 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Virtual Markers for Articulated 3D Shapes
Aug 20, 2021
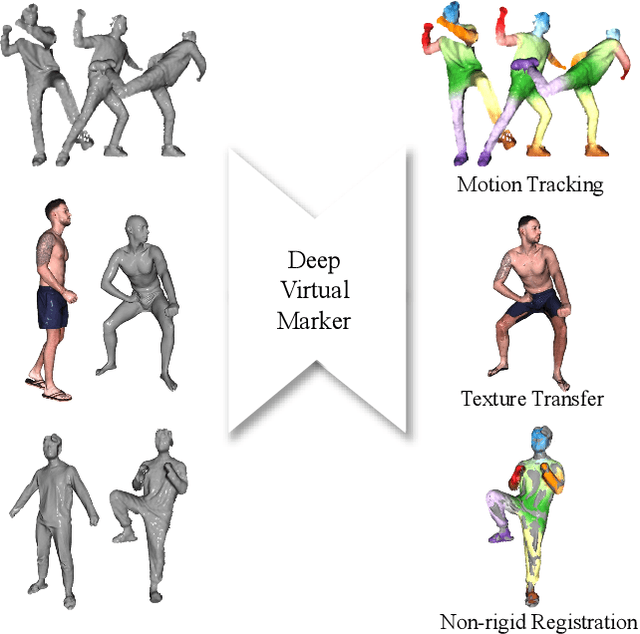
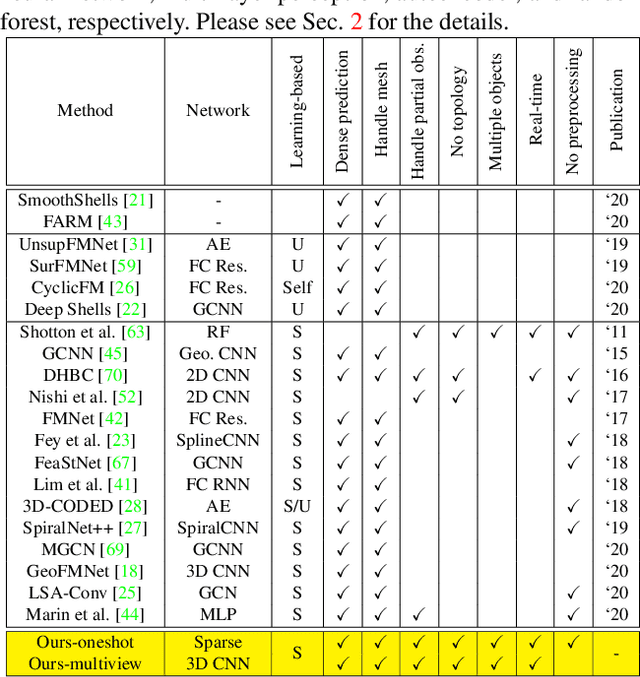
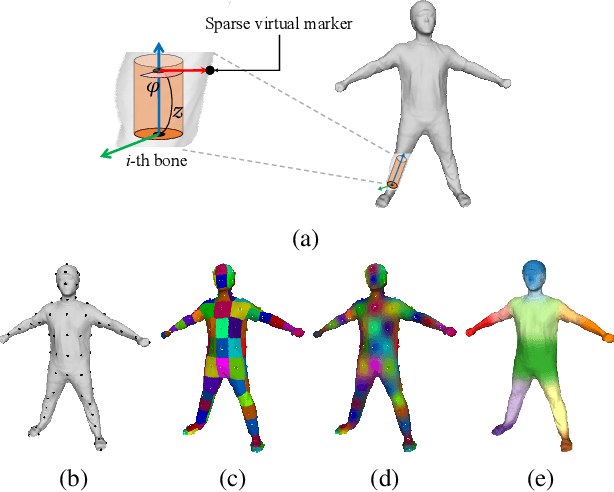
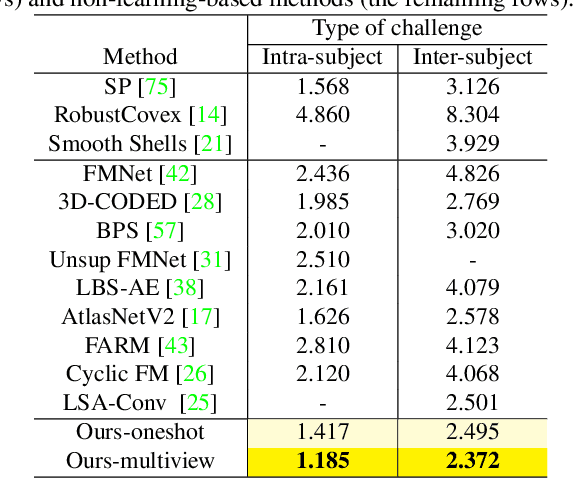
We propose deep virtual markers, a framework for estimating dense and accurate positional information for various types of 3D data. We design a concept and construct a framework that maps 3D points of 3D articulated models, like humans, into virtual marker labels. To realize the framework, we adopt a sparse convolutional neural network and classify 3D points of an articulated model into virtual marker labels. We propose to use soft labels for the classifier to learn rich and dense interclass relationships based on geodesic distance. To measure the localization accuracy of the virtual markers, we test FAUST challenge, and our result outperforms the state-of-the-art. We also observe outstanding performance on the generalizability test, unseen data evaluation, and different 3D data types (meshes and depth maps). We show additional applications using the estimated virtual markers, such as non-rigid registration, texture transfer, and realtime dense marker prediction from depth maps.
Using Biological Variables and Social Determinants to Predict Malaria and Anemia among Children in Senegal
Aug 08, 2021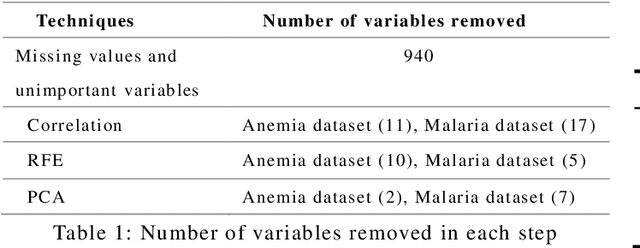
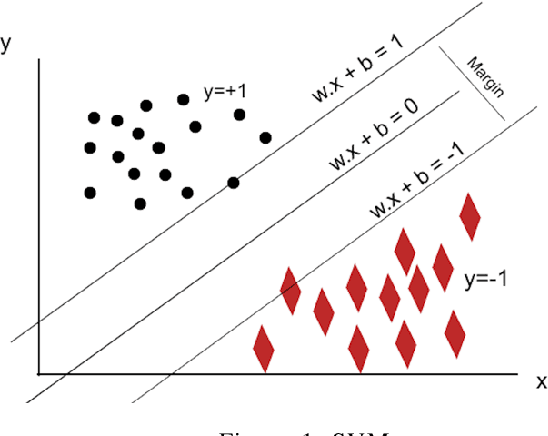
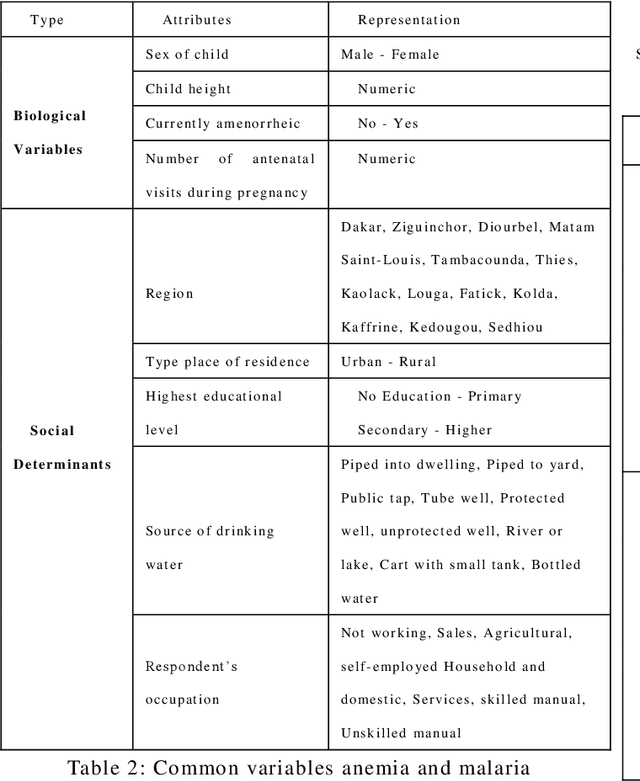

Integrating machine learning techniques in healthcare becomes very common nowadays, and it contributes positively to improving clinical care and health decisions planning. Anemia and malaria are two life-threatening diseases in Africa that affect the red blood cells and reduce hemoglobin production. This paper focuses on analyzing child health data in Senegal using four machine learning algorithms in Python: KNN, Random Forests, SVM, and Na\"ive Bayes. Our task aims to investigate large-scale data from The Demographic and Health Survey (DHS) and to find out hidden information for anemia and malaria. We present two classification models for the two blood disorders using biological variables and social determinants. The findings of this research will contribute to improving child healthcare in Senegal by eradicating anemia and malaria, and decreasing the child mortality rate.
LightMove: A Lightweight Next-POI Recommendation for Taxicab Rooftop Advertising
Aug 16, 2021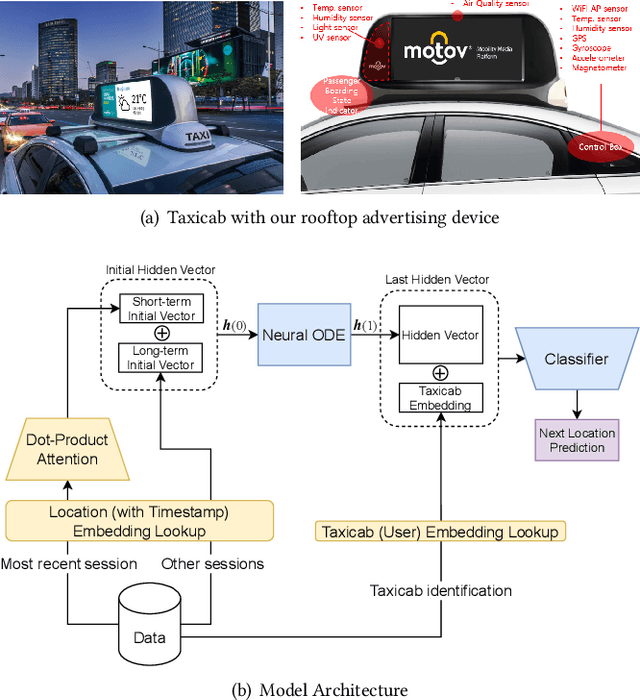

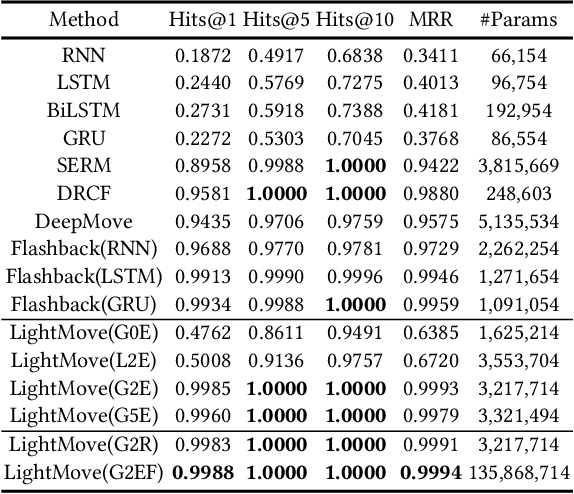
Mobile digital billboards are an effective way to augment brand-awareness. Among various such mobile billboards, taxicab rooftop devices are emerging in the market as a brand new media. Motov is a leading company in South Korea in the taxicab rooftop advertising market. In this work, we present a lightweight yet accurate deep learning-based method to predict taxicabs' next locations to better prepare for targeted advertising based on demographic information of locations. Considering the fact that next POI recommendation datasets are frequently sparse, we design our presented model based on neural ordinary differential equations (NODEs), which are known to be robust to sparse/incorrect input, with several enhancements. Our model, which we call LightMove, has a larger prediction accuracy, a smaller number of parameters, and/or a smaller training/inference time, when evaluating with various datasets, in comparison with state-of-the-art models.
Causally Constrained Data Synthesis for Private Data Release
May 27, 2021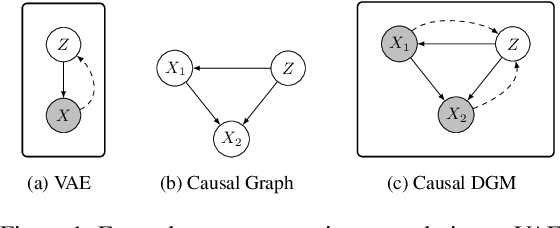
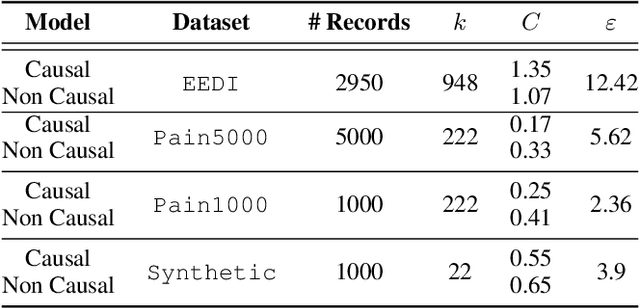
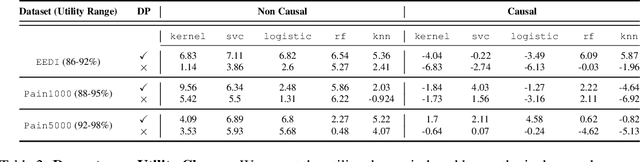
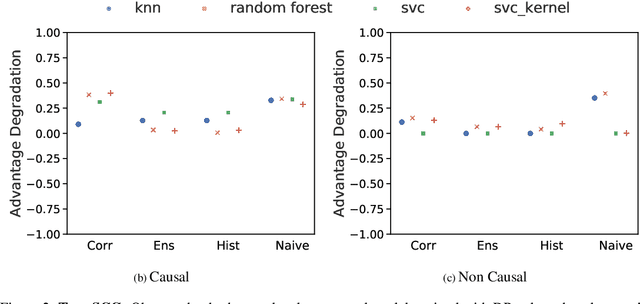
Making evidence based decisions requires data. However for real-world applications, the privacy of data is critical. Using synthetic data which reflects certain statistical properties of the original data preserves the privacy of the original data. To this end, prior works utilize differentially private data release mechanisms to provide formal privacy guarantees. However, such mechanisms have unacceptable privacy vs. utility trade-offs. We propose incorporating causal information into the training process to favorably modify the aforementioned trade-off. We theoretically prove that generative models trained with additional causal knowledge provide stronger differential privacy guarantees. Empirically, we evaluate our solution comparing different models based on variational auto-encoders (VAEs), and show that causal information improves resilience to membership inference, with improvements in downstream utility.
Lifelong 3D Object Recognition and Grasp Synthesis Using Dual Memory Recurrent Self-Organization Networks
Sep 23, 2021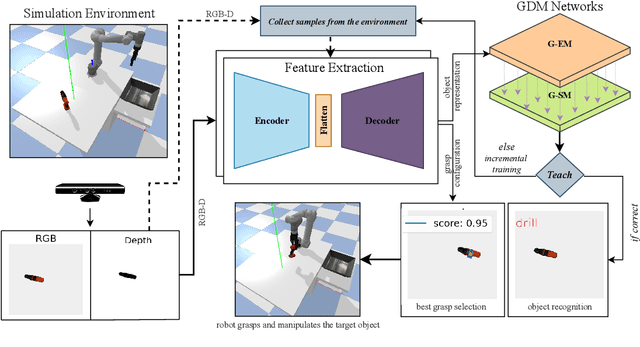

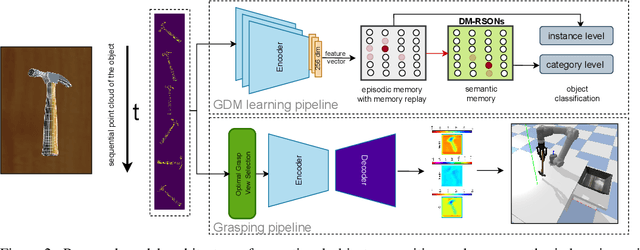

Humans learn to recognize and manipulate new objects in lifelong settings without forgetting the previously gained knowledge under non-stationary and sequential conditions. In autonomous systems, the agents also need to mitigate similar behavior to continually learn the new object categories and adapt to new environments. In most conventional deep neural networks, this is not possible due to the problem of catastrophic forgetting, where the newly gained knowledge overwrites existing representations. Furthermore, most state-of-the-art models excel either in recognizing the objects or in grasp prediction, while both tasks use visual input. The combined architecture to tackle both tasks is very limited. In this paper, we proposed a hybrid model architecture consists of a dynamically growing dual-memory recurrent neural network (GDM) and an autoencoder to tackle object recognition and grasping simultaneously. The autoencoder network is responsible to extract a compact representation for a given object, which serves as input for the GDM learning, and is responsible to predict pixel-wise antipodal grasp configurations. The GDM part is designed to recognize the object in both instances and categories levels. We address the problem of catastrophic forgetting using the intrinsic memory replay, where the episodic memory periodically replays the neural activation trajectories in the absence of external sensory information. To extensively evaluate the proposed model in a lifelong setting, we generate a synthetic dataset due to lack of sequential 3D objects dataset. Experiment results demonstrated that the proposed model can learn both object representation and grasping simultaneously in continual learning scenarios.
Independent Asymmetric Embedding Model for Cascade Prediction on Social Network
May 18, 2021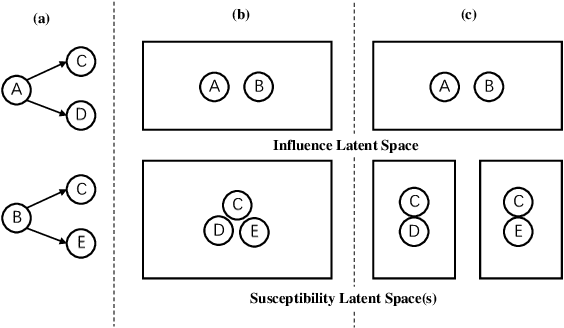
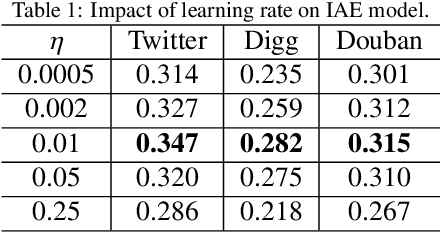
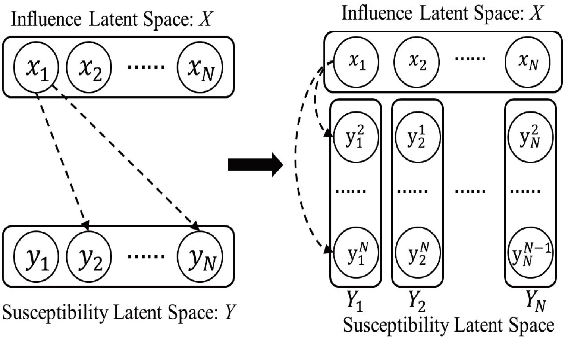
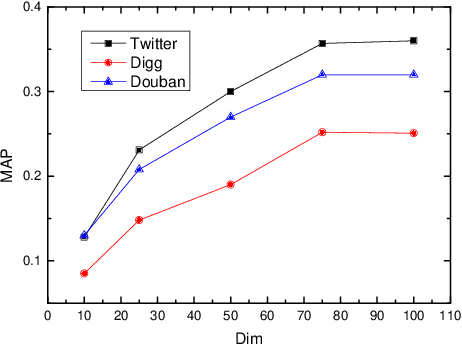
The prediction for information diffusion on social networks has great practical significance in marketing and public opinion control. Cascade prediction aims to predict the individuals who will potentially repost the message on the social network. One kind of methods either exploit demographical, structural, and temporal features for prediction, or explicitly rely on particular information diffusion models. The other kind of models are fully data-driven and do not require a global network structure. Thus massive diffusion prediction models based on network embedding are proposed. These models embed the users into the latent space using their cascade information, but are lack of consideration for the intervene among users when embedding. In this paper, we propose an independent asymmetric embedding method to learn social embedding for cascade prediction. Different from existing methods, our method embeds each individual into one latent influence space and multiple latent susceptibility spaces. Furthermore, our method captures the co-occurrence regulation of user combination in cascades to improve the calculating effectiveness. The results of extensive experiments conducted on real-world datasets verify both the predictive accuracy and cost-effectiveness of our approach.
Mathematics as information compression via the matching and unification of patterns
Oct 09, 2018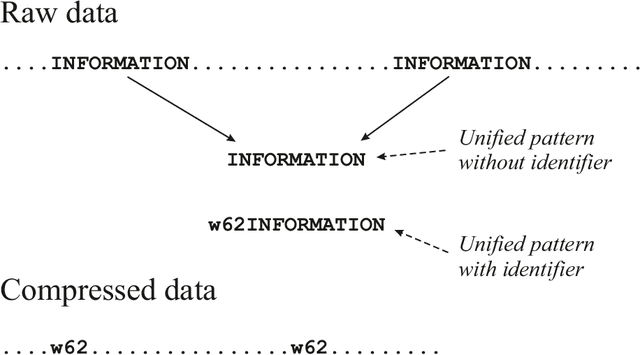
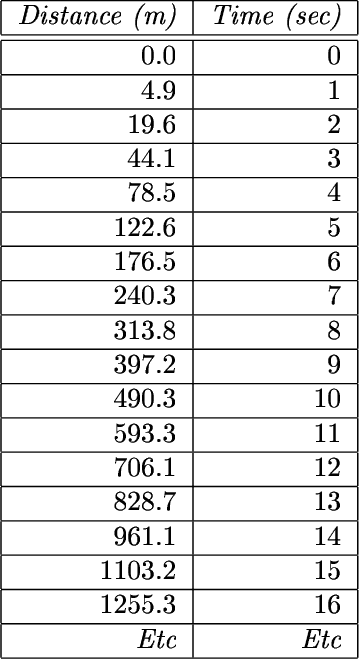
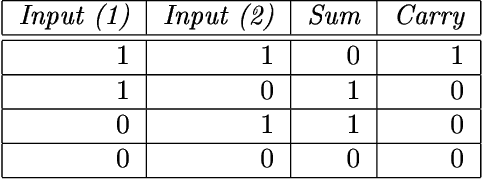
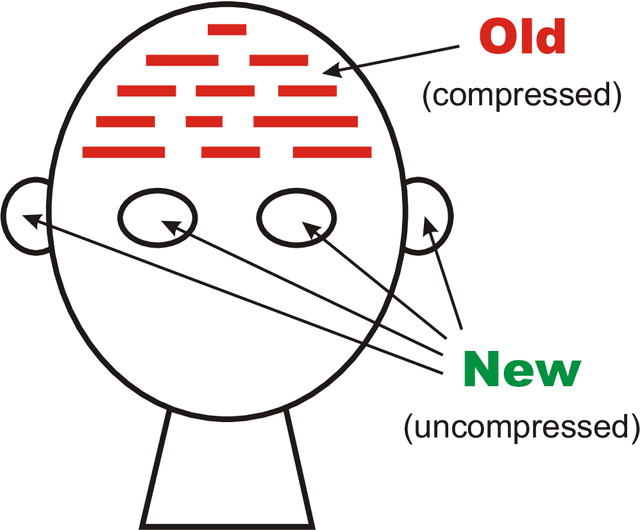
This paper describes a novel perspective on the foundations of mathematics: how mathematics may be seen to be largely about 'information compression via the matching and unification of patterns' (ICMUP). ICMUP is itself a novel approach to information compression, couched in terms of non-mathematical primitives, as is necessary in any investigation of the foundations of mathematics. This new perspective on the foundations of mathematics has grown out of an extensive programme of research developing the "SP Theory of Intelligence" and its realisation in the "SP Computer Model", a system in which a generalised version of ICMUP -- the powerful concept of SP-multiple-alignment -- plays a central role. These ideas may be seen to be part of a "Big Picture" comprising six areas of interest, with information compression as a unifying theme. The paper describes the close relation between mathematics and information compression, and describes examples showing how variants of ICMUP may be seen in widely-used structures and operations in mathematics. Examples are also given to show how the mathematics-related disciplines of logic and computing may be understood as ICMUP. There are many potential benefits and applications of these ideas.
Spelling provides a precise (but sometimes misplaced) phonological target. Orthography and acoustic variability in second language word learning
Sep 08, 2021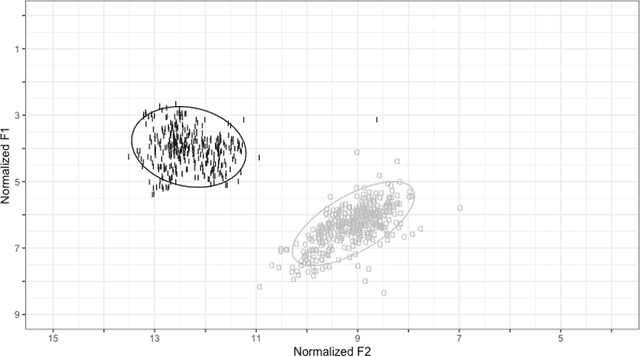

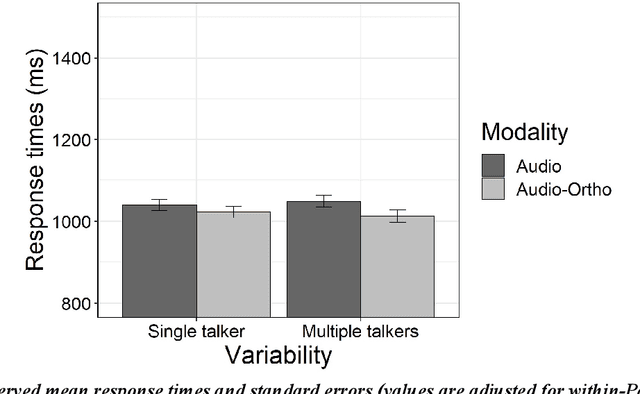

L1 French participants learned novel L2 English words over two days of learning sessions, with half of the words presented with their orthographic forms (Audio-Ortho) and half without (Audio only). One group heard the words pronounced by a single talker, while another group heard them pronounced by multiple talkers. On the third day, they completed a variety of tasks to evaluate their learning. Our results show a robust influence of orthography, with faster response times in both production (picture naming) and recognition (picture mapping) tasks for words learned in the Audio-Ortho condition. Moreover, formant analyses of the picture naming responses show that orthographic input pulls pronunciations of English novel words towards a non-native (French) phonological target. Words learned with their orthographic forms were pronounced more precisely (with smaller Dispersion Scores), but were misplaced in the vowel space (as reflected by smaller Euclidian distances with respect to French vowels). Finally, we found only limited evidence of an effect of talker-based acoustic variability: novel words learned with multiple talkers showed faster responses times in the picture naming task, but only in the Audio-only condition, which suggests that orthographic information may have overwhelmed any advantage of talker-based acoustic variability.
SDTP: Semantic-aware Decoupled Transformer Pyramid for Dense Image Prediction
Sep 18, 2021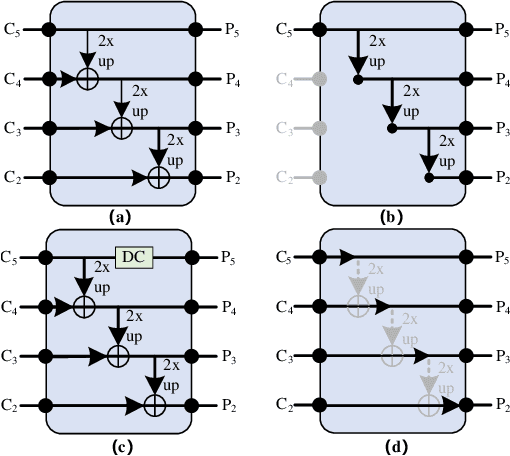
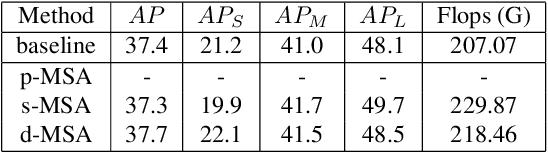
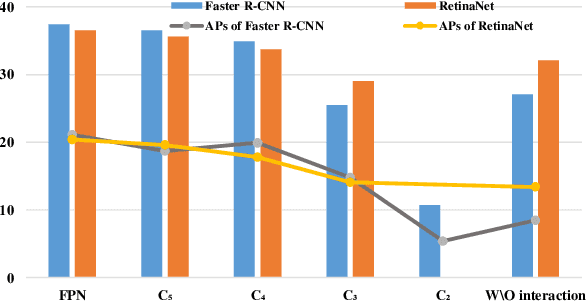
Although transformer has achieved great progress on computer vision tasks, the scale variation in dense image prediction is still the key challenge. Few effective multi-scale techniques are applied in transformer and there are two main limitations in the current methods. On one hand, self-attention module in vanilla transformer fails to sufficiently exploit the diversity of semantic information because of its rigid mechanism. On the other hand, it is hard to build attention and interaction among different levels due to the heavy computational burden. To alleviate this problem, we first revisit multi-scale problem in dense prediction, verifying the significance of diverse semantic representation and multi-scale interaction, and exploring the adaptation of transformer to pyramidal structure. Inspired by these findings, we propose a novel Semantic-aware Decoupled Transformer Pyramid (SDTP) for dense image prediction, consisting of Intra-level Semantic Promotion (ISP), Cross-level Decoupled Interaction (CDI) and Attention Refinement Function (ARF). ISP explores the semantic diversity in different receptive space. CDI builds the global attention and interaction among different levels in decoupled space which also solves the problem of heavy computation. Besides, ARF is further added to refine the attention in transformer. Experimental results demonstrate the validity and generality of the proposed method, which outperforms the state-of-the-art by a significant margin in dense image prediction tasks. Furthermore, the proposed components are all plug-and-play, which can be embedded in other methods.
Pack Together: Entity and Relation Extraction with Levitated Marker
Sep 13, 2021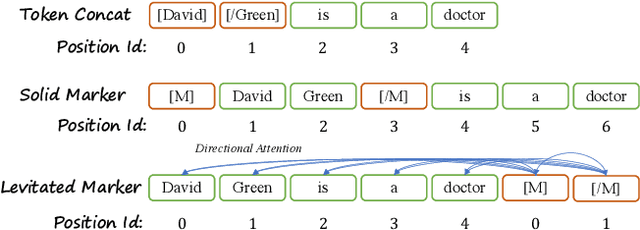
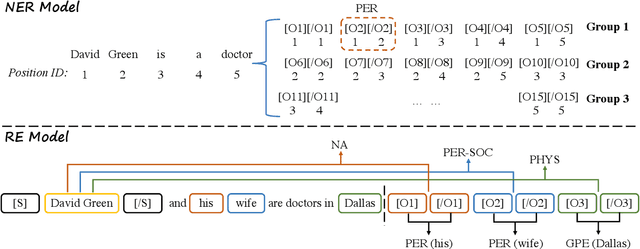
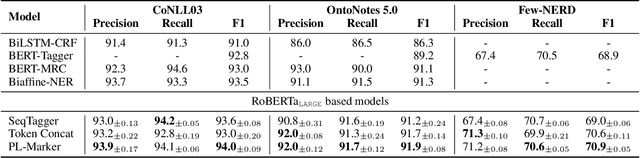
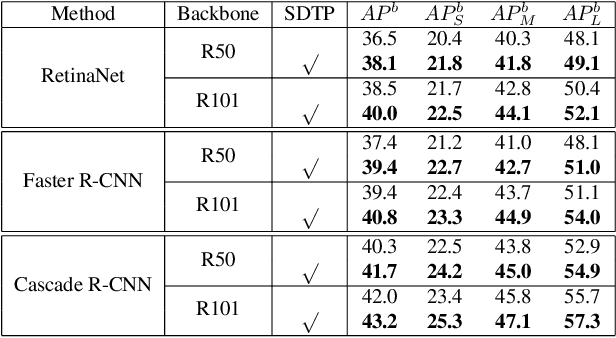
Named Entity Recognition (NER) and Relation Extraction (RE) are the core sub-tasks for information extraction. Many recent works formulate these two tasks as the span (pair) classification problem, and thus focus on investigating how to obtain a better span representation from the pre-trained encoder. However, a major limitation of existing works is that they ignore the dependencies between spans (pairs). In this work, we propose a novel span representation approach, named Packed Levitated Markers, to consider the dependencies between the spans (pairs) by strategically packing the markers in the encoder. In particular, we propose a group packing strategy to enable our model to process massive spans together to consider their dependencies with limited resources. Furthermore, for those more complicated span pair classification tasks, we design a subject-oriented packing strategy, which packs each subject and all its objects into an instance to model the dependencies between the same-subject span pairs. Our experiments show that our model with packed levitated markers outperforms the sequence labeling model by 0.4%-1.9% F1 on three flat NER tasks, beats the token concat model on six NER benchmarks, and obtains a 3.5%-3.6% strict relation F1 improvement with higher speed over previous SOTA models on ACE04 and ACE05. Code and models are publicly available at https://github.com/thunlp/PL-Marker.