 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fast Model-Selection through Adapting Design of Experiments Maximizing Information Gain
Oct 23, 2018
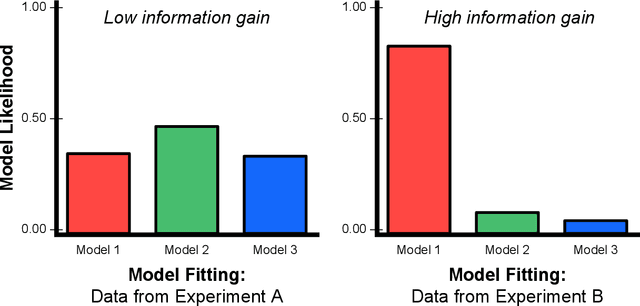

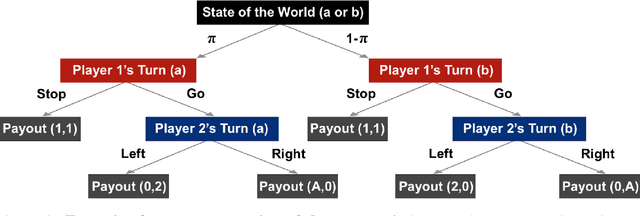
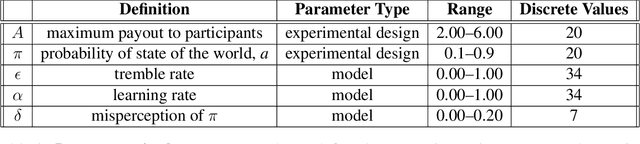
To perform model-selection efficiently, we must run informative experiments. Here, we extend a seminal method for designing Bayesian optimal experiments that maximize the information gained from data collected. We introduce two computational improvements that make the procedure tractable: a search algorithm from artificial intelligence and a sampling procedure shrinking the space of possible experiments to evaluate. We collected data for five different experimental designs of a simple imperfect information game and show that experiments optimized for information gain make model-selection possible (and cheaper). We compare the ability of the optimal experimental design to discriminate among competing models against the experimental designs chosen by a "wisdom of experts" prediction experiment. We find that a simple reinforcement learning model best explains human decision-making and that subject behavior is not adequately described by Bayesian Nash equilibrium. Our procedure is general and can be applied iteratively to lab, field and online experiments.
Reinforcement Learning, Bit by Bit
Mar 14, 2021
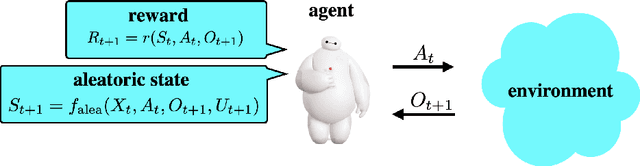
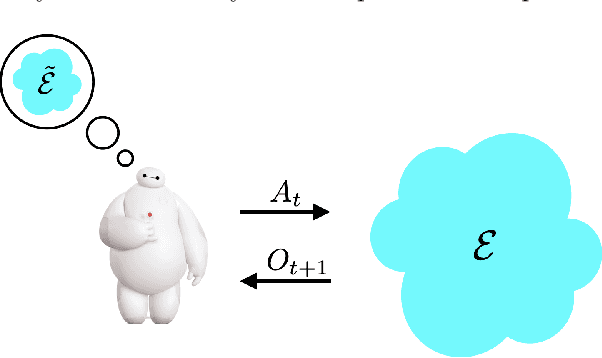

Reinforcement learning agents have demonstrated remarkable achievements in simulated environments. Data efficiency poses an impediment to carrying this success over to real environments. The design of data-efficient agents calls for a deeper understanding of information acquisition and representation. We develop concepts and establish a regret bound that together offer principled guidance. The bound sheds light on questions of what information to seek, how to seek that information, and it what information to retain. To illustrate concepts, we design simple agents that build on them and present computational results that demonstrate improvements in data efficiency.
Optimal Order Simple Regret for Gaussian Process Bandits
Aug 20, 2021
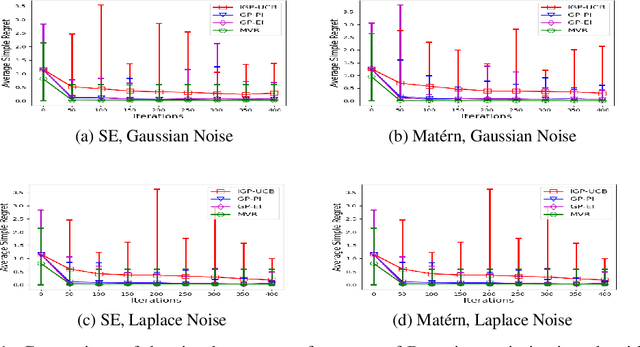
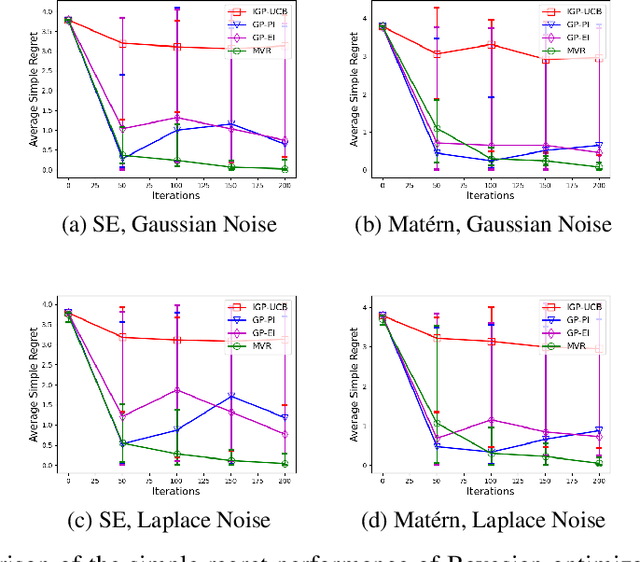
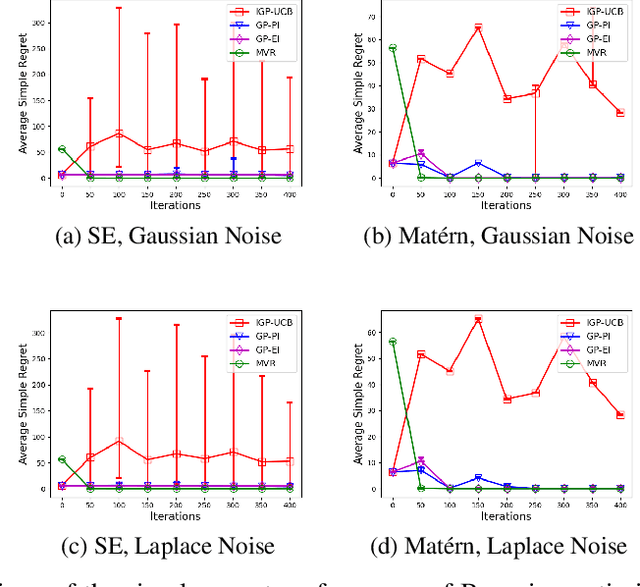
Consider the sequential optimization of a continuous, possibly non-convex, and expensive to evaluate objective function $f$. The problem can be cast as a Gaussian Process (GP) bandit where $f$ lives in a reproducing kernel Hilbert space (RKHS). The state of the art analysis of several learning algorithms shows a significant gap between the lower and upper bounds on the simple regret performance. When $N$ is the number of exploration trials and $\gamma_N$ is the maximal information gain, we prove an $\tilde{\mathcal{O}}(\sqrt{\gamma_N/N})$ bound on the simple regret performance of a pure exploration algorithm that is significantly tighter than the existing bounds. We show that this bound is order optimal up to logarithmic factors for the cases where a lower bound on regret is known. To establish these results, we prove novel and sharp confidence intervals for GP models applicable to RKHS elements which may be of broader interest.
A Novel Global Feature-Oriented Relational Triple Extraction Model based on Table Filling
Sep 14, 2021Table filling based relational triple extraction methods are attracting growing research interests due to their promising performance and their abilities on extracting triples from complex sentences. However, this kind of methods are far from their full potential because most of them only focus on using local features but ignore the global associations of relations and of token pairs, which increases the possibility of overlooking some important information during triple extraction. To overcome this deficiency, we propose a global feature-oriented triple extraction model that makes full use of the mentioned two kinds of global associations. Specifically, we first generate a table feature for each relation. Then two kinds of global associations are mined from the generated table features. Next, the mined global associations are integrated into the table feature of each relation. This "generate-mine-integrate" process is performed multiple times so that the table feature of each relation is refined step by step. Finally, each relation's table is filled based on its refined table feature, and all triples linked to this relation are extracted based on its filled table. We evaluate the proposed model on three benchmark datasets. Experimental results show our model is effective and it achieves state-of-the-art results on all of these datasets. The source code of our work is available at: https://github.com/neukg/GRTE.
DONet: Dual-Octave Network for Fast MR Image Reconstruction
May 12, 2021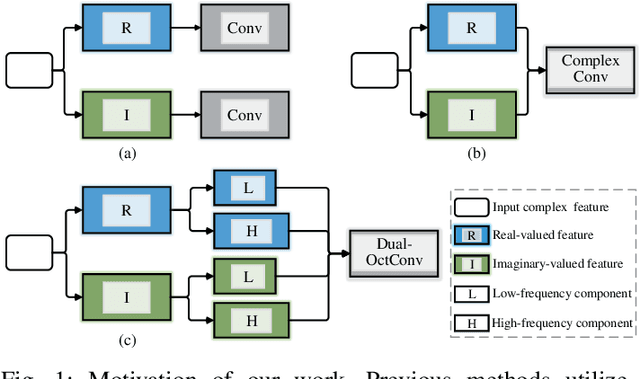
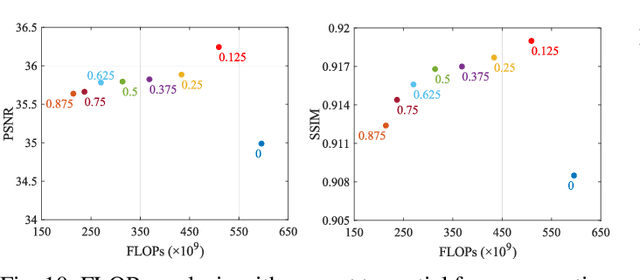

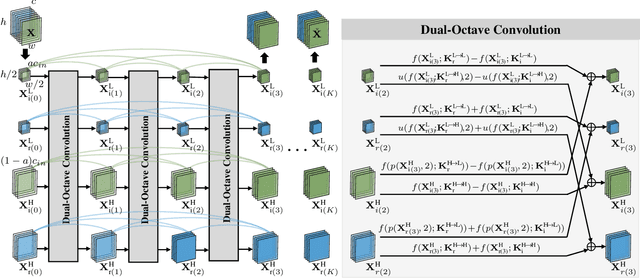
Magnetic resonance (MR) image acquisition is an inherently prolonged process, whose acceleration has long been the subject of research. This is commonly achieved by obtaining multiple undersampled images, simultaneously, through parallel imaging. In this paper, we propose the Dual-Octave Network (DONet), which is capable of learning multi-scale spatial-frequency features from both the real and imaginary components of MR data, for fast parallel MR image reconstruction. More specifically, our DONet consists of a series of Dual-Octave convolutions (Dual-OctConv), which are connected in a dense manner for better reuse of features. In each Dual-OctConv, the input feature maps and convolutional kernels are first split into two components (ie, real and imaginary), and then divided into four groups according to their spatial frequencies. Then, our Dual-OctConv conducts intra-group information updating and inter-group information exchange to aggregate the contextual information across different groups. Our framework provides three appealing benefits: (i) It encourages information interaction and fusion between the real and imaginary components at various spatial frequencies to achieve richer representational capacity. (ii) The dense connections between the real and imaginary groups in each Dual-OctConv make the propagation of features more efficient by feature reuse. (iii) DONet enlarges the receptive field by learning multiple spatial-frequency features of both the real and imaginary components. Extensive experiments on two popular datasets (ie, clinical knee and fastMRI), under different undersampling patterns and acceleration factors, demonstrate the superiority of our model in accelerated parallel MR image reconstruction.
Geometric Deep Learning on Molecular Representations
Jul 30, 2021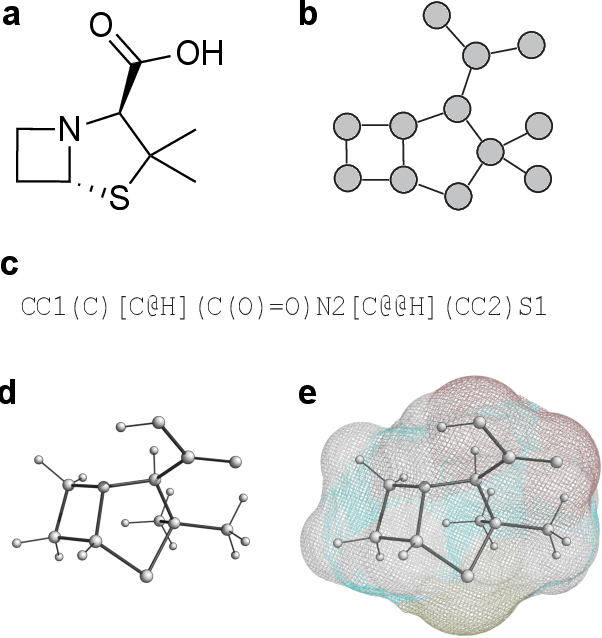
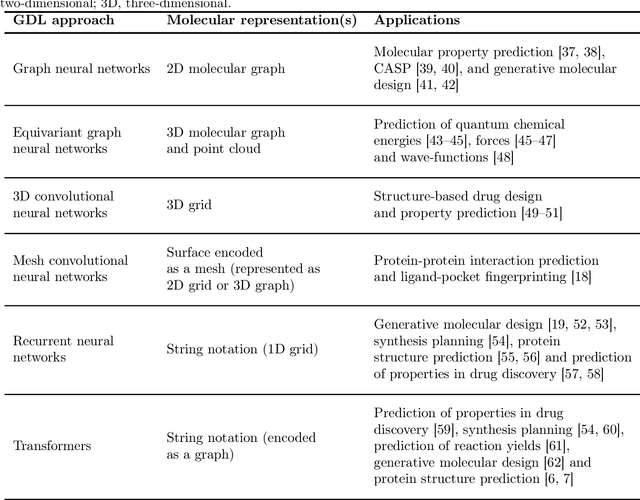
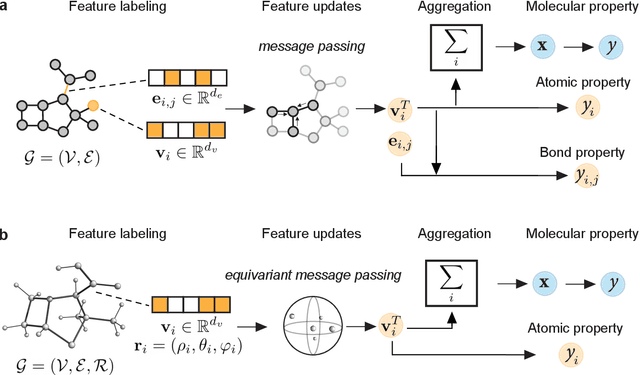
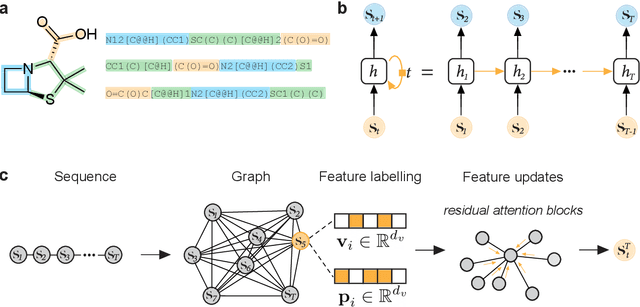
Geometric deep learning (GDL), which is based on neural network architectures that incorporate and process symmetry information, has emerged as a recent paradigm in artificial intelligence. GDL bears particular promise in molecular modeling applications, in which various molecular representations with different symmetry properties and levels of abstraction exist. This review provides a structured and harmonized overview of molecular GDL, highlighting its applications in drug discovery, chemical synthesis prediction, and quantum chemistry. Emphasis is placed on the relevance of the learned molecular features and their complementarity to well-established molecular descriptors. This review provides an overview of current challenges and opportunities, and presents a forecast of the future of GDL for molecular sciences.
A Synchronized Reprojection-based Model for 3D Human Pose Estimation
Jun 08, 2021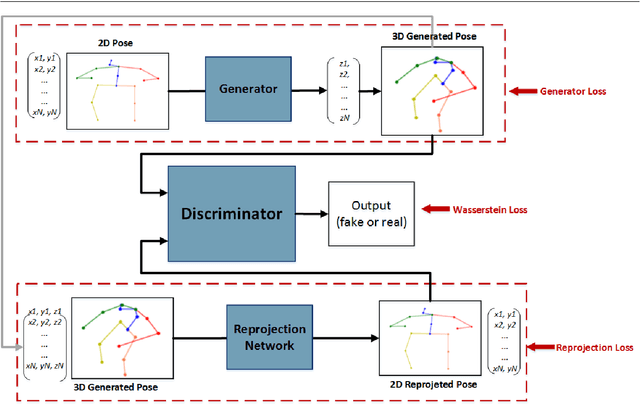
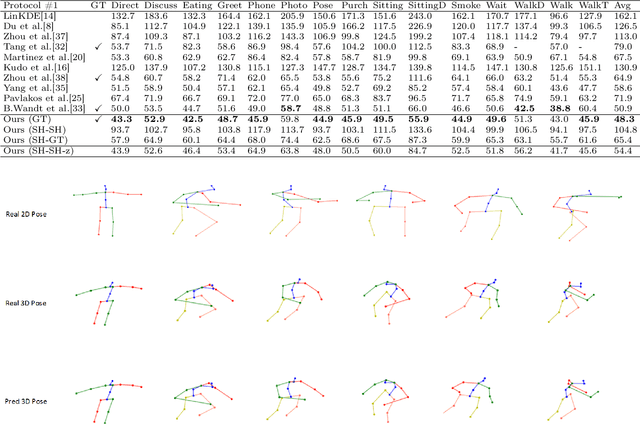
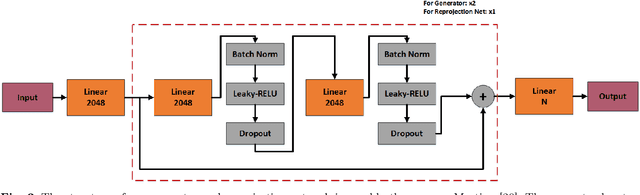
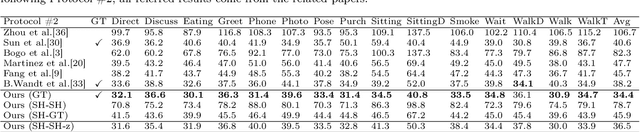
3D human pose estimation is still a challenging problem despite the large amount of work that has been done in this field. Generally, most methods directly use neural networks and ignore certain constraints (e.g., reprojection constraints and joint angle and bone length constraints). This paper proposes a weakly supervised GAN-based model for 3D human pose estimation that considers 3D information along with 2D information simultaneously, in which a reprojection network is employed to learn the mapping of the distribution from 3D poses to 2D poses. In particular, we train the reprojection network and the generative adversarial network synchronously. Furthermore, inspired by the typical kinematic chain space (KCS) matrix, we propose a weighted KCS matrix, which is added into the discriminator's input to impose joint angle and bone length constraints. The experimental results on Human3.6M show that our method outperforms state-of-the-art methods by approximately 5.1\%.
Continuous-Time Relationship Prediction in Dynamic Heterogeneous Information Networks
Oct 08, 2018
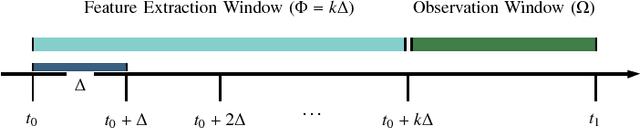
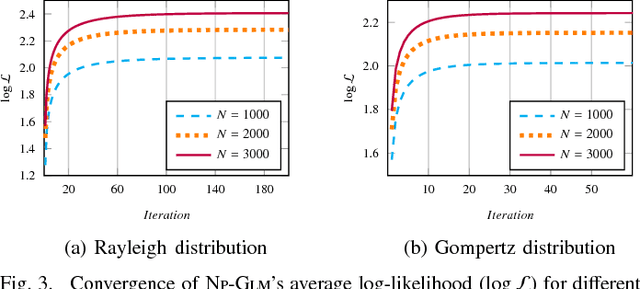
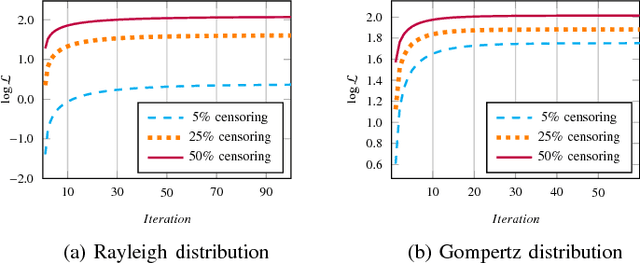
Online social networks, World Wide Web, media and technological networks, and other types of so-called information networks are ubiquitous nowadays. These information networks are inherently heterogeneous and dynamic. They are heterogeneous as they consist of multi-typed objects and relations, and they are dynamic as they are constantly evolving over time. One of the challenging issues in such heterogeneous and dynamic environments is to forecast those relationships in the network that will appear in the future. In this paper, we try to solve the problem of continuous-time relationship prediction in dynamic and heterogeneous information networks. This implies predicting the time it takes for a relationship to appear in the future, given its features that have been extracted by considering both heterogeneity and temporal dynamics of the underlying network. To this end, we first introduce a feature extraction framework that combines the power of meta-path-based modeling and recurrent neural networks to effectively extract features suitable for relationship prediction regarding heterogeneity and dynamicity of the networks. Next, we propose a supervised non-parametric approach, called Non-Parametric Generalized Linear Model (NP-GLM), which infers the hidden underlying probability distribution of the relationship building time given its features. We then present a learning algorithm to train NP-GLM and an inference method to answer time-related queries. Extensive experiments conducted on synthetic data and three real-world datasets, namely Delicious, MovieLens, and DBLP, demonstrate the effectiveness of NP-GLM in solving continuous-time relationship prediction problem vis-a-vis competitive baselines
Efficient Re-parameterization Residual Attention Network For Nonhomogeneous Image Dehazing
Sep 14, 2021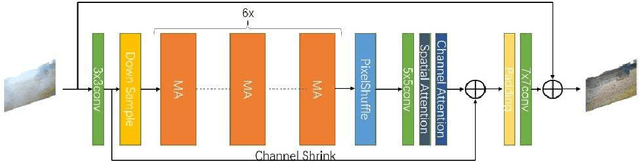
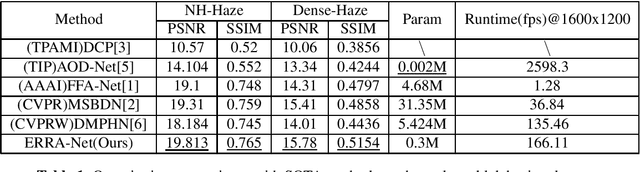

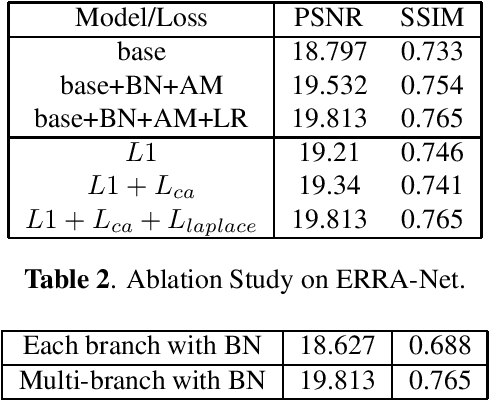
This paper proposes an end-to-end Efficient Re-parameterizationResidual Attention Network(ERRA-Net) to directly restore the nonhomogeneous hazy image. The contribution of this paper mainly has the following three aspects: 1) A novel Multi-branch Attention (MA) block. The spatial attention mechanism better reconstructs high-frequency features, and the channel attention mechanism treats the features of different channels differently. Multi-branch structure dramatically improves the representation ability of the model and can be changed into a single path structure after re-parameterization to speed up the process of inference. Local Residual Connection allows the low-frequency information in the nonhomogeneous area to pass through the block without processing so that the block can focus on detailed features. 2) A lightweight network structure. We use cascaded MA blocks to extract high-frequency features step by step, and the Multi-layer attention fusion tail combines the shallow and deep features of the model to get the residual of the clean image finally. 3)We propose two novel loss functions to help reconstruct the hazy image ColorAttenuation loss and Laplace Pyramid loss. ERRA-Net has an impressive speed, processing 1200x1600 HD quality images with an average runtime of 166.11 fps. Extensive evaluations demonstrate that ERSANet performs favorably against the SOTA approaches on the real-world hazy images.
Choosing the Right Algorithm With Hints From Complexity Theory
Sep 14, 2021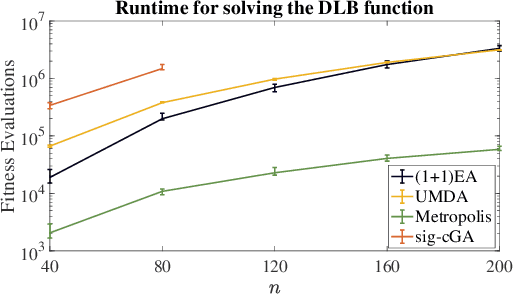
Choosing a suitable algorithm from the myriads of different search heuristics is difficult when faced with a novel optimization problem. In this work, we argue that the purely academic question of what could be the best possible algorithm in a certain broad class of black-box optimizers can give fruitful indications in which direction to search for good established optimization heuristics. We demonstrate this approach on the recently proposed DLB benchmark, for which the only known results are $O(n^3)$ runtimes for several classic evolutionary algorithms and an $O(n^2 \log n)$ runtime for an estimation-of-distribution algorithm. Our finding that the unary unbiased black-box complexity is only $O(n^2)$ suggests the Metropolis algorithm as an interesting candidate and we prove that it solves the DLB problem in quadratic time. Since we also prove that better runtimes cannot be obtained in the class of unary unbiased algorithms, we shift our attention to algorithms that use the information of more parents to generate new solutions. An artificial algorithm of this type having an $O(n \log n)$ runtime leads to the result that the significance-based compact genetic algorithm (sig-cGA) can solve the DLB problem also in time $O(n \log n)$. Our experiments show a remarkably good performance of the Metropolis algorithm, clearly the best of all algorithms regarded for reasonable problem sizes.