 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Identity-aware Graph Memory Network for Action Detection
Aug 26, 2021
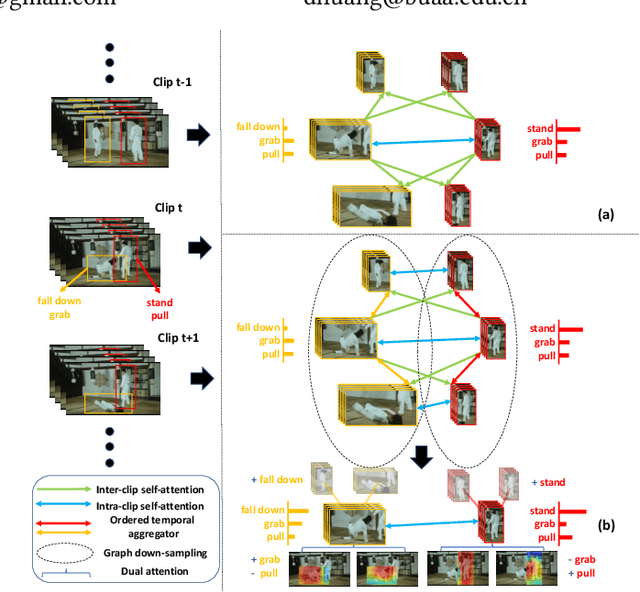
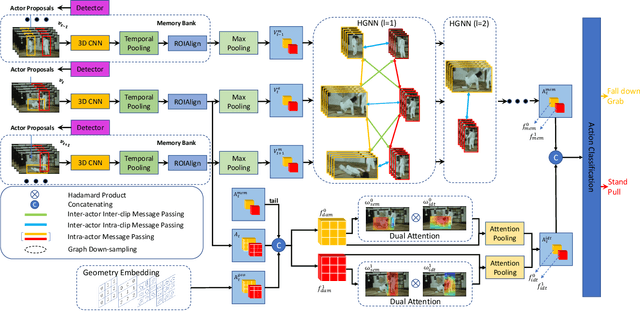
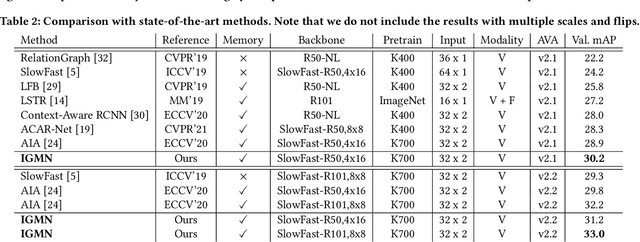
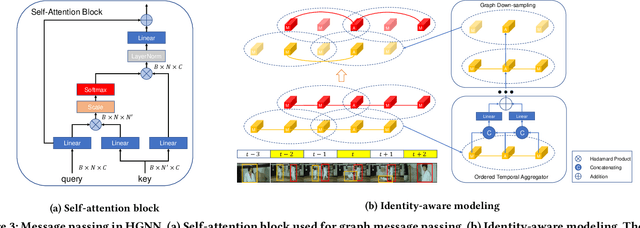
Action detection plays an important role in high-level video understanding and media interpretation. Many existing studies fulfill this spatio-temporal localization by modeling the context, capturing the relationship of actors, objects, and scenes conveyed in the video. However, they often universally treat all the actors without considering the consistency and distinctness between individuals, leaving much room for improvement. In this paper, we explicitly highlight the identity information of the actors in terms of both long-term and short-term context through a graph memory network, namely identity-aware graph memory network (IGMN). Specifically, we propose the hierarchical graph neural network (HGNN) to comprehensively conduct long-term relation modeling within the same identity as well as between different ones. Regarding short-term context, we develop a dual attention module (DAM) to generate identity-aware constraint to reduce the influence of interference by the actors of different identities. Extensive experiments on the challenging AVA dataset demonstrate the effectiveness of our method, which achieves state-of-the-art results on AVA v2.1 and v2.2.
BioNetExplorer: Architecture-Space Exploration of Bio-Signal Processing Deep Neural Networks for Wearables
Sep 07, 2021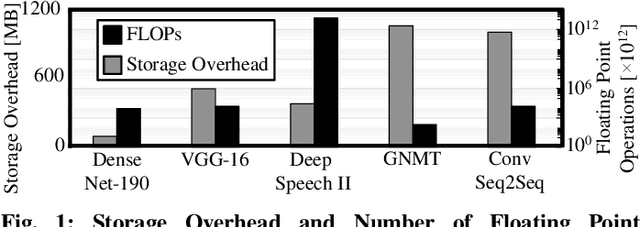
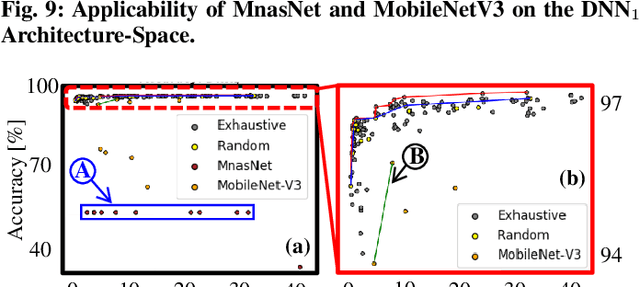
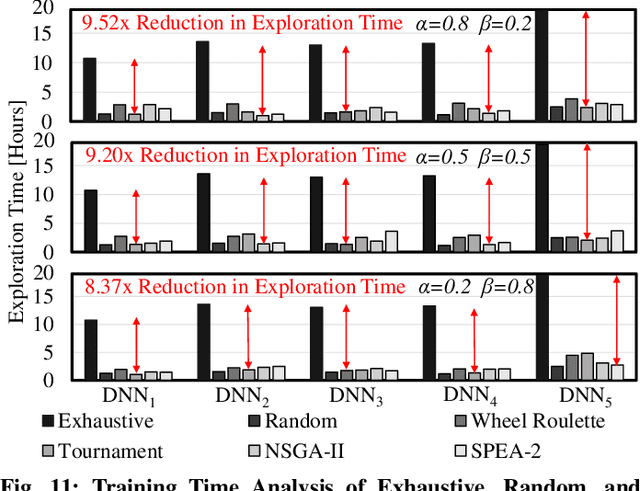
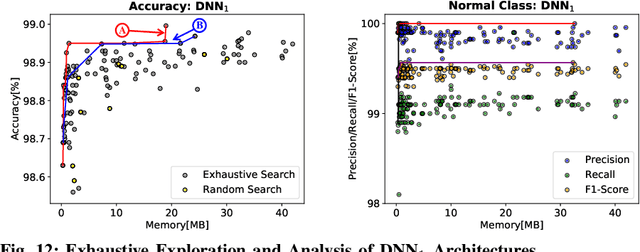
In this work, we propose the BioNetExplorer framework to systematically generate and explore multiple DNN architectures for bio-signal processing in wearables. Our framework adapts key neural architecture parameters to search for an embedded DNN with a low hardware overhead, which can be deployed in wearable edge devices to analyse the bio-signal data and to extract the relevant information, such as arrhythmia and seizure. Our framework also enables hardware-aware DNN architecture search using genetic algorithms by imposing user requirements and hardware constraints (storage, FLOPs, etc.) during the exploration stage, thereby limiting the number of networks explored. Moreover, BioNetExplorer can also be used to search for DNNs based on the user-required output classes; for instance, a user might require a specific output class due to genetic predisposition or a pre-existing heart condition. The use of genetic algorithms reduces the exploration time, on average, by 9x, compared to exhaustive exploration. We are successful in identifying Pareto-optimal designs, which can reduce the storage overhead of the DNN by ~30MB for a quality loss of less than 0.5%. To enable low-cost embedded DNNs, BioNetExplorer also employs different model compression techniques to further reduce the storage overhead of the network by up to 53x for a quality loss of <0.2%.
Information Bottleneck Methods for Distributed Learning
Oct 26, 2018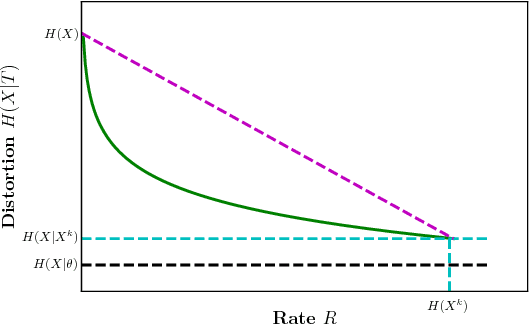
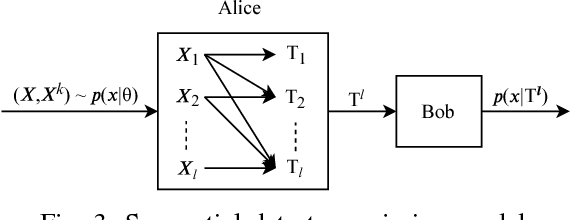
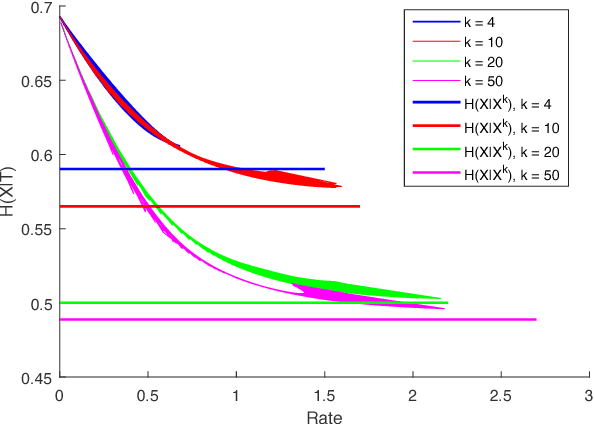
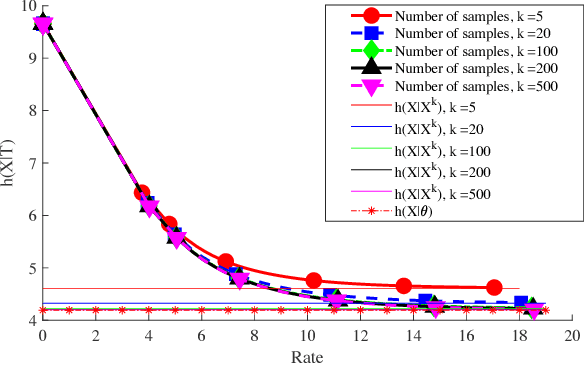
We study a distributed learning problem in which Alice sends a compressed distillation of a set of training data to Bob, who uses the distilled version to best solve an associated learning problem. We formalize this as a rate-distortion problem in which the training set is the source and Bob's cross-entropy loss is the distortion measure. We consider this problem for unsupervised learning for batch and sequential data. In the batch data, this problem is equivalent to the information bottleneck (IB), and we show that reduced-complexity versions of standard IB methods solve the associated rate-distortion problem. For the streaming data, we present a new algorithm, which may be of independent interest, that solves the rate-distortion problem for Gaussian sources. Furthermore, to improve the results of the iterative algorithm for sequential data we introduce a two-pass version of this algorithm. Finally, we show the dependency of the rate on the number of samples $k$ required for Gaussian sources to ensure cross-entropy loss that scales optimally with the growth of the training set.
Celebrating Diversity in Shared Multi-Agent Reinforcement Learning
Jun 04, 2021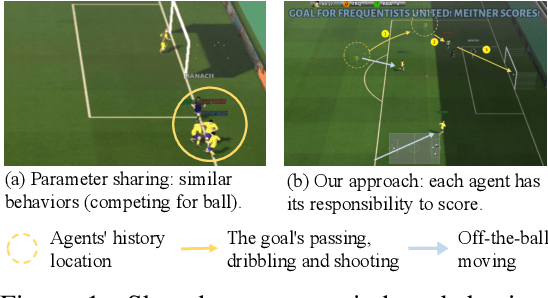
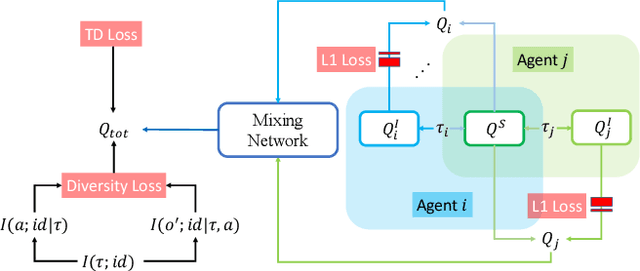
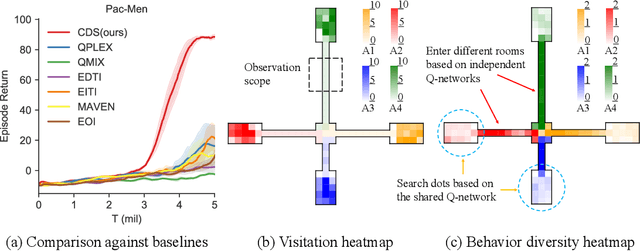
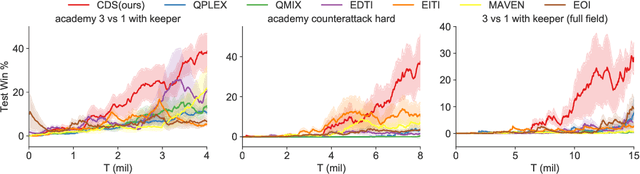
Recently, deep multi-agent reinforcement learning (MARL) has shown the promise to solve complex cooperative tasks. Its success is partly because of parameter sharing among agents. However, such sharing may lead agents to behave similarly and limit their coordination capacity. In this paper, we aim to introduce diversity in both optimization and representation of shared multi-agent reinforcement learning. Specifically, we propose an information-theoretical regularization to maximize the mutual information between agents' identities and their trajectories, encouraging extensive exploration and diverse individualized behaviors. In representation, we incorporate agent-specific modules in the shared neural network architecture, which are regularized by L1-norm to promote learning sharing among agents while keeping necessary diversity. Empirical results show that our method achieves state-of-the-art performance on Google Research Football and super hard StarCraft II micromanagement tasks.
An Information-Theoretic Framework for Non-linear Canonical Correlation Analysis
Oct 31, 2018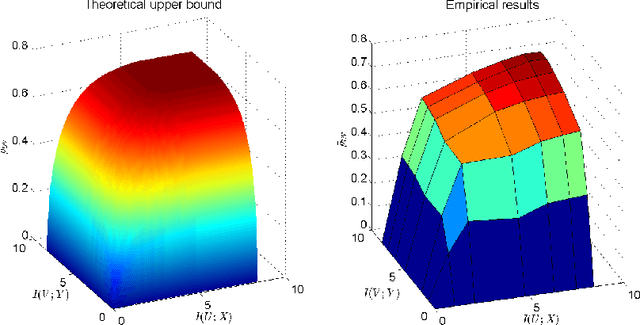
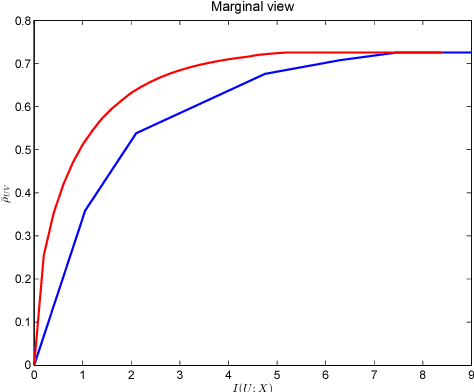
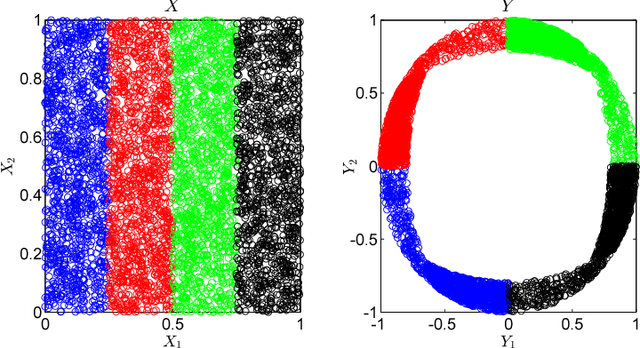
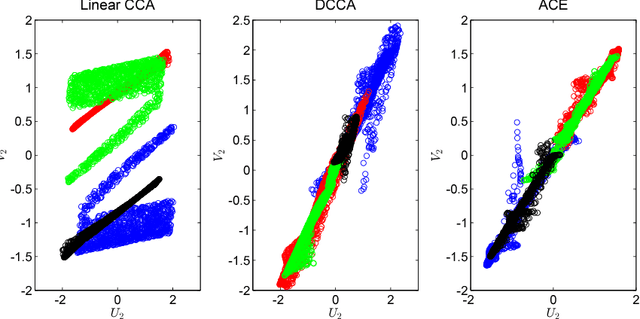
Canonical Correlation Analysis (CCA) is a linear representation learning method that seeks maximally correlated variables in multi-view data. Non-linear CCA extends this notion to a broader family of transformations, which are more powerful for many real-world applications. Given the joint probability, the Alternating Conditional Expectation (ACE) provides an optimal solution to the non-linear CCA problem. However, it suffers from limited performance and an increasing computational burden when only a finite number of observations is available. In this work we introduce an information-theoretic framework for the non-linear CCA problem (ITCCA), which extends the classical ACE approach. Our suggested framework seeks compressed representations of the data that allow a maximal level of correlation. This way we control the trade-off between the flexibility and the complexity of the representation. Our approach demonstrates favorable performance at a reduced computational burden, compared to non-linear alternatives, in a finite sample size regime. Further, ITCCA provides theoretical bounds and optimality conditions, as we establish fundamental connections to rate-distortion theory, the information bottleneck and remote source coding. In addition, it implies a "soft" dimensionality reduction, as the compression level is measured (and governed) by the mutual information between the original noisy data and the signals that we extract.
PortaSpeech: Portable and High-Quality Generative Text-to-Speech
Sep 30, 2021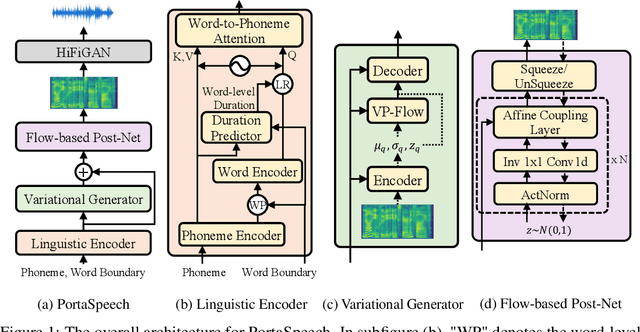
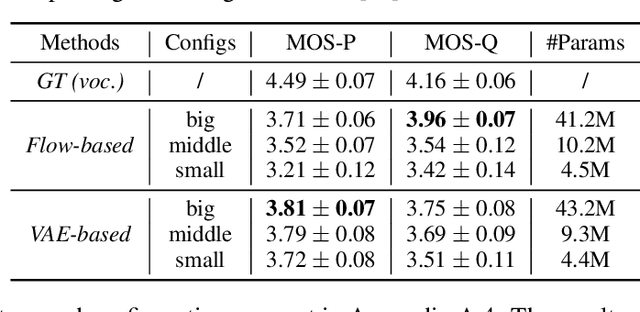
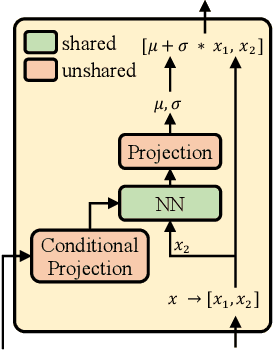
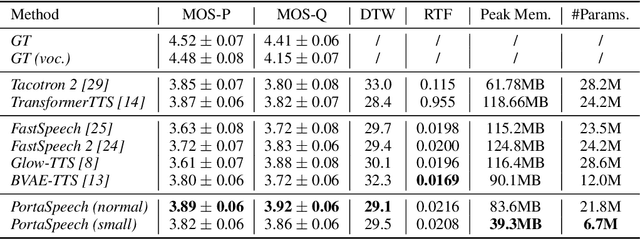
Non-autoregressive text-to-speech (NAR-TTS) models such as FastSpeech 2 and Glow-TTS can synthesize high-quality speech from the given text in parallel. After analyzing two kinds of generative NAR-TTS models (VAE and normalizing flow), we find that: VAE is good at capturing the long-range semantics features (e.g., prosody) even with small model size but suffers from blurry and unnatural results; and normalizing flow is good at reconstructing the frequency bin-wise details but performs poorly when the number of model parameters is limited. Inspired by these observations, to generate diverse speech with natural details and rich prosody using a lightweight architecture, we propose PortaSpeech, a portable and high-quality generative text-to-speech model. Specifically, 1) to model both the prosody and mel-spectrogram details accurately, we adopt a lightweight VAE with an enhanced prior followed by a flow-based post-net with strong conditional inputs as the main architecture. 2) To further compress the model size and memory footprint, we introduce the grouped parameter sharing mechanism to the affine coupling layers in the post-net. 3) To improve the expressiveness of synthesized speech and reduce the dependency on accurate fine-grained alignment between text and speech, we propose a linguistic encoder with mixture alignment combining hard inter-word alignment and soft intra-word alignment, which explicitly extracts word-level semantic information. Experimental results show that PortaSpeech outperforms other TTS models in both voice quality and prosody modeling in terms of subjective and objective evaluation metrics, and shows only a slight performance degradation when reducing the model parameters to 6.7M (about 4x model size and 3x runtime memory compression ratio compared with FastSpeech 2). Our extensive ablation studies demonstrate that each design in PortaSpeech is effective.
WhatTheWikiFact: Fact-Checking Claims Against Wikipedia
Apr 16, 2021
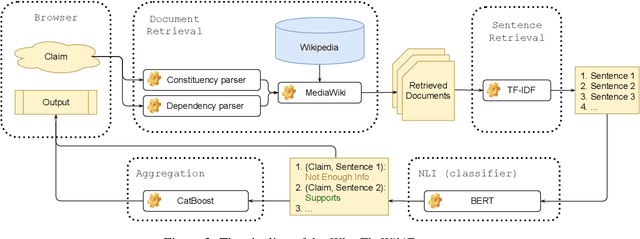
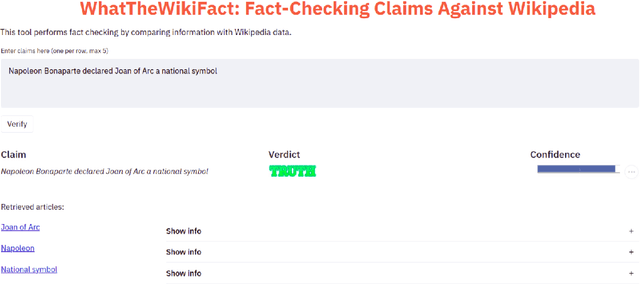
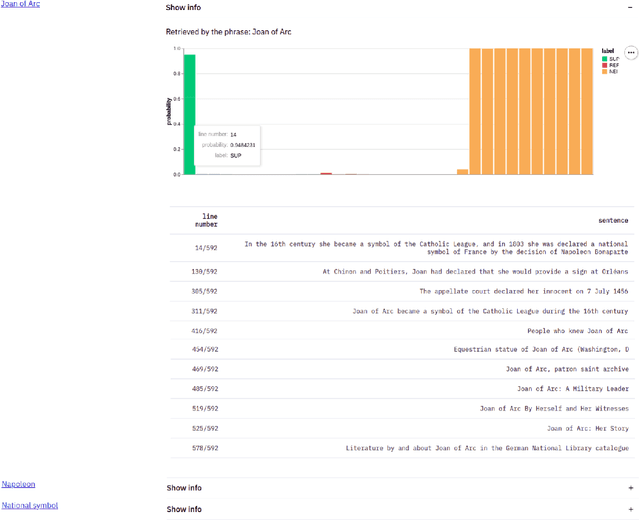
The rise of Internet has made it a major source of information. Unfortunately, not all information online is true, and thus a number of fact-checking initiatives have been launched, both manual and automatic. Here, we present our contribution in this regard: WhatTheWikiFact, a system for automatic claim verification using Wikipedia. The system predicts the veracity of an input claim, and it further shows the evidence it has retrieved as part of the verification process. It shows confidence scores and a list of relevant Wikipedia articles, together with detailed information about each article, including the phrase used to retrieve it, the most relevant sentences it contains, and their stances with respect to the input claim, with associated probabilities.
FeelsGoodMan: Inferring Semantics of Twitch Neologisms
Aug 18, 2021
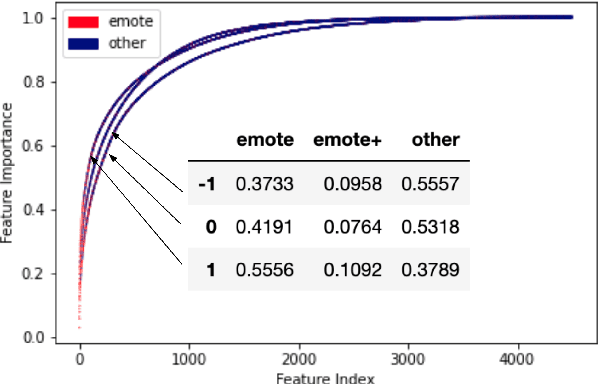
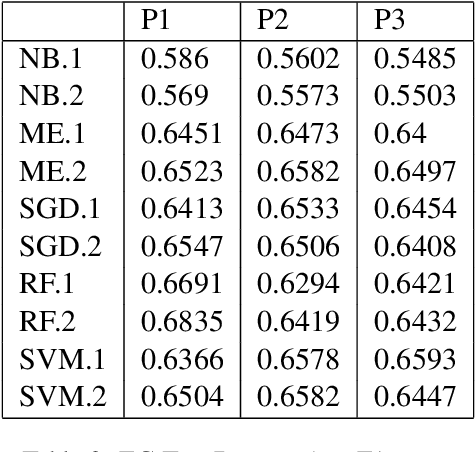
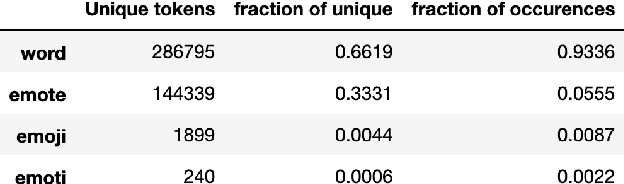
Twitch chats pose a unique problem in natural language understanding due to a large presence of neologisms, specifically emotes. There are a total of 8.06 million emotes, over 400k of which were used in the week studied. There is virtually no information on the meaning or sentiment of emotes, and with a constant influx of new emotes and drift in their frequencies, it becomes impossible to maintain an updated manually-labeled dataset. Our paper makes a two fold contribution. First we establish a new baseline for sentiment analysis on Twitch data, outperforming the previous supervised benchmark by 7.9% points. Secondly, we introduce a simple but powerful unsupervised framework based on word embeddings and k-NN to enrich existing models with out-of-vocabulary knowledge. This framework allows us to auto-generate a pseudo-dictionary of emotes and we show that we can nearly match the supervised benchmark above even when injecting such emote knowledge into sentiment classifiers trained on extraneous datasets such as movie reviews or Twitter.
Structure-Preserving Image Super-Resolution
Sep 26, 2021
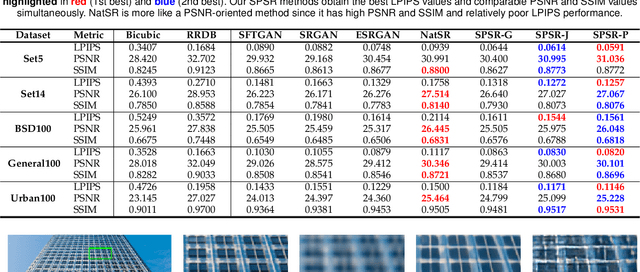
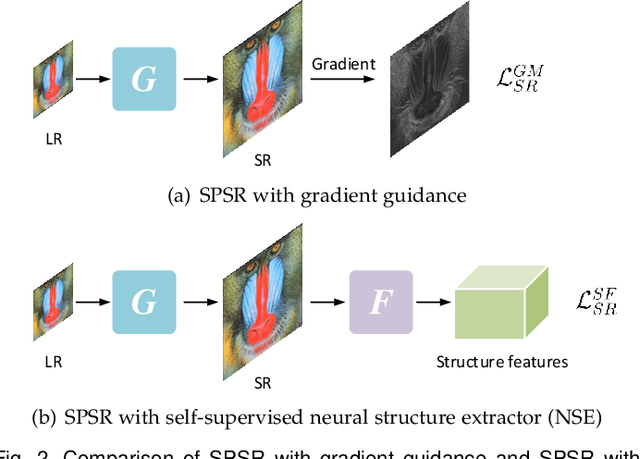

Structures matter in single image super-resolution (SISR). Benefiting from generative adversarial networks (GANs), recent studies have promoted the development of SISR by recovering photo-realistic images. However, there are still undesired structural distortions in the recovered images. In this paper, we propose a structure-preserving super-resolution (SPSR) method to alleviate the above issue while maintaining the merits of GAN-based methods to generate perceptual-pleasant details. Firstly, we propose SPSR with gradient guidance (SPSR-G) by exploiting gradient maps of images to guide the recovery in two aspects. On the one hand, we restore high-resolution gradient maps by a gradient branch to provide additional structure priors for the SR process. On the other hand, we propose a gradient loss to impose a second-order restriction on the super-resolved images, which helps generative networks concentrate more on geometric structures. Secondly, since the gradient maps are handcrafted and may only be able to capture limited aspects of structural information, we further extend SPSR-G by introducing a learnable neural structure extractor (NSE) to unearth richer local structures and provide stronger supervision for SR. We propose two self-supervised structure learning methods, contrastive prediction and solving jigsaw puzzles, to train the NSEs. Our methods are model-agnostic, which can be potentially used for off-the-shelf SR networks. Experimental results on five benchmark datasets show that the proposed methods outperform state-of-the-art perceptual-driven SR methods under LPIPS, PSNR, and SSIM metrics. Visual results demonstrate the superiority of our methods in restoring structures while generating natural SR images. Code is available at https://github.com/Maclory/SPSR.
Contrastive Learning with Temporal Correlated Medical Images: A Case Study using Lung Segmentation in Chest X-Rays
Sep 07, 2021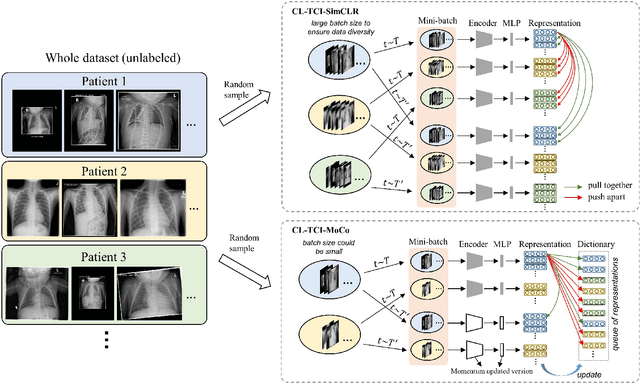
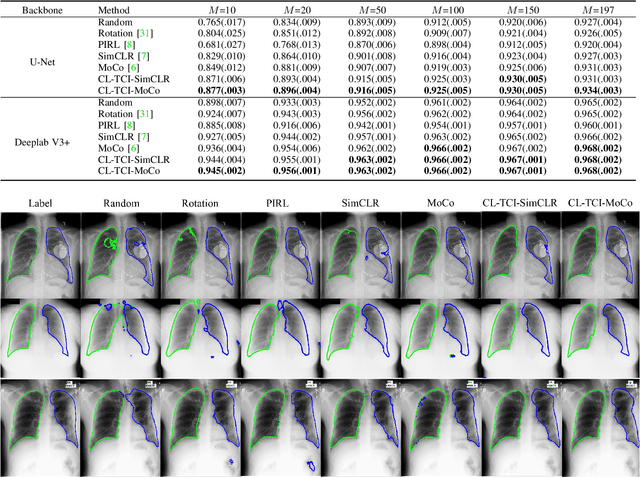
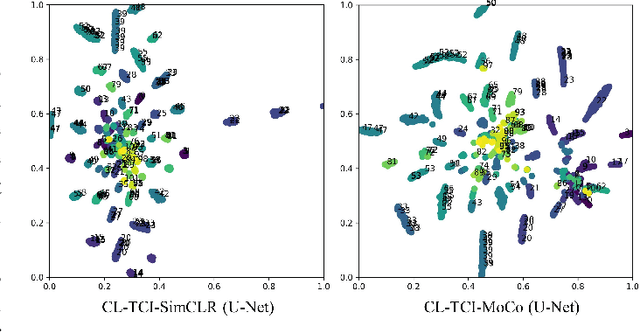
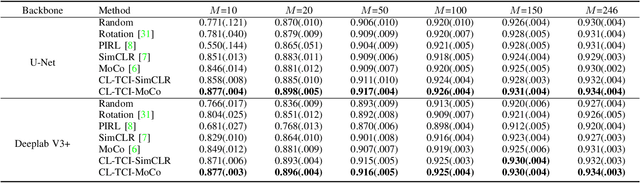
Contrastive learning has been proved to be a promising technique for image-level representation learning from unlabeled data. Many existing works have demonstrated improved results by applying contrastive learning in classification and object detection tasks for either natural images or medical images. However, its application to medical image segmentation tasks has been limited. In this work, we use lung segmentation in chest X-rays as a case study and propose a contrastive learning framework with temporal correlated medical images, named CL-TCI, to learn superior encoders for initializing the segmentation network. We adapt CL-TCI from two state-of-the-art contrastive learning methods-MoCo and SimCLR. Experiment results on three chest X-ray datasets show that under two different segmentation backbones, U-Net and Deeplab-V3, CL-TCI can outperform all baselines that do not incorporate any temporal correlation in both semi-supervised learning setting and transfer learning setting with limited annotation. This suggests that information among temporal correlated medical images can indeed improve contrastive learning performance. Between the two variations of CL-TCI, CL-TCI adapted from MoCo outperforms CL-TCI adapted from SimCLR in most settings, indicating that more contrastive samples can benefit the learning process and help the network learn high-quality representations.