 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Basic Geometric Structures of Electromagnetic Digital Information: Statistical characterization of the digital measurement of spatio-Doppler and polarimetric fluctuations of the radar electromagnetic wave
Jun 26, 2020
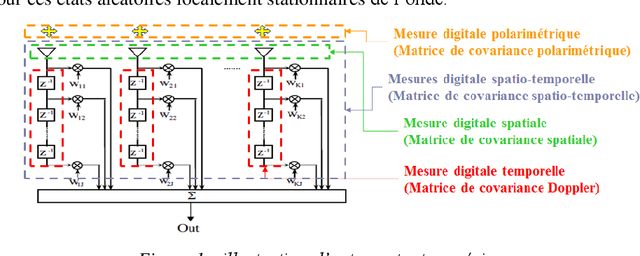

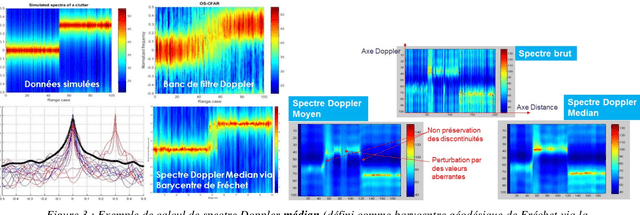
The aim is to describe new geometric approaches to define the statistics of spatio-temporal and polarimetric measurements of the states of an electromagnetic wave, using the works of Maurice Fr{\'e}chet, Jean-Louis Koszul and Jean-Marie Souriau, with in particular the notion of 'average' state of this digital measurement as a Fr{\'e}chet barycentre in a metric space and a model derived from statistical mechanics to define and calculate a maximum density of entropy (extension of the notion of Gaussian) to describe the fluctuations of the electromagnetic wave. The article will illustrate these new tools with examples of radar application for Doppler, spatio-temporal and polarimetric measurement of the electromagnetic wave by introducing a distance on the covariance matrices of the electromagnetic digital signal, based on Fisher's metric from Information Geometry.
RSSI-Based Machine Learning with Pre- and Post-Processing for Cell-Localization in IWSNs
Apr 30, 2021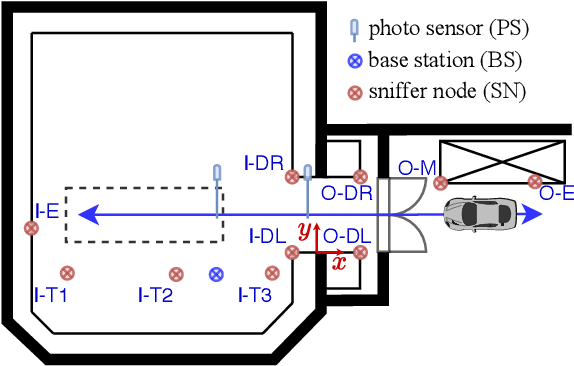
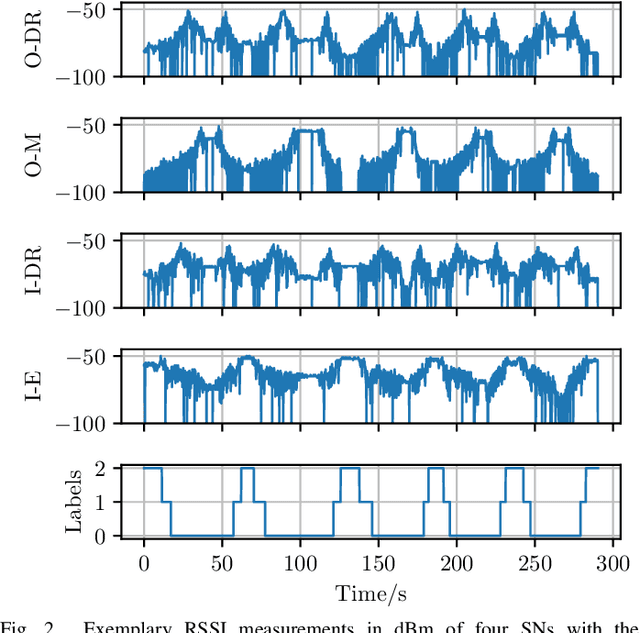
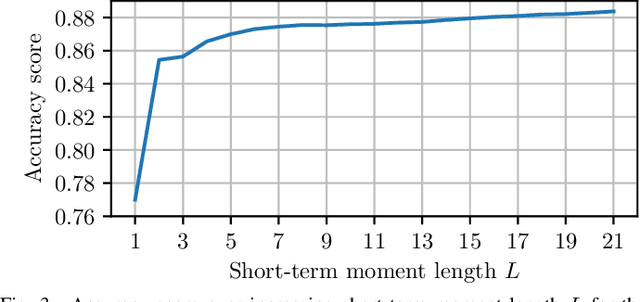
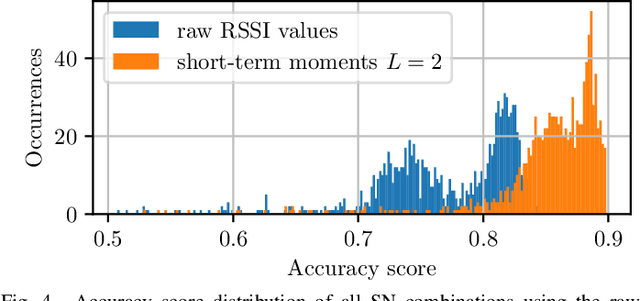
Industrial wireless sensor networks are becoming crucial for modern manufacturing. If the sensors in those networks are mobile, the position information, besides the sensor data itself, can be of high relevance. E.g. this position information can increase the trustability of a wireless sensor measurement by assuring that the sensor is not physically removed, off track, or otherwise compromised. In certain applications, localization information at cell-level, whether the sensor is inside or outside a room or cell, is sufficient. For this, localization using Received Signal Strength Indicator (RSSI) measurements is very popular since RSSI values are available in almost all existing technologies and no direct interaction with the mobile sensor node and its communication in the network is needed. For this scenario, we propose methods to improve the robustness and accuracy of common machine learning classifiers, by using features based on short-term moments and a second classification stage using Hidden Markov Models. With the data from an extensive measurement campaign, we show the applicability of our method and achieve a cell-level localization accuracy of 93.5\%.
Probabilistic Monocular 3D Human Pose Estimation with Normalizing Flows
Aug 02, 2021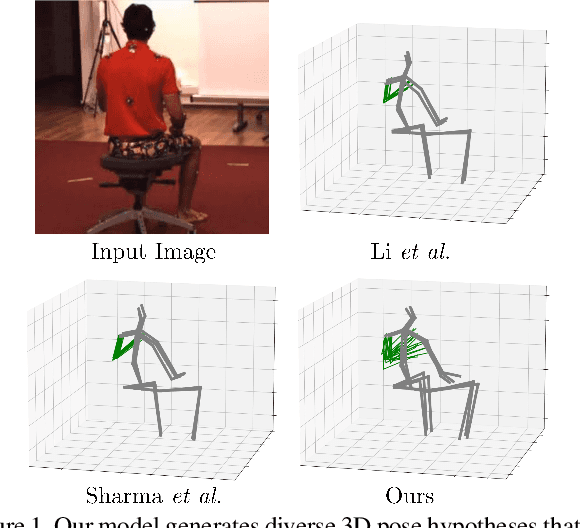
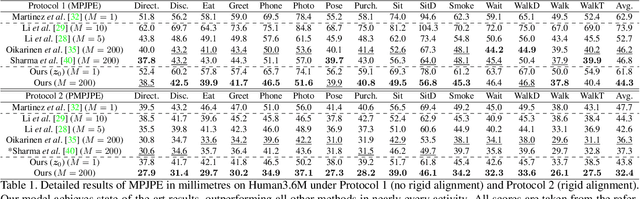
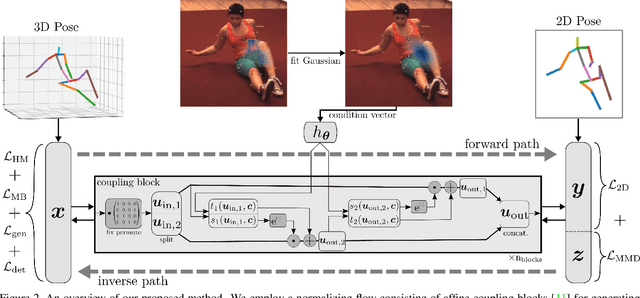

3D human pose estimation from monocular images is a highly ill-posed problem due to depth ambiguities and occlusions. Nonetheless, most existing works ignore these ambiguities and only estimate a single solution. In contrast, we generate a diverse set of hypotheses that represents the full posterior distribution of feasible 3D poses. To this end, we propose a normalizing flow based method that exploits the deterministic 3D-to-2D mapping to solve the ambiguous inverse 2D-to-3D problem. Additionally, uncertain detections and occlusions are effectively modeled by incorporating uncertainty information of the 2D detector as condition. Further keys to success are a learned 3D pose prior and a generalization of the best-of-M loss. We evaluate our approach on the two benchmark datasets Human3.6M and MPI-INF-3DHP, outperforming all comparable methods in most metrics. The implementation is available on GitHub.
Deep Reinforcement Learning for Equal Risk Pricing and Hedging under Dynamic Expectile Risk Measures
Sep 09, 2021
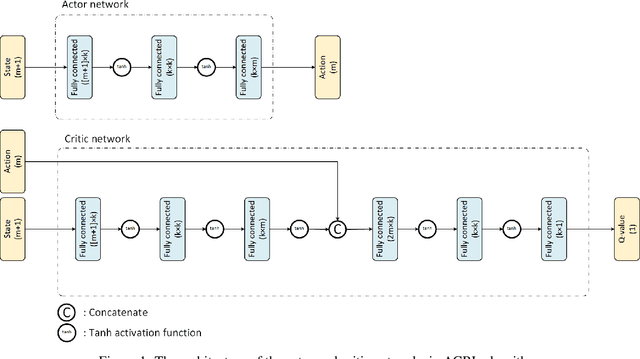
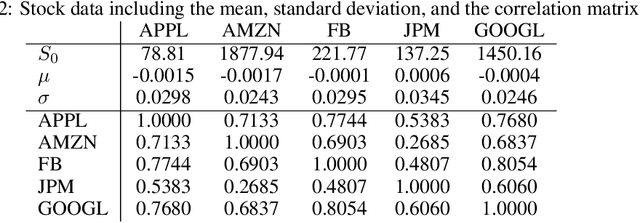
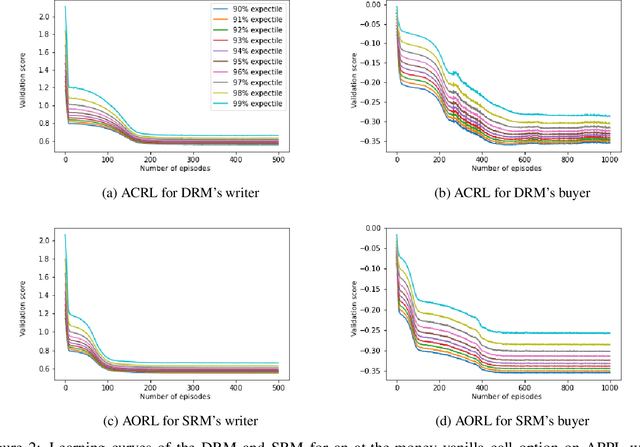
Recently equal risk pricing, a framework for fair derivative pricing, was extended to consider dynamic risk measures. However, all current implementations either employ a static risk measure that violates time consistency, or are based on traditional dynamic programming solution schemes that are impracticable in problems with a large number of underlying assets (due to the curse of dimensionality) or with incomplete asset dynamics information. In this paper, we extend for the first time a famous off-policy deterministic actor-critic deep reinforcement learning (ACRL) algorithm to the problem of solving a risk averse Markov decision process that models risk using a time consistent recursive expectile risk measure. This new ACRL algorithm allows us to identify high quality time consistent hedging policies (and equal risk prices) for options, such as basket options, that cannot be handled using traditional methods, or in context where only historical trajectories of the underlying assets are available. Our numerical experiments, which involve both a simple vanilla option and a more exotic basket option, confirm that the new ACRL algorithm can produce 1) in simple environments, nearly optimal hedging policies, and highly accurate prices, simultaneously for a range of maturities 2) in complex environments, good quality policies and prices using reasonable amount of computing resources; and 3) overall, hedging strategies that actually outperform the strategies produced using static risk measures when the risk is evaluated at later points of time.
Wallpaper Texture Generation and Style Transfer Based on Multi-label Semantics
Jun 22, 2021


Textures contain a wealth of image information and are widely used in various fields such as computer graphics and computer vision. With the development of machine learning, the texture synthesis and generation have been greatly improved. As a very common element in everyday life, wallpapers contain a wealth of texture information, making it difficult to annotate with a simple single label. Moreover, wallpaper designers spend significant time to create different styles of wallpaper. For this purpose, this paper proposes to describe wallpaper texture images by using multi-label semantics. Based on these labels and generative adversarial networks, we present a framework for perception driven wallpaper texture generation and style transfer. In this framework, a perceptual model is trained to recognize whether the wallpapers produced by the generator network are sufficiently realistic and have the attribute designated by given perceptual description; these multi-label semantic attributes are treated as condition variables to generate wallpaper images. The generated wallpaper images can be converted to those with well-known artist styles using CycleGAN. Finally, using the aesthetic evaluation method, the generated wallpaper images are quantitatively measured. The experimental results demonstrate that the proposed method can generate wallpaper textures conforming to human aesthetics and have artistic characteristics.
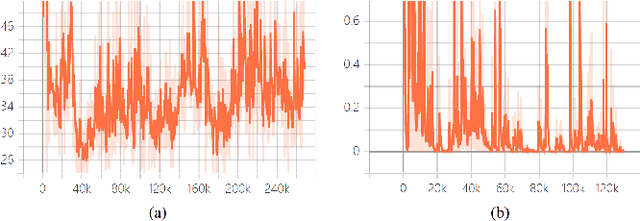
Information Plane Analysis of Deep Neural Networks via Matrix-Based Renyi's Entropy and Tensor Kernels
Sep 25, 2019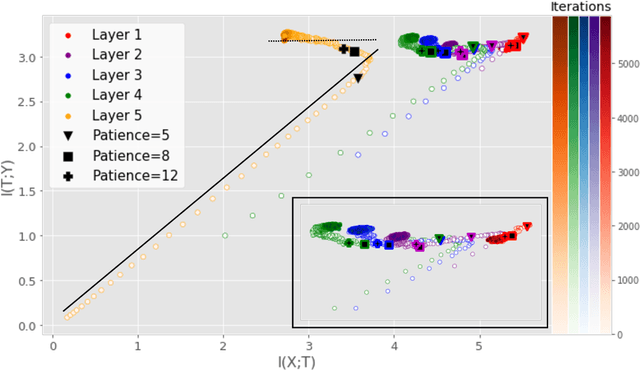
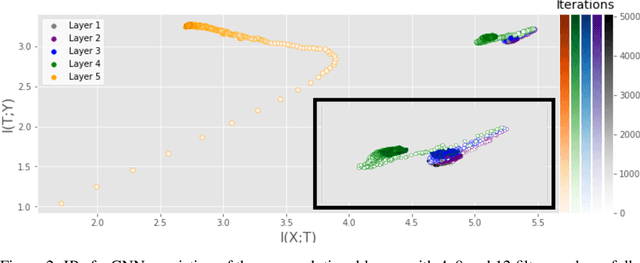
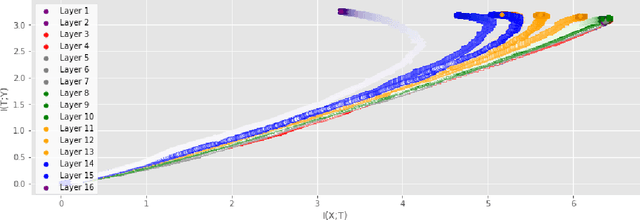
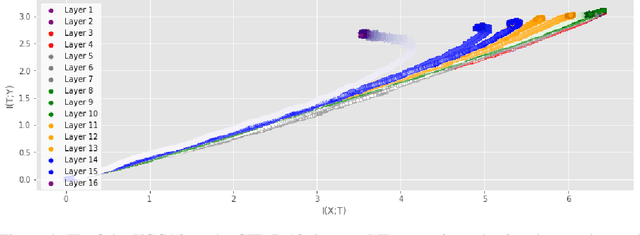
Analyzing deep neural networks (DNNs) via information plane (IP) theory has gained tremendous attention recently as a tool to gain insight into, among others, their generalization ability. However, it is by no means obvious how to estimate mutual information (MI) between each hidden layer and the input/desired output, to construct the IP. For instance, hidden layers with many neurons require MI estimators with robustness towards the high dimensionality associated with such layers. MI estimators should also be able to naturally handle convolutional layers, while at the same time being computationally tractable to scale to large networks. None of the existing IP methods to date have been able to study truly deep Convolutional Neural Networks (CNNs), such as the e.g.\ VGG-16. In this paper, we propose an IP analysis using the new matrix--based R\'enyi's entropy coupled with tensor kernels over convolutional layers, leveraging the power of kernel methods to represent properties of the probability distribution independently of the dimensionality of the data. The obtained results shed new light on the previous literature concerning small-scale DNNs, however using a completely new approach. Importantly, the new framework enables us to provide the first comprehensive IP analysis of contemporary large-scale DNNs and CNNs, investigating the different training phases and providing new insights into the training dynamics of large-scale neural networks.
Contextual Convolutional Neural Networks
Aug 17, 2021
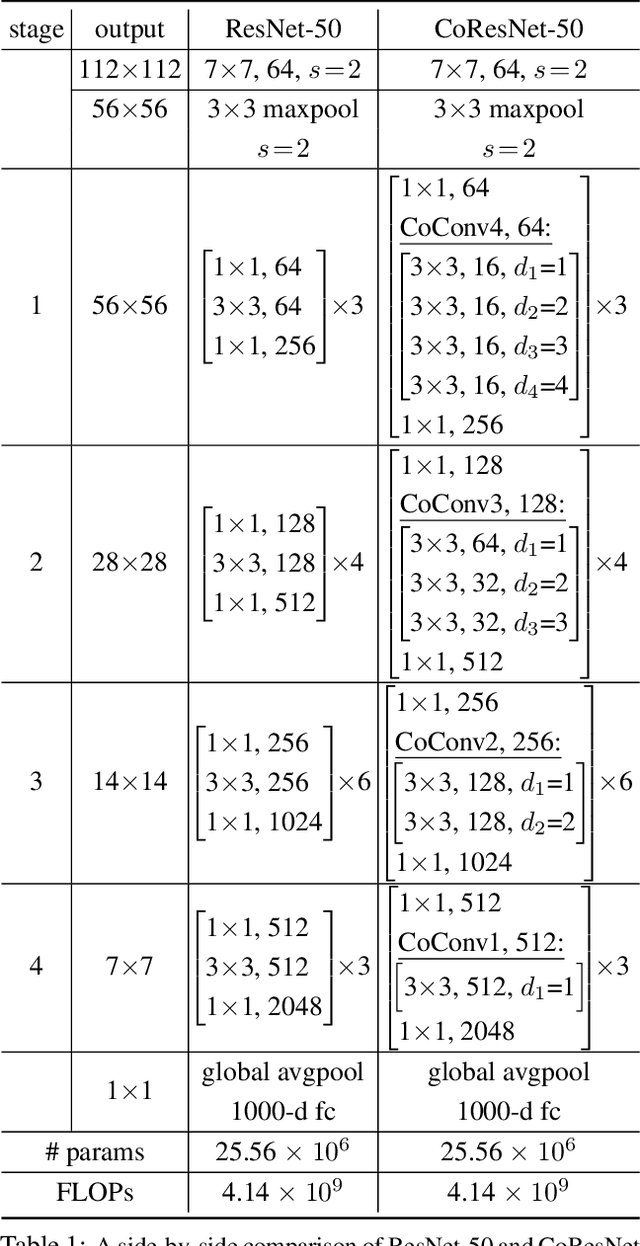
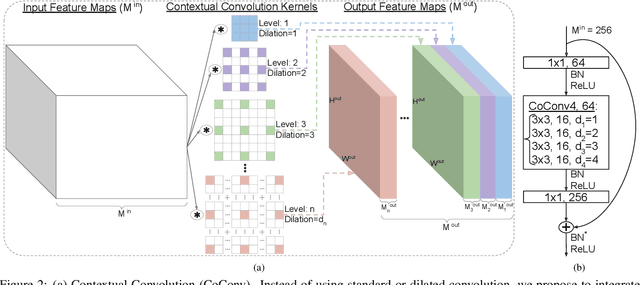

We propose contextual convolution (CoConv) for visual recognition. CoConv is a direct replacement of the standard convolution, which is the core component of convolutional neural networks. CoConv is implicitly equipped with the capability of incorporating contextual information while maintaining a similar number of parameters and computational cost compared to the standard convolution. CoConv is inspired by neuroscience studies indicating that (i) neurons, even from the primary visual cortex (V1 area), are involved in detection of contextual cues and that (ii) the activity of a visual neuron can be influenced by the stimuli placed entirely outside of its theoretical receptive field. On the one hand, we integrate CoConv in the widely-used residual networks and show improved recognition performance over baselines on the core tasks and benchmarks for visual recognition, namely image classification on the ImageNet data set and object detection on the MS COCO data set. On the other hand, we introduce CoConv in the generator of a state-of-the-art Generative Adversarial Network, showing improved generative results on CIFAR-10 and CelebA. Our code is available at https://github.com/iduta/coconv.
On the Sins of Image Synthesis Loss for Self-supervised Depth Estimation
Sep 13, 2021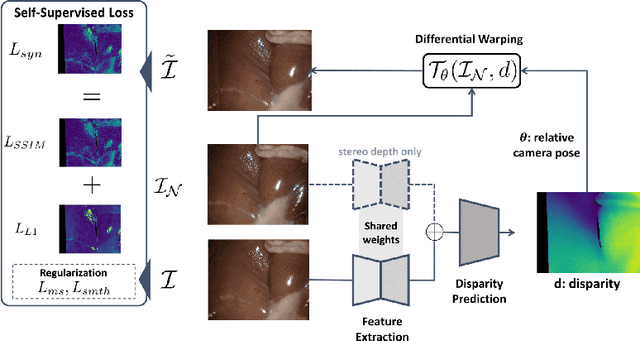
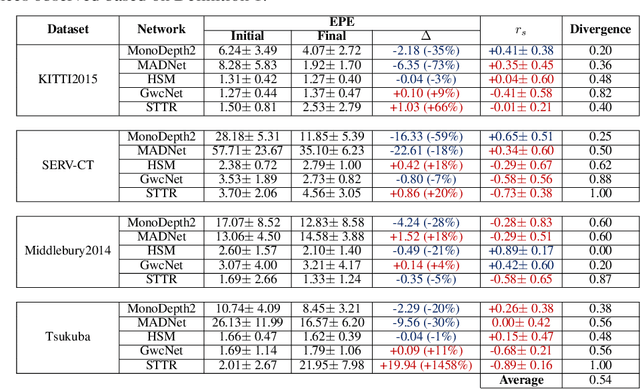
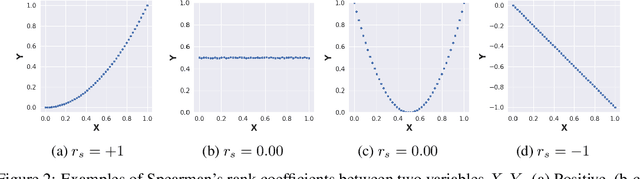
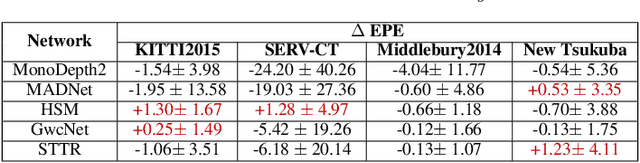
Scene depth estimation from stereo and monocular imagery is critical for extracting 3D information for downstream tasks such as scene understanding. Recently, learning-based methods for depth estimation have received much attention due to their high performance and flexibility in hardware choice. However, collecting ground truth data for supervised training of these algorithms is costly or outright impossible. This circumstance suggests a need for alternative learning approaches that do not require corresponding depth measurements. Indeed, self-supervised learning of depth estimation provides an increasingly popular alternative. It is based on the idea that observed frames can be synthesized from neighboring frames if accurate depth of the scene is known - or in this case, estimated. We show empirically that - contrary to common belief - improvements in image synthesis do not necessitate improvement in depth estimation. Rather, optimizing for image synthesis can result in diverging performance with respect to the main prediction objective - depth. We attribute this diverging phenomenon to aleatoric uncertainties, which originate from data. Based on our experiments on four datasets (spanning street, indoor, and medical) and five architectures (monocular and stereo), we conclude that this diverging phenomenon is independent of the dataset domain and not mitigated by commonly used regularization techniques. To underscore the importance of this finding, we include a survey of methods which use image synthesis, totaling 127 papers over the last six years. This observed divergence has not been previously reported or studied in depth, suggesting room for future improvement of self-supervised approaches which might be impacted the finding.
PnP-3D: A Plug-and-Play for 3D Point Clouds
Aug 16, 2021
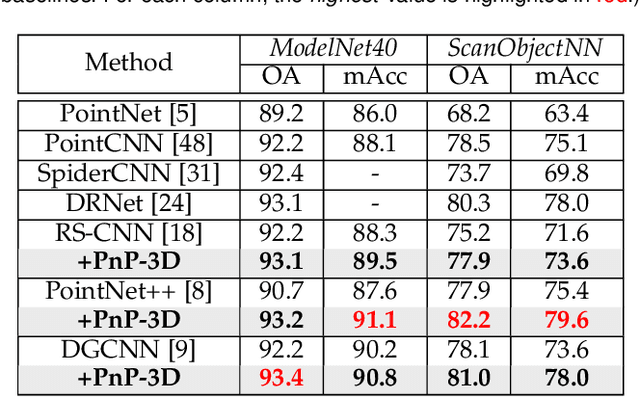
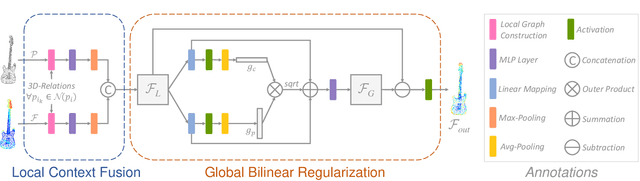

With the help of the deep learning paradigm, many point cloud networks have been invented for visual analysis. However, there is great potential for development of these networks since the given information of point cloud data has not been fully exploited. To improve the effectiveness of existing networks in analyzing point cloud data, we propose a plug-and-play module, PnP-3D, aiming to refine the fundamental point cloud feature representations by involving more local context and global bilinear response from explicit 3D space and implicit feature space. To thoroughly evaluate our approach, we conduct experiments on three standard point cloud analysis tasks, including classification, semantic segmentation, and object detection, where we select three state-of-the-art networks from each task for evaluation. Serving as a plug-and-play module, PnP-3D can significantly boost the performances of established networks. In addition to achieving state-of-the-art results on four widely used point cloud benchmarks, we present comprehensive ablation studies and visualizations to demonstrate our approach's advantages. The code will be available at https://github.com/ShiQiu0419/pnp-3d.
Towards Olfactory Information Extraction from Text: A Case Study on Detecting Smell Experiences in Novels
Dec 06, 2020
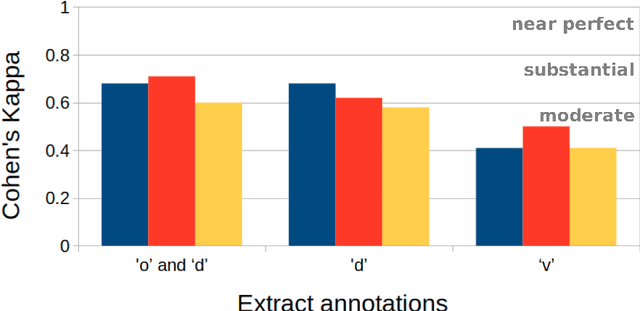
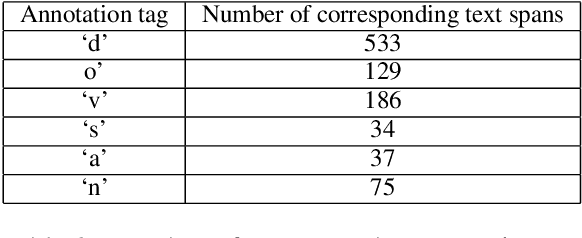
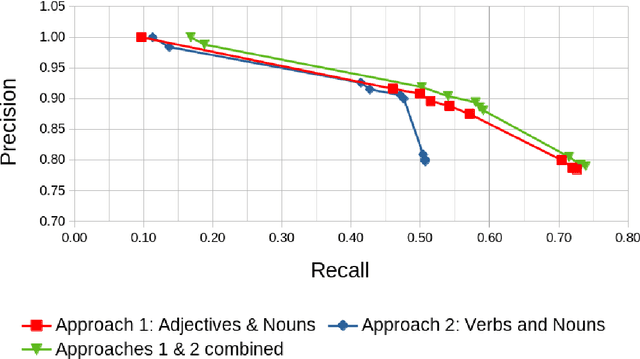
Environmental factors determine the smells we perceive, but societal factors factors shape the importance, sentiment and biases we give to them. Descriptions of smells in text, or as we call them `smell experiences', offer a window into these factors, but they must first be identified. To the best of our knowledge, no tool exists to extract references to smell experiences from text. In this paper, we present two variations on a semi-supervised approach to identify smell experiences in English literature. The combined set of patterns from both implementations offer significantly better performance than a keyword-based baseline.