 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Task-Driven Estimation and Control via Information Bottlenecks
Sep 27, 2018
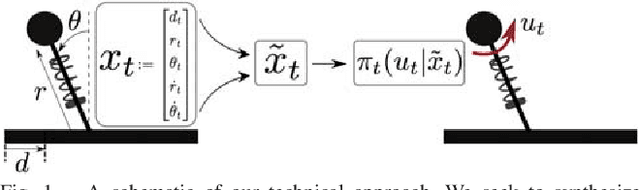
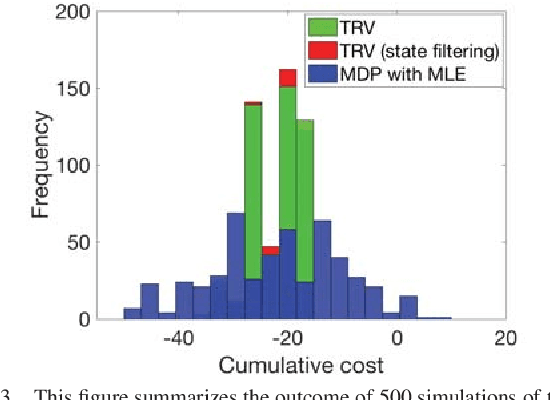
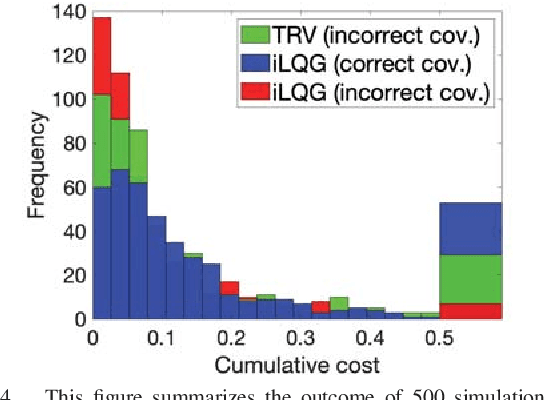
Our goal is to develop a principled and general algorithmic framework for task-driven estimation and control for robotic systems. State-of-the-art approaches for controlling robotic systems typically rely heavily on accurately estimating the full state of the robot (e.g., a running robot might estimate joint angles and velocities, torso state, and position relative to a goal). However, full state representations are often excessively rich for the specific task at hand and can lead to significant computational inefficiency and brittleness to errors in state estimation. In contrast, we present an approach that eschews such rich representations and seeks to create task-driven representations. The key technical insight is to leverage the theory of information bottlenecks}to formalize the notion of a "task-driven representation" in terms of information theoretic quantities that measure the minimality of a representation. We propose novel iterative algorithms for automatically synthesizing (offline) a task-driven representation (given in terms of a set of task-relevant variables (TRVs)) and a performant control policy that is a function of the TRVs. We present online algorithms for estimating the TRVs in order to apply the control policy. We demonstrate that our approach results in significant robustness to unmodeled measurement uncertainty both theoretically and via thorough simulation experiments including a spring-loaded inverted pendulum running to a goal location.
An End-to-End Deep Learning Approach for Epileptic Seizure Prediction
Aug 17, 2021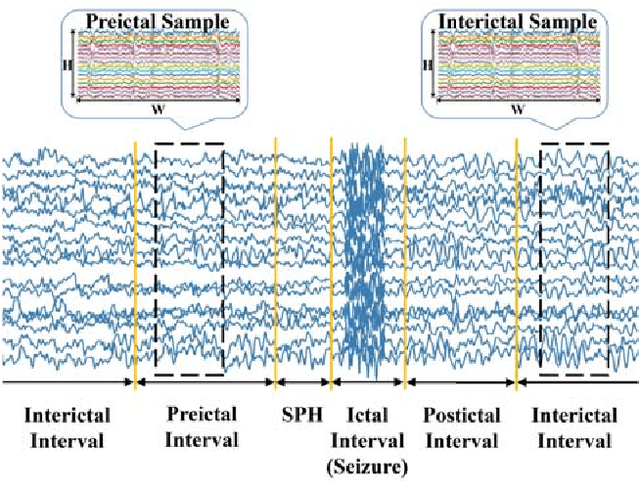
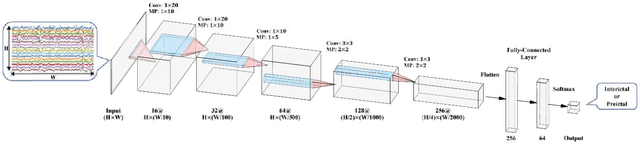
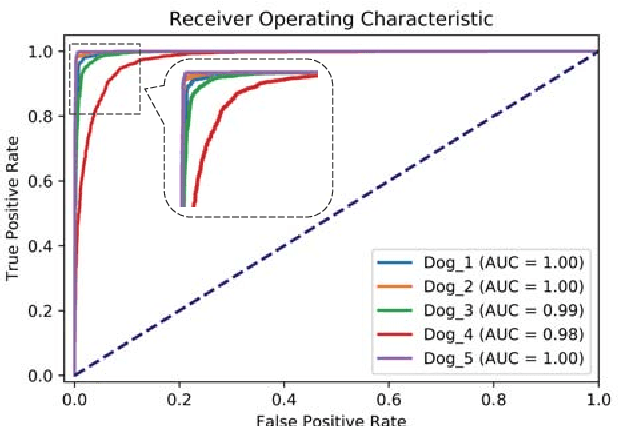
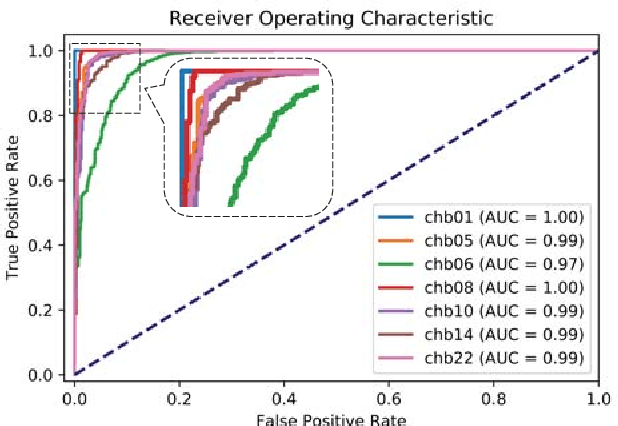
An accurate seizure prediction system enables early warnings before seizure onset of epileptic patients. It is extremely important for drug-refractory patients. Conventional seizure prediction works usually rely on features extracted from Electroencephalography (EEG) recordings and classification algorithms such as regression or support vector machine (SVM) to locate the short time before seizure onset. However, such methods cannot achieve high-accuracy prediction due to information loss of the hand-crafted features and the limited classification ability of regression and SVM algorithms. We propose an end-to-end deep learning solution using a convolutional neural network (CNN) in this paper. One and two dimensional kernels are adopted in the early- and late-stage convolution and max-pooling layers, respectively. The proposed CNN model is evaluated on Kaggle intracranial and CHB-MIT scalp EEG datasets. Overall sensitivity, false prediction rate, and area under receiver operating characteristic curve reaches 93.5%, 0.063/h, 0.981 and 98.8%, 0.074/h, 0.988 on two datasets respectively. Comparison with state-of-the-art works indicates that the proposed model achieves exceeding prediction performance.
Text is NOT Enough: Integrating Visual Impressions into Open-domain Dialogue Generation
Sep 18, 2021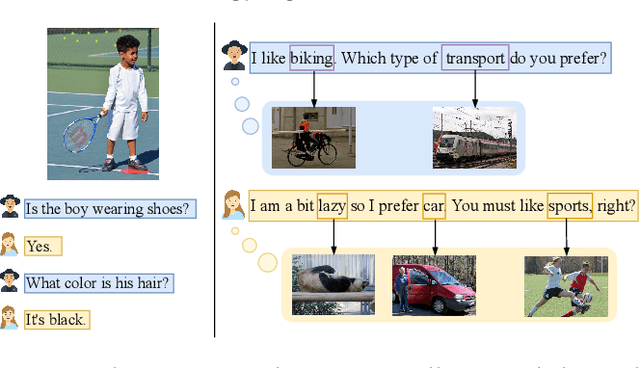
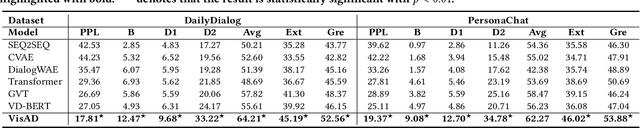
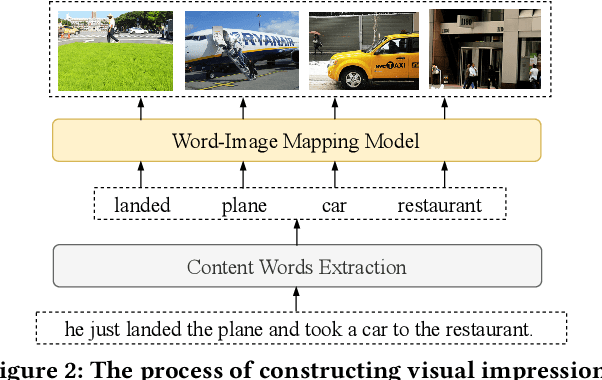
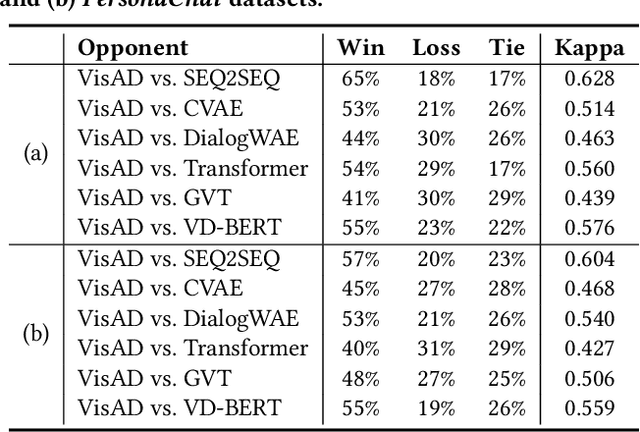
Open-domain dialogue generation in natural language processing (NLP) is by default a pure-language task, which aims to satisfy human need for daily communication on open-ended topics by producing related and informative responses. In this paper, we point out that hidden images, named as visual impressions (VIs), can be explored from the text-only data to enhance dialogue understanding and help generate better responses. Besides, the semantic dependency between an dialogue post and its response is complicated, e.g., few word alignments and some topic transitions. Therefore, the visual impressions of them are not shared, and it is more reasonable to integrate the response visual impressions (RVIs) into the decoder, rather than the post visual impressions (PVIs). However, both the response and its RVIs are not given directly in the test process. To handle the above issues, we propose a framework to explicitly construct VIs based on pure-language dialogue datasets and utilize them for better dialogue understanding and generation. Specifically, we obtain a group of images (PVIs) for each post based on a pre-trained word-image mapping model. These PVIs are used in a co-attention encoder to get a post representation with both visual and textual information. Since the RVIs are not provided directly during testing, we design a cascade decoder that consists of two sub-decoders. The first sub-decoder predicts the content words in response, and applies the word-image mapping model to get those RVIs. Then, the second sub-decoder generates the response based on the post and RVIs. Experimental results on two open-domain dialogue datasets show that our proposed approach achieves superior performance over competitive baselines.
Inspecting the Process of Bank Credit Rating via Visual Analytics
Aug 06, 2021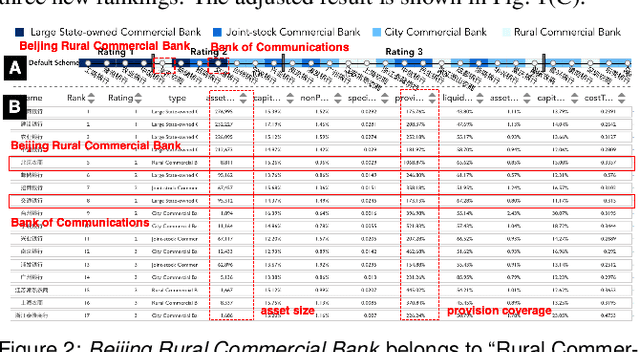
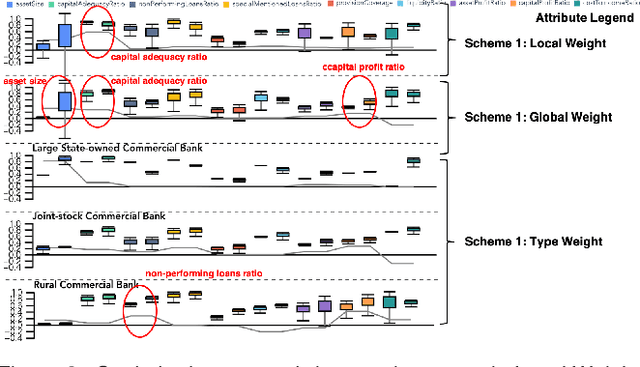
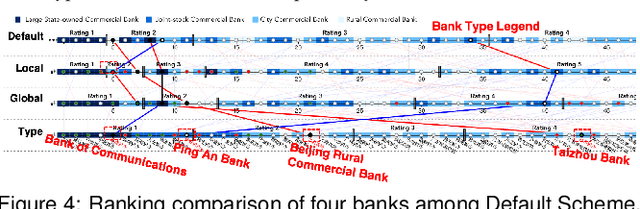
Bank credit rating classifies banks into different levels based on publicly disclosed and internal information, serving as an important input in financial risk management. However, domain experts have a vague idea of exploring and comparing different bank credit rating schemes. A loose connection between subjective and quantitative analysis and difficulties in determining appropriate indicator weights obscure understanding of bank credit ratings. Furthermore, existing models fail to consider bank types by just applying a unified indicator weight set to all banks. We propose RatingVis to assist experts in exploring and comparing different bank credit rating schemes. It supports interactively inferring indicator weights for banks by involving domain knowledge and considers bank types in the analysis loop. We conduct a case study with real-world bank data to verify the efficacy of RatingVis. Expert feedback suggests that our approach helps them better understand different rating schemes.
Self-Supervised Video Representation Learning with Meta-Contrastive Network
Aug 23, 2021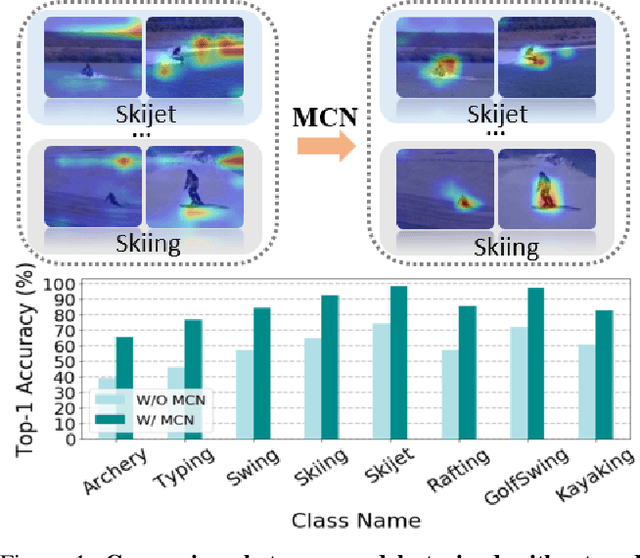
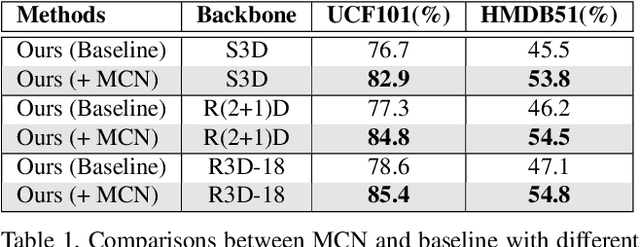
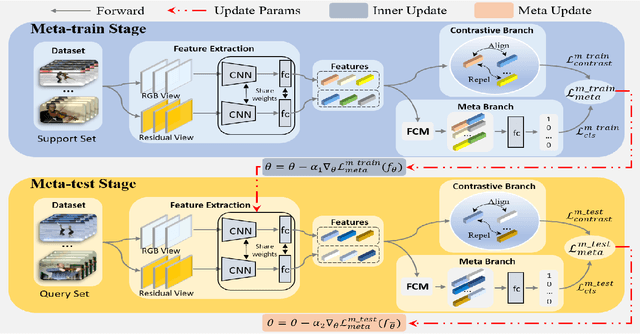
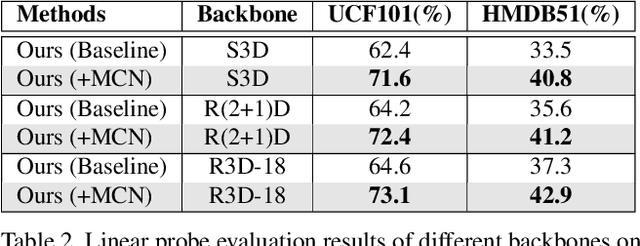
Self-supervised learning has been successfully applied to pre-train video representations, which aims at efficient adaptation from pre-training domain to downstream tasks. Existing approaches merely leverage contrastive loss to learn instance-level discrimination. However, lack of category information will lead to hard-positive problem that constrains the generalization ability of this kind of methods. We find that the multi-task process of meta learning can provide a solution to this problem. In this paper, we propose a Meta-Contrastive Network (MCN), which combines the contrastive learning and meta learning, to enhance the learning ability of existing self-supervised approaches. Our method contains two training stages based on model-agnostic meta learning (MAML), each of which consists of a contrastive branch and a meta branch. Extensive evaluations demonstrate the effectiveness of our method. For two downstream tasks, i.e., video action recognition and video retrieval, MCN outperforms state-of-the-art approaches on UCF101 and HMDB51 datasets. To be more specific, with R(2+1)D backbone, MCN achieves Top-1 accuracies of 84.8% and 54.5% for video action recognition, as well as 52.5% and 23.7% for video retrieval.
Learning Skeletal Graph Neural Networks for Hard 3D Pose Estimation
Aug 17, 2021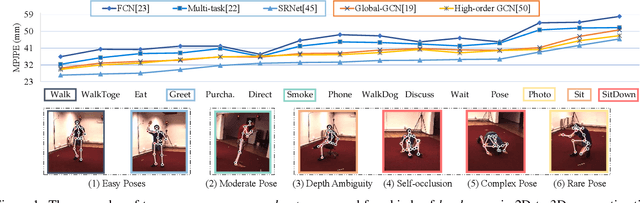
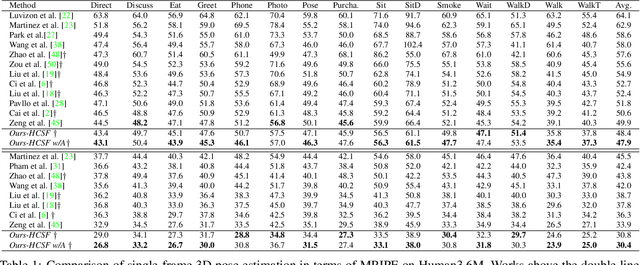
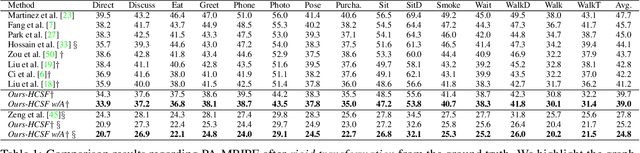
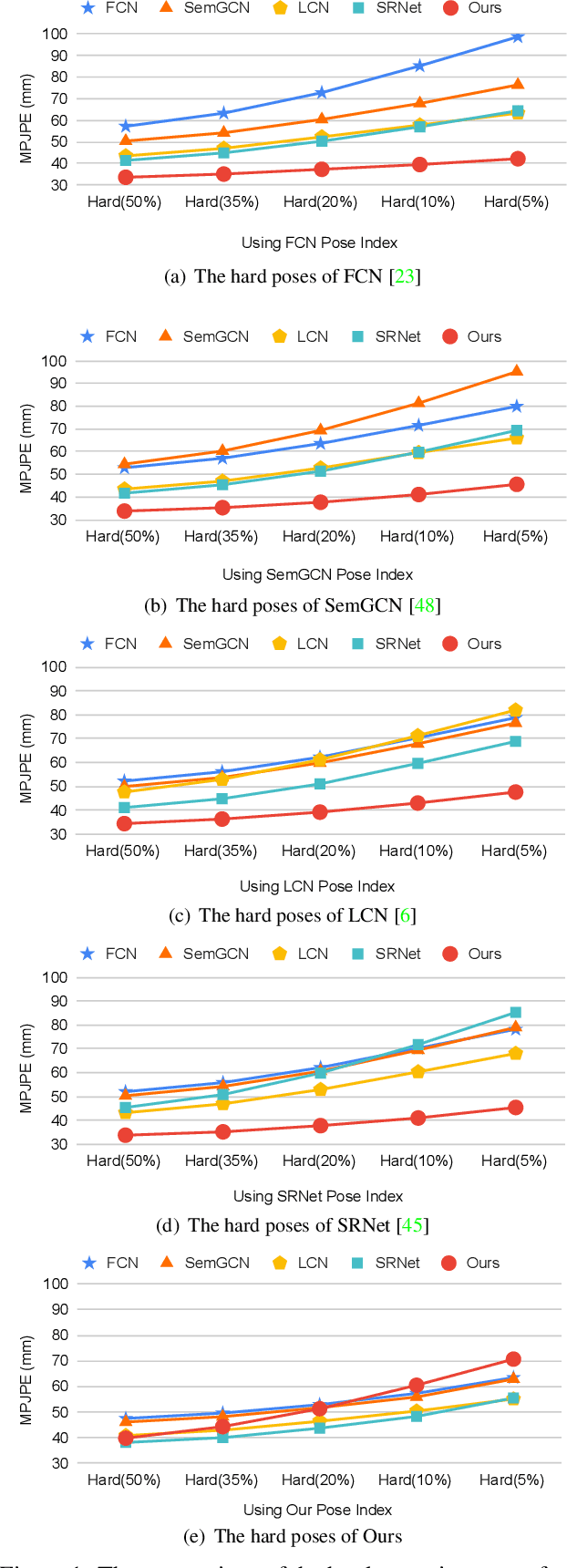
Various deep learning techniques have been proposed to solve the single-view 2D-to-3D pose estimation problem. While the average prediction accuracy has been improved significantly over the years, the performance on hard poses with depth ambiguity, self-occlusion, and complex or rare poses is still far from satisfactory. In this work, we target these hard poses and present a novel skeletal GNN learning solution. To be specific, we propose a hop-aware hierarchical channel-squeezing fusion layer to effectively extract relevant information from neighboring nodes while suppressing undesired noises in GNN learning. In addition, we propose a temporal-aware dynamic graph construction procedure that is robust and effective for 3D pose estimation. Experimental results on the Human3.6M dataset show that our solution achieves 10.3\% average prediction accuracy improvement and greatly improves on hard poses over state-of-the-art techniques. We further apply the proposed technique on the skeleton-based action recognition task and also achieve state-of-the-art performance. Our code is available at https://github.com/ailingzengzzz/Skeletal-GNN.
Social influence leads to the formation of diverse local trends
Aug 17, 2021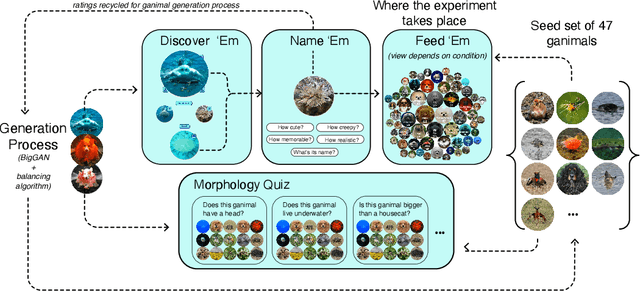

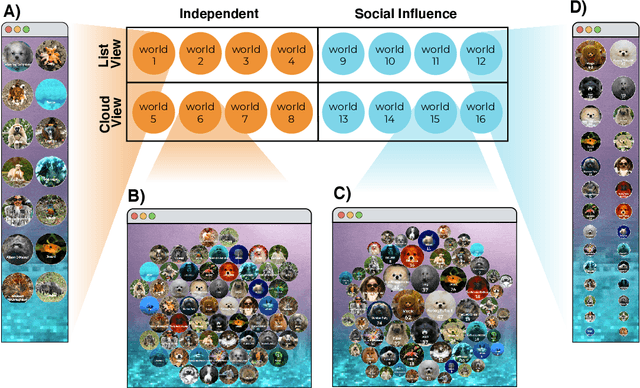
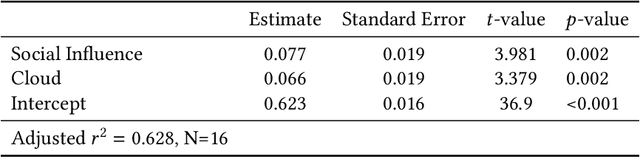
How does the visual design of digital platforms impact user behavior and the resulting environment? A body of work suggests that introducing social signals to content can increase both the inequality and unpredictability of its success, but has only been shown in the context of music listening. To further examine the effect of social influence on media popularity, we extend this research to the context of algorithmically-generated images by re-adapting Salganik et al's Music Lab experiment. On a digital platform where participants discover and curate AI-generated hybrid animals, we randomly assign both the knowledge of other participants' behavior and the visual presentation of the information. We successfully replicate the Music Lab's findings in the context of images, whereby social influence leads to an unpredictable winner-take-all market. However, we also find that social influence can lead to the emergence of local cultural trends that diverge from the status quo and are ultimately more diverse. We discuss the implications of these results for platform designers and animal conservation efforts.
Deep Reinforcement Learning for Equal Risk Pricing and Hedging under Dynamic Expectile Risk Measures
Sep 09, 2021
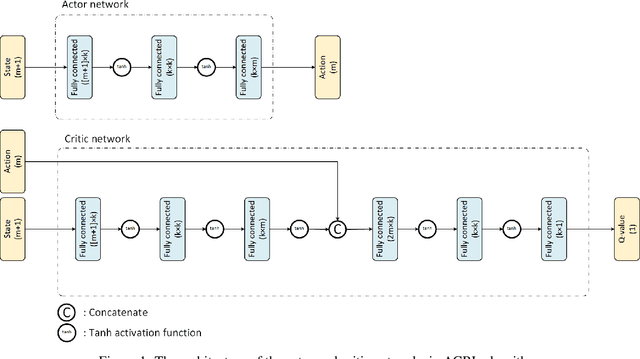
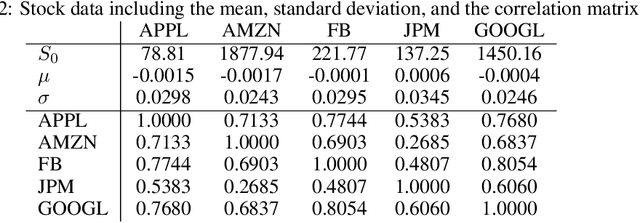
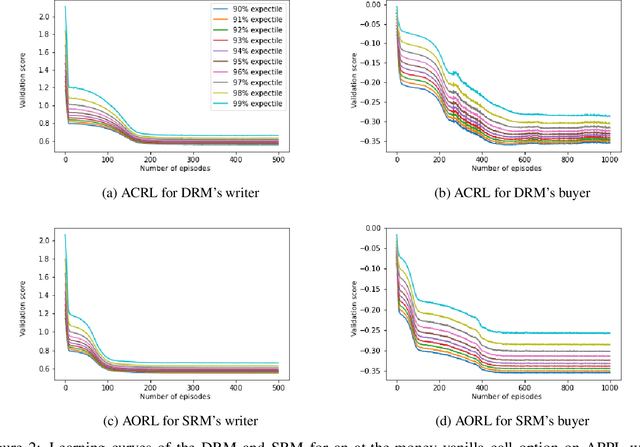
Recently equal risk pricing, a framework for fair derivative pricing, was extended to consider dynamic risk measures. However, all current implementations either employ a static risk measure that violates time consistency, or are based on traditional dynamic programming solution schemes that are impracticable in problems with a large number of underlying assets (due to the curse of dimensionality) or with incomplete asset dynamics information. In this paper, we extend for the first time a famous off-policy deterministic actor-critic deep reinforcement learning (ACRL) algorithm to the problem of solving a risk averse Markov decision process that models risk using a time consistent recursive expectile risk measure. This new ACRL algorithm allows us to identify high quality time consistent hedging policies (and equal risk prices) for options, such as basket options, that cannot be handled using traditional methods, or in context where only historical trajectories of the underlying assets are available. Our numerical experiments, which involve both a simple vanilla option and a more exotic basket option, confirm that the new ACRL algorithm can produce 1) in simple environments, nearly optimal hedging policies, and highly accurate prices, simultaneously for a range of maturities 2) in complex environments, good quality policies and prices using reasonable amount of computing resources; and 3) overall, hedging strategies that actually outperform the strategies produced using static risk measures when the risk is evaluated at later points of time.
Ctrl-P: Temporal Control of Prosodic Variation for Speech Synthesis
Jun 15, 2021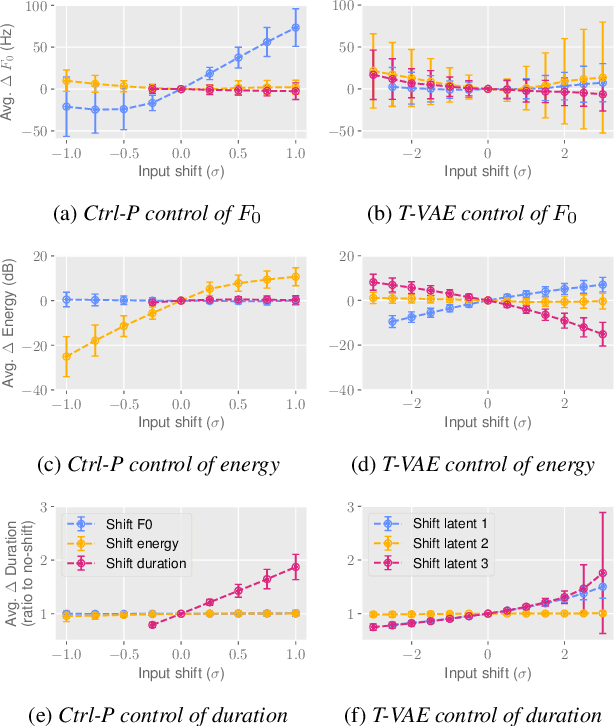
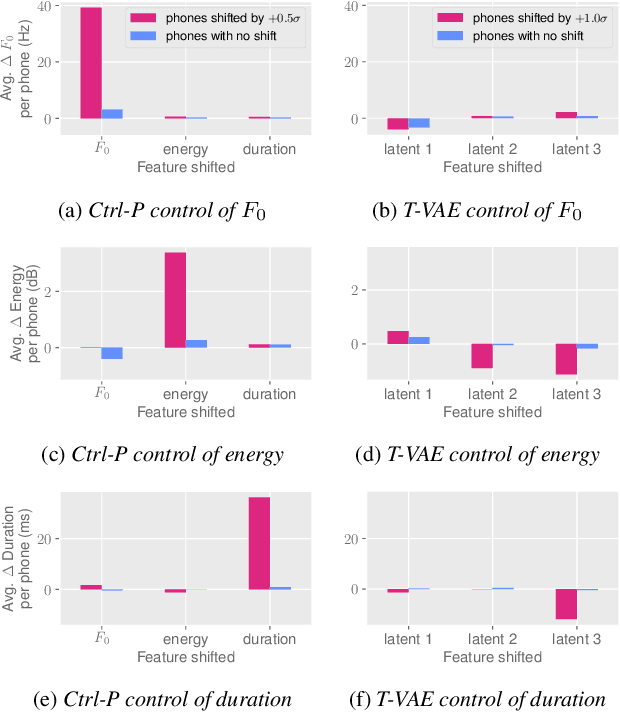
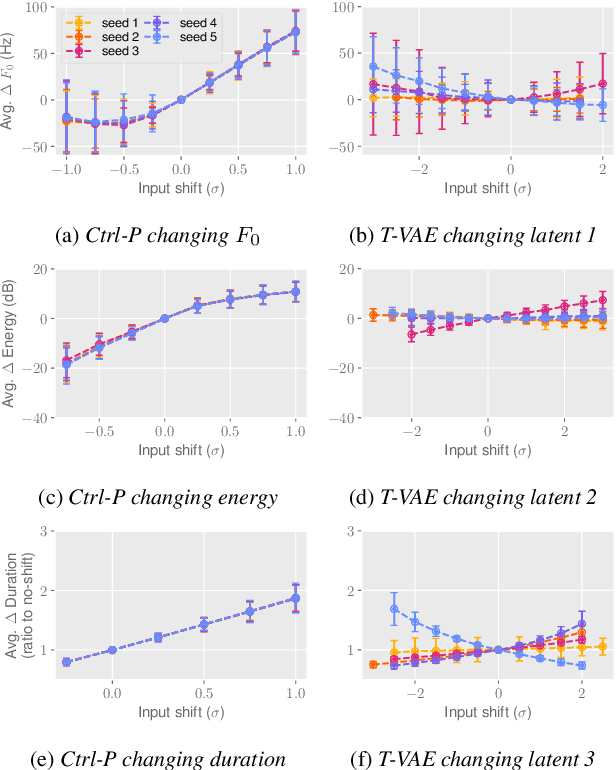
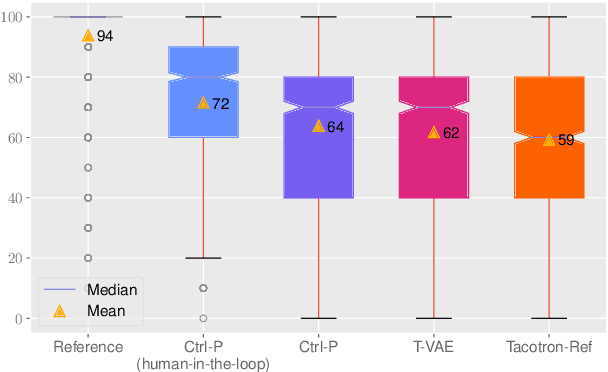
Text does not fully specify the spoken form, so text-to-speech models must be able to learn from speech data that vary in ways not explained by the corresponding text. One way to reduce the amount of unexplained variation in training data is to provide acoustic information as an additional learning signal. When generating speech, modifying this acoustic information enables multiple distinct renditions of a text to be produced. Since much of the unexplained variation is in the prosody, we propose a model that generates speech explicitly conditioned on the three primary acoustic correlates of prosody: $F_{0}$, energy and duration. The model is flexible about how the values of these features are specified: they can be externally provided, or predicted from text, or predicted then subsequently modified. Compared to a model that employs a variational auto-encoder to learn unsupervised latent features, our model provides more interpretable, temporally-precise, and disentangled control. When automatically predicting the acoustic features from text, it generates speech that is more natural than that from a Tacotron 2 model with reference encoder. Subsequent human-in-the-loop modification of the predicted acoustic features can significantly further increase naturalness.
Probabilistic Monocular 3D Human Pose Estimation with Normalizing Flows
Aug 02, 2021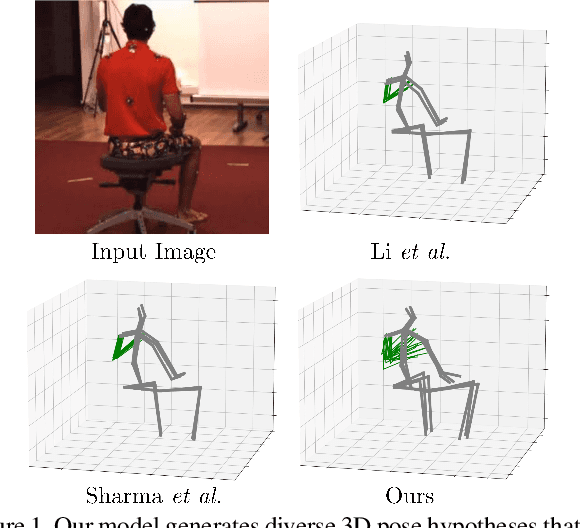
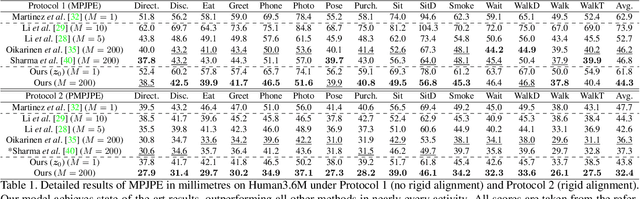
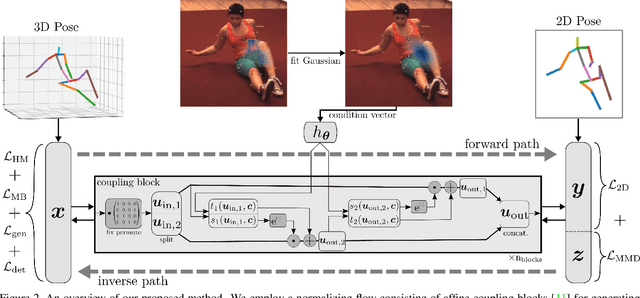

3D human pose estimation from monocular images is a highly ill-posed problem due to depth ambiguities and occlusions. Nonetheless, most existing works ignore these ambiguities and only estimate a single solution. In contrast, we generate a diverse set of hypotheses that represents the full posterior distribution of feasible 3D poses. To this end, we propose a normalizing flow based method that exploits the deterministic 3D-to-2D mapping to solve the ambiguous inverse 2D-to-3D problem. Additionally, uncertain detections and occlusions are effectively modeled by incorporating uncertainty information of the 2D detector as condition. Further keys to success are a learned 3D pose prior and a generalization of the best-of-M loss. We evaluate our approach on the two benchmark datasets Human3.6M and MPI-INF-3DHP, outperforming all comparable methods in most metrics. The implementation is available on GitHub.