 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Faces in the Wild: Efficient Gender Recognition in Surveillance Conditions
Jul 14, 2021
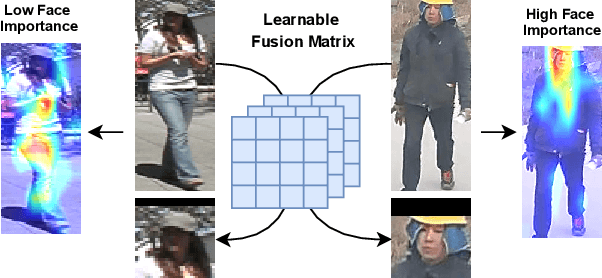
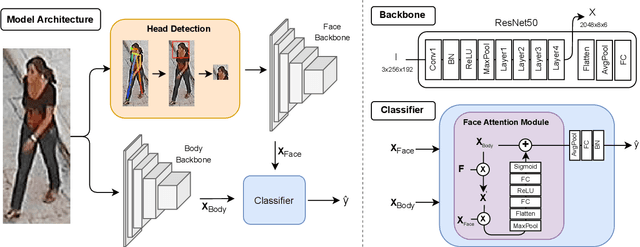


Soft biometrics inference in surveillance scenarios is a topic of interest for various applications, particularly in security-related areas. However, soft biometric analysis is not extensively reported in wild conditions. In particular, previous works on gender recognition report their results in face datasets, with relatively good image quality and frontal poses. Given the uncertainty of the availability of the facial region in wild conditions, we consider that these methods are not adequate for surveillance settings. To overcome these limitations, we: 1) present frontal and wild face versions of three well-known surveillance datasets; and 2) propose a model that effectively and dynamically combines facial and body information, which makes it suitable for gender recognition in wild conditions. The frontal and wild face datasets derive from widely used Pedestrian Attribute Recognition (PAR) sets (PETA, PA-100K, and RAP), using a pose-based approach to filter the frontal samples and facial regions. This approach retrieves the facial region of images with varying image/subject conditions, where the state-of-the-art face detectors often fail. Our model combines facial and body information through a learnable fusion matrix and a channel-attention sub-network, focusing on the most influential body parts according to the specific image/subject features. We compare it with five PAR methods, consistently obtaining state-of-the-art results on gender recognition, and reducing the prediction errors by up to 24% in frontal samples. The announced PAR datasets versions and model serve as the basis for wild soft biometrics classification and are available in https://github.com/Tiago-Roxo.
Computational Imaging and Artificial Intelligence: The Next Revolution of Mobile Vision
Sep 18, 2021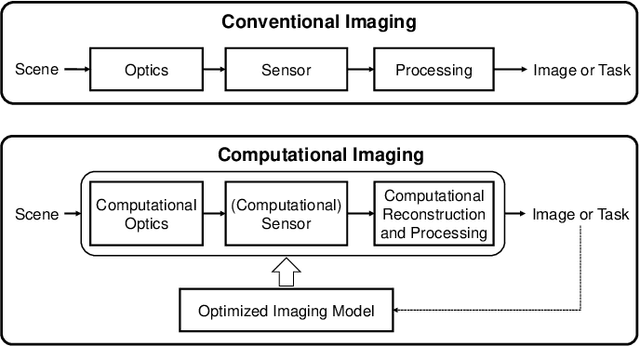

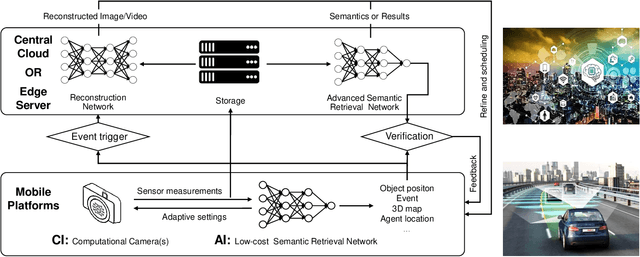

Signal capture stands in the forefront to perceive and understand the environment and thus imaging plays the pivotal role in mobile vision. Recent explosive progresses in Artificial Intelligence (AI) have shown great potential to develop advanced mobile platforms with new imaging devices. Traditional imaging systems based on the "capturing images first and processing afterwards" mechanism cannot meet this unprecedented demand. Differently, Computational Imaging (CI) systems are designed to capture high-dimensional data in an encoded manner to provide more information for mobile vision systems.Thanks to AI, CI can now be used in real systems by integrating deep learning algorithms into the mobile vision platform to achieve the closed loop of intelligent acquisition, processing and decision making, thus leading to the next revolution of mobile vision.Starting from the history of mobile vision using digital cameras, this work first introduces the advances of CI in diverse applications and then conducts a comprehensive review of current research topics combining CI and AI. Motivated by the fact that most existing studies only loosely connect CI and AI (usually using AI to improve the performance of CI and only limited works have deeply connected them), in this work, we propose a framework to deeply integrate CI and AI by using the example of self-driving vehicles with high-speed communication, edge computing and traffic planning. Finally, we outlook the future of CI plus AI by investigating new materials, brain science and new computing techniques to shed light on new directions of mobile vision systems.
The Atlas of Lane Changes: Investigating Location-dependent Lane Change Behaviors Using Measurement Data from a Customer Fleet
Jul 09, 2021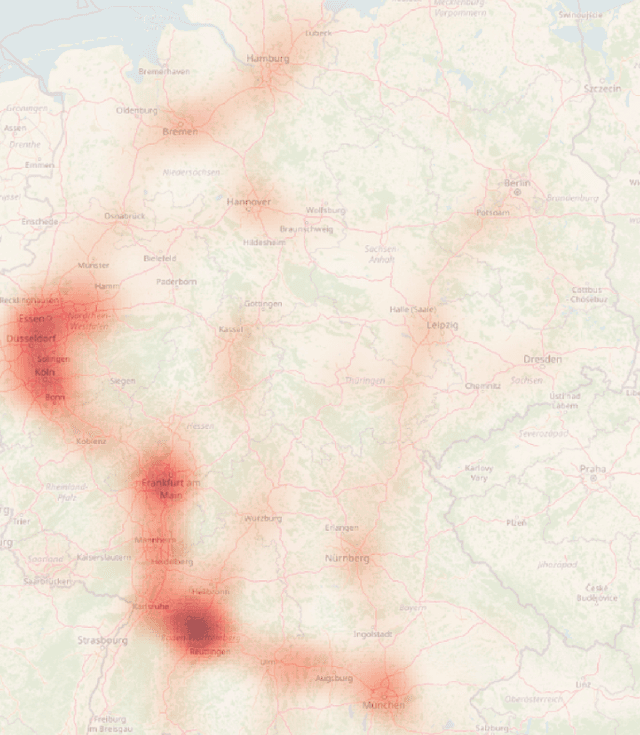
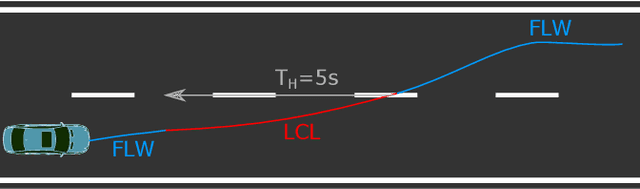
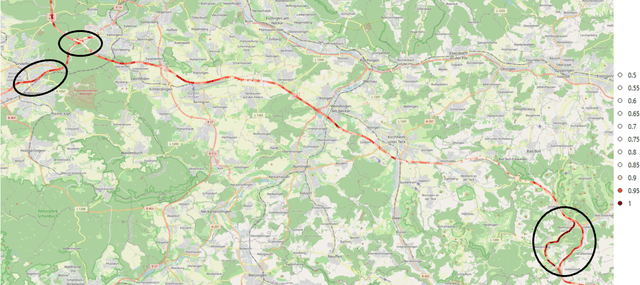
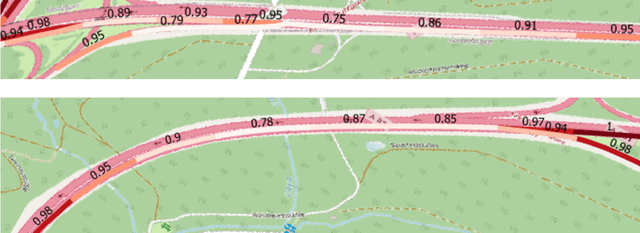
The prediction of surrounding traffic participants behavior is a crucial and challenging task for driver assistance and autonomous driving systems. Today's approaches mainly focus on modeling dynamic aspects of the traffic situation and try to predict traffic participants behavior based on this. In this article we take a first step towards extending this common practice by calculating location-specific a-priori lane change probabilities. The idea behind this is straight forward: The driving behavior of humans may vary in exactly the same traffic situation depending on the respective location. E.g. drivers may ask themselves: Should I pass the truck in front of me immediately or should I wait until reaching the less curvy part of my route lying only a few kilometers ahead? Although, such information is far away from allowing behavior prediction on its own, it is obvious that today's approaches will greatly benefit when incorporating such location-specific a-priori probabilities into their predictions. For example, our investigations show that highway interchanges tend to enhance driver's motivation to perform lane changes, whereas curves seem to have lane change-dampening effects. Nevertheless, the investigation of all considered local conditions shows that superposition of various effects can lead to unexpected probabilities at some locations. We thus suggest dynamically constructing and maintaining a lane change probability map based on customer fleet data in order to support onboard prediction systems with additional information. For deriving reliable lane change probabilities a broad customer fleet is the key to success.
Information Directed Sampling and Bandits with Heteroscedastic Noise
Apr 19, 2018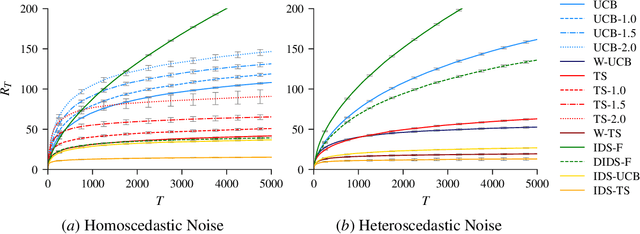
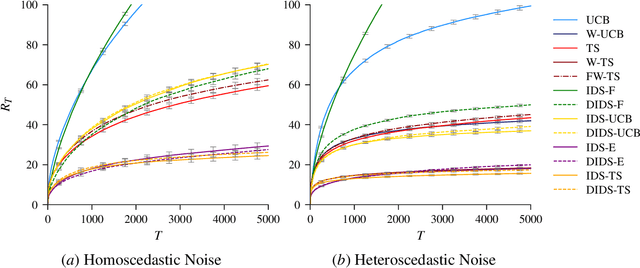
In the stochastic bandit problem, the goal is to maximize an unknown function via a sequence of noisy evaluations. Typically, the observation noise is assumed to be independent of the evaluation point and to satisfy a tail bound uniformly on the domain; a restrictive assumption for many applications. In this work, we consider bandits with heteroscedastic noise, where we explicitly allow the noise distribution to depend on the evaluation point. We show that this leads to new trade-offs for information and regret, which are not taken into account by existing approaches like upper confidence bound algorithms (UCB) or Thompson Sampling. To address these shortcomings, we introduce a frequentist regret analysis framework, that is similar to the Bayesian framework of Russo and Van Roy (2014), and we prove a new high-probability regret bound for general, possibly randomized policies, which depends on a quantity we refer to as regret-information ratio. From this bound, we define a frequentist version of Information Directed Sampling (IDS) to minimize the regret-information ratio over all possible action sampling distributions. This further relies on concentration inequalities for online least squares regression in separable Hilbert spaces, which we generalize to the case of heteroscedastic noise. We then formulate several variants of IDS for linear and reproducing kernel Hilbert space response functions, yielding novel algorithms for Bayesian optimization. We also prove frequentist regret bounds, which in the homoscedastic case recover known bounds for UCB, but can be much better when the noise is heteroscedastic. Empirically, we demonstrate in a linear setting with heteroscedastic noise, that some of our methods can outperform UCB and Thompson Sampling, while staying competitive when the noise is homoscedastic.
A Unified Efficient Pyramid Transformer for Semantic Segmentation
Jul 29, 2021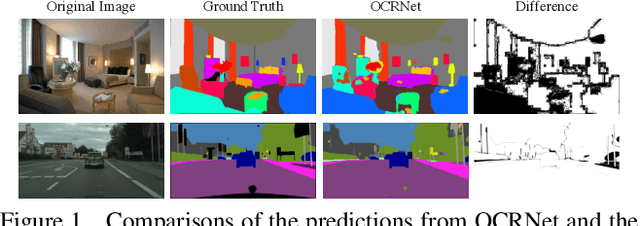
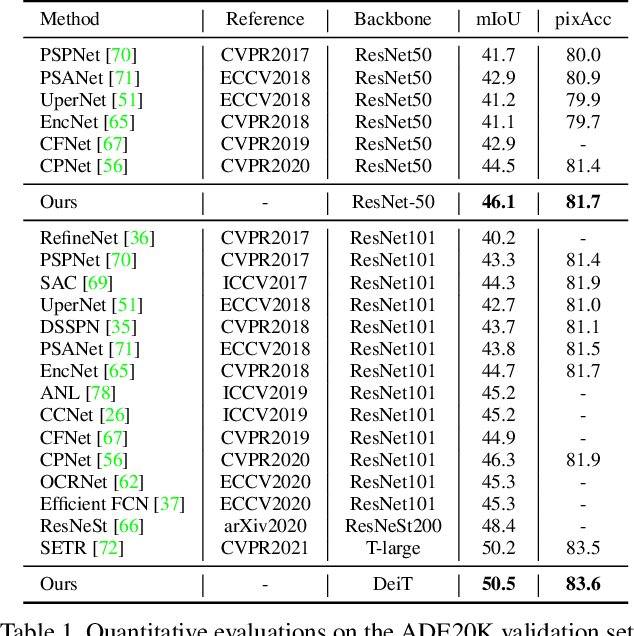
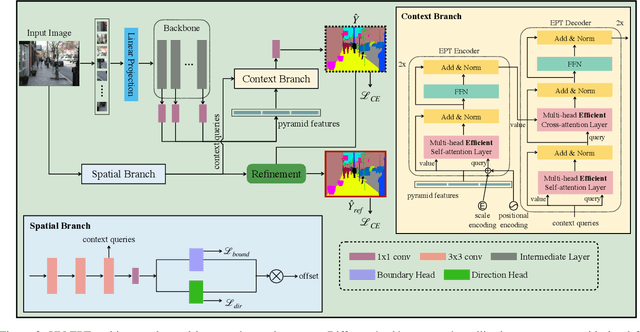
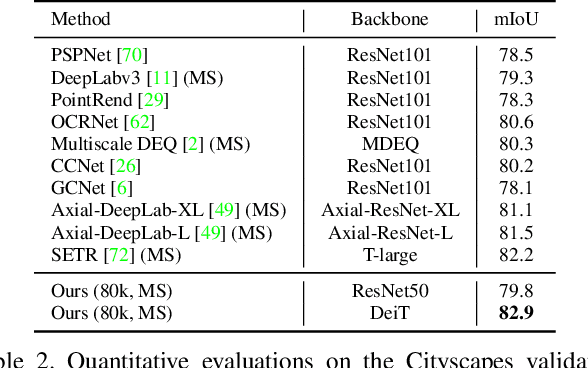
Semantic segmentation is a challenging problem due to difficulties in modeling context in complex scenes and class confusions along boundaries. Most literature either focuses on context modeling or boundary refinement, which is less generalizable in open-world scenarios. In this work, we advocate a unified framework(UN-EPT) to segment objects by considering both context information and boundary artifacts. We first adapt a sparse sampling strategy to incorporate the transformer-based attention mechanism for efficient context modeling. In addition, a separate spatial branch is introduced to capture image details for boundary refinement. The whole model can be trained in an end-to-end manner. We demonstrate promising performance on three popular benchmarks for semantic segmentation with low memory footprint. Code will be released soon.
How is Time Frequency Space Modulation Related to Short Time Fourier Signaling?
Sep 13, 2021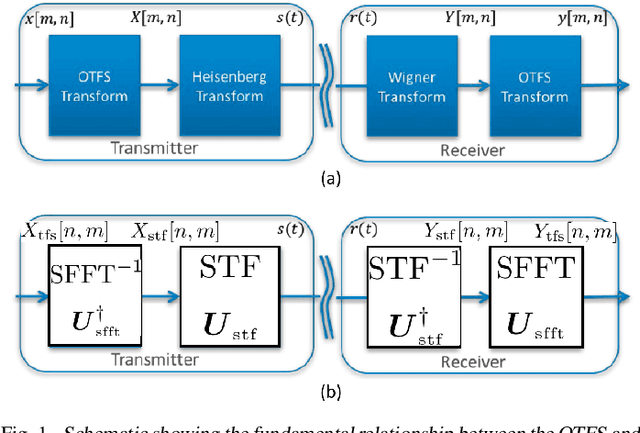
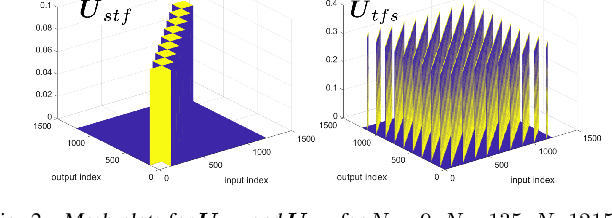
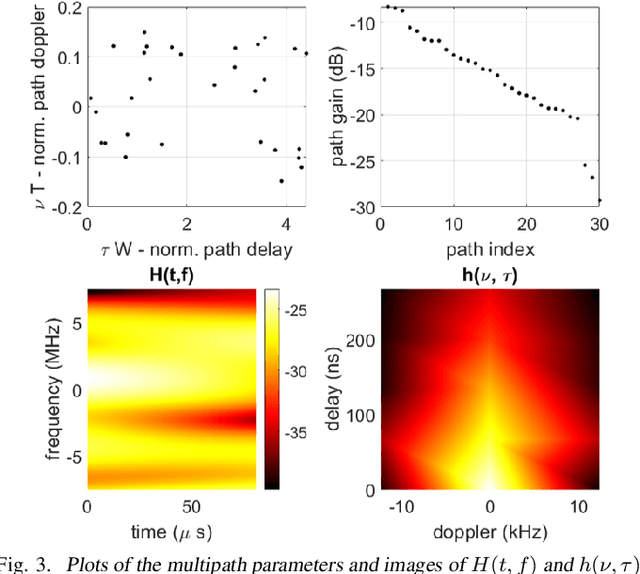
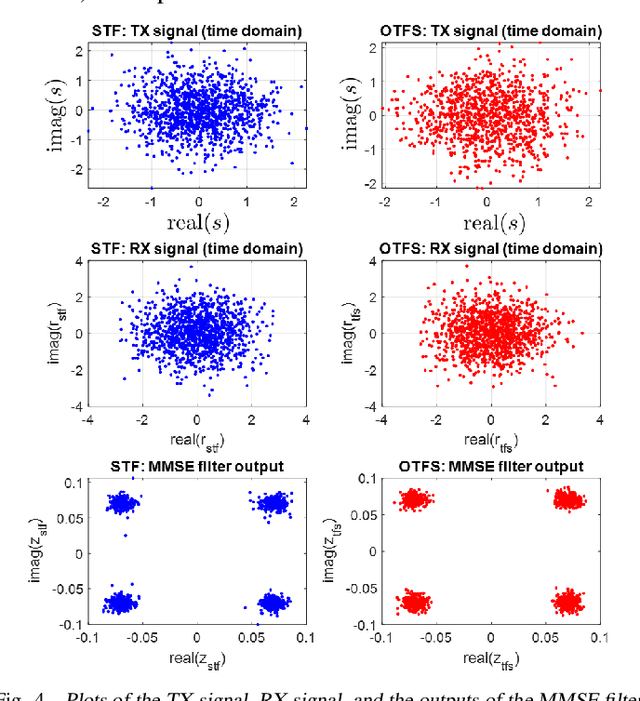
We investigate the relationship between Orthogonal Time Frequency Space (OTFS) modulation and Orthogonal Short Time Fourier (OSTF) signaling. OTFS was recently proposed as a new scheme for high Doppler scenarios and builds on OSTF. We first show that the two schemes are unitarily equivalent in the digital domain. However, OSTF defines the analog-digital interface with the waveform domain. We then develop a critically sampled matrix-vector model for the two systems and consider linear minimum mean-squared error (MMSE) filtering at the receiver to suppress inter-symbol interference. Initial comparison of capacity and (uncoded) probability of error reveals a surprising observation: OTFS under-performs OSTF in capacity but over-performs in probability of error. This result can be attributed to characteristics of the channel matrices induced by the two systems. In particular, the diagonal entries of OTFS matrix exhibit nearly identical magnitude, whereas those of the OSTF matrix exhibit wild fluctuations induced by multipath randomness. It is observed that by simply replacing the unitary matrix, relating OTFS to OSTF, by an arbitrary unitary matrix results in performance nearly identical to OTFS. We then extend our analysis to orthogonal frequency division multiplexing (OFDM) and also consider a more extreme scenario of relatively large delay and Doppler spreads. Our results demonstrate the significance of using OSTF basis waveforms rather than sinusoidal ones in OFDM in highly dynamic environments, and also highlight the impact of the level of channel state information used at the receiver.
LightMove: A Lightweight Next-POI Recommendation for Taxicab Rooftop Advertising
Aug 11, 2021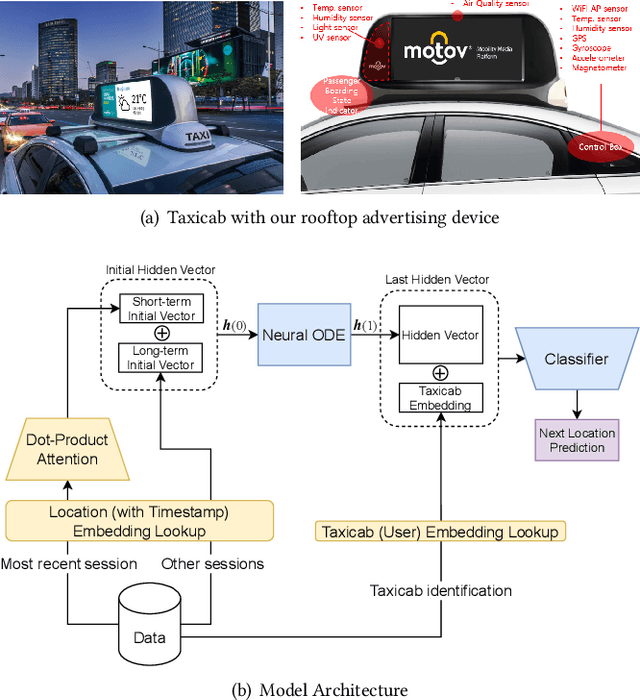

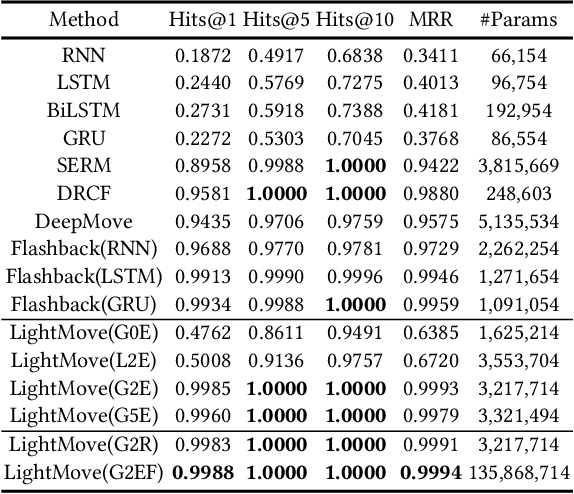
Mobile digital billboards are an effective way to augment brand-awareness. Among various such mobile billboards, taxicab rooftop devices are emerging in the market as a brand new media. Motov is a leading company in South Korea in the taxicab rooftop advertising market. In this work, we present a lightweight yet accurate deep learning-based method to predict taxicabs' next locations to better prepare for targeted advertising based on demographic information of locations. Considering the fact that next POI recommendation datasets are frequently sparse, we design our presented model based on neural ordinary differential equations (NODEs), which are known to be robust to sparse/incorrect input, with several enhancements. Our model, which we call LightMove, has a larger prediction accuracy, a smaller number of parameters, and/or a smaller training/inference time, when evaluating with various datasets, in comparison with state-of-the-art models.
A Systematic Investigation of KB-Text Embedding Alignment at Scale
Jun 03, 2021
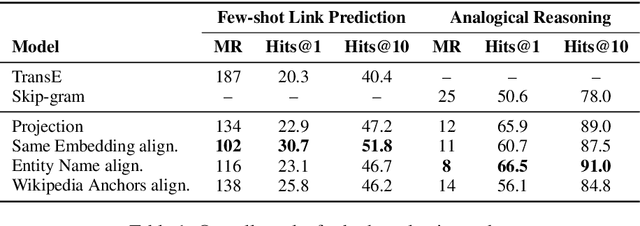
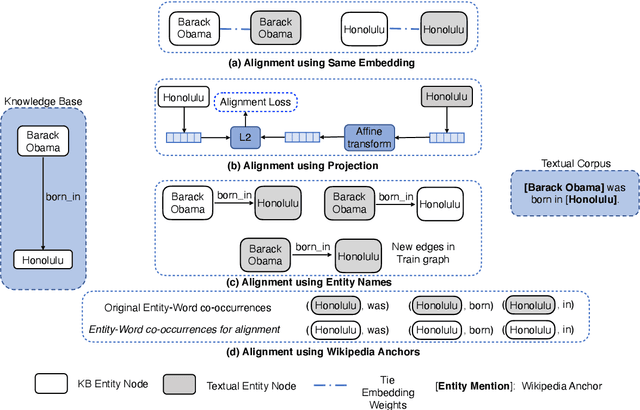
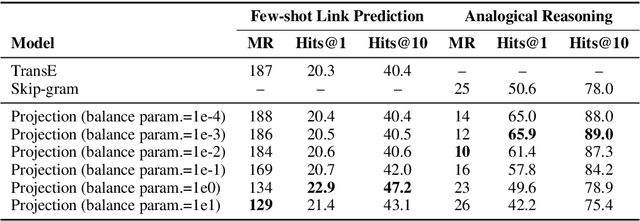
Knowledge bases (KBs) and text often contain complementary knowledge: KBs store structured knowledge that can support long range reasoning, while text stores more comprehensive and timely knowledge in an unstructured way. Separately embedding the individual knowledge sources into vector spaces has demonstrated tremendous successes in encoding the respective knowledge, but how to jointly embed and reason with both knowledge sources to fully leverage the complementary information is still largely an open problem. We conduct a large-scale, systematic investigation of aligning KB and text embeddings for joint reasoning. We set up a novel evaluation framework with two evaluation tasks, few-shot link prediction and analogical reasoning, and evaluate an array of KB-text embedding alignment methods. We also demonstrate how such alignment can infuse textual information into KB embeddings for more accurate link prediction on emerging entities and events, using COVID-19 as a case study.
iPool -- Information-based Pooling in Hierarchical Graph Neural Networks
Jul 01, 2019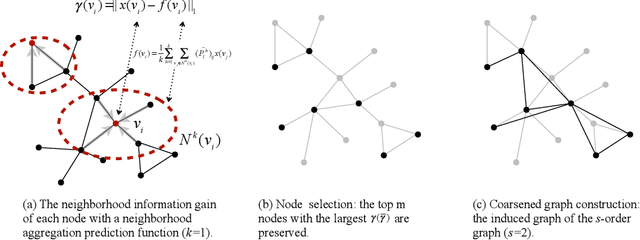
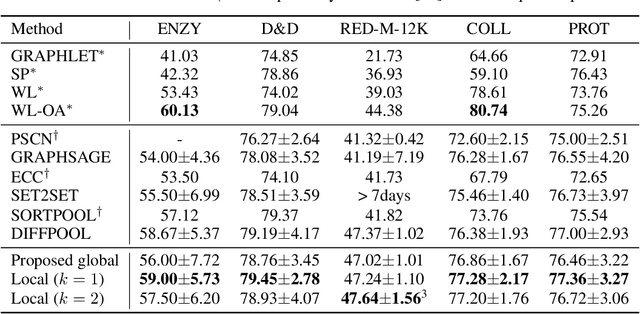

With the advent of data science, the analysis of network or graph data has become a very timely research problem. A variety of recent works have been proposed to generalize neural networks to graphs, either from a spectral graph theory or a spatial perspective. The majority of these works however focus on adapting the convolution operator to graph representation. At the same time, the pooling operator also plays an important role in distilling multiscale and hierarchical representations but it has been mostly overlooked so far. In this paper, we propose a parameter-free pooling operator, called iPool, that permits to retain the most informative features in arbitrary graphs. With the argument that informative nodes dominantly characterize graph signals, we propose a criterion to evaluate the amount of information of each node given its neighbors, and theoretically demonstrate its relationship to neighborhood conditional entropy. This new criterion determines how nodes are selected and coarsened graphs are constructed in the pooling layer. The resulting hierarchical structure yields an effective isomorphism-invariant representation of networked data in arbitrary topologies. The proposed strategy is evaluated in terms of graph classification on a collection of public graph datasets, including bioinformatics and social networks, and achieves state-of-the-art performance on most of the datasets.
Unpaired Adversarial Learning for Single Image Deraining with Rain-Space Contrastive Constraints
Sep 08, 2021
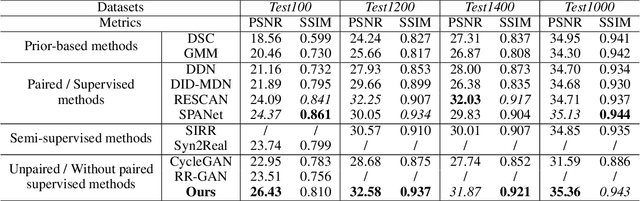
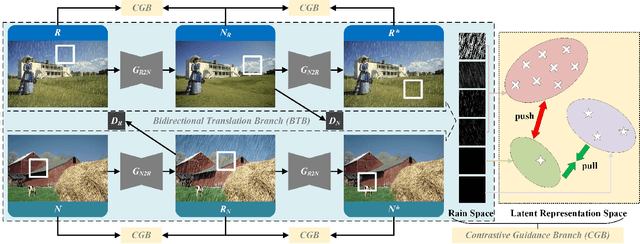
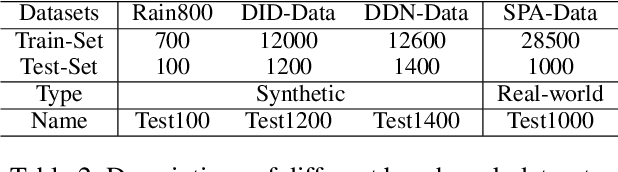
Deep learning-based single image deraining (SID) with unpaired information is of immense importance, as relying on paired synthetic data often limits their generality and scalability in real-world applications. However, we noticed that direct employ of unpaired adversarial learning and cycle-consistency constraints in the SID task is insufficient to learn the underlying relationship from rainy input to clean outputs, since the domain knowledge between rainy and rain-free images is asymmetrical. To address such limitation, we develop an effective unpaired SID method which explores mutual properties of the unpaired exemplars by a contrastive learning manner in a GAN framework, named as CDR-GAN. The proposed method mainly consists of two cooperative branches: Bidirectional Translation Branch (BTB) and Contrastive Guidance Branch (CGB). Specifically, BTB takes full advantage of the circulatory architecture of adversarial consistency to exploit latent feature distributions and guide transfer ability between two domains by equipping it with bidirectional mapping. Simultaneously, CGB implicitly constrains the embeddings of different exemplars in rain space by encouraging the similar feature distributions closer while pushing the dissimilar further away, in order to better help rain removal and image restoration. During training, we explore several loss functions to further constrain the proposed CDR-GAN. Extensive experiments show that our method performs favorably against existing unpaired deraining approaches on both synthetic and real-world datasets, even outperforms several fully-supervised or semi-supervised models.