 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Qualitative Evaluation of User Preference for Link-based vs. Text-based Recommendations of Wikipedia Articles
Sep 16, 2021
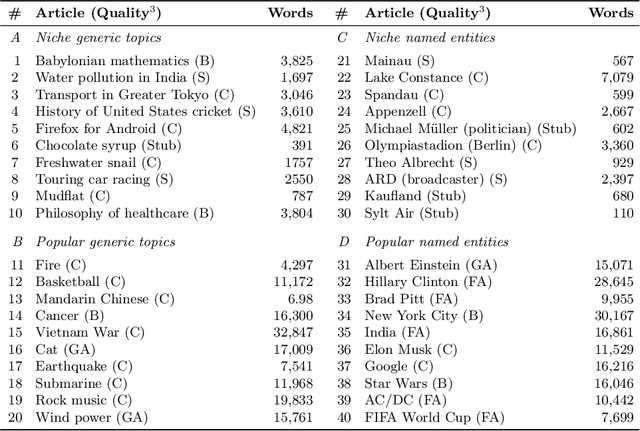
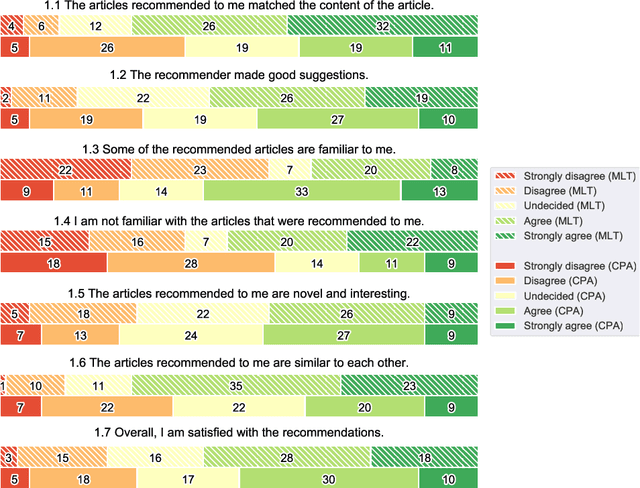
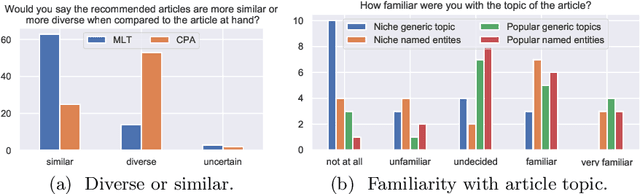
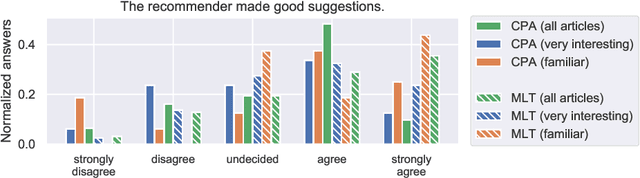
Literature recommendation systems (LRS) assist readers in the discovery of relevant content from the overwhelming amount of literature available. Despite the widespread adoption of LRS, there is a lack of research on the user-perceived recommendation characteristics for fundamentally different approaches to content-based literature recommendation. To complement existing quantitative studies on literature recommendation, we present qualitative study results that report on users' perceptions for two contrasting recommendation classes: (1) link-based recommendation represented by the Co-Citation Proximity (CPA) approach, and (2) text-based recommendation represented by Lucene's MoreLikeThis (MLT) algorithm. The empirical data analyzed in our study with twenty users and a diverse set of 40 Wikipedia articles indicate a noticeable difference between text- and link-based recommendation generation approaches along several key dimensions. The text-based MLT method receives higher satisfaction ratings in terms of user-perceived similarity of recommended articles. In contrast, the CPA approach receives higher satisfaction scores in terms of diversity and serendipity of recommendations. We conclude that users of literature recommendation systems can benefit most from hybrid approaches that combine both link- and text-based approaches, where the user's information needs and preferences should control the weighting for the approaches used. The optimal weighting of multiple approaches used in a hybrid recommendation system is highly dependent on a user's shifting needs.
Joint Embedding of Meta-Path and Meta-Graph for Heterogeneous Information Networks
Sep 11, 2018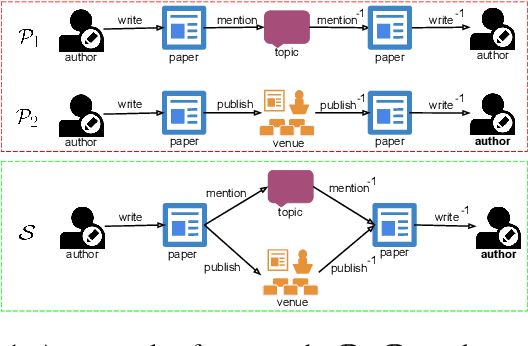
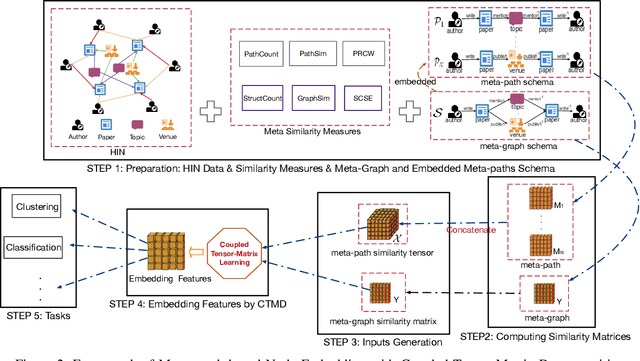

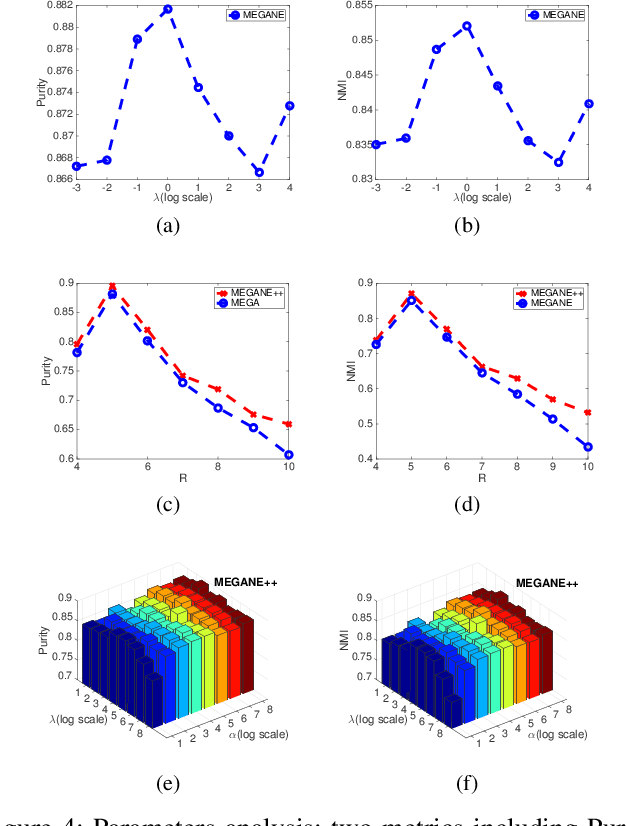
Meta-graph is currently the most powerful tool for similarity search on heterogeneous information networks,where a meta-graph is a composition of meta-paths that captures the complex structural information. However, current relevance computing based on meta-graph only considers the complex structural information, but ignores its embedded meta-paths information. To address this problem, we proposeMEta-GrAph-based network embedding models, called MEGA and MEGA++, respectively. The MEGA model uses normalized relevance or similarity measures that are derived from a meta-graph and its embedded meta-paths between nodes simultaneously, and then leverages tensor decomposition method to perform node embedding. The MEGA++ further facilitates the use of coupled tensor-matrix decomposition method to obtain a joint embedding for nodes, which simultaneously considers the hidden relations of all meta information of a meta-graph.Extensive experiments on two real datasets demonstrate thatMEGA and MEGA++ are more effective than state-of-the-art approaches.
Not All Memories are Created Equal: Learning to Forget by Expiring
May 13, 2021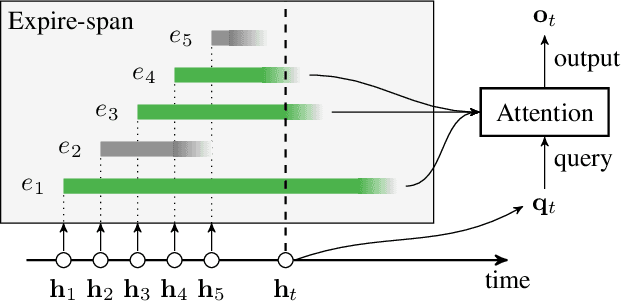
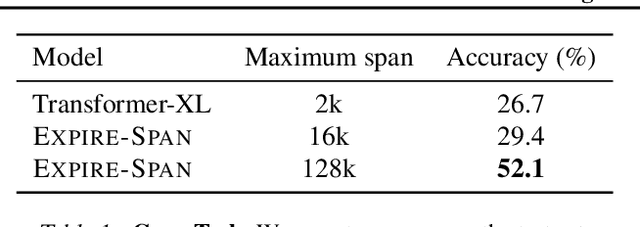
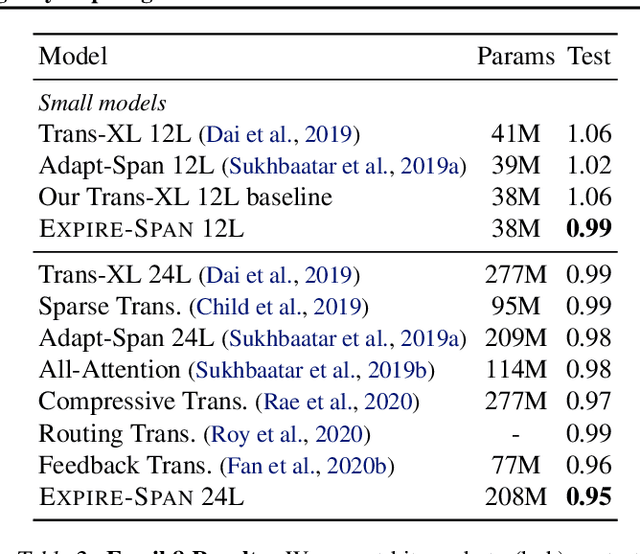

Attention mechanisms have shown promising results in sequence modeling tasks that require long-term memory. Recent work investigated mechanisms to reduce the computational cost of preserving and storing memories. However, not all content in the past is equally important to remember. We propose Expire-Span, a method that learns to retain the most important information and expire the irrelevant information. This forgetting of memories enables Transformers to scale to attend over tens of thousands of previous timesteps efficiently, as not all states from previous timesteps are preserved. We demonstrate that Expire-Span can help models identify and retain critical information and show it can achieve strong performance on reinforcement learning tasks specifically designed to challenge this functionality. Next, we show that Expire-Span can scale to memories that are tens of thousands in size, setting a new state of the art on incredibly long context tasks such as character-level language modeling and a frame-by-frame moving objects task. Finally, we analyze the efficiency of Expire-Span compared to existing approaches and demonstrate that it trains faster and uses less memory.
Exploiting Multi-modal Contextual Sensing for City-bus's Stay Location Characterization: Towards Sub-60 Seconds Accurate Arrival Time Prediction
May 24, 2021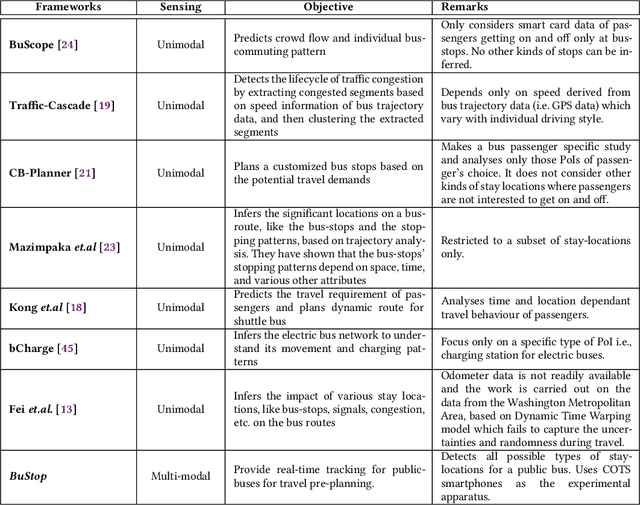
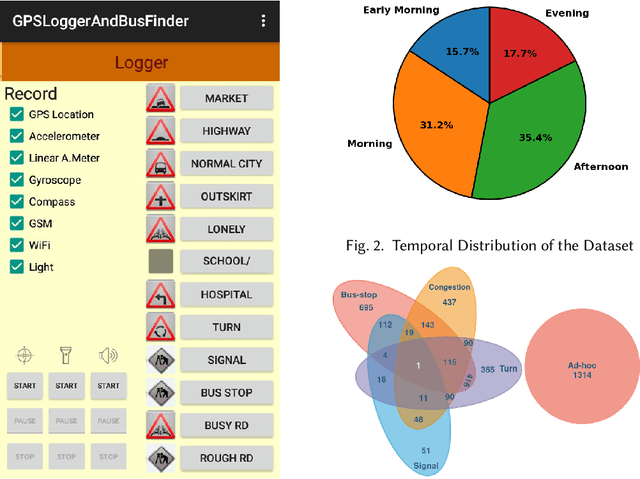


Intelligent city transportation systems are one of the core infrastructures of a smart city. The true ingenuity of such an infrastructure lies in providing the commuters with real-time information about citywide transports like public buses, allowing her to pre-plan the travel. However, providing prior information for transportation systems like public buses in real-time is inherently challenging because of the diverse nature of different stay-locations that a public bus stops. Although straightforward factors stay duration, extracted from unimodal sources like GPS, at these locations look erratic, a thorough analysis of public bus GPS trails for 720km of bus travels at the city of Durgapur, a semi-urban city in India, reveals that several other fine-grained contextual features can characterize these locations accurately. Accordingly, we develop BuStop, a system for extracting and characterizing the stay locations from multi-modal sensing using commuters' smartphones. Using this multi-modal information BuStop extracts a set of granular contextual features that allow the system to differentiate among the different stay-location types. A thorough analysis of BuStop using the collected dataset indicates that the system works with high accuracy in identifying different stay locations like regular bus stops, random ad-hoc stops, stops due to traffic congestion stops at traffic signals, and stops at sharp turns. Additionally, we also develop a proof-of-concept setup on top of BuStop to analyze the potential of the framework in predicting expected arrival time, a critical piece of information required to pre-plan travel, at any given bus stop. Subsequent analysis of the PoC framework, through simulation over the test dataset, shows that characterizing the stay-locations indeed helps make more accurate arrival time predictions with deviations less than 60s from the ground-truth arrival time.
Enhancing Self-Disclosure In Neural Dialog Models By Candidate Re-ranking
Sep 10, 2021
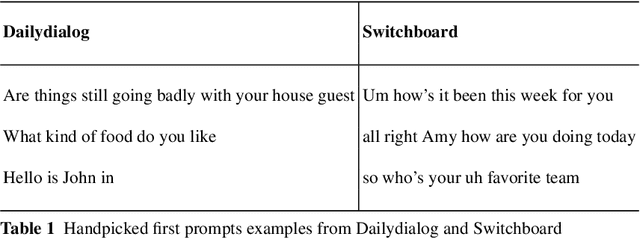
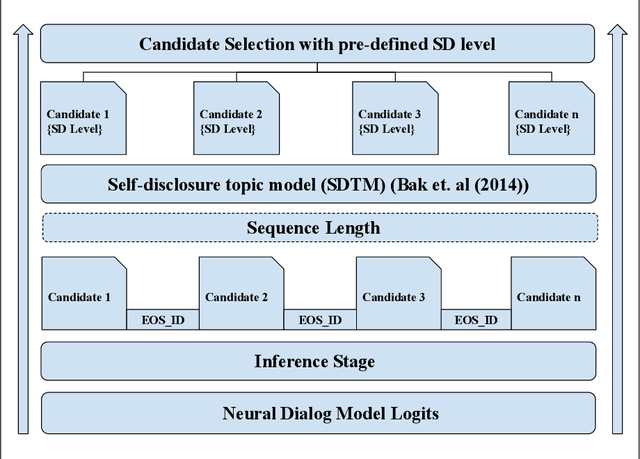
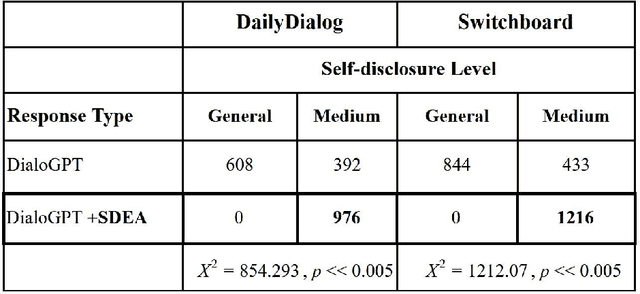
Neural language modelling has progressed the state-of-the-art in different downstream Natural Language Processing (NLP) tasks. One such area is of open-domain dialog modelling, neural dialog models based on GPT-2 such as DialoGPT have shown promising performance in single-turn conversation. However, such (neural) dialog models have been criticized for generating responses which although may have relevance to the previous human response, tend to quickly dissipate human interest and descend into trivial conversation. One reason for such performance is the lack of explicit conversation strategy being employed in human-machine conversation. Humans employ a range of conversation strategies while engaging in a conversation, one such key social strategies is Self-disclosure(SD). A phenomenon of revealing information about one-self to others. Social penetration theory (SPT) proposes that communication between two people moves from shallow to deeper levels as the relationship progresses primarily through self-disclosure. Disclosure helps in creating rapport among the participants engaged in a conversation. In this paper, Self-disclosure enhancement architecture (SDEA) is introduced utilizing Self-disclosure Topic Model (SDTM) during inference stage of a neural dialog model to re-rank response candidates to enhance self-disclosure in single-turn responses from from the model.
Improving Distantly Supervised Relation Extraction with Self-Ensemble Noise Filtering
Aug 22, 2021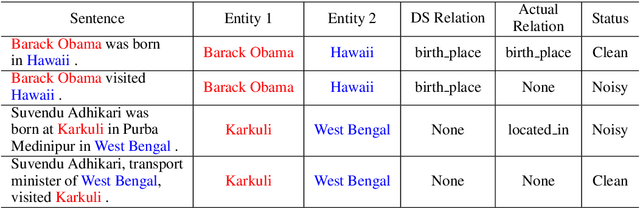
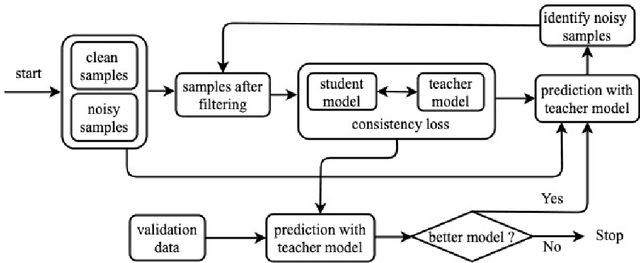
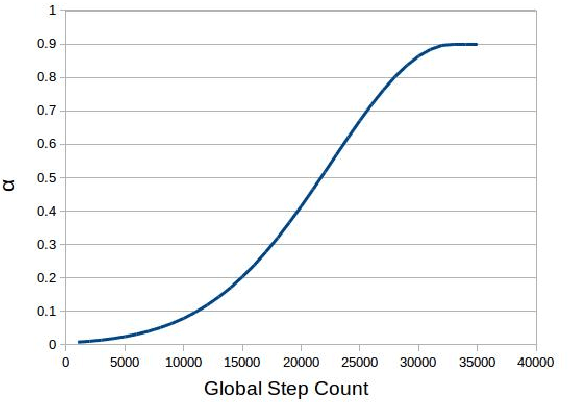

Distantly supervised models are very popular for relation extraction since we can obtain a large amount of training data using the distant supervision method without human annotation. In distant supervision, a sentence is considered as a source of a tuple if the sentence contains both entities of the tuple. However, this condition is too permissive and does not guarantee the presence of relevant relation-specific information in the sentence. As such, distantly supervised training data contains much noise which adversely affects the performance of the models. In this paper, we propose a self-ensemble filtering mechanism to filter out the noisy samples during the training process. We evaluate our proposed framework on the New York Times dataset which is obtained via distant supervision. Our experiments with multiple state-of-the-art neural relation extraction models show that our proposed filtering mechanism improves the robustness of the models and increases their F1 scores.
LGD-GCN: Local and Global Disentangled Graph Convolutional Networks
Apr 24, 2021
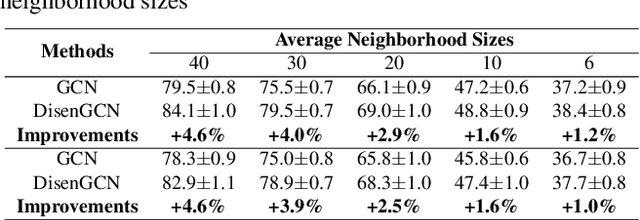
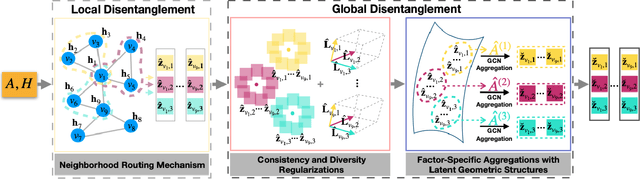
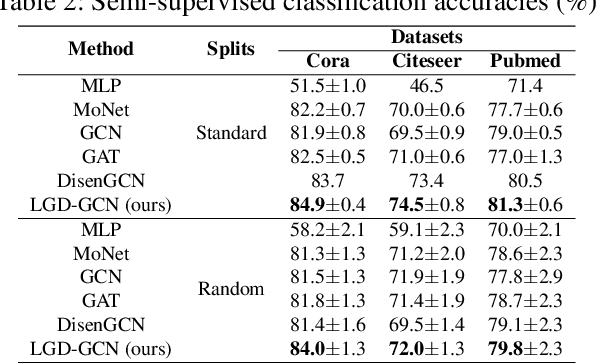
Disentangled Graph Convolutional Network (DisenGCN) is an encouraging framework to disentangle the latent factors arising in a real-world graph. However, it relies on disentangling information heavily from a local range (i.e., a node and its 1-hop neighbors), while the local information in many cases can be uneven and incomplete, hindering the interpretabiliy power and model performance of DisenGCN. In this paper, we introduce a novel Local and Global Disentangled Graph Convolutional Network (LGD-GCN) to capture both local and global information for graph disentanglement. LGD-GCN performs a statistical mixture modeling to derive a factor-aware latent continuous space, and then constructs different structures w.r.t. different factors from the revealed space. In this way, the global factor-specific information can be efficiently and selectively encoded via a message passing along these built structures, strengthening the intra-factor consistency. We also propose a novel diversity promoting regularizer employed with the latent space modeling, to encourage inter-factor diversity. Evaluations of the proposed LGD-GCN on the synthetic and real-world datasets show a better interpretability and improved performance in node classification over the existing competitive models.
FDeblur-GAN: Fingerprint Deblurring using Generative Adversarial Network
Jun 21, 2021
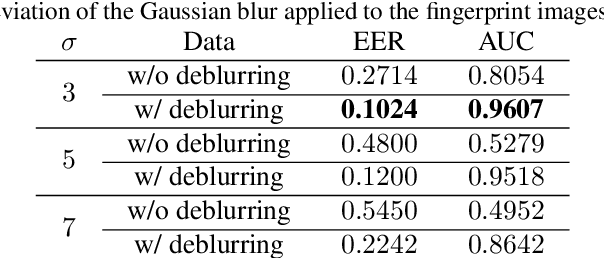
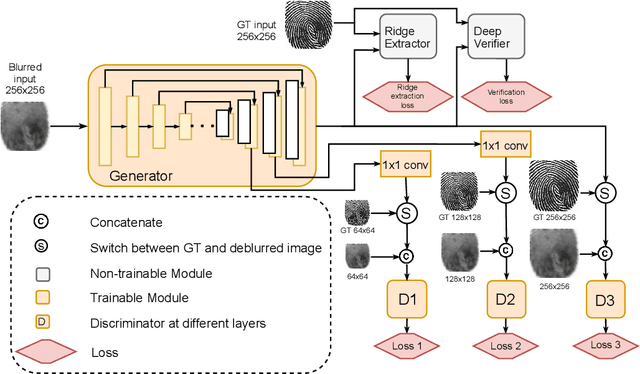
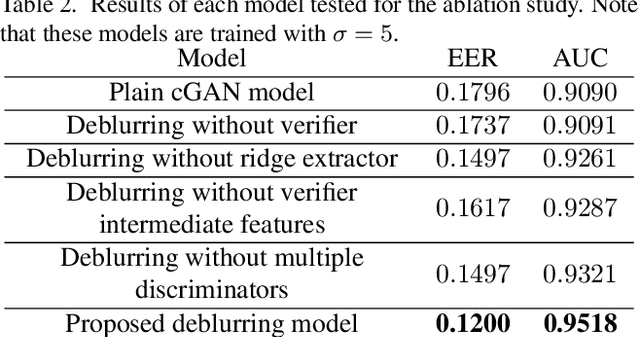
While working with fingerprint images acquired from crime scenes, mobile cameras, or low-quality sensors, it becomes difficult for automated identification systems to verify the identity due to image blur and distortion. We propose a fingerprint deblurring model FDeblur-GAN, based on the conditional Generative Adversarial Networks (cGANs) and multi-stage framework of the stack GAN. Additionally, we integrate two auxiliary sub-networks into the model for the deblurring task. The first sub-network is a ridge extractor model. It is added to generate ridge maps to ensure that fingerprint information and minutiae are preserved in the deblurring process and prevent the model from generating erroneous minutiae. The second sub-network is a verifier that helps the generator to preserve the ID information during the generation process. Using a database of blurred fingerprints and corresponding ridge maps, the deep network learns to deblur from the input blurry samples. We evaluate the proposed method in combination with two different fingerprint matching algorithms. We achieved an accuracy of 95.18% on our fingerprint database for the task of matching deblurred and ground truth fingerprints.
SPIN Road Mapper: Extracting Roads from Aerial Images via Spatial and Interaction Space Graph Reasoning for Autonomous Driving
Sep 16, 2021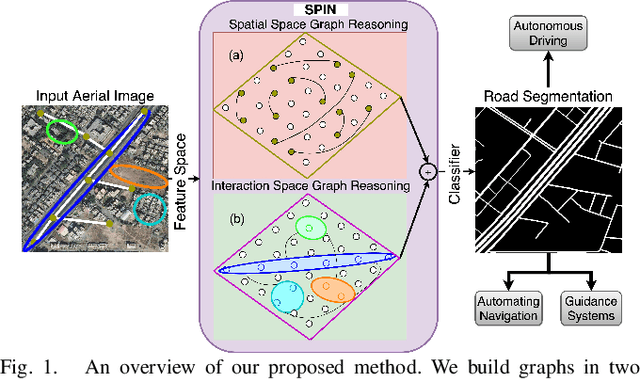
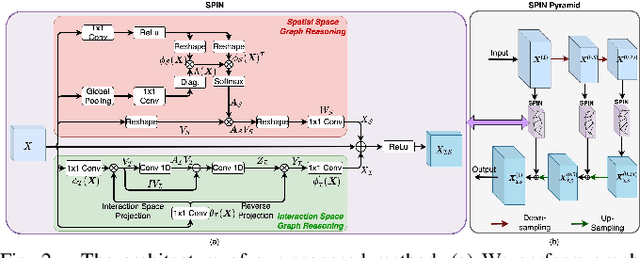
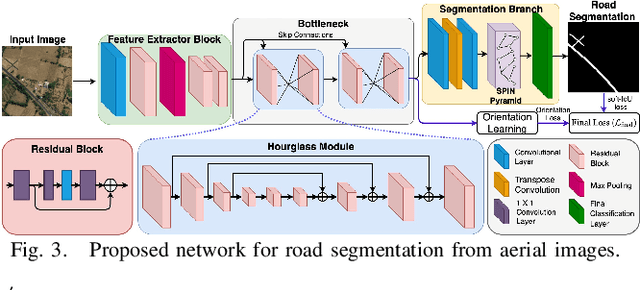

Road extraction is an essential step in building autonomous navigation systems. Detecting road segments is challenging as they are of varying widths, bifurcated throughout the image, and are often occluded by terrain, cloud, or other weather conditions. Using just convolution neural networks (ConvNets) for this problem is not effective as it is inefficient at capturing distant dependencies between road segments in the image which is essential to extract road connectivity. To this end, we propose a Spatial and Interaction Space Graph Reasoning (SPIN) module which when plugged into a ConvNet performs reasoning over graphs constructed on spatial and interaction spaces projected from the feature maps. Reasoning over spatial space extracts dependencies between different spatial regions and other contextual information. Reasoning over a projected interaction space helps in appropriate delineation of roads from other topographies present in the image. Thus, SPIN extracts long-range dependencies between road segments and effectively delineates roads from other semantics. We also introduce a SPIN pyramid which performs SPIN graph reasoning across multiple scales to extract multi-scale features. We propose a network based on stacked hourglass modules and SPIN pyramid for road segmentation which achieves better performance compared to existing methods. Moreover, our method is computationally efficient and significantly boosts the convergence speed during training, making it feasible for applying on large-scale high-resolution aerial images. Code available at: https://github.com/wgcban/SPIN_RoadMapper.git.
* Code available at: https://github.com/wgcban/SPIN_RoadMapper.git
The Temporal Opportunist: Self-Supervised Multi-Frame Monocular Depth
Apr 29, 2021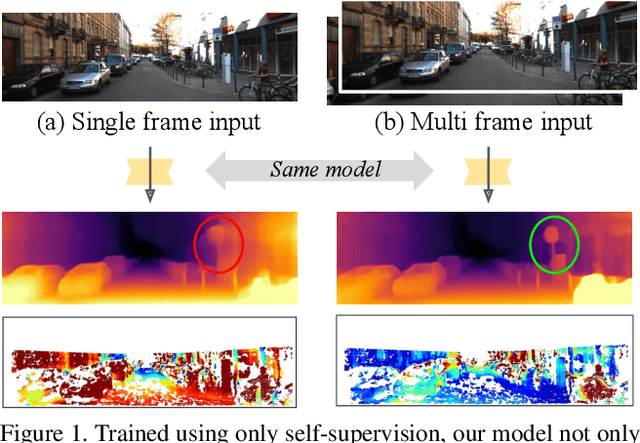
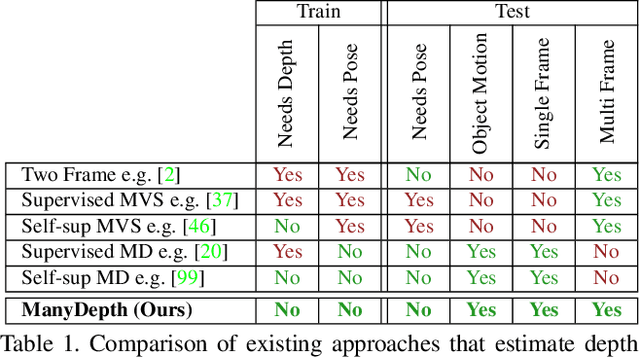
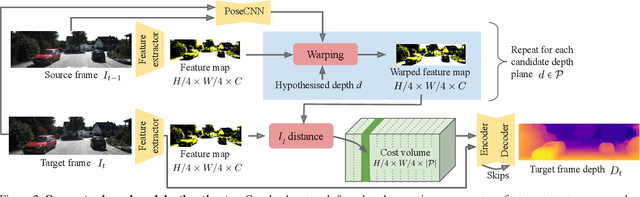
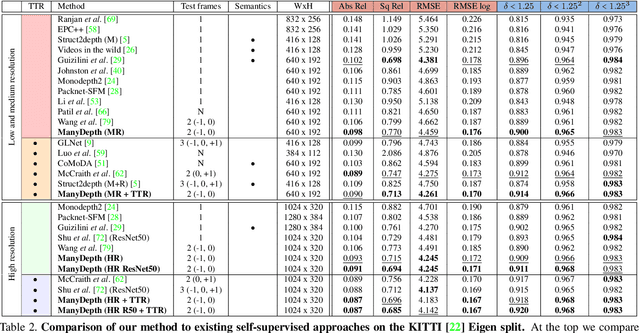
Self-supervised monocular depth estimation networks are trained to predict scene depth using nearby frames as a supervision signal during training. However, for many applications, sequence information in the form of video frames is also available at test time. The vast majority of monocular networks do not make use of this extra signal, thus ignoring valuable information that could be used to improve the predicted depth. Those that do, either use computationally expensive test-time refinement techniques or off-the-shelf recurrent networks, which only indirectly make use of the geometric information that is inherently available. We propose ManyDepth, an adaptive approach to dense depth estimation that can make use of sequence information at test time, when it is available. Taking inspiration from multi-view stereo, we propose a deep end-to-end cost volume based approach that is trained using self-supervision only. We present a novel consistency loss that encourages the network to ignore the cost volume when it is deemed unreliable, e.g. in the case of moving objects, and an augmentation scheme to cope with static cameras. Our detailed experiments on both KITTI and Cityscapes show that we outperform all published self-supervised baselines, including those that use single or multiple frames at test time.