 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Monotonicity Marking from Universal Dependency Trees
May 12, 2021
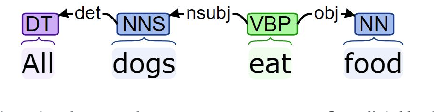
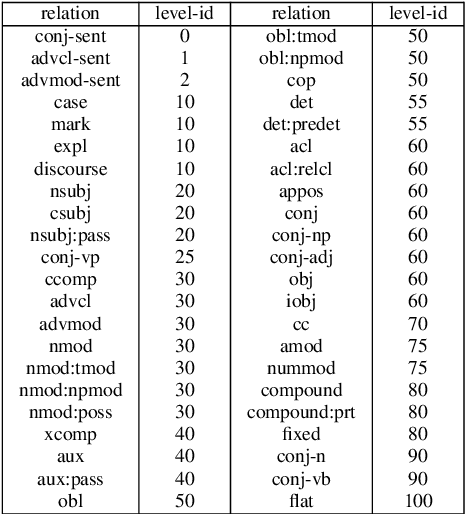
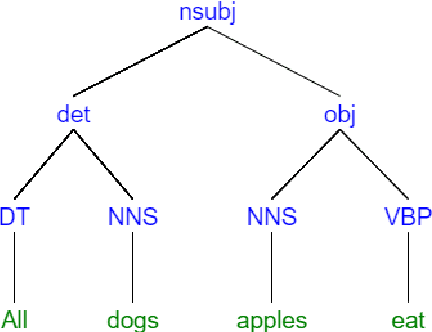

Dependency parsing is a tool widely used in the field of Natural language processing and computational linguistics. However, there is hardly any work that connects dependency parsing to monotonicity, which is an essential part of logic and linguistic semantics. In this paper, we present a system that automatically annotates monotonicity information based on Universal Dependency parse trees. Our system utilizes surface-level monotonicity facts about quantifiers, lexical items, and token-level polarity information. We compared our system's performance with existing systems in the literature, including NatLog and ccg2mono, on a small evaluation dataset. Results show that our system outperforms NatLog and ccg2mono.
Spelling provides a precise (but sometimes misplaced) phonological target. Orthography and acoustic variability in second language word learning
Sep 08, 2021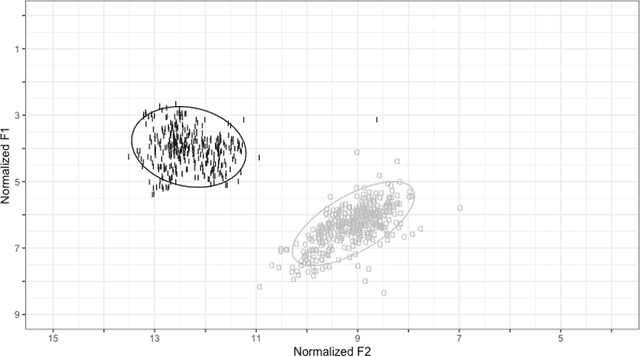

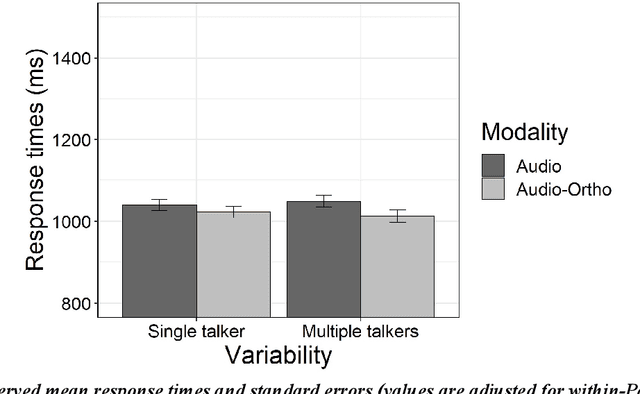

L1 French participants learned novel L2 English words over two days of learning sessions, with half of the words presented with their orthographic forms (Audio-Ortho) and half without (Audio only). One group heard the words pronounced by a single talker, while another group heard them pronounced by multiple talkers. On the third day, they completed a variety of tasks to evaluate their learning. Our results show a robust influence of orthography, with faster response times in both production (picture naming) and recognition (picture mapping) tasks for words learned in the Audio-Ortho condition. Moreover, formant analyses of the picture naming responses show that orthographic input pulls pronunciations of English novel words towards a non-native (French) phonological target. Words learned with their orthographic forms were pronounced more precisely (with smaller Dispersion Scores), but were misplaced in the vowel space (as reflected by smaller Euclidian distances with respect to French vowels). Finally, we found only limited evidence of an effect of talker-based acoustic variability: novel words learned with multiple talkers showed faster responses times in the picture naming task, but only in the Audio-only condition, which suggests that orthographic information may have overwhelmed any advantage of talker-based acoustic variability.
Fast Model-Selection through Adapting Design of Experiments Maximizing Information Gain
Oct 23, 2018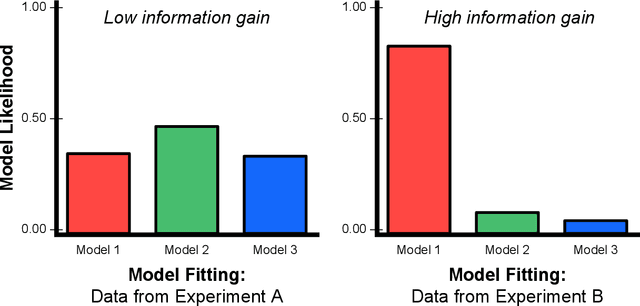

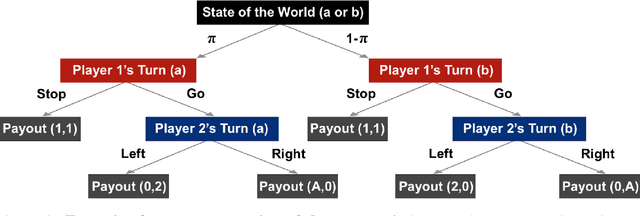
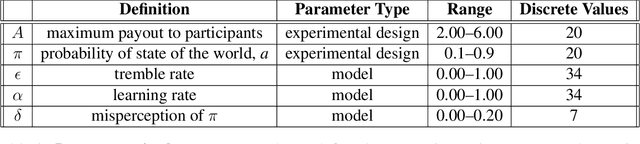
To perform model-selection efficiently, we must run informative experiments. Here, we extend a seminal method for designing Bayesian optimal experiments that maximize the information gained from data collected. We introduce two computational improvements that make the procedure tractable: a search algorithm from artificial intelligence and a sampling procedure shrinking the space of possible experiments to evaluate. We collected data for five different experimental designs of a simple imperfect information game and show that experiments optimized for information gain make model-selection possible (and cheaper). We compare the ability of the optimal experimental design to discriminate among competing models against the experimental designs chosen by a "wisdom of experts" prediction experiment. We find that a simple reinforcement learning model best explains human decision-making and that subject behavior is not adequately described by Bayesian Nash equilibrium. Our procedure is general and can be applied iteratively to lab, field and online experiments.
One Timestep is All You Need: Training Spiking Neural Networks with Ultra Low Latency
Oct 01, 2021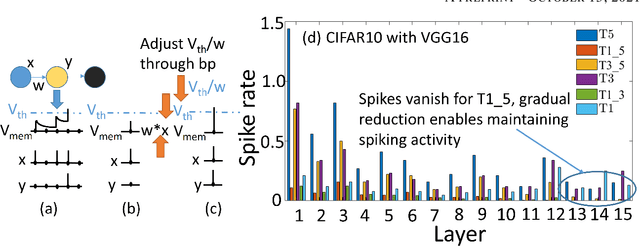
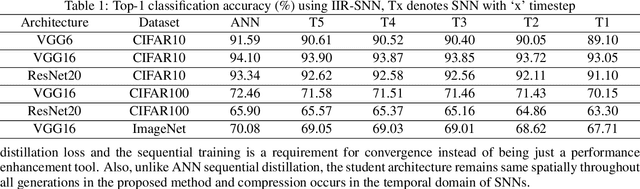
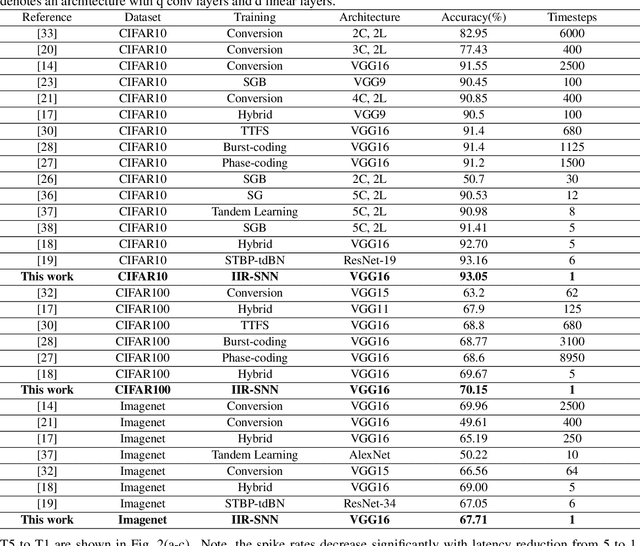
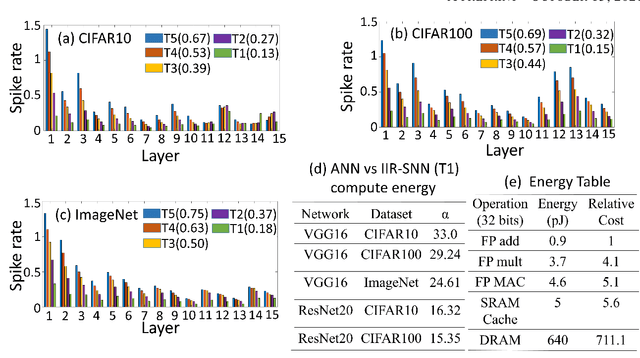
Spiking Neural Networks (SNNs) are energy efficient alternatives to commonly used deep neural networks (DNNs). Through event-driven information processing, SNNs can reduce the expensive compute requirements of DNNs considerably, while achieving comparable performance. However, high inference latency is a significant hindrance to the edge deployment of deep SNNs. Computation over multiple timesteps not only increases latency as well as overall energy budget due to higher number of operations, but also incurs memory access overhead of fetching membrane potentials, both of which lessen the energy benefits of SNNs. To overcome this bottleneck and leverage the full potential of SNNs, we propose an Iterative Initialization and Retraining method for SNNs (IIR-SNN) to perform single shot inference in the temporal axis. The method starts with an SNN trained with T timesteps (T>1). Then at each stage of latency reduction, the network trained at previous stage with higher timestep is utilized as initialization for subsequent training with lower timestep. This acts as a compression method, as the network is gradually shrunk in the temporal domain. In this paper, we use direct input encoding and choose T=5, since as per literature, it is the minimum required latency to achieve satisfactory performance on ImageNet. The proposed scheme allows us to obtain SNNs with up to unit latency, requiring a single forward pass during inference. We achieve top-1 accuracy of 93.05%, 70.15% and 67.71% on CIFAR-10, CIFAR-100 and ImageNet, respectively using VGG16, with just 1 timestep. In addition, IIR-SNNs perform inference with 5-2500X reduced latency compared to other state-of-the-art SNNs, maintaining comparable or even better accuracy. Furthermore, in comparison with standard DNNs, the proposed IIR-SNNs provide25-33X higher energy efficiency, while being comparable to them in classification performance.
Video-aided Unsupervised Grammar Induction
May 04, 2021

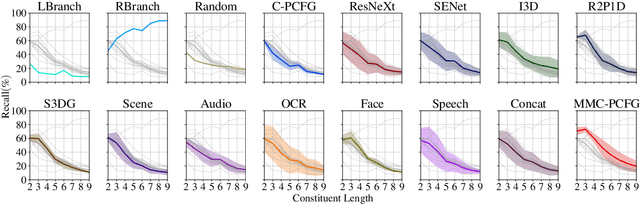

We investigate video-aided grammar induction, which learns a constituency parser from both unlabeled text and its corresponding video. Existing methods of multi-modal grammar induction focus on learning syntactic grammars from text-image pairs, with promising results showing that the information from static images is useful in induction. However, videos provide even richer information, including not only static objects but also actions and state changes useful for inducing verb phrases. In this paper, we explore rich features (e.g. action, object, scene, audio, face, OCR and speech) from videos, taking the recent Compound PCFG model as the baseline. We further propose a Multi-Modal Compound PCFG model (MMC-PCFG) to effectively aggregate these rich features from different modalities. Our proposed MMC-PCFG is trained end-to-end and outperforms each individual modality and previous state-of-the-art systems on three benchmarks, i.e. DiDeMo, YouCook2 and MSRVTT, confirming the effectiveness of leveraging video information for unsupervised grammar induction.
Lifelong 3D Object Recognition and Grasp Synthesis Using Dual Memory Recurrent Self-Organization Networks
Sep 23, 2021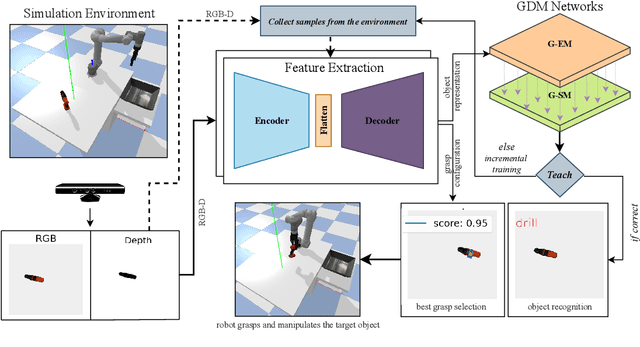

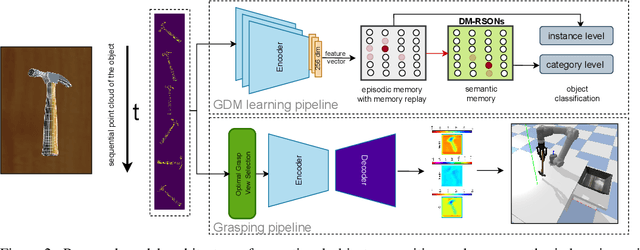

Humans learn to recognize and manipulate new objects in lifelong settings without forgetting the previously gained knowledge under non-stationary and sequential conditions. In autonomous systems, the agents also need to mitigate similar behavior to continually learn the new object categories and adapt to new environments. In most conventional deep neural networks, this is not possible due to the problem of catastrophic forgetting, where the newly gained knowledge overwrites existing representations. Furthermore, most state-of-the-art models excel either in recognizing the objects or in grasp prediction, while both tasks use visual input. The combined architecture to tackle both tasks is very limited. In this paper, we proposed a hybrid model architecture consists of a dynamically growing dual-memory recurrent neural network (GDM) and an autoencoder to tackle object recognition and grasping simultaneously. The autoencoder network is responsible to extract a compact representation for a given object, which serves as input for the GDM learning, and is responsible to predict pixel-wise antipodal grasp configurations. The GDM part is designed to recognize the object in both instances and categories levels. We address the problem of catastrophic forgetting using the intrinsic memory replay, where the episodic memory periodically replays the neural activation trajectories in the absence of external sensory information. To extensively evaluate the proposed model in a lifelong setting, we generate a synthetic dataset due to lack of sequential 3D objects dataset. Experiment results demonstrated that the proposed model can learn both object representation and grasping simultaneously in continual learning scenarios.
Cross-Camera Feature Prediction for Intra-Camera Supervised Person Re-identification across Distant Scenes
Jul 29, 2021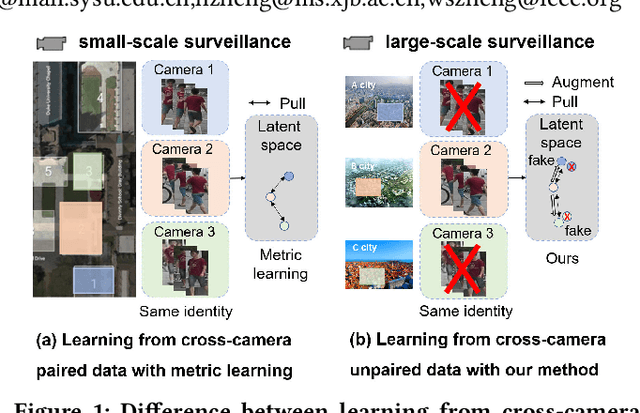
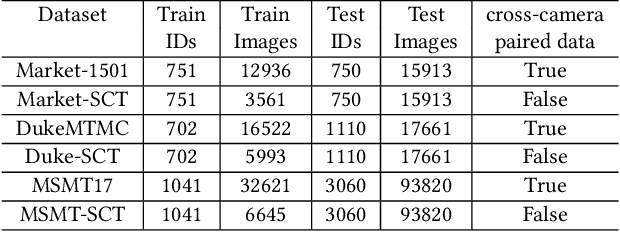
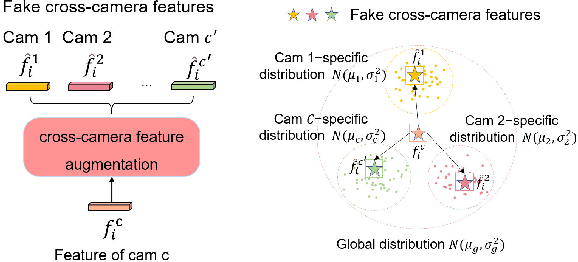
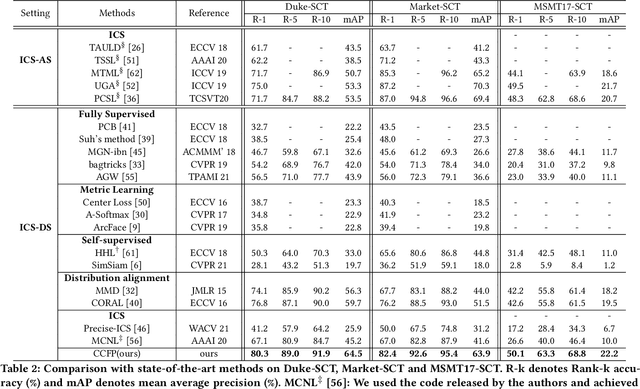
Person re-identification (Re-ID) aims to match person images across non-overlapping camera views. The majority of Re-ID methods focus on small-scale surveillance systems in which each pedestrian is captured in different camera views of adjacent scenes. However, in large-scale surveillance systems that cover larger areas, it is required to track a pedestrian of interest across distant scenes (e.g., a criminal suspect escapes from one city to another). Since most pedestrians appear in limited local areas, it is difficult to collect training data with cross-camera pairs of the same person. In this work, we study intra-camera supervised person re-identification across distant scenes (ICS-DS Re-ID), which uses cross-camera unpaired data with intra-camera identity labels for training. It is challenging as cross-camera paired data plays a crucial role for learning camera-invariant features in most existing Re-ID methods. To learn camera-invariant representation from cross-camera unpaired training data, we propose a cross-camera feature prediction method to mine cross-camera self supervision information from camera-specific feature distribution by transforming fake cross-camera positive feature pairs and minimize the distances of the fake pairs. Furthermore, we automatically localize and extract local-level feature by a transformer. Joint learning of global-level and local-level features forms a global-local cross-camera feature prediction scheme for mining fine-grained cross-camera self supervision information. Finally, cross-camera self supervision and intra-camera supervision are aggregated in a framework. The experiments are conducted in the ICS-DS setting on Market-SCT, Duke-SCT and MSMT17-SCT datasets. The evaluation results demonstrate the superiority of our method, which gains significant improvements of 15.4 Rank-1 and 22.3 mAP on Market-SCT as compared to the second best method.
Personalized News Recommendation: A Survey
Jul 08, 2021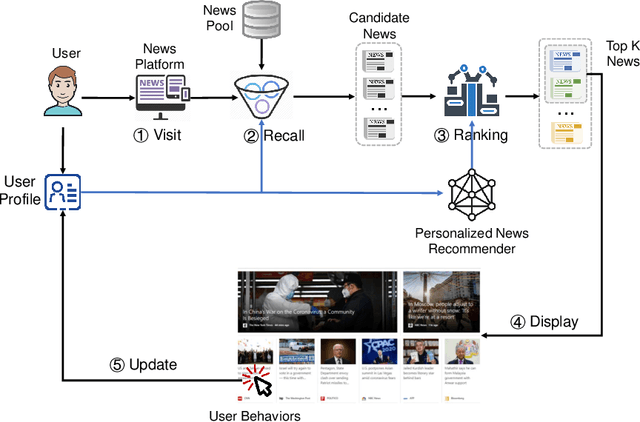

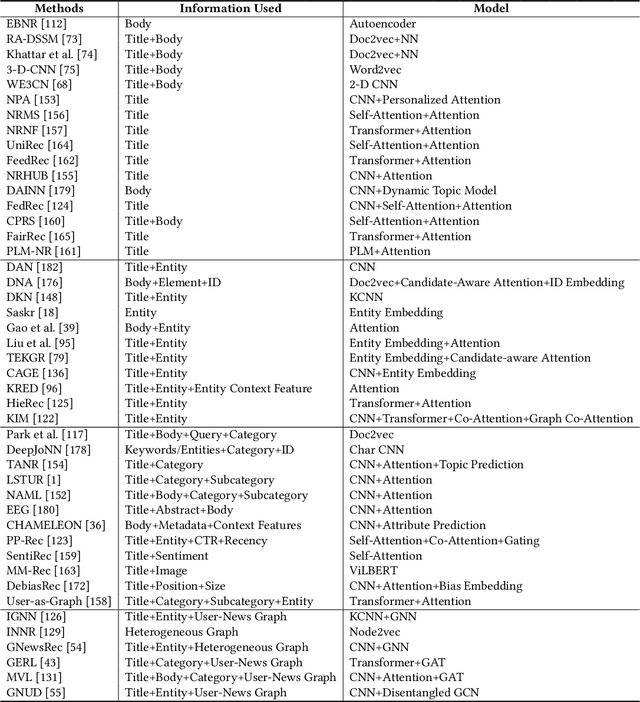
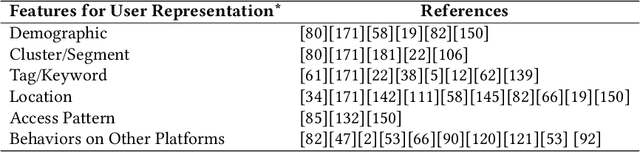
Personalized news recommendation is an important technique to help users find their interested news information and alleviate their information overload. It has been extensively studied over decades and has achieved notable success in improving users' news reading experience. However, there are still many unsolved problems and challenges that need to be further studied. To help researchers master the advances in personalized news recommendation over the past years, in this paper we present a comprehensive overview of personalized news recommendation. Instead of following the conventional taxonomy of news recommendation methods, in this paper we propose a novel perspective to understand personalized news recommendation based on its core problems and the associated techniques and challenges. We first review the techniques for tackling each core problem in a personalized news recommender system and the challenges they face. Next, we introduce the public datasets and evaluation methods for personalized news recommendation. We then discuss the key points on improving the responsibility of personalized news recommender systems. Finally, we raise several research directions that are worth investigating in the future. This paper can provide up-to-date and comprehensive views to help readers understand the personalized news recommendation field. We hope this paper can facilitate research on personalized news recommendation and as well as related fields in natural language processing and data mining.
Pack Together: Entity and Relation Extraction with Levitated Marker
Sep 13, 2021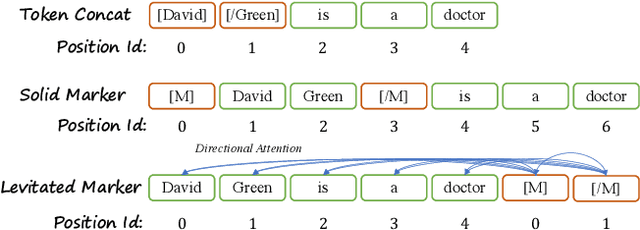
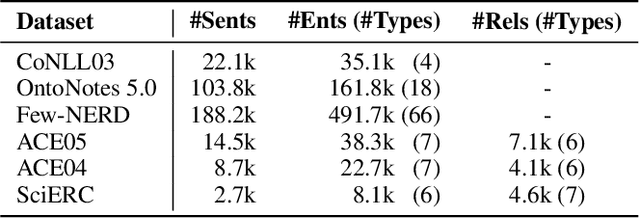
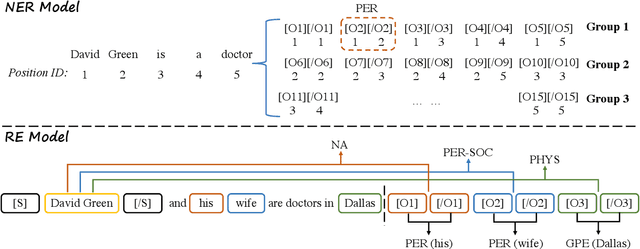
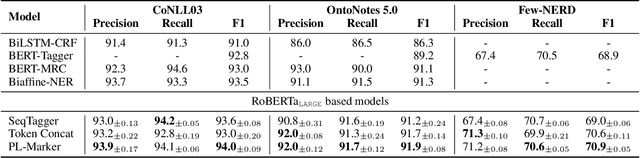
Named Entity Recognition (NER) and Relation Extraction (RE) are the core sub-tasks for information extraction. Many recent works formulate these two tasks as the span (pair) classification problem, and thus focus on investigating how to obtain a better span representation from the pre-trained encoder. However, a major limitation of existing works is that they ignore the dependencies between spans (pairs). In this work, we propose a novel span representation approach, named Packed Levitated Markers, to consider the dependencies between the spans (pairs) by strategically packing the markers in the encoder. In particular, we propose a group packing strategy to enable our model to process massive spans together to consider their dependencies with limited resources. Furthermore, for those more complicated span pair classification tasks, we design a subject-oriented packing strategy, which packs each subject and all its objects into an instance to model the dependencies between the same-subject span pairs. Our experiments show that our model with packed levitated markers outperforms the sequence labeling model by 0.4%-1.9% F1 on three flat NER tasks, beats the token concat model on six NER benchmarks, and obtains a 3.5%-3.6% strict relation F1 improvement with higher speed over previous SOTA models on ACE04 and ACE05. Code and models are publicly available at https://github.com/thunlp/PL-Marker.
SDTP: Semantic-aware Decoupled Transformer Pyramid for Dense Image Prediction
Sep 18, 2021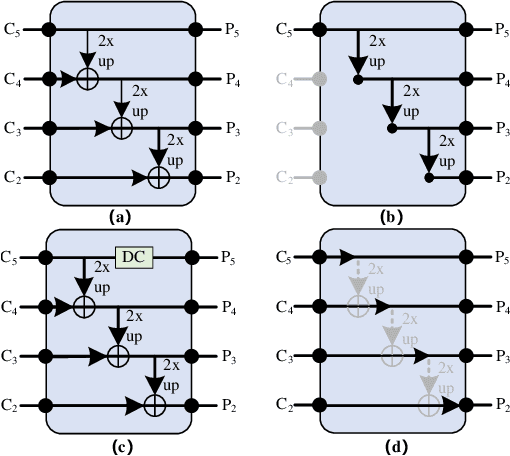
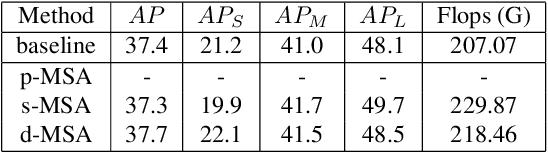
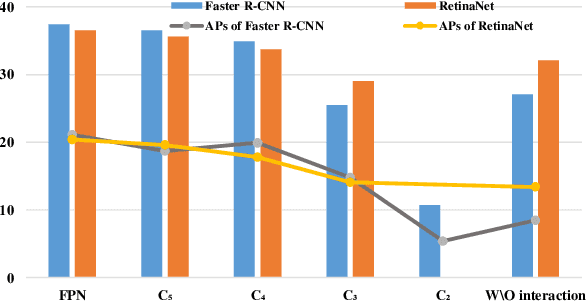
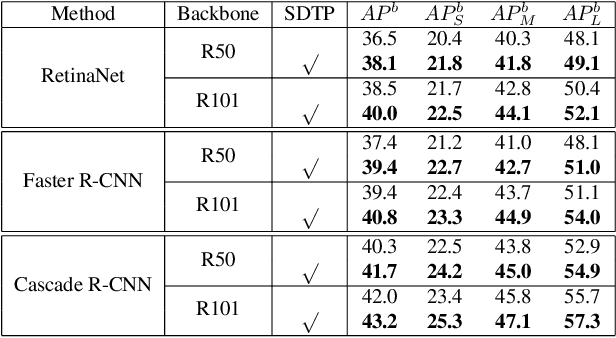
Although transformer has achieved great progress on computer vision tasks, the scale variation in dense image prediction is still the key challenge. Few effective multi-scale techniques are applied in transformer and there are two main limitations in the current methods. On one hand, self-attention module in vanilla transformer fails to sufficiently exploit the diversity of semantic information because of its rigid mechanism. On the other hand, it is hard to build attention and interaction among different levels due to the heavy computational burden. To alleviate this problem, we first revisit multi-scale problem in dense prediction, verifying the significance of diverse semantic representation and multi-scale interaction, and exploring the adaptation of transformer to pyramidal structure. Inspired by these findings, we propose a novel Semantic-aware Decoupled Transformer Pyramid (SDTP) for dense image prediction, consisting of Intra-level Semantic Promotion (ISP), Cross-level Decoupled Interaction (CDI) and Attention Refinement Function (ARF). ISP explores the semantic diversity in different receptive space. CDI builds the global attention and interaction among different levels in decoupled space which also solves the problem of heavy computation. Besides, ARF is further added to refine the attention in transformer. Experimental results demonstrate the validity and generality of the proposed method, which outperforms the state-of-the-art by a significant margin in dense image prediction tasks. Furthermore, the proposed components are all plug-and-play, which can be embedded in other methods.