 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Correcting the User Feedback-Loop Bias for Recommendation Systems
Sep 13, 2021
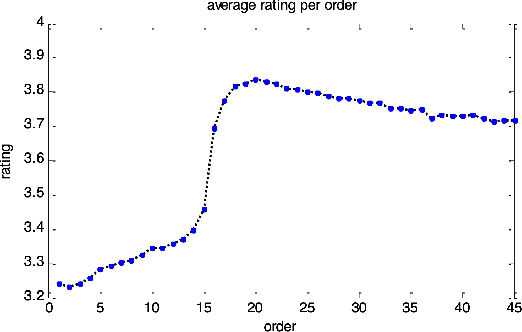

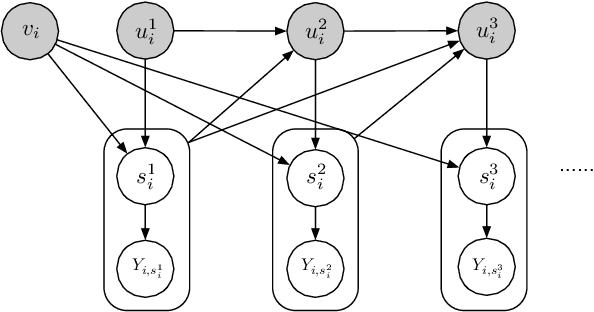
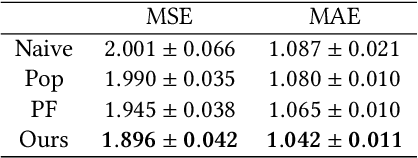
Selection bias is prevalent in the data for training and evaluating recommendation systems with explicit feedback. For example, users tend to rate items they like. However, when rating an item concerning a specific user, most of the recommendation algorithms tend to rely too much on his/her rating (feedback) history. This introduces implicit bias on the recommendation system, which is referred to as user feedback-loop bias in this paper. We propose a systematic and dynamic way to correct such bias and to obtain more diverse and objective recommendations by utilizing temporal rating information. Specifically, our method includes a deep-learning component to learn each user's dynamic rating history embedding for the estimation of the probability distribution of the items that the user rates sequentially. These estimated dynamic exposure probabilities are then used as propensity scores to train an inverse-propensity-scoring (IPS) rating predictor. We empirically validated the existence of such user feedback-loop bias in real world recommendation systems and compared the performance of our method with the baseline models that are either without de-biasing or with propensity scores estimated by other methods. The results show the superiority of our approach.
Knowledge-Grounded Dialogue with Reward-Driven Knowledge Selection
Aug 31, 2021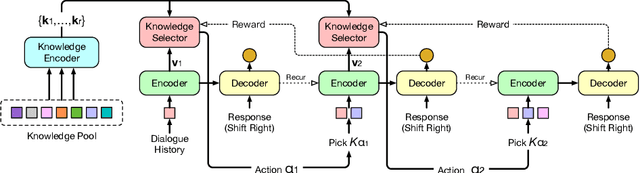

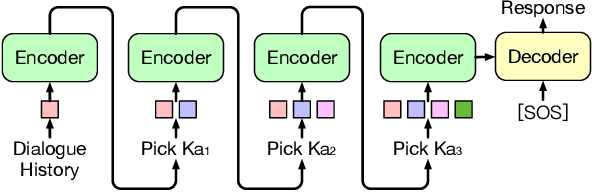
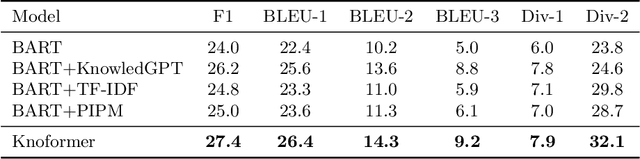
Knowledge-grounded dialogue is a task of generating a fluent and informative response based on both conversation context and a collection of external knowledge, in which knowledge selection plays an important role and attracts more and more research interest. However, most existing models either select only one knowledge or use all knowledge for responses generation. The former may lose valuable information in discarded knowledge, while the latter may bring a lot of noise. At the same time, many approaches need to train the knowledge selector with knowledge labels that indicate ground-truth knowledge, but these labels are difficult to obtain and require a large number of manual annotations. Motivated by these issues, we propose Knoformer, a dialogue response generation model based on reinforcement learning, which can automatically select one or more related knowledge from the knowledge pool and does not need knowledge labels during training. Knoformer is evaluated on two knowledge-guided conversation datasets, and achieves state-of-the-art performance.
PTT: Point-Track-Transformer Module for 3D Single Object Tracking in Point Clouds
Aug 31, 2021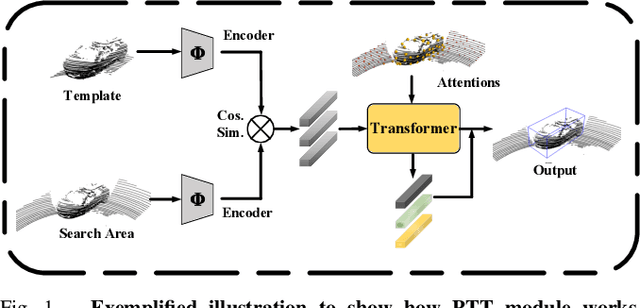
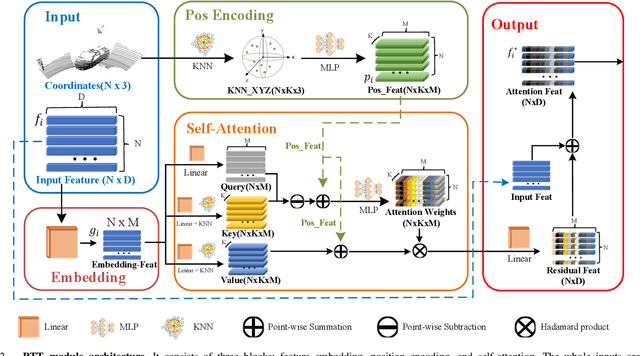
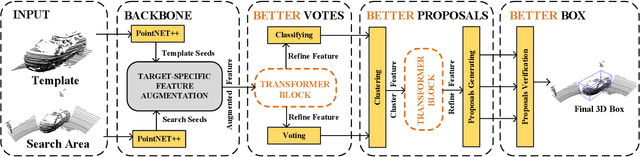
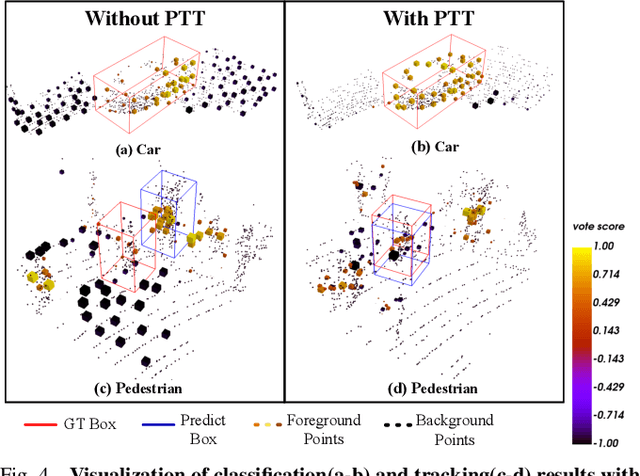
3D single object tracking is a key issue for robotics. In this paper, we propose a transformer module called Point-Track-Transformer (PTT) for point cloud-based 3D single object tracking. PTT module contains three blocks for feature embedding, position encoding, and self-attention feature computation. Feature embedding aims to place features closer in the embedding space if they have similar semantic information. Position encoding is used to encode coordinates of point clouds into high dimension distinguishable features. Self-attention generates refined attention features by computing attention weights. Besides, we embed the PTT module into the open-source state-of-the-art method P2B to construct PTT-Net. Experiments on the KITTI dataset reveal that our PTT-Net surpasses the state-of-the-art by a noticeable margin (~10\%). Additionally, PTT-Net could achieve real-time performance (~40FPS) on NVIDIA 1080Ti GPU. Our code is open-sourced for the robotics community at https://github.com/shanjiayao/PTT.
SSC: Semantic Scan Context for Large-Scale Place Recognition
Jul 01, 2021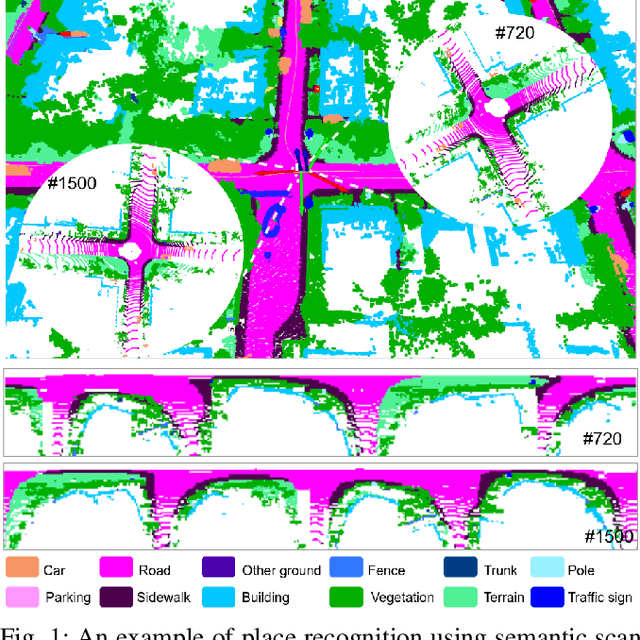
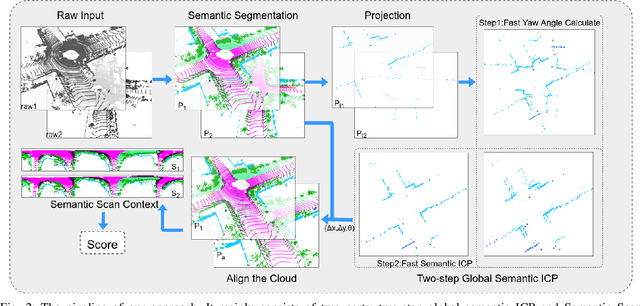
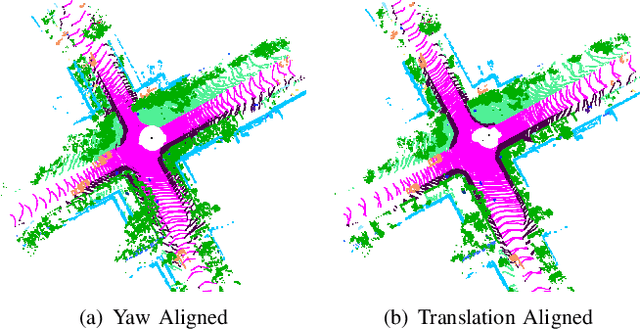
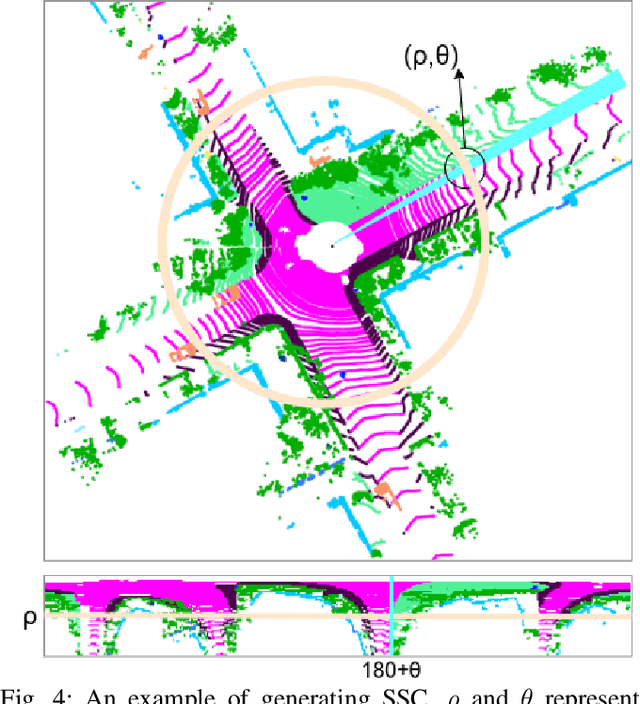
Place recognition gives a SLAM system the ability to correct cumulative errors. Unlike images that contain rich texture features, point clouds are almost pure geometric information which makes place recognition based on point clouds challenging. Existing works usually encode low-level features such as coordinate, normal, reflection intensity, etc., as local or global descriptors to represent scenes. Besides, they often ignore the translation between point clouds when matching descriptors. Different from most existing methods, we explore the use of high-level features, namely semantics, to improve the descriptor's representation ability. Also, when matching descriptors, we try to correct the translation between point clouds to improve accuracy. Concretely, we propose a novel global descriptor, Semantic Scan Context, which explores semantic information to represent scenes more effectively. We also present a two-step global semantic ICP to obtain the 3D pose (x, y, yaw) used to align the point cloud to improve matching performance. Our experiments on the KITTI dataset show that our approach outperforms the state-of-the-art methods with a large margin. Our code is available at: https://github.com/lilin-hitcrt/SSC.
ChiNet: Deep Recurrent Convolutional Learning for Multimodal Spacecraft Pose Estimation
Aug 23, 2021


This paper presents an innovative deep learning pipeline which estimates the relative pose of a spacecraft by incorporating the temporal information from a rendezvous sequence. It leverages the performance of long short-term memory (LSTM) units in modelling sequences of data for the processing of features extracted by a convolutional neural network (CNN) backbone. Three distinct training strategies, which follow a coarse-to-fine funnelled approach, are combined to facilitate feature learning and improve end-to-end pose estimation by regression. The capability of CNNs to autonomously ascertain feature representations from images is exploited to fuse thermal infrared data with red-green-blue (RGB) inputs, thus mitigating the effects of artefacts from imaging space objects in the visible wavelength. Each contribution of the proposed framework, dubbed ChiNet, is demonstrated on a synthetic dataset, and the complete pipeline is validated on experimental data.
Hybrid Model and Data Driven Algorithm for Online Learning of Any-to-Any Path Loss Maps
Jul 14, 2021
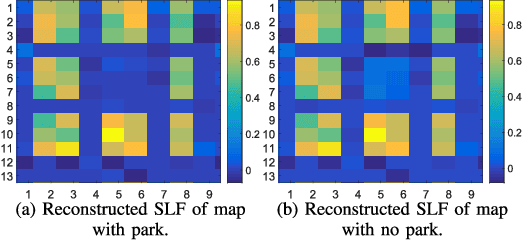
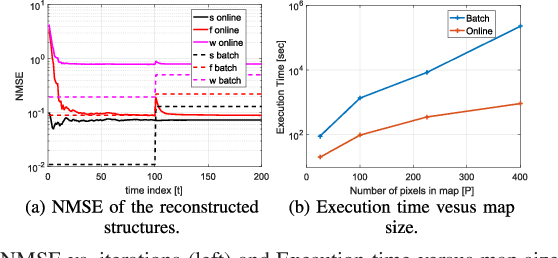
Learning any-to-any (A2A) path loss maps, where the objective is the reconstruction of path loss between any two given points in a map, might be a key enabler for many applications that rely on device-to-device (D2D) communication. Such applications include machine-type communications (MTC) or vehicle-to-vehicle (V2V) communications. Current approaches for learning A2A maps are either model-based methods, or pure data-driven methods. Model-based methods have the advantage that they can generate reliable estimations with low computational complexity, but they cannot exploit information coming from data. Pure data-driven methods can achieve good performance without assuming any physical model, but their complexity and their lack of robustness is not acceptable for many applications. In this paper, we propose a novel hybrid model and data-driven approach that fuses information obtained from datasets and models in an online fashion. To that end, we leverage the framework of stochastic learning to deal with the sequential arrival of samples and propose an online algorithm that alternatively and sequentially minimizes the original non-convex problem. A proof of convergence is presented, along with experiments based firstly on synthetic data, and secondly on a more realistic dataset for V2X, with both experiments showing promising results.
Emotion Recognition of the Singing Voice: Toward a Real-Time Analysis Tool for Singers
May 01, 2021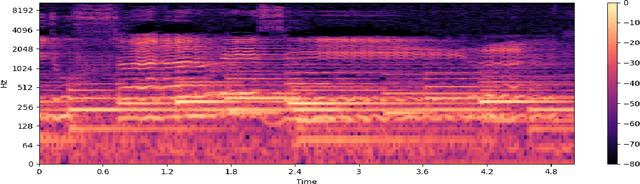

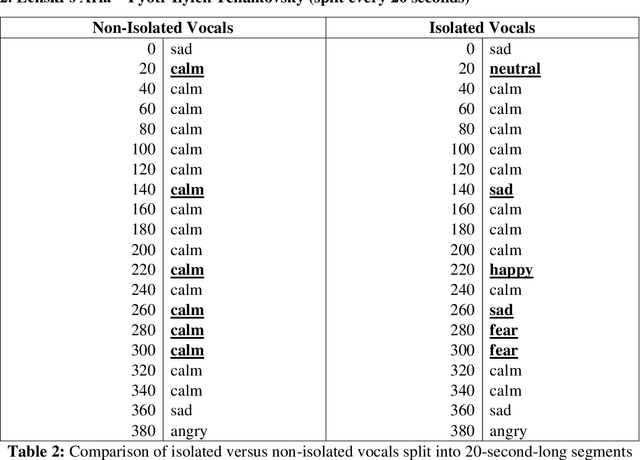
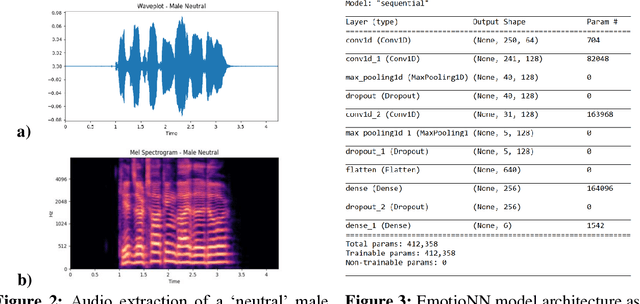
Current computational-emotion research has focused on applying acoustic properties to analyze how emotions are perceived mathematically or used in natural language processing machine learning models. With most recent interest being in analyzing emotions from the spoken voice, little experimentation has been performed to discover how emotions are recognized in the singing voice -- both in noiseless and noisy data (i.e., data that is either inaccurate, difficult to interpret, has corrupted/distorted/nonsense information like actual noise sounds in this case, or has a low ratio of usable/unusable information). Not only does this ignore the challenges of training machine learning models on more subjective data and testing them with much noisier data, but there is also a clear disconnect in progress between advancing the development of convolutional neural networks and the goal of emotionally cognizant artificial intelligence. By training a new model to include this type of information with a rich comprehension of psycho-acoustic properties, not only can models be trained to recognize information within extremely noisy data, but advancement can be made toward more complex biofeedback applications -- including creating a model which could recognize emotions given any human information (language, breath, voice, body, posture) and be used in any performance medium (music, speech, acting) or psychological assistance for patients with disorders such as BPD, alexithymia, autism, among others. This paper seeks to reflect and expand upon the findings of related research and present a stepping-stone toward this end goal.
Phase Noise Resilient Three-Level Continuous-Phase Modulation for DFT-Spread OFDM
Oct 12, 2021
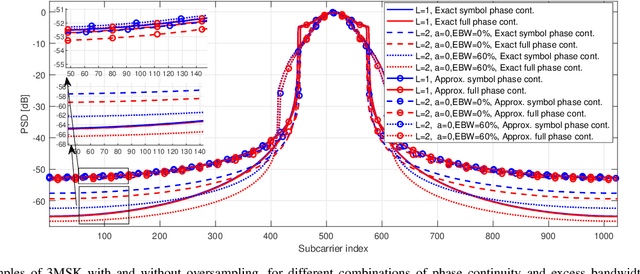
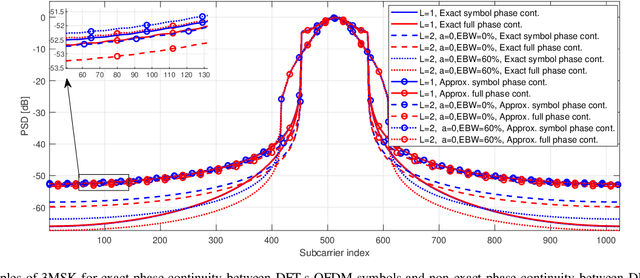
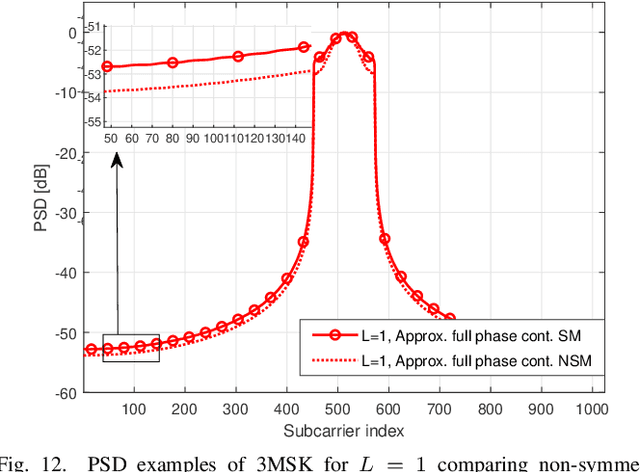
A novel OFDM-based waveform with low peak-to-average power ratio (PAPR) and high robustness against phase noise (PN) is presented. It follows the discrete Fourier transform spread orthogonal frequency division multiplexing (DFT-s-OFDM) signal model. 3MSK, is inspired by continuous-phase frequency shift keying (FSK), but it uses three frequencies in the baseband model -- specifically, 0 and $\pm f_{symbol}/4$, where $f_{symbol}$ is the symbol rate -- which effectively constrains the phase transitions between consecutive symbols to 0 and $\pm \pi/2$ rad. Motivated by the phase controlled model of modulation, different degrees of phase continuity can be achieved, while supporting receiver processing with low complexity. The signal characteristics are improved by generating an initial time-domain nearly constant envelope signal at higher than the symbol rate. This helps to reach smooth phase transitions between 3MSK symbols. Also the possibility of using excess bandwidth is investigated by transmitting additional non-zero subcarriers outside active subcarriers of the basic DFT-s-OFDM model, which provides the capability to greatly reduce the PAPR. Due to the fact that the information is encoded in the phase transitions, a receiver model that tracks the phase variations without needing reference signals is developed. To this end, it is shown that this new modulation is well-suited for non-coherent receivers, even under strong phase noise (PN) conditions, thus allowing to reduce the overhead of reference signals. Evaluations of this physical-layer modulation and waveform scheme are performed in terms of transmitter metrics such as PAPR, OOB emissions and achievable output power after the power amplifier (PA). Finally, coded radio link evaluations are also shown and provided, demonstrating that 3MSK has a similar BER performance as that of traditional QPSK.
IDS 3D City: A Digital Scaled Smart City
Sep 07, 2021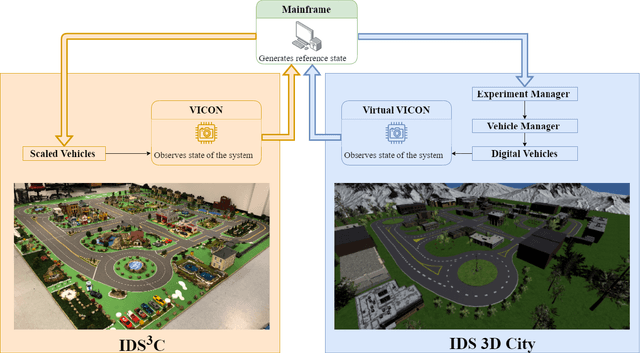
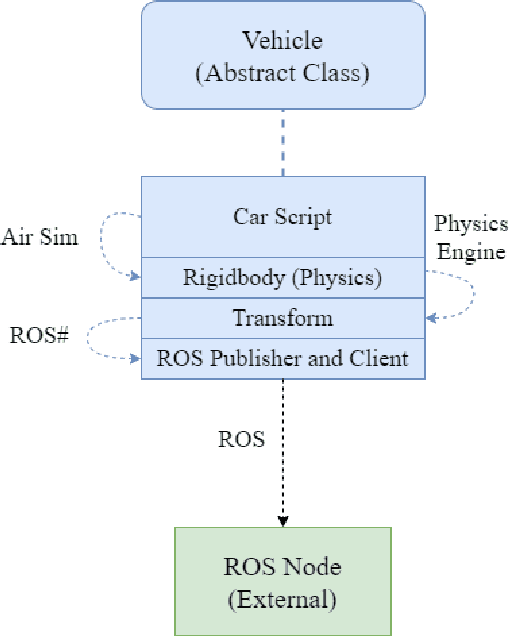
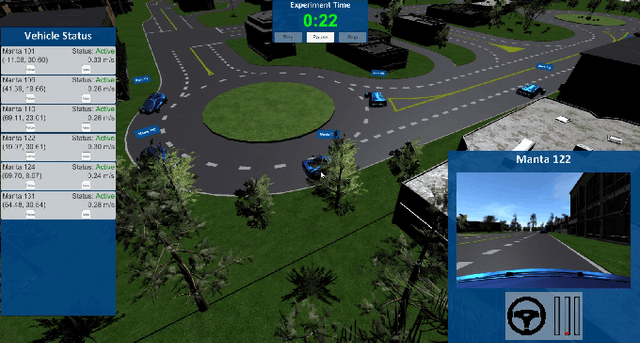
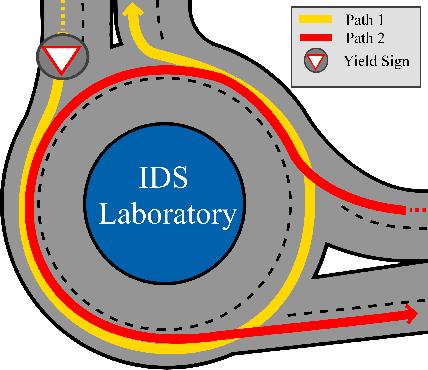
As the demand for connected and automated vehicles emerges, so to does the need for quality testing environments to support their development. In this paper, we introduce a Unity-based virtual simulation environment for emerging mobility systems, called Information and Decision Science Lab's Scaled Smart Digital City (IDS 3D City), intended to operate alongside its physical peer and its existing control framework. By utilizing the Robot Operation System, AirSim, and Unity, we have constructed a simulation environment capable of iteratively designing experiments significantly faster than is possible in a physical testbed. This provides us with an intermediate step to validate the effectiveness of our control framework prior to testing them in the physical testbed. Another benefit provided by the IDS 3D City is demonstrating that our control algorithms work independent of the physical vehicle dynamics, since the vehicle dynamics introduced by AirSim operate at a different scale than our scaled smart city. We finally demonstrate the effectiveness of our digital environment by performing an experiment in both virtual and physical environments.
Combining Supervised and Un-supervised Learning for Automatic Citrus Segmentation
May 04, 2021
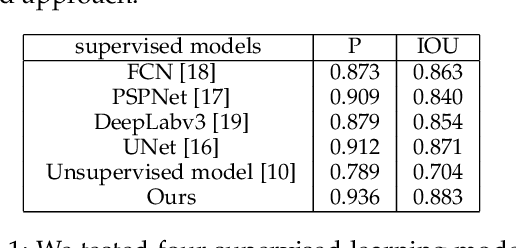
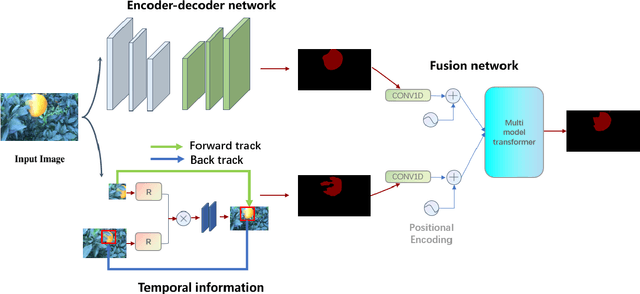

Citrus segmentation is a key step of automatic citrus picking. While most current image segmentation approaches achieve good segmentation results by pixel-wise segmentation, these supervised learning-based methods require a large amount of annotated data, and do not consider the continuous temporal changes of citrus position in real-world applications. In this paper, we first train a simple CNN with a small number of labelled citrus images in a supervised manner, which can roughly predict the citrus location from each frame. Then, we extend a state-of-the-art unsupervised learning approach to pre-learn the citrus's potential movements between frames from unlabelled citrus's videos. To take advantages of both networks, we employ the multimodal transformer to combine supervised learned static information and unsupervised learned movement information. The experimental results show that combing both network allows the prediction accuracy reached at 88.3$\%$ IOU and 93.6$\%$ precision, outperforming the original supervised baseline 1.2$\%$ and 2.4$\%$. Compared with most of the existing citrus segmentation methods, our method uses a small amount of supervised data and a large number of unsupervised data, while learning the pixel level location information and the temporal information of citrus changes to enhance the segmentation effect.