 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
InfoBot: Transfer and Exploration via the Information Bottleneck
Apr 04, 2019
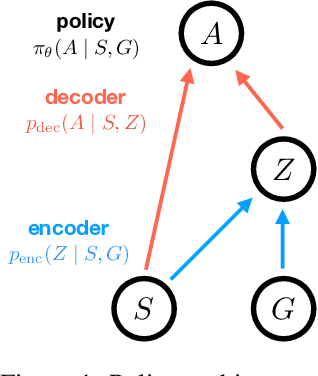



A central challenge in reinforcement learning is discovering effective policies for tasks where rewards are sparsely distributed. We postulate that in the absence of useful reward signals, an effective exploration strategy should seek out {\it decision states}. These states lie at critical junctions in the state space from where the agent can transition to new, potentially unexplored regions. We propose to learn about decision states from prior experience. By training a goal-conditioned policy with an information bottleneck, we can identify decision states by examining where the model actually leverages the goal state. We find that this simple mechanism effectively identifies decision states, even in partially observed settings. In effect, the model learns the sensory cues that correlate with potential subgoals. In new environments, this model can then identify novel subgoals for further exploration, guiding the agent through a sequence of potential decision states and through new regions of the state space.
Membership Inference Attacks on Knowledge Graphs
Apr 16, 2021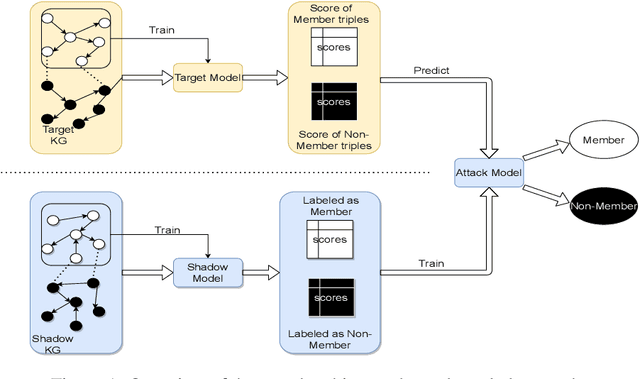
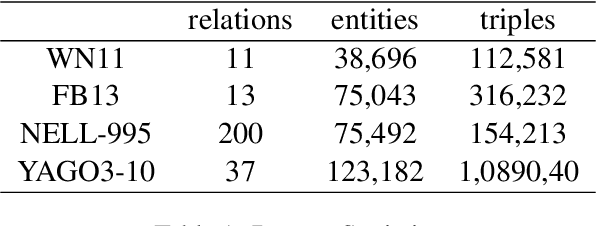

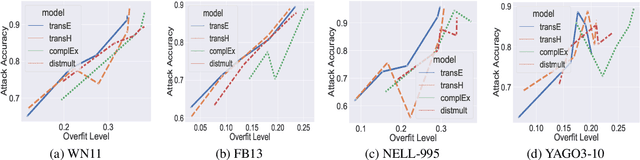
Knowledge graphs have become increasingly popular supplemental information because they represented structural relations between entities. Knowledge graph embedding methods (KGE) are used for various downstream tasks, e.g., knowledge graph completion, including triple classification, link prediction. However, the knowledge graph also includes much sensitive information in the training set, which is very vulnerable to privacy attacks. In this paper, we conduct such one attack, i.e., membership inference attack, on four standard KGE methods to explore the privacy vulnerabilities of knowledge graphs. Our experimental results on four benchmark knowledge graph datasets show that our privacy attacks can reveal the membership information leakage of KGE methods.
Proxy-bridged Image Reconstruction Network for Anomaly Detection in Medical Images
Oct 05, 2021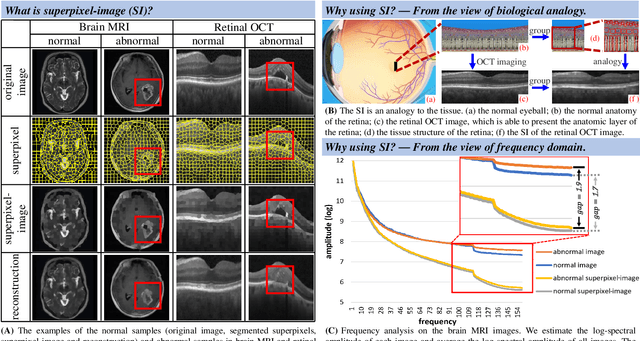
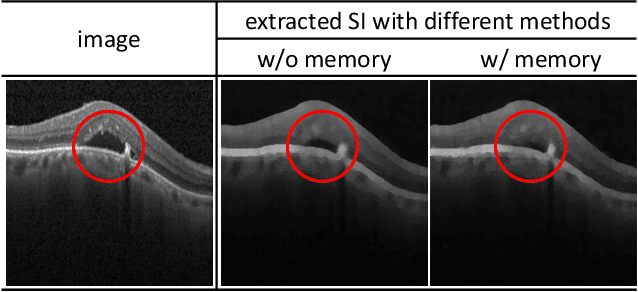
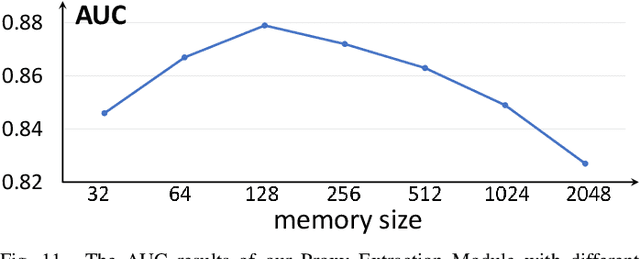
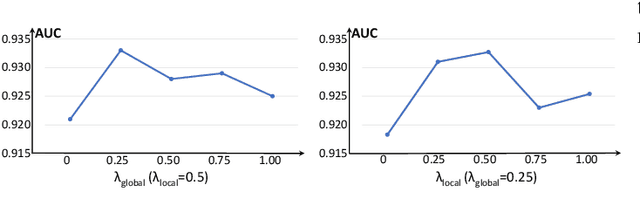
Anomaly detection in medical images refers to the identification of abnormal images with only normal images in the training set. Most existing methods solve this problem with a self-reconstruction framework, which tends to learn an identity mapping and reduces the sensitivity to anomalies. To mitigate this problem, in this paper, we propose a novel Proxy-bridged Image Reconstruction Network (ProxyAno) for anomaly detection in medical images. Specifically, we use an intermediate proxy to bridge the input image and the reconstructed image. We study different proxy types, and we find that the superpixel-image (SI) is the best one. We set all pixels' intensities within each superpixel as their average intensity, and denote this image as SI. The proposed ProxyAno consists of two modules, a Proxy Extraction Module and an Image Reconstruction Module. In the Proxy Extraction Module, a memory is introduced to memorize the feature correspondence for normal image to its corresponding SI, while the memorized correspondence does not apply to the abnormal images, which leads to the information loss for abnormal image and facilitates the anomaly detection. In the Image Reconstruction Module, we map an SI to its reconstructed image. Further, we crop a patch from the image and paste it on the normal SI to mimic the anomalies, and enforce the network to reconstruct the normal image even with the pseudo abnormal SI. In this way, our network enlarges the reconstruction error for anomalies. Extensive experiments on brain MR images, retinal OCT images and retinal fundus images verify the effectiveness of our method for both image-level and pixel-level anomaly detection.
TabPert: An Effective Platform for Tabular Perturbation
Aug 02, 2021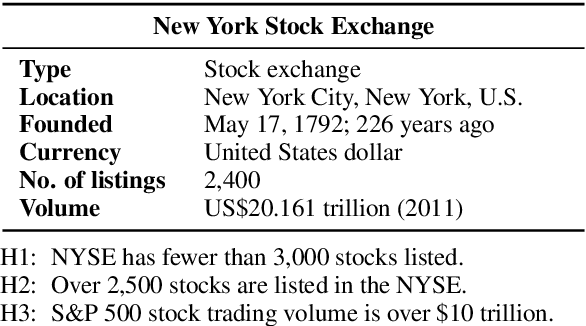
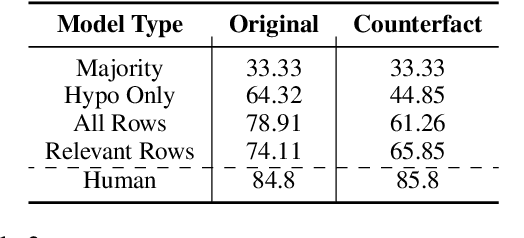
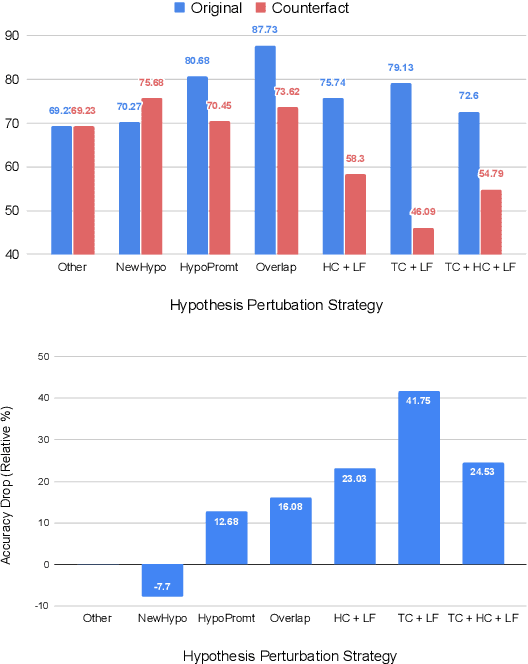
To truly grasp reasoning ability, a Natural Language Inference model should be evaluated on counterfactual data. TabPert facilitates this by assisting in the generation of such counterfactual data for assessing model tabular reasoning issues. TabPert allows a user to update a table, change its associated hypotheses, change their labels, and highlight rows that are important for hypothesis classification. TabPert also captures information about the techniques used to automatically produce the table, as well as the strategies employed to generate the challenging hypotheses. These counterfactual tables and hypotheses, as well as the metadata, can then be used to explore an existing model's shortcomings methodically and quantitatively.
A Synchronized Reprojection-based Model for 3D Human Pose Estimation
Jun 16, 2021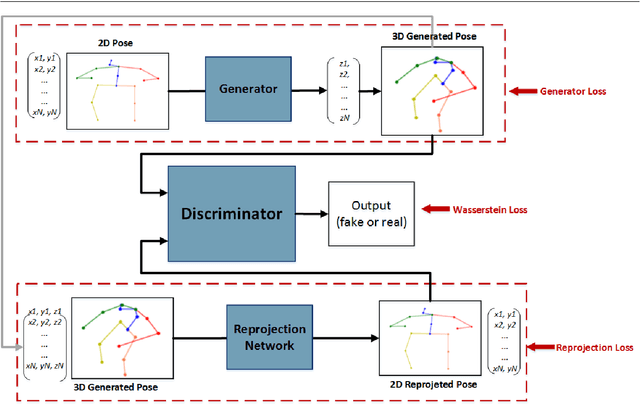
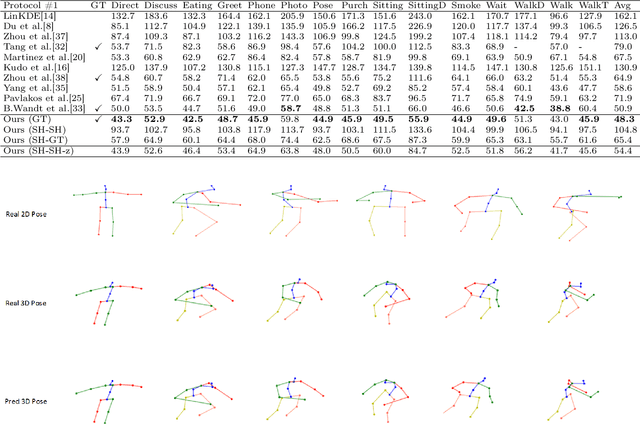
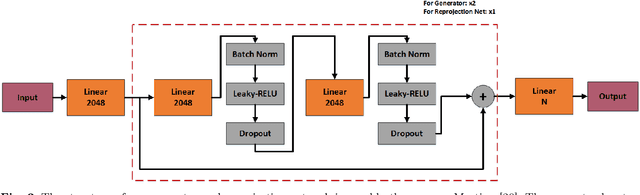
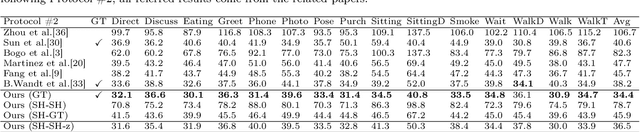
3D human pose estimation is still a challenging problem despite the large amount of work that has been done in this field. Generally, most methods directly use neural networks and ignore certain constraints (e.g., reprojection constraints and joint angle and bone length constraints). This paper proposes a weakly supervised GAN-based model for 3D human pose estimation that considers 3D information along with 2D information simultaneously, in which a reprojection network is employed to learn the mapping of the distribution from 3D poses to 2D poses. In particular, we train the reprojection network and the generative adversarial network synchronously. Furthermore, inspired by the typical kinematic chain space (KCS) matrix, we propose a weighted KCS matrix, which is added into the discriminator's input to impose joint angle and bone length constraints. The experimental results on Human3.6M show that our method outperforms state-of-the-art methods by approximately 5.1\%.
Introducing an Abusive Language Classification Framework for Telegram to Investigate the German Hater Community
Sep 15, 2021
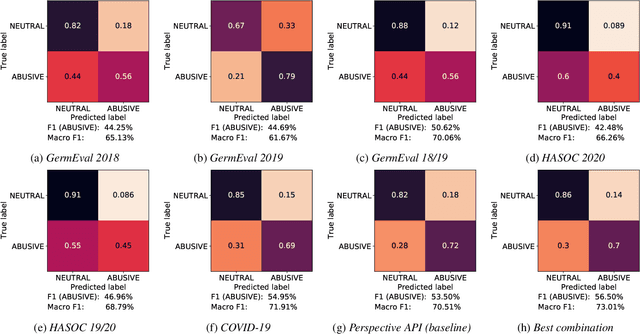
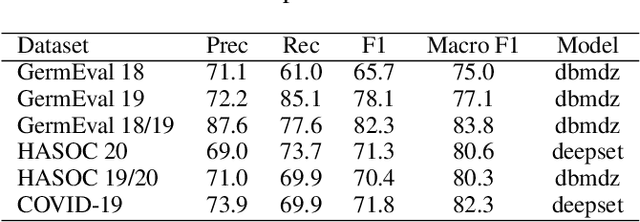
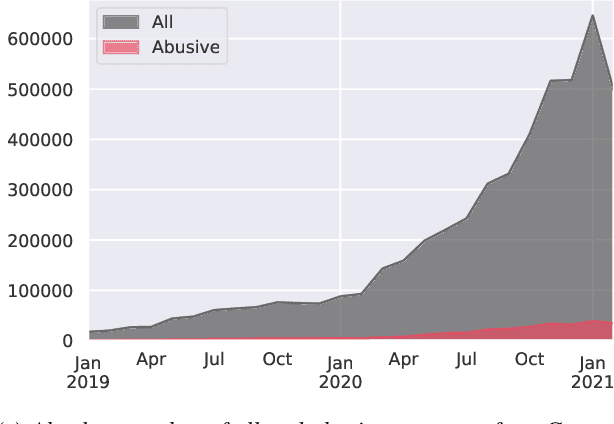
Since traditional social media platforms ban more and more actors that distribute hate speech or other forms of abusive language (deplatforming), these actors migrate to alternative platforms that do not moderate the users' content. One known platform that is relevant for the German hater community is Telegram, for which there have only been made limited research efforts so far. The goal of this study is to develop a broad framework that consists of (i) an abusive language classification model for German Telegram messages and (ii) a classification model for the hatefulness of Telegram channels. For the first part, we employ existing abusive language datasets containing posts from other platforms to build our classification models. For the channel classification model, we develop a method that combines channel specific content information coming from a topic model with a social graph to predict the hatefulness of channels. Furthermore, we complement these two approaches for hate speech detection with insightful results on the evolution of the hater community on Telegram in Germany. Moreover, we propose methods to the hate speech research community for scalable network analyses for social media platforms. As an additional output of the study, we release an annotated abusive language dataset containing 1,149 annotated Telegram messages.
Distribution-free Contextual Dynamic Pricing
Sep 15, 2021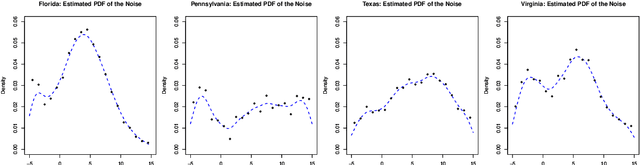

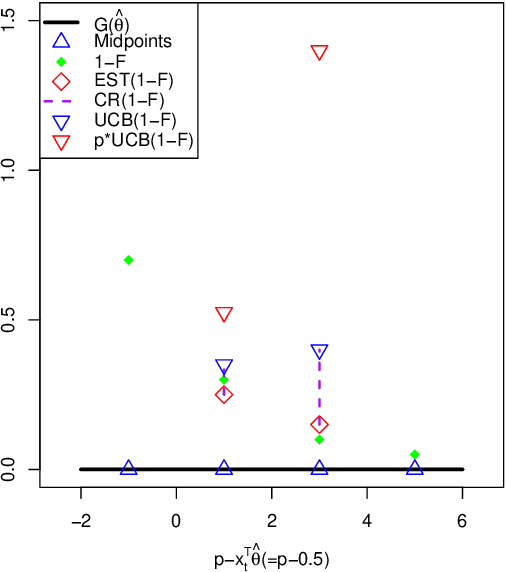
Contextual dynamic pricing aims to set personalized prices based on sequential interactions with customers. At each time period, a customer who is interested in purchasing a product comes to the platform. The customer's valuation for the product is a linear function of contexts, including product and customer features, plus some random market noise. The seller does not observe the customer's true valuation, but instead needs to learn the valuation by leveraging contextual information and historical binary purchase feedbacks. Existing models typically assume full or partial knowledge of the random noise distribution. In this paper, we consider contextual dynamic pricing with unknown random noise in the valuation model. Our distribution-free pricing policy learns both the contextual function and the market noise simultaneously. A key ingredient of our method is a novel perturbed linear bandit framework, where a modified linear upper confidence bound algorithm is proposed to balance the exploration of market noise and the exploitation of the current knowledge for better pricing. We establish the regret upper bound and a matching lower bound of our policy in the perturbed linear bandit framework and prove a sub-linear regret bound in the considered pricing problem. Finally, we demonstrate the superior performance of our policy on simulations and a real-life auto-loan dataset.
MD-CSDNetwork: Multi-Domain Cross Stitched Network for Deepfake Detection
Sep 15, 2021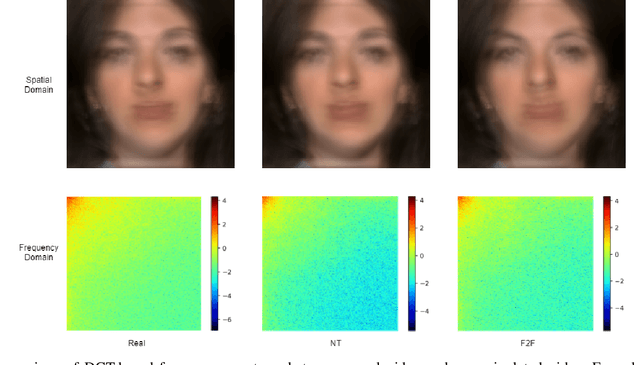
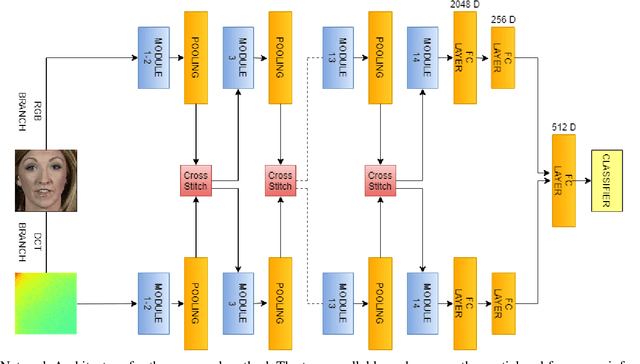
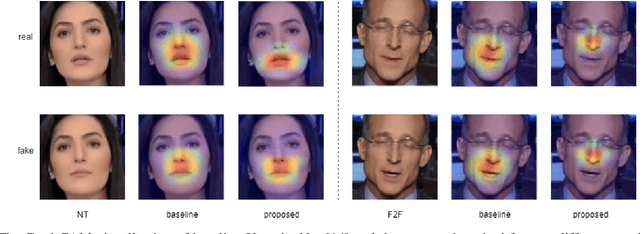
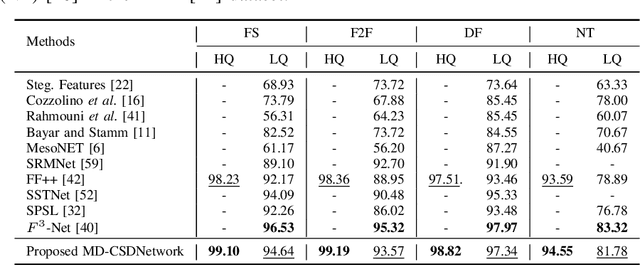
The rapid progress in the ease of creating and spreading ultra-realistic media over social platforms calls for an urgent need to develop a generalizable deepfake detection technique. It has been observed that current deepfake generation methods leave discriminative artifacts in the frequency spectrum of fake images and videos. Inspired by this observation, in this paper, we present a novel approach, termed as MD-CSDNetwork, for combining the features in the spatial and frequency domains to mine a shared discriminative representation for classifying \textit{deepfakes}. MD-CSDNetwork is a novel cross-stitched network with two parallel branches carrying the spatial and frequency information, respectively. We hypothesize that these multi-domain input data streams can be considered as related supervisory signals. The supervision from both branches ensures better performance and generalization. Further, the concept of cross-stitch connections is utilized where they are inserted between the two branches to learn an optimal combination of domain-specific and shared representations from other domains automatically. Extensive experiments are conducted on the popular benchmark dataset namely FaceForeniscs++ for forgery classification. We report improvements over all the manipulation types in FaceForensics++ dataset and comparable results with state-of-the-art methods for cross-database evaluation on the Celeb-DF dataset and the Deepfake Detection Dataset.
Image Captioning for Effective Use of Language Models in Knowledge-Based Visual Question Answering
Sep 15, 2021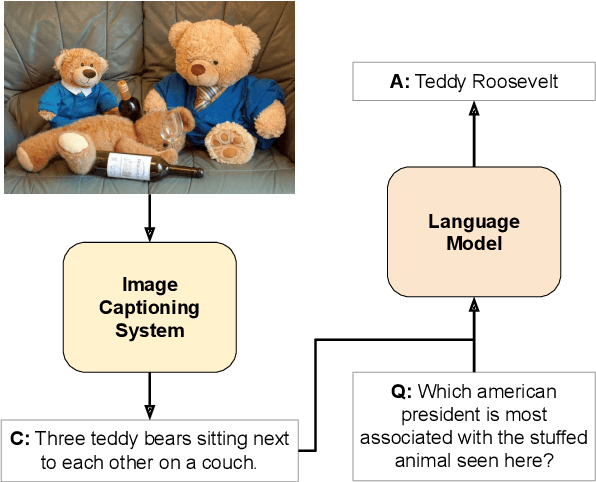



Integrating outside knowledge for reasoning in visio-linguistic tasks such as visual question answering (VQA) is an open problem. Given that pretrained language models have been shown to include world knowledge, we propose to use a unimodal (text-only) train and inference procedure based on automatic off-the-shelf captioning of images and pretrained language models. Our results on a visual question answering task which requires external knowledge (OK-VQA) show that our text-only model outperforms pretrained multimodal (image-text) models of comparable number of parameters. In contrast, our model is less effective in a standard VQA task (VQA 2.0) confirming that our text-only method is specially effective for tasks requiring external knowledge. In addition, we show that our unimodal model is complementary to multimodal models in both OK-VQA and VQA 2.0, and yield the best result to date in OK-VQA among systems not using external knowledge graphs, and comparable to systems that do use them. Our qualitative analysis on OK-VQA reveals that automatic captions often fail to capture relevant information in the images, which seems to be balanced by the better inference ability of the text-only language models. Our work opens up possibilities to further improve inference in visio-linguistic tasks.
Multi-Slice Dense-Sparse Learning for Efficient Liver and Tumor Segmentation
Aug 15, 2021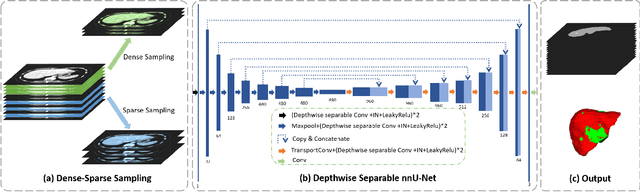
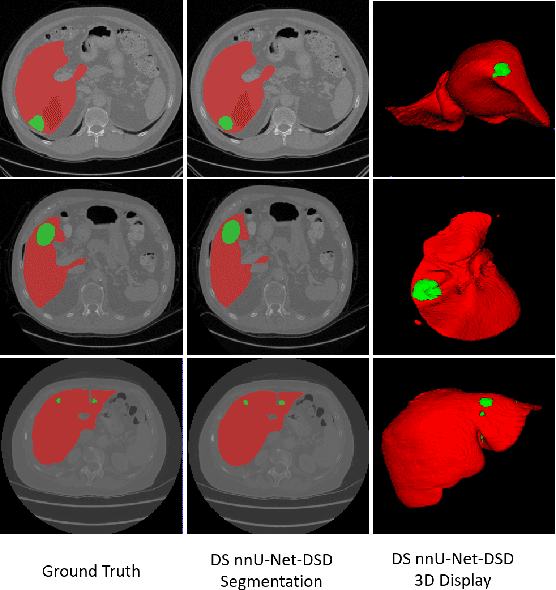
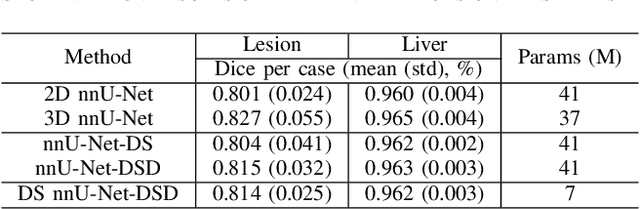
Accurate automatic liver and tumor segmentation plays a vital role in treatment planning and disease monitoring. Recently, deep convolutional neural network (DCNNs) has obtained tremendous success in 2D and 3D medical image segmentation. However, 2D DCNNs cannot fully leverage the inter-slice information, while 3D DCNNs are computationally expensive and memory intensive. To address these issues, we first propose a novel dense-sparse training flow from a data perspective, in which, densely adjacent slices and sparsely adjacent slices are extracted as inputs for regularizing DCNNs, thereby improving the model performance. Moreover, we design a 2.5D light-weight nnU-Net from a network perspective, in which, depthwise separable convolutions are adopted to improve the efficiency. Extensive experiments on the LiTS dataset have demonstrated the superiority of the proposed method.