 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Audio-visual Attentive Fusion for Continuous Emotion Recognition
Jul 02, 2021
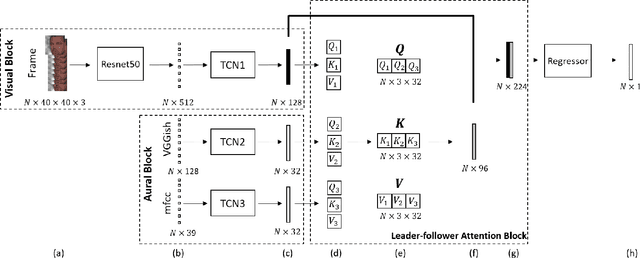
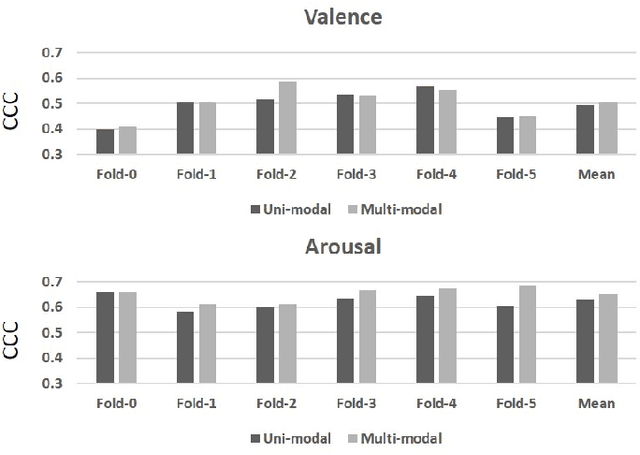
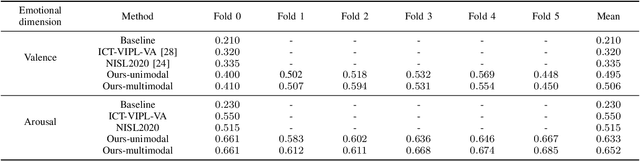
We propose an audio-visual spatial-temporal deep neural network with: (1) a visual block containing a pretrained 2D-CNN followed by a temporal convolutional network (TCN); (2) an aural block containing several parallel TCNs; and (3) a leader-follower attentive fusion block combining the audio-visual information. The TCN with large history coverage enables our model to exploit spatial-temporal information within a much larger window length (i.e., 300) than that from the baseline and state-of-the-art methods (i.e., 36 or 48). The fusion block emphasizes the visual modality while exploits the noisy aural modality using the inter-modality attention mechanism. To make full use of the data and alleviate over-fitting, cross-validation is carried out on the training and validation set. The concordance correlation coefficient (CCC) centering is used to merge the results from each fold. On the development set, the achieved CCC is 0.410 for valence and 0.661 for arousal, which significantly outperforms the baseline method with the corresponding CCC of 0.210 and 0.230 for valence and arousal, respectively. The code is available at https://github.com/sucv/ABAW2.
Scaling Bayesian Optimization With Game Theory
Oct 07, 2021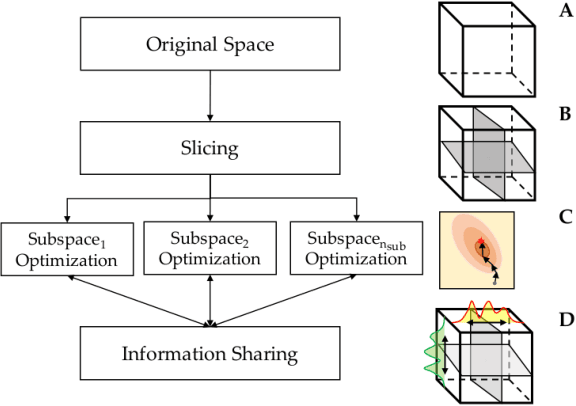


We introduce the algorithm Bayesian Optimization (BO) with Fictitious Play (BOFiP) for the optimization of high dimensional black box functions. BOFiP decomposes the original, high dimensional, space into several sub-spaces defined by non-overlapping sets of dimensions. These sets are randomly generated at the start of the algorithm, and they form a partition of the dimensions of the original space. BOFiP searches the original space with alternating BO, within sub-spaces, and information exchange among sub-spaces, to update the sub-space function evaluation. The basic idea is to distribute the high dimensional optimization across low dimensional sub-spaces, where each sub-space is a player in an equal interest game. At each iteration, BO produces approximate best replies that update the players belief distribution. The belief update and BO alternate until a stopping condition is met. High dimensional problems are common in real applications, and several contributions in the BO literature have highlighted the difficulty in scaling to high dimensions due to the computational complexity associated to the estimation of the model hyperparameters. Such complexity is exponential in the problem dimension, resulting in substantial loss of performance for most techniques with the increase of the input dimensionality. We compare BOFiP to several state-of-the-art approaches in the field of high dimensional black box optimization. The numerical experiments show the performance over three benchmark objective functions from 20 up to 1000 dimensions. A neural network architecture design problem is tested with 42 up to 911 nodes in 6 up to 92 layers, respectively, resulting into networks with 500 up to 10,000 weights. These sets of experiments empirically show that BOFiP outperforms its competitors, showing consistent performance across different problems and increasing problem dimensionality.
The Impact of Network Connectivity on Collective Learning
Jun 18, 2021
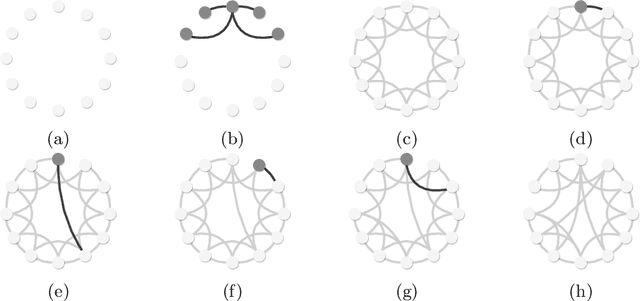
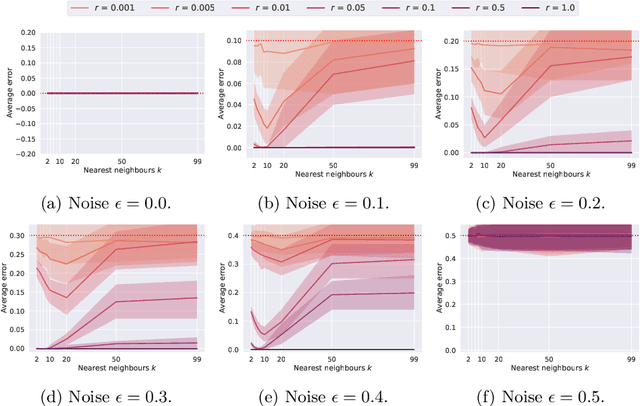
In decentralised autonomous systems it is the interactions between individual agents which govern the collective behaviours of the system. These local-level interactions are themselves often governed by an underlying network structure. These networks are particularly important for collective learning and decision-making whereby agents must gather evidence from their environment and propagate this information to other agents in the system. Models for collective behaviours may often rely upon the assumption of total connectivity between agents to provide effective information sharing within the system, but this assumption may be ill-advised. In this paper we investigate the impact that the underlying network has on performance in the context of collective learning. Through simulations we study small-world networks with varying levels of connectivity and randomness and conclude that totally-connected networks result in higher average error when compared to networks with less connectivity. Furthermore, we show that networks of high regularity outperform networks with increasing levels of random connectivity.
Energy Minimization for IRS-aided WPCNs with Non-linear Energy Harvesting Model
Sep 02, 2021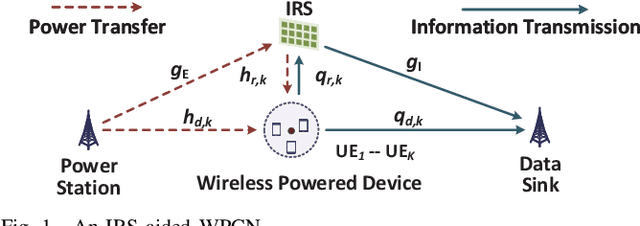
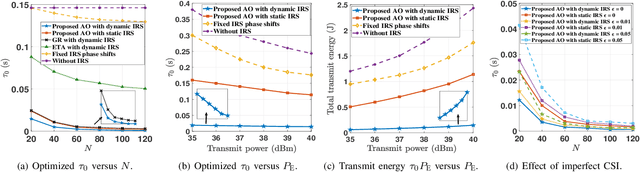
This paper considers an intelligent reflecting surface(IRS)-aided wireless powered communication network (WPCN), where devices first harvest energy from a power station (PS) in the downlink (DL) and then transmit information using non-orthogonal multiple access (NOMA) to a data sink in the uplink (UL). However, most existing works on WPCNs adopted the simplified linear energy-harvesting model and also cannot guarantee strict user quality-of-service requirements. To address these issues, we aim to minimize the total transmit energy consumption at the PS by jointly optimizing the resource allocation and IRS phase shifts over time, subject to the minimum throughput requirements of all devices. The formulated problem is decomposed into two subproblems, and solved iteratively in an alternative manner by employing difference of convex functions programming, successive convex approximation, and penalty-based algorithm. Numerical results demonstrate the significant performance gains achieved by the proposed algorithm over benchmark schemes and reveal the benefits of integrating IRS into WPCNs. In particular, employing different IRS phase shifts over UL and DL outperforms the case with static IRS beamforming.
Review of Visual Saliency Detection with Comprehensive Information
Sep 14, 2018



Visual saliency detection model simulates the human visual system to perceive the scene, and has been widely used in many vision tasks. With the acquisition technology development, more comprehensive information, such as depth cue, inter-image correspondence, or temporal relationship, is available to extend image saliency detection to RGBD saliency detection, co-saliency detection, or video saliency detection. RGBD saliency detection model focuses on extracting the salient regions from RGBD images by combining the depth information. Co-saliency detection model introduces the inter-image correspondence constraint to discover the common salient object in an image group. The goal of video saliency detection model is to locate the motion-related salient object in video sequences, which considers the motion cue and spatiotemporal constraint jointly. In this paper, we review different types of saliency detection algorithms, summarize the important issues of the existing methods, and discuss the existent problems and future works. Moreover, the evaluation datasets and quantitative measurements are briefly introduced, and the experimental analysis and discission are conducted to provide a holistic overview of different saliency detection methods.
A Dual-Decoder Conformer for Multilingual Speech Recognition
Aug 22, 2021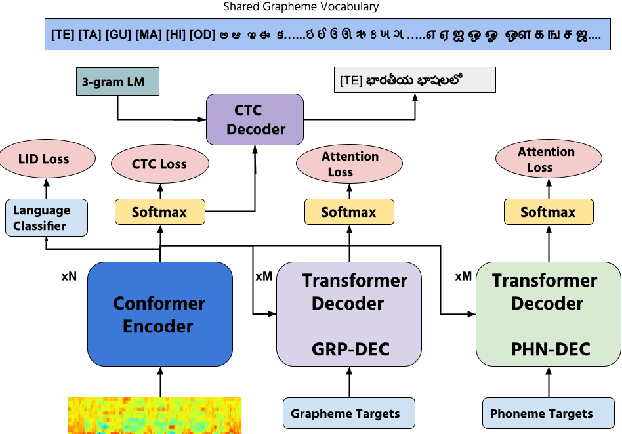
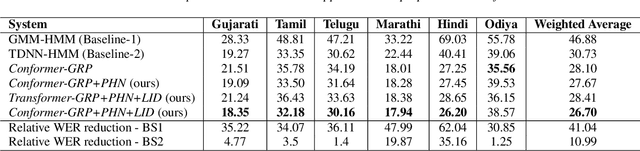


Transformer-based models have recently become very popular for sequence-to-sequence applications such as machine translation and speech recognition. This work proposes a dual-decoder transformer model for low-resource multilingual speech recognition for Indian languages. Our proposed model consists of a Conformer [1] encoder, two parallel transformer decoders, and a language classifier. We use a phoneme decoder (PHN-DEC) for the phoneme recognition task and a grapheme decoder (GRP-DEC) to predict grapheme sequence along with language information. We consider phoneme recognition and language identification as auxiliary tasks in the multi-task learning framework. We jointly optimize the network for phoneme recognition, grapheme recognition, and language identification tasks with Joint CTC-Attention [2] training. Our experiments show that we can obtain a significant reduction in WER over the baseline approaches. We also show that our dual-decoder approach obtains significant improvement over the single decoder approach.
Formalizing and Estimating Distribution Inference Risks
Sep 24, 2021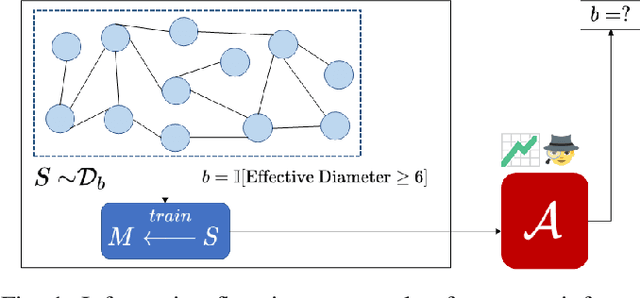
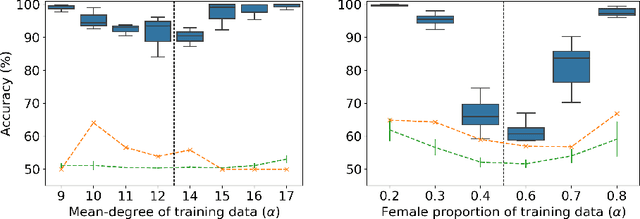
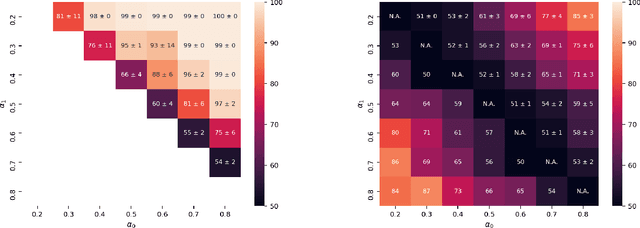
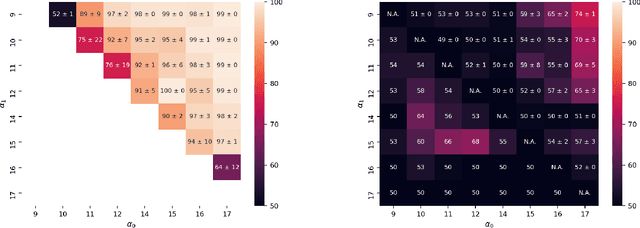
Property inference attacks reveal statistical properties about a training set but are difficult to distinguish from the intrinsic purpose of statistical machine learning, namely to produce models that capture statistical properties about a distribution. Motivated by Yeom et al.'s membership inference framework, we propose a formal and general definition of property inference attacks. The proposed notion describes attacks that can distinguish between possible training distributions, extending beyond previous property inference attacks that infer the ratio of a particular type of data in the training data set such as the proportion of females. We show how our definition captures previous property inference attacks as well as a new attack that can reveal the average node degree or clustering coefficient of a training graph. Our definition also enables a theorem that connects the maximum possible accuracy of inference attacks distinguishing between distributions to the effective size of dataset leaked by the model. To quantify and understand property inference risks, we conduct a series of experiments across a range of different distributions using both black-box and white-box attacks. Our results show that inexpensive attacks are often as effective as expensive meta-classifier attacks, and that there are surprising asymmetries in the effectiveness of attacks. We also extend the state-of-the-art property inference attack to work on convolutional neural networks, and propose techniques to help identify parameters in a model that leak the most information, thus significantly lowering resource requirements for meta-classifier attacks.
Netmarble AI Center's WMT21 Automatic Post-Editing Shared Task Submission
Sep 14, 2021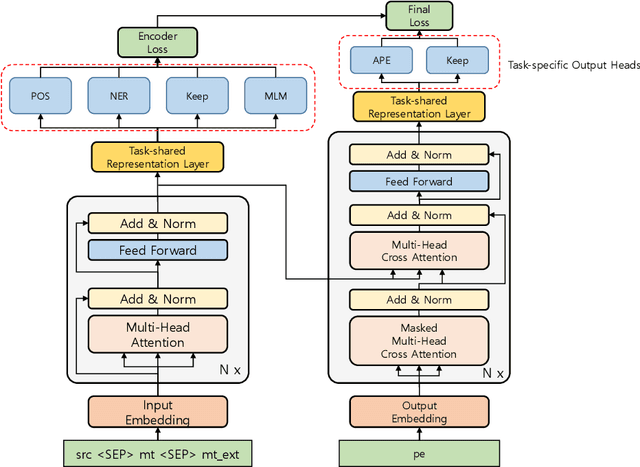
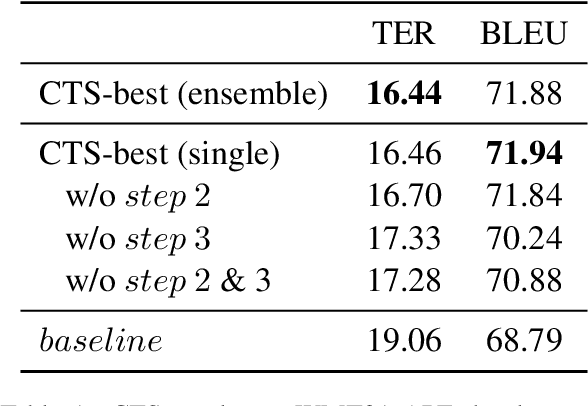
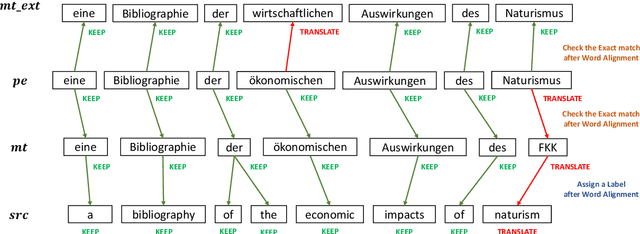

This paper describes Netmarble's submission to WMT21 Automatic Post-Editing (APE) Shared Task for the English-German language pair. First, we propose a Curriculum Training Strategy in training stages. Facebook Fair's WMT19 news translation model was chosen to engage the large and powerful pre-trained neural networks. Then, we post-train the translation model with different levels of data at each training stages. As the training stages go on, we make the system learn to solve multiple tasks by adding extra information at different training stages gradually. We also show a way to utilize the additional data in large volume for APE tasks. For further improvement, we apply Multi-Task Learning Strategy with the Dynamic Weight Average during the fine-tuning stage. To fine-tune the APE corpus with limited data, we add some related subtasks to learn a unified representation. Finally, for better performance, we leverage external translations as augmented machine translation (MT) during the post-training and fine-tuning. As experimental results show, our APE system significantly improves the translations of provided MT results by -2.848 and +3.74 on the development dataset in terms of TER and BLEU, respectively. It also demonstrates its effectiveness on the test dataset with higher quality than the development dataset.
Bayesian Nonparametric Causal Inference: Information Rates and Learning Algorithms
Jan 21, 2018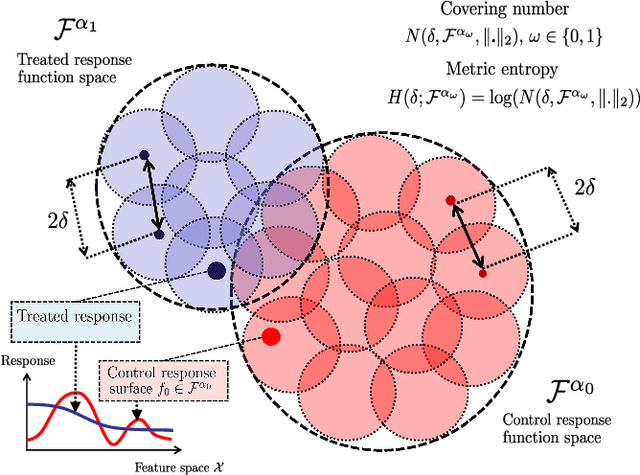
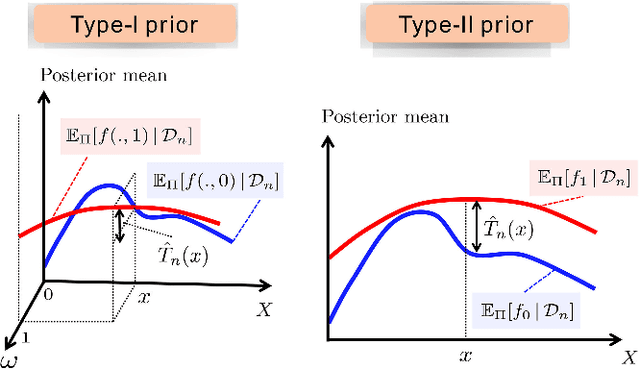
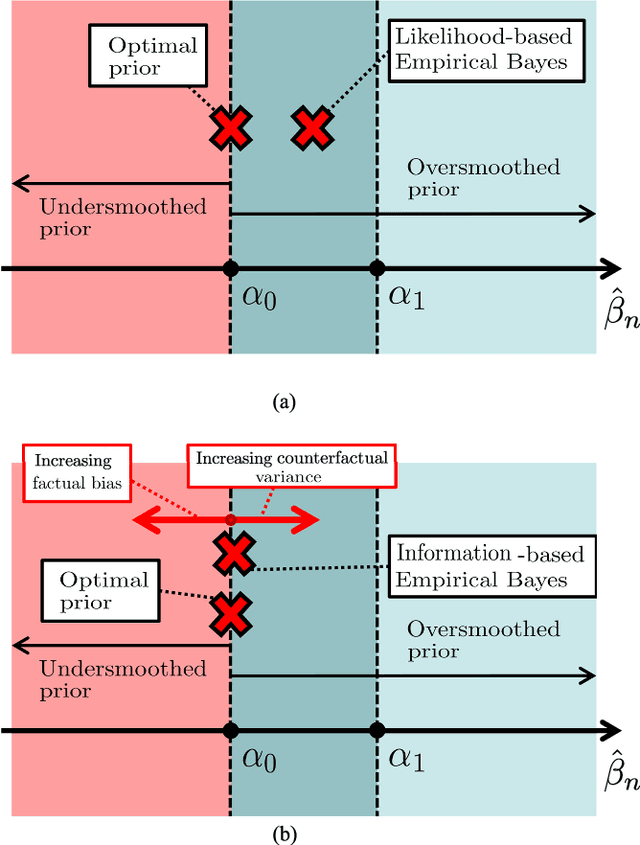

We investigate the problem of estimating the causal effect of a treatment on individual subjects from observational data, this is a central problem in various application domains, including healthcare, social sciences, and online advertising. Within the Neyman Rubin potential outcomes model, we use the Kullback Leibler (KL) divergence between the estimated and true distributions as a measure of accuracy of the estimate, and we define the information rate of the Bayesian causal inference procedure as the (asymptotic equivalence class of the) expected value of the KL divergence between the estimated and true distributions as a function of the number of samples. Using Fano method, we establish a fundamental limit on the information rate that can be achieved by any Bayesian estimator, and show that this fundamental limit is independent of the selection bias in the observational data. We characterize the Bayesian priors on the potential (factual and counterfactual) outcomes that achieve the optimal information rate. As a consequence, we show that a particular class of priors that have been widely used in the causal inference literature cannot achieve the optimal information rate. On the other hand, a broader class of priors can achieve the optimal information rate. We go on to propose a prior adaptation procedure (which we call the information based empirical Bayes procedure) that optimizes the Bayesian prior by maximizing an information theoretic criterion on the recovered causal effects rather than maximizing the marginal likelihood of the observed (factual) data. Building on our analysis, we construct an information optimal Bayesian causal inference algorithm.
Multilevel profiling of situation and dialogue-based deep networks for movie genre classification using movie trailers
Sep 14, 2021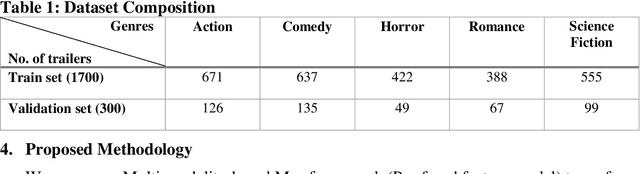
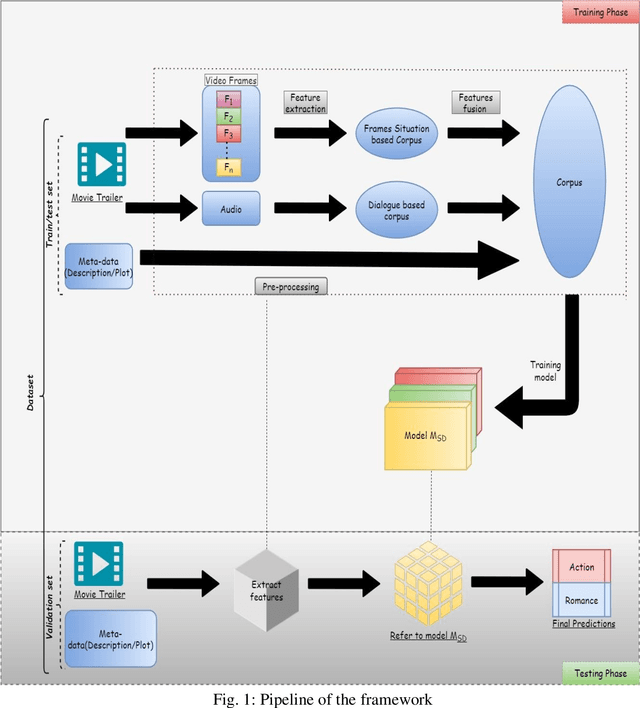
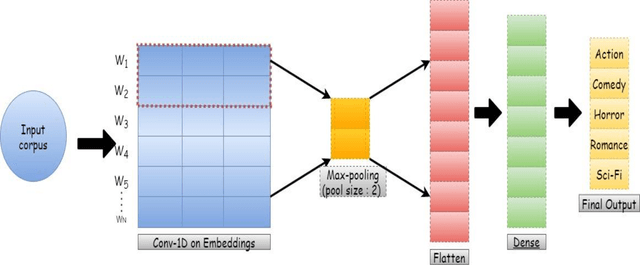
Automated movie genre classification has emerged as an active and essential area of research and exploration. Short duration movie trailers provide useful insights about the movie as video content consists of the cognitive and the affective level features. Previous approaches were focused upon either cognitive or affective content analysis. In this paper, we propose a novel multi-modality: situation, dialogue, and metadata-based movie genre classification framework that takes both cognition and affect-based features into consideration. A pre-features fusion-based framework that takes into account: situation-based features from a regular snapshot of a trailer that includes nouns and verbs providing the useful affect-based mapping with the corresponding genres, dialogue (speech) based feature from audio, metadata which together provides the relevant information for cognitive and affect based video analysis. We also develop the English movie trailer dataset (EMTD), which contains 2000 Hollywood movie trailers belonging to five popular genres: Action, Romance, Comedy, Horror, and Science Fiction, and perform cross-validation on the standard LMTD-9 dataset for validating the proposed framework. The results demonstrate that the proposed methodology for movie genre classification has performed excellently as depicted by the F1 scores, precision, recall, and area under the precision-recall curves.