 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GRNN: Generative Regression Neural Network -- A Data Leakage Attack for Federated Learning
May 02, 2021
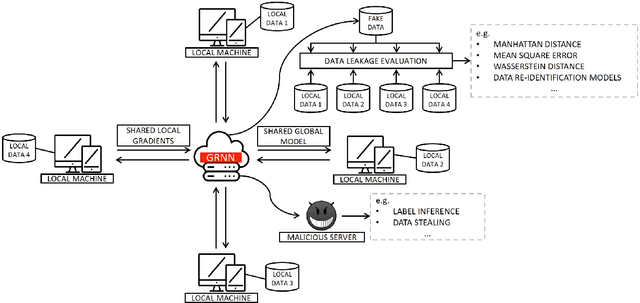
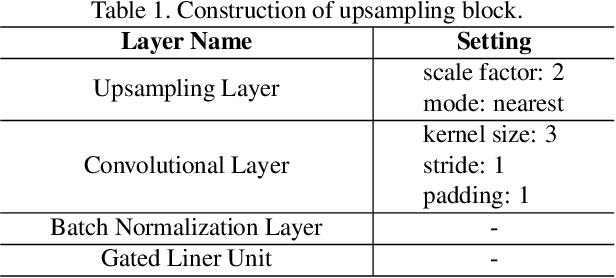
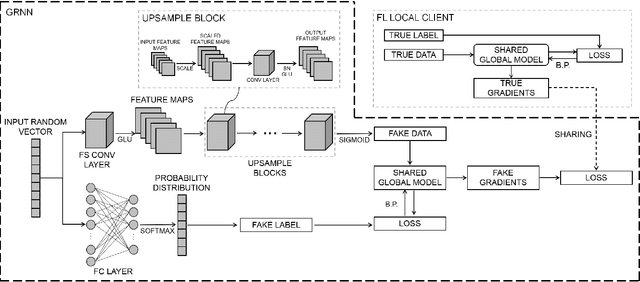

Data privacy has become an increasingly important issue in machine learning. Many approaches have been developed to tackle this issue, e.g., cryptography (Homomorphic Encryption, Differential Privacy, etc.) and collaborative training (Secure Multi-Party Computation, Distributed Learning and Federated Learning). These techniques have a particular focus on data encryption or secure local computation. They transfer the intermediate information to the third-party to compute the final result. Gradient exchanging is commonly considered to be a secure way of training a robust model collaboratively in deep learning. However, recent researches have demonstrated that sensitive information can be recovered from the shared gradient. Generative Adversarial Networks (GAN), in particular, have shown to be effective in recovering those information. However, GAN based techniques require additional information, such as class labels which are generally unavailable for privacy persevered learning. In this paper, we show that, in Federated Learning (FL) system, image-based privacy data can be easily recovered in full from the shared gradient only via our proposed Generative Regression Neural Network (GRNN). We formulate the attack to be a regression problem and optimise two branches of the generative model by minimising the distance between gradients. We evaluate our method on several image classification tasks. The results illustrate that our proposed GRNN outperforms state-of-the-art methods with better stability, stronger robustness, and higher accuracy. It also has no convergence requirement to the global FL model. Moreover, we demonstrate information leakage using face re-identification. Some defense strategies are also discussed in this work.
Confidence-guided Adaptive Gate and Dual Differential Enhancement for Video Salient Object Detection
May 14, 2021
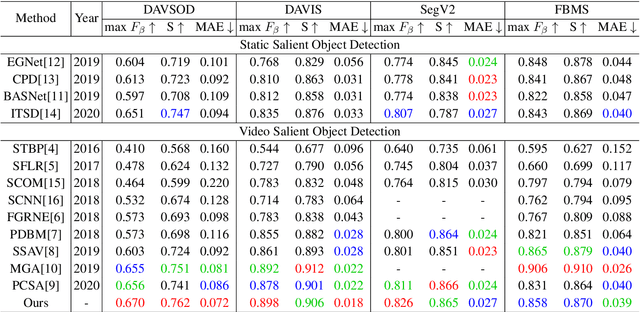
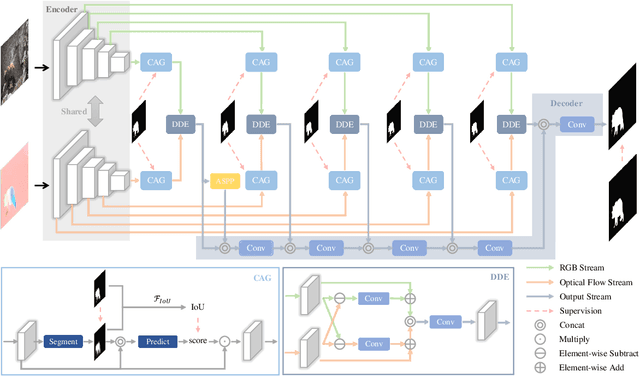
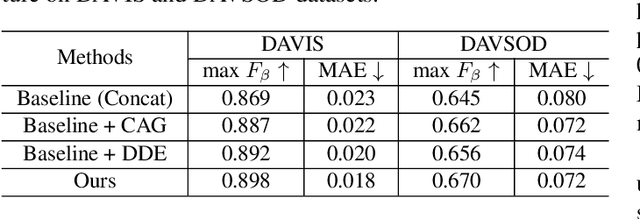
Video salient object detection (VSOD) aims to locate and segment the most attractive object by exploiting both spatial cues and temporal cues hidden in video sequences. However, spatial and temporal cues are often unreliable in real-world scenarios, such as low-contrast foreground, fast motion, and multiple moving objects. To address these problems, we propose a new framework to adaptively capture available information from spatial and temporal cues, which contains Confidence-guided Adaptive Gate (CAG) modules and Dual Differential Enhancement (DDE) modules. For both RGB features and optical flow features, CAG estimates confidence scores supervised by the IoU between predictions and the ground truths to re-calibrate the information with a gate mechanism. DDE captures the differential feature representation to enrich the spatial and temporal information and generate the fused features. Experimental results on four widely used datasets demonstrate the effectiveness of the proposed method against thirteen state-of-the-art methods.
Optimal Status Update for Caching Enabled IoT Networks: A Dueling Deep R-Network Approach
Jun 13, 2021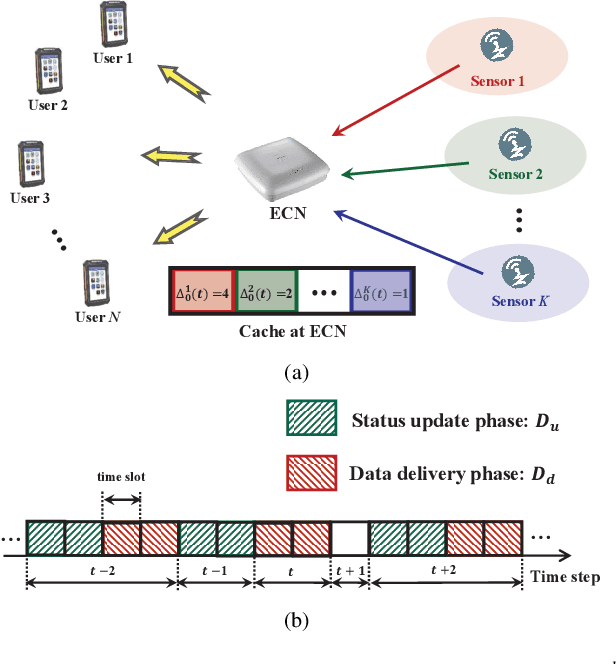
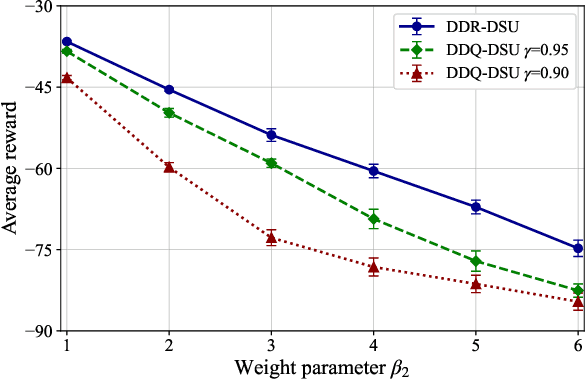
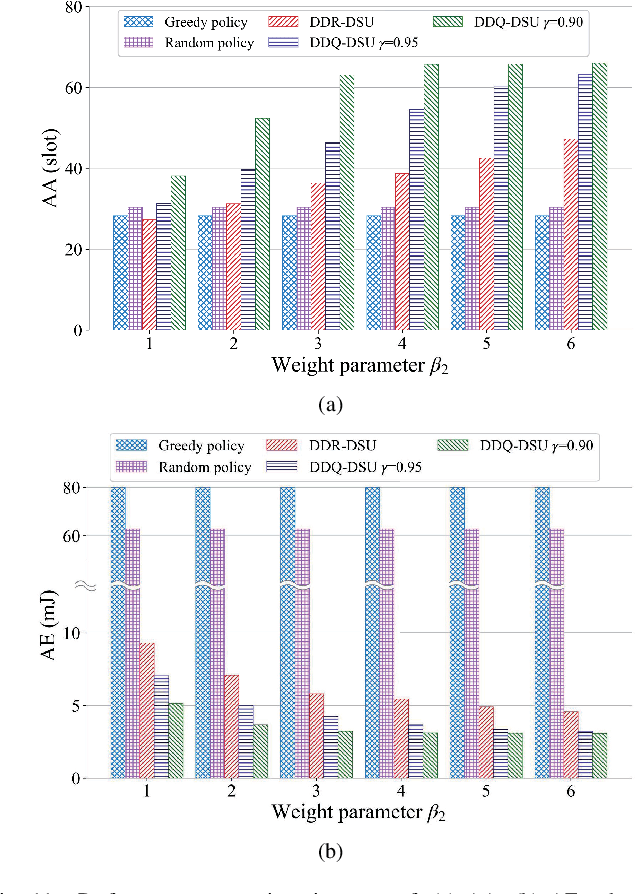
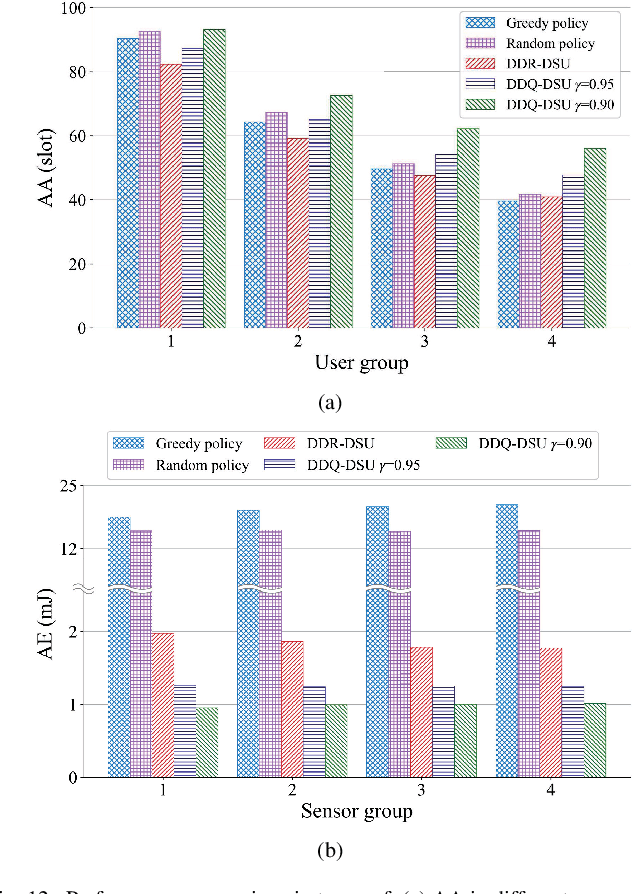
In the Internet of Things (IoT) networks, caching is a promising technique to alleviate energy consumption of sensors by responding to users' data requests with the data packets cached in the edge caching node (ECN). However, without an efficient status update strategy, the information obtained by users may be stale, which in return would inevitably deteriorate the accuracy and reliability of derived decisions for real-time applications. In this paper, we focus on striking the balance between the information freshness, in terms of age of information (AoI), experienced by users and energy consumed by sensors, by appropriately activating sensors to update their current status. Particularly, we first depict the evolutions of the AoI with each sensor from different users' perspective with time steps of non-uniform duration, which are determined by both the users' data requests and the ECN's status update decision. Then, we formulate a non-uniform time step based dynamic status update optimization problem to minimize the long-term average cost, jointly considering the average AoI and energy consumption. To this end, a Markov Decision Process is formulated and further, a dueling deep R-network based dynamic status update algorithm is devised by combining dueling deep Q-network and tabular R-learning, with which challenges from the curse of dimensionality and unknown of the environmental dynamics can be addressed. Finally, extensive simulations are conducted to validate the effectiveness of our proposed algorithm by comparing it with five baseline deep reinforcement learning algorithms and policies.
Locality Relationship Constrained Multi-view Clustering Framework
Jul 11, 2021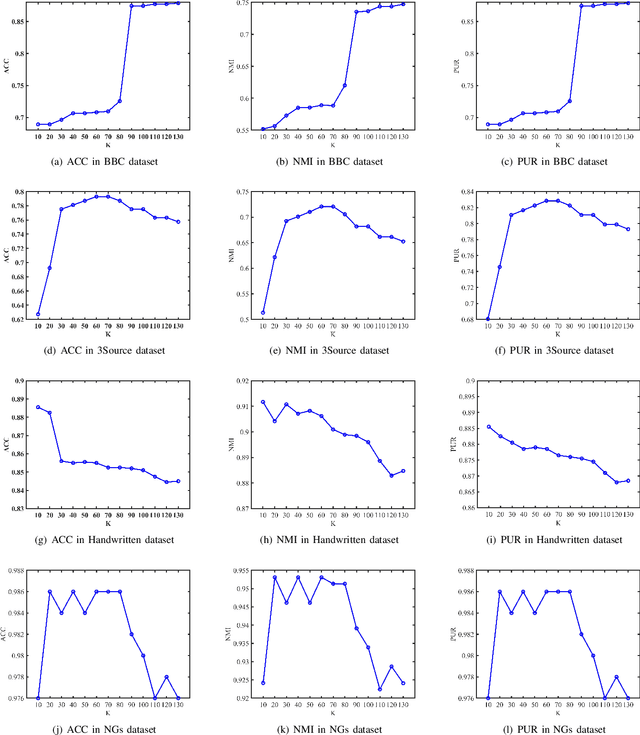
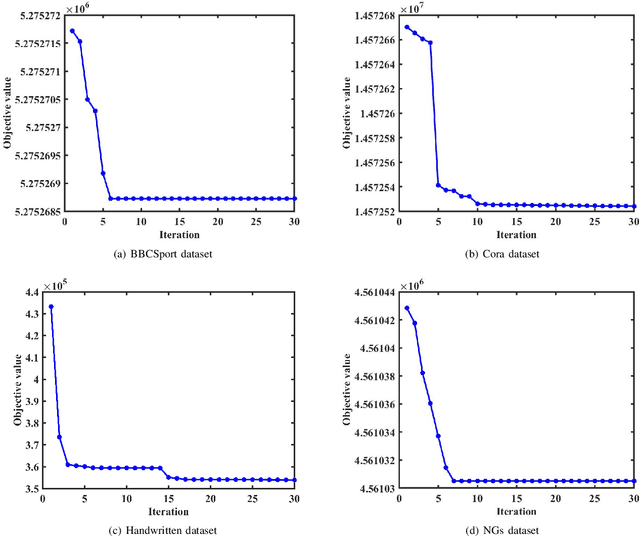
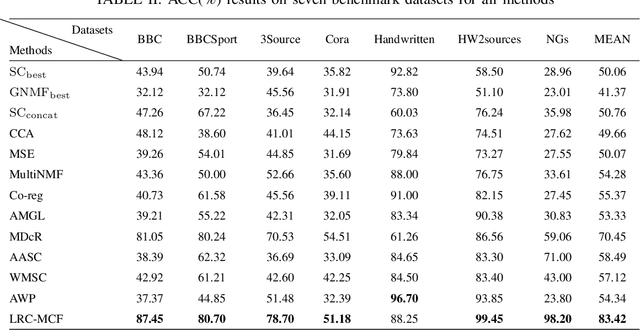
In most practical applications, it's common to utilize multiple features from different views to represent one object. Among these works, multi-view subspace-based clustering has gained extensive attention from many researchers, which aims to provide clustering solutions to multi-view data. However, most existing methods fail to take full use of the locality geometric structure and similarity relationship among samples under the multi-view scenario. To solve these issues, we propose a novel multi-view learning method with locality relationship constraint to explore the problem of multi-view clustering, called Locality Relationship Constrained Multi-view Clustering Framework (LRC-MCF). LRC-MCF aims to explore the diversity, geometric, consensus and complementary information among different views, by capturing the locality relationship information and the common similarity relationships among multiple views. Moreover, LRC-MCF takes sufficient consideration to weights of different views in finding the common-view locality structure and straightforwardly produce the final clusters. To effectually reduce the redundancy of the learned representations, the low-rank constraint on the common similarity matrix is considered additionally. To solve the minimization problem of LRC-MCF, an Alternating Direction Minimization (ADM) method is provided to iteratively calculate all variables LRC-MCF. Extensive experimental results on seven benchmark multi-view datasets validate the effectiveness of the LRC-MCF method.
Infrastructure Node-based Vehicle Localization for Autonomous Driving
Sep 21, 2021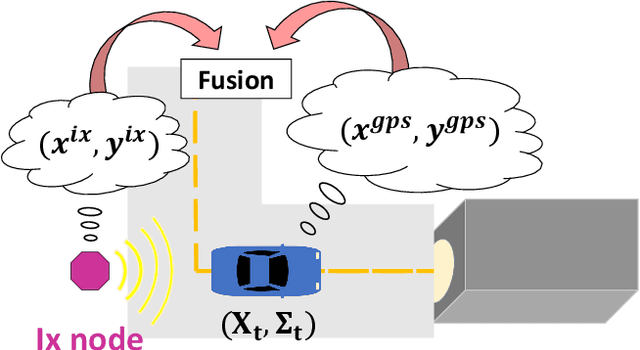

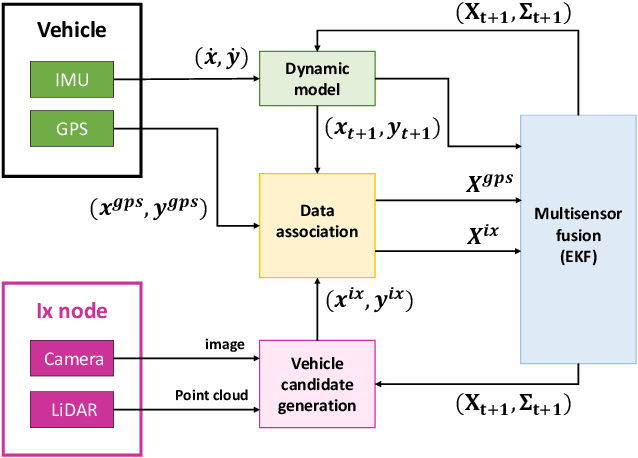
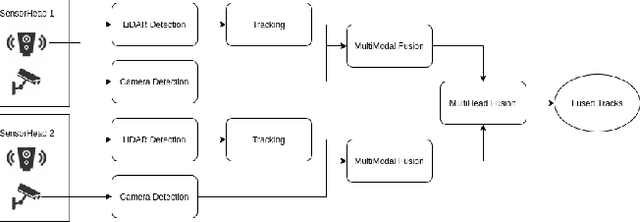
Vehicle localization is essential for autonomous vehicle (AV) navigation and Advanced Driver Assistance Systems (ADAS). Accurate vehicle localization is often achieved via expensive inertial navigation systems or by employing compute-intensive vision processing (LiDAR/camera) to augment the low-cost and noisy inertial sensors. Here we have developed a framework for fusing the information obtained from a smart infrastructure node (ix-node) with the autonomous vehicles on-board localization engine to estimate the robust and accurate pose of the ego-vehicle even with cheap inertial sensors. A smart ix-node is typically used to augment the perception capability of an autonomous vehicle, especially when the onboard perception sensors of AVs are blocked by the dynamic and static objects in the environment thereby making them ineffectual. In this work, we utilize this perception output from an ix-node to increase the localization accuracy of the AV. The fusion of ix-node perception output with the vehicle's low-cost inertial sensors allows us to perform reliable vehicle localization without the need for relying on expensive inertial navigation systems or compute-intensive vision processing onboard the AVs. The proposed approach has been tested on real-world datasets collected from a test track in Ann Arbor, Michigan. Detailed analysis of the experimental results shows that incorporating ix-node data improves localization performance.
SMARRT: Self-Repairing Motion-Reactive Anytime RRT for Dynamic Environments
Sep 10, 2021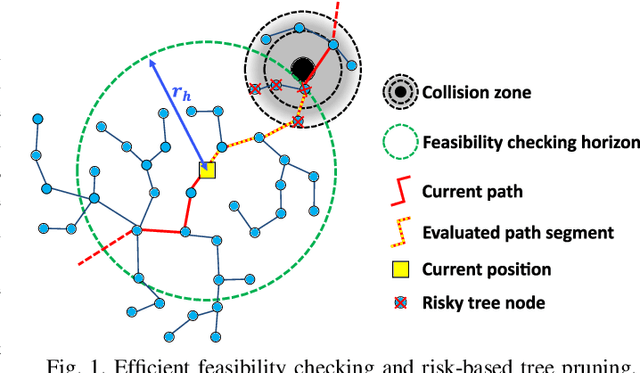
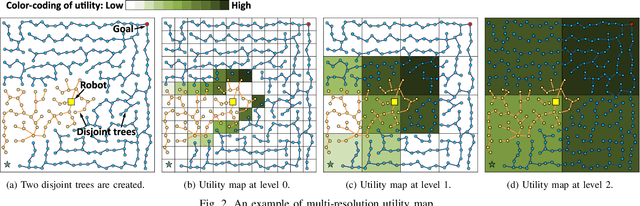
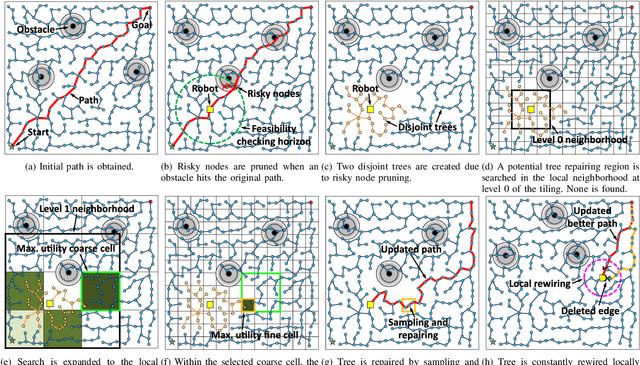
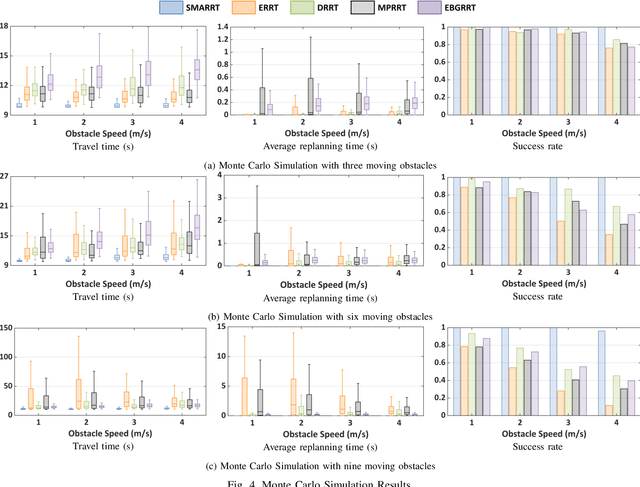
This paper addresses the fast replanning problem in dynamic environments with moving obstacles. Since for randomly moving obstacles the future states are unpredictable, the proposed method, called SMARRT, reacts to obstacle motions and revises the path in real-time based on the current interfering obstacle state (i.e., position and velocity). SMARRT is fast and efficient and performs collision checking only on the partial path segment close to the robot within a feasibility checking horizon. If the path is infeasible, then tree parts associated with the path inside the horizon are pruned while maintaining the maximal tree structure of already-explored regions. Then, a multi-resolution utility map is created to capture the environmental information used to compute the replanning utility for each cell on the multi-scale tiling. A hierarchical searching method is applied on the map to find the sampling cell efficiently. Finally, uniform samples are drawn within the sampling cell for fast replanning. The SMARRT method is validated via simulation runs, and the results are evaluated in comparison to four existing methods. The SMARRT method yields significant improvements in travel time, replanning time, and success rate compared against the existing methods.
Fast Wireless Sensor Anomaly Detection based on Data Stream in Edge Computing Enabled Smart Greenhouse
Jul 28, 2021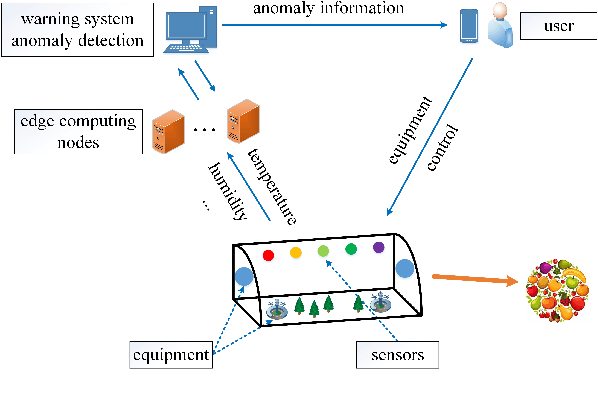
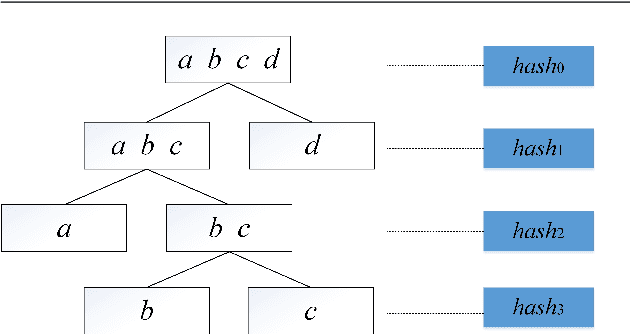

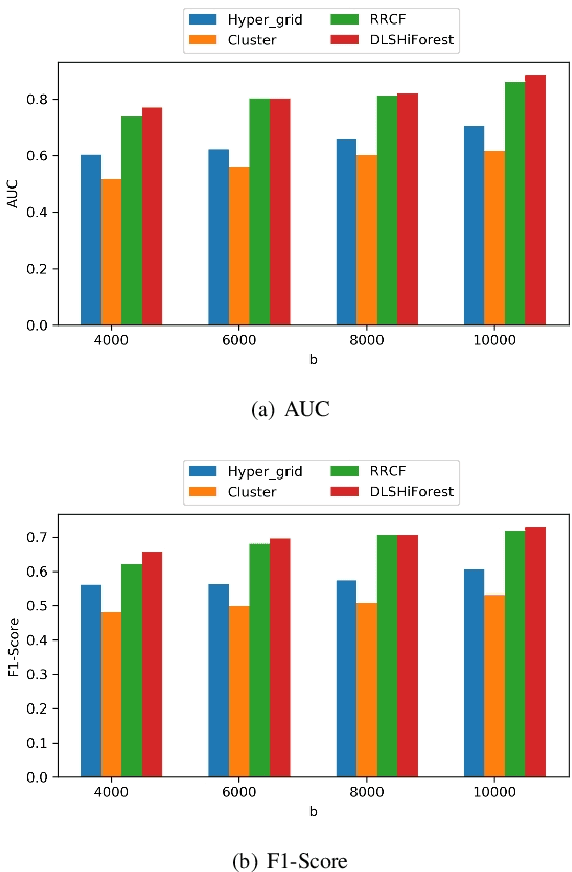
Edge computing enabled smart greenhouse is a representative application of Internet of Things technology, which can monitor the environmental information in real time and employ the information to contribute to intelligent decision-making. In the process, anomaly detection for wireless sensor data plays an important role. However, traditional anomaly detection algorithms originally designed for anomaly detection in static data have not properly considered the inherent characteristics of data stream produced by wireless sensor such as infiniteness, correlations and concept drift, which may pose a considerable challenge on anomaly detection based on data stream, and lead to low detection accuracy and efficiency. First, data stream usually generates quickly which means that it is infinite and enormous, so any traditional off-line anomaly detection algorithm that attempts to store the whole dataset or to scan the dataset multiple times for anomaly detection will run out of memory space. Second, there exist correlations among different data streams, which traditional algorithms hardly consider. Third, the underlying data generation process or data distribution may change over time. Thus, traditional anomaly detection algorithms with no model update will lose their effects. Considering these issues, a novel method (called DLSHiForest) on basis of Locality-Sensitive Hashing and time window technique in this paper is proposed to solve these problems while achieving accurate and efficient detection. Comprehensive experiments are executed using real-world agricultural greenhouse dataset to demonstrate the feasibility of our approach. Experimental results show that our proposal is practicable in addressing challenges of traditional anomaly detection while ensuring accuracy and efficiency.
Cellular traffic offloading via Opportunistic Networking with Reinforcement Learning
Oct 01, 2021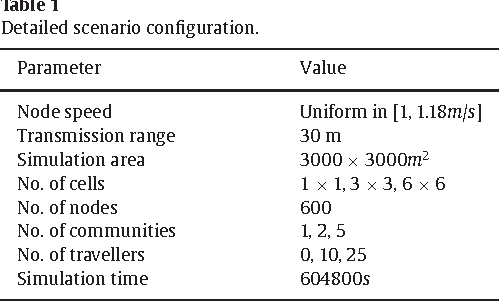

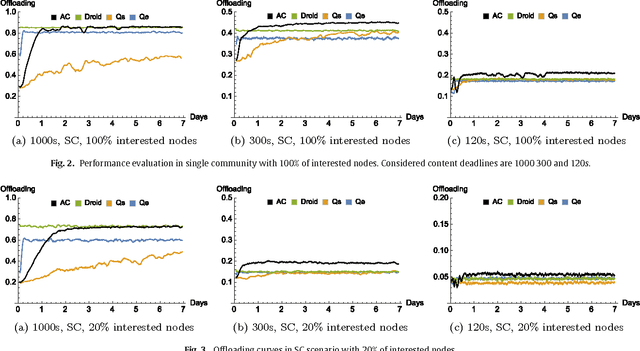
The widespread diffusion of mobile phones is triggering an exponential growth of mobile data traffic that is likely to cause, in the near future, considerable traffic overload issues even in last-generation cellular networks. Offloading part of the traffic to other networks is considered a very promising approach and, in particular, in this paper, we consider offloading through opportunistic networks of users' devices. However, the performance of this solution strongly depends on the pattern of encounters between mobile nodes, which should therefore be taken into account when designing offloading control algorithms. In this paper, we propose an adaptive offloading solution based on the Reinforcement Learning framework and we evaluate and compare the performance of two well-known learning algorithms: Actor-Critic and Q-Learning. More precisely, in our solution the controller of the dissemination process, once trained, is able to select a proper number of content replicas to be injected into the opportunistic network to guarantee the timely delivery of contents to all interested users. We show that our system based on Reinforcement Learning is able to automatically learn a very efficient strategy to reduce the traffic on the cellular network, without relying on any additional context information about the opportunistic network. Our solution achieves a higher level of offloading with respect to other state-of-the-art approaches, in a range of different mobility settings. Moreover, we show that a more refined learning solution, based on the Actor-Critic algorithm, is significantly more efficient than a simpler solution based on Q-learning.
GAN-based Reactive Motion Synthesis with Class-aware Discriminators for Human-human Interaction
Oct 01, 2021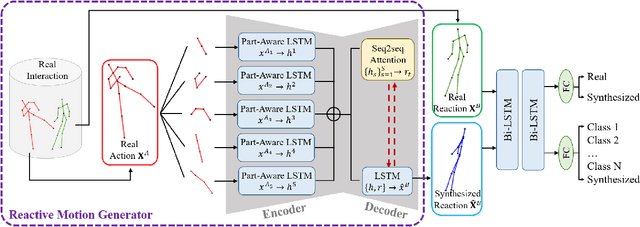
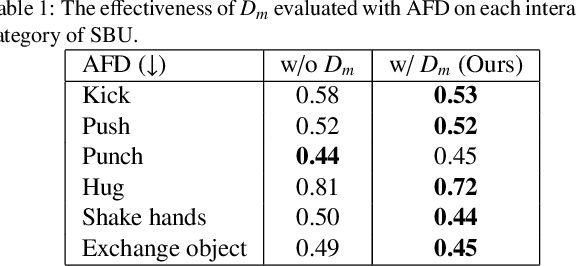
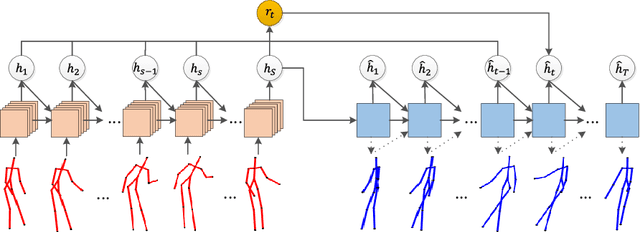
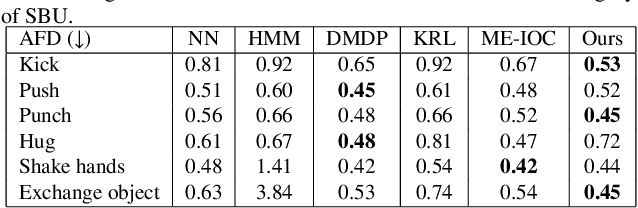
Creating realistic characters that can react to the users' or another character's movement can benefit computer graphics, games and virtual reality hugely. However, synthesizing such reactive motions in human-human interactions is a challenging task due to the many different ways two humans can interact. While there are a number of successful researches in adapting the generative adversarial network (GAN) in synthesizing single human actions, there are very few on modelling human-human interactions. In this paper, we propose a semi-supervised GAN system that synthesizes the reactive motion of a character given the active motion from another character. Our key insights are two-fold. First, to effectively encode the complicated spatial-temporal information of a human motion, we empower the generator with a part-based long short-term memory (LSTM) module, such that the temporal movement of different limbs can be effectively modelled. We further include an attention module such that the temporal significance of the interaction can be learned, which enhances the temporal alignment of the active-reactive motion pair. Second, as the reactive motion of different types of interactions can be significantly different, we introduce a discriminator that not only tells if the generated movement is realistic or not, but also tells the class label of the interaction. This allows the use of such labels in supervising the training of the generator. We experiment with the SBU and the HHOI datasets. The high quality of the synthetic motion demonstrates the effective design of our generator, and the discriminability of the synthesis also demonstrates the strength of our discriminator.
An optimized Capsule-LSTM model for facial expression recognition with video sequences
May 27, 2021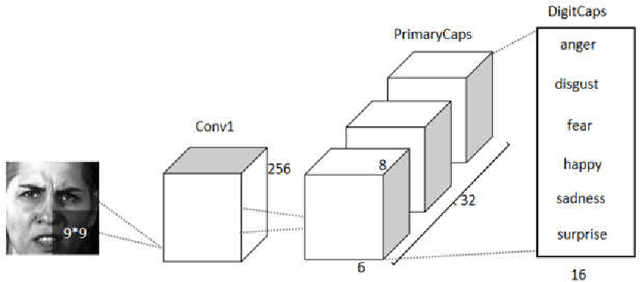
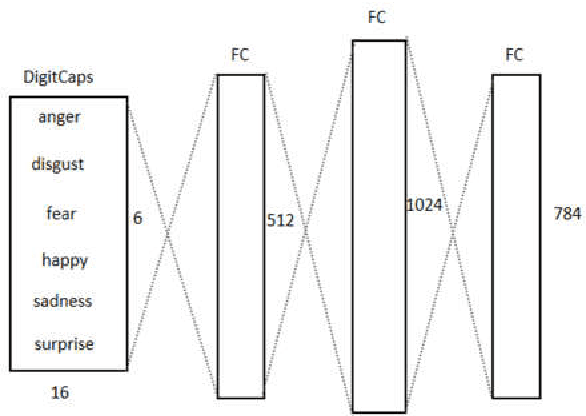
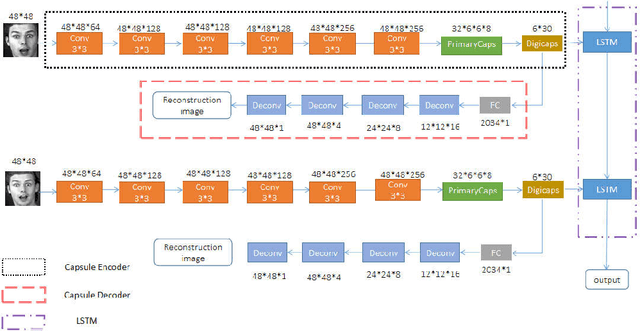

To overcome the limitations of convolutional neural network in the process of facial expression recognition, a facial expression recognition model Capsule-LSTM based on video frame sequence is proposed. This model is composed of three networks includingcapsule encoders, capsule decoders and LSTM network. The capsule encoder extracts the spatial information of facial expressions in video frames. Capsule decoder reconstructs the images to optimize the network. LSTM extracts the temporal information between video frames and analyzes the differences in expression changes between frames. The experimental results from the MMI dataset show that the Capsule-LSTM model proposed in this paper can effectively improve the accuracy of video expression recognition.