 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Easing Embedding Learning by Comprehensive Transcription of Heterogeneous Information Networks
Jul 10, 2018
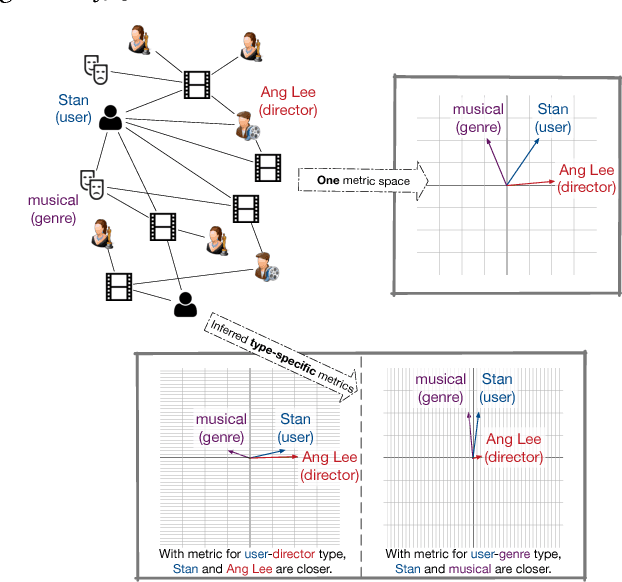

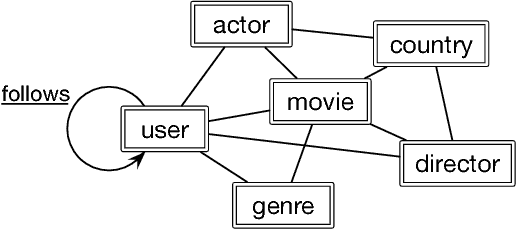

Heterogeneous information networks (HINs) are ubiquitous in real-world applications. In the meantime, network embedding has emerged as a convenient tool to mine and learn from networked data. As a result, it is of interest to develop HIN embedding methods. However, the heterogeneity in HINs introduces not only rich information but also potentially incompatible semantics, which poses special challenges to embedding learning in HINs. With the intention to preserve the rich yet potentially incompatible information in HIN embedding, we propose to study the problem of comprehensive transcription of heterogeneous information networks. The comprehensive transcription of HINs also provides an easy-to-use approach to unleash the power of HINs, since it requires no additional supervision, expertise, or feature engineering. To cope with the challenges in the comprehensive transcription of HINs, we propose the HEER algorithm, which embeds HINs via edge representations that are further coupled with properly-learned heterogeneous metrics. To corroborate the efficacy of HEER, we conducted experiments on two large-scale real-words datasets with an edge reconstruction task and multiple case studies. Experiment results demonstrate the effectiveness of the proposed HEER model and the utility of edge representations and heterogeneous metrics. The code and data are available at https://github.com/GentleZhu/HEER.
Curiosity-based Robot Navigation under Uncertainty in Crowded Environments
Jun 10, 2021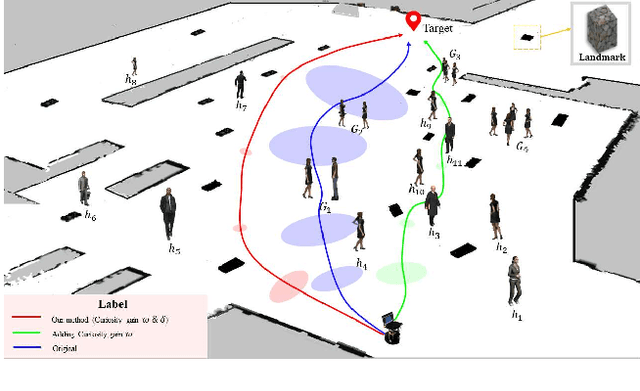
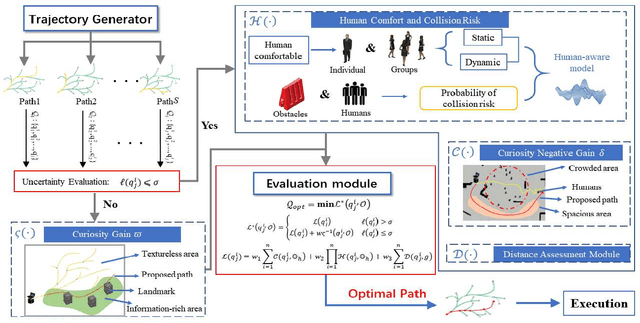
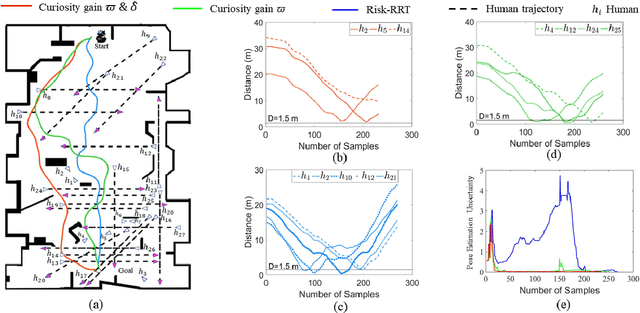

Mobile robots have become more and more popular in our daily life. In large-scale and crowded environments, how to navigate safely with localization precision is a critical problem. To solve this problem, we proposed a curiosity-based framework that can find an effective path with the consideration of human comfort, localization uncertainty, crowds, and the cost-to-go to the target. Three parts are involved in the proposed framework: the distance assessment module, the curiosity gain of the information-rich area, and the curiosity negative gain of crowded areas. The curiosity gain of the information-rich area was proposed to provoke the robot to approach localization referenced landmarks. To guarantee human comfort while coexisting with robots, we propose curiosity gain of the spacious area to bypass the crowd and maintain an appropriate distance between robots and humans. The evaluation is conducted in an unstructured environment. The results show that our method can find a feasible path, which can consider the localization uncertainty while simultaneously avoiding the crowded area. Curiosity-based Robot Navigation under Uncertainty in Crowded Environments
Lifelong Infinite Mixture Model Based on Knowledge-Driven Dirichlet Process
Aug 25, 2021
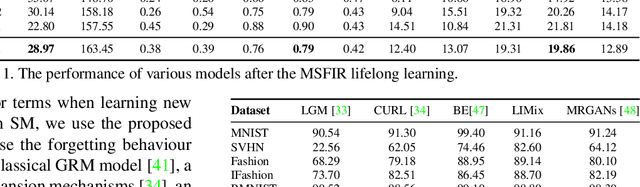
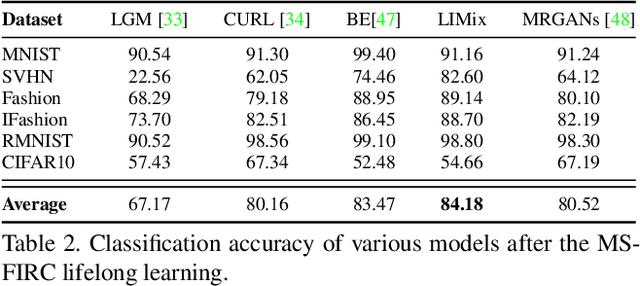

Recent research efforts in lifelong learning propose to grow a mixture of models to adapt to an increasing number of tasks. The proposed methodology shows promising results in overcoming catastrophic forgetting. However, the theory behind these successful models is still not well understood. In this paper, we perform the theoretical analysis for lifelong learning models by deriving the risk bounds based on the discrepancy distance between the probabilistic representation of data generated by the model and that corresponding to the target dataset. Inspired by the theoretical analysis, we introduce a new lifelong learning approach, namely the Lifelong Infinite Mixture (LIMix) model, which can automatically expand its network architectures or choose an appropriate component to adapt its parameters for learning a new task, while preserving its previously learnt information. We propose to incorporate the knowledge by means of Dirichlet processes by using a gating mechanism which computes the dependence between the knowledge learnt previously and stored in each component, and a new set of data. Besides, we train a compact Student model which can accumulate cross-domain representations over time and make quick inferences. The code is available at https://github.com/dtuzi123/Lifelong-infinite-mixture-model.
Linguistically Informed Masking for Representation Learning in the Patent Domain
Jun 10, 2021
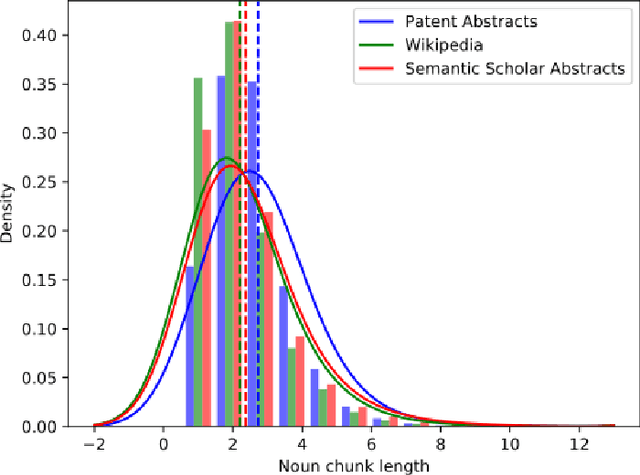
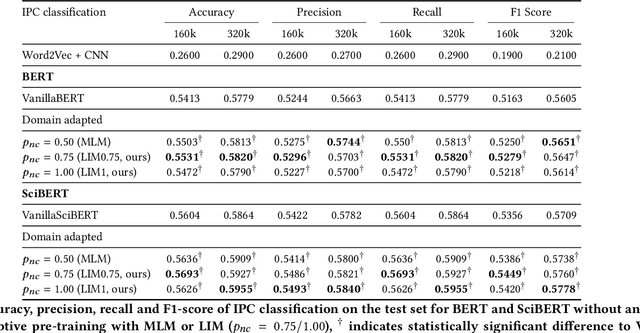
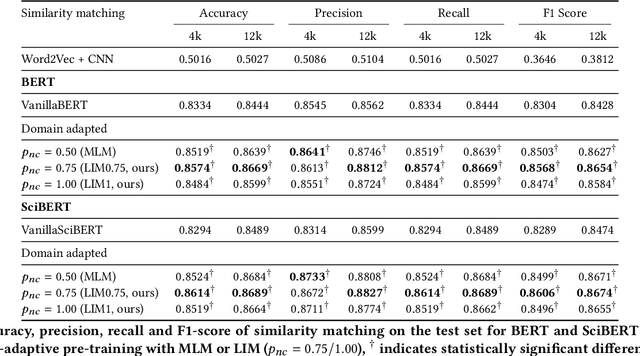
Domain-specific contextualized language models have demonstrated substantial effectiveness gains for domain-specific downstream tasks, like similarity matching, entity recognition or information retrieval. However successfully applying such models in highly specific language domains requires domain adaptation of the pre-trained models. In this paper we propose the empirically motivated Linguistically Informed Masking (LIM) method to focus domain-adaptative pre-training on the linguistic patterns of patents, which use a highly technical sublanguage. We quantify the relevant differences between patent, scientific and general-purpose language and demonstrate for two different language models (BERT and SciBERT) that domain adaptation with LIM leads to systematically improved representations by evaluating the performance of the domain-adapted representations of patent language on two independent downstream tasks, the IPC classification and similarity matching. We demonstrate the impact of balancing the learning from different information sources during domain adaptation for the patent domain. We make the source code as well as the domain-adaptive pre-trained patent language models publicly available at https://github.com/sophiaalthammer/patent-lim.
Unsupervised Corpus Aware Language Model Pre-training for Dense Passage Retrieval
Aug 12, 2021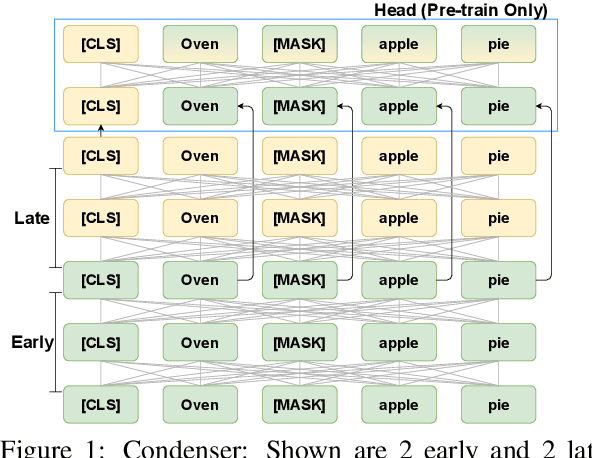
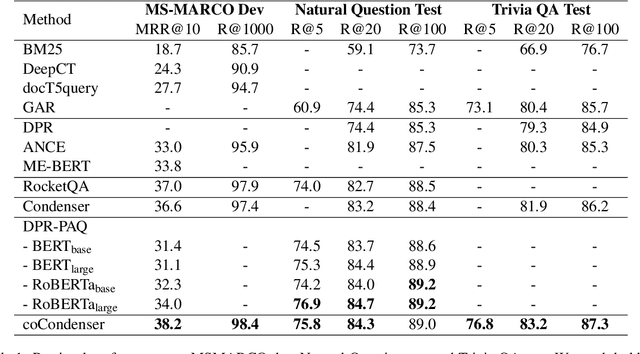
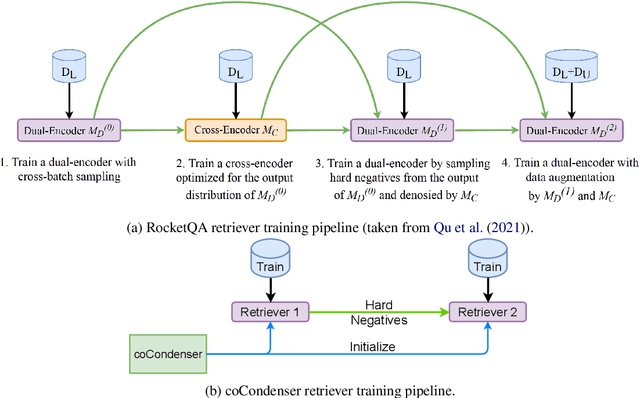
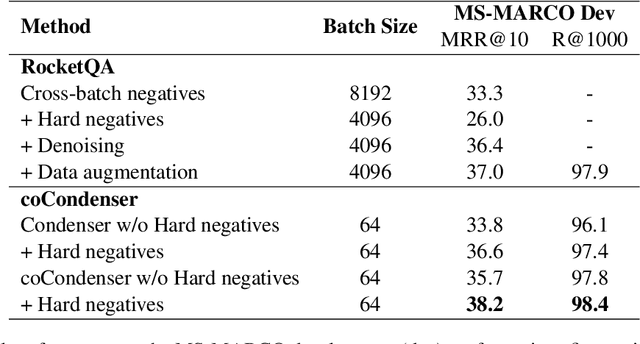
Recent research demonstrates the effectiveness of using fine-tuned language models~(LM) for dense retrieval. However, dense retrievers are hard to train, typically requiring heavily engineered fine-tuning pipelines to realize their full potential. In this paper, we identify and address two underlying problems of dense retrievers: i)~fragility to training data noise and ii)~requiring large batches to robustly learn the embedding space. We use the recently proposed Condenser pre-training architecture, which learns to condense information into the dense vector through LM pre-training. On top of it, we propose coCondenser, which adds an unsupervised corpus-level contrastive loss to warm up the passage embedding space. Retrieval experiments on MS-MARCO, Natural Question, and Trivia QA datasets show that coCondenser removes the need for heavy data engineering such as augmentation, synthesis, or filtering, as well as the need for large batch training. It shows comparable performance to RocketQA, a state-of-the-art, heavily engineered system, using simple small batch fine-tuning.
Intelligent computational model for the classification of Covid-19 with chest radiography compared to other respiratory diseases
Aug 12, 2021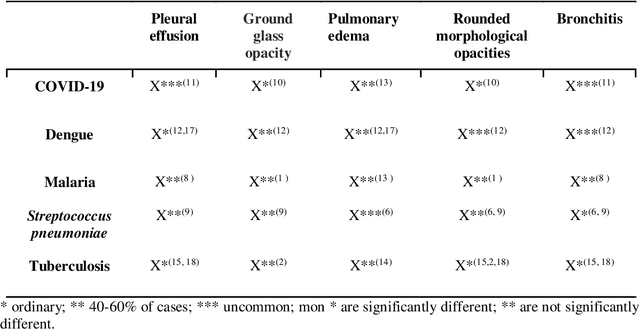
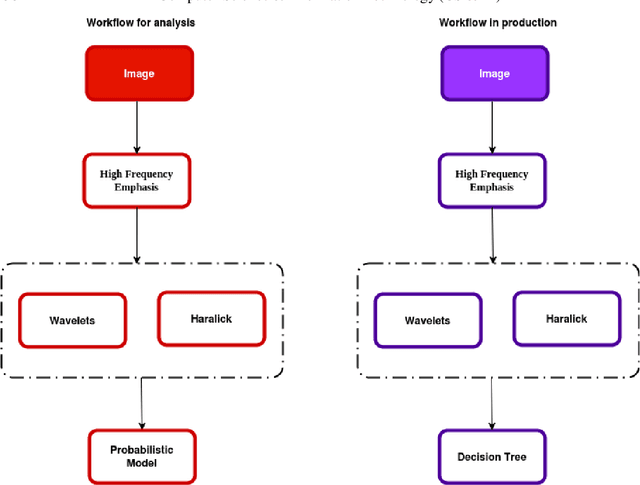

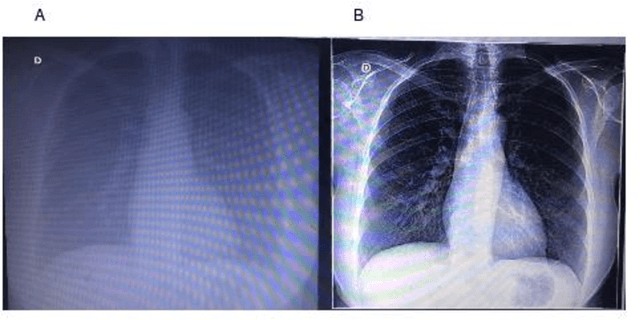
Lung X-ray images, if processed using statistical and computational methods, can distinguish pneumonia from COVID-19. The present work shows that it is possible to extract lung X-ray characteristics to improve the methods of examining and diagnosing patients with suspected COVID-19, distinguishing them from malaria, dengue, H1N1, tuberculosis, and Streptococcus pneumonia. More precisely, an intelligent computational model was developed to process lung X-ray images and classify whether the image is of a patient with COVID-19. The images were processed and extracted their characteristics. These characteristics were the input data for an unsupervised statistical learning method, PCA, and clustering, which identified specific attributes of X-ray images with Covid-19. The introduction of statistical models allowed a fast algorithm, which used the X-means clustering method associated with the Bayesian Information Criterion (CIB). The developed algorithm efficiently distinguished each pulmonary pathology from X-ray images. The method exhibited excellent sensitivity. The average recognition accuracy of COVID-19 was 0.93 and 0.051.
* 12 pages, 7 figures
R-PCC: A Baseline for Range Image-based Point Cloud Compression
Sep 16, 2021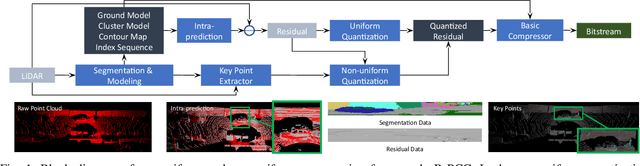

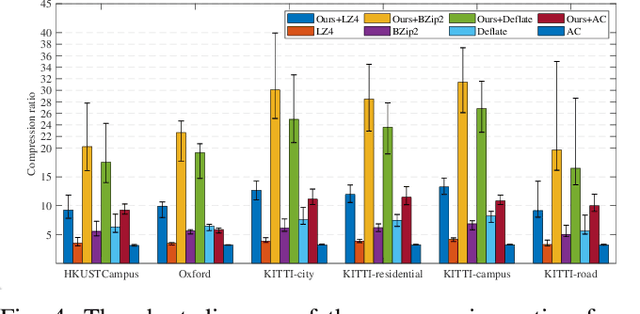
In autonomous vehicles or robots, point clouds from LiDAR can provide accurate depth information of objects compared with 2D images, but they also suffer a large volume of data, which is inconvenient for data storage or transmission. In this paper, we propose a Range image-based Point Cloud Compression method, R-PCC, which can reconstruct the point cloud with uniform or non-uniform accuracy loss. We segment the original large-scale point cloud into small and compact regions for spatial redundancy and salient region classification. Compared with other voxel-based or image-based compression methods, our method can keep and align all points from the original point cloud in the reconstructed point cloud. It can also control the maximum reconstruction error for each point through a quantization module. In the experiments, we prove that our easier FPS-based segmentation method can achieve better performance than instance-based segmentation methods such as DBSCAN. To verify the advantages of our proposed method, we evaluate the reconstruction quality and fidelity for 3D object detection and SLAM, as the downstream tasks. The experimental results show that our elegant framework can achieve 30$\times$ compression ratio without affecting downstream tasks, and our non-uniform compression framework shows a great improvement on the downstream tasks compared with the state-of-the-art large-scale point cloud compression methods. Our real-time method is efficient and effective enough to act as a baseline for range image-based point cloud compression. The code is available on https://github.com/StevenWang30/R-PCC.git.
ELICA: An Automated Tool for Dynamic Extraction of Requirements Relevant Information
Jul 21, 2018
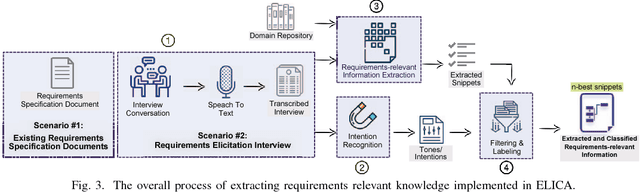
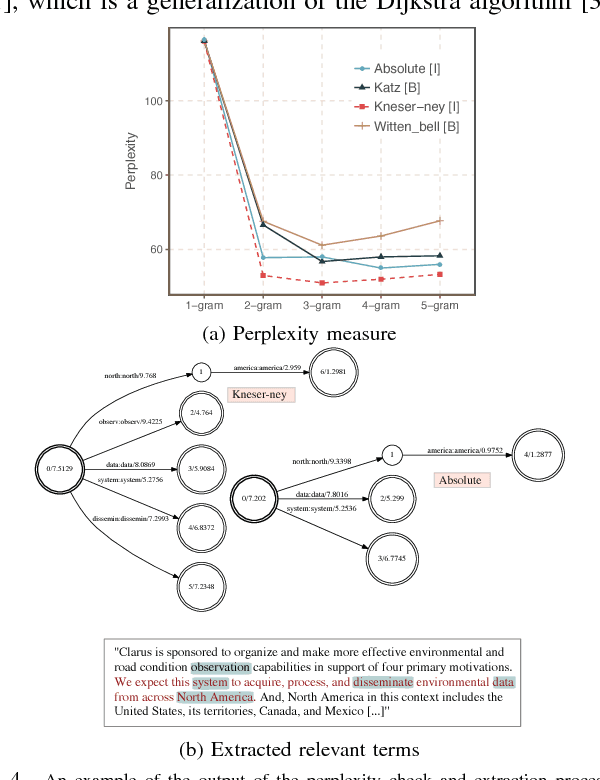
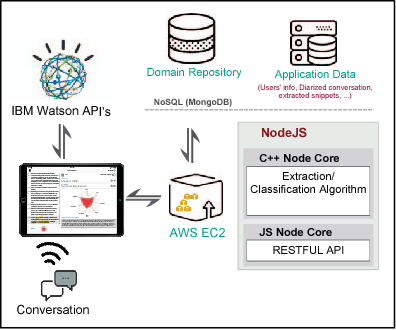
Requirements elicitation requires extensive knowledge and deep understanding of the problem domain where the final system will be situated. However, in many software development projects, analysts are required to elicit the requirements from an unfamiliar domain, which often causes communication barriers between analysts and stakeholders. In this paper, we propose a requirements ELICitation Aid tool (ELICA) to help analysts better understand the target application domain by dynamic extraction and labeling of requirements-relevant knowledge. To extract the relevant terms, we leverage the flexibility and power of Weighted Finite State Transducers (WFSTs) in dynamic modeling of natural language processing tasks. In addition to the information conveyed through text, ELICA captures and processes non-linguistic information about the intention of speakers such as their confidence level, analytical tone, and emotions. The extracted information is made available to the analysts as a set of labeled snippets with highlighted relevant terms which can also be exported as an artifact of the Requirements Engineering (RE) process. The application and usefulness of ELICA are demonstrated through a case study. This study shows how pre-existing relevant information about the application domain and the information captured during an elicitation meeting, such as the conversation and stakeholders' intentions, can be captured and used to support analysts achieving their tasks.
Runtime Monitoring for Markov Decision Processes
May 26, 2021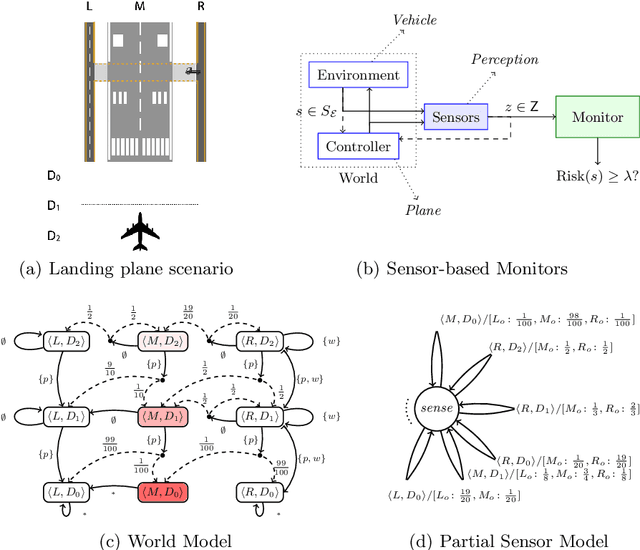
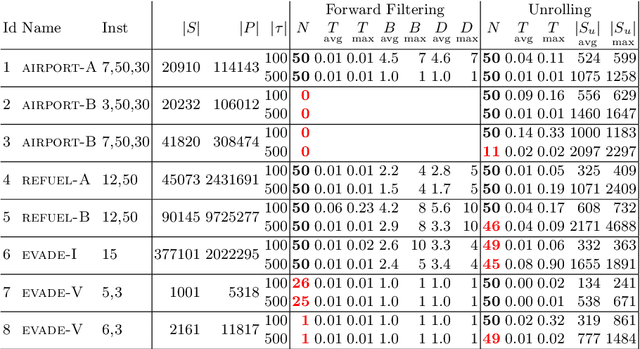
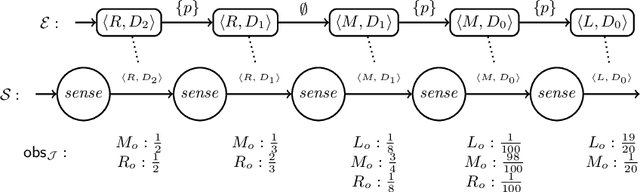
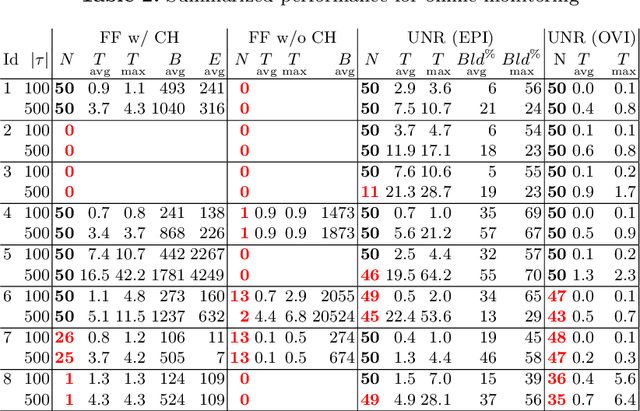
We investigate the problem of monitoring partially observable systems with nondeterministic and probabilistic dynamics. In such systems, every state may be associated with a risk, e.g., the probability of an imminent crash. During runtime, we obtain partial information about the system state in form of observations. The monitor uses this information to estimate the risk of the (unobservable) current system state. Our results are threefold. First, we show that extensions of state estimation approaches do not scale due the combination of nondeterminism and probabilities. While convex hull algorithms improve the practical runtime, they do not prevent an exponential memory blowup. Second, we present a tractable algorithm based on model checking conditional reachability probabilities. Third, we provide prototypical implementations and manifest the applicability of our algorithms to a range of benchmarks. The results highlight the possibilities and boundaries of our novel algorithms.
Joint Retrieval and Generation Training for Grounded Text Generation
Jun 03, 2021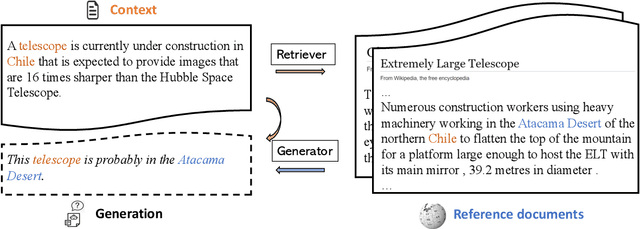
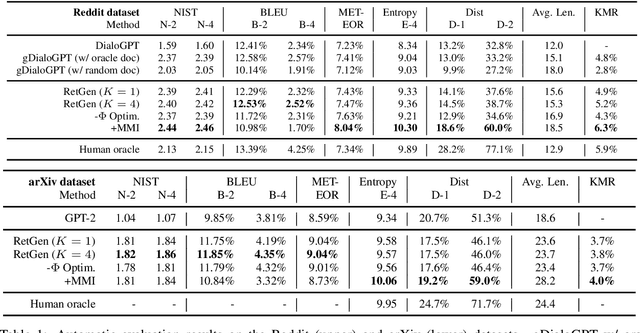
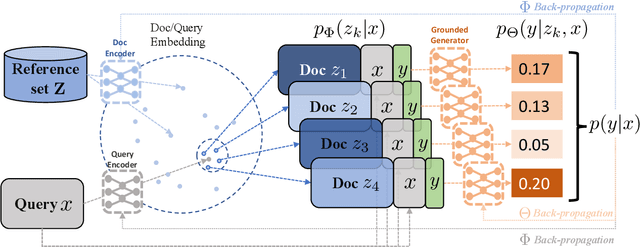

Recent advances in large-scale pre-training such as GPT-3 allow seemingly high quality text to be generated from a given prompt. However, such generation systems often suffer from problems of hallucinated facts, and are not inherently designed to incorporate useful external information. Grounded generation models appear to offer remedies, but their training typically relies on rarely-available parallel data where corresponding information-relevant documents are provided for context. We propose a framework that alleviates this data constraint by jointly training a grounded generator and document retriever on the language model signal. The model learns to reward retrieval of the documents with the highest utility in generation, and attentively combines them using a Mixture-of-Experts (MoE) ensemble to generate follow-on text. We demonstrate that both generator and retriever can take advantage of this joint training and work synergistically to produce more informative and relevant text in both prose and dialogue generation.