 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reinforcement Learning-based Dialogue Guided Event Extraction to Exploit Argument Relations
Jun 23, 2021

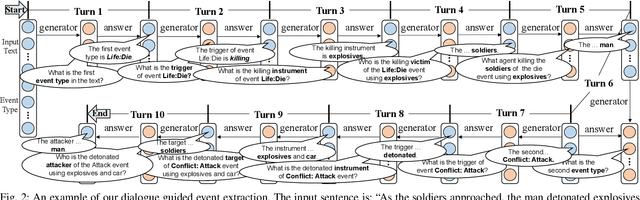
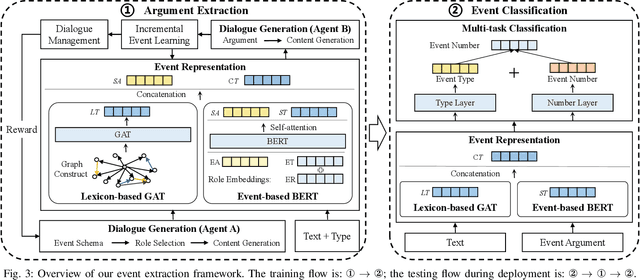
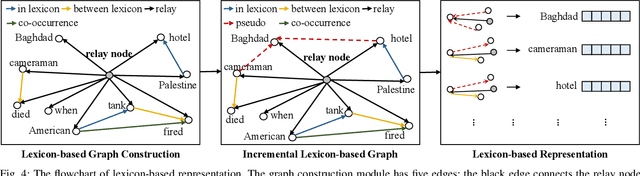
Event extraction is a fundamental task for natural language processing. Finding the roles of event arguments like event participants is essential for event extraction. However, doing so for real-life event descriptions is challenging because an argument's role often varies in different contexts. While the relationship and interactions between multiple arguments are useful for settling the argument roles, such information is largely ignored by existing approaches. This paper presents a better approach for event extraction by explicitly utilizing the relationships of event arguments. We achieve this through a carefully designed task-oriented dialogue system. To model the argument relation, we employ reinforcement learning and incremental learning to extract multiple arguments via a multi-turned, iterative process. Our approach leverages knowledge of the already extracted arguments of the same sentence to determine the role of arguments that would be difficult to decide individually. It then uses the newly obtained information to improve the decisions of previously extracted arguments. This two-way feedback process allows us to exploit the argument relations to effectively settle argument roles, leading to better sentence understanding and event extraction. Experimental results show that our approach consistently outperforms seven state-of-the-art event extraction methods for the classification of events and argument role and argument identification.
Automatic Online Multi-Source Domain Adaptation
Sep 05, 2021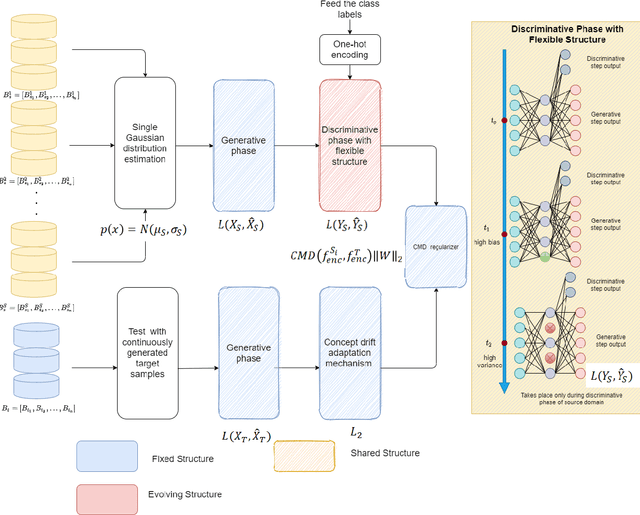
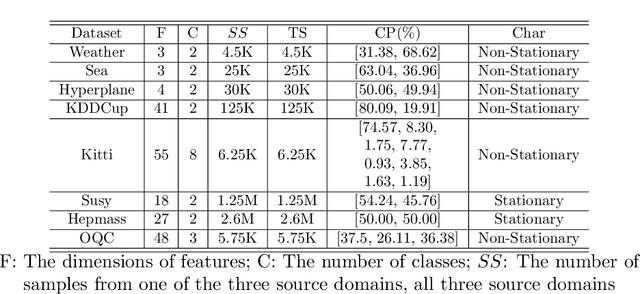
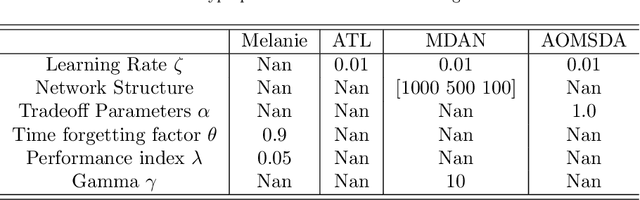
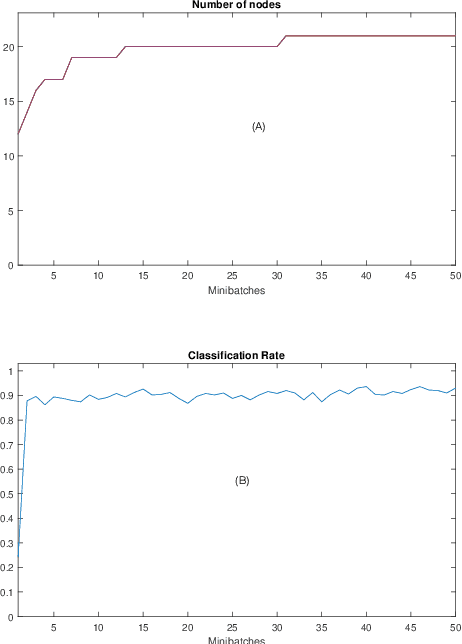
Knowledge transfer across several streaming processes remain challenging problem not only because of different distributions of each stream but also because of rapidly changing and never-ending environments of data streams. Albeit growing research achievements in this area, most of existing works are developed for a single source domain which limits its resilience to exploit multi-source domains being beneficial to recover from concept drifts quickly and to avoid the negative transfer problem. An online domain adaptation technique under multisource streaming processes, namely automatic online multi-source domain adaptation (AOMSDA), is proposed in this paper. The online domain adaptation strategy of AOMSDA is formulated under a coupled generative and discriminative approach of denoising autoencoder (DAE) where the central moment discrepancy (CMD)-based regularizer is integrated to handle the existence of multi-source domains thereby taking advantage of complementary information sources. The asynchronous concept drifts taking place at different time periods are addressed by a self-organizing structure and a node re-weighting strategy. Our numerical study demonstrates that AOMSDA is capable of outperforming its counterparts in 5 of 8 study cases while the ablation study depicts the advantage of each learning component. In addition, AOMSDA is general for any number of source streams. The source code of AOMSDA is shared publicly in https://github.com/Renchunzi-Xie/AOMSDA.git.
A Cognitive Regularizer for Language Modeling
Jun 02, 2021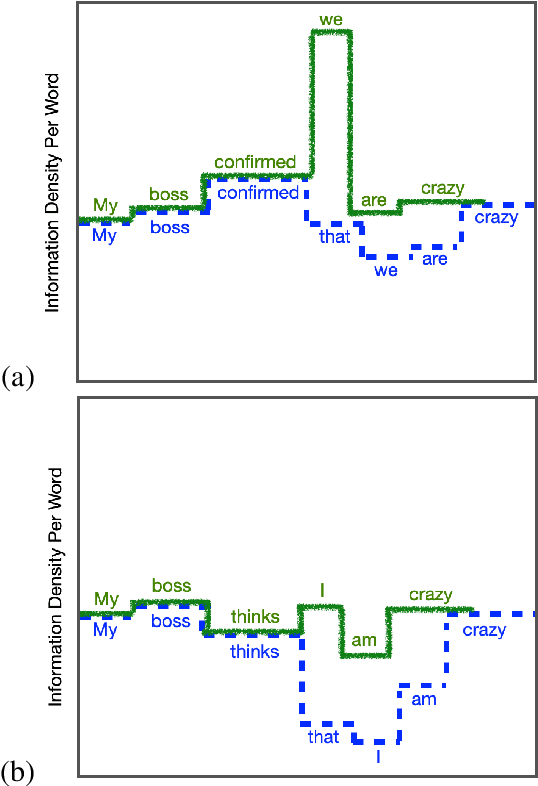
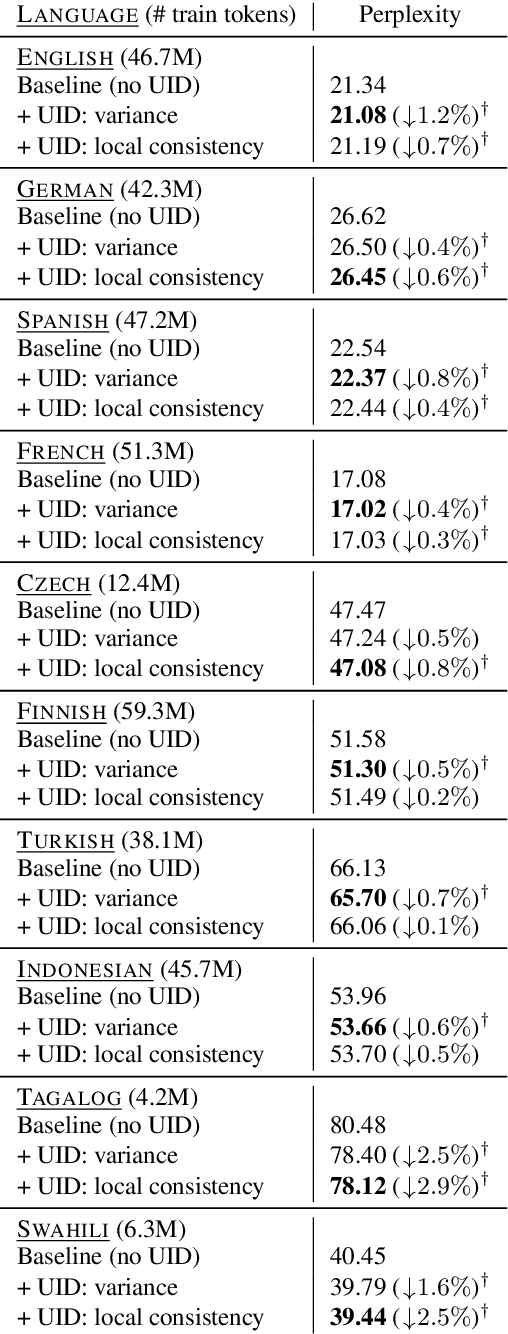
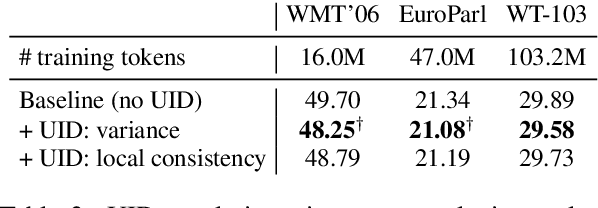
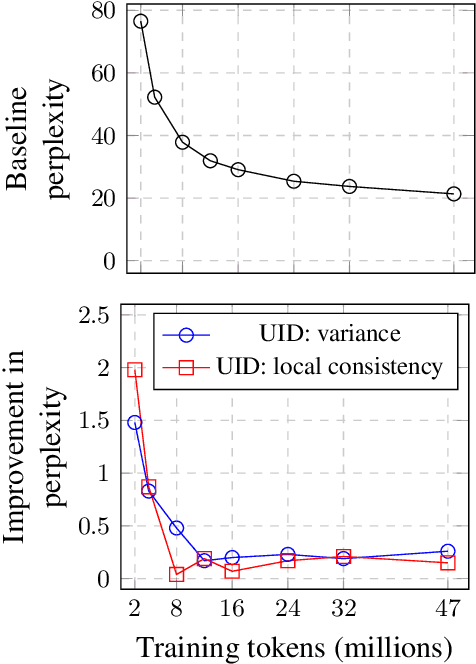
The uniform information density (UID) hypothesis, which posits that speakers behaving optimally tend to distribute information uniformly across a linguistic signal, has gained traction in psycholinguistics as an explanation for certain syntactic, morphological, and prosodic choices. In this work, we explore whether the UID hypothesis can be operationalized as an inductive bias for statistical language modeling. Specifically, we augment the canonical MLE objective for training language models with a regularizer that encodes UID. In experiments on ten languages spanning five language families, we find that using UID regularization consistently improves perplexity in language models, having a larger effect when training data is limited. Moreover, via an analysis of generated sequences, we find that UID-regularized language models have other desirable properties, e.g., they generate text that is more lexically diverse. Our results not only suggest that UID is a reasonable inductive bias for language modeling, but also provide an alternative validation of the UID hypothesis using modern-day NLP tools.
Survival Prediction of Heart Failure Patients using Stacked Ensemble Machine Learning Algorithm
Aug 30, 2021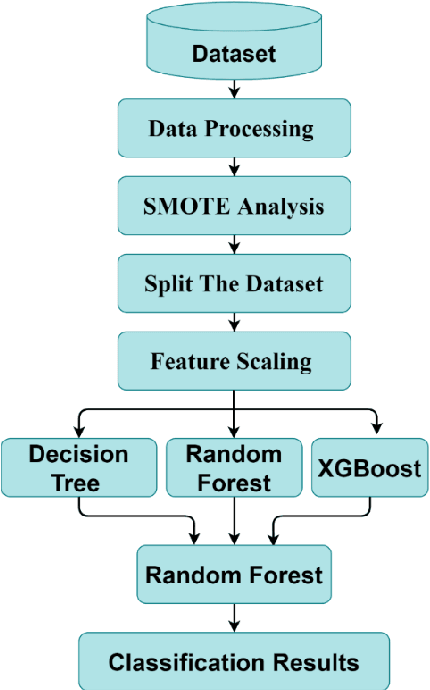
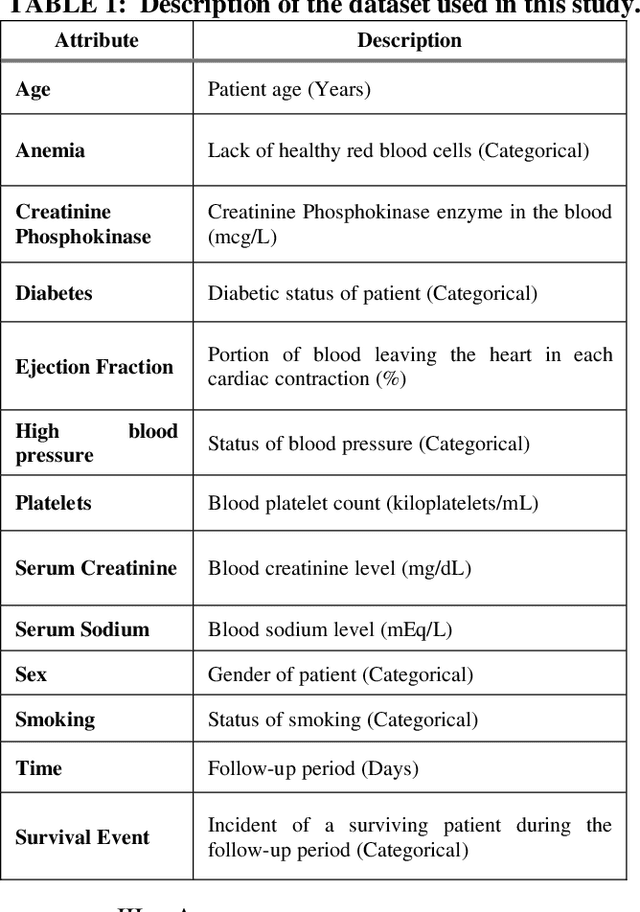
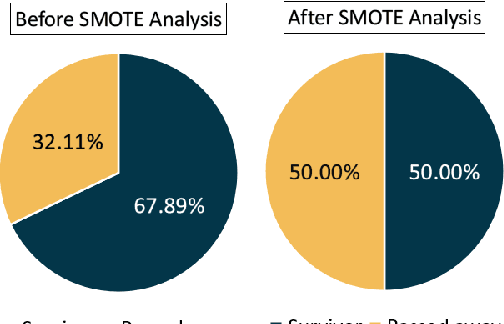
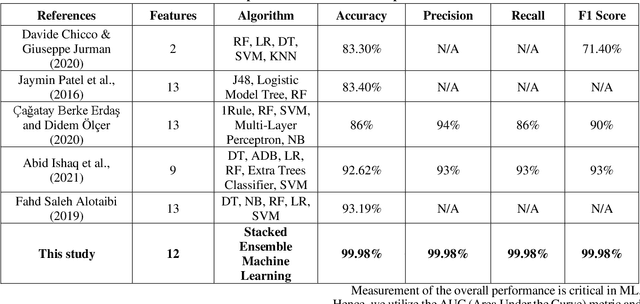
Cardiovascular disease, especially heart failure is one of the major health hazard issues of our time and is a leading cause of death worldwide. Advancement in data mining techniques using machine learning (ML) models is paving promising prediction approaches. Data mining is the process of converting massive volumes of raw data created by the healthcare institutions into meaningful information that can aid in making predictions and crucial decisions. Collecting various follow-up data from patients who have had heart failures, analyzing those data, and utilizing several ML models to predict the survival possibility of cardiovascular patients is the key aim of this study. Due to the imbalance of the classes in the dataset, Synthetic Minority Oversampling Technique (SMOTE) has been implemented. Two unsupervised models (K-Means and Fuzzy C-Means clustering) and three supervised classifiers (Random Forest, XGBoost and Decision Tree) have been used in our study. After thorough investigation, our results demonstrate a superior performance of the supervised ML algorithms over unsupervised models. Moreover, we designed and propose a supervised stacked ensemble learning model that can achieve an accuracy, precision, recall and F1 score of 99.98%. Our study shows that only certain attributes collected from the patients are imperative to successfully predict the surviving possibility post heart failure, using supervised ML algorithms.
BERT-Defense: A Probabilistic Model Based on BERT to Combat Cognitively Inspired Orthographic Adversarial Attacks
Jun 02, 2021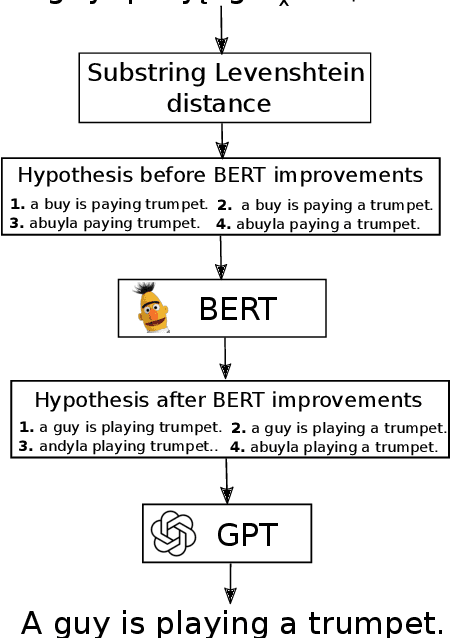
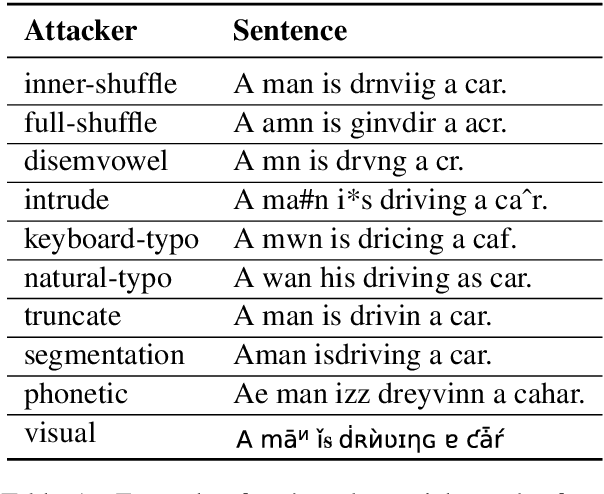
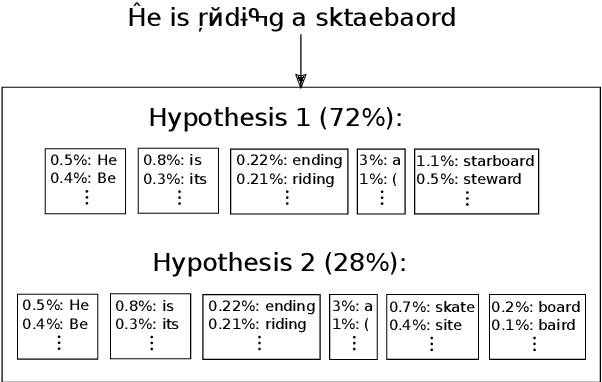

Adversarial attacks expose important blind spots of deep learning systems. While word- and sentence-level attack scenarios mostly deal with finding semantic paraphrases of the input that fool NLP models, character-level attacks typically insert typos into the input stream. It is commonly thought that these are easier to defend via spelling correction modules. In this work, we show that both a standard spellchecker and the approach of Pruthi et al. (2019), which trains to defend against insertions, deletions and swaps, perform poorly on the character-level benchmark recently proposed in Eger and Benz (2020) which includes more challenging attacks such as visual and phonetic perturbations and missing word segmentations. In contrast, we show that an untrained iterative approach which combines context-independent character-level information with context-dependent information from BERT's masked language modeling can perform on par with human crowd-workers from Amazon Mechanical Turk (AMT) supervised via 3-shot learning.
3rd Place Solution for Short-video Face Parsing Challenge
Jun 14, 2021
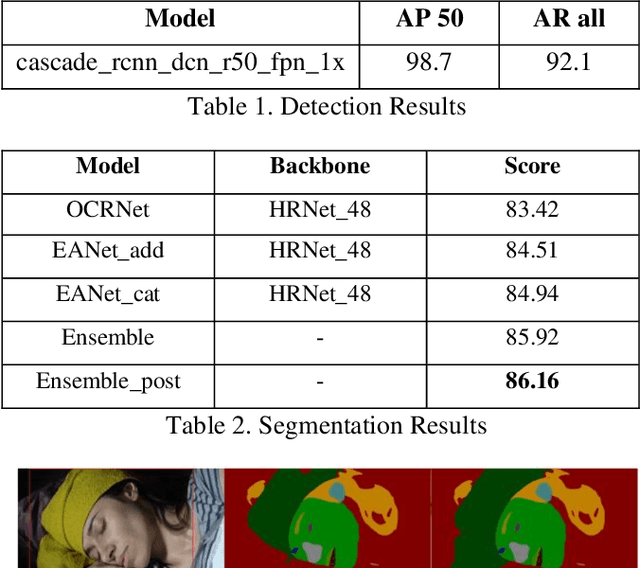
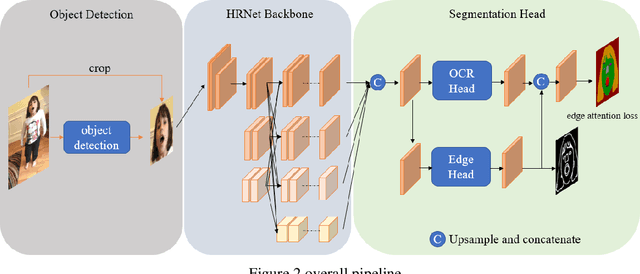
Short videos have many applications on fashion trends, hot spots, street interviews, public education, and creative advertising. We propose an Edge-Aware Network(EANet) that uses edge information to refine the segmentation edge. And experiments show our proposed EANet boots up the facial parsing results. We also use post-process like grab cut to refine and merge the parsing results.
Monte Carlo Neural Fictitious Self-Play: Approach to Approximate Nash equilibrium of Imperfect-Information Games
Apr 06, 2019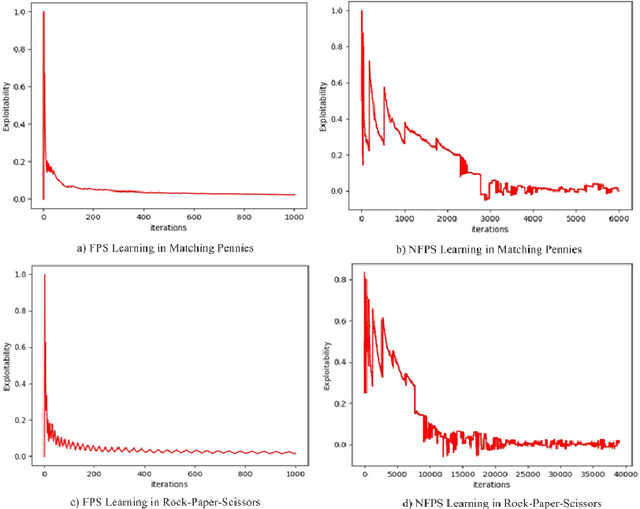
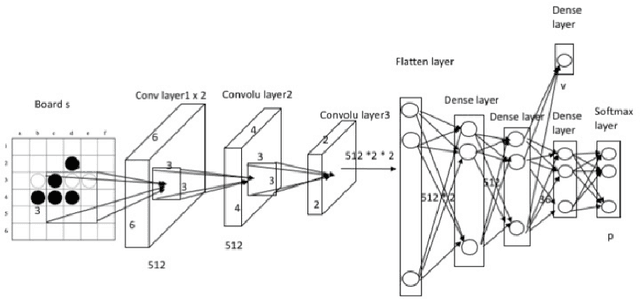
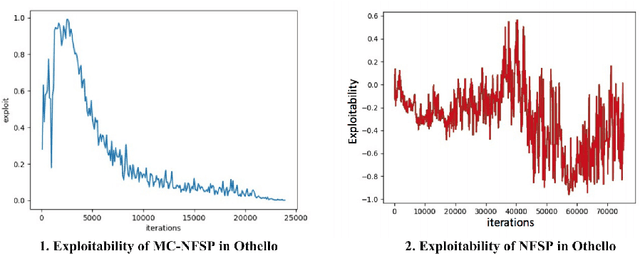
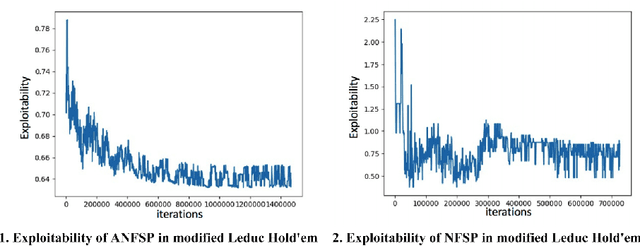
Researchers on artificial intelligence have achieved human-level intelligence in large-scale perfect-information games, but it is still a challenge to achieve (nearly) optimal results (in other words, an approximate Nash Equilibrium) in large-scale imperfect-information games (i.e. war games, football coach or business strategies). Neural Fictitious Self Play (NFSP) is an effective algorithm for learning approximate Nash equilibrium of imperfect-information games from self-play without prior domain knowledge. However, it relies on Deep Q-Network, which is off-line and is hard to converge in online games with changing opponent strategy, so it can't approach approximate Nash equilibrium in games with large search scale and deep search depth. In this paper, we propose Monte Carlo Neural Fictitious Self Play (MC-NFSP), an algorithm combines Monte Carlo tree search with NFSP, which greatly improves the performance on large-scale zero-sum imperfect-information games. Experimentally, we demonstrate that the proposed Monte Carlo Neural Fictitious Self Play can converge to approximate Nash equilibrium in games with large-scale search depth while the Neural Fictitious Self Play can't. Furthermore, we develop Asynchronous Neural Fictitious Self Play (ANFSP). It use asynchronous and parallel architecture to collect game experience. In experiments, we show that parallel actor-learners have a further accelerated and stabilizing effect on training.
Multi-Modulation Network for Audio-Visual Event Localization
Aug 30, 2021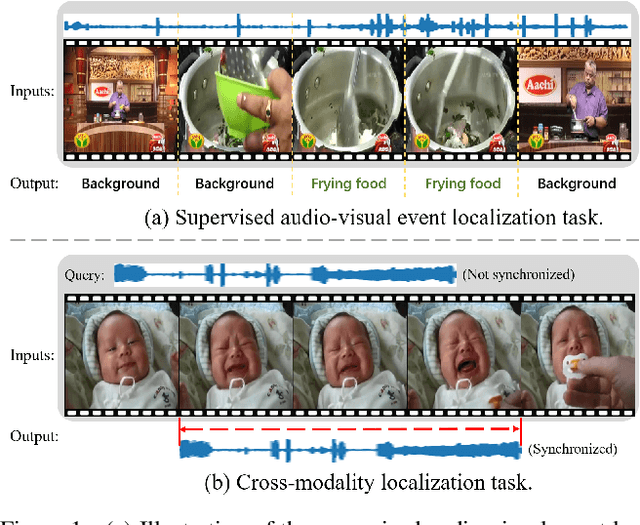

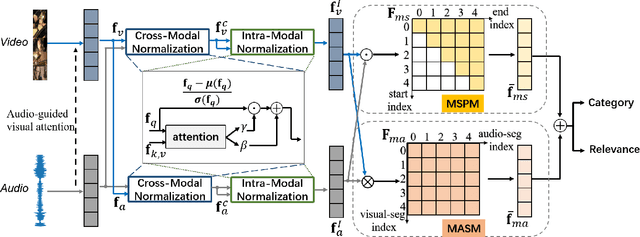
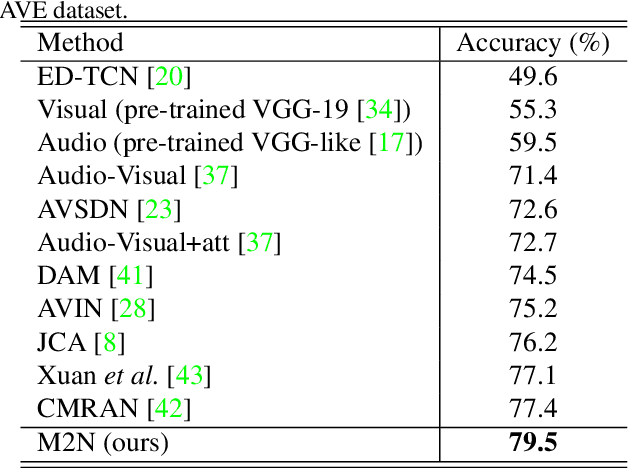
We study the problem of localizing audio-visual events that are both audible and visible in a video. Existing works focus on encoding and aligning audio and visual features at the segment level while neglecting informative correlation between segments of the two modalities and between multi-scale event proposals. We propose a novel MultiModulation Network (M2N) to learn the above correlation and leverage it as semantic guidance to modulate the related auditory, visual, and fused features. In particular, during feature encoding, we propose cross-modal normalization and intra-modal normalization. The former modulates the features of two modalities by establishing and exploiting the cross-modal relationship. The latter modulates the features of a single modality with the event-relevant semantic guidance of the same modality. In the fusion stage,we propose a multi-scale proposal modulating module and a multi-alignment segment modulating module to introduce multi-scale event proposals and enable dense matching between cross-modal segments. With the auditory, visual, and fused features modulated by the correlation information regarding audio-visual events, M2N performs accurate event localization. Extensive experiments conducted on the AVE dataset demonstrate that our proposed method outperforms the state of the art in both supervised event localization and cross-modality localization.
ELICA: An Automated Tool for Dynamic Extraction of Requirements Relevant Information
Jul 21, 2018
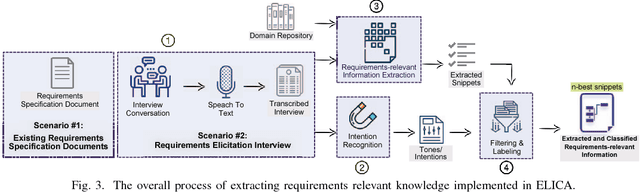
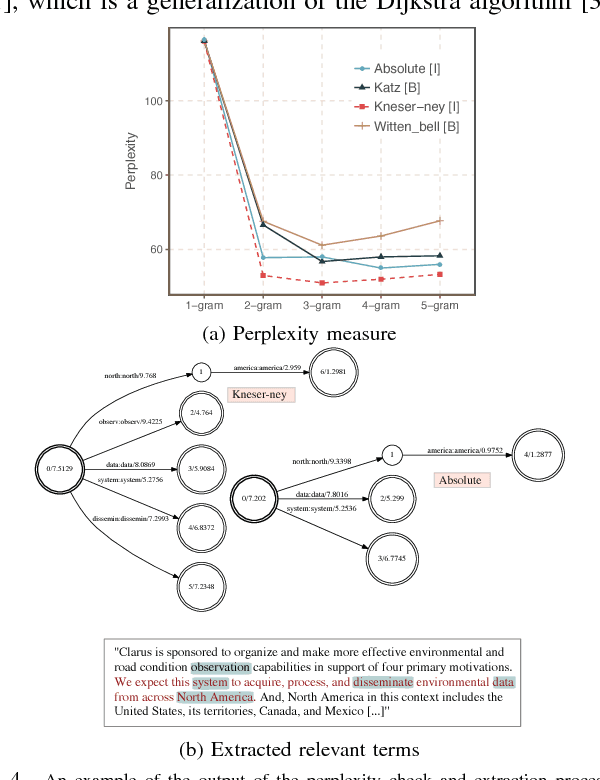
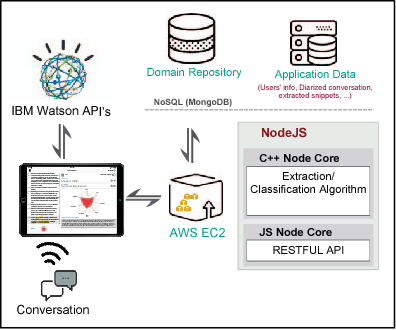
Requirements elicitation requires extensive knowledge and deep understanding of the problem domain where the final system will be situated. However, in many software development projects, analysts are required to elicit the requirements from an unfamiliar domain, which often causes communication barriers between analysts and stakeholders. In this paper, we propose a requirements ELICitation Aid tool (ELICA) to help analysts better understand the target application domain by dynamic extraction and labeling of requirements-relevant knowledge. To extract the relevant terms, we leverage the flexibility and power of Weighted Finite State Transducers (WFSTs) in dynamic modeling of natural language processing tasks. In addition to the information conveyed through text, ELICA captures and processes non-linguistic information about the intention of speakers such as their confidence level, analytical tone, and emotions. The extracted information is made available to the analysts as a set of labeled snippets with highlighted relevant terms which can also be exported as an artifact of the Requirements Engineering (RE) process. The application and usefulness of ELICA are demonstrated through a case study. This study shows how pre-existing relevant information about the application domain and the information captured during an elicitation meeting, such as the conversation and stakeholders' intentions, can be captured and used to support analysts achieving their tasks.
Learning Conditional Knowledge Distillation for Degraded-Reference Image Quality Assessment
Aug 18, 2021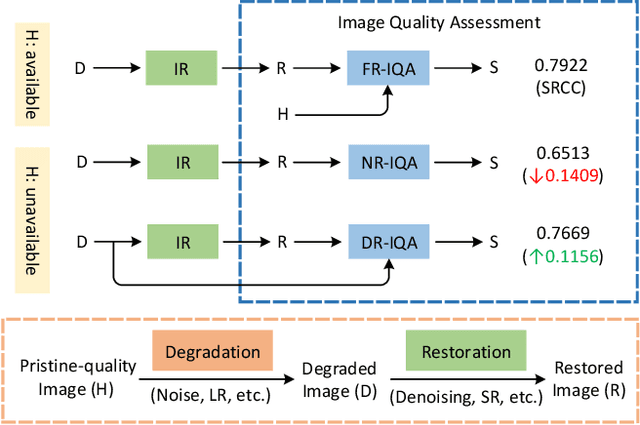
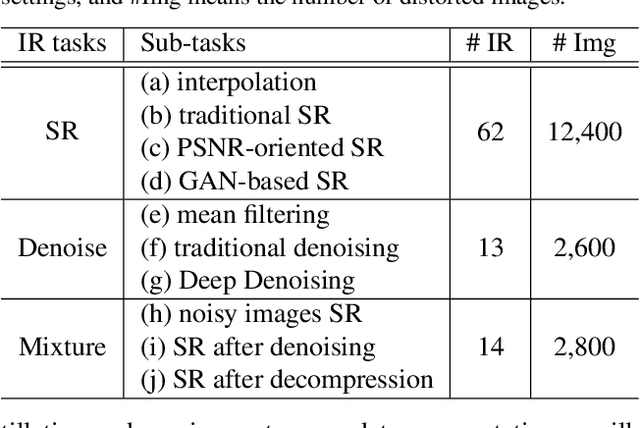
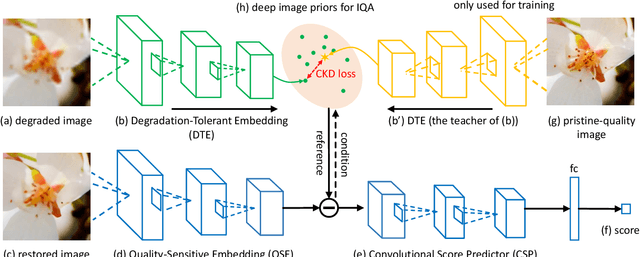
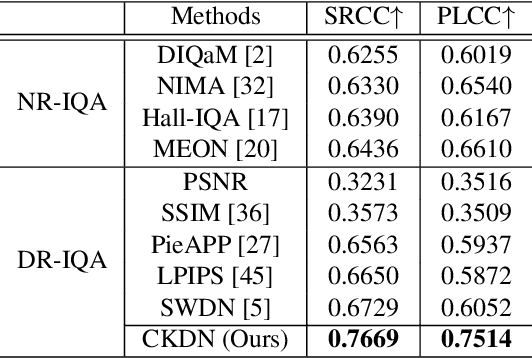
An important scenario for image quality assessment (IQA) is to evaluate image restoration (IR) algorithms. The state-of-the-art approaches adopt a full-reference paradigm that compares restored images with their corresponding pristine-quality images. However, pristine-quality images are usually unavailable in blind image restoration tasks and real-world scenarios. In this paper, we propose a practical solution named degraded-reference IQA (DR-IQA), which exploits the inputs of IR models, degraded images, as references. Specifically, we extract reference information from degraded images by distilling knowledge from pristine-quality images. The distillation is achieved through learning a reference space, where various degraded images are encouraged to share the same feature statistics with pristine-quality images. And the reference space is optimized to capture deep image priors that are useful for quality assessment. Note that pristine-quality images are only used during training. Our work provides a powerful and differentiable metric for blind IRs, especially for GAN-based methods. Extensive experiments show that our results can even be close to the performance of full-reference settings.