 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The CM Algorithm for the Maximum Mutual Information Classifications of Unseen Instances
Jan 28, 2019
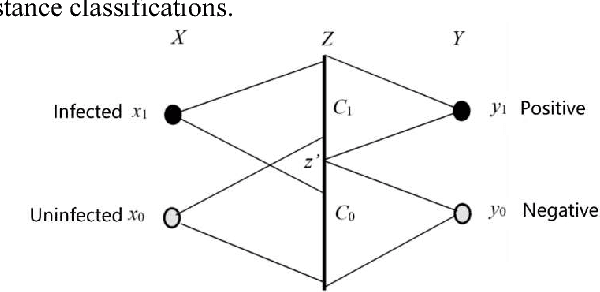
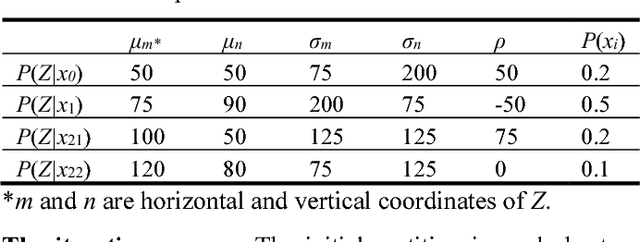
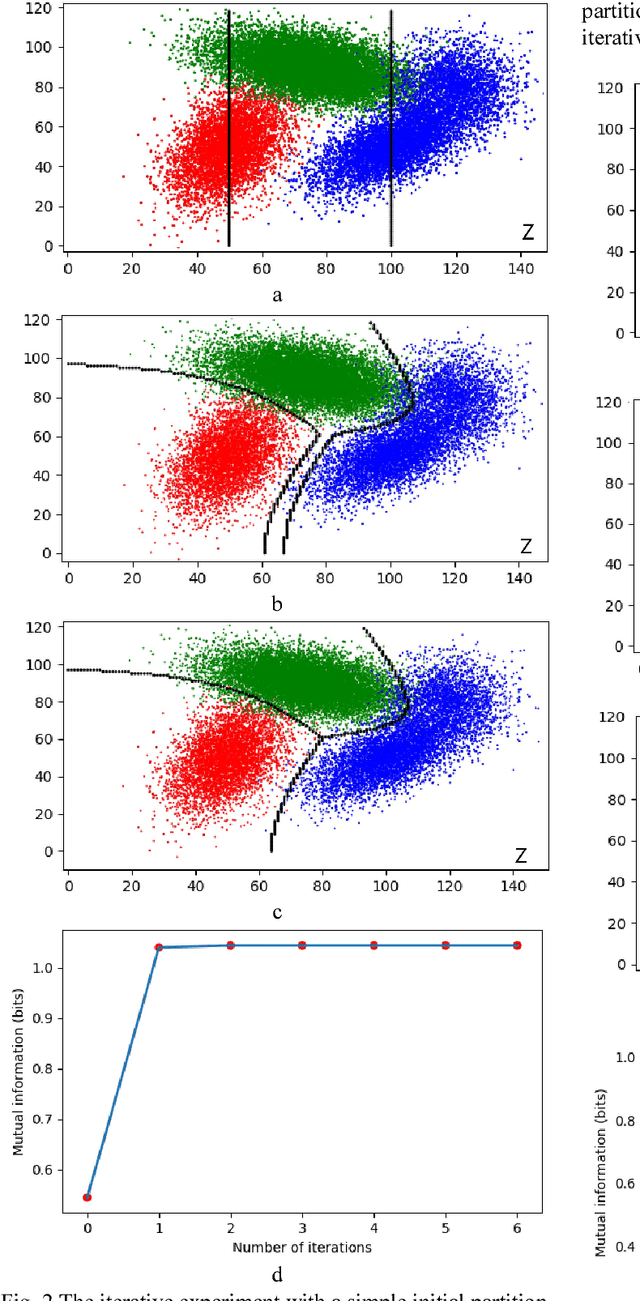
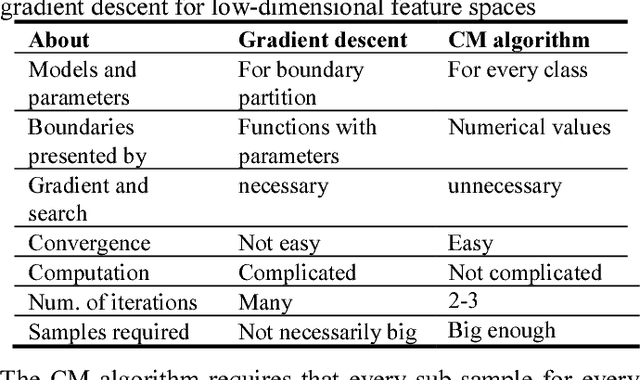
The Maximum Mutual Information (MMI) criterion is different from the Least Error Rate (LER) criterion. It can reduce failing to report small probability events. This paper introduces the Channels Matching (CM) algorithm for the MMI classifications of unseen instances. It also introduces some semantic information methods, which base the CM algorithm. In the CM algorithm, label learning is to let the semantic channel match the Shannon channel (Matching I) whereas classifying is to let the Shannon channel match the semantic channel (Matching II). We can achieve the MMI classifications by repeating Matching I and II. For low-dimensional feature spaces, we only use parameters to construct n likelihood functions for n different classes (rather than to construct partitioning boundaries as gradient descent) and expresses the boundaries by numerical values. Without searching in parameter spaces, the computation of the CM algorithm for low-dimensional feature spaces is very simple and fast. Using a two-dimensional example, we test the speed and reliability of the CM algorithm by different initial partitions. For most initial partitions, two iterations can make the mutual information surpass 99% of the convergent MMI. The analysis indicates that for high-dimensional feature spaces, we may combine the CM algorithm with neural networks to improve the MMI classifications for faster and more reliable convergence.
Prediction of Metacarpophalangeal joint angles and Classification of Hand configurations based on Ultrasound Imaging of the Forearm
Sep 23, 2021

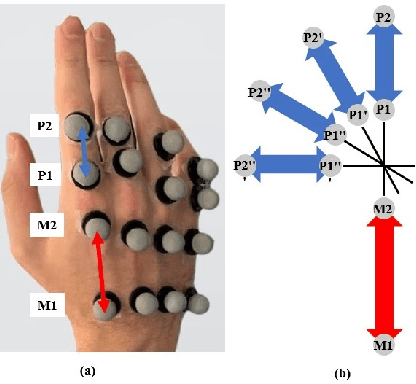
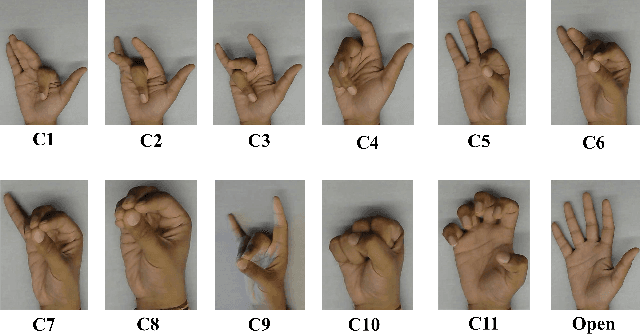
With the advancement in computing and robotics, it is necessary to develop fluent and intuitive methods for interacting with digital systems, AR/VR interfaces, and physical robotic systems. Hand movement recognition is widely used to enable this interaction. Hand configuration classification and Metacarpophalangeal (MCP) joint angle detection are important for a comprehensive reconstruction of the hand motion. Surface electromyography and other technologies have been used for the detection of hand motions. Ultrasound images of the forearm offer a way to visualize the internal physiology of the hand from a musculoskeletal perspective. Recent work has shown that these images can be classified using machine learning to predict various hand configurations. In this paper, we propose a Convolutional Neural Network (CNN) based deep learning pipeline for predicting the MCP joint angles. We supplement our results by using a Support Vector Classifier (SVC) to classify the ultrasound information into several predefined hand configurations based on activities of daily living (ADL). Ultrasound data from the forearm was obtained from 6 subjects who were instructed to move their hands according to predefined hand configurations relevant to ADLs. Motion capture data was acquired as the ground truth for hand movements at different speeds (0.5 Hz, 1 Hz, & 2 Hz) for the index, middle, ring, and pinky fingers. We were able to get promising SVC classification results on a subset of our collected data set. We demonstrated a correspondence between the predicted MCP joint angles and the actual MCP joint angles for the fingers, with an average root mean square error of 7.35 degrees. We implemented a low latency (6.25 - 9.1 Hz) pipeline for the prediction of both MCP joint angles and hand configuration estimation aimed at real-time control of digital devices, AR/VR interfaces, and physical robots.
Do Transformers Really Perform Bad for Graph Representation?
Jun 09, 2021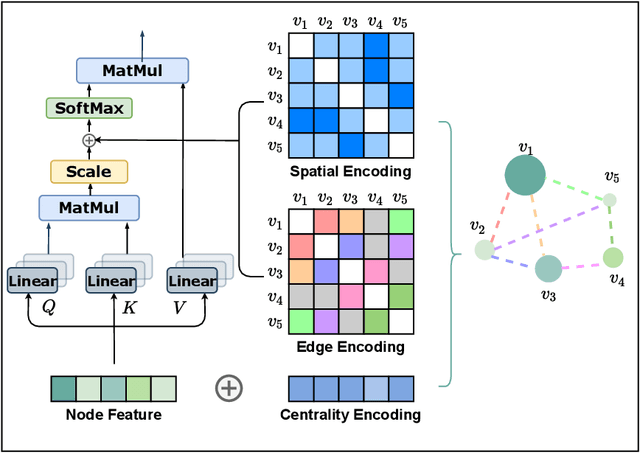
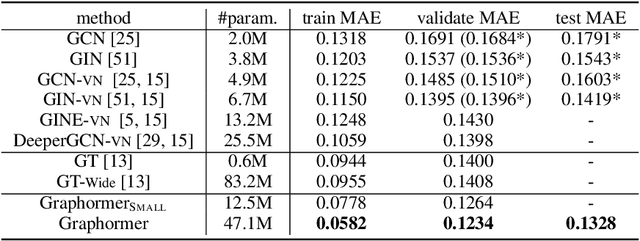
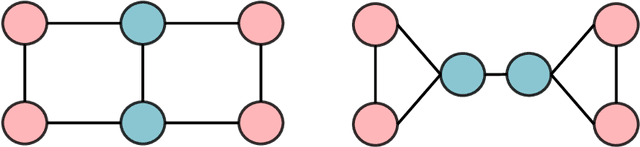

The Transformer architecture has become a dominant choice in many domains, such as natural language processing and computer vision. Yet, it has not achieved competitive performance on popular leaderboards of graph-level prediction compared to mainstream GNN variants. Therefore, it remains a mystery how Transformers could perform well for graph representation learning. In this paper, we solve this mystery by presenting Graphormer, which is built upon the standard Transformer architecture, and could attain excellent results on a broad range of graph representation learning tasks, especially on the recent OGB Large-Scale Challenge. Our key insight to utilizing Transformer in the graph is the necessity of effectively encoding the structural information of a graph into the model. To this end, we propose several simple yet effective structural encoding methods to help Graphormer better model graph-structured data. Besides, we mathematically characterize the expressive power of Graphormer and exhibit that with our ways of encoding the structural information of graphs, many popular GNN variants could be covered as the special cases of Graphormer.
Direct Detection Under Tukey Signalling
May 28, 2021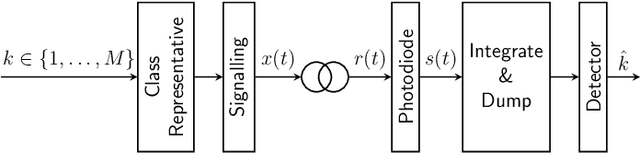
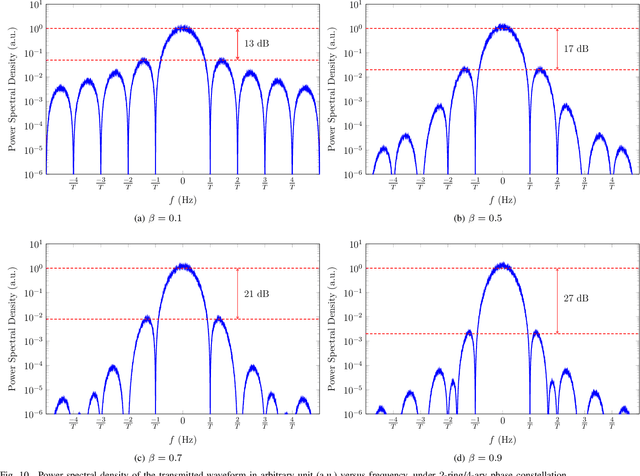
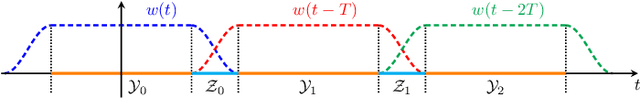
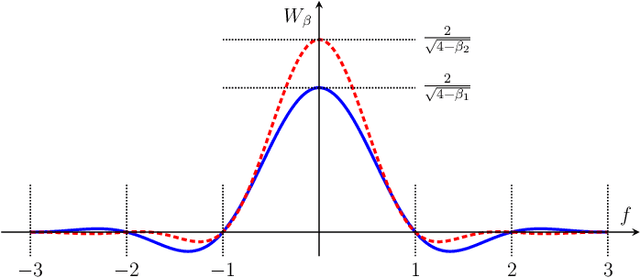
A new direct-detection-compatible signalling scheme is proposed for fiber-optic communication over short distances. Controlled inter-symbol interference is exploited to extract phase information, thereby achieving data rates within one bit per channel-use of those of a coherent detector.
Pix2Prof: fast extraction of sequential information from galaxy imagery via deep learning
Oct 01, 2020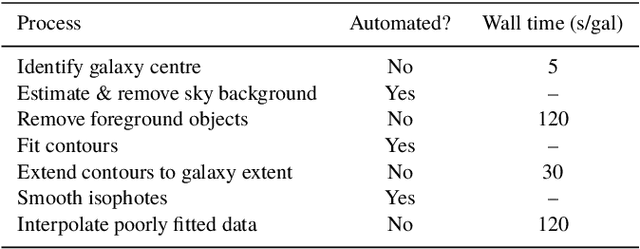
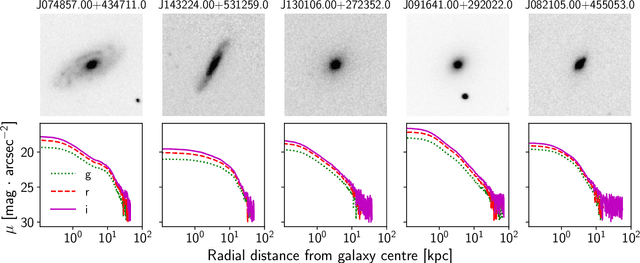
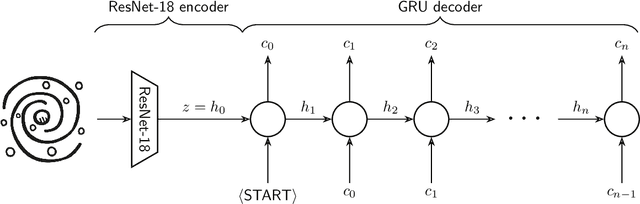
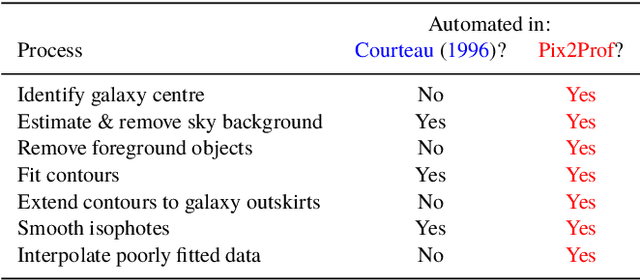
We present "Pix2Prof", a deep learning model that eliminates manual steps in the measurement of galaxy surface brightness (SB) profiles. We argue that a galaxy "profile" of any sort is conceptually similar to an image caption. This idea allows us to leverage image captioning methods from the field of natural language processing, and so we design Pix2Prof as a float sequence "captioning" model suitable for SB profile inferral. We demonstrate the technique by approximating the galaxy SB fitting method described by Courteau (1996), an algorithm with several manual steps. We use g, r, and i-band images from the Sloan Digital Sky Survey (SDSS) Data Release 10 (DR10) to train Pix2Prof on 5367 image--SB profile pairs. We test Pix2Prof on 300 SDSS DR10 galaxy image--SB profile pairs in each of the g, r, and i bands to calibrate the mean SB deviation between interactive manual measurements and automated extractions, and demonstrate the effectiveness of Pix2Prof in mirroring the manual method. Pix2Prof processes $\sim1$ image per second on an Intel Xeon E5-2650 v3 and $\sim2$ images per second on a NVIDIA TESLA V100, improving on the speed of the manual interactive method by more than two orders of magnitude. Crucially, Pix2Prof requires no manual interaction, and since galaxy profile estimation is an embarrassingly parallel problem, we can further increase the throughput by running many Pix2Prof instances simultaneously. In perspective, Pix2Prof would take under an hour to infer profiles for $10^5$ galaxies on a single NVIDIA DGX-2 system. A single human expert would take approximately two years to complete the same task. Automated methodology such as this will accelerate the analysis of the next generation of large area sky surveys expected to yield hundreds of millions of targets. In such instances, all manual approaches -- even those involving a large number of experts -- would be impractical.
Luminance Attentive Networks for HDR Image and Panorama Reconstruction
Sep 14, 2021
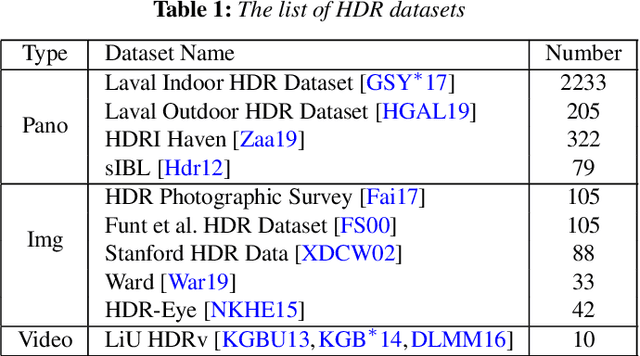
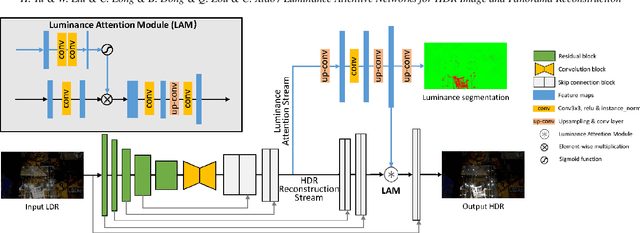
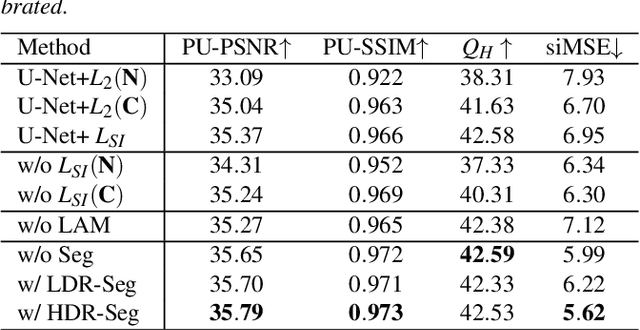
It is very challenging to reconstruct a high dynamic range (HDR) from a low dynamic range (LDR) image as an ill-posed problem. This paper proposes a luminance attentive network named LANet for HDR reconstruction from a single LDR image. Our method is based on two fundamental observations: (1) HDR images stored in relative luminance are scale-invariant, which means the HDR images will hold the same information when multiplied by any positive real number. Based on this observation, we propose a novel normalization method called " HDR calibration " for HDR images stored in relative luminance, calibrating HDR images into a similar luminance scale according to the LDR images. (2) The main difference between HDR images and LDR images is in under-/over-exposed areas, especially those highlighted. Following this observation, we propose a luminance attention module with a two-stream structure for LANet to pay more attention to the under-/over-exposed areas. In addition, we propose an extended network called panoLANet for HDR panorama reconstruction from an LDR panorama and build a dualnet structure for panoLANet to solve the distortion problem caused by the equirectangular panorama. Extensive experiments show that our proposed approach LANet can reconstruct visually convincing HDR images and demonstrate its superiority over state-of-the-art approaches in terms of all metrics in inverse tone mapping. The image-based lighting application with our proposed panoLANet also demonstrates that our method can simulate natural scene lighting using only LDR panorama. Our source code is available at https://github.com/LWT3437/LANet.
Information-Theoretic Active Learning for Content-Based Image Retrieval
Sep 07, 2018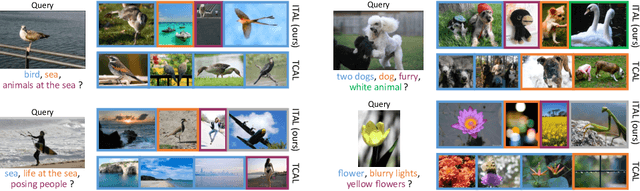
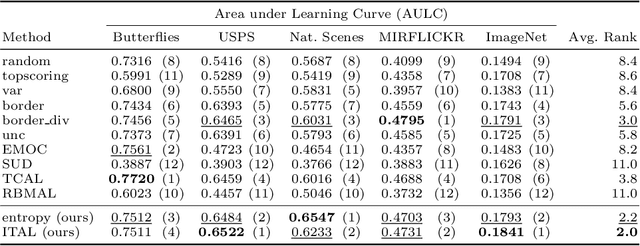
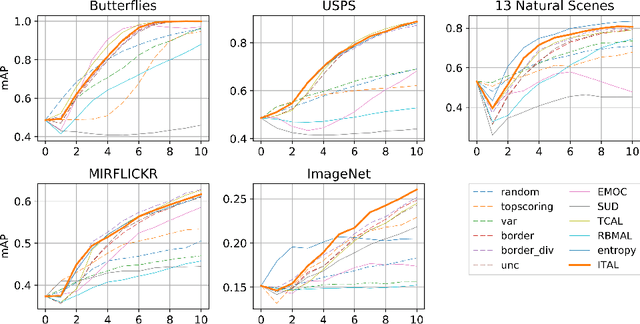
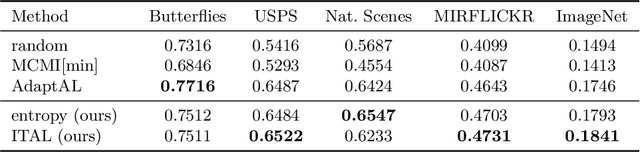
We propose Information-Theoretic Active Learning (ITAL), a novel batch-mode active learning method for binary classification, and apply it for acquiring meaningful user feedback in the context of content-based image retrieval. Instead of combining different heuristics such as uncertainty, diversity, or density, our method is based on maximizing the mutual information between the predicted relevance of the images and the expected user feedback regarding the selected batch. We propose suitable approximations to this computationally demanding problem and also integrate an explicit model of user behavior that accounts for possible incorrect labels and unnameable instances. Furthermore, our approach does not only take the structure of the data but also the expected model output change caused by the user feedback into account. In contrast to other methods, ITAL turns out to be highly flexible and provides state-of-the-art performance across various datasets, such as MIRFLICKR and ImageNet.
Truth Discovery in Sequence Labels from Crowds
Sep 09, 2021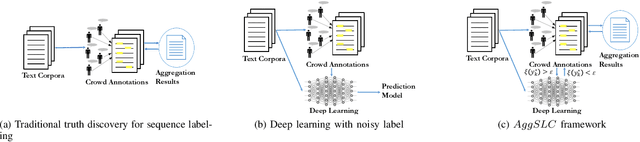
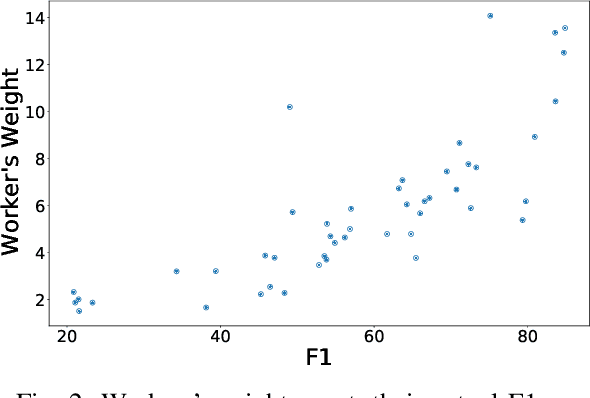
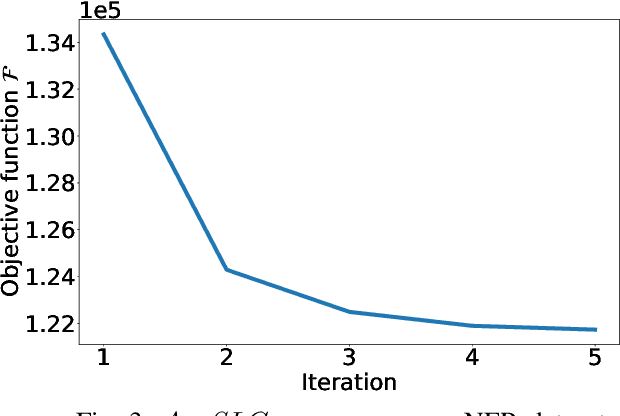
Annotations quality and quantity positively affect the performance of sequence labeling, a vital task in Natural Language Processing. Hiring domain experts to annotate a corpus set is very costly in terms of money and time. Crowdsourcing platforms, such as Amazon Mechanical Turk (AMT), have been deployed to assist in this purpose. However, these platforms are prone to human errors due to the lack of expertise; hence, one worker's annotations cannot be directly used to train the model. Existing literature in annotation aggregation more focuses on binary or multi-choice problems. In recent years, handling the sequential label aggregation tasks on imbalanced datasets with complex dependencies between tokens has been challenging. To conquer the challenge, we propose an optimization-based method that infers the best set of aggregated annotations using labels provided by workers. The proposed Aggregation method for Sequential Labels from Crowds ($AggSLC$) jointly considers the characteristics of sequential labeling tasks, workers' reliabilities, and advanced machine learning techniques. We evaluate $AggSLC$ on different crowdsourced data for Named Entity Recognition (NER), Information Extraction tasks in biomedical (PICO), and the simulated dataset. Our results show that the proposed method outperforms the state-of-the-art aggregation methods. To achieve insights into the framework, we study $AggSLC$ components' effectiveness through ablation studies by evaluating our model in the absence of the prediction module and inconsistency loss function. Theoretical analysis of our algorithm's convergence points that the proposed $AggSLC$ halts after a finite number of iterations.
Silent Speech and Emotion Recognition from Vocal Tract Shape Dynamics in Real-Time MRI
Jun 16, 2021
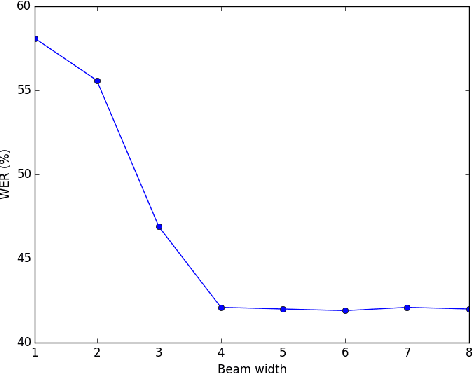
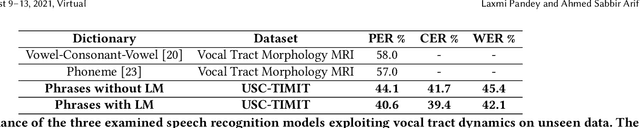
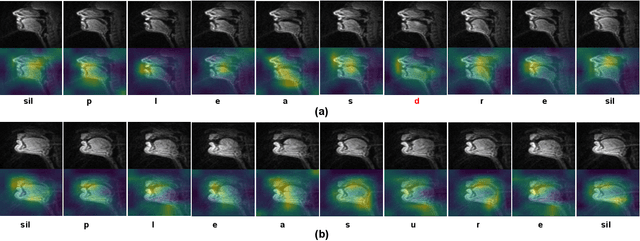
Speech sounds of spoken language are obtained by varying configuration of the articulators surrounding the vocal tract. They contain abundant information that can be utilized to better understand the underlying mechanism of human speech production. We propose a novel deep neural network-based learning framework that understands acoustic information in the variable-length sequence of vocal tract shaping during speech production, captured by real-time magnetic resonance imaging (rtMRI), and translate it into text. The proposed framework comprises of spatiotemporal convolutions, a recurrent network, and the connectionist temporal classification loss, trained entirely end-to-end. On the USC-TIMIT corpus, the model achieved a 40.6% PER at sentence-level, much better compared to the existing models. To the best of our knowledge, this is the first study that demonstrates the recognition of entire spoken sentence based on an individual's articulatory motions captured by rtMRI video. We also performed an analysis of variations in the geometry of articulation in each sub-regions of the vocal tract (i.e., pharyngeal, velar and dorsal, hard palate, labial constriction region) with respect to different emotions and genders. Results suggest that each sub-regions distortion is affected by both emotion and gender.
HintedBT: Augmenting Back-Translation with Quality and Transliteration Hints
Sep 09, 2021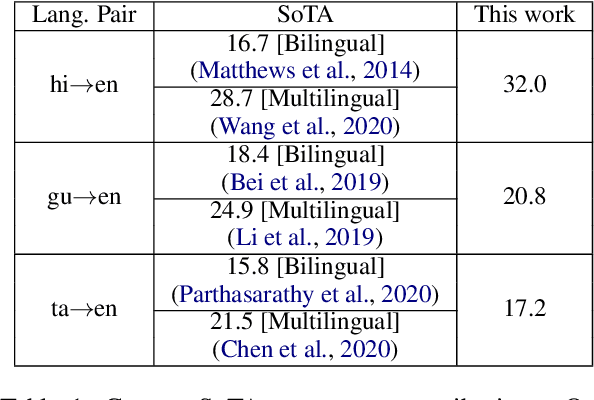


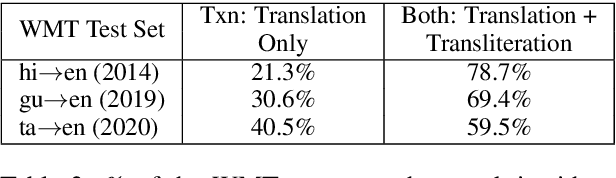
Back-translation (BT) of target monolingual corpora is a widely used data augmentation strategy for neural machine translation (NMT), especially for low-resource language pairs. To improve effectiveness of the available BT data, we introduce HintedBT -- a family of techniques which provides hints (through tags) to the encoder and decoder. First, we propose a novel method of using both high and low quality BT data by providing hints (as source tags on the encoder) to the model about the quality of each source-target pair. We don't filter out low quality data but instead show that these hints enable the model to learn effectively from noisy data. Second, we address the problem of predicting whether a source token needs to be translated or transliterated to the target language, which is common in cross-script translation tasks (i.e., where source and target do not share the written script). For such cases, we propose training the model with additional hints (as target tags on the decoder) that provide information about the operation required on the source (translation or both translation and transliteration). We conduct experiments and detailed analyses on standard WMT benchmarks for three cross-script low/medium-resource language pairs: {Hindi,Gujarati,Tamil}-to-English. Our methods compare favorably with five strong and well established baselines. We show that using these hints, both separately and together, significantly improves translation quality and leads to state-of-the-art performance in all three language pairs in corresponding bilingual settings.