 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Causally Constrained Data Synthesis for Private Data Release
May 27, 2021
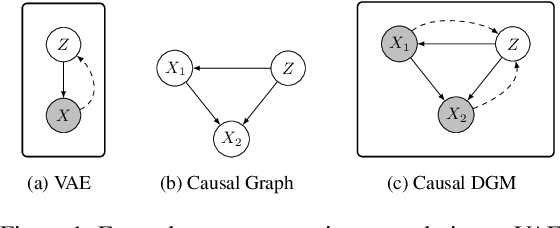
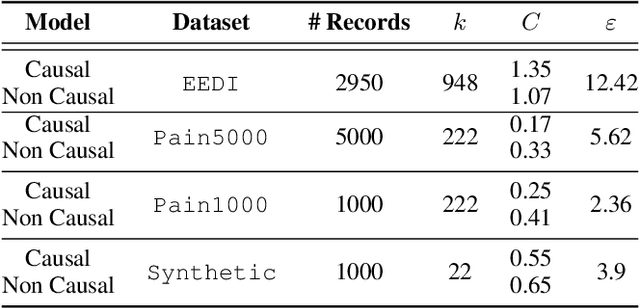
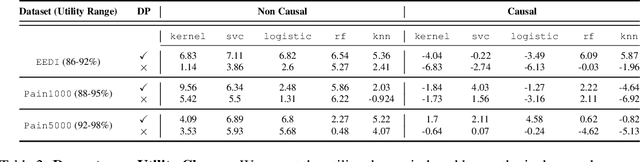
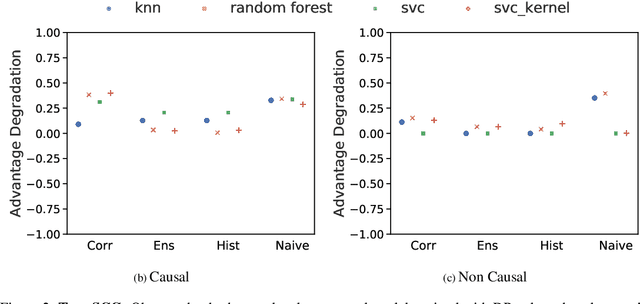
Making evidence based decisions requires data. However for real-world applications, the privacy of data is critical. Using synthetic data which reflects certain statistical properties of the original data preserves the privacy of the original data. To this end, prior works utilize differentially private data release mechanisms to provide formal privacy guarantees. However, such mechanisms have unacceptable privacy vs. utility trade-offs. We propose incorporating causal information into the training process to favorably modify the aforementioned trade-off. We theoretically prove that generative models trained with additional causal knowledge provide stronger differential privacy guarantees. Empirically, we evaluate our solution comparing different models based on variational auto-encoders (VAEs), and show that causal information improves resilience to membership inference, with improvements in downstream utility.
Intra-Inter Subject Self-supervised Learning for Multivariate Cardiac Signals
Sep 18, 2021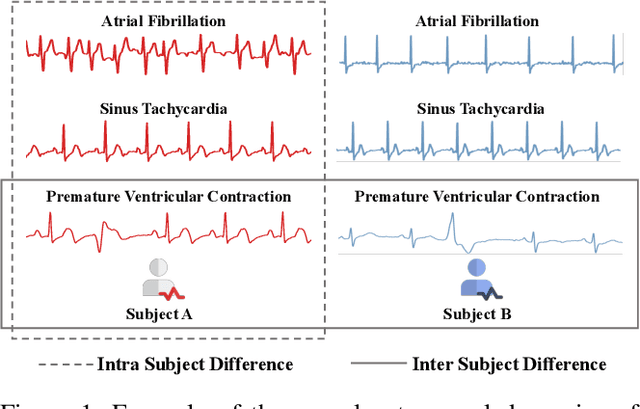

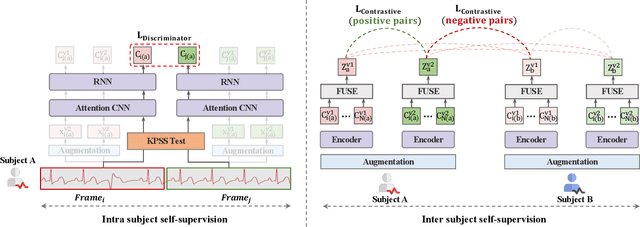
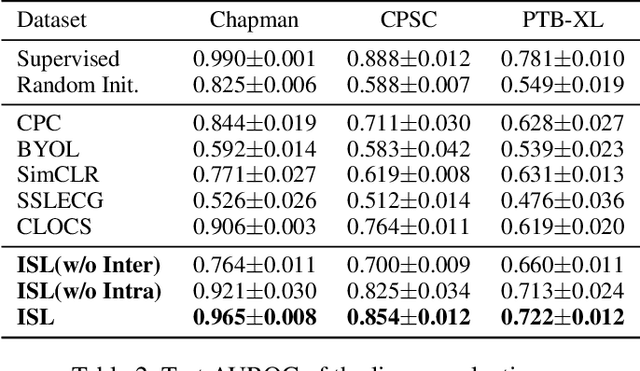
Learning information-rich and generalizable representations effectively from unlabeled multivariate cardiac signals to identify abnormal heart rhythms (cardiac arrhythmias) is valuable in real-world clinical settings but often challenging due to its complex temporal dynamics. Cardiac arrhythmias can vary significantly in temporal patterns even for the same patient ($i.e.$, intra subject difference). Meanwhile, the same type of cardiac arrhythmia can show different temporal patterns among different patients due to different cardiac structures ($i.e.$, inter subject difference). In this paper, we address the challenges by proposing an Intra-inter Subject self-supervised Learning (ISL) model that is customized for multivariate cardiac signals. Our proposed ISL model integrates medical knowledge into self-supervision to effectively learn from intra-inter subject differences. In intra subject self-supervision, ISL model first extracts heartbeat-level features from each subject using a channel-wise attentional CNN-RNN encoder. Then a stationarity test module is employed to capture the temporal dependencies between heartbeats. In inter subject self-supervision, we design a set of data augmentations according to the clinical characteristics of cardiac signals and perform contrastive learning among subjects to learn distinctive representations for various types of patients. Extensive experiments on three real-world datasets were conducted. In a semi-supervised transfer learning scenario, our pre-trained ISL model leads about 10% improvement over supervised training when only 1% labeled data is available, suggesting strong generalizability and robustness of the model.
GTNet:Guided Transformer Network for Detecting Human-Object Interactions
Aug 03, 2021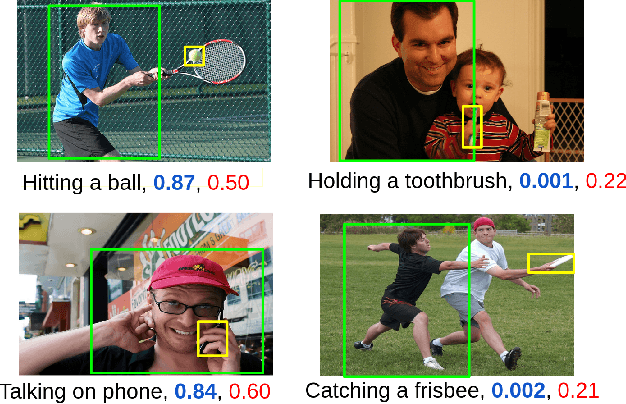
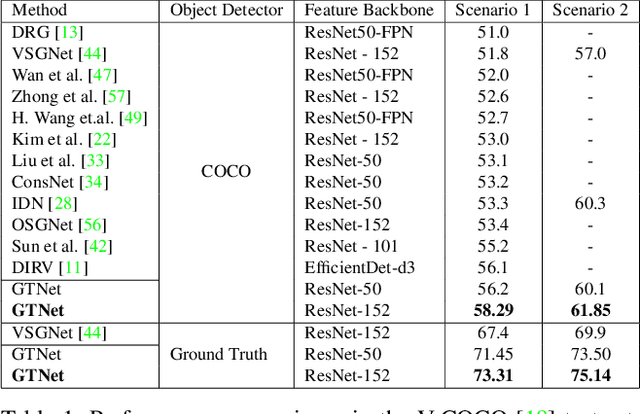
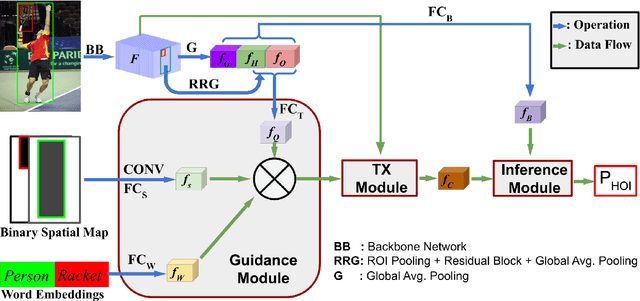
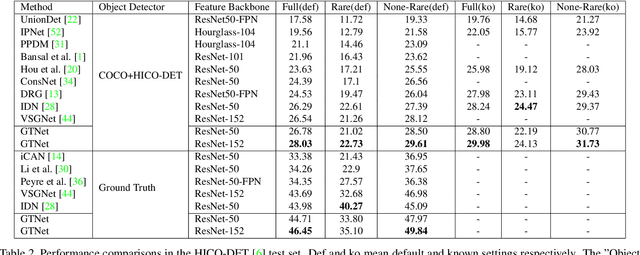
The human-object interaction (HOI) detection task refers to localizing humans, localizing objects, and predicting the interactions between each human-object pair. HOI is considered one of the fundamental steps in truly understanding complex visual scenes. For detecting HOI, it is important to utilize relative spatial configurations and object semantics to find salient spatial regions of images that highlight the interactions between human object pairs. This issue is addressed by the proposed self-attention based guided transformer network, GTNet. GTNet encodes this spatial contextual information in human and object visual features via self-attention while achieving a 4%-6% improvement over previous state of the art results on both the V-COCO and HICO-DET datasets. Code will be made available online.
Independent Asymmetric Embedding Model for Cascade Prediction on Social Network
May 18, 2021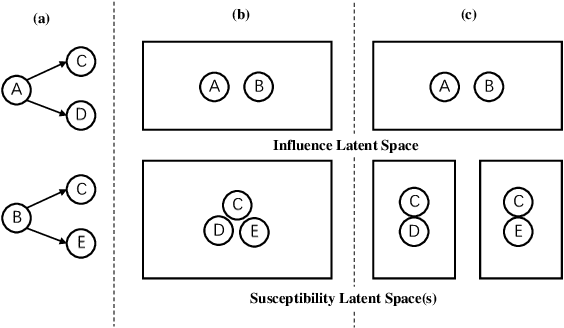
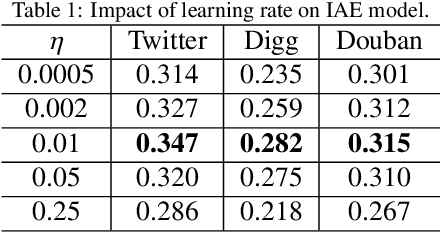
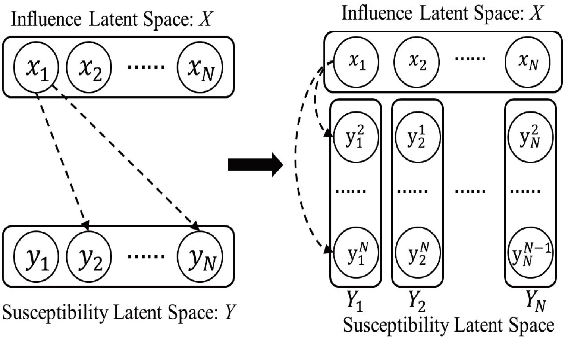
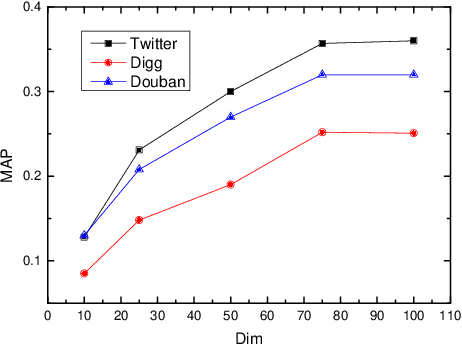
The prediction for information diffusion on social networks has great practical significance in marketing and public opinion control. Cascade prediction aims to predict the individuals who will potentially repost the message on the social network. One kind of methods either exploit demographical, structural, and temporal features for prediction, or explicitly rely on particular information diffusion models. The other kind of models are fully data-driven and do not require a global network structure. Thus massive diffusion prediction models based on network embedding are proposed. These models embed the users into the latent space using their cascade information, but are lack of consideration for the intervene among users when embedding. In this paper, we propose an independent asymmetric embedding method to learn social embedding for cascade prediction. Different from existing methods, our method embeds each individual into one latent influence space and multiple latent susceptibility spaces. Furthermore, our method captures the co-occurrence regulation of user combination in cascades to improve the calculating effectiveness. The results of extensive experiments conducted on real-world datasets verify both the predictive accuracy and cost-effectiveness of our approach.
Learning Cross-modal Contrastive Features for Video Domain Adaptation
Aug 26, 2021

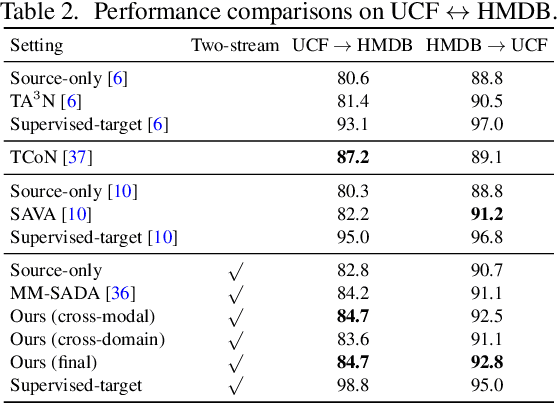
Learning transferable and domain adaptive feature representations from videos is important for video-relevant tasks such as action recognition. Existing video domain adaptation methods mainly rely on adversarial feature alignment, which has been derived from the RGB image space. However, video data is usually associated with multi-modal information, e.g., RGB and optical flow, and thus it remains a challenge to design a better method that considers the cross-modal inputs under the cross-domain adaptation setting. To this end, we propose a unified framework for video domain adaptation, which simultaneously regularizes cross-modal and cross-domain feature representations. Specifically, we treat each modality in a domain as a view and leverage the contrastive learning technique with properly designed sampling strategies. As a result, our objectives regularize feature spaces, which originally lack the connection across modalities or have less alignment across domains. We conduct experiments on domain adaptive action recognition benchmark datasets, i.e., UCF, HMDB, and EPIC-Kitchens, and demonstrate the effectiveness of our components against state-of-the-art algorithms.
Graph-to-3D: End-to-End Generation and Manipulation of 3D Scenes Using Scene Graphs
Aug 19, 2021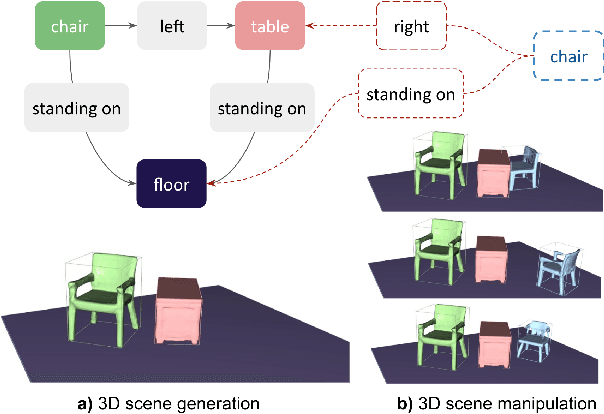
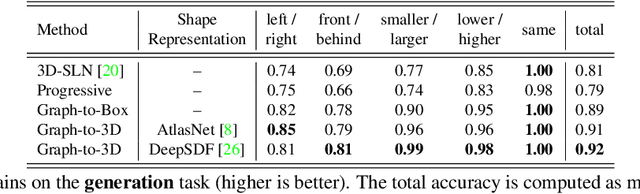
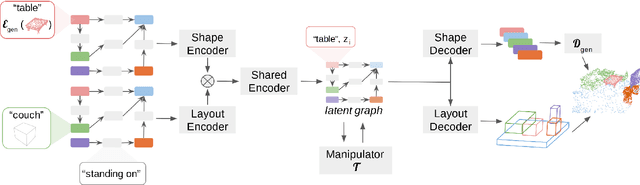
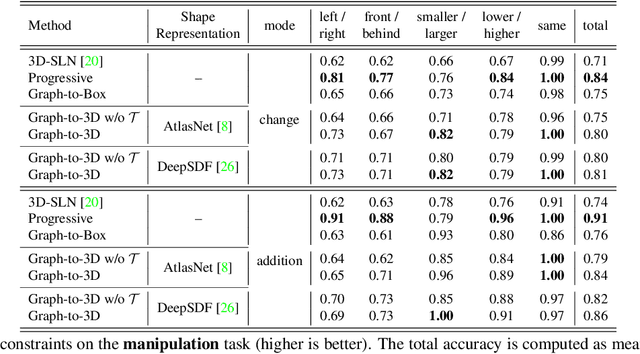
Controllable scene synthesis consists of generating 3D information that satisfy underlying specifications. Thereby, these specifications should be abstract, i.e. allowing easy user interaction, whilst providing enough interface for detailed control. Scene graphs are representations of a scene, composed of objects (nodes) and inter-object relationships (edges), proven to be particularly suited for this task, as they allow for semantic control on the generated content. Previous works tackling this task often rely on synthetic data, and retrieve object meshes, which naturally limits the generation capabilities. To circumvent this issue, we instead propose the first work that directly generates shapes from a scene graph in an end-to-end manner. In addition, we show that the same model supports scene modification, using the respective scene graph as interface. Leveraging Graph Convolutional Networks (GCN) we train a variational Auto-Encoder on top of the object and edge categories, as well as 3D shapes and scene layouts, allowing latter sampling of new scenes and shapes.
Performance of UAV assisted Multiuser Terrestrial-Satellite Communication System over Mixed FSO/RF Channels
Sep 13, 2021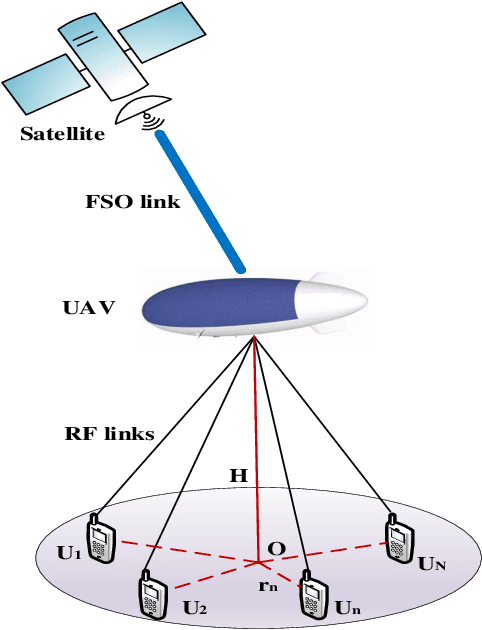
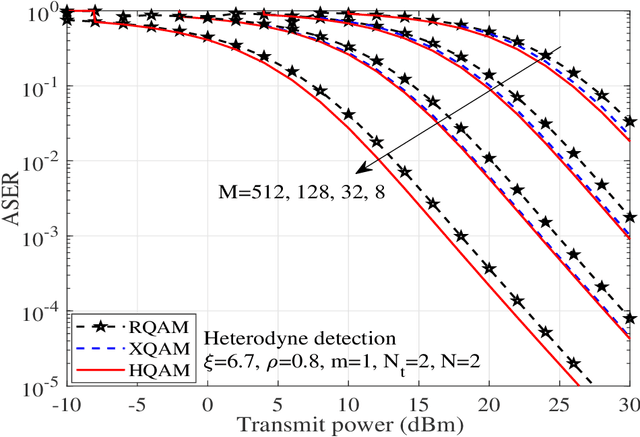
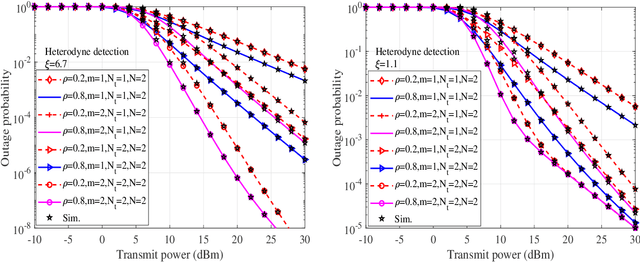
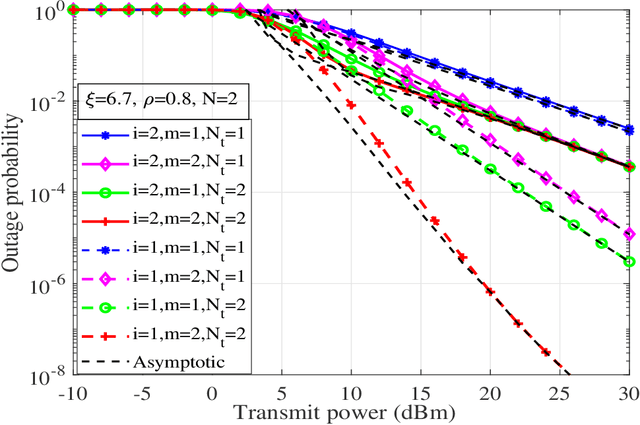
In this work, performance of a multi-antenna multiuser unmanned aerial vehicle (UAV) assisted terrestrial-satellite communication system over mixed free space optics (FSO)/ radio frequency (RF) channels is analyzed. Downlink transmission from the satellite to the UAV is completed through FSO link which follows Gamma-Gamma distribution with pointing error impairments. Both the heterodyne detection and intensity modulation direct detection techniques are considered at the FSO receiver. To avail the antenna diversity, multiple transmit antennas are considered at the UAV. Selective decode-and-forward scheme is assumed at the UAV and opportunistic user scheduling is performed while considering the practical constraints of outdated channel state information (CSI) during the user selection and transmission phase. The RF links are assumed to follow Nakagami-m distribution due to its versatile nature. In this context, for the performance analysis, analytical expressions of outage probability, asymptotic outage probability, ergodic capacity, effective capacity, and generalized average symbol-error-rate expressions of various quadrature amplitude modulation (QAM) schemes such as hexagonal-QAM, cross-QAM, and rectangular QAM are derived. A comparison of various modulation schemes is presented. Further, the impact of pointing error, number of antennas, delay constraint, fading severity, and imperfect CSI are highlighted on the system performance. Finally, all the analytical results are verified through the Monte-Carlo simulations.
Controllable deep melody generation via hierarchical music structure representation
Sep 02, 2021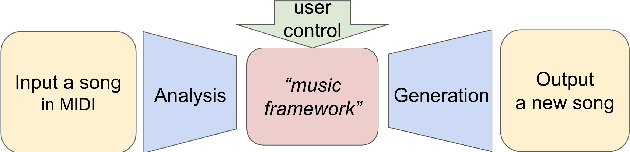
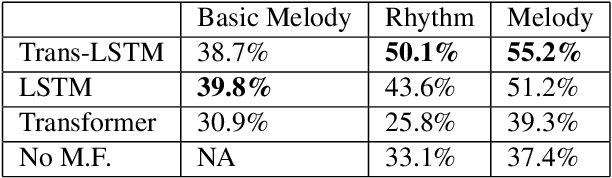
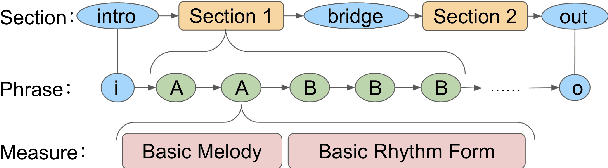
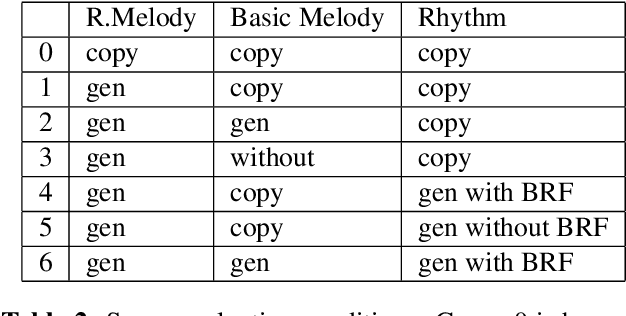
Recent advances in deep learning have expanded possibilities to generate music, but generating a customizable full piece of music with consistent long-term structure remains a challenge. This paper introduces MusicFrameworks, a hierarchical music structure representation and a multi-step generative process to create a full-length melody guided by long-term repetitive structure, chord, melodic contour, and rhythm constraints. We first organize the full melody with section and phrase-level structure. To generate melody in each phrase, we generate rhythm and basic melody using two separate transformer-based networks, and then generate the melody conditioned on the basic melody, rhythm and chords in an auto-regressive manner. By factoring music generation into sub-problems, our approach allows simpler models and requires less data. To customize or add variety, one can alter chords, basic melody, and rhythm structure in the music frameworks, letting our networks generate the melody accordingly. Additionally, we introduce new features to encode musical positional information, rhythm patterns, and melodic contours based on musical domain knowledge. A listening test reveals that melodies generated by our method are rated as good as or better than human-composed music in the POP909 dataset about half the time.
Click to Move: Controlling Video Generation with Sparse Motion
Aug 19, 2021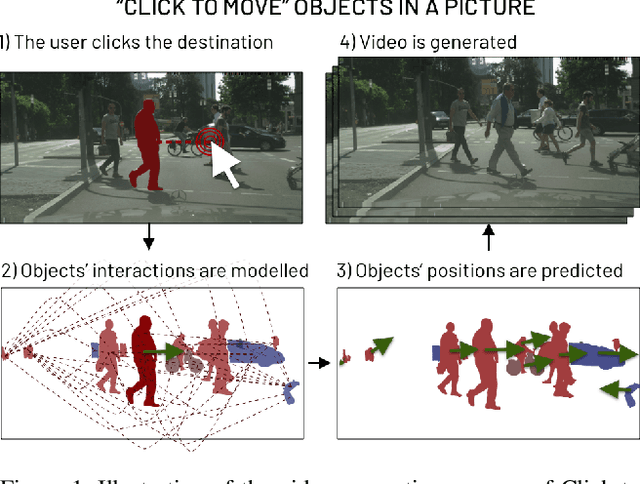
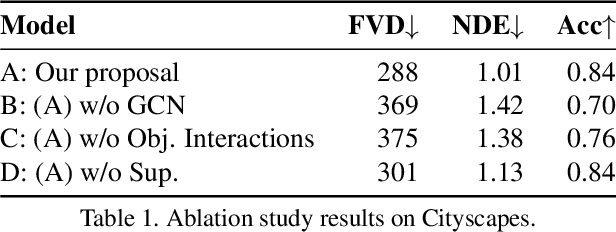
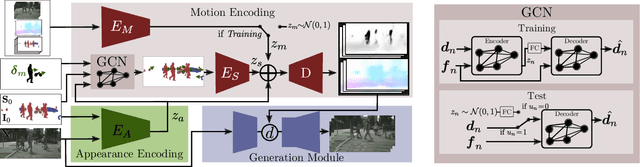
This paper introduces Click to Move (C2M), a novel framework for video generation where the user can control the motion of the synthesized video through mouse clicks specifying simple object trajectories of the key objects in the scene. Our model receives as input an initial frame, its corresponding segmentation map and the sparse motion vectors encoding the input provided by the user. It outputs a plausible video sequence starting from the given frame and with a motion that is consistent with user input. Notably, our proposed deep architecture incorporates a Graph Convolution Network (GCN) modelling the movements of all the objects in the scene in a holistic manner and effectively combining the sparse user motion information and image features. Experimental results show that C2M outperforms existing methods on two publicly available datasets, thus demonstrating the effectiveness of our GCN framework at modelling object interactions. The source code is publicly available at https://github.com/PierfrancescoArdino/C2M.
A Synchronized Reprojection-based Model for 3D Human Pose Estimation
Jun 08, 2021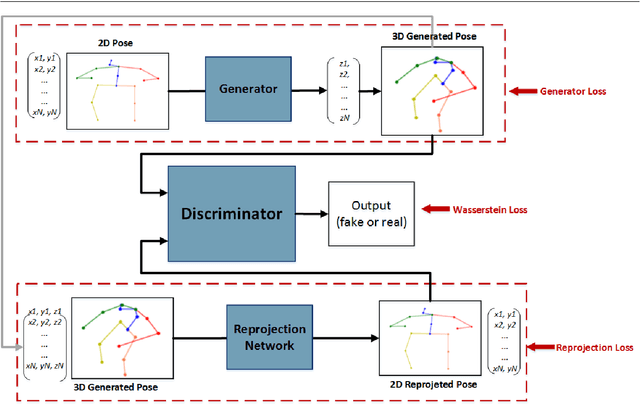
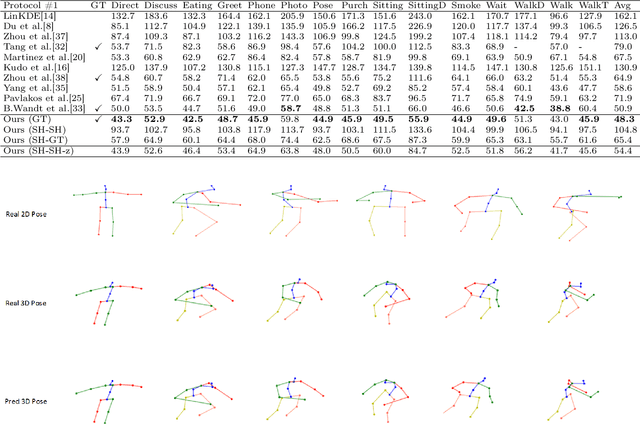
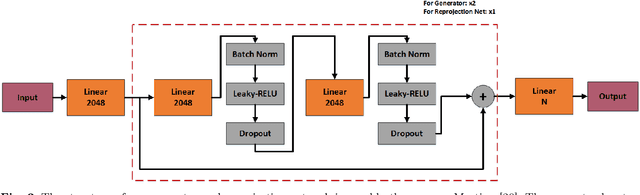
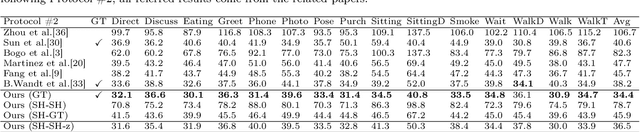
3D human pose estimation is still a challenging problem despite the large amount of work that has been done in this field. Generally, most methods directly use neural networks and ignore certain constraints (e.g., reprojection constraints and joint angle and bone length constraints). This paper proposes a weakly supervised GAN-based model for 3D human pose estimation that considers 3D information along with 2D information simultaneously, in which a reprojection network is employed to learn the mapping of the distribution from 3D poses to 2D poses. In particular, we train the reprojection network and the generative adversarial network synchronously. Furthermore, inspired by the typical kinematic chain space (KCS) matrix, we propose a weighted KCS matrix, which is added into the discriminator's input to impose joint angle and bone length constraints. The experimental results on Human3.6M show that our method outperforms state-of-the-art methods by approximately 5.1\%.