 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Learning Based OFDM Channel Estimation Using Frequency-Time Division and Attention Mechanism
Jul 30, 2021
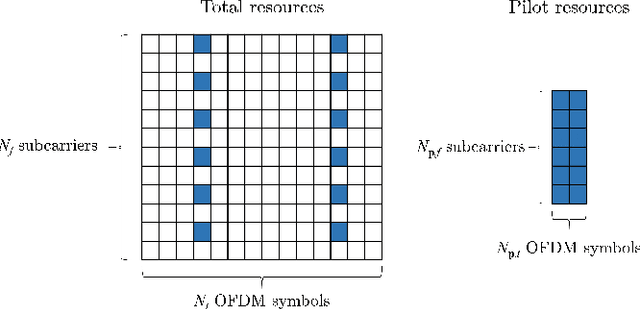
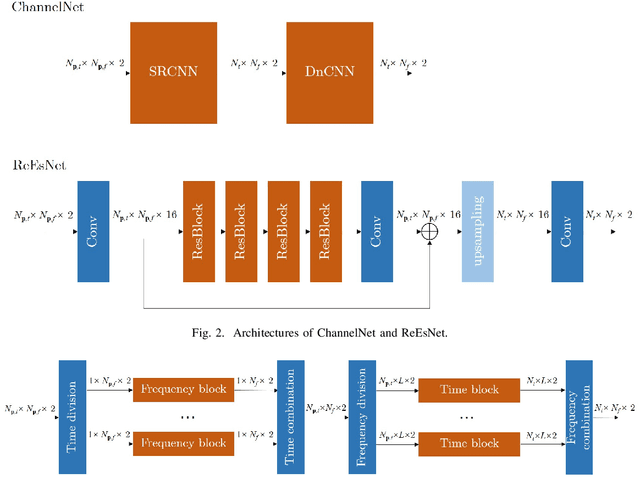
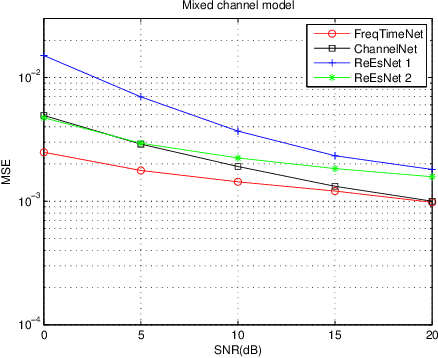
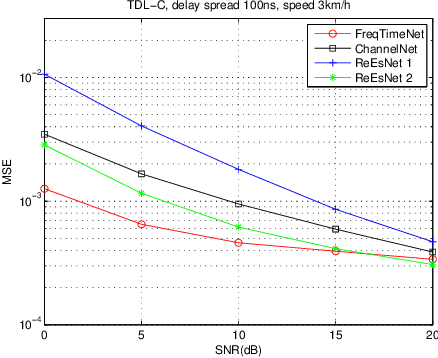
In this paper, we propose a frequency-time division network (FreqTimeNet) to improve the performance of deep learning (DL) based OFDM channel estimation. This FreqTimeNet is designed based on the orthogonality between the frequency domain and the time domain. In FreqTimeNet, the input is processed by parallel frequency blocks and parallel time blocks in sequential. Introducing the attention mechanism to use the SNR information, an attention based FreqTimeNet (AttenFreqTimeNet) is proposed. Using 3rd Generation Partnership Project (3GPP) channel models, the mean square error (MSE) performance of FreqTimeNet and AttenFreqTimeNet under different scenarios is evaluated. A method for constructing mixed training data is proposed, which could address the generalization problem in DL. It is observed that AttenFreqTimeNet outperforms FreqTimeNet, and FreqTimeNet outperforms other DL networks, with acceptable complexity.
Automated Security Assessment for the Internet of Things
Sep 09, 2021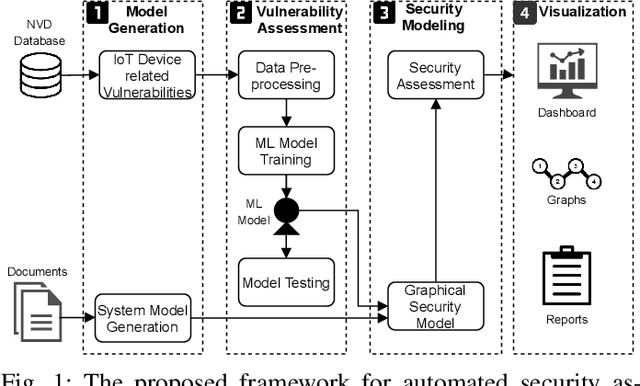
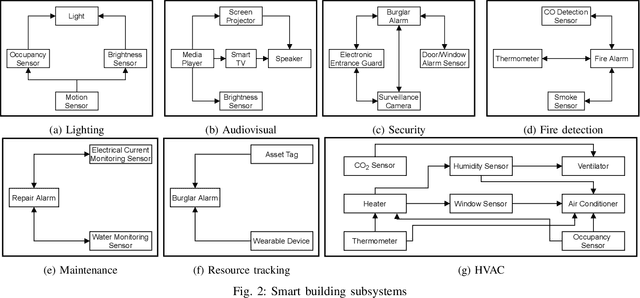
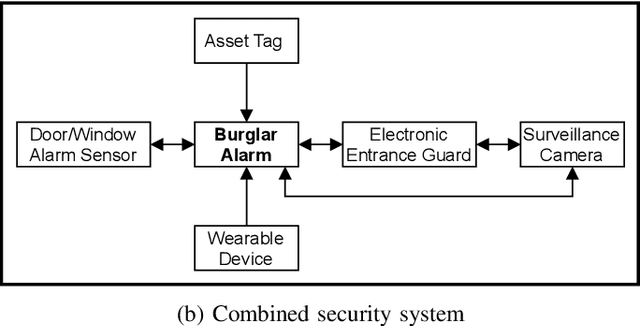
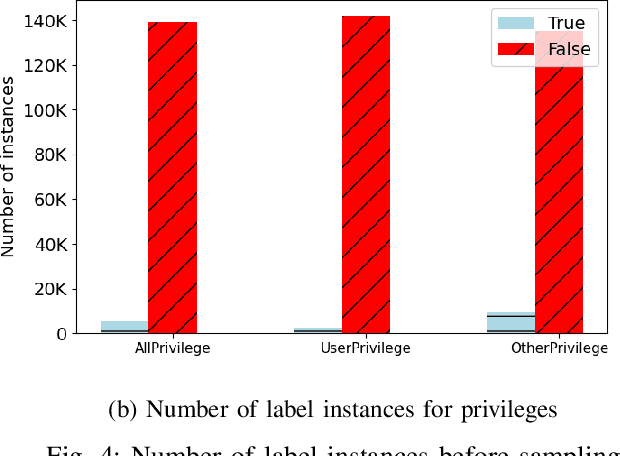
Internet of Things (IoT) based applications face an increasing number of potential security risks, which need to be systematically assessed and addressed. Expert-based manual assessment of IoT security is a predominant approach, which is usually inefficient. To address this problem, we propose an automated security assessment framework for IoT networks. Our framework first leverages machine learning and natural language processing to analyze vulnerability descriptions for predicting vulnerability metrics. The predicted metrics are then input into a two-layered graphical security model, which consists of an attack graph at the upper layer to present the network connectivity and an attack tree for each node in the network at the bottom layer to depict the vulnerability information. This security model automatically assesses the security of the IoT network by capturing potential attack paths. We evaluate the viability of our approach using a proof-of-concept smart building system model which contains a variety of real-world IoT devices and potential vulnerabilities. Our evaluation of the proposed framework demonstrates its effectiveness in terms of automatically predicting the vulnerability metrics of new vulnerabilities with more than 90% accuracy, on average, and identifying the most vulnerable attack paths within an IoT network. The produced assessment results can serve as a guideline for cybersecurity professionals to take further actions and mitigate risks in a timely manner.
Robust Neural Abstractive Summarization Systems and Evaluation against Adversarial Information
Oct 14, 2018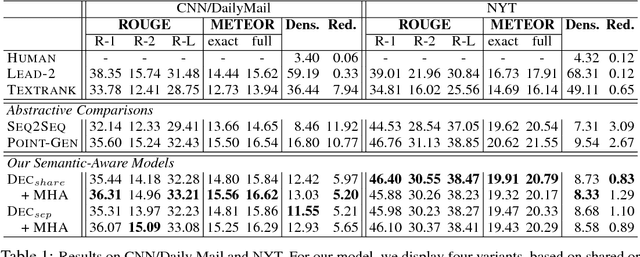
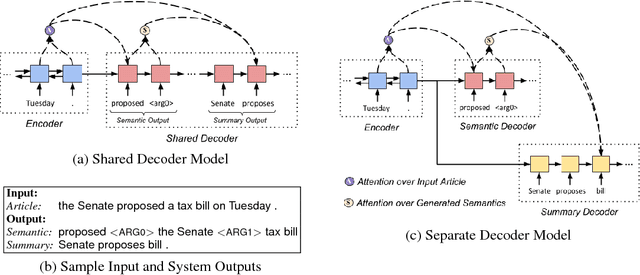
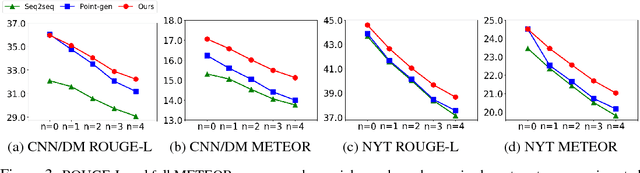
Sequence-to-sequence (seq2seq) neural models have been actively investigated for abstractive summarization. Nevertheless, existing neural abstractive systems frequently generate factually incorrect summaries and are vulnerable to adversarial information, suggesting a crucial lack of semantic understanding. In this paper, we propose a novel semantic-aware neural abstractive summarization model that learns to generate high quality summaries through semantic interpretation over salient content. A novel evaluation scheme with adversarial samples is introduced to measure how well a model identifies off-topic information, where our model yields significantly better performance than the popular pointer-generator summarizer. Human evaluation also confirms that our system summaries are uniformly more informative and faithful as well as less redundant than the seq2seq model.
YES SIR!Optimizing Semantic Space of Negatives with Self-Involvement Ranker
Sep 14, 2021
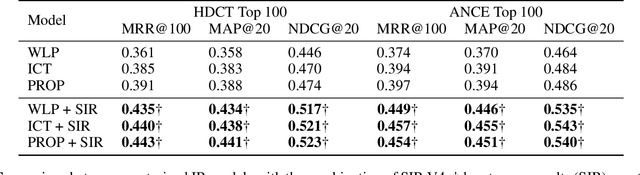
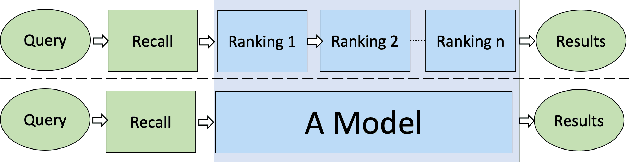
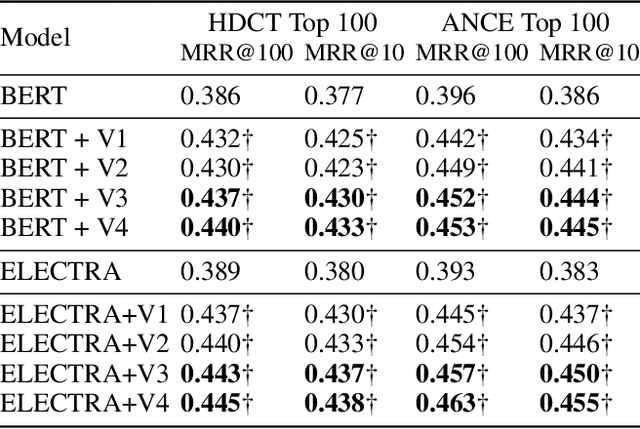
Pre-trained model such as BERT has been proved to be an effective tool for dealing with Information Retrieval (IR) problems. Due to its inspiring performance, it has been widely used to tackle with real-world IR problems such as document ranking. Recently, researchers have found that selecting "hard" rather than "random" negative samples would be beneficial for fine-tuning pre-trained models on ranking tasks. However, it remains elusive how to leverage hard negative samples in a principled way. To address the aforementioned issues, we propose a fine-tuning strategy for document ranking, namely Self-Involvement Ranker (SIR), to dynamically select hard negative samples to construct high-quality semantic space for training a high-quality ranking model. Specifically, SIR consists of sequential compressors implemented with pre-trained models. Front compressor selects hard negative samples for rear compressor. Moreover, SIR leverages supervisory signal to adaptively adjust semantic space of negative samples. Finally, supervisory signal in rear compressor is computed based on condition probability and thus can control sample dynamic and further enhance the model performance. SIR is a lightweight and general framework for pre-trained models, which simplifies the ranking process in industry practice. We test our proposed solution on MS MARCO with document ranking setting, and the results show that SIR can significantly improve the ranking performance of various pre-trained models. Moreover, our method became the new SOTA model anonymously on MS MARCO Document ranking leaderboard in May 2021.
Learning Complex Users' Preferences for Recommender Systems
Jul 04, 2021Recommender systems (RSs) have emerged as very useful tools to help customers with their decision-making process, find items of their interest, and alleviate the information overload problem. There are two different lines of approaches in RSs: (1) general recommenders with the main goal of discovering long-term users' preferences, and (2) sequential recommenders with the main focus of capturing short-term users' preferences in a session of user-item interaction (here, a session refers to a record of purchasing multiple items in one shopping event). While considering short-term users' preferences may satisfy their current needs and interests, long-term users' preferences provide users with the items that they may interact with, eventually. In this thesis, we first focus on improving the performance of general RSs. Most of the existing general RSs tend to exploit the users' rating patterns on common items to detect similar users. The data sparsity problem (i.e. the lack of available information) is one of the major challenges for the current general RSs, and they may fail to have any recommendations when there are no common items of interest among users. We call this problem data sparsity with no feedback on common items (DSW-n-FCI). To overcome this problem, we propose a personality-based RS in which similar users are identified based on the similarity of their personality traits.
Reference Service Model for Federated Identity Management
Aug 15, 2021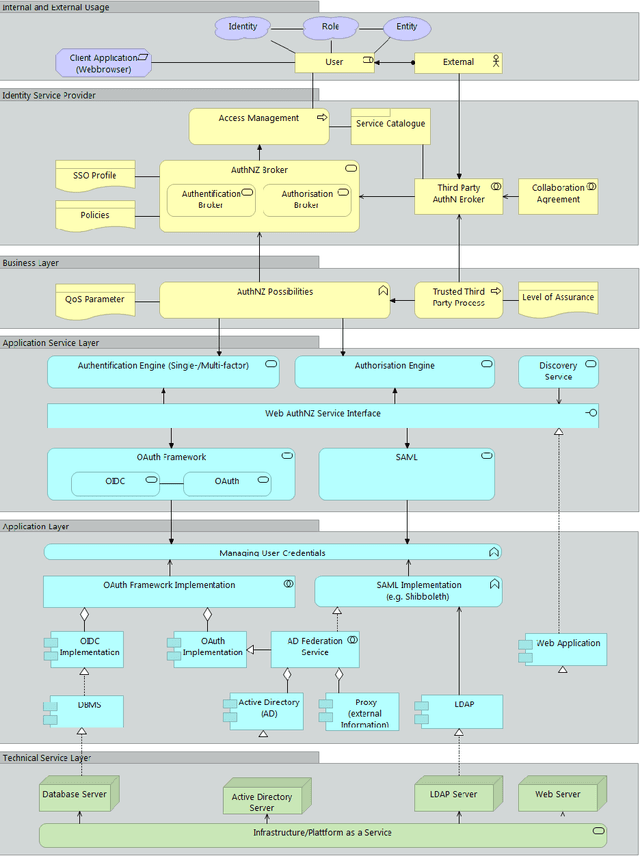
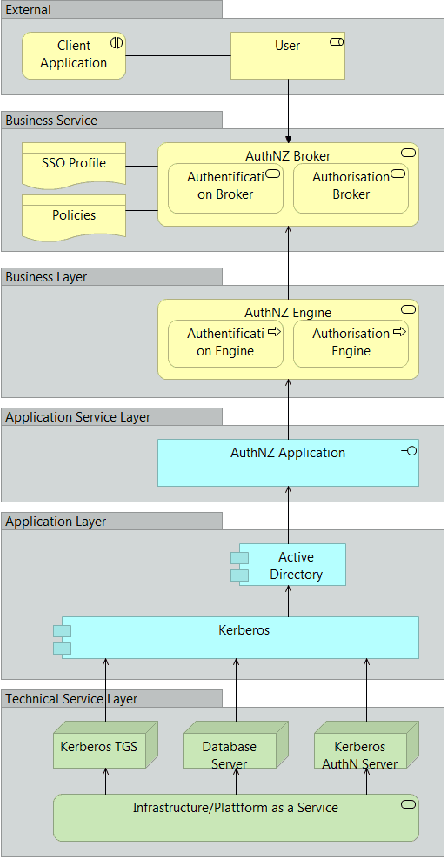
With the pandemic of COVID-19, people around the world increasingly work from home. Each natural person typically has several digital identities with different associated information. During the last years, various identity and access management approaches have gained attraction, helping for example to access other organization's services within trust boundaries. The resulting heterogeneity creates a high complexity to differentiate between these approaches and scenarios as participating entity; combining them is even harder. Last but not least, various actors have a different understanding or perspective of the terms, like 'service', in this context. Our paper describes a reference service with standard components in generic federated identity management. This is utilized with modern Enterprise Architecture using the framework ArchiMate. The proposed universal federated identity management service model (FIMSM) is applied to describe various federated identity management scenarios in a generic service-oriented way. The presented reference design is approved in multiple aspects and is easily applicable in numerous scenarios.
Neural Human Deformation Transfer
Sep 03, 2021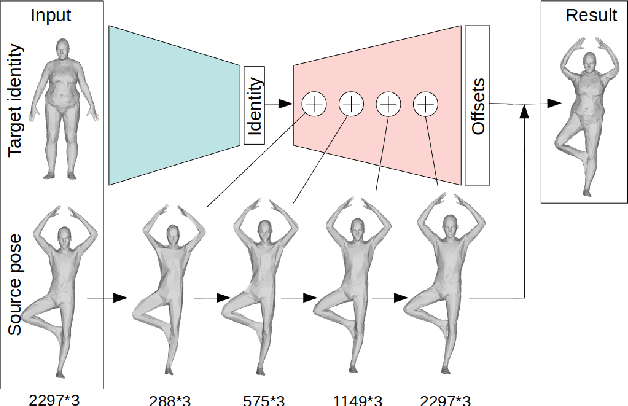

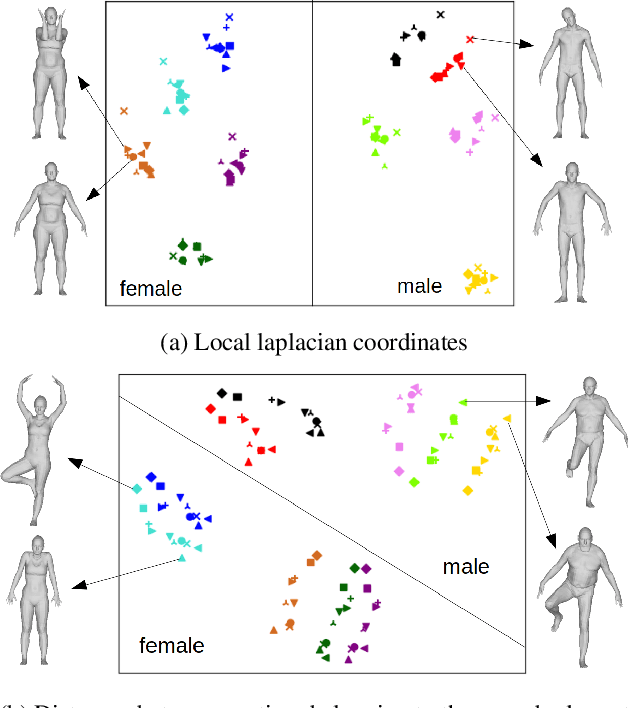
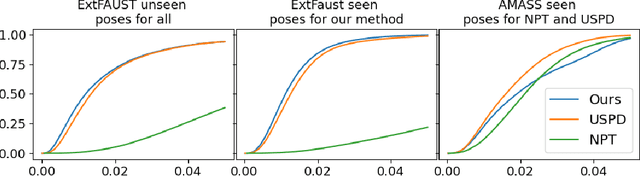
We consider the problem of human deformation transfer, where the goal is to retarget poses between different characters. Traditional methods that tackle this problem require a clear definition of the pose, and use this definition to transfer poses between characters. In this work, we take a different approach and transform the identity of a character into a new identity without modifying the character's pose. This offers the advantage of not having to define equivalences between 3D human poses, which is not straightforward as poses tend to change depending on the identity of the character performing them, and as their meaning is highly contextual. To achieve the deformation transfer, we propose a neural encoder-decoder architecture where only identity information is encoded and where the decoder is conditioned on the pose. We use pose independent representations, such as isometry-invariant shape characteristics, to represent identity features. Our model uses these features to supervise the prediction of offsets from the deformed pose to the result of the transfer. We show experimentally that our method outperforms state-of-the-art methods both quantitatively and qualitatively, and generalises better to poses not seen during training. We also introduce a fine-tuning step that allows to obtain competitive results for extreme identities, and allows to transfer simple clothing.
Model Pruning Based on Quantified Similarity of Feature Maps
May 13, 2021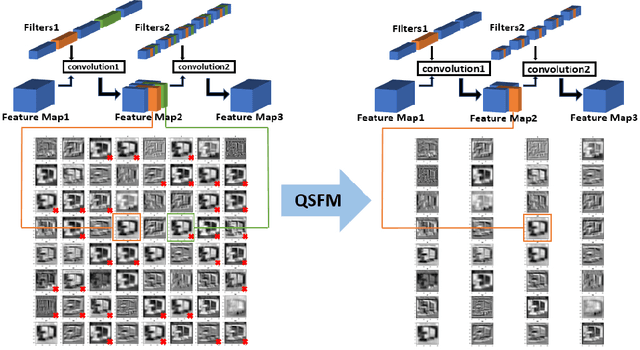

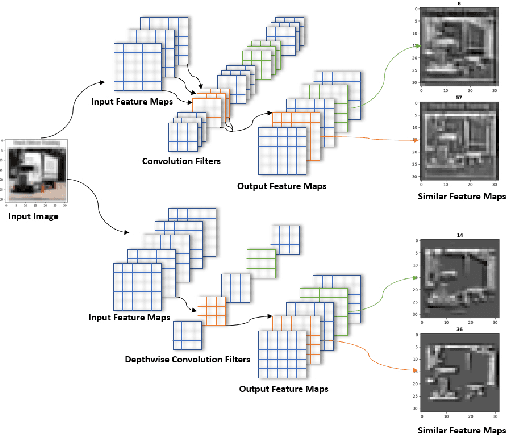
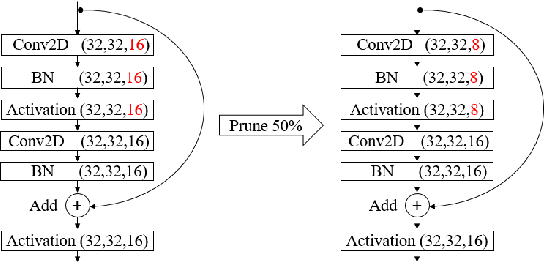
A high-accuracy CNN is often accompanied by huge parameters, which are usually stored in the high-dimensional tensors. However, there are few methods can figure out the redundant information of the parameters stored in the high-dimensional tensors, which leads to the lack of theoretical guidance for the compression of CNNs. In this paper, we propose a novel theory to find redundant information in three dimensional tensors, namely Quantified Similarity of Feature Maps (QSFM), and use this theory to prune convolutional neural networks to enhance the inference speed. Our method belongs to filter pruning, which can be implemented without using any special libraries. We perform our method not only on common convolution layers but also on special convolution layers, such as depthwise separable convolution layers. The experiments prove that QSFM can find the redundant information in the neural network effectively. Without any fine-tuning operation, QSFM can compress ResNet-56 on CIFAR-10 significantly (48.27% FLOPs and 57.90% parameters reduction) with only a loss of 0.54% in the top-1 accuracy. QSFM also prunes ResNet-56, VGG-16 and MobileNetV2 with fine-tuning operation, which also shows excellent results.
Distilling effective supervision for robust medical image segmentation with noisy labels
Jun 21, 2021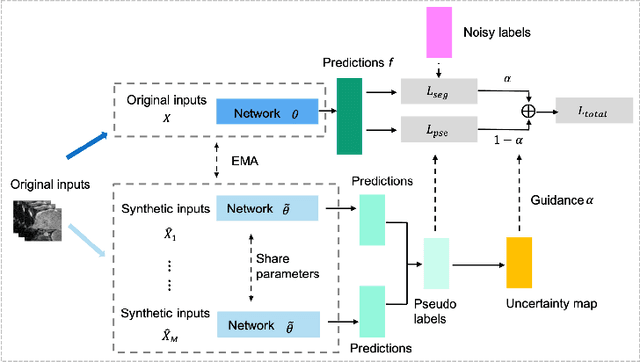
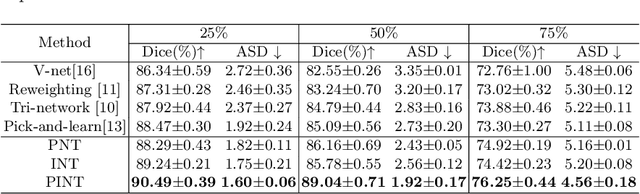
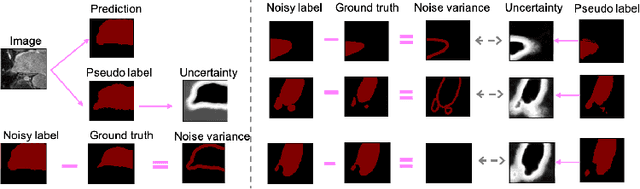
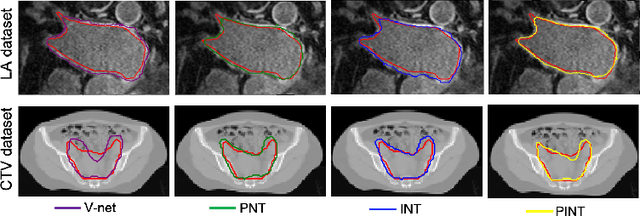
Despite the success of deep learning methods in medical image segmentation tasks, the human-level performance relies on massive training data with high-quality annotations, which are expensive and time-consuming to collect. The fact is that there exist low-quality annotations with label noise, which leads to suboptimal performance of learned models. Two prominent directions for segmentation learning with noisy labels include pixel-wise noise robust training and image-level noise robust training. In this work, we propose a novel framework to address segmenting with noisy labels by distilling effective supervision information from both pixel and image levels. In particular, we explicitly estimate the uncertainty of every pixel as pixel-wise noise estimation, and propose pixel-wise robust learning by using both the original labels and pseudo labels. Furthermore, we present an image-level robust learning method to accommodate more information as the complements to pixel-level learning. We conduct extensive experiments on both simulated and real-world noisy datasets. The results demonstrate the advantageous performance of our method compared to state-of-the-art baselines for medical image segmentation with noisy labels.
Situated Conditional Reasoning
Sep 03, 2021
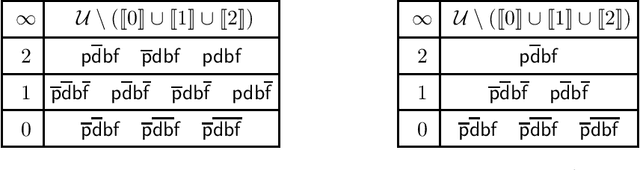

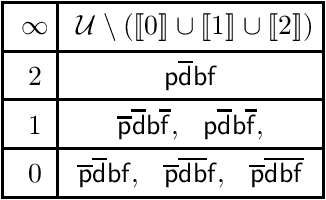
Conditionals are useful for modelling, but are not always sufficiently expressive for capturing information accurately. In this paper we make the case for a form of conditional that is situation-based. These conditionals are more expressive than classical conditionals, are general enough to be used in several application domains, and are able to distinguish, for example, between expectations and counterfactuals. Formally, they are shown to generalise the conditional setting in the style of Kraus, Lehmann, and Magidor. We show that situation-based conditionals can be described in terms of a set of rationality postulates. We then propose an intuitive semantics for these conditionals, and present a representation result which shows that our semantic construction corresponds exactly to the description in terms of postulates. With the semantics in place, we proceed to define a form of entailment for situated conditional knowledge bases, which we refer to as minimal closure. It is reminiscent of and, indeed, inspired by, the version of entailment for propositional conditional knowledge bases known as rational closure. Finally, we proceed to show that it is possible to reduce the computation of minimal closure to a series of propositional entailment and satisfiability checks. While this is also the case for rational closure, it is somewhat surprising that the result carries over to minimal closure.