 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cough Detection from Acoustic signals for patient monitoring system
Jul 25, 2021
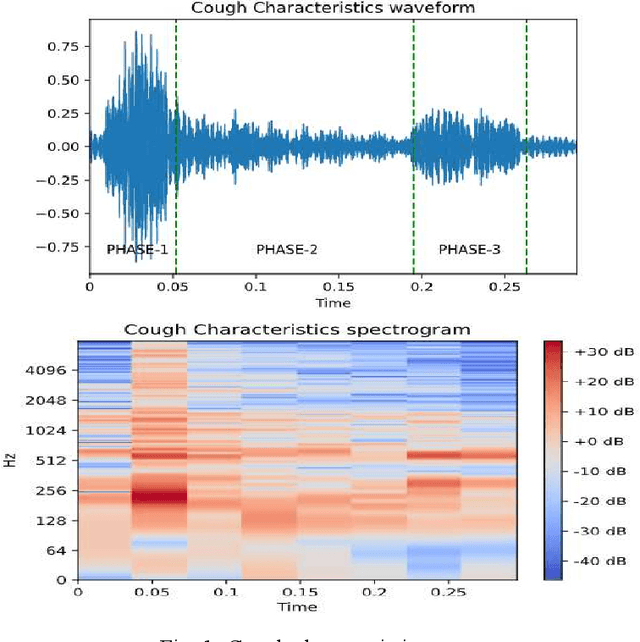
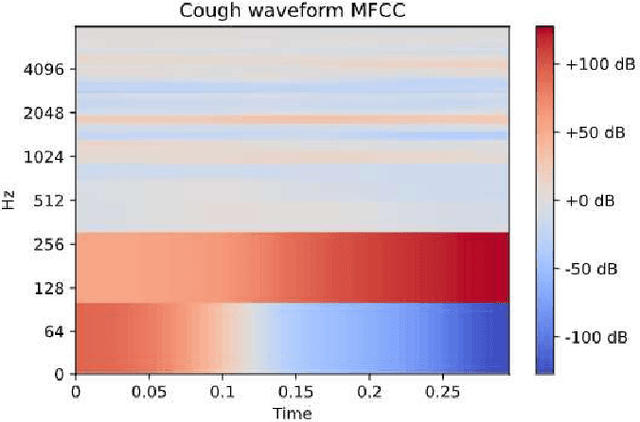
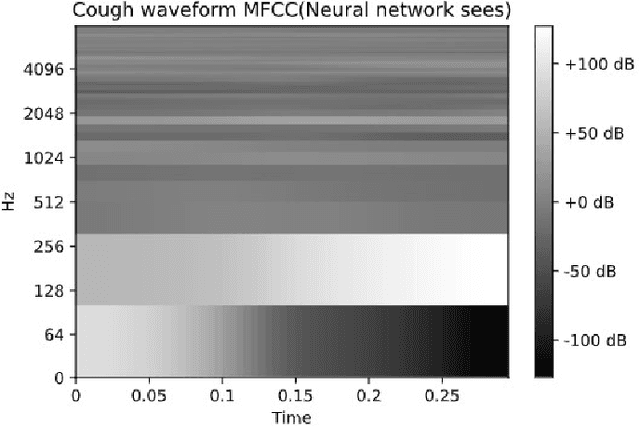
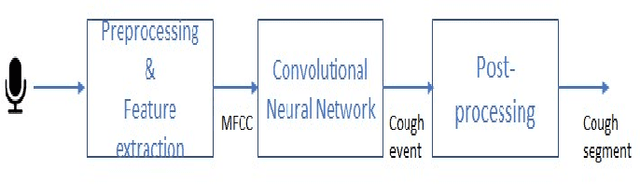
Cough is one of the most common symptoms in all respiratory diseases. In cases like Chronic Obstructive Pulmonary Disease, Asthma, acute and chronic Bronchitis and the recent pandemic Covid-19, the early identification of cough is important to provide healthcare professionals with useful clinical information such as frequency, severity, and nature of cough to enable better diagnosis. This paper presents and demonstrates best feature selection using MFCC which can help to determine cough events, eventually helping a neural network to learn and improve accuracy of cough detection. The paper proposes to achieve performance of 97.77% Sensitivity (SE), 98.75% Specificity (SP) and 98.17% F1-score with a very light binary classification network of size close to 16K parameters, enabling fitment into smart IoT devices.
Luminance Attentive Networks for HDR Image and Panorama Reconstruction
Sep 14, 2021
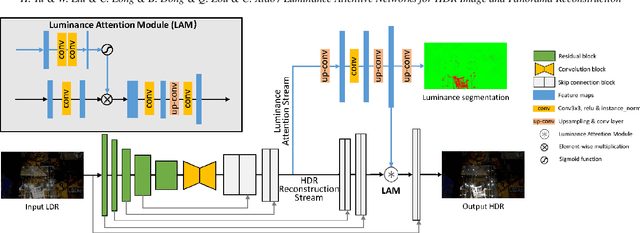
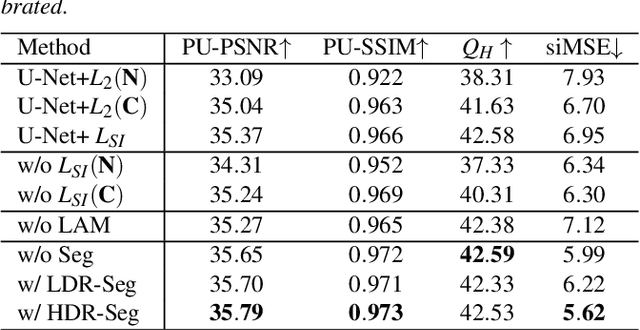
It is very challenging to reconstruct a high dynamic range (HDR) from a low dynamic range (LDR) image as an ill-posed problem. This paper proposes a luminance attentive network named LANet for HDR reconstruction from a single LDR image. Our method is based on two fundamental observations: (1) HDR images stored in relative luminance are scale-invariant, which means the HDR images will hold the same information when multiplied by any positive real number. Based on this observation, we propose a novel normalization method called " HDR calibration " for HDR images stored in relative luminance, calibrating HDR images into a similar luminance scale according to the LDR images. (2) The main difference between HDR images and LDR images is in under-/over-exposed areas, especially those highlighted. Following this observation, we propose a luminance attention module with a two-stream structure for LANet to pay more attention to the under-/over-exposed areas. In addition, we propose an extended network called panoLANet for HDR panorama reconstruction from an LDR panorama and build a dualnet structure for panoLANet to solve the distortion problem caused by the equirectangular panorama. Extensive experiments show that our proposed approach LANet can reconstruct visually convincing HDR images and demonstrate its superiority over state-of-the-art approaches in terms of all metrics in inverse tone mapping. The image-based lighting application with our proposed panoLANet also demonstrates that our method can simulate natural scene lighting using only LDR panorama. Our source code is available at https://github.com/LWT3437/LANet.
Deep Learning from Dual-Energy Information for Whole-Heart Segmentation in Dual-Energy and Single-Energy Non-Contrast-Enhanced Cardiac CT
Aug 10, 2020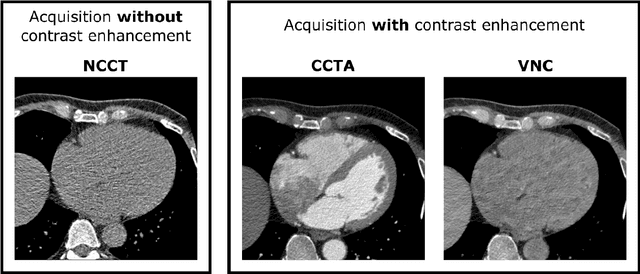
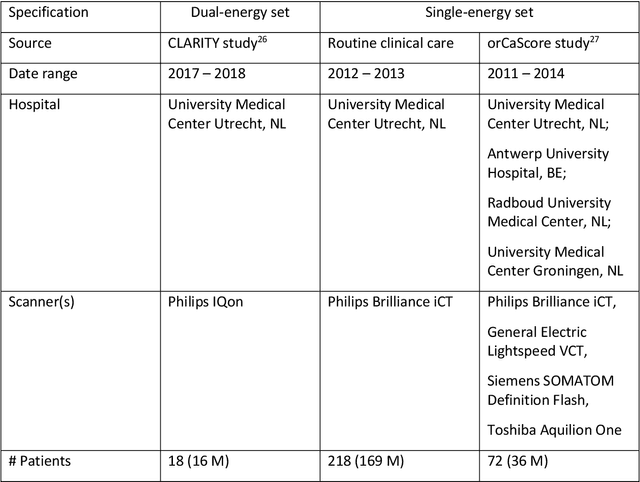
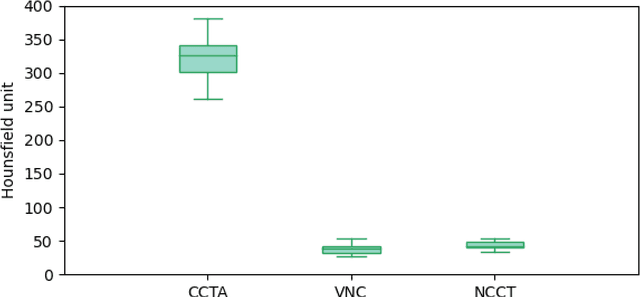

Deep learning-based whole-heart segmentation in coronary CT angiography (CCTA) allows the extraction of quantitative imaging measures for cardiovascular risk prediction. Automatic extraction of these measures in patients undergoing only non-contrast-enhanced CT (NCCT) scanning would be valuable. In this work, we leverage information provided by a dual-layer detector CT scanner to obtain a reference standard in virtual non-contrast (VNC) CT images mimicking NCCT images, and train a 3D convolutional neural network (CNN) for the segmentation of VNC as well as NCCT images. Contrast-enhanced acquisitions on a dual-layer detector CT scanner were reconstructed into a CCTA and a perfectly aligned VNC image. In each CCTA image, manual reference segmentations of the left ventricular (LV) myocardium, LV cavity, right ventricle, left atrium, right atrium, ascending aorta, and pulmonary artery trunk were obtained and propagated to the corresponding VNC image. These VNC images and reference segmentations were used to train 3D CNNs for automatic segmentation in either VNC images or NCCT images. Automatic segmentations in VNC images showed good agreement with reference segmentations, with an average Dice similarity coefficient of 0.897 \pm 0.034 and an average symmetric surface distance of 1.42 \pm 0.45 mm. Volume differences [95% confidence interval] between automatic NCCT and reference CCTA segmentations were -19 [-67; 30] mL for LV myocardium, -25 [-78; 29] mL for LV cavity, -29 [-73; 14] mL for right ventricle, -20 [-62; 21] mL for left atrium, and -19 [-73; 34] mL for right atrium, respectively. In 214 (74%) NCCT images from an independent multi-vendor multi-center set, two observers agreed that the automatic segmentation was mostly accurate or better. This method might enable quantification of additional cardiac measures from NCCT images for improved cardiovascular risk prediction.
Terahertz Wireless Communications with Flexible Index Modulation Aided Pilot Design
Jun 23, 2021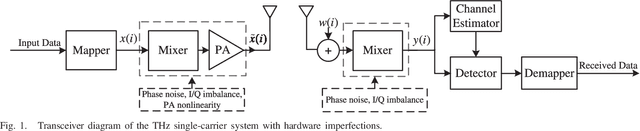
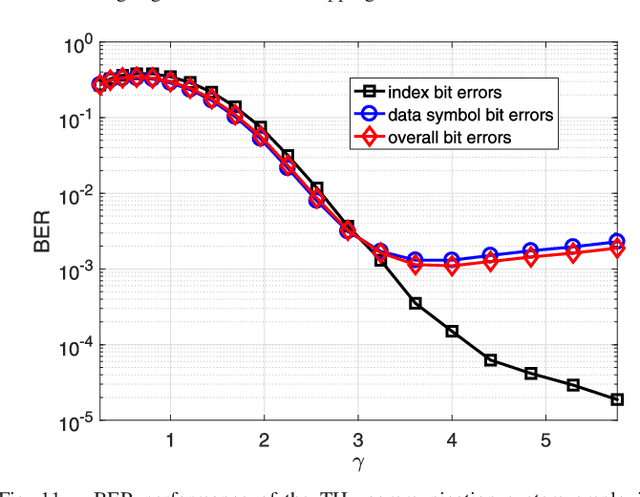
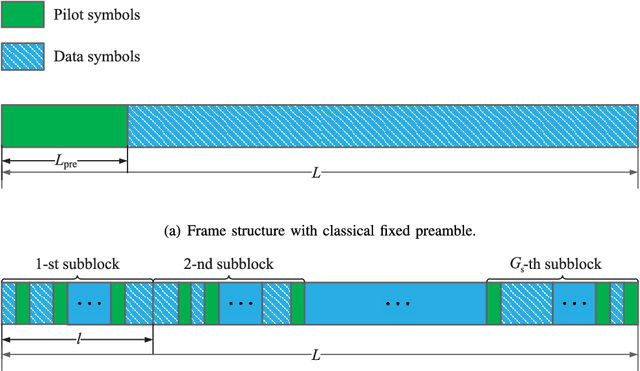
Terahertz (THz) wireless communication is envisioned as a promising technology, which is capable of providing ultra-high-rate transmission up to Terabit per second. However, some hardware imperfections, which are generally neglected in the existing literature concerning lower data rates and traditional operating frequencies, cannot be overlooked in the THz systems. Hardware imperfections usually consist of phase noise, in-phase/quadrature imbalance, and nonlinearity of power amplifier. Due to the time-variant characteristic of phase noise, frequent pilot insertion is required, leading to decreased spectral efficiency. In this paper, to address this issue, a novel pilot design strategy is proposed based on index modulation (IM), where the positions of pilots are flexibly changed in the data frame, and additional information bits can be conveyed by indices of pilots. Furthermore, a turbo receiving algorithm is developed, which jointly performs the detection of pilot indices and channel estimation in an iterative manner. It is shown that the proposed turbo receiver works well even under the situation where the prior knowledge of channel state information is outdated. Analytical and simulation results validate that the proposed schemes achieve significant enhancement of bit-error rate performance and channel estimation accuracy, whilst attaining higher spectral efficiency in comparison with its classical counterpart.
Truth Discovery in Sequence Labels from Crowds
Sep 09, 2021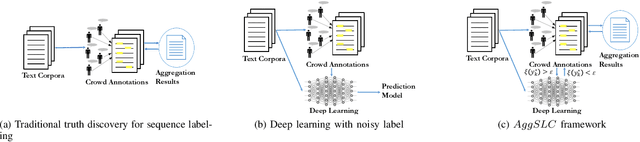
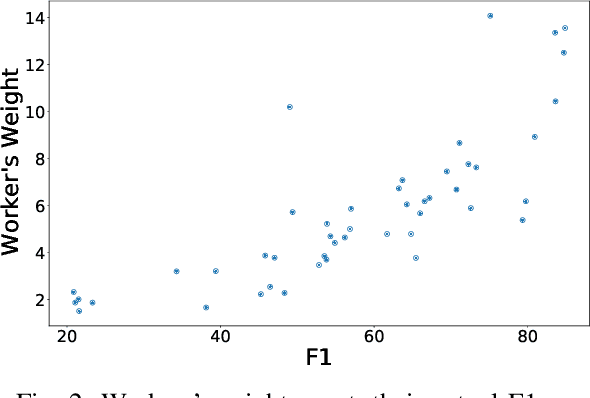
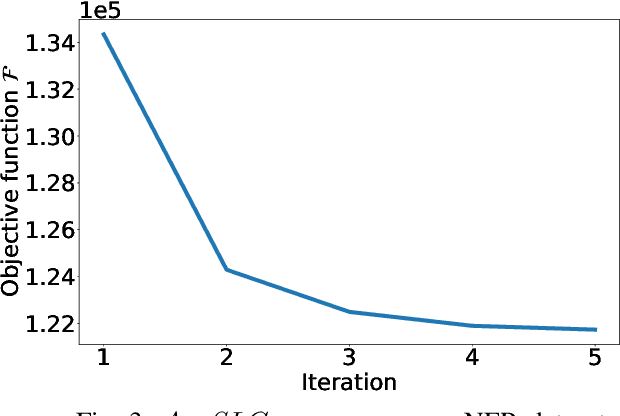
Annotations quality and quantity positively affect the performance of sequence labeling, a vital task in Natural Language Processing. Hiring domain experts to annotate a corpus set is very costly in terms of money and time. Crowdsourcing platforms, such as Amazon Mechanical Turk (AMT), have been deployed to assist in this purpose. However, these platforms are prone to human errors due to the lack of expertise; hence, one worker's annotations cannot be directly used to train the model. Existing literature in annotation aggregation more focuses on binary or multi-choice problems. In recent years, handling the sequential label aggregation tasks on imbalanced datasets with complex dependencies between tokens has been challenging. To conquer the challenge, we propose an optimization-based method that infers the best set of aggregated annotations using labels provided by workers. The proposed Aggregation method for Sequential Labels from Crowds ($AggSLC$) jointly considers the characteristics of sequential labeling tasks, workers' reliabilities, and advanced machine learning techniques. We evaluate $AggSLC$ on different crowdsourced data for Named Entity Recognition (NER), Information Extraction tasks in biomedical (PICO), and the simulated dataset. Our results show that the proposed method outperforms the state-of-the-art aggregation methods. To achieve insights into the framework, we study $AggSLC$ components' effectiveness through ablation studies by evaluating our model in the absence of the prediction module and inconsistency loss function. Theoretical analysis of our algorithm's convergence points that the proposed $AggSLC$ halts after a finite number of iterations.
Enriching Source Style Transfer in Recognition-Synthesis based Non-Parallel Voice Conversion
Jun 23, 2021
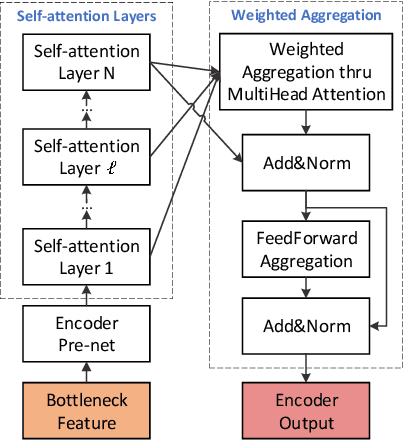
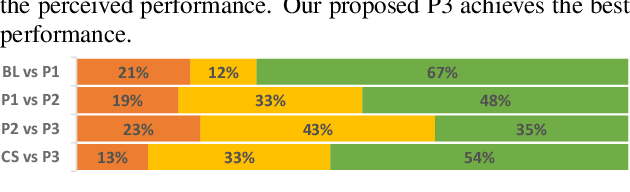
Current voice conversion (VC) methods can successfully convert timbre of the audio. As modeling source audio's prosody effectively is a challenging task, there are still limitations of transferring source style to the converted speech. This study proposes a source style transfer method based on recognition-synthesis framework. Previously in speech generation task, prosody can be modeled explicitly with prosodic features or implicitly with a latent prosody extractor. In this paper, taking advantages of both, we model the prosody in a hybrid manner, which effectively combines explicit and implicit methods in a proposed prosody module. Specifically, prosodic features are used to explicit model prosody, while VAE and reference encoder are used to implicitly model prosody, which take Mel spectrum and bottleneck feature as input respectively. Furthermore, adversarial training is introduced to remove speaker-related information from the VAE outputs, avoiding leaking source speaker information while transferring style. Finally, we use a modified self-attention based encoder to extract sentential context from bottleneck features, which also implicitly aggregates the prosodic aspects of source speech from the layered representations. Experiments show that our approach is superior to the baseline and a competitive system in terms of style transfer; meanwhile, the speech quality and speaker similarity are well maintained.
MULTIMODAL ANALYSIS: Informed content estimation and audio source separation
May 03, 2021
This dissertation proposes the study of multimodal learning in the context of musical signals. Throughout, we focus on the interaction between audio signals and text information. Among the many text sources related to music that can be used (e.g. reviews, metadata, or social network feedback), we concentrate on lyrics. The singing voice directly connects the audio signal and the text information in a unique way, combining melody and lyrics where a linguistic dimension complements the abstraction of musical instruments. Our study focuses on the audio and lyrics interaction for targeting source separation and informed content estimation.
Inductive Framework for Multi-Aspect Streaming Tensor Completion with Side Information
Sep 01, 2018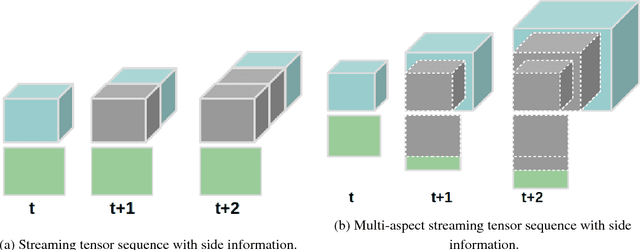

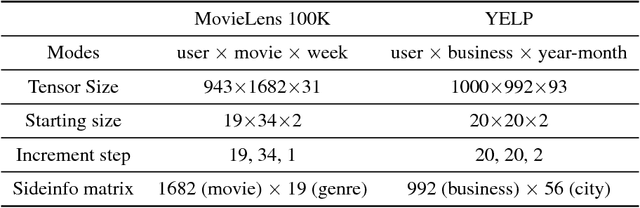
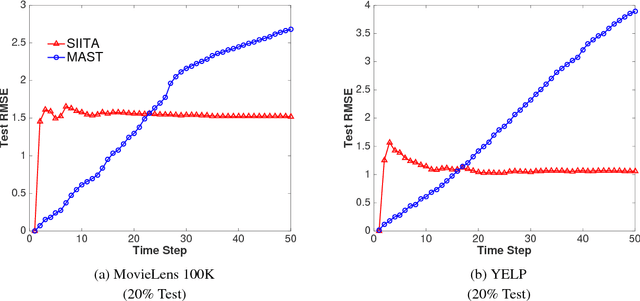
Low rank tensor completion is a well studied problem and has applications in various fields. However, in many real world applications the data is dynamic, i.e., new data arrives at different time intervals. As a result, the tensors used to represent the data grow in size. Besides the tensors, in many real world scenarios, side information is also available in the form of matrices which also grow in size with time. The problem of predicting missing values in the dynamically growing tensor is called dynamic tensor completion. Most of the previous work in dynamic tensor completion make an assumption that the tensor grows only in one mode. To the best of our Knowledge, there is no previous work which incorporates side information with dynamic tensor completion. We bridge this gap in this paper by proposing a dynamic tensor completion framework called Side Information infused Incremental Tensor Analysis (SIITA), which incorporates side information and works for general incremental tensors. We also show how non-negative constraints can be incorporated with SIITA, which is essential for mining interpretable latent clusters. We carry out extensive experiments on multiple real world datasets to demonstrate the effectiveness of SIITA in various different settings.
HintedBT: Augmenting Back-Translation with Quality and Transliteration Hints
Sep 09, 2021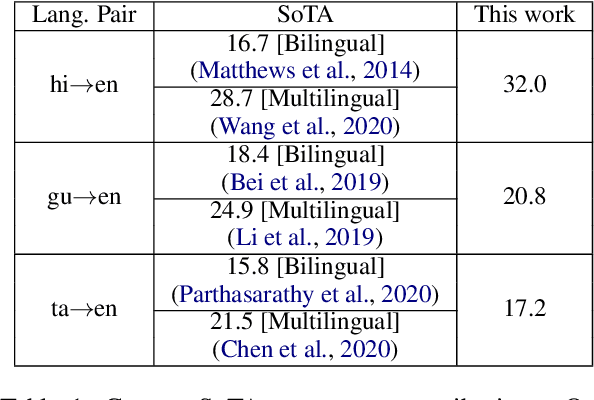


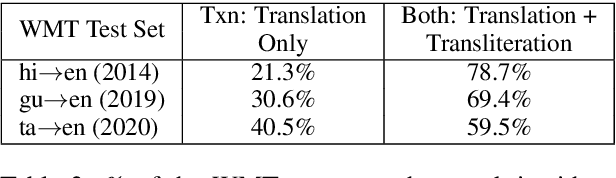
Back-translation (BT) of target monolingual corpora is a widely used data augmentation strategy for neural machine translation (NMT), especially for low-resource language pairs. To improve effectiveness of the available BT data, we introduce HintedBT -- a family of techniques which provides hints (through tags) to the encoder and decoder. First, we propose a novel method of using both high and low quality BT data by providing hints (as source tags on the encoder) to the model about the quality of each source-target pair. We don't filter out low quality data but instead show that these hints enable the model to learn effectively from noisy data. Second, we address the problem of predicting whether a source token needs to be translated or transliterated to the target language, which is common in cross-script translation tasks (i.e., where source and target do not share the written script). For such cases, we propose training the model with additional hints (as target tags on the decoder) that provide information about the operation required on the source (translation or both translation and transliteration). We conduct experiments and detailed analyses on standard WMT benchmarks for three cross-script low/medium-resource language pairs: {Hindi,Gujarati,Tamil}-to-English. Our methods compare favorably with five strong and well established baselines. We show that using these hints, both separately and together, significantly improves translation quality and leads to state-of-the-art performance in all three language pairs in corresponding bilingual settings.
A parallel-network continuous quantitative trading model with GARCH and PPO
May 21, 2021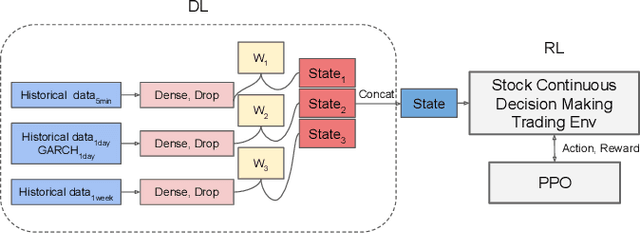
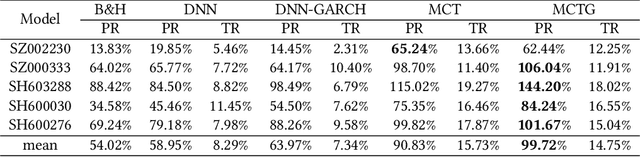
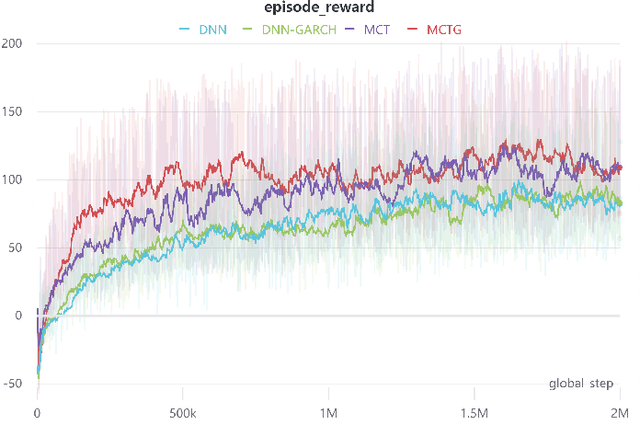
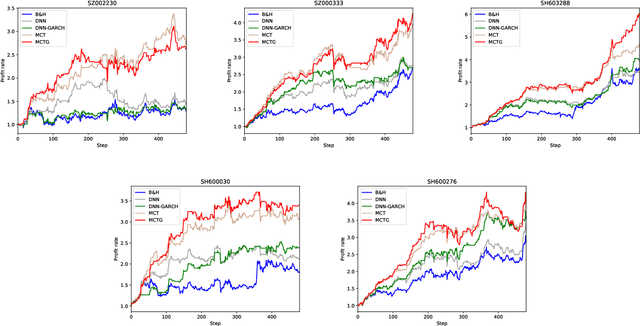
It is a difficult task for both professional investors and individual traders continuously making profit in stock market. With the development of computer science and deep reinforcement learning, Buy\&Hold (B\&H) has been oversteped by many artificial intelligence trading algorithms. However, the information and process are not enough, which limit the performance of reinforcement learning algorithms. Thus, we propose a parallel-network continuous quantitative trading model with GARCH and PPO to enrich the basical deep reinforcement learning model, where the deep learning parallel network layers deal with 3 different frequencies data (including GARCH information) and proximal policy optimization (PPO) algorithm interacts actions and rewards with stock trading environment. Experiments in 5 stocks from Chinese stock market show our method achieves more extra profit comparing with basical reinforcement learning methods and bench models.