 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Cognitive Regularizer for Language Modeling
Jun 10, 2021
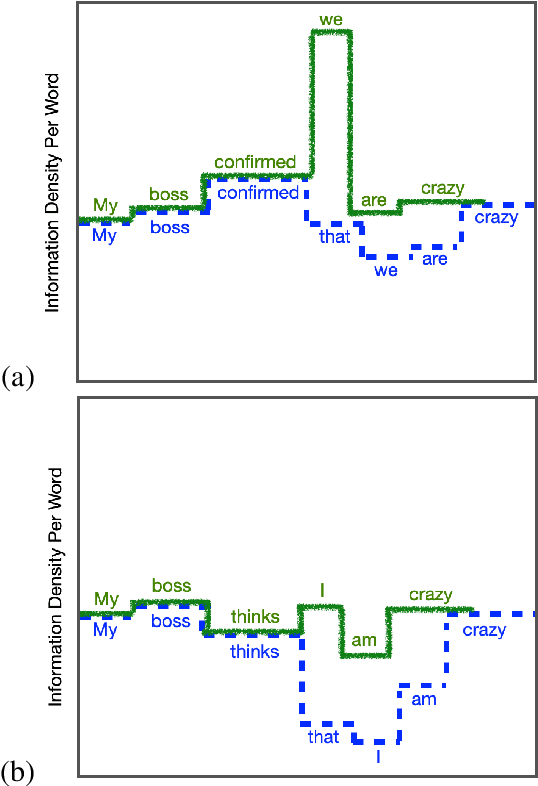
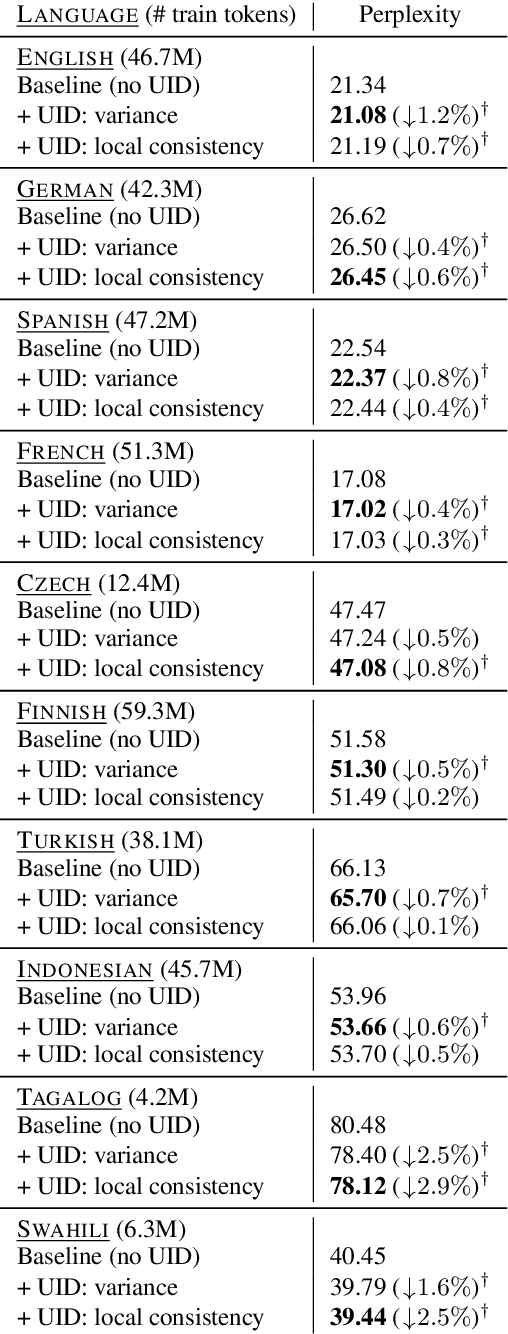
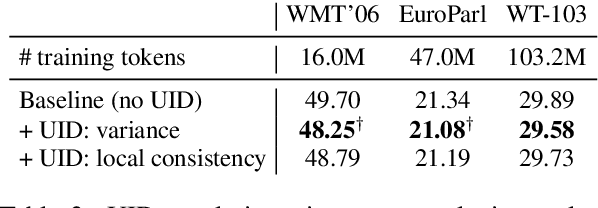
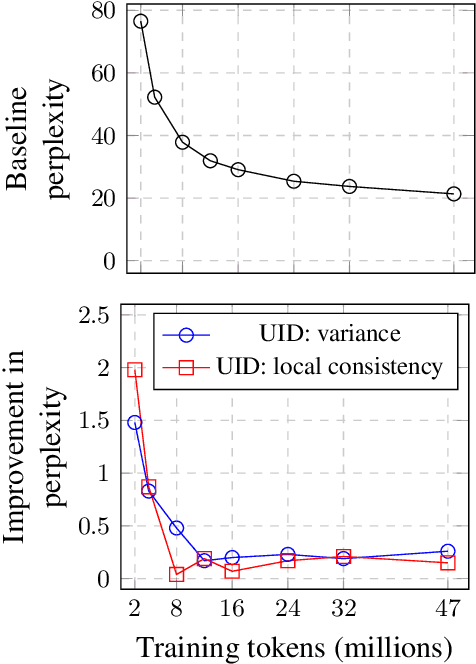
The uniform information density (UID) hypothesis, which posits that speakers behaving optimally tend to distribute information uniformly across a linguistic signal, has gained traction in psycholinguistics as an explanation for certain syntactic, morphological, and prosodic choices. In this work, we explore whether the UID hypothesis can be operationalized as an inductive bias for statistical language modeling. Specifically, we augment the canonical MLE objective for training language models with a regularizer that encodes UID. In experiments on ten languages spanning five language families, we find that using UID regularization consistently improves perplexity in language models, having a larger effect when training data is limited. Moreover, via an analysis of generated sequences, we find that UID-regularized language models have other desirable properties, e.g., they generate text that is more lexically diverse. Our results not only suggest that UID is a reasonable inductive bias for language modeling, but also provide an alternative validation of the UID hypothesis using modern-day NLP tools.
Syntactic Patterns Improve Information Extraction for Medical Search
Apr 30, 2018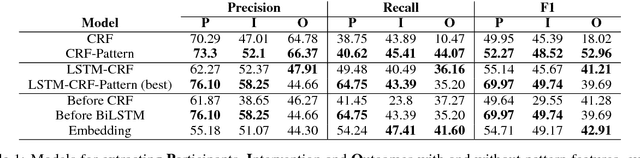
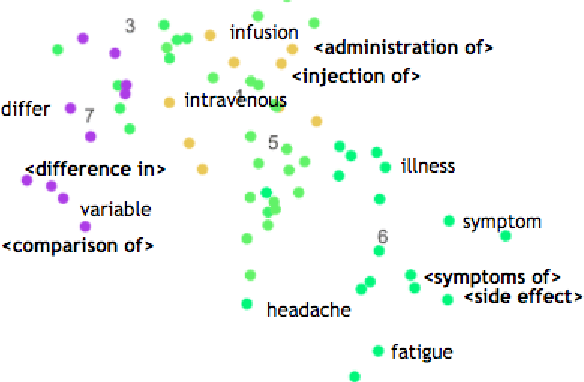


Medical professionals search the published literature by specifying the type of patients, the medical intervention(s) and the outcome measure(s) of interest. In this paper we demonstrate how features encoding syntactic patterns improve the performance of state-of-the-art sequence tagging models (both linear and neural) for information extraction of these medically relevant categories. We present an analysis of the type of patterns exploited, and the semantic space induced for these, i.e., the distributed representations learned for identified multi-token patterns. We show that these learned representations differ substantially from those of the constituent unigrams, suggesting that the patterns capture contextual information that is otherwise lost.
Generating Master Faces for Dictionary Attacks with a Network-Assisted Latent Space Evolution
Aug 01, 2021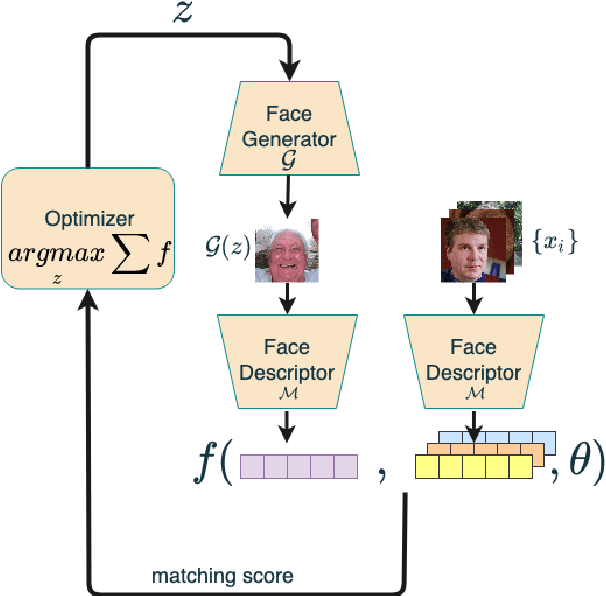


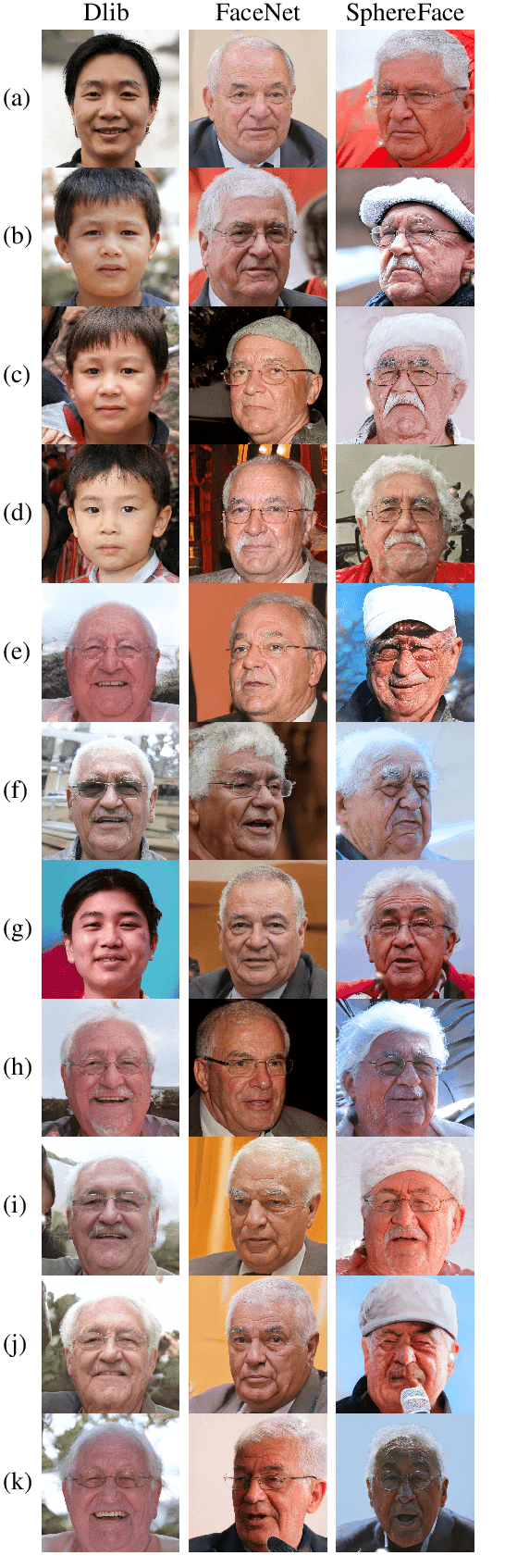
A master face is a face image that passes face-based identity-authentication for a large portion of the population. These faces can be used to impersonate, with a high probability of success, any user, without having access to any user information. We optimize these faces, by using an evolutionary algorithm in the latent embedding space of the StyleGAN face generator. Multiple evolutionary strategies are compared, and we propose a novel approach that employs a neural network in order to direct the search in the direction of promising samples, without adding fitness evaluations. The results we present demonstrate that it is possible to obtain a high coverage of the population (over 40%) with less than 10 master faces, for three leading deep face recognition systems.
Geodesy of irregular small bodies via neural density fields: geodesyNets
May 27, 2021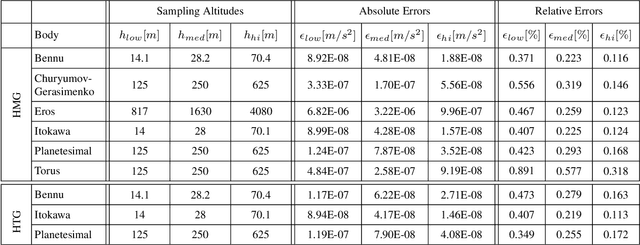
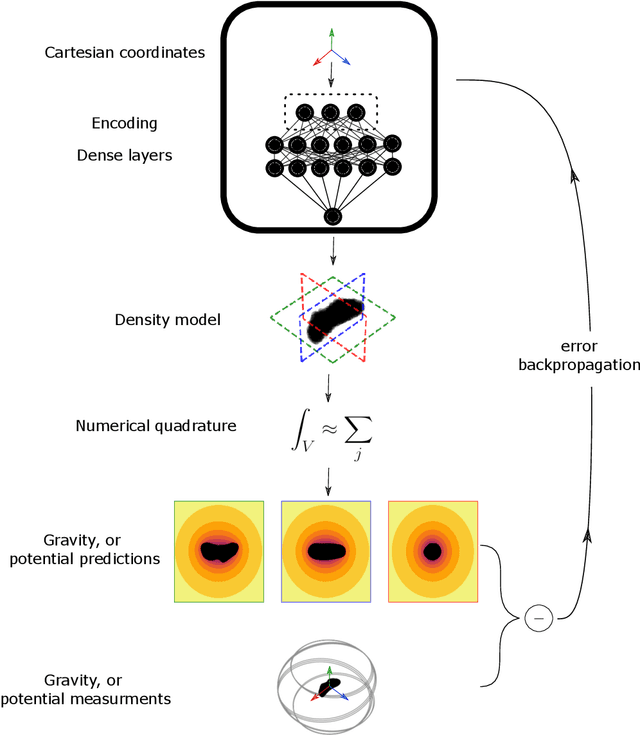

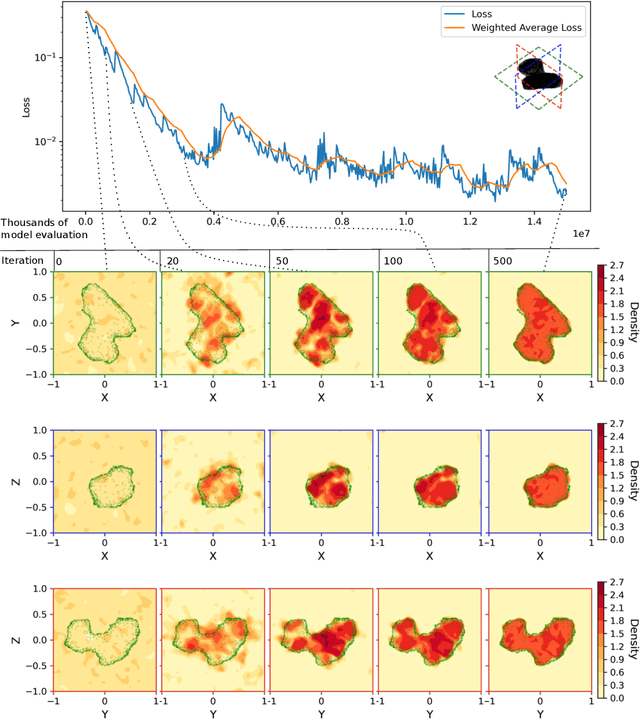
We present a novel approach based on artificial neural networks, so-called geodesyNets, and present compelling evidence of their ability to serve as accurate geodetic models of highly irregular bodies using minimal prior information on the body. The approach does not rely on the body shape information but, if available, can harness it. GeodesyNets learn a three-dimensional, differentiable, function representing the body density, which we call neural density field. The body shape, as well as other geodetic properties, can easily be recovered. We investigate six different shapes including the bodies 101955 Bennu, 67P Churyumov-Gerasimenko, 433 Eros and 25143 Itokawa for which shape models developed during close proximity surveys are available. Both heterogeneous and homogeneous mass distributions are considered. The gravitational acceleration computed from the trained geodesyNets models, as well as the inferred body shape, show great accuracy in all cases with a relative error on the predicted acceleration smaller than 1\% even close to the asteroid surface. When the body shape information is available, geodesyNets can seamlessly exploit it and be trained to represent a high-fidelity neural density field able to give insights into the internal structure of the body. This work introduces a new unexplored approach to geodesy, adding a powerful tool to consolidated ones based on spherical harmonics, mascon models and polyhedral gravity.
Graph Laplacian Diffusion Localization of Connected and Automated Vehicles
Aug 24, 2021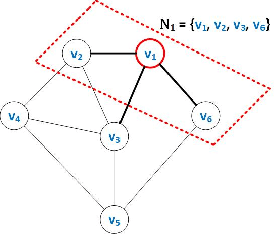
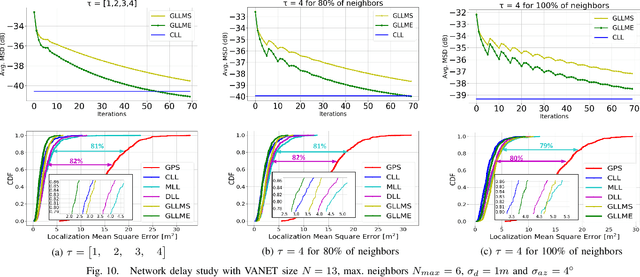
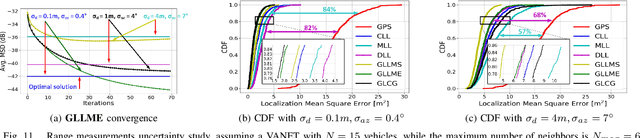
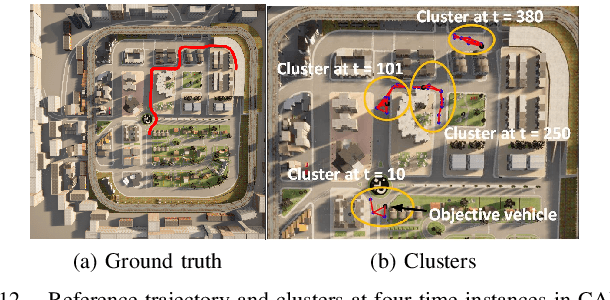
In this paper, we design distributed multi-modal localization approaches for Connected and Automated vehicles. We utilize information diffusion on graphs formed by moving vehicles, based on Adapt-then-Combine strategies combined with the Least-Mean-Squares and the Conjugate Gradient algorithms. We treat the vehicular network as an undirected graph, where vehicles communicate with each other by means of Vehicle-to- Vehicle communication protocols. Connected vehicles perform cooperative fusion of different measurement modalities, including location and range measurements, in order to estimate both their positions and the positions of all other networked vehicles, by interacting only with their local neighborhood. The trajectories of vehicles were generated either by a well-known kinematic model, or by using the CARLA autonomous driving simulator. The various proposed distributed and diffusion localization schemes significantly reduce the GPS error and do not only converge to the global solution, but they even outperformed it. Extensive simulation studies highlight the benefits of the various approaches, outperforming the accuracy of the state of the art approaches. The impact of the network connections and the network latency are also investigated.
Spoken Moments: Learning Joint Audio-Visual Representations from Video Descriptions
May 10, 2021

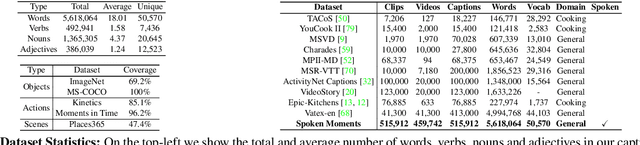
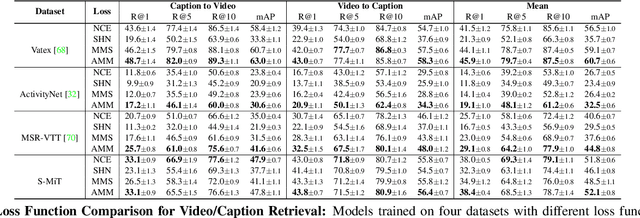
When people observe events, they are able to abstract key information and build concise summaries of what is happening. These summaries include contextual and semantic information describing the important high-level details (what, where, who and how) of the observed event and exclude background information that is deemed unimportant to the observer. With this in mind, the descriptions people generate for videos of different dynamic events can greatly improve our understanding of the key information of interest in each video. These descriptions can be captured in captions that provide expanded attributes for video labeling (e.g. actions/objects/scenes/sentiment/etc.) while allowing us to gain new insight into what people find important or necessary to summarize specific events. Existing caption datasets for video understanding are either small in scale or restricted to a specific domain. To address this, we present the Spoken Moments (S-MiT) dataset of 500k spoken captions each attributed to a unique short video depicting a broad range of different events. We collect our descriptions using audio recordings to ensure that they remain as natural and concise as possible while allowing us to scale the size of a large classification dataset. In order to utilize our proposed dataset, we present a novel Adaptive Mean Margin (AMM) approach to contrastive learning and evaluate our models on video/caption retrieval on multiple datasets. We show that our AMM approach consistently improves our results and that models trained on our Spoken Moments dataset generalize better than those trained on other video-caption datasets.
Vietnamese Open Information Extraction
Jan 23, 2018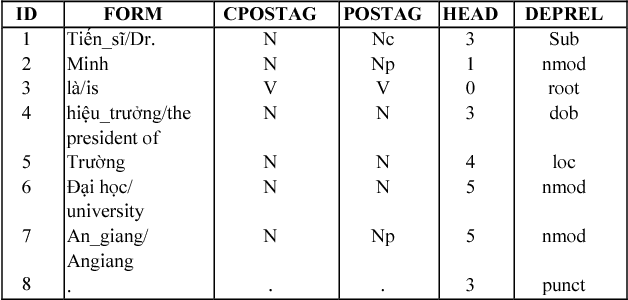
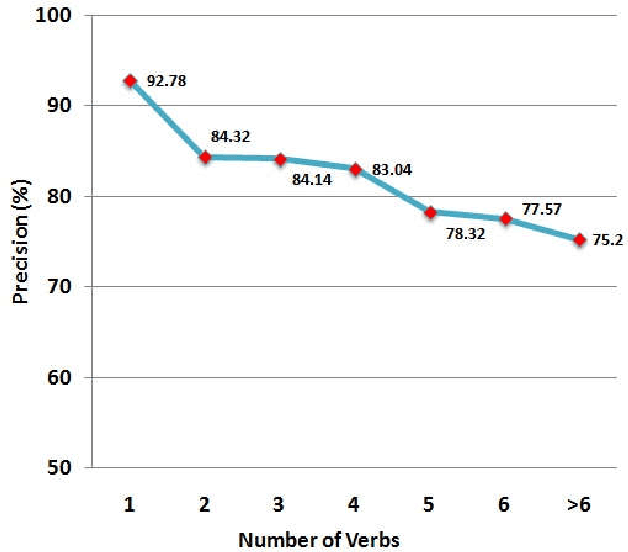
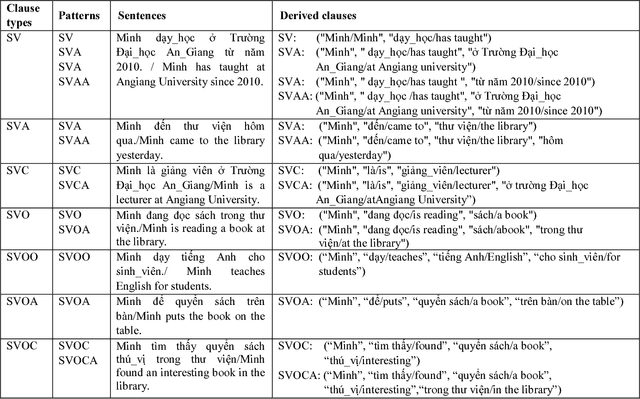
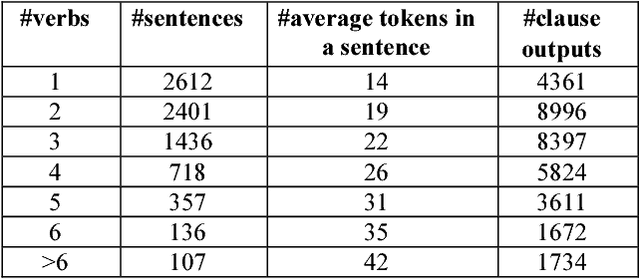
Open information extraction (OIE) is the process to extract relations and their arguments automatically from textual documents without the need to restrict the search to predefined relations. In recent years, several OIE systems for the English language have been created but there is not any system for the Vietnamese language. In this paper, we propose a method of OIE for Vietnamese using a clause-based approach. Accordingly, we exploit Vietnamese dependency parsing using grammar clauses that strives to consider all possible relations in a sentence. The corresponding clause types are identified by their propositions as extractable relations based on their grammatical functions of constituents. As a result, our system is the first OIE system named vnOIE for the Vietnamese language that can generate open relations and their arguments from Vietnamese text with highly scalable extraction while being domain independent. Experimental results show that our OIE system achieves promising results with a precision of 83.71%.
Hop-Count Based Self-Supervised Anomaly Detection on Attributed Networks
Apr 16, 2021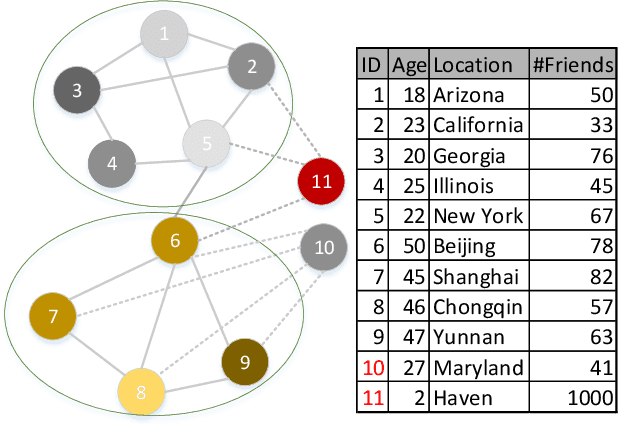
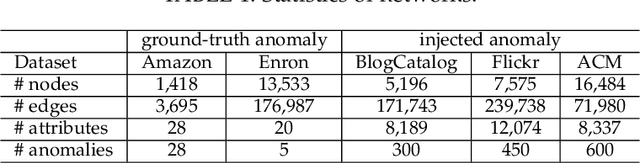
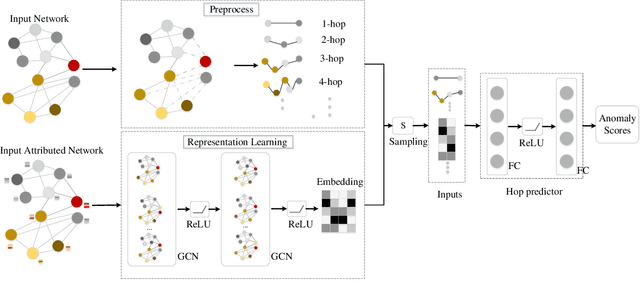
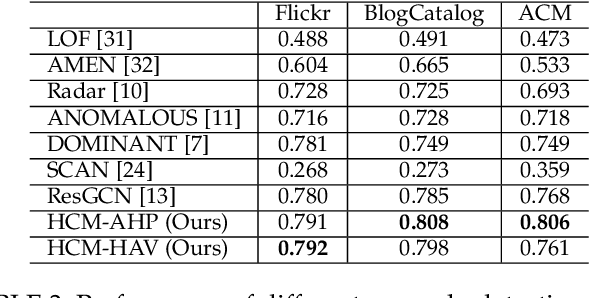
Recent years have witnessed an upsurge of interest in the problem of anomaly detection on attributed networks due to its importance in both research and practice. Although various approaches have been proposed to solve this problem, two major limitations exist: (1) unsupervised approaches usually work much less efficiently due to the lack of supervisory signal, and (2) existing anomaly detection methods only use local contextual information to detect anomalous nodes, e.g., one- or two-hop information, but ignore the global contextual information. Since anomalous nodes differ from normal nodes in structures and attributes, it is intuitive that the distance between anomalous nodes and their neighbors should be larger than that between normal nodes and their neighbors if we remove the edges connecting anomalous and normal nodes. Thus, hop counts based on both global and local contextual information can be served as the indicators of anomaly. Motivated by this intuition, we propose a hop-count based model (HCM) to detect anomalies by modeling both local and global contextual information. To make better use of hop counts for anomaly identification, we propose to use hop counts prediction as a self-supervised task. We design two anomaly scores based on the hop counts prediction via HCM model to identify anomalies. Besides, we employ Bayesian learning to train HCM model for capturing uncertainty in learned parameters and avoiding overfitting. Extensive experiments on real-world attributed networks demonstrate that our proposed model is effective in anomaly detection.
PnP-DETR: Towards Efficient Visual Analysis with Transformers
Sep 16, 2021
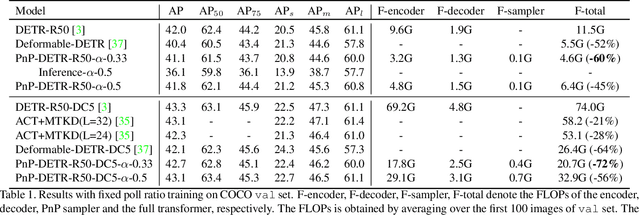
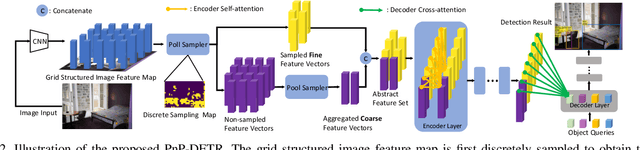

Recently, DETR pioneered the solution of vision tasks with transformers, it directly translates the image feature map into the object detection result. Though effective, translating the full feature map can be costly due to redundant computation on some area like the background. In this work, we encapsulate the idea of reducing spatial redundancy into a novel poll and pool (PnP) sampling module, with which we build an end-to-end PnP-DETR architecture that adaptively allocates its computation spatially to be more efficient. Concretely, the PnP module abstracts the image feature map into fine foreground object feature vectors and a small number of coarse background contextual feature vectors. The transformer models information interaction within the fine-coarse feature space and translates the features into the detection result. Moreover, the PnP-augmented model can instantly achieve various desired trade-offs between performance and computation with a single model by varying the sampled feature length, without requiring to train multiple models as existing methods. Thus it offers greater flexibility for deployment in diverse scenarios with varying computation constraint. We further validate the generalizability of the PnP module on panoptic segmentation and the recent transformer-based image recognition model ViT and show consistent efficiency gain. We believe our method makes a step for efficient visual analysis with transformers, wherein spatial redundancy is commonly observed. Code will be available at \url{https://github.com/twangnh/pnp-detr}.
Prompt-Learning for Fine-Grained Entity Typing
Aug 24, 2021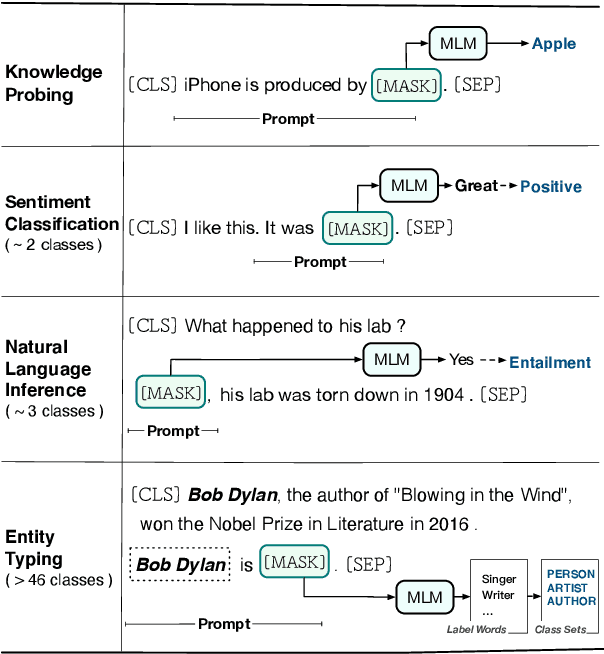


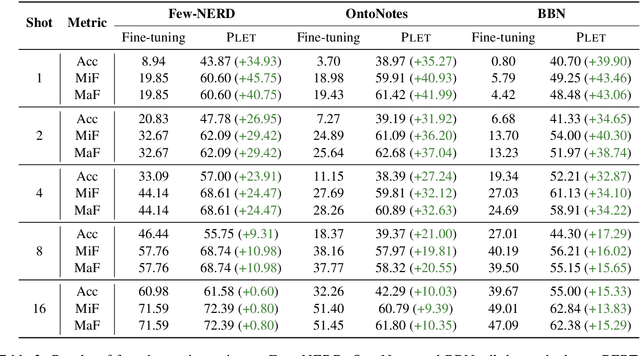
As an effective approach to tune pre-trained language models (PLMs) for specific tasks, prompt-learning has recently attracted much attention from researchers. By using \textit{cloze}-style language prompts to stimulate the versatile knowledge of PLMs, prompt-learning can achieve promising results on a series of NLP tasks, such as natural language inference, sentiment classification, and knowledge probing. In this work, we investigate the application of prompt-learning on fine-grained entity typing in fully supervised, few-shot and zero-shot scenarios. We first develop a simple and effective prompt-learning pipeline by constructing entity-oriented verbalizers and templates and conducting masked language modeling. Further, to tackle the zero-shot regime, we propose a self-supervised strategy that carries out distribution-level optimization in prompt-learning to automatically summarize the information of entity types. Extensive experiments on three fine-grained entity typing benchmarks (with up to 86 classes) under fully supervised, few-shot and zero-shot settings show that prompt-learning methods significantly outperform fine-tuning baselines, especially when the training data is insufficient.