 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towers of Babel: Combining Images, Language, and 3D Geometry for Learning Multimodal Vision
Aug 12, 2021




The abundance and richness of Internet photos of landmarks and cities has led to significant progress in 3D vision over the past two decades, including automated 3D reconstructions of the world's landmarks from tourist photos. However, a major source of information available for these 3D-augmented collections---namely language, e.g., from image captions---has been virtually untapped. In this work, we present WikiScenes, a new, large-scale dataset of landmark photo collections that contains descriptive text in the form of captions and hierarchical category names. WikiScenes forms a new testbed for multimodal reasoning involving images, text, and 3D geometry. We demonstrate the utility of WikiScenes for learning semantic concepts over images and 3D models. Our weakly-supervised framework connects images, 3D structure, and semantics---utilizing the strong constraints provided by 3D geometry---to associate semantic concepts to image pixels and 3D points.
Semi-Supervised Siamese Network for Identifying Bad Data in Medical Imaging Datasets
Aug 16, 2021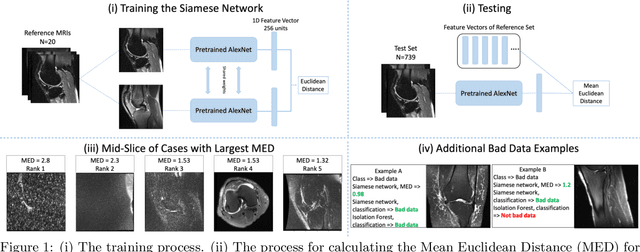
Noisy data present in medical imaging datasets can often aid the development of robust models that are equipped to handle real-world data. However, if the bad data contains insufficient anatomical information, it can have a severe negative effect on the model's performance. We propose a novel methodology using a semi-supervised Siamese network to identify bad data. This method requires only a small pool of 'reference' medical images to be reviewed by a non-expert human to ensure the major anatomical structures are present in the Field of View. The model trains on this reference set and identifies bad data by using the Siamese network to compute the distance between the reference set and all other medical images in the dataset. This methodology achieves an Area Under the Curve (AUC) of 0.989 for identifying bad data. Code will be available at https://git.io/JYFuV.
Using Biological Variables and Social Determinants to Predict Malaria and Anemia among Children in Senegal
Aug 08, 2021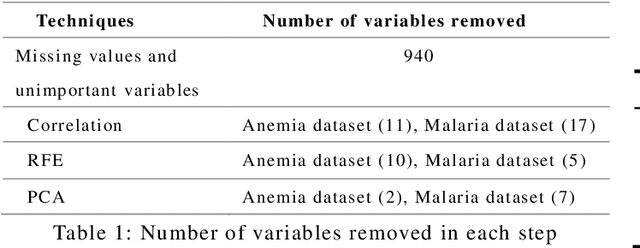
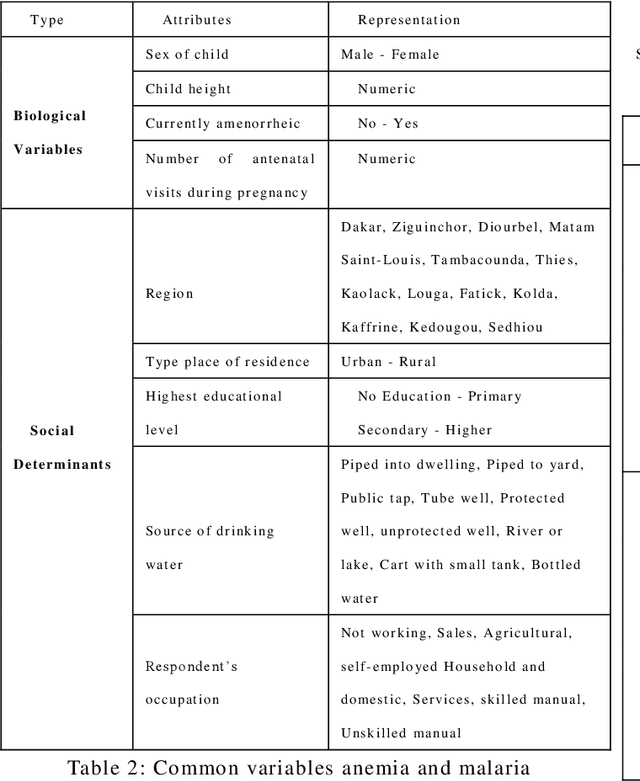

Integrating machine learning techniques in healthcare becomes very common nowadays, and it contributes positively to improving clinical care and health decisions planning. Anemia and malaria are two life-threatening diseases in Africa that affect the red blood cells and reduce hemoglobin production. This paper focuses on analyzing child health data in Senegal using four machine learning algorithms in Python: KNN, Random Forests, SVM, and Na\"ive Bayes. Our task aims to investigate large-scale data from The Demographic and Health Survey (DHS) and to find out hidden information for anemia and malaria. We present two classification models for the two blood disorders using biological variables and social determinants. The findings of this research will contribute to improving child healthcare in Senegal by eradicating anemia and malaria, and decreasing the child mortality rate.
Cross-Policy Compliance Detection via Question Answering
Sep 08, 2021


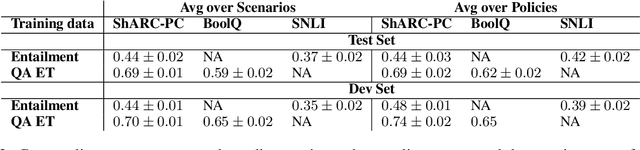
Policy compliance detection is the task of ensuring that a scenario conforms to a policy (e.g. a claim is valid according to government rules or a post in an online platform conforms to community guidelines). This task has been previously instantiated as a form of textual entailment, which results in poor accuracy due to the complexity of the policies. In this paper we propose to address policy compliance detection via decomposing it into question answering, where questions check whether the conditions stated in the policy apply to the scenario, and an expression tree combines the answers to obtain the label. Despite the initial upfront annotation cost, we demonstrate that this approach results in better accuracy, especially in the cross-policy setup where the policies during testing are unseen in training. In addition, it allows us to use existing question answering models pre-trained on existing large datasets. Finally, it explicitly identifies the information missing from a scenario in case policy compliance cannot be determined. We conduct our experiments using a recent dataset consisting of government policies, which we augment with expert annotations and find that the cost of annotating question answering decomposition is largely offset by improved inter-annotator agreement and speed.
Neural Networks with Physics-Informed Architectures and Constraints for Dynamical Systems Modeling
Sep 14, 2021
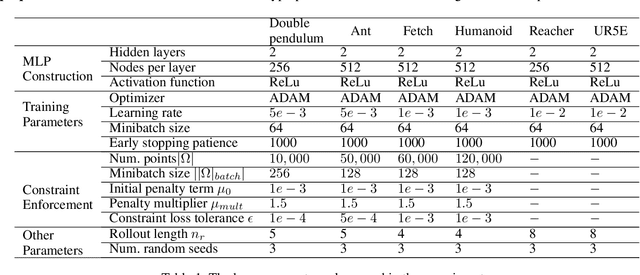
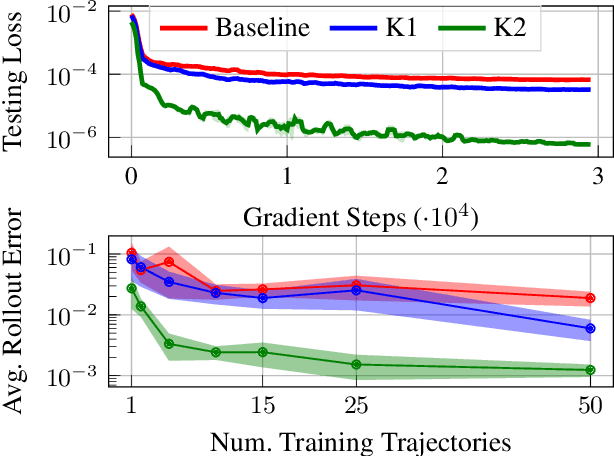

Effective inclusion of physics-based knowledge into deep neural network models of dynamical systems can greatly improve data efficiency and generalization. Such a-priori knowledge might arise from physical principles (e.g., conservation laws) or from the system's design (e.g., the Jacobian matrix of a robot), even if large portions of the system dynamics remain unknown. We develop a framework to learn dynamics models from trajectory data while incorporating a-priori system knowledge as inductive bias. More specifically, the proposed framework uses physics-based side information to inform the structure of the neural network itself, and to place constraints on the values of the outputs and the internal states of the model. It represents the system's vector field as a composition of known and unknown functions, the latter of which are parametrized by neural networks. The physics-informed constraints are enforced via the augmented Lagrangian method during the model's training. We experimentally demonstrate the benefits of the proposed approach on a variety of dynamical systems -- including a benchmark suite of robotics environments featuring large state spaces, non-linear dynamics, external forces, contact forces, and control inputs. By exploiting a-priori system knowledge during training, the proposed approach learns to predict the system dynamics two orders of magnitude more accurately than a baseline approach that does not include prior knowledge, given the same training dataset.
In-N-Out: Towards Good Initialization for Inpainting and Outpainting
Jun 26, 2021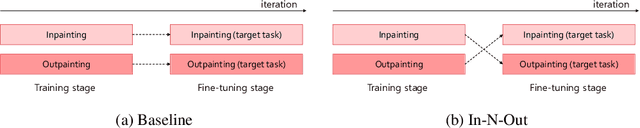
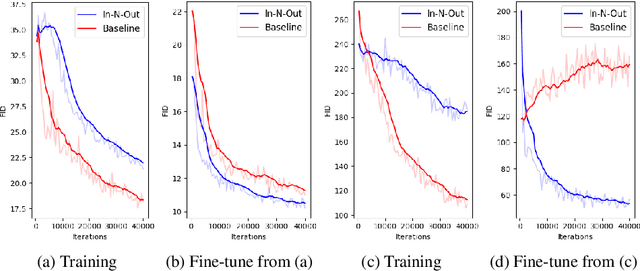

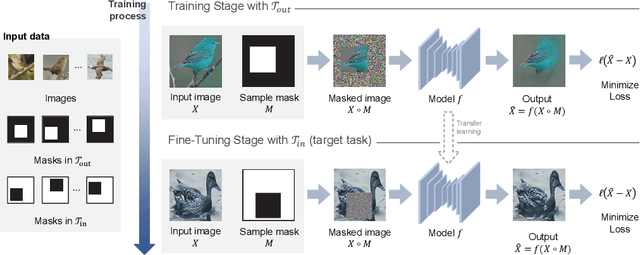
In computer vision, recovering spatial information by filling in masked regions, e.g., inpainting, has been widely investigated for its usability and wide applicability to other various applications: image inpainting, image extrapolation, and environment map estimation. Most of them are studied separately depending on the applications. Our focus, however, is on accommodating the opposite task, e.g., image outpainting, which would benefit the target applications, e.g., image inpainting. Our self-supervision method, In-N-Out, is summarized as a training approach that leverages the knowledge of the opposite task into the target model. We empirically show that In-N-Out -- which explores the complementary information -- effectively takes advantage over the traditional pipelines where only task-specific learning takes place in training. In experiments, we compare our method to the traditional procedure and analyze the effectiveness of our method on different applications: image inpainting, image extrapolation, and environment map estimation. For these tasks, we demonstrate that In-N-Out consistently improves the performance of the recent works with In-N-Out self-supervision to their training procedure. Also, we show that our approach achieves better results than an existing training approach for outpainting.
LightMove: A Lightweight Next-POI Recommendation for Taxicab Rooftop Advertising
Aug 16, 2021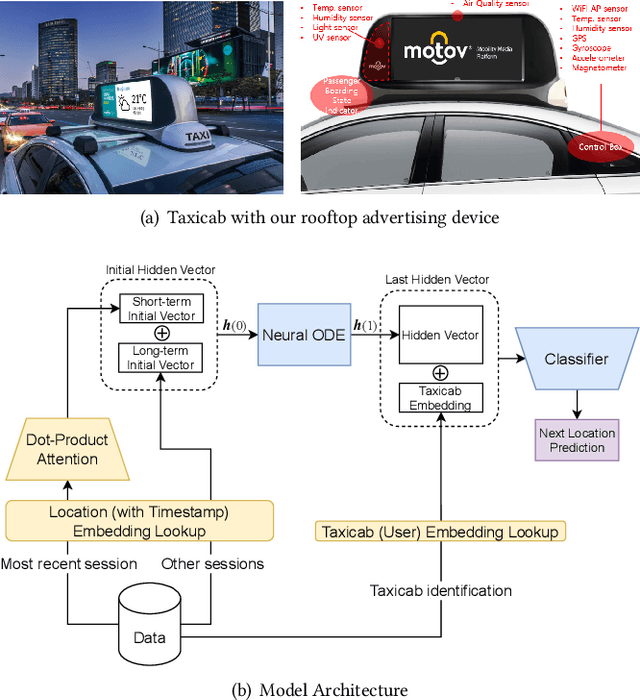

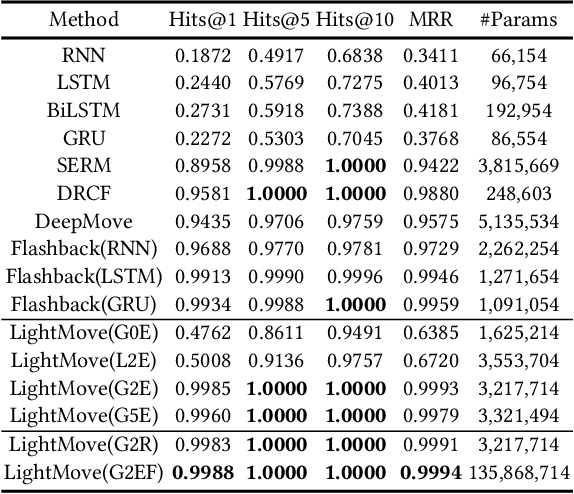
Mobile digital billboards are an effective way to augment brand-awareness. Among various such mobile billboards, taxicab rooftop devices are emerging in the market as a brand new media. Motov is a leading company in South Korea in the taxicab rooftop advertising market. In this work, we present a lightweight yet accurate deep learning-based method to predict taxicabs' next locations to better prepare for targeted advertising based on demographic information of locations. Considering the fact that next POI recommendation datasets are frequently sparse, we design our presented model based on neural ordinary differential equations (NODEs), which are known to be robust to sparse/incorrect input, with several enhancements. Our model, which we call LightMove, has a larger prediction accuracy, a smaller number of parameters, and/or a smaller training/inference time, when evaluating with various datasets, in comparison with state-of-the-art models.
Deep Virtual Markers for Articulated 3D Shapes
Aug 20, 2021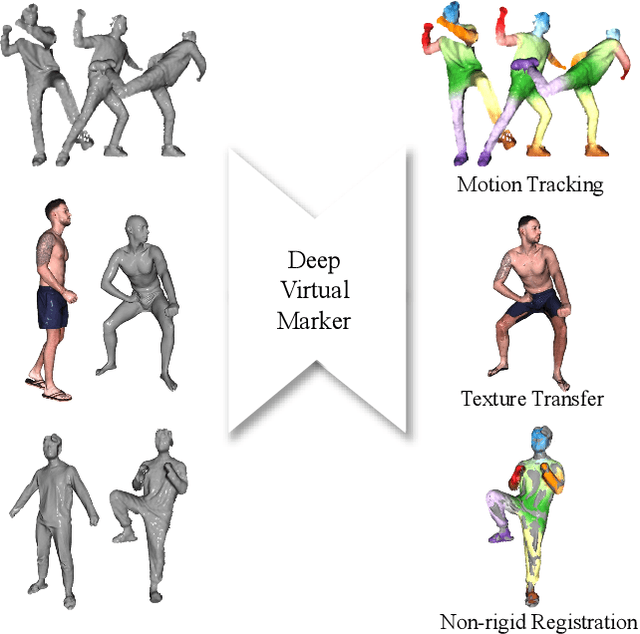
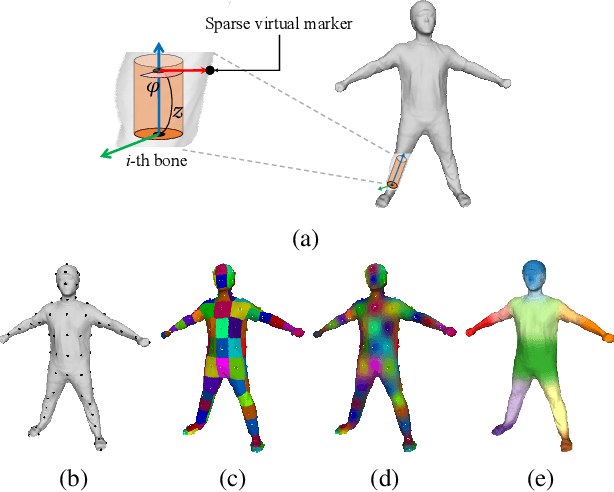
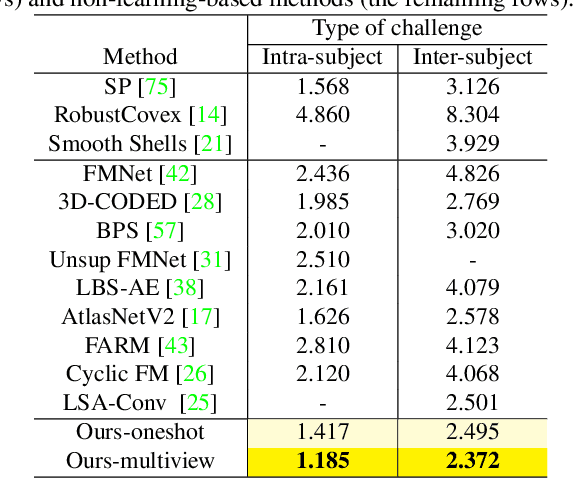
We propose deep virtual markers, a framework for estimating dense and accurate positional information for various types of 3D data. We design a concept and construct a framework that maps 3D points of 3D articulated models, like humans, into virtual marker labels. To realize the framework, we adopt a sparse convolutional neural network and classify 3D points of an articulated model into virtual marker labels. We propose to use soft labels for the classifier to learn rich and dense interclass relationships based on geodesic distance. To measure the localization accuracy of the virtual markers, we test FAUST challenge, and our result outperforms the state-of-the-art. We also observe outstanding performance on the generalizability test, unseen data evaluation, and different 3D data types (meshes and depth maps). We show additional applications using the estimated virtual markers, such as non-rigid registration, texture transfer, and realtime dense marker prediction from depth maps.
Automated Generation of Accurate \& Fluent Medical X-ray Reports
Aug 27, 2021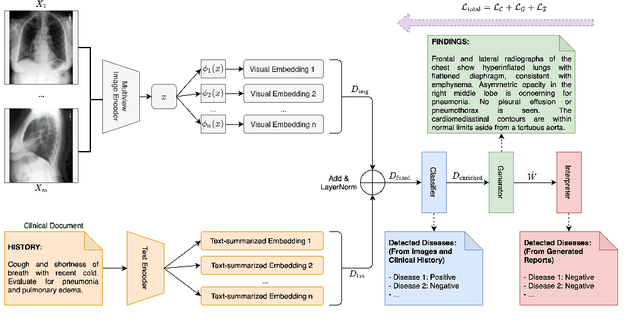
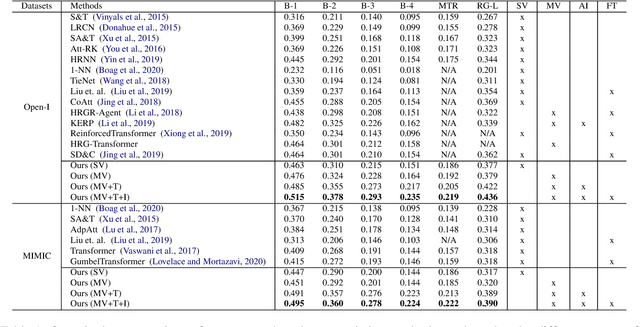
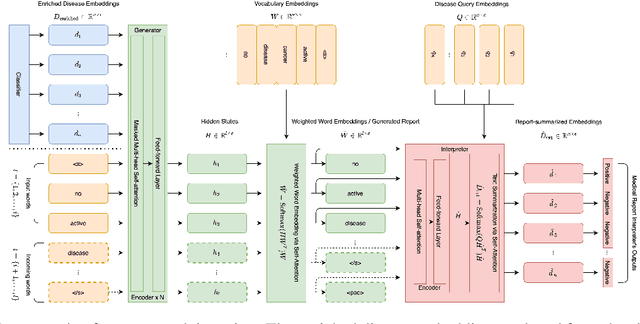
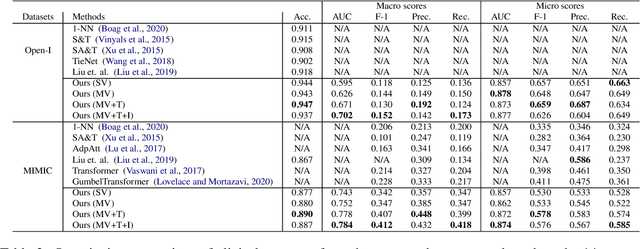
Our paper focuses on automating the generation of medical reports from chest X-ray image inputs, a critical yet time-consuming task for radiologists. Unlike existing medical re-port generation efforts that tend to produce human-readable reports, we aim to generate medical reports that are both fluent and clinically accurate. This is achieved by our fully differentiable and end-to-end paradigm containing three complementary modules: taking the chest X-ray images and clinical his-tory document of patients as inputs, our classification module produces an internal check-list of disease-related topics, referred to as enriched disease embedding; the embedding representation is then passed to our transformer-based generator, giving rise to the medical reports; meanwhile, our generator also pro-duces the weighted embedding representation, which is fed to our interpreter to ensure consistency with respect to disease-related topics.Our approach achieved promising results on commonly-used metrics concerning language fluency and clinical accuracy. Moreover, noticeable performance gains are consistently ob-served when additional input information is available, such as the clinical document and extra scans of different views.
DAE : Discriminatory Auto-Encoder for multivariate time-series anomaly detection in air transportation
Sep 08, 2021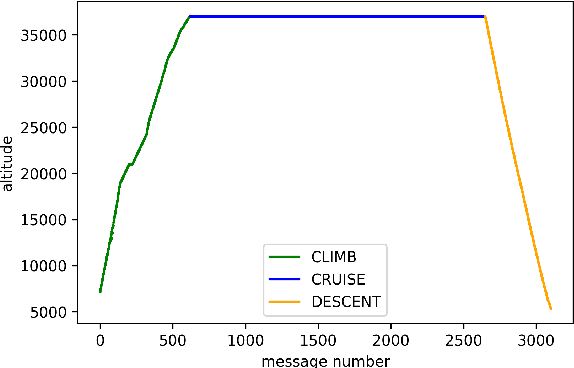
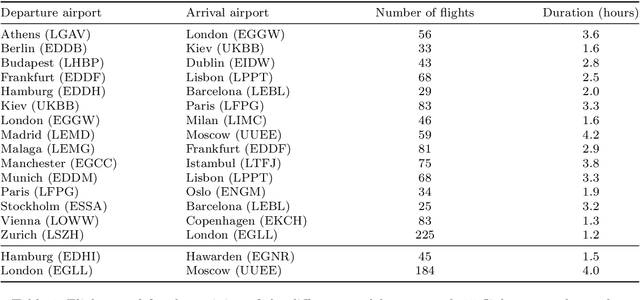
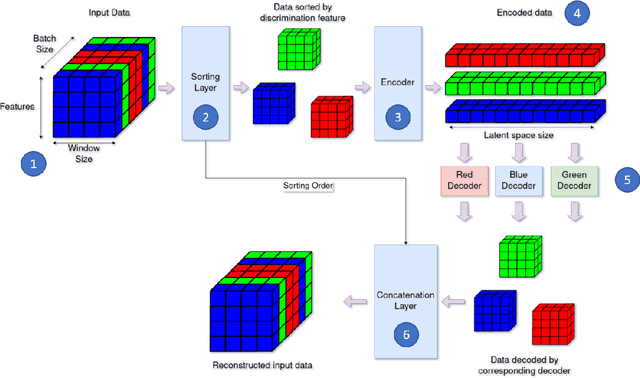
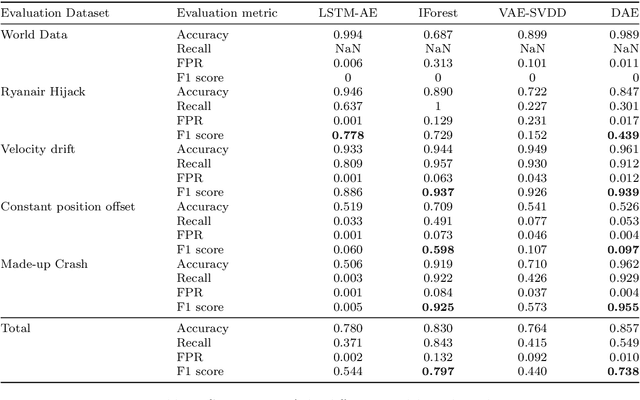
The Automatic Dependent Surveillance Broadcast protocol is one of the latest compulsory advances in air surveillance. While it supports the tracking of the ever-growing number of aircraft in the air, it also introduces cybersecurity issues that must be mitigated e.g., false data injection attacks where an attacker emits fake surveillance information. The recent data sources and tools available to obtain flight tracking records allow the researchers to create datasets and develop Machine Learning models capable of detecting such anomalies in En-Route trajectories. In this context, we propose a novel multivariate anomaly detection model called Discriminatory Auto-Encoder (DAE). It uses the baseline of a regular LSTM-based auto-encoder but with several decoders, each getting data of a specific flight phase (e.g. climbing, cruising or descending) during its training.To illustrate the DAE's efficiency, an evaluation dataset was created using real-life anomalies as well as realistically crafted ones, with which the DAE as well as three anomaly detection models from the literature were evaluated. Results show that the DAE achieves better results in both accuracy and speed of detection. The dataset, the models implementations and the evaluation results are available in an online repository, thereby enabling replicability and facilitating future experiments.