 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Focus on Impact: Indoor Exploration with Intrinsic Motivation
Sep 14, 2021
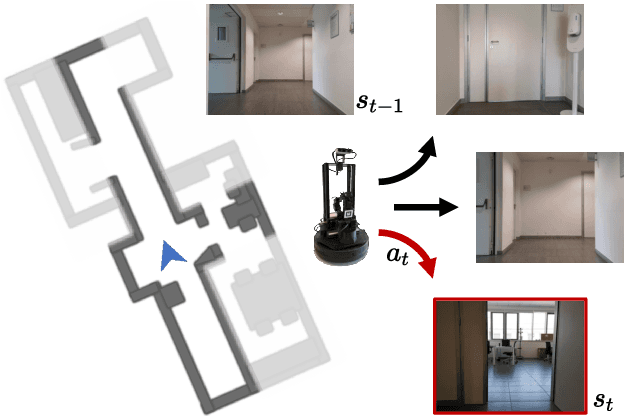
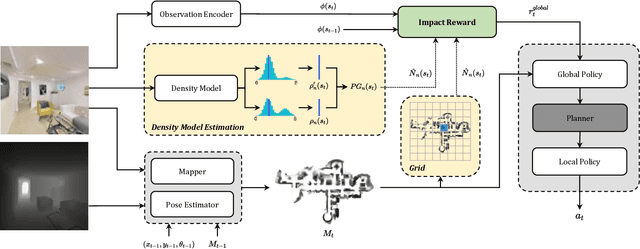

Exploration of indoor environments has recently experienced a significant interest, also thanks to the introduction of deep neural agents built in a hierarchical fashion and trained with Deep Reinforcement Learning (DRL) on simulated environments. Current state-of-the-art methods employ a dense extrinsic reward that requires the complete a priori knowledge of the layout of the training environment to learn an effective exploration policy. However, such information is expensive to gather in terms of time and resources. In this work, we propose to train the model with a purely intrinsic reward signal to guide exploration, which is based on the impact of the robot's actions on the environment. So far, impact-based rewards have been employed for simple tasks and in procedurally generated synthetic environments with countable states. Since the number of states observable by the agent in realistic indoor environments is non-countable, we include a neural-based density model and replace the traditional count-based regularization with an estimated pseudo-count of previously visited states. The proposed exploration approach outperforms DRL-based competitors relying on intrinsic rewards and surpasses the agents trained with a dense extrinsic reward computed with the environment layouts. We also show that a robot equipped with the proposed approach seamlessly adapts to point-goal navigation and real-world deployment.
Not All Memories are Created Equal: Learning to Forget by Expiring
May 13, 2021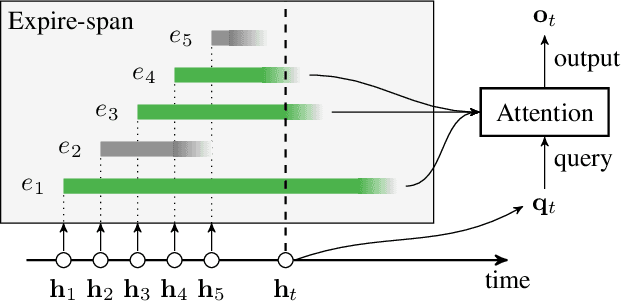
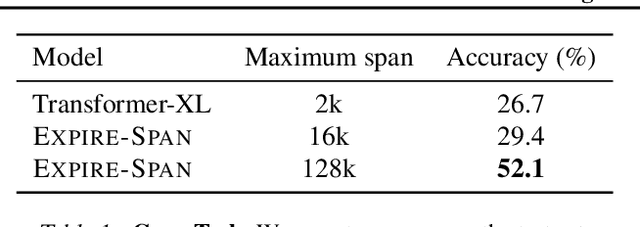
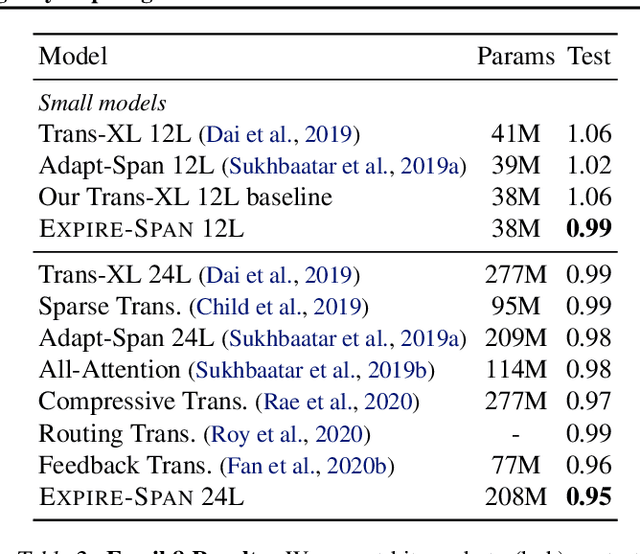

Attention mechanisms have shown promising results in sequence modeling tasks that require long-term memory. Recent work investigated mechanisms to reduce the computational cost of preserving and storing memories. However, not all content in the past is equally important to remember. We propose Expire-Span, a method that learns to retain the most important information and expire the irrelevant information. This forgetting of memories enables Transformers to scale to attend over tens of thousands of previous timesteps efficiently, as not all states from previous timesteps are preserved. We demonstrate that Expire-Span can help models identify and retain critical information and show it can achieve strong performance on reinforcement learning tasks specifically designed to challenge this functionality. Next, we show that Expire-Span can scale to memories that are tens of thousands in size, setting a new state of the art on incredibly long context tasks such as character-level language modeling and a frame-by-frame moving objects task. Finally, we analyze the efficiency of Expire-Span compared to existing approaches and demonstrate that it trains faster and uses less memory.
Two-stream Convolutional Networks for Multi-frame Face Anti-spoofing
Aug 09, 2021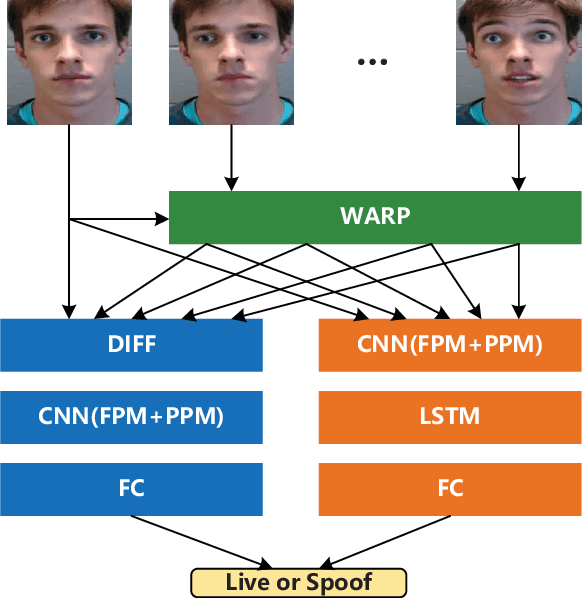
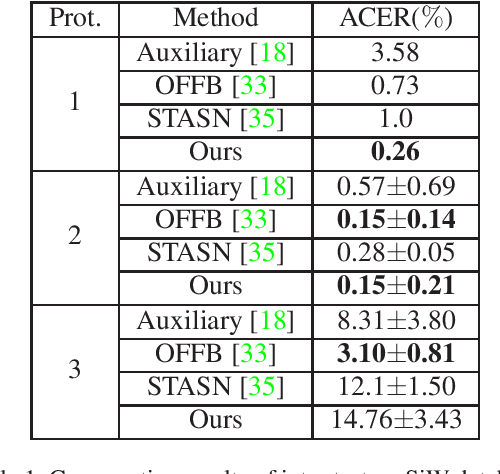
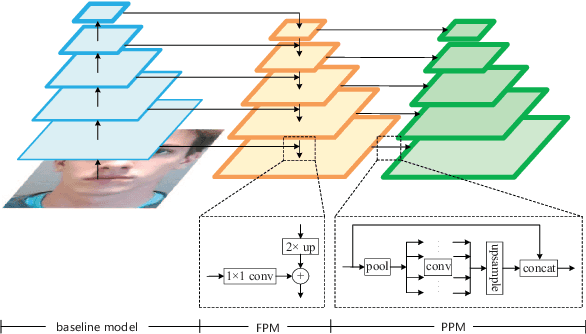
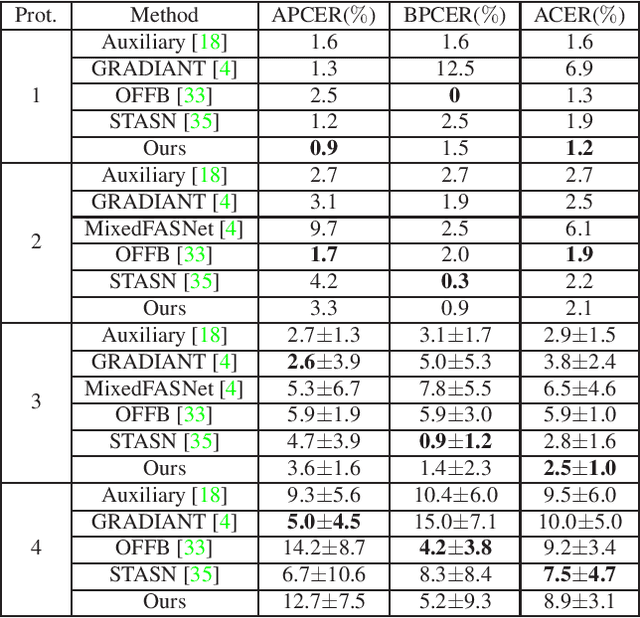
Face anti-spoofing is an important task to protect the security of face recognition. Most of previous work either struggle to capture discriminative and generalizable feature or rely on auxiliary information which is unavailable for most of industrial product. Inspired by the video classification work, we propose an efficient two-stream model to capture the key differences between live and spoof faces, which takes multi-frames and RGB difference as input respectively. Feature pyramid modules with two opposite fusion directions and pyramid pooling modules are applied to enhance feature representation. We evaluate the proposed method on the datasets of Siw, Oulu-NPU, CASIA-MFSD and Replay-Attack. The results show that our model achieves the state-of-the-art results on most of datasets' protocol with much less parameter size.
Text mining policy: Classifying forest and landscape restoration policy agenda with neural information retrieval
Aug 07, 2019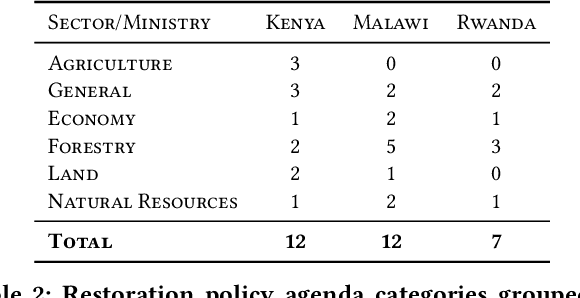
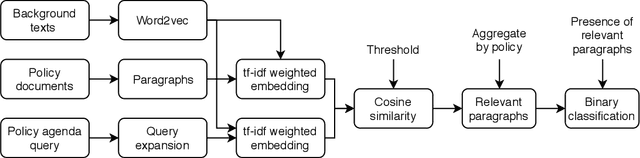


Dozens of countries have committed to restoring the ecological functionality of 350 million hectares of land by 2030. In order to achieve such wide-scale implementation of restoration, the values and priorities of multi-sectoral stakeholders must be aligned and integrated with national level commitments and other development agenda. Although misalignment across scales of policy and between stakeholders are well known barriers to implementing restoration, fast-paced policy making in multi-stakeholder environments complicates the monitoring and analysis of governance and policy. In this work, we assess the potential of machine learning to identify restoration policy agenda across diverse policy documents. An unsupervised neural information retrieval architecture is introduced that leverages transfer learning and word embeddings to create high-dimensional representations of paragraphs. Policy agenda labels are recast as information retrieval queries in order to classify policies with a cosine similarity threshold between paragraphs and query embeddings. This approach achieves a 0.83 F1-score measured across 14 policy agenda in 31 policy documents in Malawi, Kenya, and Rwanda, indicating that automated text mining can provide reliable, generalizable, and efficient analyses of restoration policy.
Spatially Invariant Unsupervised 3D Object Segmentation with Graph Neural Networks
Jun 10, 2021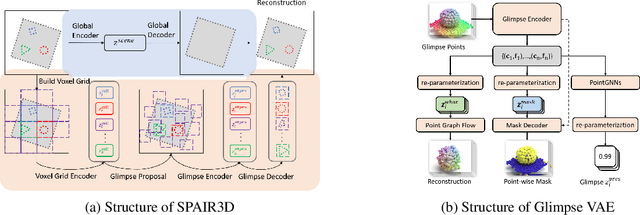
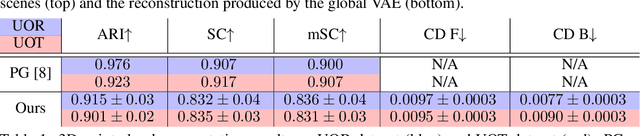
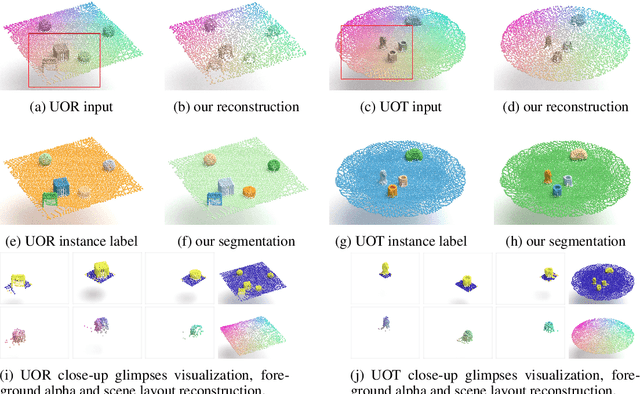
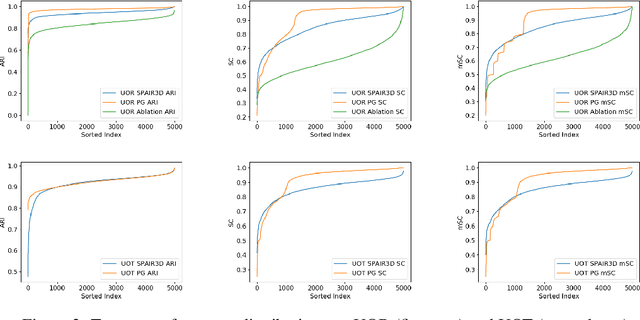
In this paper, we tackle the problem of unsupervised 3D object segmentation from a point cloud without RGB information. In particular, we propose a framework,~{\bf SPAIR3D}, to model a point cloud as a spatial mixture model and jointly learn the multiple-object representation and segmentation in 3D via Variational Autoencoders (VAE). Inspired by SPAIR, we adopt an object-specification scheme that describes each object's location relative to its local voxel grid cell rather than the point cloud as a whole. To model the spatial mixture model on point clouds, we derive the~\emph{Chamfer Likelihood}, which fits naturally into the variational training pipeline. We further design a new spatially invariant graph neural network to generate a varying number of 3D points as a decoder within our VAE.~Experimental results demonstrate that~{\bf SPAIR3D} is capable of detecting and segmenting variable number of objects without appearance information across diverse scenes.
Mathematics as information compression via the matching and unification of patterns
Oct 09, 2018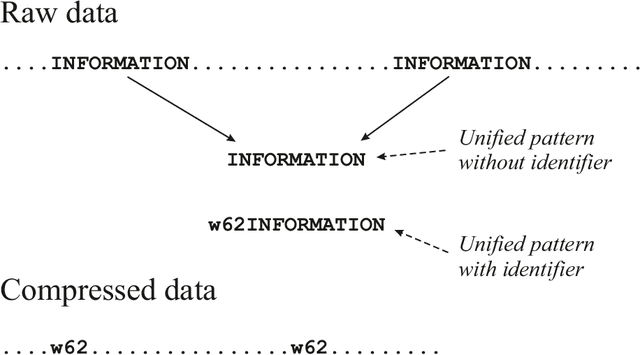
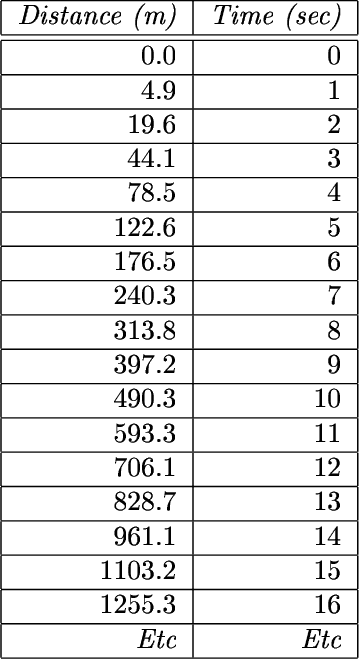
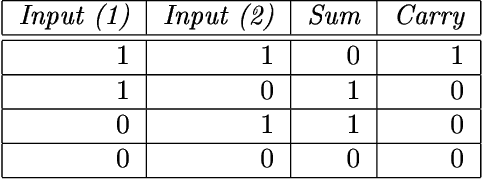
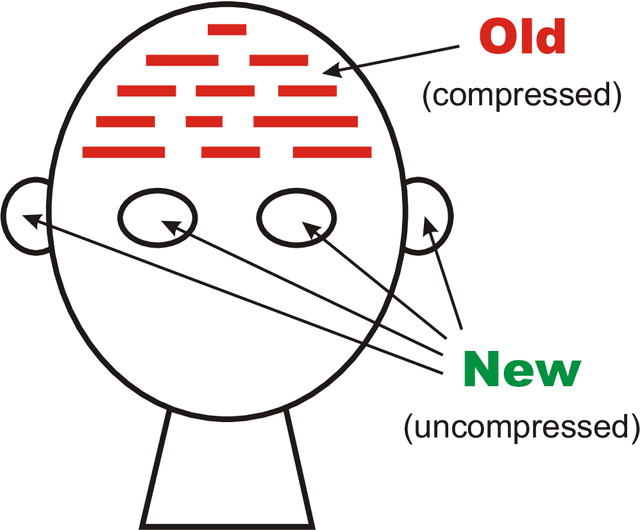
This paper describes a novel perspective on the foundations of mathematics: how mathematics may be seen to be largely about 'information compression via the matching and unification of patterns' (ICMUP). ICMUP is itself a novel approach to information compression, couched in terms of non-mathematical primitives, as is necessary in any investigation of the foundations of mathematics. This new perspective on the foundations of mathematics has grown out of an extensive programme of research developing the "SP Theory of Intelligence" and its realisation in the "SP Computer Model", a system in which a generalised version of ICMUP -- the powerful concept of SP-multiple-alignment -- plays a central role. These ideas may be seen to be part of a "Big Picture" comprising six areas of interest, with information compression as a unifying theme. The paper describes the close relation between mathematics and information compression, and describes examples showing how variants of ICMUP may be seen in widely-used structures and operations in mathematics. Examples are also given to show how the mathematics-related disciplines of logic and computing may be understood as ICMUP. There are many potential benefits and applications of these ideas.
Tosca: Operationalizing Commitments Over Information Protocols
Aug 10, 2017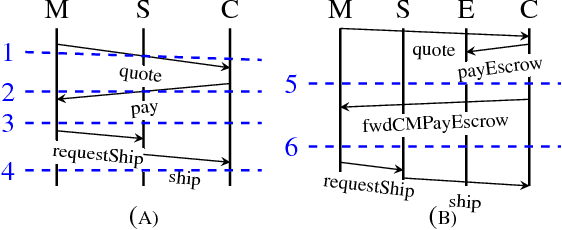

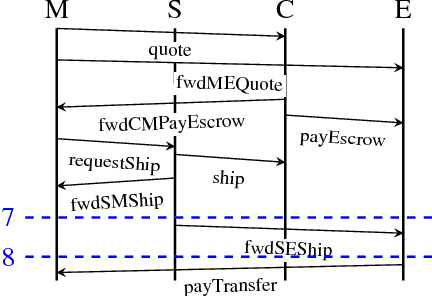
The notion of commitment is widely studied as a high-level abstraction for modeling multiagent interaction. An important challenge is supporting flexible decentralized enactments of commitment specifications. In this paper, we combine recent advances on specifying commitments and information protocols. Specifically, we contribute Tosca, a technique for automatically synthesizing information protocols from commitment specifications. Our main result is that the synthesized protocols support commitment alignment, which is the idea that agents must make compatible inferences about their commitments despite decentralization.
A Novel Global Feature-Oriented Relational Triple Extraction Model based on Table Filling
Sep 14, 2021Table filling based relational triple extraction methods are attracting growing research interests due to their promising performance and their abilities on extracting triples from complex sentences. However, this kind of methods are far from their full potential because most of them only focus on using local features but ignore the global associations of relations and of token pairs, which increases the possibility of overlooking some important information during triple extraction. To overcome this deficiency, we propose a global feature-oriented triple extraction model that makes full use of the mentioned two kinds of global associations. Specifically, we first generate a table feature for each relation. Then two kinds of global associations are mined from the generated table features. Next, the mined global associations are integrated into the table feature of each relation. This "generate-mine-integrate" process is performed multiple times so that the table feature of each relation is refined step by step. Finally, each relation's table is filled based on its refined table feature, and all triples linked to this relation are extracted based on its filled table. We evaluate the proposed model on three benchmark datasets. Experimental results show our model is effective and it achieves state-of-the-art results on all of these datasets. The source code of our work is available at: https://github.com/neukg/GRTE.
Trade When Opportunity Comes: Price Movement Forecasting via Locality-Aware Attention and Adaptive Refined Labeling
Jul 26, 2021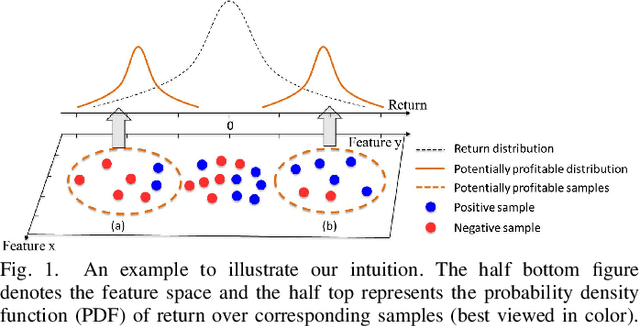
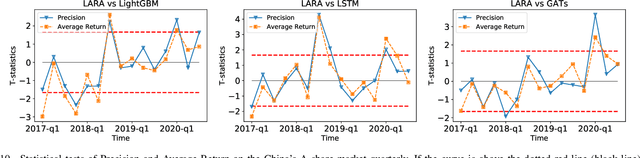
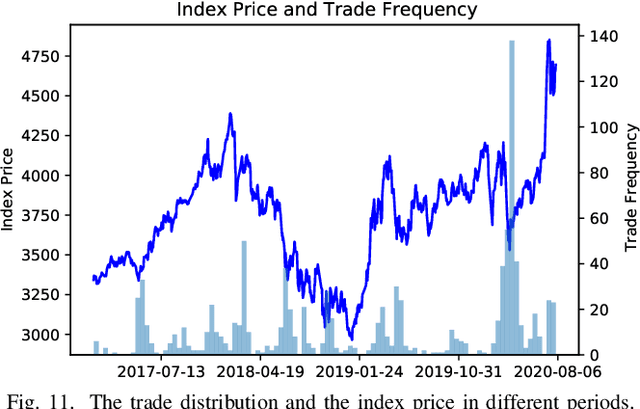
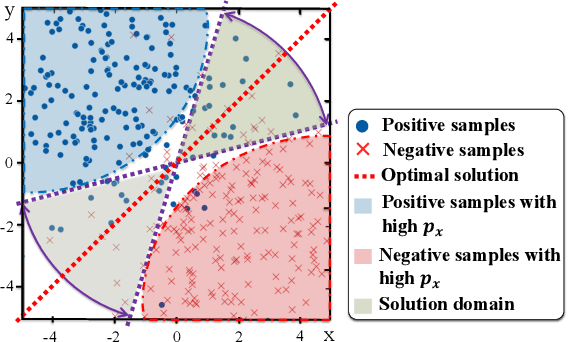
Price movement forecasting aims at predicting the future trends of financial assets based on the current market conditions and other relevant information. Recently, machine learning(ML) methods have become increasingly popular and achieved promising results for price movement forecasting in both academia and industry. Most existing ML solutions formulate the forecasting problem as a classification(to predict the direction) or a regression(to predict the return) problem in the entire set of training data. However, due to the extremely low signal-to-noise ratio and stochastic nature of financial data, good trading opportunities are extremely scarce. As a result, without careful selection of potentially profitable samples, such ML methods are prone to capture the patterns of noises instead of real signals. To address the above issues, we propose a novel framework-LARA(Locality-Aware Attention and Adaptive Refined Labeling), which contains the following three components: 1)Locality-aware attention automatically extracts the potentially profitable samples by attending to their label information in order to construct a more accurate classifier on these selected samples. 2)Adaptive refined labeling further iteratively refines the labels, alleviating the noise of samples. 3)Equipped with metric learning techniques, Locality-aware attention enjoys task-specific distance metrics and distributes attention on potentially profitable samples in a more effective way. To validate our method, we conduct comprehensive experiments on three real-world financial markets: ETFs, the China's A-share stock market, and the cryptocurrency market. LARA achieves superior performance compared with the time-series analysis methods and a set of machine learning based competitors on the Qlib platform. Extensive ablation studies and experiments demonstrate that LARA indeed captures more reliable trading opportunities.
Attention-based Clinical Note Summarization
Apr 18, 2021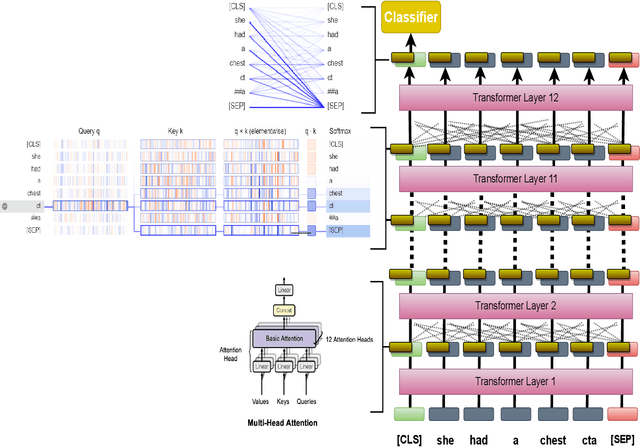

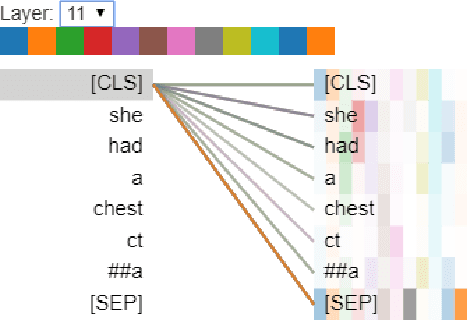
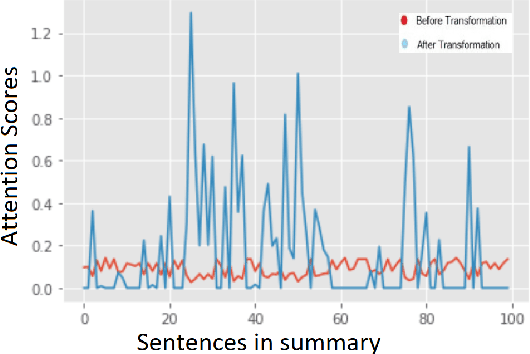
The trend of deploying digital systems in numerous industries has induced a hike in recording digital information. The health sector has observed a large adoption of digital devices and systems generating large volumes of personal medical health records. Electronic health records contain valuable information for retrospective and prospective analysis that is often not entirely exploited because of the dense information storage. The crude purpose of condensing health records is to select the information that holds most characteristics of the original documents based on reported disease. These summaries may boost diagnosis and extend a doctor's interaction time with the patient during a high workload situation like the COVID-19 pandemic. In this paper, we propose a multi-head attention-based mechanism to perform extractive summarization of meaningful phrases in clinical notes. This method finds major sentences for a summary by correlating tokens, segments and positional embeddings. The model outputs attention scores that are statistically transformed to extract key phrases and can be used for a projection on the heat-mapping tool for visual and human use.