameters of deep convolutional neural networks(DCNN) and to speed up the inference. This paper aims to address the long-standing inefficiency of channel pruning. Most channel pruning methods recover the prediction accuracy by re-training the pruned model from the remaining parameters or random initialization. This re-training process is heavily dependent on the sufficiency of computational resources, training data, and human interference(tuning the training strategy). In this paper, a highly efficient pruning method is proposed to significantly reduce the cost of pruning DCNN. The main contributions of our method include: 1) pruning compensation, a fast and data-efficient substitute of re-training to minimize the post-pruning reconstruction loss of features, 2) compensation-aware pruning(CaP), a novel pruning algorithm to remove redundant or less-weighted channels by minimizing the loss of information, and 3) binary structural search with step constraint to minimize human interference. On benchmarks including CIFAR-10/100 and ImageNet, our method shows competitive pruning performance among the state-of-the-art retraining-based pruning methods and, more importantly, reduces the processing time by 95% and data usage by 90%.
Joint Biomedical Entity and Relation Extraction with Knowledge-Enhanced Collective Inference
Jun 01, 2021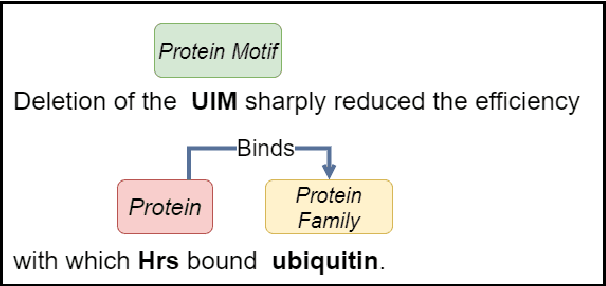
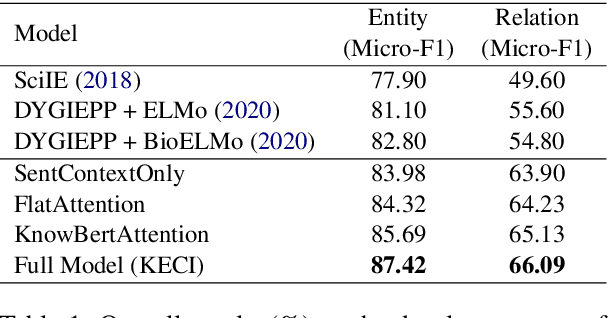
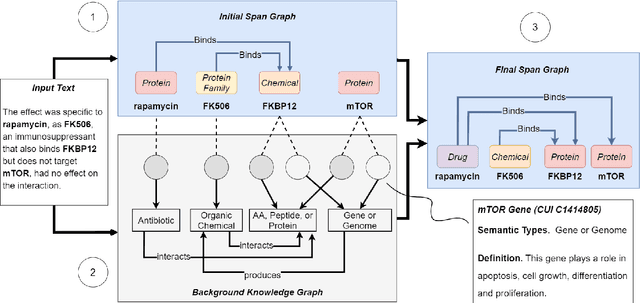
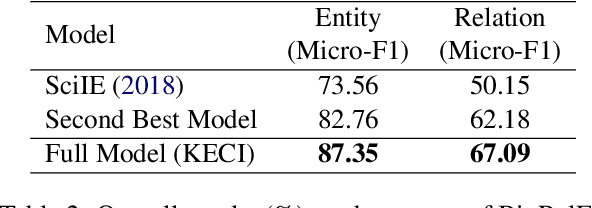
Compared to the general news domain, information extraction (IE) from biomedical text requires much broader domain knowledge. However, many previous IE methods do not utilize any external knowledge during inference. Due to the exponential growth of biomedical publications, models that do not go beyond their fixed set of parameters will likely fall behind. Inspired by how humans look up relevant information to comprehend a scientific text, we present a novel framework that utilizes external knowledge for joint entity and relation extraction named KECI (Knowledge-Enhanced Collective Inference). Given an input text, KECI first constructs an initial span graph representing its initial understanding of the text. It then uses an entity linker to form a knowledge graph containing relevant background knowledge for the the entity mentions in the text. To make the final predictions, KECI fuses the initial span graph and the knowledge graph into a more refined graph using an attention mechanism. KECI takes a collective approach to link mention spans to entities by integrating global relational information into local representations using graph convolutional networks. Our experimental results show that the framework is highly effective, achieving new state-of-the-art results in two different benchmark datasets: BioRelEx (binding interaction detection) and ADE (adverse drug event extraction). For example, KECI achieves absolute improvements of 4.59% and 4.91% in F1 scores over the state-of-the-art on the BioRelEx entity and relation extraction tasks.
Generating Master Faces for Dictionary Attacks with a Network-Assisted Latent Space Evolution
Aug 01, 2021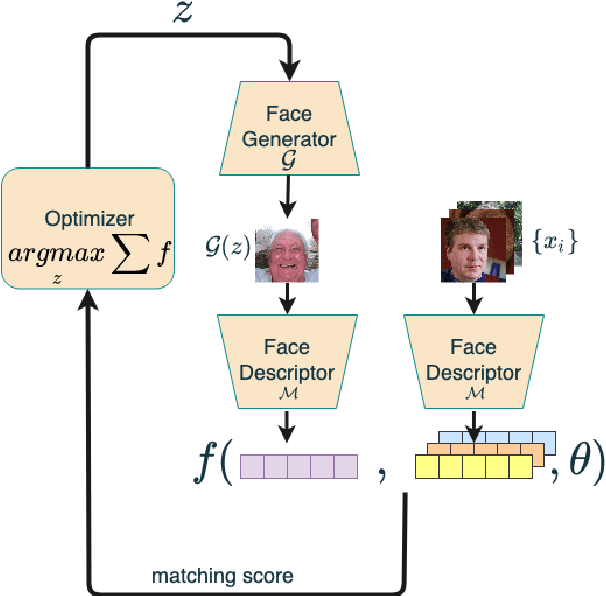


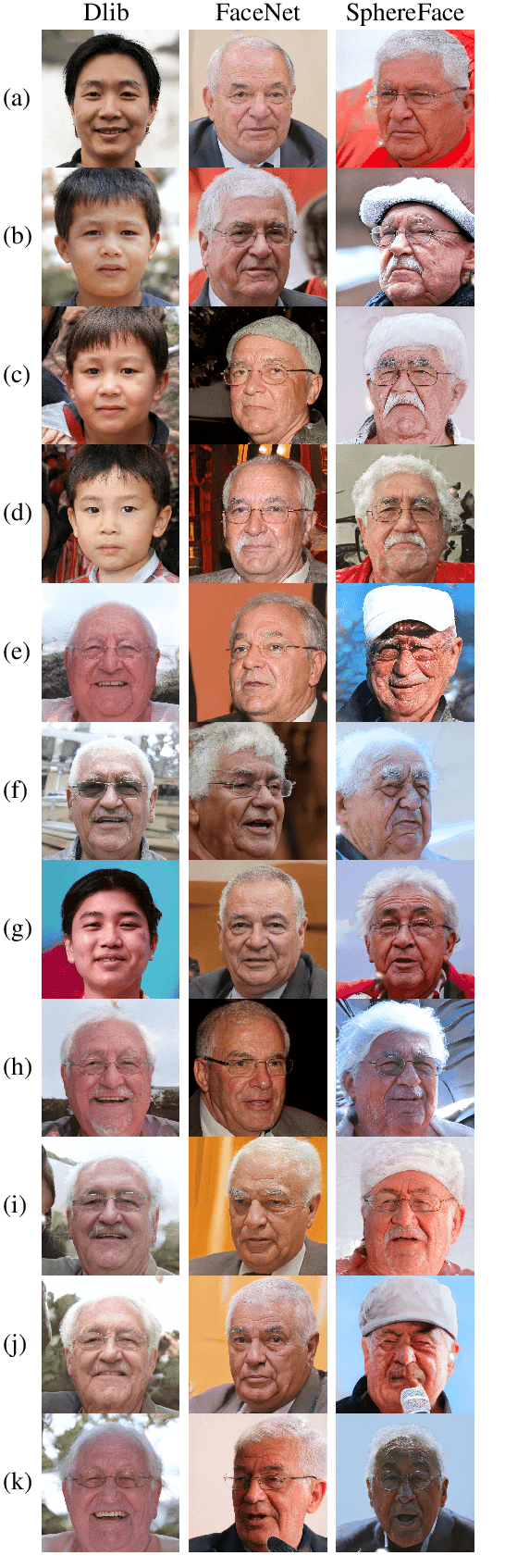
A master face is a face image that passes face-based identity-authentication for a large portion of the population. These faces can be used to impersonate, with a high probability of success, any user, without having access to any user information. We optimize these faces, by using an evolutionary algorithm in the latent embedding space of the StyleGAN face generator. Multiple evolutionary strategies are compared, and we propose a novel approach that employs a neural network in order to direct the search in the direction of promising samples, without adding fitness evaluations. The results we present demonstrate that it is possible to obtain a high coverage of the population (over 40%) with less than 10 master faces, for three leading deep face recognition systems.