 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Graph Embedding with Rich Information through Heterogeneous Network
Jan 17, 2018
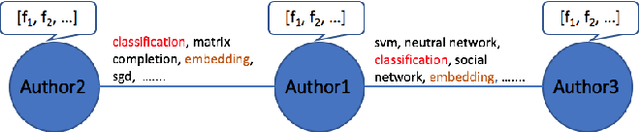
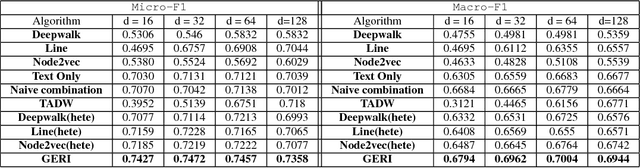
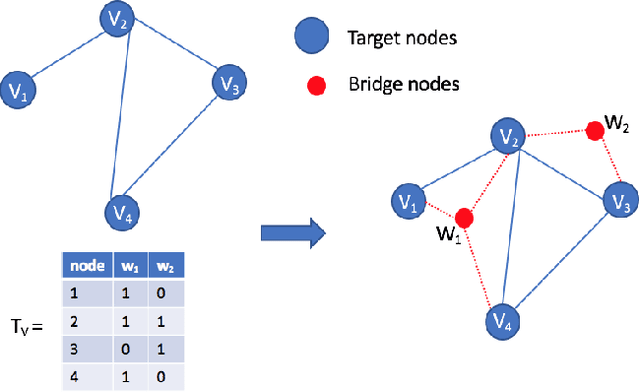
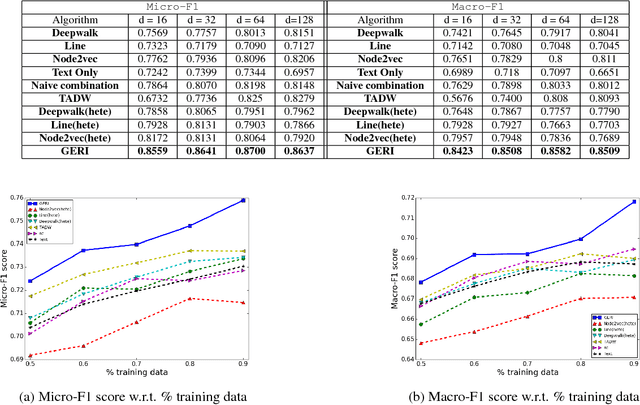
Graph embedding has attracted increasing attention due to its critical application in social network analysis. Most existing algorithms for graph embedding only rely on the typology information and fail to use the copious information in nodes as well as edges. As a result, their performance for many tasks may not be satisfactory. In this paper, we proposed a novel and general framework of representation learning for graph with rich text information through constructing a bipartite heterogeneous network. Specially, we designed a biased random walk to explore the constructed heterogeneous network with the notion of flexible neighborhood. The efficacy of our method is demonstrated by extensive comparison experiments with several baselines on various datasets. It improves the Micro-F1 and Macro-F1 of node classification by 10% and 7% on Cora dataset.
Attend What You Need: Motion-Appearance Synergistic Networks for Video Question Answering
Jun 19, 2021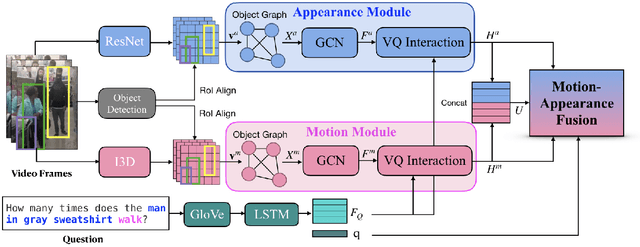
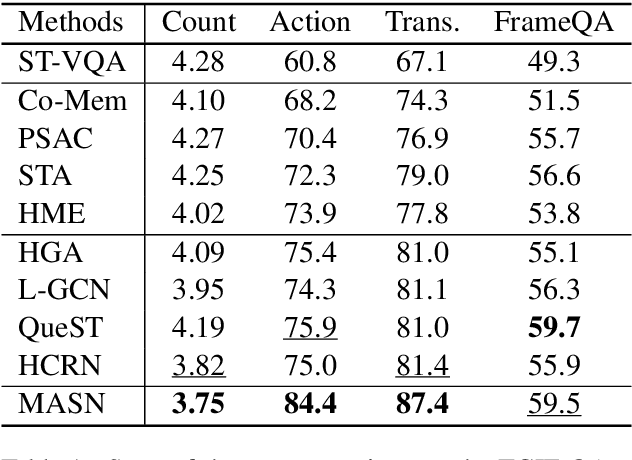
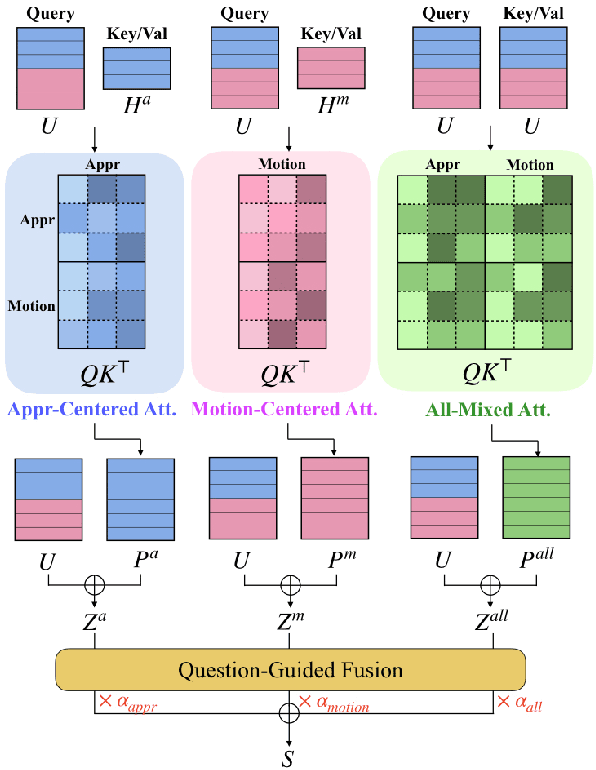
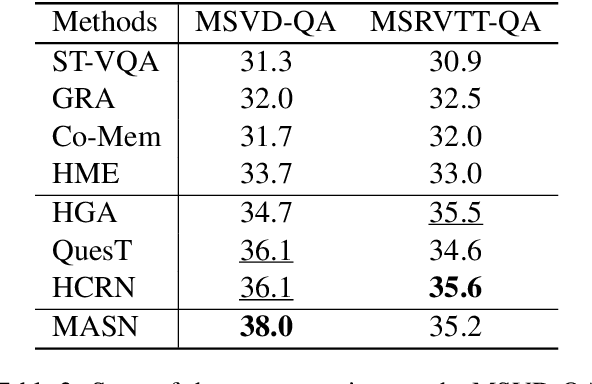
Video Question Answering is a task which requires an AI agent to answer questions grounded in video. This task entails three key challenges: (1) understand the intention of various questions, (2) capturing various elements of the input video (e.g., object, action, causality), and (3) cross-modal grounding between language and vision information. We propose Motion-Appearance Synergistic Networks (MASN), which embed two cross-modal features grounded on motion and appearance information and selectively utilize them depending on the question's intentions. MASN consists of a motion module, an appearance module, and a motion-appearance fusion module. The motion module computes the action-oriented cross-modal joint representations, while the appearance module focuses on the appearance aspect of the input video. Finally, the motion-appearance fusion module takes each output of the motion module and the appearance module as input, and performs question-guided fusion. As a result, MASN achieves new state-of-the-art performance on the TGIF-QA and MSVD-QA datasets. We also conduct qualitative analysis by visualizing the inference results of MASN. The code is available at https://github.com/ahjeongseo/MASN-pytorch.
Improving Fairness of AI Systems with Lossless De-biasing
May 10, 2021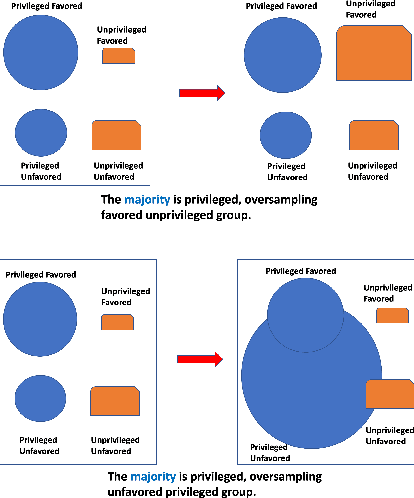
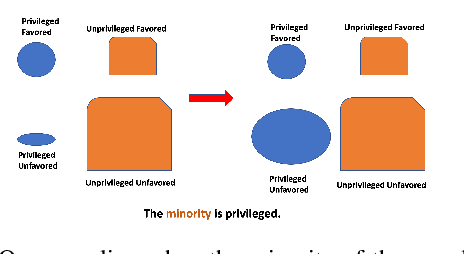
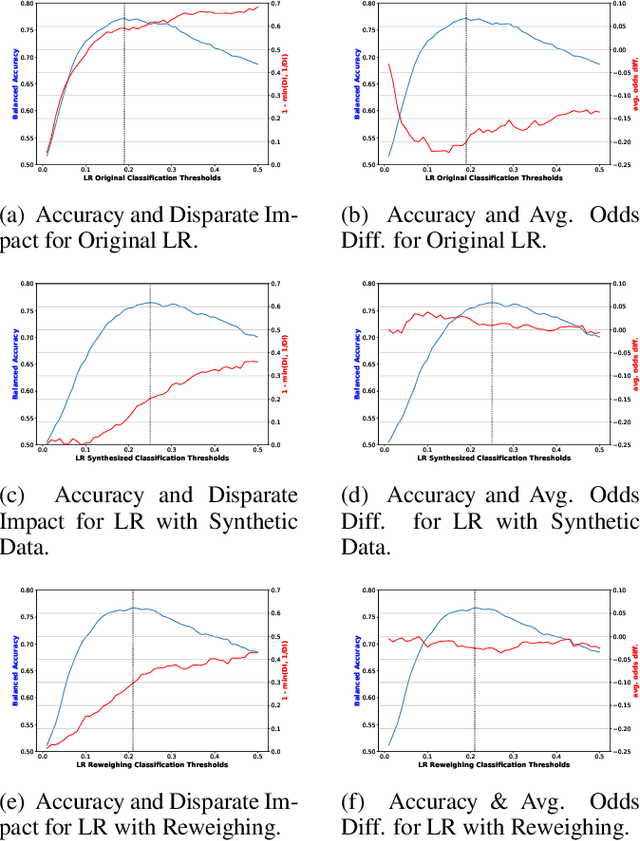
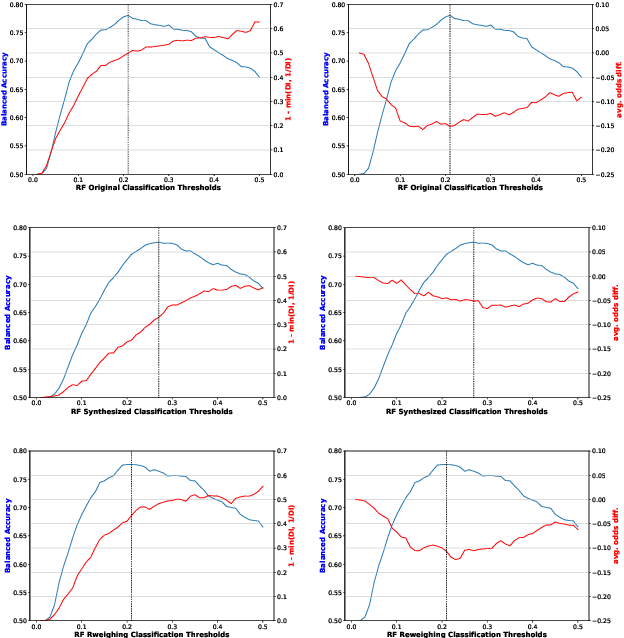
In today's society, AI systems are increasingly used to make critical decisions such as credit scoring and patient triage. However, great convenience brought by AI systems comes with troubling prevalence of bias against underrepresented groups. Mitigating bias in AI systems to increase overall fairness has emerged as an important challenge. Existing studies on mitigating bias in AI systems focus on eliminating sensitive demographic information embedded in data. Given the temporal and contextual complexity of conceptualizing fairness, lossy treatment of demographic information may contribute to an unnecessary trade-off between accuracy and fairness, especially when demographic attributes and class labels are correlated. In this paper, we present an information-lossless de-biasing technique that targets the scarcity of data in the disadvantaged group. Unlike the existing work, we demonstrate, both theoretically and empirically, that oversampling underrepresented groups can not only mitigate algorithmic bias in AI systems that consistently predict a favorable outcome for a certain group, but improve overall accuracy by mitigating class imbalance within data that leads to a bias towards the majority class. We demonstrate the effectiveness of our technique on real datasets using a variety of fairness metrics.
Selective Light Field Refocusing for Camera Arrays Using Bokeh Rendering and Superresolution
Aug 09, 2021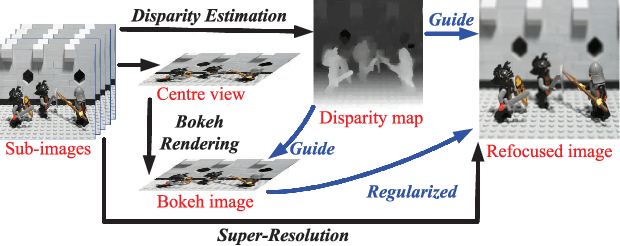


Camera arrays provide spatial and angular information within a single snapshot. With refocusing methods, focal planes can be altered after exposure. In this letter, we propose a light field refocusing method to improve the imaging quality of camera arrays. In our method, the disparity is first estimated. Then, the unfocused region (bokeh) is rendered by using a depth-based anisotropic filter. Finally, the refocused image is produced by a reconstruction-based superresolution approach where the bokeh image is used as a regularization term. Our method can selectively refocus images with focused region being superresolved and bokeh being aesthetically rendered. Our method also enables postadjustment of depth of field. We conduct experiments on both public and self-developed datasets. Our method achieves superior visual performance with acceptable computational cost as compared to other state-of-the-art methods. Code is available at https://github.com/YingqianWang/Selective-LF-Refocusing.
Throughput Maximization for IRS-Assisted Wireless Powered Hybrid NOMA and TDMA
Apr 27, 2021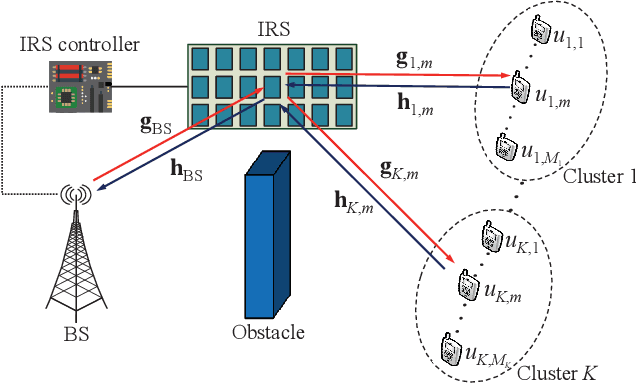
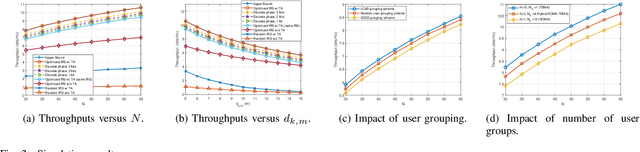
The high reflect beamforming gain of the intelligent reflecting surface (IRS) makes it appealing not only for wireless information transmission but also for wireless power transfer. In this letter, we consider an IRS-assisted wireless powered communication network, where a base station (BS) transmits energy to multiple users grouped into multiple clusters in the downlink, and the clustered users transmit information to the BS in the manner of hybrid non-orthogonal multiple access and time division multiple access in the uplink. We investigate optimizing the reflect beamforming of the IRS and the time allocation among the BS's power transfer and different user clusters' information transmission to maximize the throughput of the network, and we propose an efficient algorithm based on the block coordinate ascent, semidefinite relaxation, and sequential rank-one constraint relaxation techniques to solve the resultant problem. Simulation results have verified the effectiveness of the proposed algorithm and have shown the impact of user clustering setup on the throughput performance of the network.
Exploring deep learning methods for recognizing rare diseases and their clinical manifestations from texts
Sep 01, 2021
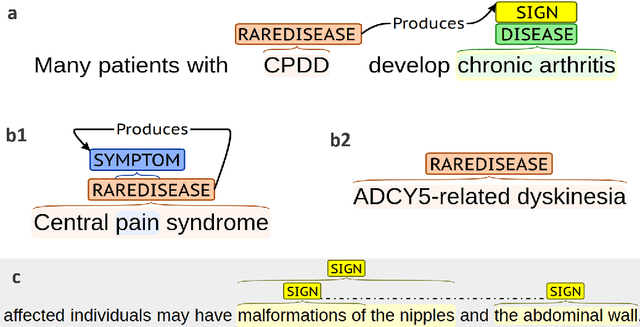
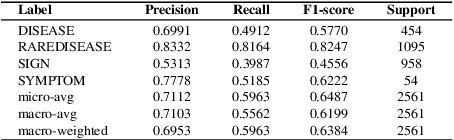
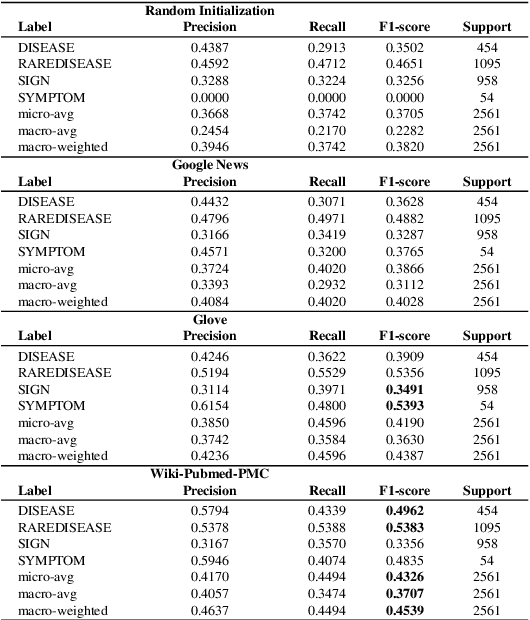
Although rare diseases are characterized by low prevalence, approximately 300 million people are affected by a rare disease. The early and accurate diagnosis of these conditions is a major challenge for general practitioners, who do not have enough knowledge to identify them. In addition to this, rare diseases usually show a wide variety of manifestations, which might make the diagnosis even more difficult. A delayed diagnosis can negatively affect the patient's life. Therefore, there is an urgent need to increase the scientific and medical knowledge about rare diseases. Natural Language Processing (NLP) and Deep Learning can help to extract relevant information about rare diseases to facilitate their diagnosis and treatments. The paper explores the use of several deep learning techniques such as Bidirectional Long Short Term Memory (BiLSTM) networks or deep contextualized word representations based on Bidirectional Encoder Representations from Transformers (BERT) to recognize rare diseases and their clinical manifestations (signs and symptoms) in the RareDis corpus. This corpus contains more than 5,000 rare diseases and almost 6,000 clinical manifestations. BioBERT, a domain-specific language representation based on BERT and trained on biomedical corpora, obtains the best results. In particular, this model obtains an F1-score of 85.2% for rare diseases, outperforming all the other models.
Human readable network troubleshooting based on anomaly detection and feature scoring
Aug 26, 2021


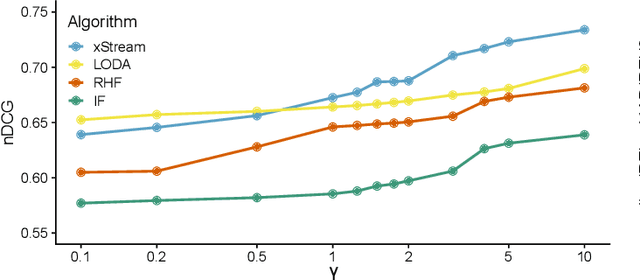
Network troubleshooting is still a heavily human-intensive process. To reduce the time spent by human operators in the diagnosis process, we present a system based on (i) unsupervised learning methods for detecting anomalies in the time domain, (ii) an attention mechanism to rank features in the feature space and finally (iii) an expert knowledge module able to seamlessly incorporate previously collected domain-knowledge. In this paper, we thoroughly evaluate the performance of the full system and of its individual building blocks: particularly, we consider (i) 10 anomaly detection algorithms as well as (ii) 10 attention mechanisms, that comprehensively represent the current state of the art in the respective fields. Leveraging a unique collection of expert-labeled datasets worth several months of real router telemetry data, we perform a thorough performance evaluation contrasting practical results in constrained stream-mode settings, with the results achievable by an ideal oracle in academic settings. Our experimental evaluation shows that (i) the proposed system is effective in achieving high levels of agreement with the expert, and (ii) that even a simple statistical approach is able to extract useful information from expert knowledge gained in past cases, significantly improving troubleshooting performance.
SMedBERT: A Knowledge-Enhanced Pre-trained Language Model with Structured Semantics for Medical Text Mining
Aug 20, 2021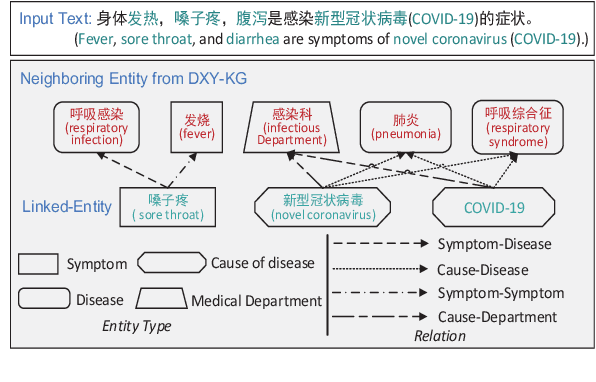
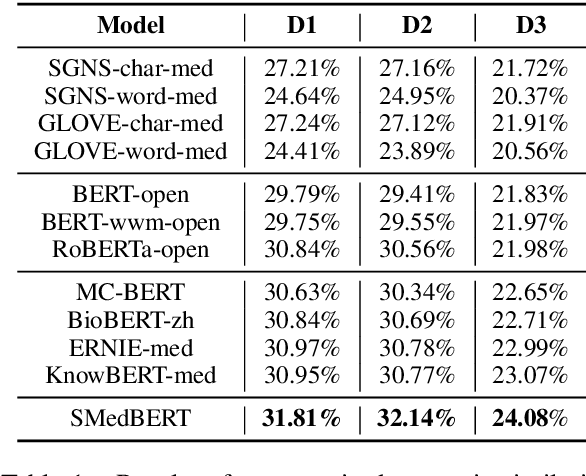
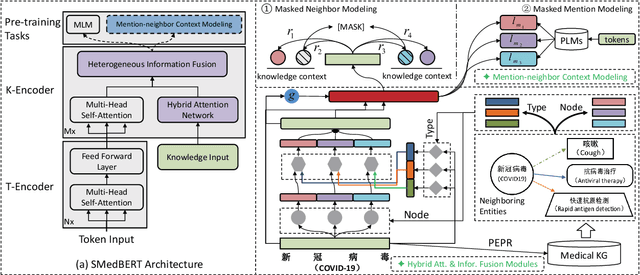
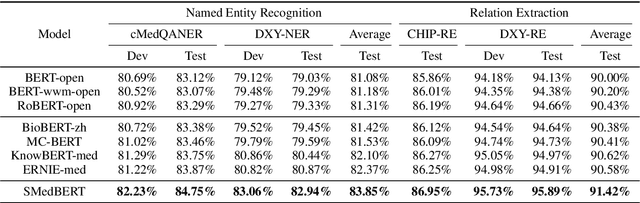
Recently, the performance of Pre-trained Language Models (PLMs) has been significantly improved by injecting knowledge facts to enhance their abilities of language understanding. For medical domains, the background knowledge sources are especially useful, due to the massive medical terms and their complicated relations are difficult to understand in text. In this work, we introduce SMedBERT, a medical PLM trained on large-scale medical corpora, incorporating deep structured semantic knowledge from neighbors of linked-entity.In SMedBERT, the mention-neighbor hybrid attention is proposed to learn heterogeneous-entity information, which infuses the semantic representations of entity types into the homogeneous neighboring entity structure. Apart from knowledge integration as external features, we propose to employ the neighbors of linked-entities in the knowledge graph as additional global contexts of text mentions, allowing them to communicate via shared neighbors, thus enrich their semantic representations. Experiments demonstrate that SMedBERT significantly outperforms strong baselines in various knowledge-intensive Chinese medical tasks. It also improves the performance of other tasks such as question answering, question matching and natural language inference.
Respiratory Rate Estimation Based on WiFi Frame Capture
Aug 05, 2021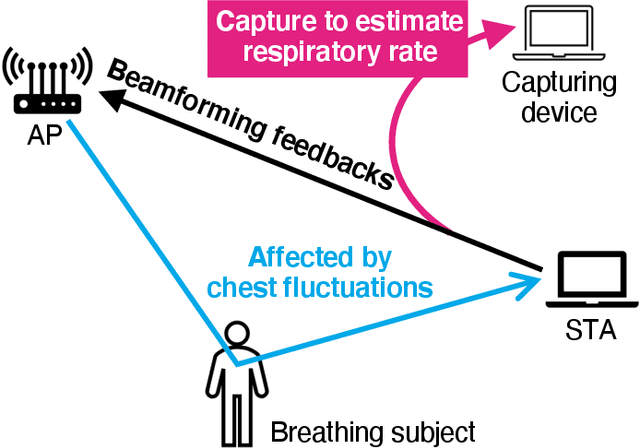
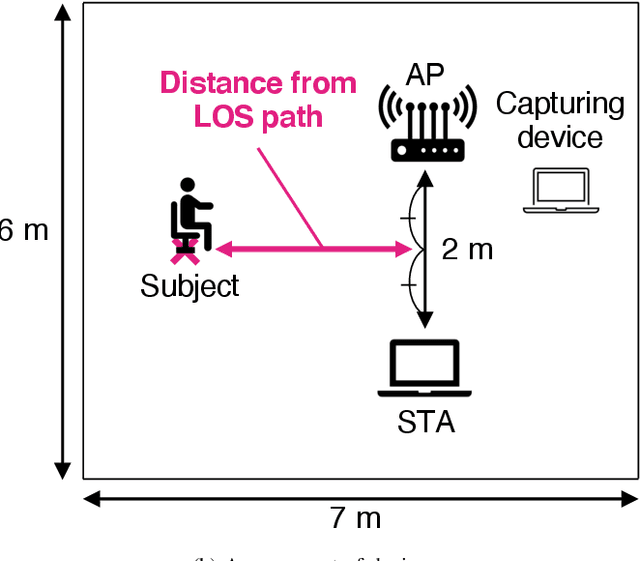
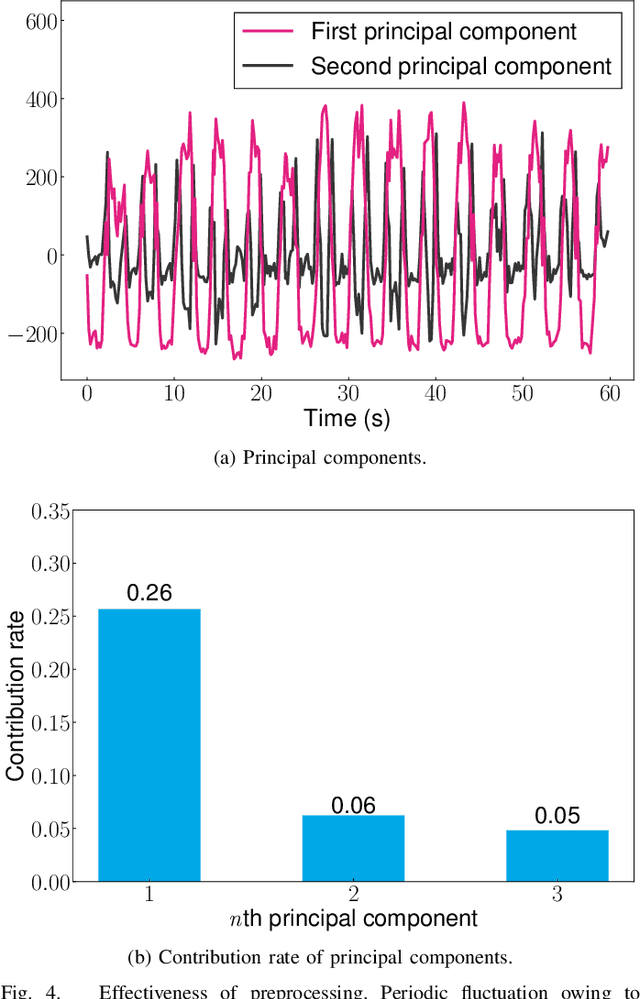
This paper presents a method that estimates the respiratory rate based on the frame capturing of wireless local area networks. The method uses beamforming feedback matrices (BFMs) contained in the captured frames, which is a rotation matrix of channel state information (CSI). BFMs are transmitted unencrypted and easily obtained using frame capturing, requiring no specific firmware or WiFi chipsets, unlike the methods that use CSI. Such properties of BFMs allow us to apply frame capturing to various sensing tasks, e.g., vital sensing. In the proposed method, principal component analysis is applied to BFMs to isolate the effect of the chest movement of the subject, and then, discrete Fourier transform is performed to extract respiratory rates in a frequency domain. Experimental evaluation results confirm that the frame-capture-based respiratory rate estimation can achieve estimation error lower than 3.2 breaths/minute.
DeepIC: Coding for Interference Channels via Deep Learning
Aug 13, 2021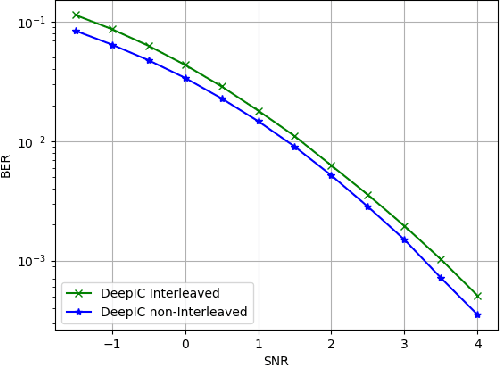
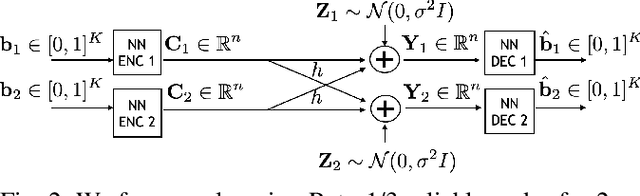
The two-user interference channel is a model for multi one-to-one communications, where two transmitters wish to communicate with their corresponding receivers via a shared wireless medium. Two most common and simple coding schemes are time division (TD) and treating interference as noise (TIN). Interestingly, it is shown that there exists an asymptotic scheme, called Han-Kobayashi scheme, that performs better than TD and TIN. However, Han-Kobayashi scheme has impractically high complexity and is designed for asymptotic settings, which leads to a gap between information theory and practice. In this paper, we focus on designing practical codes for interference channels. As it is challenging to analytically design practical codes with feasible complexity, we apply deep learning to learn codes for interference channels. We demonstrate that DeepIC, a convolutional neural network-based code with an iterative decoder, outperforms TD and TIN by a significant margin for two-user additive white Gaussian noise channels with moderate amount of interference.