 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Blackbox Attacks on Reinforcement Learning Agents Using Approximated Temporal Information
Sep 06, 2019
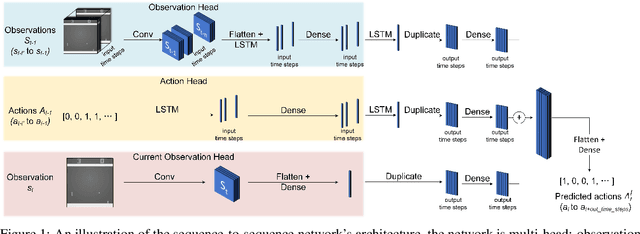


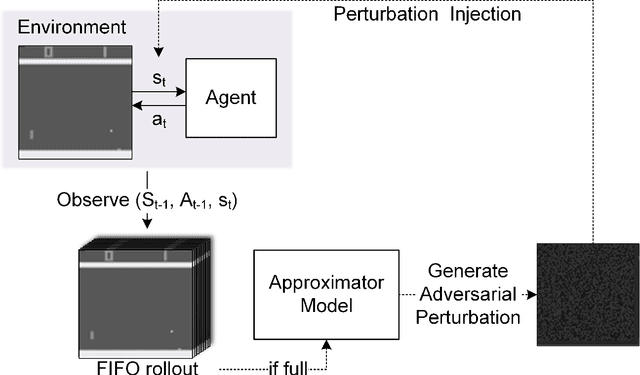
Recent research on reinforcement learning has shown that trained agents are vulnerable to maliciously crafted adversarial samples. In this work, we show how adversarial samples against RL agents can be generalised from White-box and Grey-box attacks to a strong Black-box case, namely where the attacker has no knowledge of the agents and their training methods. We use sequence-to-sequence models to predict a single action or a sequence of future actions that a trained agent will make. Our approximation model, based on time-series information from the agent, successfully predicts agents' future actions with consistently above 80% accuracy on a wide range of games and training methods. Second, we find that although such adversarial samples are transferable, they do not outperform random Gaussian noise as a means of reducing the game scores of trained RL agents. This highlights a serious methodological deficiency in previous work on such agents; random jamming should have been taken as the baseline for evaluation. Third, we do find a novel use for adversarial samples in this context: they can be used to trigger a trained agent to misbehave after a specific delay. This appears to be a genuinely new type of attack; it potentially enables an attacker to use devices controlled by RL agents as time bombs.
GLocal-K: Global and Local Kernels for Recommender Systems
Aug 27, 2021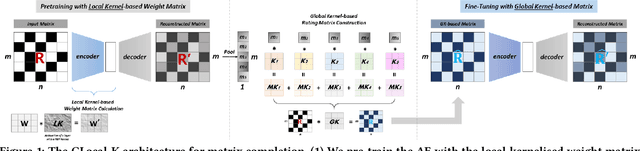
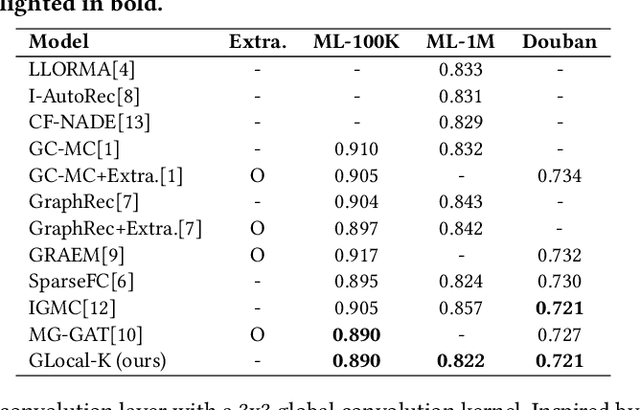
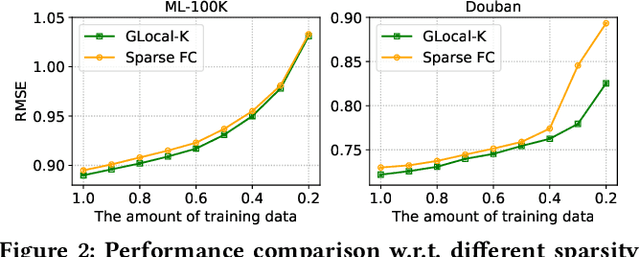
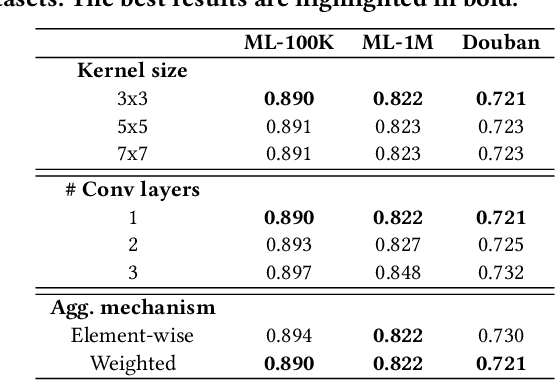
Recommender systems typically operate on high-dimensional sparse user-item matrices. Matrix completion is a very challenging task to predict one's interest based on millions of other users having each seen a small subset of thousands of items. We propose a Global-Local Kernel-based matrix completion framework, named GLocal-K, that aims to generalise and represent a high-dimensional sparse user-item matrix entry into a low dimensional space with a small number of important features. Our GLocal-K can be divided into two major stages. First, we pre-train an auto encoder with the local kernelised weight matrix, which transforms the data from one space into the feature space by using a 2d-RBF kernel. Then, the pre-trained auto encoder is fine-tuned with the rating matrix, produced by a convolution-based global kernel, which captures the characteristics of each item. We apply our GLocal-K model under the extreme low-resource setting, which includes only a user-item rating matrix, with no side information. Our model outperforms the state-of-the-art baselines on three collaborative filtering benchmarks: ML-100K, ML-1M, and Douban.
Detect and Classify -- Joint Span Detection and Classification for Health Outcomes
Apr 15, 2021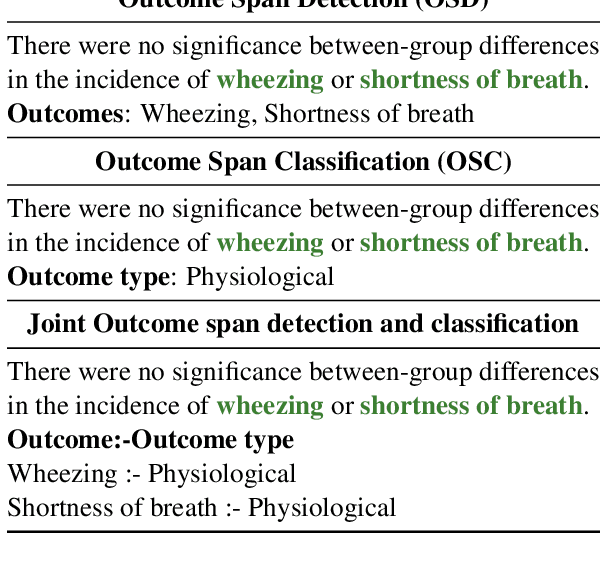
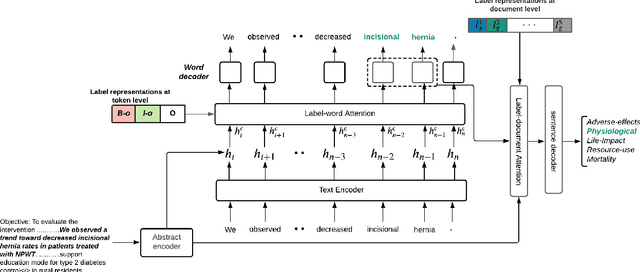
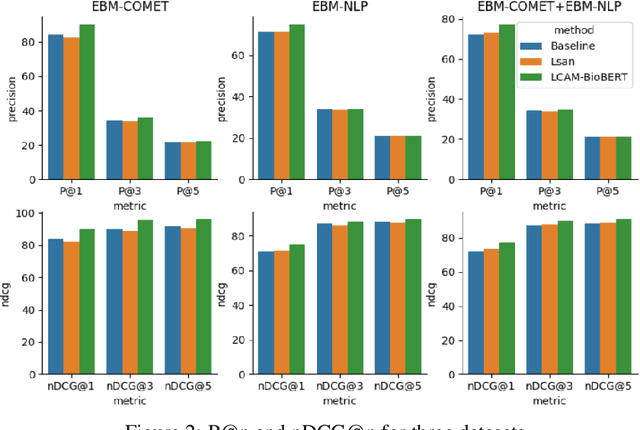
A health outcome is a measurement or an observation used to capture and assess the effect of a treatment. Automatic detection of health outcomes from text would undoubtedly speed up access to evidence necessary in healthcare decision making. Prior work on outcome detection has modelled this task as either (a) a sequence labelling task, where the goal is to detect which text spans describe health outcomes or (b) a classification task, where the goal is to classify a text into a pre-defined set of categories depending on an outcome that is mentioned somewhere in that text. However, this decoupling of span detection and classification is problematic from a modelling perspective and ignores global structural correspondences between sentence-level and word-level information present in a given text. We propose a method that uses both word-level and sentence-level information to simultaneously perform outcome span detection and outcome type classification. In addition to injecting contextual information to hidden vectors, we use label attention to appropriately weight both word-level and sentence-level information. Experimental results on several benchmark datasets for health outcome detection show that our model consistently outperforms decoupled methods, reporting competitive results.
Unsupervised Conversation Disentanglement through Co-Training
Sep 07, 2021
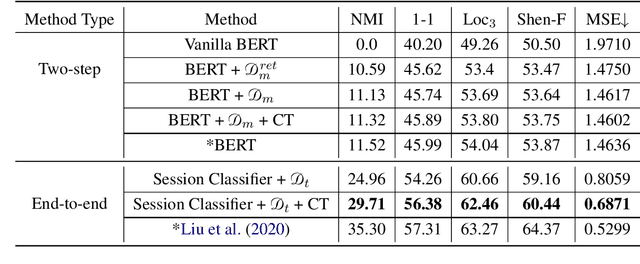
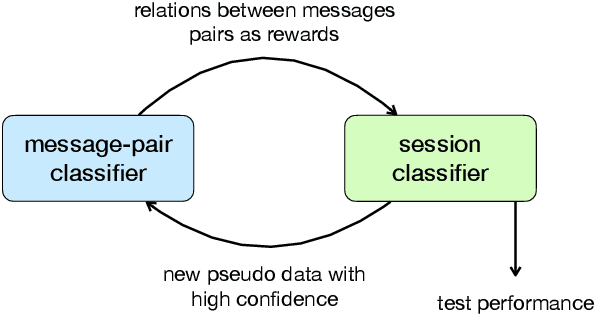
Conversation disentanglement aims to separate intermingled messages into detached sessions, which is a fundamental task in understanding multi-party conversations. Existing work on conversation disentanglement relies heavily upon human-annotated datasets, which are expensive to obtain in practice. In this work, we explore to train a conversation disentanglement model without referencing any human annotations. Our method is built upon a deep co-training algorithm, which consists of two neural networks: a message-pair classifier and a session classifier. The former is responsible for retrieving local relations between two messages while the latter categorizes a message to a session by capturing context-aware information. Both networks are initialized respectively with pseudo data built from an unannotated corpus. During the deep co-training process, we use the session classifier as a reinforcement learning component to learn a session assigning policy by maximizing the local rewards given by the message-pair classifier. For the message-pair classifier, we enrich its training data by retrieving message pairs with high confidence from the disentangled sessions predicted by the session classifier. Experimental results on the large Movie Dialogue Dataset demonstrate that our proposed approach achieves competitive performance compared to the previous supervised methods. Further experiments show that the predicted disentangled conversations can promote the performance on the downstream task of multi-party response selection.
The Evolution of Rumors on a Closed Platform during COVID-19
Apr 28, 2021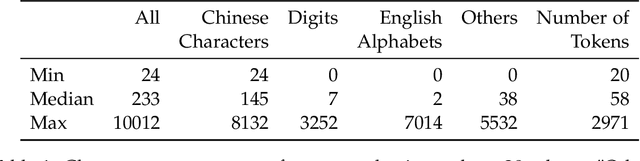
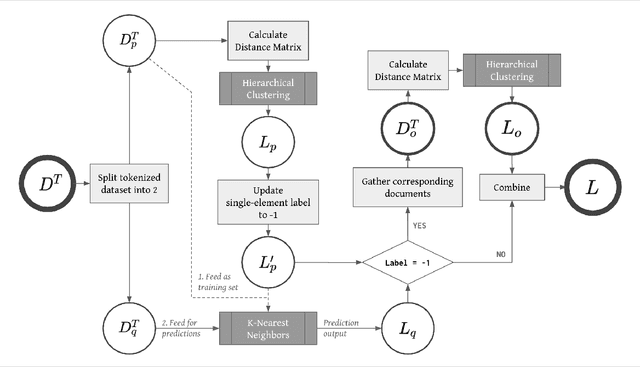
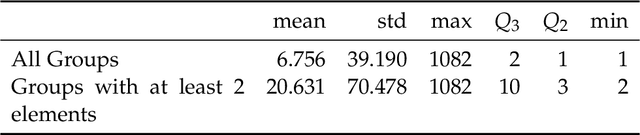
In this work we looked into a dataset of 114 thousands of suspicious messages collected from the most popular closed messaging platform in Taiwan between January and July, 2020. We proposed an hybrid algorithm that could efficiently cluster a large number of text messages according their topics and narratives. That is, we obtained groups of messages that are within a limited content alterations within each other. By employing the algorithm to the dataset, we were able to look at the content alterations and the temporal dynamics of each particular rumor over time. With qualitative case studies of three COVID-19 related rumors, we have found that key authoritative figures were often misquoted in false information. It was an effective measure to increase the popularity of one false information. In addition, fact-check was not effective in stopping misinformation from getting attention. In fact, the popularity of one false information was often more influenced by major societal events and effective content alterations.
Dealing with Typos for BERT-based Passage Retrieval and Ranking
Aug 27, 2021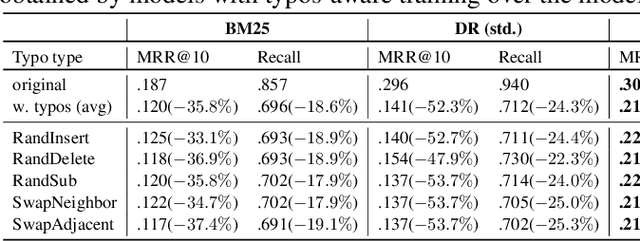
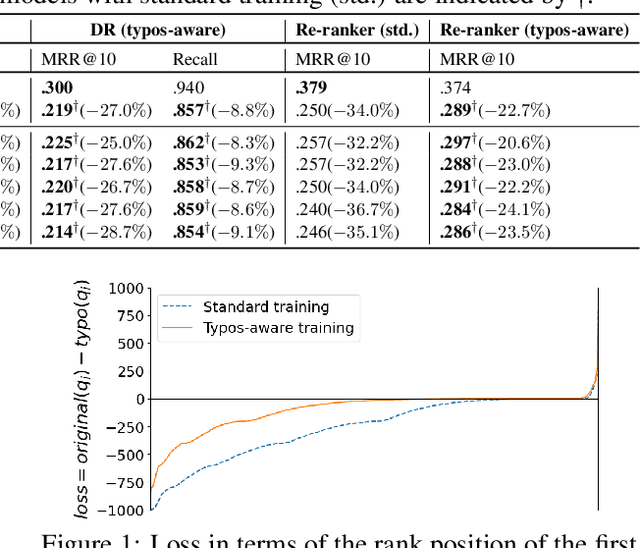
Passage retrieval and ranking is a key task in open-domain question answering and information retrieval. Current effective approaches mostly rely on pre-trained deep language model-based retrievers and rankers. These methods have been shown to effectively model the semantic matching between queries and passages, also in presence of keyword mismatch, i.e. passages that are relevant to a query but do not contain important query tokens. In this paper we consider the Dense Retriever (DR), a passage retrieval method, and the BERT re-ranker, a popular passage re-ranking method. In this context, we formally investigate how these models respond and adapt to a specific type of keyword mismatch -- that caused by keyword typos occurring in queries. Through empirical investigation, we find that typos can lead to a significant drop in retrieval and ranking effectiveness. We then propose a simple typos-aware training framework for DR and BERT re-ranker to address this issue. Our experimental results on the MS MARCO passage ranking dataset show that, with our proposed typos-aware training, DR and BERT re-ranker can become robust to typos in queries, resulting in significantly improved effectiveness compared to models trained without appropriately accounting for typos.
Logician: A Unified End-to-End Neural Approach for Open-Domain Information Extraction
Apr 29, 2019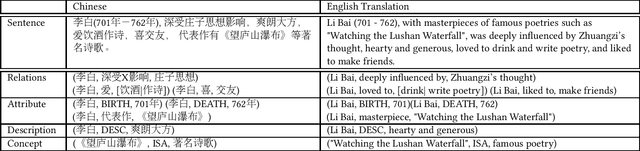
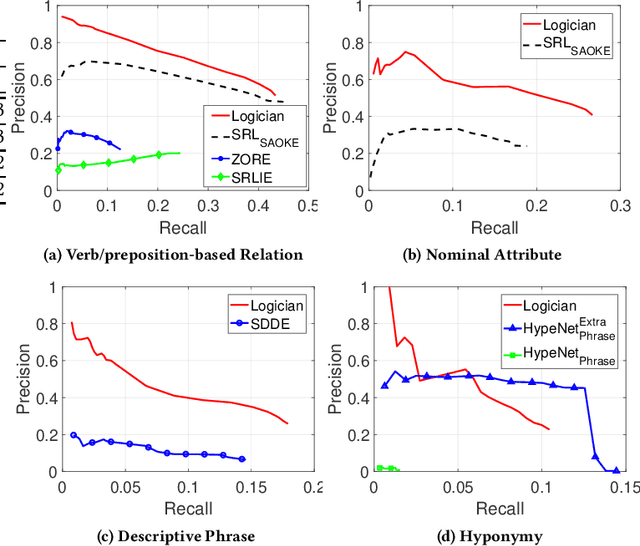
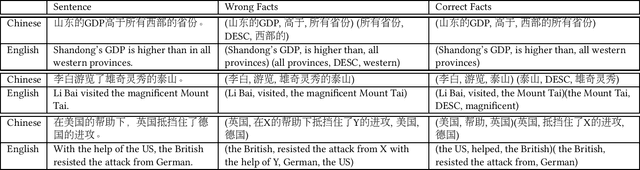

In this paper, we consider the problem of open information extraction (OIE) for extracting entity and relation level intermediate structures from sentences in open-domain. We focus on four types of valuable intermediate structures (Relation, Attribute, Description, and Concept), and propose a unified knowledge expression form, SAOKE, to express them. We publicly release a data set which contains more than forty thousand sentences and the corresponding facts in the SAOKE format labeled by crowd-sourcing. To our knowledge, this is the largest publicly available human labeled data set for open information extraction tasks. Using this labeled SAOKE data set, we train an end-to-end neural model using the sequenceto-sequence paradigm, called Logician, to transform sentences into facts. For each sentence, different to existing algorithms which generally focus on extracting each single fact without concerning other possible facts, Logician performs a global optimization over all possible involved facts, in which facts not only compete with each other to attract the attention of words, but also cooperate to share words. An experimental study on various types of open domain relation extraction tasks reveals the consistent superiority of Logician to other states-of-the-art algorithms. The experiments verify the reasonableness of SAOKE format, the valuableness of SAOKE data set, the effectiveness of the proposed Logician model, and the feasibility of the methodology to apply end-to-end learning paradigm on supervised data sets for the challenging tasks of open information extraction.
PyPhi: A toolbox for integrated information theory
Jun 27, 2018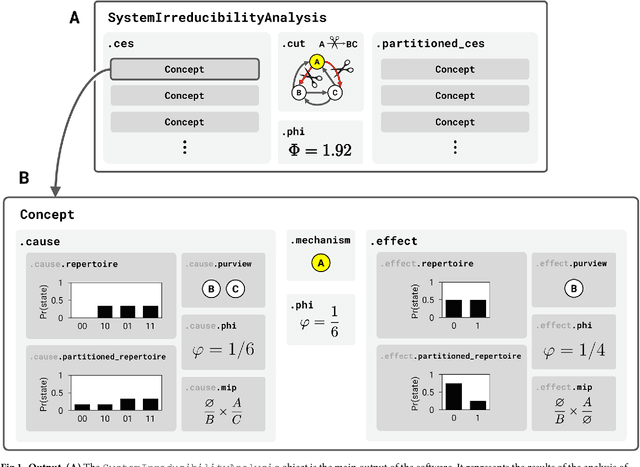

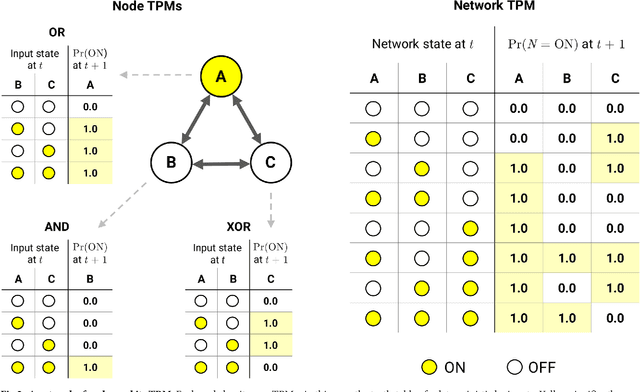
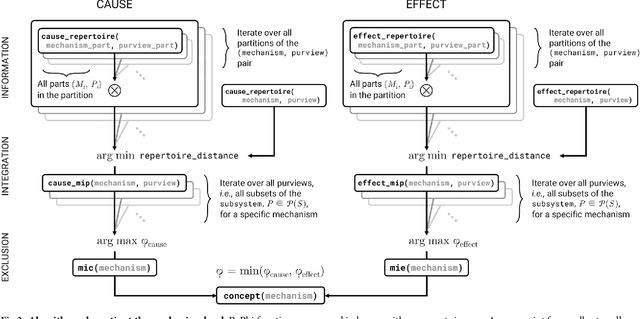
Integrated information theory provides a mathematical framework to fully characterize the cause-effect structure of a physical system. Here, we introduce PyPhi, a Python software package that implements this framework for causal analysis and unfolds the full cause-effect structure of discrete dynamical systems of binary elements. The software allows users to easily study these structures, serves as an up-to-date reference implementation of the formalisms of integrated information theory, and has been applied in research on complexity, emergence, and certain biological questions. We first provide an overview of the main algorithm and demonstrate PyPhi's functionality in the course of analyzing an example system, and then describe details of the algorithm's design and implementation. PyPhi can be installed with Python's package manager via the command 'pip install pyphi' on Linux and macOS systems equipped with Python 3.4 or higher. PyPhi is open-source and licensed under the GPLv3; the source code is hosted on GitHub at https://github.com/wmayner/pyphi . Comprehensive and continually-updated documentation is available at https://pyphi.readthedocs.io/ . The pyphi-users mailing list can be joined at https://groups.google.com/forum/#!forum/pyphi-users . A web-based graphical interface to the software is available at http://integratedinformationtheory.org/calculate.html .
* 22 pages, 4 figures, 6 pages of appendices. Supporting information "S1 Calculating Phi" can be found in the ancillary files
Unsupervised Image-to-Image Translation Using Domain-Specific Variational Information Bound
Nov 29, 2018
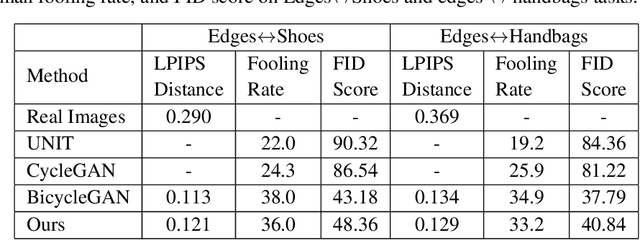
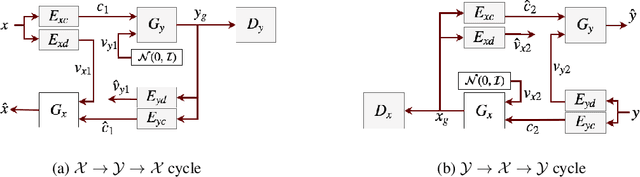
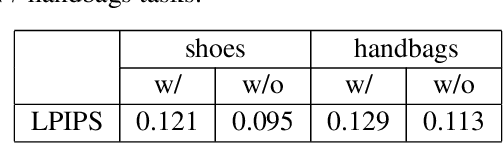
Unsupervised image-to-image translation is a class of computer vision problems which aims at modeling conditional distribution of images in the target domain, given a set of unpaired images in the source and target domains. An image in the source domain might have multiple representations in the target domain. Therefore, ambiguity in modeling of the conditional distribution arises, specially when the images in the source and target domains come from different modalities. Current approaches mostly rely on simplifying assumptions to map both domains into a shared-latent space. Consequently, they are only able to model the domain-invariant information between the two modalities. These approaches usually fail to model domain-specific information which has no representation in the target domain. In this work, we propose an unsupervised image-to-image translation framework which maximizes a domain-specific variational information bound and learns the target domain-invariant representation of the two domain. The proposed framework makes it possible to map a single source image into multiple images in the target domain, utilizing several target domain-specific codes sampled randomly from the prior distribution, or extracted from reference images.
Enriching Source Style Transfer in Recognition-Synthesis based Non-Parallel Voice Conversion
Jun 26, 2021
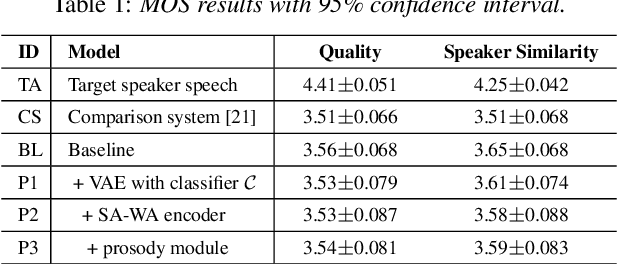
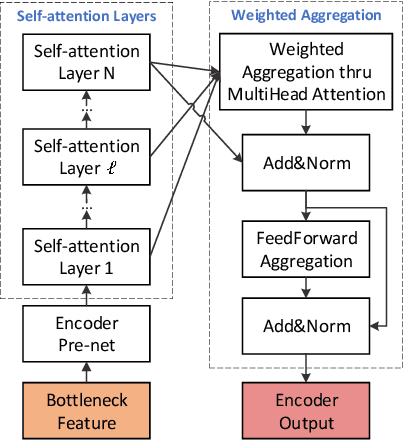
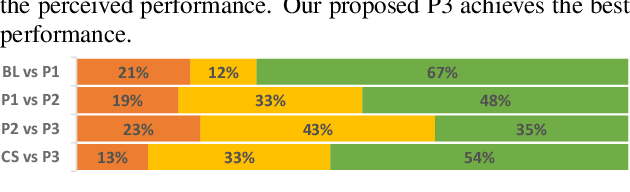
Current voice conversion (VC) methods can successfully convert timbre of the audio. As modeling source audio's prosody effectively is a challenging task, there are still limitations of transferring source style to the converted speech. This study proposes a source style transfer method based on recognition-synthesis framework. Previously in speech generation task, prosody can be modeled explicitly with prosodic features or implicitly with a latent prosody extractor. In this paper, taking advantages of both, we model the prosody in a hybrid manner, which effectively combines explicit and implicit methods in a proposed prosody module. Specifically, prosodic features are used to explicit model prosody, while VAE and reference encoder are used to implicitly model prosody, which take Mel spectrum and bottleneck feature as input respectively. Furthermore, adversarial training is introduced to remove speaker-related information from the VAE outputs, avoiding leaking source speaker information while transferring style. Finally, we use a modified self-attention based encoder to extract sentential context from bottleneck features, which also implicitly aggregates the prosodic aspects of source speech from the layered representations. Experiments show that our approach is superior to the baseline and a competitive system in terms of style transfer; meanwhile, the speech quality and speaker similarity are well maintained.