 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
N-Best ASR Transformer: Enhancing SLU Performance using Multiple ASR Hypotheses
Jun 11, 2021

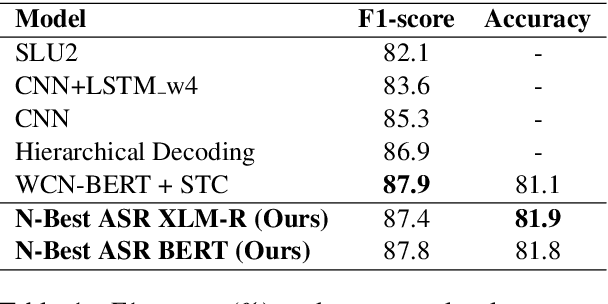
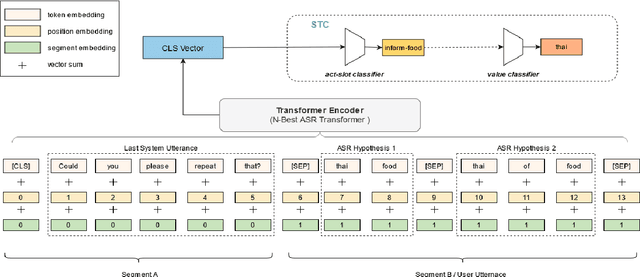
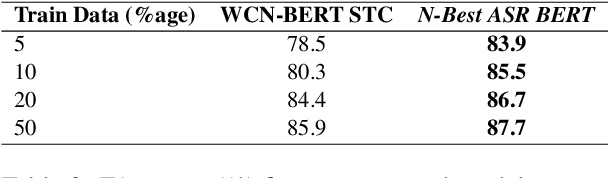
Spoken Language Understanding (SLU) systems parse speech into semantic structures like dialog acts and slots. This involves the use of an Automatic Speech Recognizer (ASR) to transcribe speech into multiple text alternatives (hypotheses). Transcription errors, common in ASRs, impact downstream SLU performance negatively. Approaches to mitigate such errors involve using richer information from the ASR, either in form of N-best hypotheses or word-lattices. We hypothesize that transformer models learn better with a simpler utterance representation using the concatenation of the N-best ASR alternatives, where each alternative is separated by a special delimiter [SEP]. In our work, we test our hypothesis by using concatenated N-best ASR alternatives as the input to transformer encoder models, namely BERT and XLM-RoBERTa, and achieve performance equivalent to the prior state-of-the-art model on DSTC2 dataset. We also show that our approach significantly outperforms the prior state-of-the-art when subjected to the low data regime. Additionally, this methodology is accessible to users of third-party ASR APIs which do not provide word-lattice information.
Unsupervised domain adaptation for cross-modality liver segmentation via joint adversarial learning and self-learning
Sep 20, 2021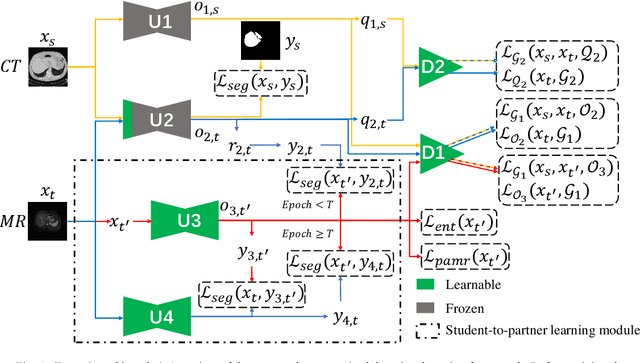
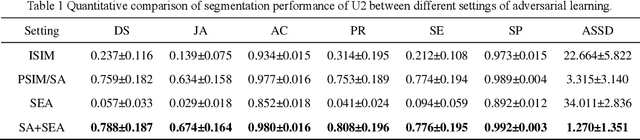
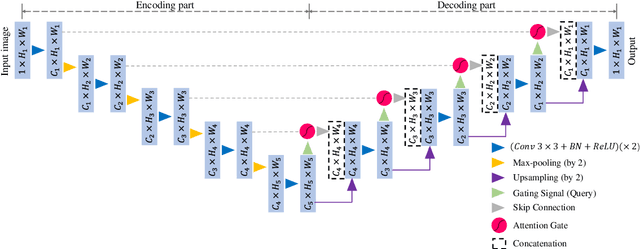
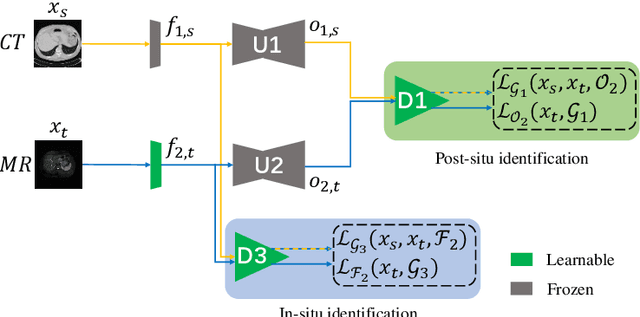
Liver segmentation on images acquired using computed tomography (CT) and magnetic resonance imaging (MRI) plays an important role in clinical management of liver diseases. Compared to MRI, CT images of liver are more abundant and readily available. However, MRI can provide richer quantitative information of the liver compared to CT. Thus, it is desirable to achieve unsupervised domain adaptation for transferring the learned knowledge from the source domain containing labeled CT images to the target domain containing unlabeled MR images. In this work, we report a novel unsupervised domain adaptation framework for cross-modality liver segmentation via joint adversarial learning and self-learning. We propose joint semantic-aware and shape-entropy-aware adversarial learning with post-situ identification manner to implicitly align the distribution of task-related features extracted from the target domain with those from the source domain. In proposed framework, a network is trained with the above two adversarial losses in an unsupervised manner, and then a mean completer of pseudo-label generation is employed to produce pseudo-labels to train the next network (desired model). Additionally, semantic-aware adversarial learning and two self-learning methods, including pixel-adaptive mask refinement and student-to-partner learning, are proposed to train the desired model. To improve the robustness of the desired model, a low-signal augmentation function is proposed to transform MRI images as the input of the desired model to handle hard samples. Using the public data sets, our experiments demonstrated the proposed unsupervised domain adaptation framework outperformed four supervised learning methods with a Dice score 0.912 plus or minus 0.037 (mean plus or minus standard deviation).
Plot2Spectra: an Automatic Spectra Extraction Tool
Jul 06, 2021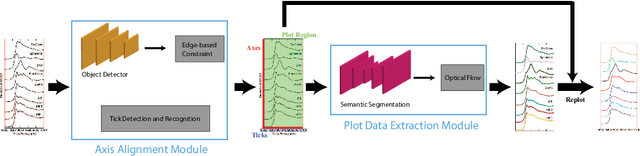
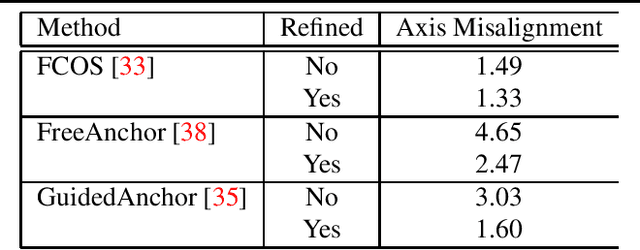
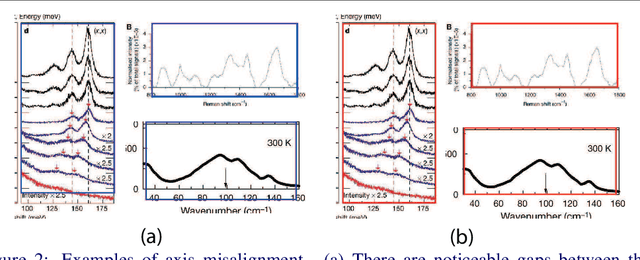
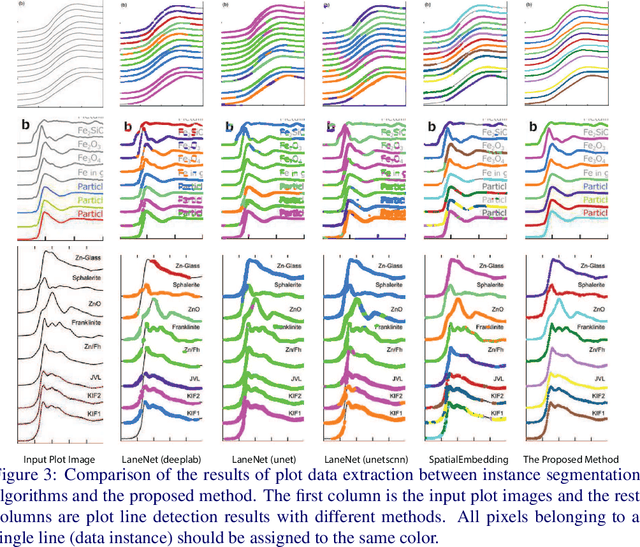
Different types of spectroscopies, such as X-ray absorption near edge structure (XANES) and Raman spectroscopy, play a very important role in analyzing the characteristics of different materials. In scientific literature, XANES/Raman data are usually plotted in line graphs which is a visually appropriate way to represent the information when the end-user is a human reader. However, such graphs are not conducive to direct programmatic analysis due to the lack of automatic tools. In this paper, we develop a plot digitizer, named Plot2Spectra, to extract data points from spectroscopy graph images in an automatic fashion, which makes it possible for large scale data acquisition and analysis. Specifically, the plot digitizer is a two-stage framework. In the first axis alignment stage, we adopt an anchor-free detector to detect the plot region and then refine the detected bounding boxes with an edge-based constraint to locate the position of two axes. We also apply scene text detector to extract and interpret all tick information below the x-axis. In the second plot data extraction stage, we first employ semantic segmentation to separate pixels belonging to plot lines from the background, and from there, incorporate optical flow constraints to the plot line pixels to assign them to the appropriate line (data instance) they encode. Extensive experiments are conducted to validate the effectiveness of the proposed plot digitizer, which shows that such a tool could help accelerate the discovery and machine learning of materials properties.
MT-ORL: Multi-Task Occlusion Relationship Learning
Aug 12, 2021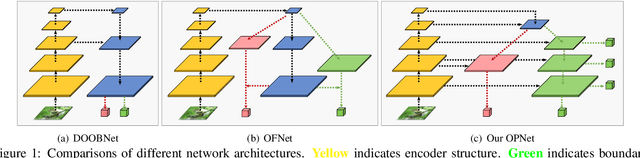
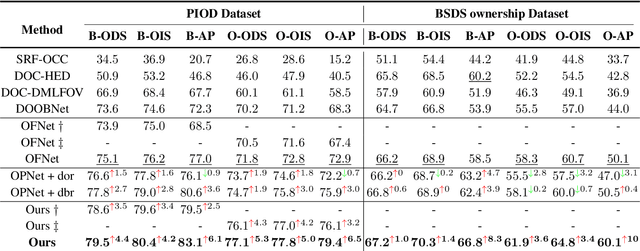
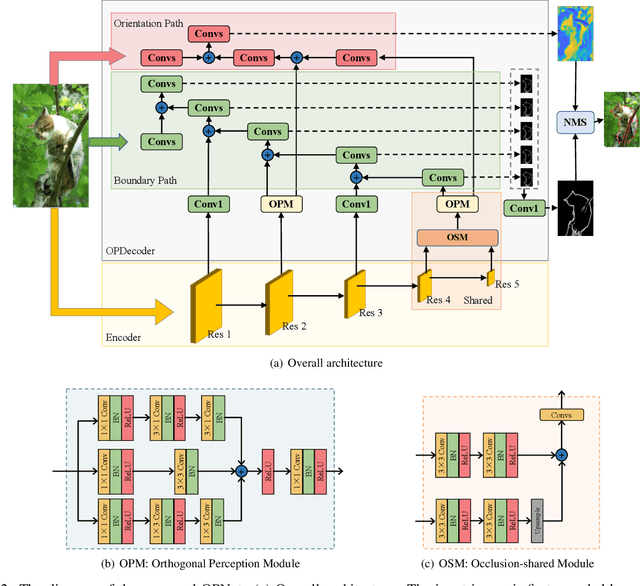
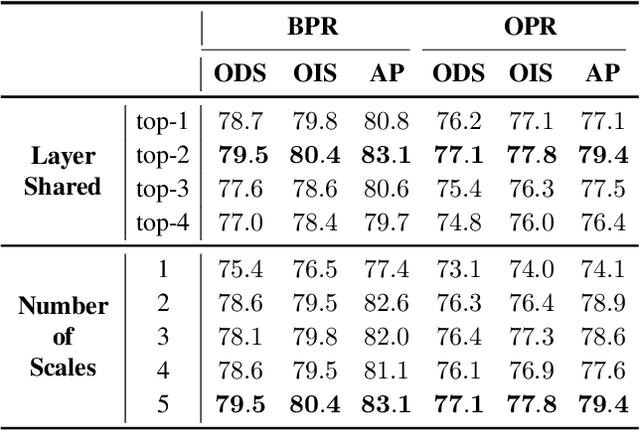
Retrieving occlusion relation among objects in a single image is challenging due to sparsity of boundaries in image. We observe two key issues in existing works: firstly, lack of an architecture which can exploit the limited amount of coupling in the decoder stage between the two subtasks, namely occlusion boundary extraction and occlusion orientation prediction, and secondly, improper representation of occlusion orientation. In this paper, we propose a novel architecture called Occlusion-shared and Path-separated Network (OPNet), which solves the first issue by exploiting rich occlusion cues in shared high-level features and structured spatial information in task-specific low-level features. We then design a simple but effective orthogonal occlusion representation (OOR) to tackle the second issue. Our method surpasses the state-of-the-art methods by 6.1%/8.3% Boundary-AP and 6.5%/10% Orientation-AP on standard PIOD/BSDS ownership datasets. Code is available at https://github.com/fengpanhe/MT-ORL.
Hard Clusters Maximize Mutual Information
Aug 17, 2016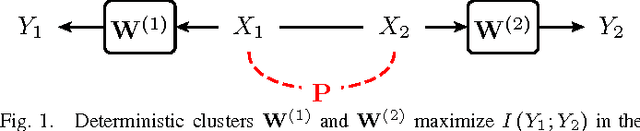
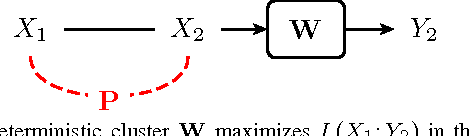

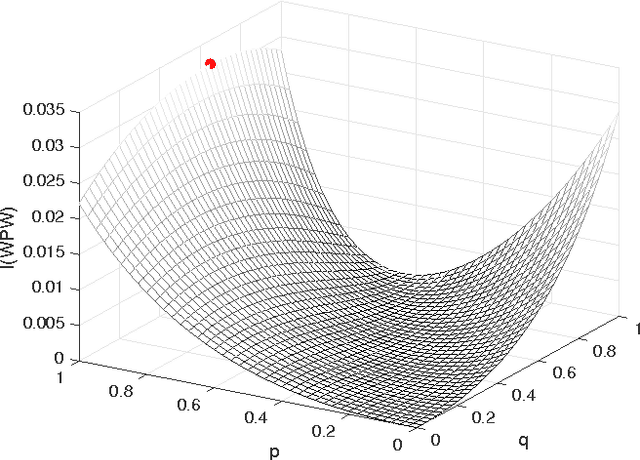
In this paper, we investigate mutual information as a cost function for clustering, and show in which cases hard, i.e., deterministic, clusters are optimal. Using convexity properties of mutual information, we show that certain formulations of the information bottleneck problem are solved by hard clusters. Similarly, hard clusters are optimal for the information-theoretic co-clustering problem that deals with simultaneous clustering of two dependent data sets. If both data sets have to be clustered using the same cluster assignment, hard clusters are not optimal in general. We point at interesting and practically relevant special cases of this so-called pairwise clustering problem, for which we can either prove or have evidence that hard clusters are optimal. Our results thus show that one can relax the otherwise combinatorial hard clustering problem to a real-valued optimization problem with the same global optimum.
Enhanced Invertible Encoding for Learned Image Compression
Aug 08, 2021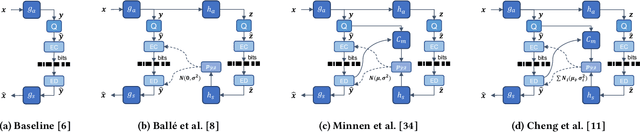

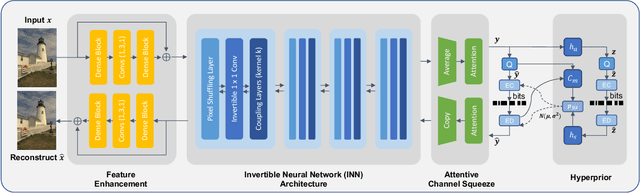
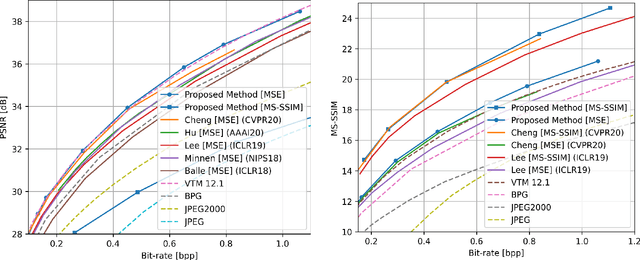
Although deep learning based image compression methods have achieved promising progress these days, the performance of these methods still cannot match the latest compression standard Versatile Video Coding (VVC). Most of the recent developments focus on designing a more accurate and flexible entropy model that can better parameterize the distributions of the latent features. However, few efforts are devoted to structuring a better transformation between the image space and the latent feature space. In this paper, instead of employing previous autoencoder style networks to build this transformation, we propose an enhanced Invertible Encoding Network with invertible neural networks (INNs) to largely mitigate the information loss problem for better compression. Experimental results on the Kodak, CLIC, and Tecnick datasets show that our method outperforms the existing learned image compression methods and compression standards, including VVC (VTM 12.1), especially for high-resolution images. Our source code is available at https://github.com/xyq7/InvCompress.
Uni-FedRec: A Unified Privacy-Preserving News Recommendation Framework for Model Training and Online Serving
Sep 11, 2021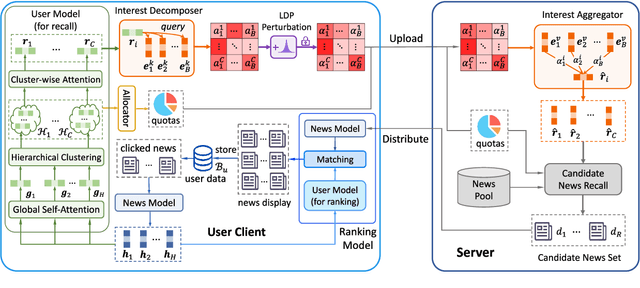
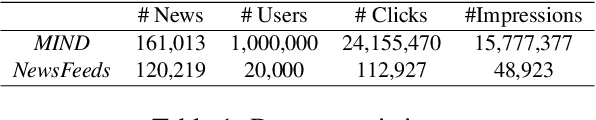
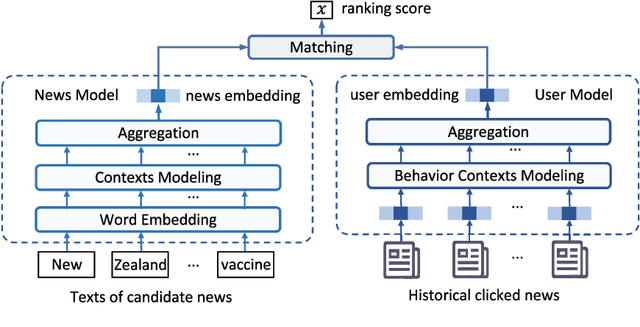
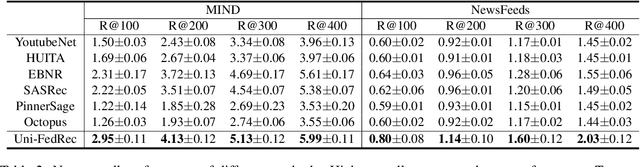
News recommendation is important for personalized online news services. Most existing news recommendation methods rely on centrally stored user behavior data to both train models offline and provide online recommendation services. However, user data is usually highly privacy-sensitive, and centrally storing them may raise privacy concerns and risks. In this paper, we propose a unified news recommendation framework, which can utilize user data locally stored in user clients to train models and serve users in a privacy-preserving way. Following a widely used paradigm in real-world recommender systems, our framework contains two stages. The first one is for candidate news generation (i.e., recall) and the second one is for candidate news ranking (i.e., ranking). At the recall stage, each client locally learns multiple interest representations from clicked news to comprehensively model user interests. These representations are uploaded to the server to recall candidate news from a large news pool, which are further distributed to the user client at the ranking stage for personalized news display. In addition, we propose an interest decomposer-aggregator method with perturbation noise to better protect private user information encoded in user interest representations. Besides, we collaboratively train both recall and ranking models on the data decentralized in a large number of user clients in a privacy-preserving way. Experiments on two real-world news datasets show that our method can outperform baseline methods and effectively protect user privacy.
FedCCEA : A Practical Approach of Client Contribution Evaluation for Federated Learning
Jun 04, 2021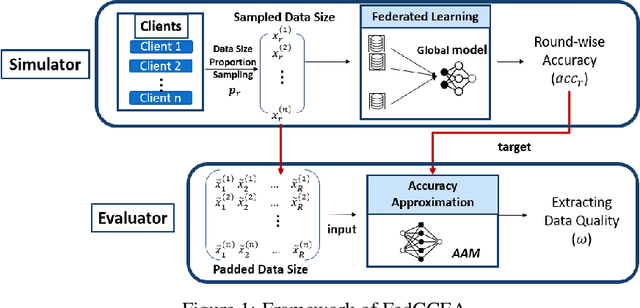
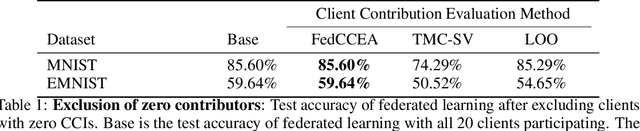
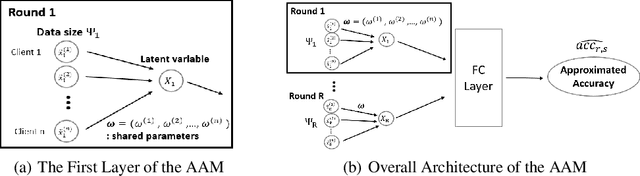

Client contribution evaluation, also known as data valuation, is a crucial approach in federated learning(FL) for client selection and incentive allocation. However, due to restrictions of accessibility of raw data, only limited information such as local weights and local data size of each client is open for quantifying the client contribution. Using data size from available information, we introduce an empirical evaluation method called Federated Client Contribution Evaluation through Accuracy Approximation(FedCCEA). This method builds the Accuracy Approximation Model(AAM), which estimates a simulated test accuracy using inputs of sampled data size and extracts the clients' data quality and data size to measure client contribution. FedCCEA strengthens some advantages: (1) enablement of data size selection to the clients, (2) feasible evaluation time regardless of the number of clients, and (3) precise estimation in non-IID settings. We demonstrate the superiority of FedCCEA compared to previous methods through several experiments: client contribution distribution, client removal, and robustness test to partial participation.
Recalling Holistic Information for Semantic Segmentation
Nov 24, 2016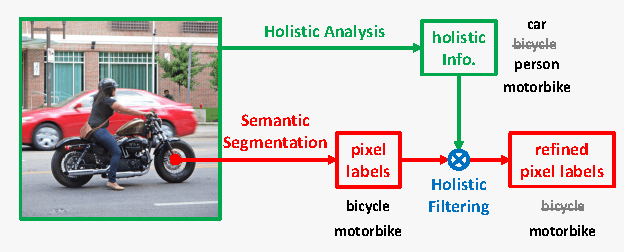
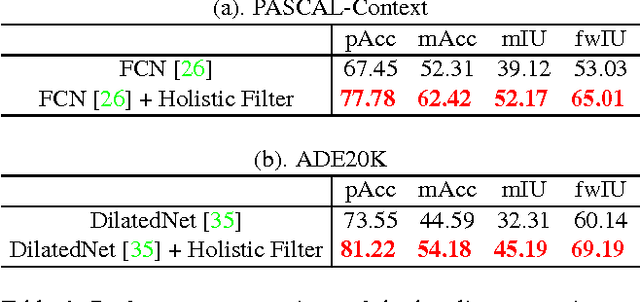
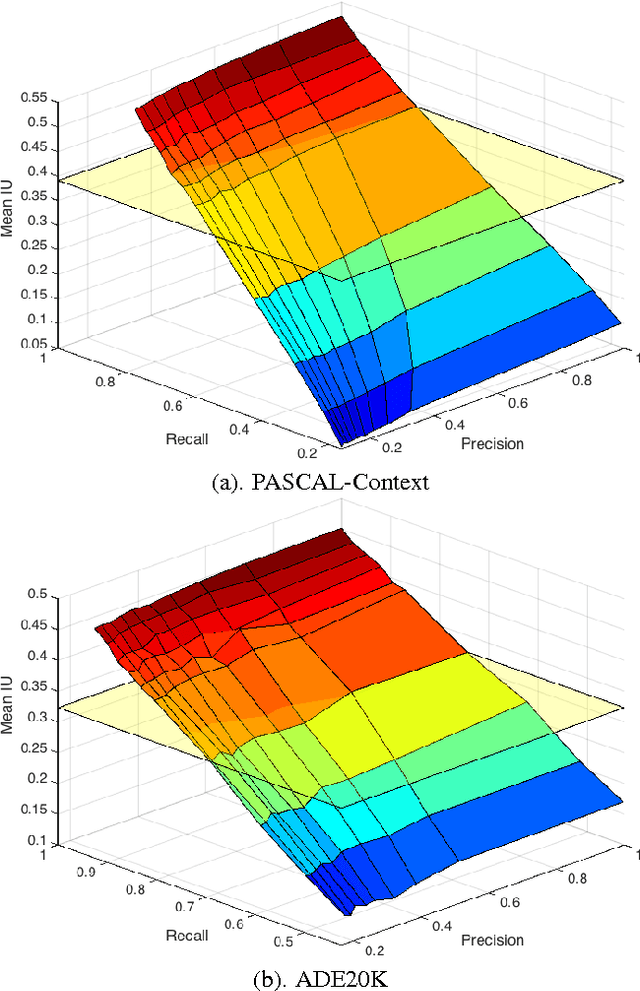
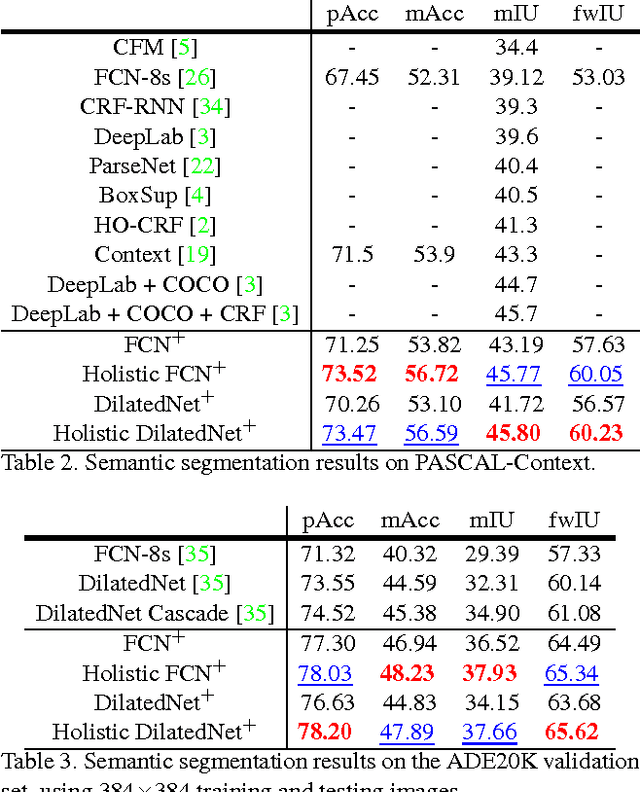
Semantic segmentation requires a detailed labeling of image pixels by object category. Information derived from local image patches is necessary to describe the detailed shape of individual objects. However, this information is ambiguous and can result in noisy labels. Global inference of image content can instead capture the general semantic concepts present. We advocate that high-recall holistic inference of image concepts provides valuable information for detailed pixel labeling. We build a two-stream neural network architecture that facilitates information flow from holistic information to local pixels, while keeping common image features shared among the low-level layers of both the holistic analysis and segmentation branches. We empirically evaluate our network on four standard semantic segmentation datasets. Our network obtains state-of-the-art performance on PASCAL-Context and NYUDv2, and ablation studies verify its effectiveness on ADE20K and SIFT-Flow.
Spatio-Temporal Human Action Recognition Modelwith Flexible-interval Sampling and Normalization
Aug 12, 2021
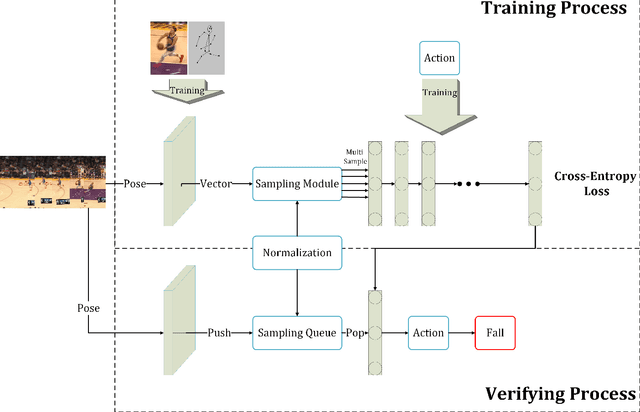
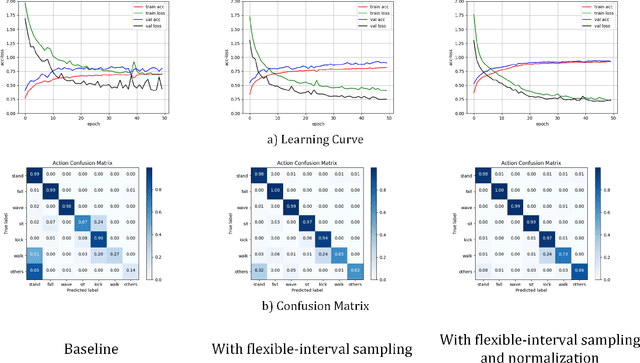
Human action recognition is a well-known computer vision and pattern recognition task of identifying which action a man is actually doing. Extracting the keypoint information of a single human with both spatial and temporal features of action sequences plays an essential role to accomplish the task.In this paper, we propose a human action system for Red-Green-Blue(RGB) input video with our own designed module. Based on the efficient Gated Recurrent Unit(GRU) for spatio-temporal feature extraction, we add another sampling module and normalization module to improve the performance of the model in order to recognize the human actions. Furthermore, we build a novel dataset with a similar background and discriminative actions for both human keypoint prediction and behavior recognition. To get a better result, we retrain the pose model with our new dataset to get better performance. Experimental results demonstrate the effectiveness of the proposed model on our own human behavior recognition dataset and some public datasets.