 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MICE: A Crosslinguistic Emotion Corpus in Malay, Indonesian, Chinese and English
Jun 09, 2021
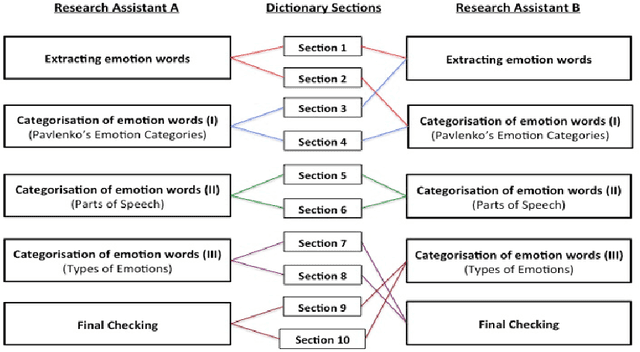

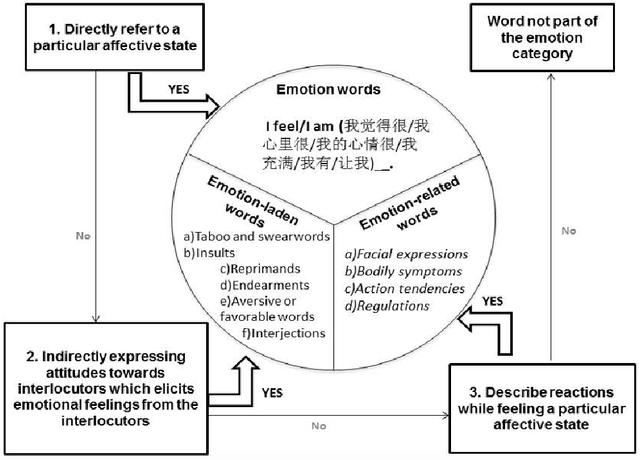
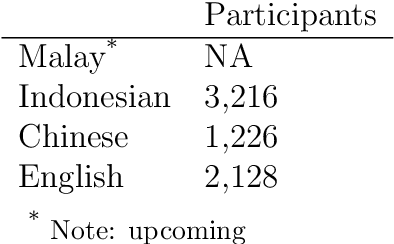
MICE is a corpus of emotion words in four languages which is currently working progress. There are two sections to this study, Part I: Emotion word corpus and Part II: Emotion word survey. In Part 1, the method of how the emotion data is culled for each of the four languages will be described and very preliminary data will be presented. In total, we identified 3,750 emotion expressions in Malay, 6,657 in Indonesian, 3,347 in Mandarin Chinese and 8,683 in English. We are currently evaluating and double checking the corpus and doing further analysis on the distribution of these emotion expressions. Part II Emotion word survey involved an online language survey which collected information on how speakers assigned the emotion words into basic emotion categories, the rating for valence and intensity as well as biographical information of all the respondents.
RCNet: Incorporating Structural Information into Deep RNN for MIMO-OFDM Symbol Detection with Limited Training
Mar 15, 2020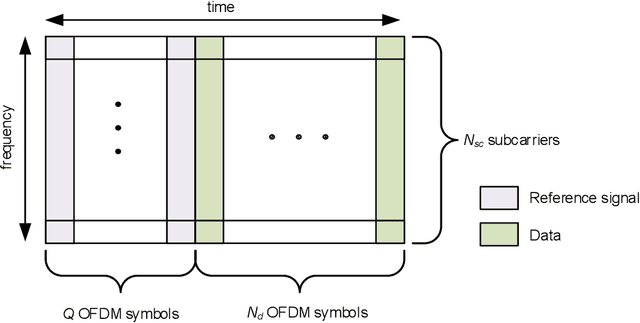
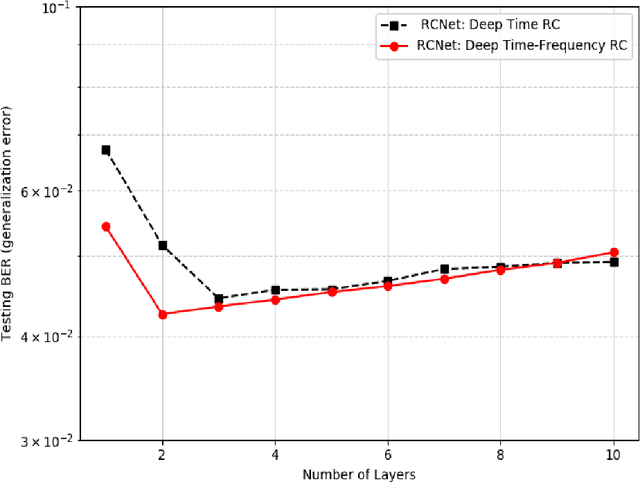
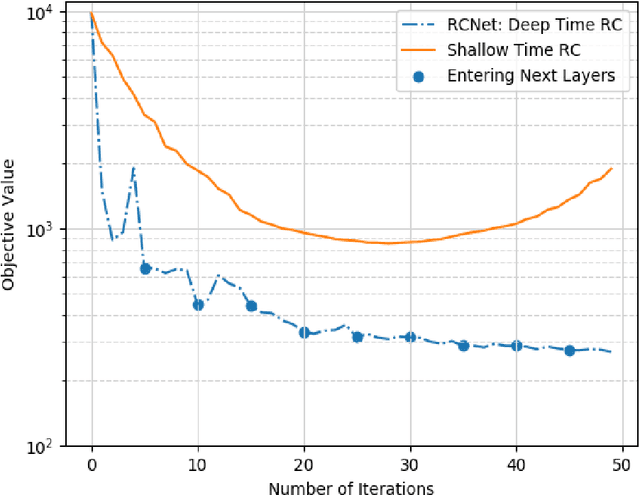
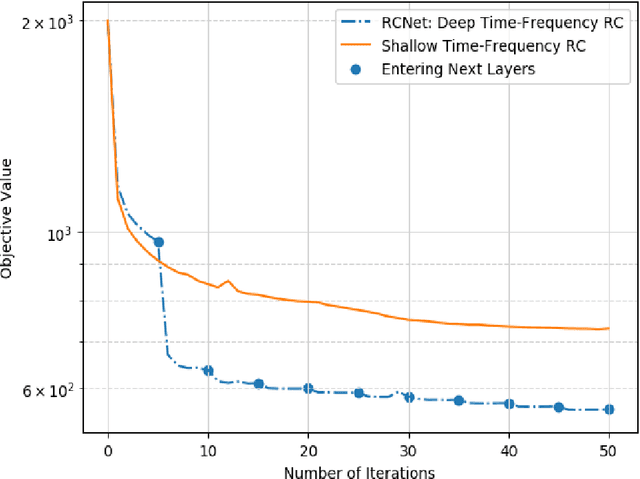
In this paper, we investigate learning-based MIMO-OFDM symbol detection strategies focusing on a special recurrent neural network (RNN) -- reservoir computing (RC). We first introduce the Time-Frequency RC to take advantage of the structural information inherent in OFDM signals. Using the time domain RC and the time-frequency RC as the building blocks, we provide two extensions of the shallow RC to RCNet: 1) Stacking multiple time domain RCs; 2) Stacking multiple time-frequency RCs into a deep structure. The combination of RNN dynamics, the time-frequency structure of MIMO-OFDM signals, and the deep network enables RCNet to handle the interference and nonlinear distortion of MIMO-OFDM signals to outperform existing methods. Unlike most existing NN-based detection strategies, RCNet is also shown to provide a good generalization performance even with a limited training set (i.e, similar amount of reference signals/training as standard model-based approaches). Numerical experiments demonstrate that the introduced RCNet can offer a faster learning convergence and as much as 20% gain in bit error rate over a shallow RC structure by compensating for the nonlinear distortion of the MIMO-OFDM signal, such as due to power amplifier compression in the transmitter or due to finite quantization resolution in the receiver.
Designing Rotationally Invariant Neural Networks from PDEs and Variational Methods
Aug 31, 2021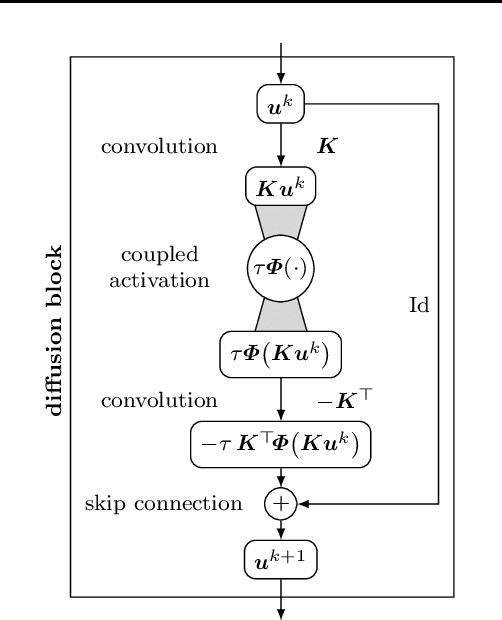

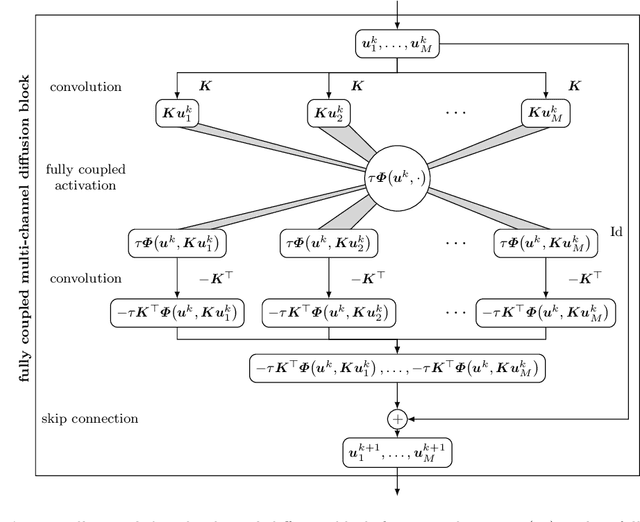
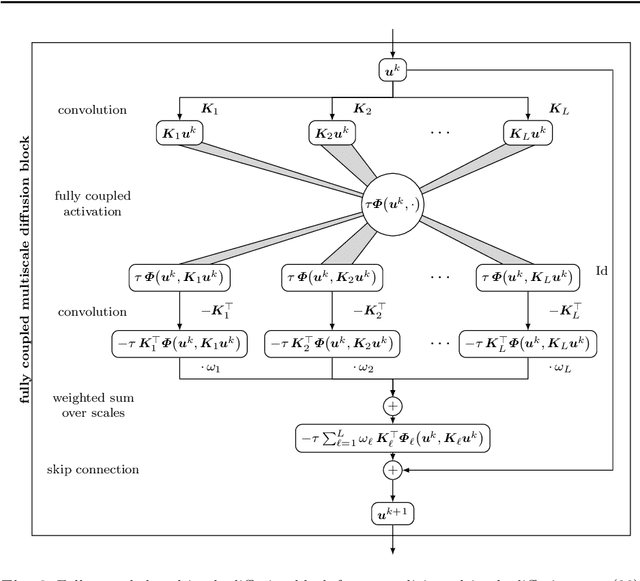
Partial differential equation (PDE) models and their associated variational energy formulations are often rotationally invariant by design. This ensures that a rotation of the input results in a corresponding rotation of the output, which is desirable in applications such as image analysis. Convolutional neural networks (CNNs) do not share this property, and existing remedies are often complex. The goal of our paper is to investigate how diffusion and variational models achieve rotation invariance and transfer these ideas to neural networks. As a core novelty we propose activation functions which couple network channels by combining information from several oriented filters. This guarantees rotation invariance within the basic building blocks of the networks while still allowing for directional filtering. The resulting neural architectures are inherently rotationally invariant. With only a few small filters, they can achieve the same invariance as existing techniques which require a fine-grained sampling of orientations. Our findings help to translate diffusion and variational models into mathematically well-founded network architectures, and provide novel concepts for model-based CNN design.
A User-Guided Bayesian Framework for Ensemble Feature Selection in Life Science Applications (UBayFS)
May 28, 2021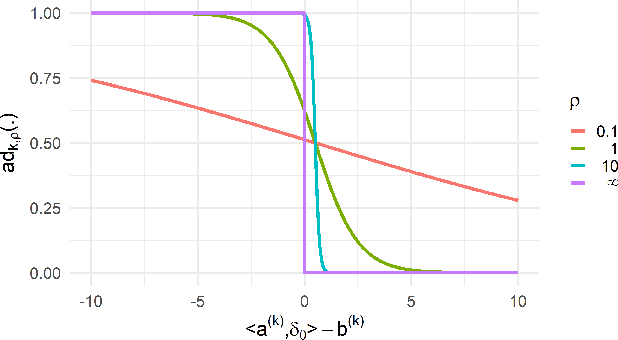
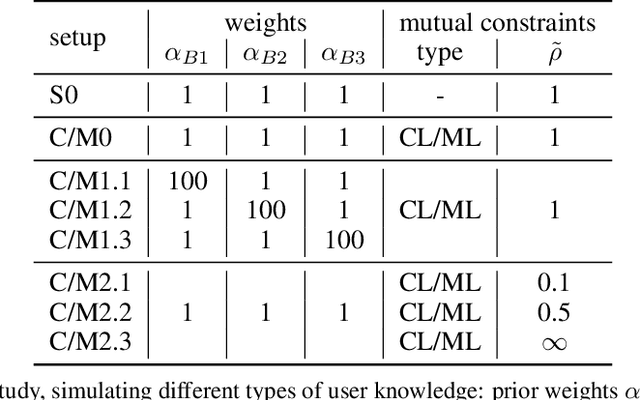
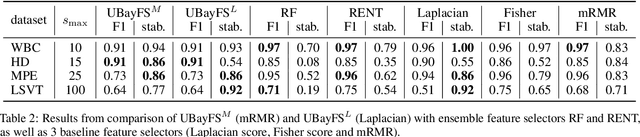
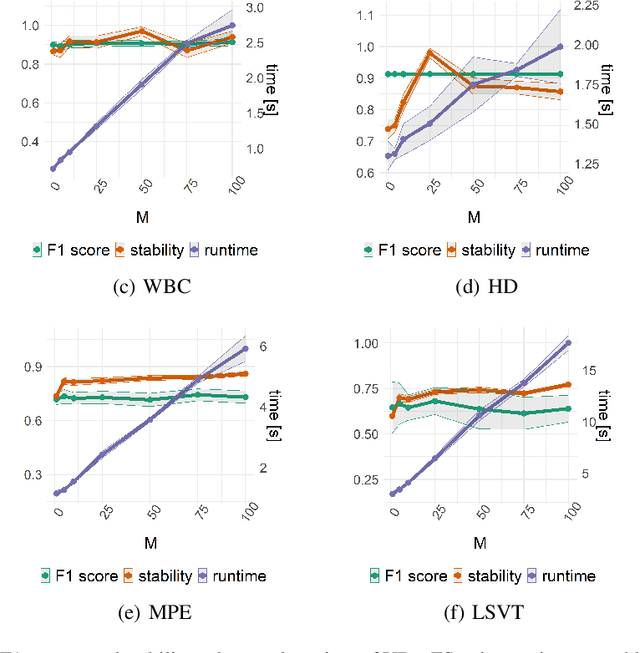
Training machine learning models on high-dimensional datasets is a challenging task and requires measures to prevent overfitting and to keep model complexity low. Feature selection, which represents such a measure, plays a key role in data preprocessing and may provide insights into the systematic variation in the data. The latter aspect is crucial in domains that rely on model interpretability, such as life sciences. We propose UBayFS, an ensemble feature selection technique, embedded in a Bayesian statistical framework. Our approach considers two sources of information: data and domain knowledge. We build an ensemble of elementary feature selectors that extract information from empirical data and aggregate this information to form a meta-model, which compensates for inconsistencies between elementary feature selectors. The user guides UBayFS by weighting features and penalizing specific feature blocks or combinations. The framework builds on a multinomial likelihood and a novel version of constrained Dirichlet-type prior distribution, involving initial feature weights and side constraints. In a quantitative evaluation, we demonstrate that the presented framework allows for a balanced trade-off between user knowledge and data observations. A comparison with standard feature selectors underlines that UBayFS achieves competitive performance, while providing additional flexibility to incorporate domain knowledge.
Where is the disease? Semi-supervised pseudo-normality synthesis from an abnormal image
Jun 24, 2021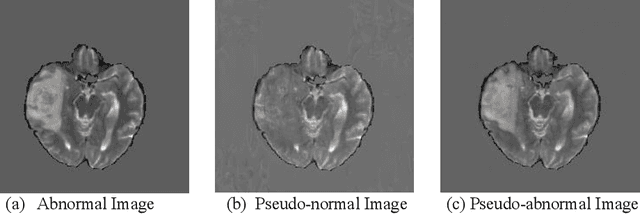

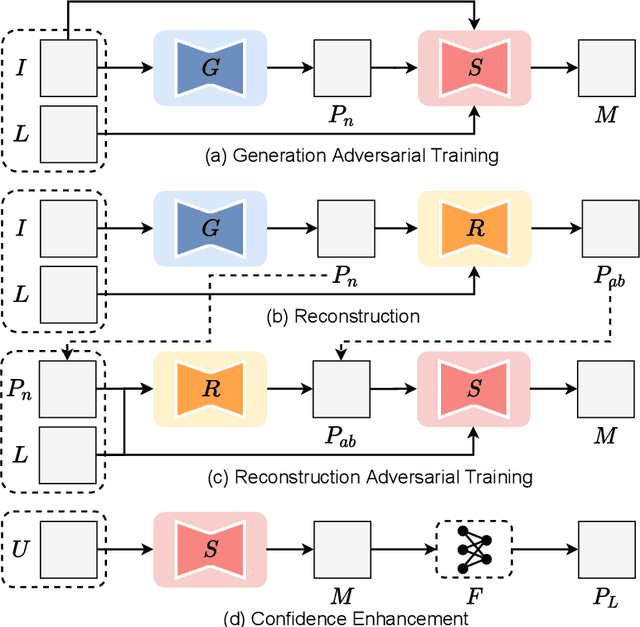
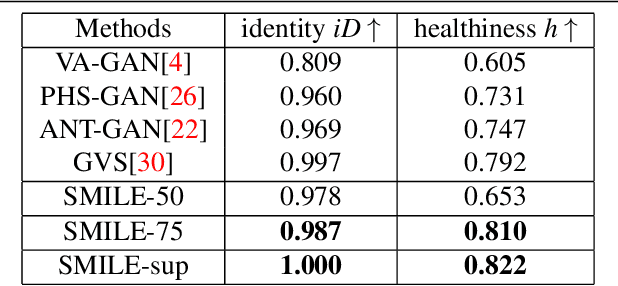
Pseudo-normality synthesis, which computationally generates a pseudo-normal image from an abnormal one (e.g., with lesions), is critical in many perspectives, from lesion detection, data augmentation to clinical surgery suggestion. However, it is challenging to generate high-quality pseudo-normal images in the absence of the lesion information. Thus, expensive lesion segmentation data have been introduced to provide lesion information for the generative models and improve the quality of the synthetic images. In this paper, we aim to alleviate the need of a large amount of lesion segmentation data when generating pseudo-normal images. We propose a Semi-supervised Medical Image generative LEarning network (SMILE) which not only utilizes limited medical images with segmentation masks, but also leverages massive medical images without segmentation masks to generate realistic pseudo-normal images. Extensive experiments show that our model outperforms the best state-of-the-art model by up to 6% for data augmentation task and 3% in generating high-quality images. Moreover, the proposed semi-supervised learning achieves comparable medical image synthesis quality with supervised learning model, using only 50 of segmentation data.
S&P 500 Stock Price Prediction Using Technical, Fundamental and Text Data
Aug 24, 2021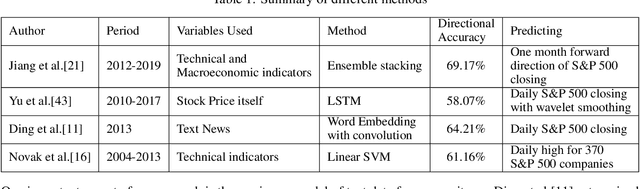

We summarized both common and novel predictive models used for stock price prediction and combined them with technical indices, fundamental characteristics and text-based sentiment data to predict S&P stock prices. A 66.18% accuracy in S&P 500 index directional prediction and 62.09% accuracy in individual stock directional prediction was achieved by combining different machine learning models such as Random Forest and LSTM together into state-of-the-art ensemble models. The data we use contains weekly historical prices, finance reports, and text information from news items associated with 518 different common stocks issued by current and former S&P 500 large-cap companies, from January 1, 2000 to December 31, 2019. Our study's innovation includes utilizing deep language models to categorize and infer financial news item sentiment; fusing different models containing different combinations of variables and stocks to jointly make predictions; and overcoming the insufficient data problem for machine learning models in time series by using data across different stocks.
FastHyMix: Fast and Parameter-free Hyperspectral Image Mixed Noise Removal
Sep 18, 2021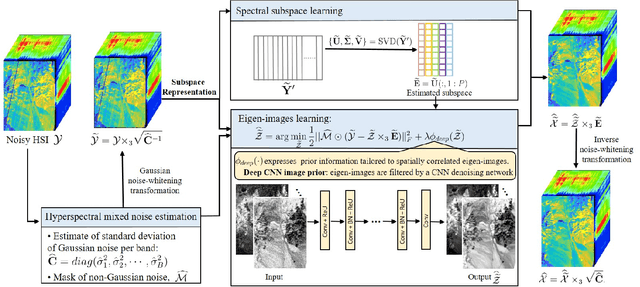
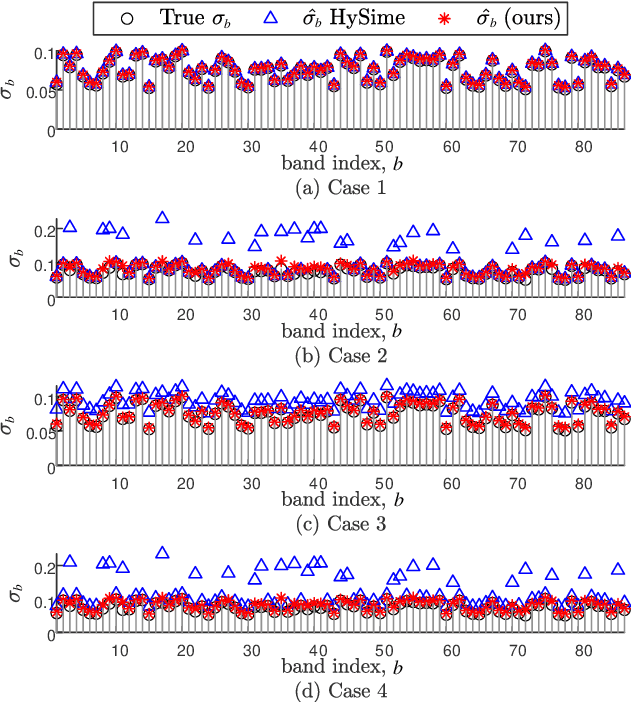

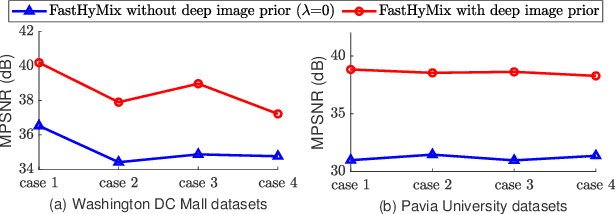
Hyperspectral imaging with high spectral resolution plays an important role in finding objects, identifying materials, or detecting processes. The decrease of the widths of spectral bands leads to a decrease in the signal-to-noise ratio (SNR) of measurements. The decreased SNR reduces the reliability of measured features or information extracted from HSIs. Furthermore, the image degradations linked with various mechanisms also result in different types of noise, such as Gaussian noise, impulse noise, deadlines, and stripes. This paper introduces a fast and parameter-free hyperspectral image mixed noise removal method (termed FastHyMix), which characterizes the complex distribution of mixed noise by using a Gaussian mixture model and exploits two main characteristics of hyperspectral data, namely low-rankness in the spectral domain and high correlation in the spatial domain. The Gaussian mixture model enables us to make a good estimation of Gaussian noise intensity and the location of sparse noise. The proposed method takes advantage of the low-rankness using subspace representation and the spatial correlation of HSIs by adding a powerful deep image prior, which is extracted from a neural denoising network. An exhaustive array of experiments and comparisons with state-of-the-art denoisers were carried out. The experimental results show significant improvement in both synthetic and real datasets. A MATLAB demo of this work will be available at https://github.com/LinaZhuang for the sake of reproducibility.
Partial Gradient Optimal Thresholding Algorithms for a Class of Sparse Optimization Problems
Jul 19, 2021
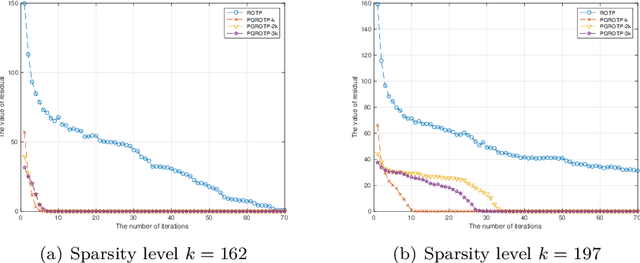
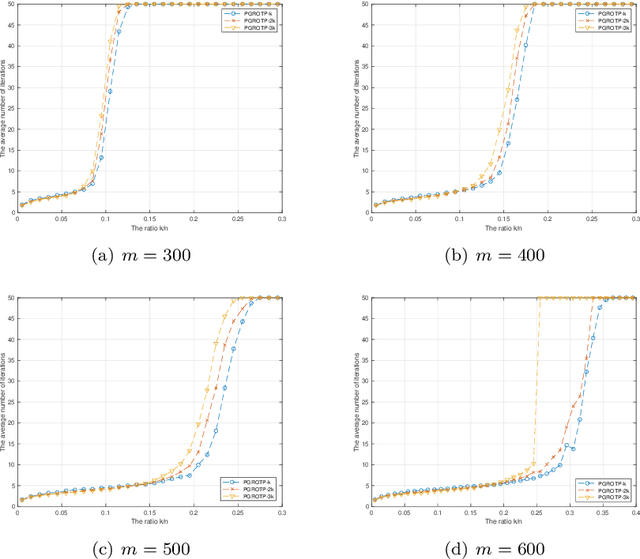
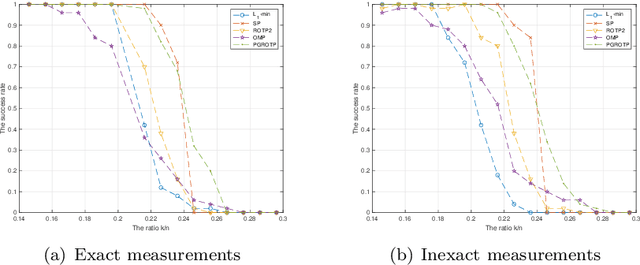
The optimization problems with a sparsity constraint is a class of important global optimization problems. A typical type of thresholding algorithms for solving such a problem adopts the traditional full steepest descent direction or Newton-like direction as a search direction to generate an iterate on which a certain thresholding is performed. Traditional hard thresholding discards a large part of a vector when the vector is dense. Thus a large part of important information contained in a dense vector has been lost in such a thresholding process. Recent study [Zhao, SIAM J Optim, 30(1), pp. 31-55, 2020] shows that the hard thresholding should be applied to a compressible vector instead of a dense vector to avoid a big loss of information. On the other hand, the optimal $k$-thresholding as a novel thresholding technique may overcome the intrinsic drawback of hard thresholding, and performs thresholding and objective function minimization simultaneously. This motivates us to propose the so-called partial gradient optimal thresholding method in this paper, which is an integration of the partial gradient and the optimal $k$-thresholding technique. The solution error bound and convergence for the proposed algorithms have been established in this paper under suitable conditions. Application of our results to the sparse optimization problems arising from signal recovery is also discussed. Experiment results from synthetic data indicate that the proposed algorithm called PGROTP is efficient and comparable to several existing algorithms.
Toward Safety-Aware Informative Motion Planning for Legged Robots
Mar 26, 2021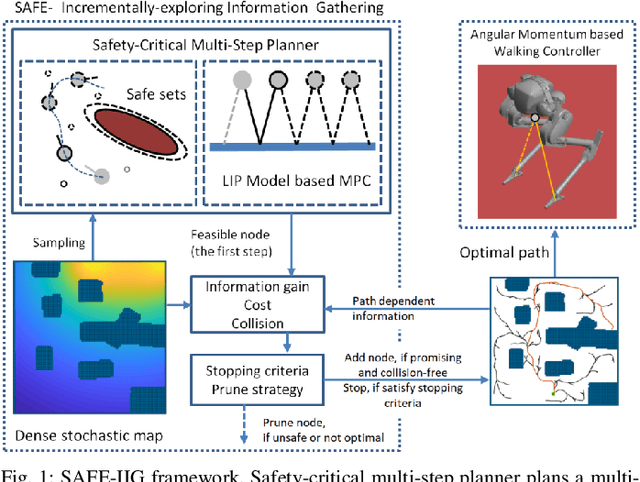
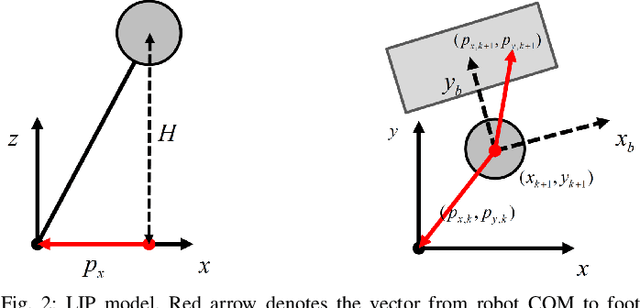
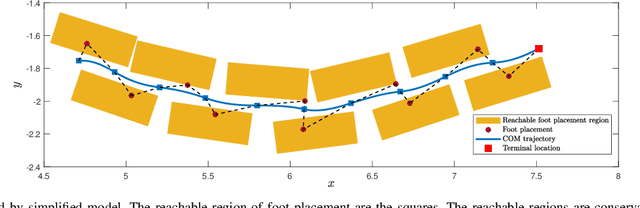
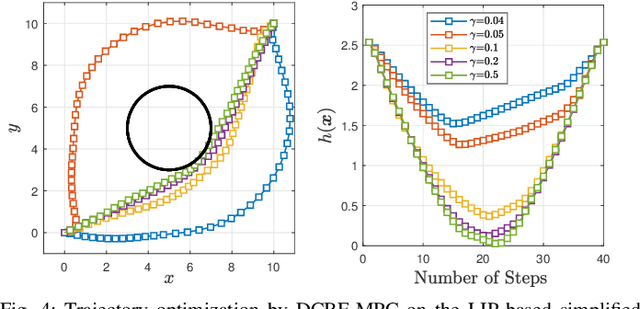
This paper reports on developing an integrated framework for safety-aware informative motion planning suitable for legged robots. The information-gathering planner takes a dense stochastic map of the environment into account, while safety constraints are enforced via Control Barrier Functions (CBFs). The planner is based on the Incrementally-exploring Information Gathering (IIG) algorithm and allows closed-loop kinodynamic node expansion using a Model Predictive Control (MPC) formalism. Robotic exploration and information gathering problems are inherently path-dependent problems. That is, the information collected along a path depends on the state and observation history. As such, motion planning solely based on a modular cost does not lead to suitable plans for exploration. We propose SAFE-IIG, an integrated informative motion planning algorithm that takes into account: 1) a robot's perceptual field of view via a submodular information function computed over a stochastic map of the environment, 2) a robot's dynamics and safety constraints via discrete-time CBFs and MPC for closed-loop multi-horizon node expansions, and 3) an automatic stopping criterion via setting an information-theoretic planning horizon. The simulation results show that SAFE-IIG can plan a safe and dynamically feasible path while exploring a dense map.
Predicting Inflation with Neural Networks
Apr 08, 2021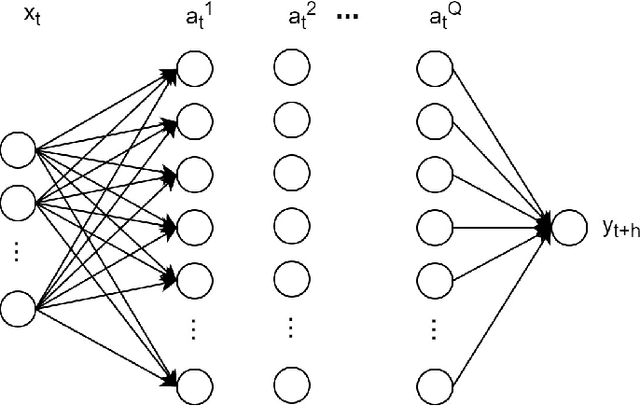
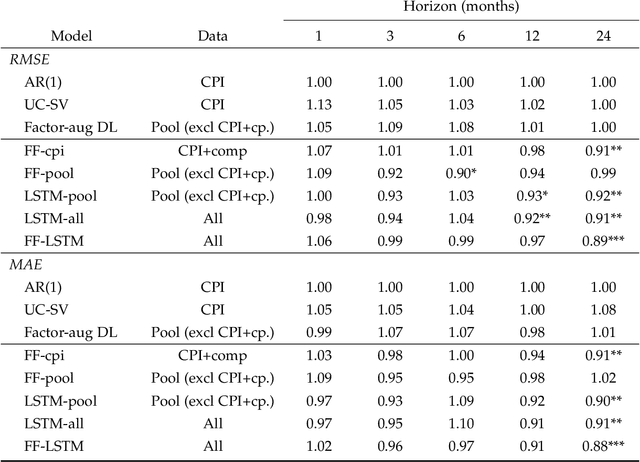
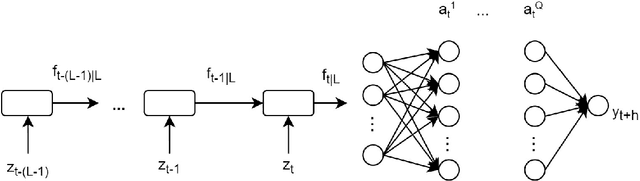
This paper applies neural network models to forecast inflation. The use of a particular recurrent neural network, the long-short term memory model, or LSTM, that summarizes macroeconomic information into common components is a major contribution of the paper. Results from an exercise with US data indicate that the estimated neural nets usually present better forecasting performance than standard benchmarks, especially at long horizons. The LSTM in particular is found to outperform the traditional feed-forward network at long horizons, suggesting an advantage of the recurrent model in capturing the long-term trend of inflation. This finding can be rationalized by the so called long memory of the LSTM that incorporates relatively old information in the forecast as long as accuracy is improved, while economizing in the number of estimated parameters. Interestingly, the neural nets containing macroeconomic information capture well the features of inflation during and after the Great Recession, possibly indicating a role for nonlinearities and macro information in this episode. The estimated common components used in the forecast seem able to capture the business cycle dynamics, as well as information on prices.