 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Few-shot Quality-Diversity Optimisation
Sep 14, 2021
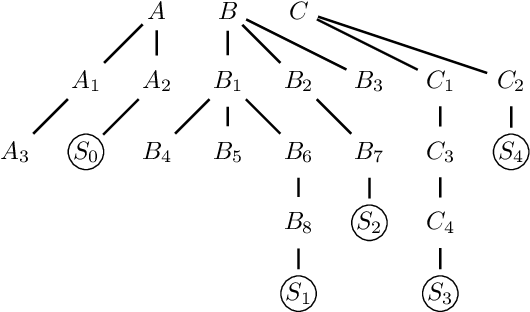
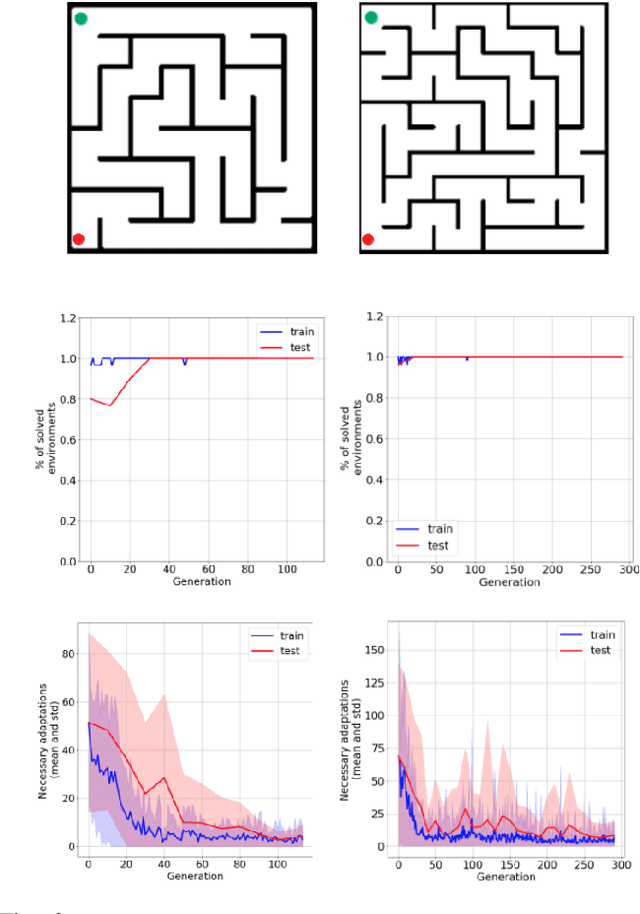
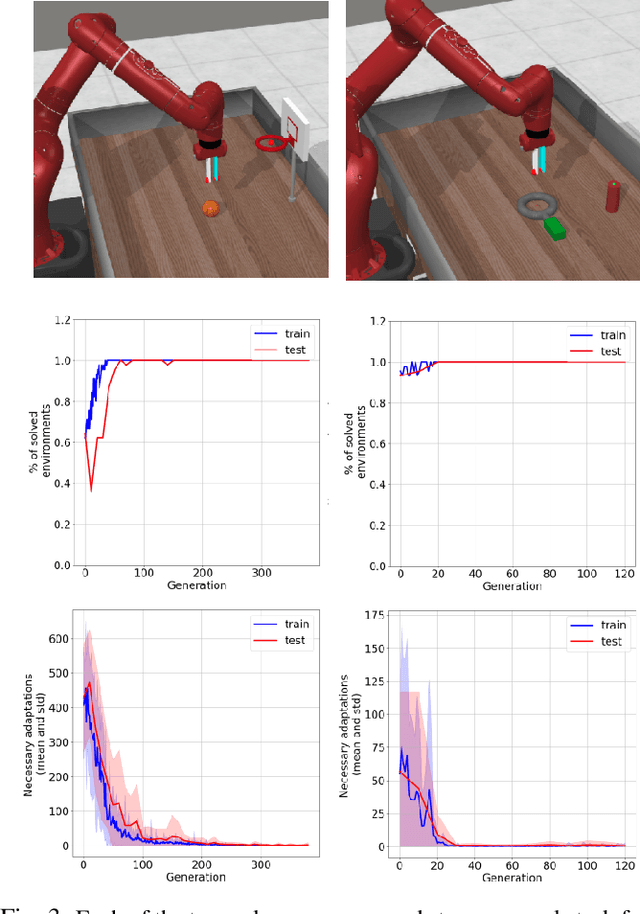
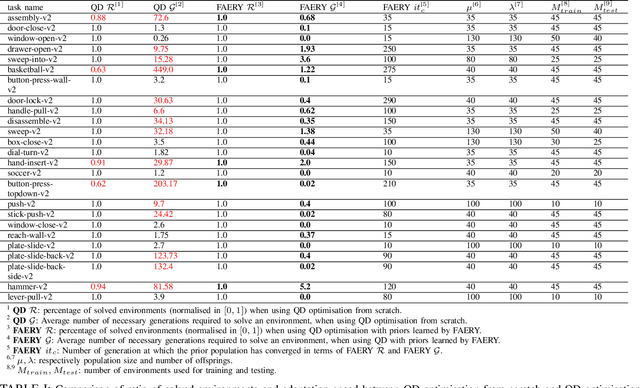
In the past few years, a considerable amount of research has been dedicated to the exploitation of previous learning experiences and the design of Few-shot and Meta Learning approaches, in problem domains ranging from Computer Vision to Reinforcement Learning based control. A notable exception, where to the best of our knowledge, little to no effort has been made in this direction is Quality-Diversity (QD) optimisation. QD methods have been shown to be effective tools in dealing with deceptive minima and sparse rewards in Reinforcement Learning. However, they remain costly due to their reliance on inherently sample inefficient evolutionary processes. We show that, given examples from a task distribution, information about the paths taken by optimisation in parameter space can be leveraged to build a prior population, which when used to initialise QD methods in unseen environments, allows for few-shot adaptation. Our proposed method does not require backpropagation. It is simple to implement and scale, and furthermore, it is agnostic to the underlying models that are being trained. Experiments carried in both sparse and dense reward settings using robotic manipulation and navigation benchmarks show that it considerably reduces the number of generations that are required for QD optimisation in these environments.
SuMa++: Efficient LiDAR-based Semantic SLAM
May 24, 2021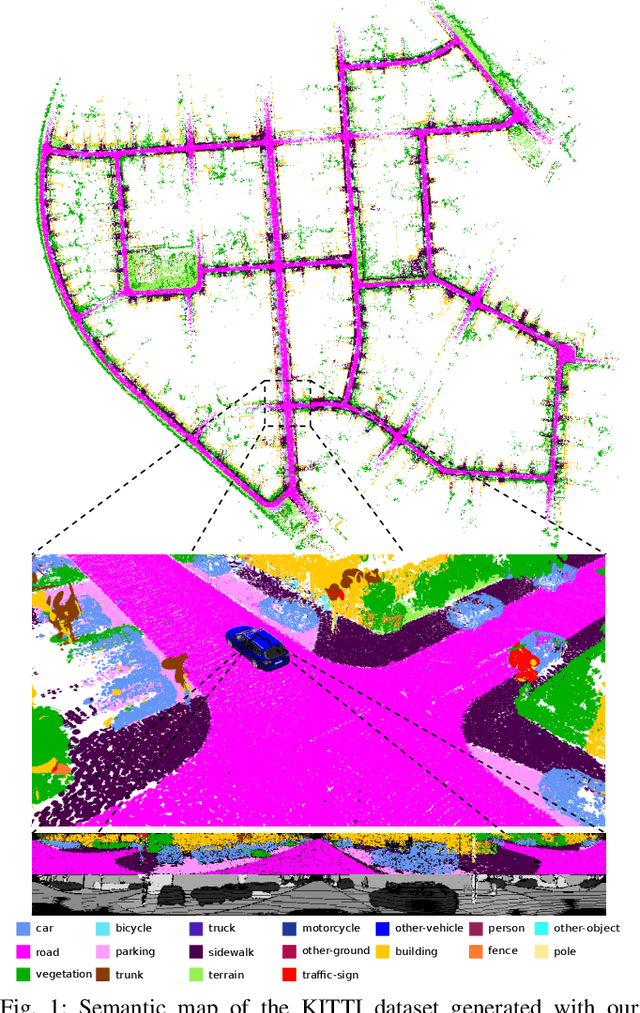
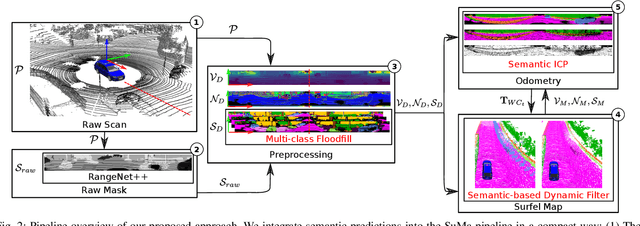

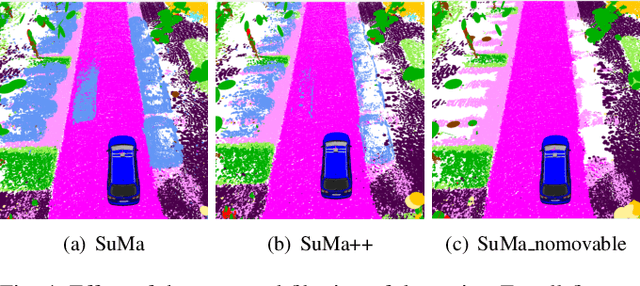
Reliable and accurate localization and mapping are key components of most autonomous systems. Besides geometric information about the mapped environment, the semantics plays an important role to enable intelligent navigation behaviors. In most realistic environments, this task is particularly complicated due to dynamics caused by moving objects, which can corrupt the mapping step or derail localization. In this paper, we propose an extension of a recently published surfel-based mapping approach exploiting three-dimensional laser range scans by integrating semantic information to facilitate the mapping process. The semantic information is efficiently extracted by a fully convolutional neural network and rendered on a spherical projection of the laser range data. This computed semantic segmentation results in point-wise labels for the whole scan, allowing us to build a semantically-enriched map with labeled surfels. This semantic map enables us to reliably filter moving objects, but also improve the projective scan matching via semantic constraints. Our experimental evaluation on challenging highways sequences from KITTI dataset with very few static structures and a large amount of moving cars shows the advantage of our semantic SLAM approach in comparison to a purely geometric, state-of-the-art approach.
HANet: Hierarchical Alignment Networks for Video-Text Retrieval
Jul 26, 2021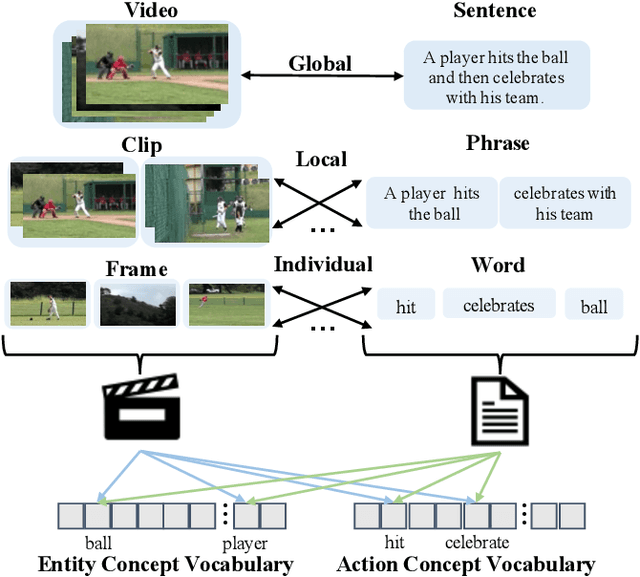
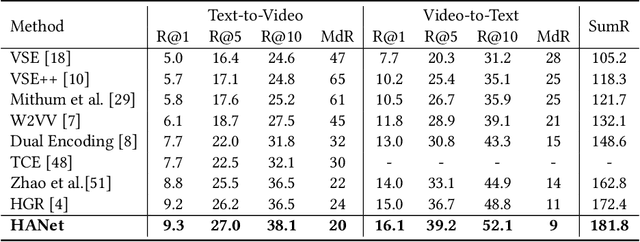
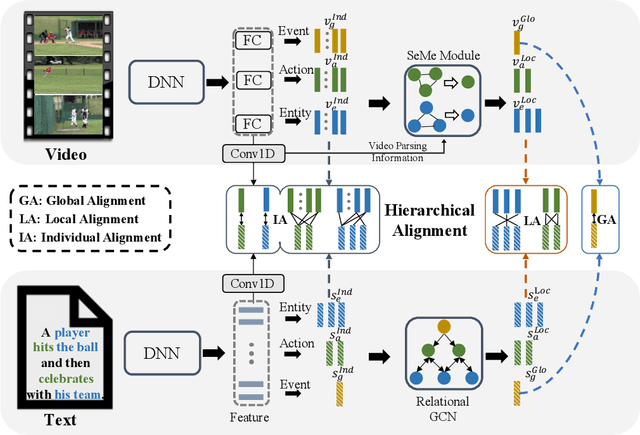
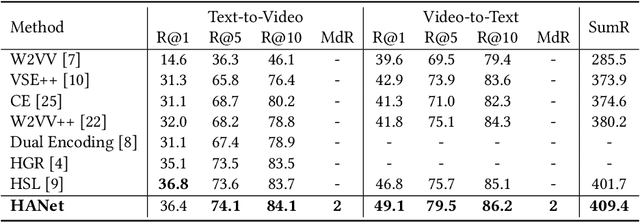
Video-text retrieval is an important yet challenging task in vision-language understanding, which aims to learn a joint embedding space where related video and text instances are close to each other. Most current works simply measure the video-text similarity based on video-level and text-level embeddings. However, the neglect of more fine-grained or local information causes the problem of insufficient representation. Some works exploit the local details by disentangling sentences, but overlook the corresponding videos, causing the asymmetry of video-text representation. To address the above limitations, we propose a Hierarchical Alignment Network (HANet) to align different level representations for video-text matching. Specifically, we first decompose video and text into three semantic levels, namely event (video and text), action (motion and verb), and entity (appearance and noun). Based on these, we naturally construct hierarchical representations in the individual-local-global manner, where the individual level focuses on the alignment between frame and word, local level focuses on the alignment between video clip and textual context, and global level focuses on the alignment between the whole video and text. Different level alignments capture fine-to-coarse correlations between video and text, as well as take the advantage of the complementary information among three semantic levels. Besides, our HANet is also richly interpretable by explicitly learning key semantic concepts. Extensive experiments on two public datasets, namely MSR-VTT and VATEX, show the proposed HANet outperforms other state-of-the-art methods, which demonstrates the effectiveness of hierarchical representation and alignment. Our code is publicly available.
LSB: Local Self-Balancing MCMC in Discrete Spaces
Sep 08, 2021

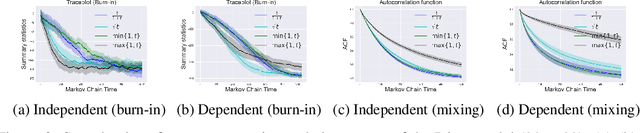

Markov Chain Monte Carlo (MCMC) methods are promising solutions to sample from target distributions in high dimensions. While MCMC methods enjoy nice theoretical properties, like guaranteed convergence and mixing to the true target, in practice their sampling efficiency depends on the choice of the proposal distribution and the target at hand. This work considers using machine learning to adapt the proposal distribution to the target, in order to improve the sampling efficiency in the purely discrete domain. Specifically, (i) it proposes a new parametrization for a family of proposal distributions, called locally balanced proposals, (ii) it defines an objective function based on mutual information and (iii) it devises a learning procedure to adapt the parameters of the proposal to the target, thus achieving fast convergence and fast mixing. We call the resulting sampler as the Locally Self-Balancing Sampler (LSB). We show through experimental analysis on the Ising model and Bayesian networks that LSB is indeed able to improve the efficiency over a state-of-the-art sampler based on locally balanced proposals, thus reducing the number of iterations required to converge, while achieving comparable mixing performance.
Training a Deep Neural Network via Policy Gradients for Blind Source Separation in Polyphonic Music Recordings
Jul 09, 2021
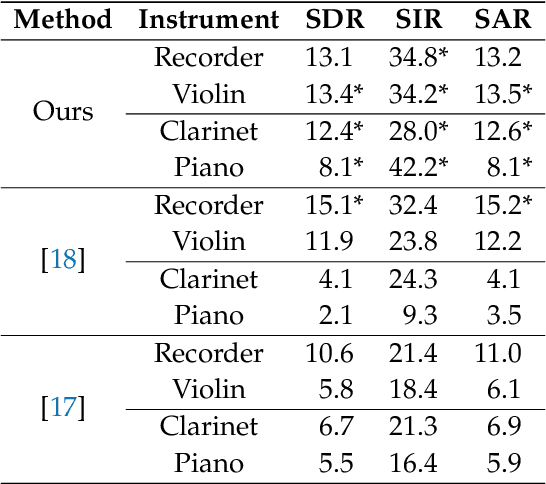
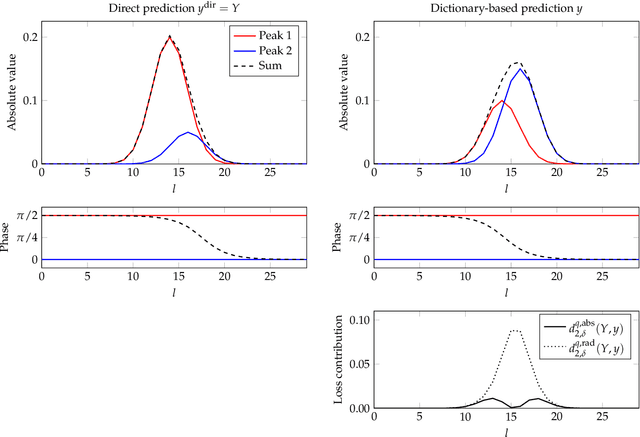
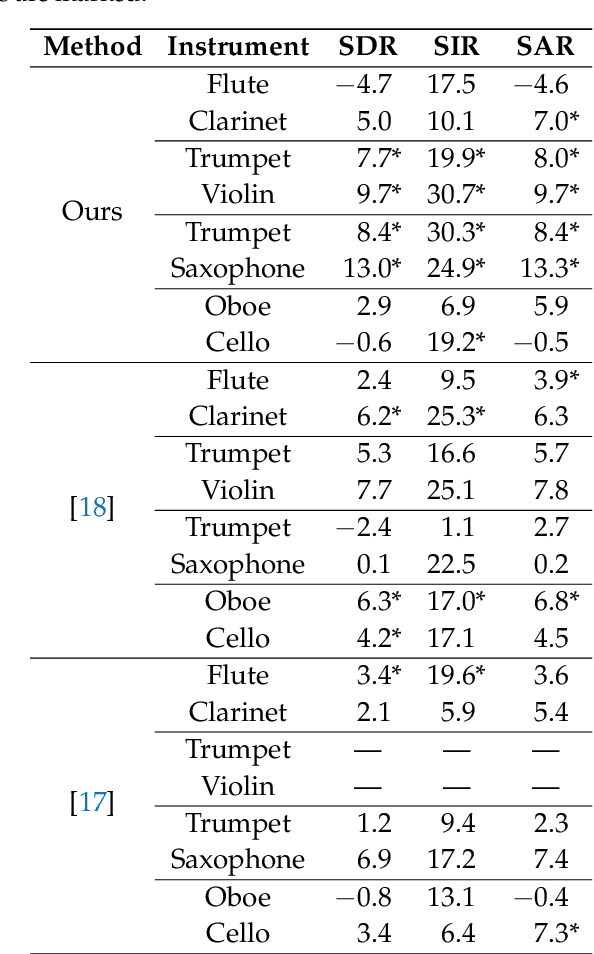
We propose a method for the blind separation of sounds of musical instruments in audio signals. We describe the individual tones via a parametric model, training a dictionary to capture the relative amplitudes of the harmonics. The model parameters are predicted via a U-Net, which is a type of deep neural network. The network is trained without ground truth information, based on the difference between the model prediction and the individual STFT time frames. Since some of the model parameters do not yield a useful backpropagation gradient, we model them stochastically and employ the policy gradient instead. To provide phase information and account for inaccuracies in the dictionary-based representation, we also let the network output a direct prediction, which we then use to resynthesize the audio signals for the individual instruments. Due to the flexibility of the neural network, inharmonicity can be incorporated seamlessly and no preprocessing of the input spectra is required. Our algorithm yields high-quality separation results with particularly low interference on a variety of different audio samples, both acoustic and synthetic, provided that the sample contains enough data for the training and that the spectral characteristics of the musical instruments are sufficiently stable to be approximated by the dictionary.
Multimodal Entity Linking for Tweets
Apr 07, 2021

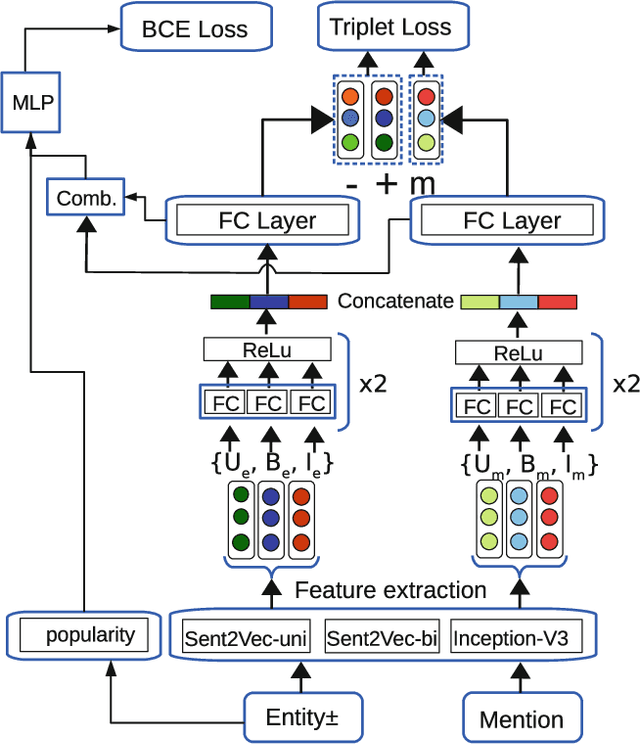

In many information extraction applications, entity linking (EL) has emerged as a crucial task that allows leveraging information about named entities from a knowledge base. In this paper, we address the task of multimodal entity linking (MEL), an emerging research field in which textual and visual information is used to map an ambiguous mention to an entity in a knowledge base (KB). First, we propose a method for building a fully annotated Twitter dataset for MEL, where entities are defined in a Twitter KB. Then, we propose a model for jointly learning a representation of both mentions and entities from their textual and visual contexts. We demonstrate the effectiveness of the proposed model by evaluating it on the proposed dataset and highlight the importance of leveraging visual information when it is available.
Review of Visual Saliency Detection with Comprehensive Information
Sep 14, 2018



Visual saliency detection model simulates the human visual system to perceive the scene, and has been widely used in many vision tasks. With the acquisition technology development, more comprehensive information, such as depth cue, inter-image correspondence, or temporal relationship, is available to extend image saliency detection to RGBD saliency detection, co-saliency detection, or video saliency detection. RGBD saliency detection model focuses on extracting the salient regions from RGBD images by combining the depth information. Co-saliency detection model introduces the inter-image correspondence constraint to discover the common salient object in an image group. The goal of video saliency detection model is to locate the motion-related salient object in video sequences, which considers the motion cue and spatiotemporal constraint jointly. In this paper, we review different types of saliency detection algorithms, summarize the important issues of the existing methods, and discuss the existent problems and future works. Moreover, the evaluation datasets and quantitative measurements are briefly introduced, and the experimental analysis and discission are conducted to provide a holistic overview of different saliency detection methods.
Detecting Personality and Emotion Traits in Crowds from Video Sequences
Apr 27, 2021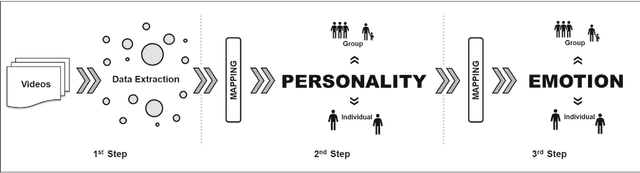
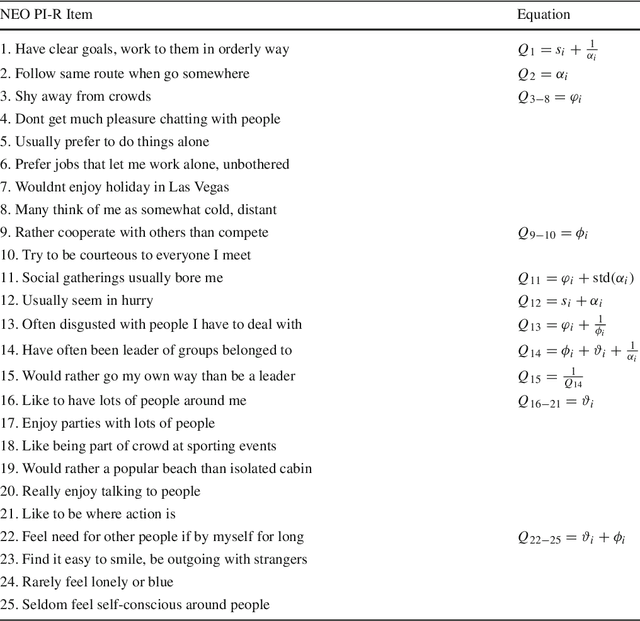
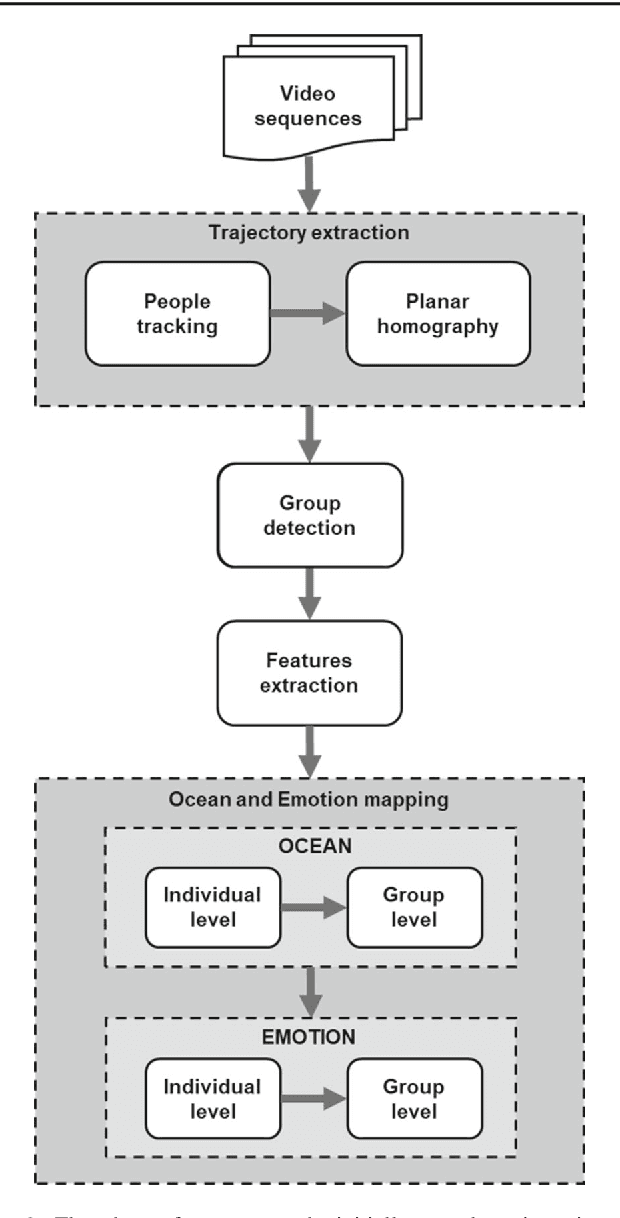

This paper presents a methodology to detect personality and basic emotion characteristics of crowds in video sequences. Firstly, individuals are detected and tracked, then groups are recognized and characterized. Such information is then mapped to OCEAN dimensions, used to find out personality and emotion in videos, based on OCC emotion models. Although it is a clear challenge to validate our results with real life experiments, we evaluate our method with the available literature information regarding OCEAN values of different Countries and also emergent Personal distance among people. Hence, such analysis refer to cultural differences of each country too. Our results indicate that this model generates coherent information when compared to data provided in available literature, as shown in qualitative and quantitative results.
Application of Monte Carlo Stochastic Optimization (MOST) to Deep Learning
Sep 02, 2021
In this paper, we apply the Monte Carlo stochastic optimization (MOST) proposed by the authors to a deep learning of XOR gate and verify its effectiveness. Deep machine learning based on neural networks is one of the most important keywords driving innovation in today's highly advanced information society. Therefore, there has been active research on large-scale, high-speed, and high-precision systems. For the purpose of efficiently searching the optimum value of the objective function, the author divides the search region of a multivariable parameter constituting the objective function into two by each parameter, numerically finds the integration of the two regions by the Monte Carlo method, compares the magnitude of the integration value, and judges that there is an optimum point in a small region. In the previous paper, we examined the problem of the benchmark in the optimization method. This method is applied to neural networks of XOR gate, and compared with the results of weight factor optimization by Adam and genetic algorithm. As a result, it was confirmed that it converged faster than the existing method.
Sample and Communication-Efficient Decentralized Actor-Critic Algorithms with Finite-Time Analysis
Sep 08, 2021
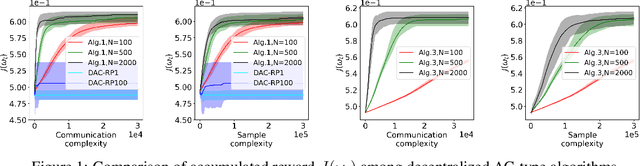
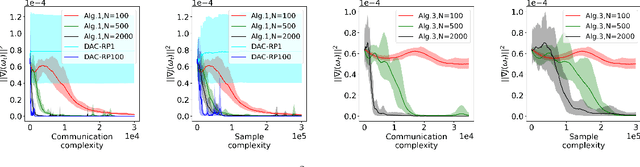
Actor-critic (AC) algorithms have been widely adopted in decentralized multi-agent systems to learn the optimal joint control policy. However, existing decentralized AC algorithms either do not preserve the privacy of agents or are not sample and communication-efficient. In this work, we develop two decentralized AC and natural AC (NAC) algorithms that are private, and sample and communication-efficient. In both algorithms, agents share noisy information to preserve privacy and adopt mini-batch updates to improve sample and communication efficiency. Particularly for decentralized NAC, we develop a decentralized Markovian SGD algorithm with an adaptive mini-batch size to efficiently compute the natural policy gradient. Under Markovian sampling and linear function approximation, we prove the proposed decentralized AC and NAC algorithms achieve the state-of-the-art sample complexities $\mathcal{O}\big(\epsilon^{-2}\ln(\epsilon^{-1})\big)$ and $\mathcal{O}\big(\epsilon^{-3}\ln(\epsilon^{-1})\big)$, respectively, and the same small communication complexity $\mathcal{O}\big(\epsilon^{-1}\ln(\epsilon^{-1})\big)$. Numerical experiments demonstrate that the proposed algorithms achieve lower sample and communication complexities than the existing decentralized AC algorithm.