 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learnable Multi-level Frequency Decomposition and Hierarchical Attention Mechanism for Generalized Face Presentation Attack Detection
Sep 16, 2021

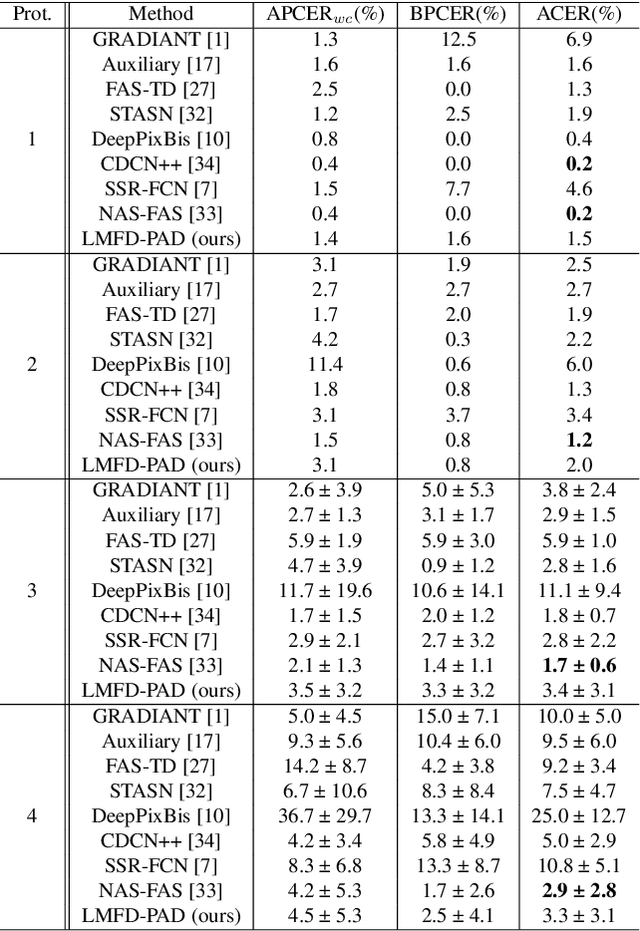
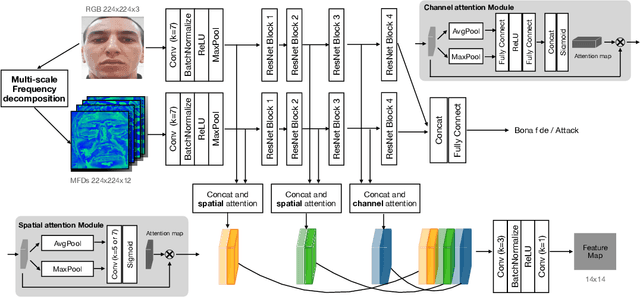
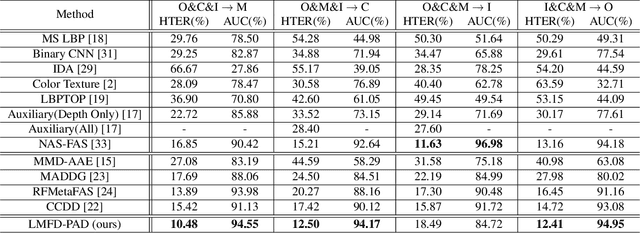
With the increased deployment of face recognition systems in our daily lives, face presentation attack detection (PAD) is attracting a lot of attention and playing a key role in securing face recognition systems. Despite the great performance achieved by the hand-crafted and deep learning based methods in intra-dataset evaluations, the performance drops when dealing with unseen scenarios. In this work, we propose a dual-stream convolution neural networks (CNNs) framework. One stream adapts four learnable frequency filters to learn features in the frequency domain, which are less influenced variations in sensors/illuminations. The other stream leverage the RGB images to complement the features of the frequency domain. Moreover, we propose a hierarchical attention module integration to join the information from the two streams at different stages by considering the nature of deep features in different layers of the CNN. The proposed method is evaluated in the intra-dataset and cross-dataset setups and the results demonstrates that our proposed approach enhances the generalizability in most experimental setups in comparison to state-of-the-art, including the methods designed explicitly for domain adaption/shift problem. We successfully prove the design of our proposed PAD solution in a step-wise ablation study that involves our proposed learnable frequency decomposition, our hierarchical attention module design, and the used loss function. Training codes and pre-trained models are publicly released.
Towards a Sample Efficient Reinforcement Learning Pipeline for Vision Based Robotics
May 20, 2021

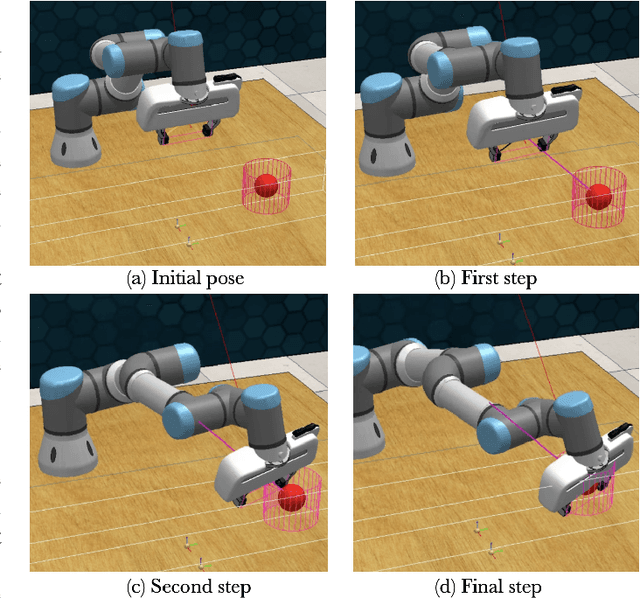
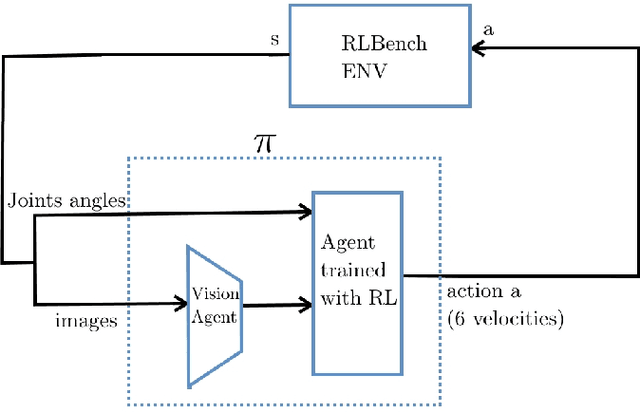
Deep Reinforcement learning holds the guarantee of empowering self-ruling robots to master enormous collections of conduct abilities with negligible human mediation. The improvements brought by this technique enables robots to perform difficult tasks such as grabbing or reaching targets. Nevertheless, the training process is still time consuming and tedious especially when learning policies only with RGB camera information. This way of learning is capital to transfer the task from simulation to the real world since the only external source of information for the robot in real life is video. In this paper, we study how to limit the time taken for training a robotic arm with 6 Degrees Of Freedom (DOF) to reach a ball from scratch by assembling a pipeline as efficient as possible. The pipeline is divided into two parts: the first one is to capture the relevant information from the RGB video with a Computer Vision algorithm. The second one studies how to train faster a Deep Reinforcement Learning algorithm in order to make the robotic arm reach the target in front of him. Follow this link to find videos and plots in higher resolution: \url{https://drive.google.com/drive/folders/1_lRlDSoPzd_GTcVrxNip10o_lm-_DPdn?usp=sharing}
Information Flow in Pregroup Models of Natural Language
Nov 08, 2018

This paper is about pregroup models of natural languages, and how they relate to the explicitly categorical use of pregroups in Compositional Distributional Semantics and Natural Language Processing. These categorical interpretations make certain assumptions about the nature of natural languages that, when stated formally, may be seen to impose strong restrictions on pregroup grammars for natural languages. We formalize this as a hypothesis about the form that pregroup models of natural languages must take, and demonstrate by an artificial language example that these restrictions are not imposed by the pregroup axioms themselves. We compare and contrast the artificial language examples with natural languages (using Welsh, a language where the 'noun' type cannot be taken as primitive, as an illustrative example). The hypothesis is simply that there must exist a causal connection, or information flow, between the words of a sentence in a language whose purpose is to communicate information. This is not necessarily the case with formal languages that are simply generated by a series of 'meaning-free' rules. This imposes restrictions on the types of pregroup grammars that we expect to find in natural languages; we formalize this in algebraic, categorical, and graphical terms. We take some preliminary steps in providing conditions that ensure pregroup models satisfy these conjectured properties, and discuss the more general forms this hypothesis may take.
* In Proceedings CAPNS 2018, arXiv:1811.02701
Learning Hierarchical Structures with Differentiable Nondeterministic Stacks
Sep 05, 2021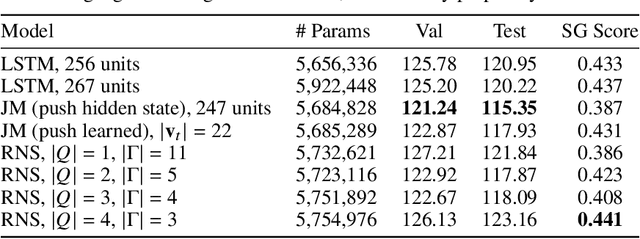
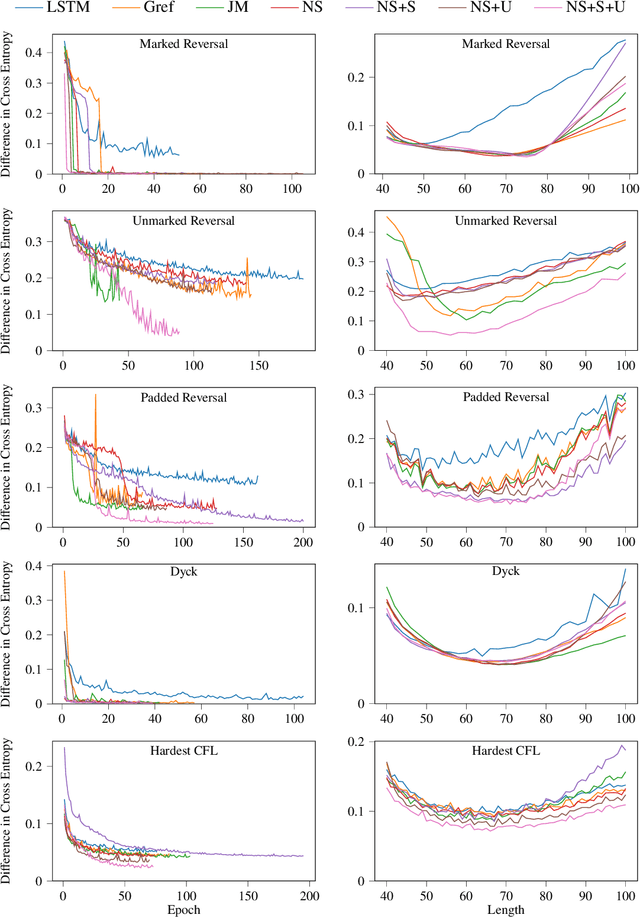
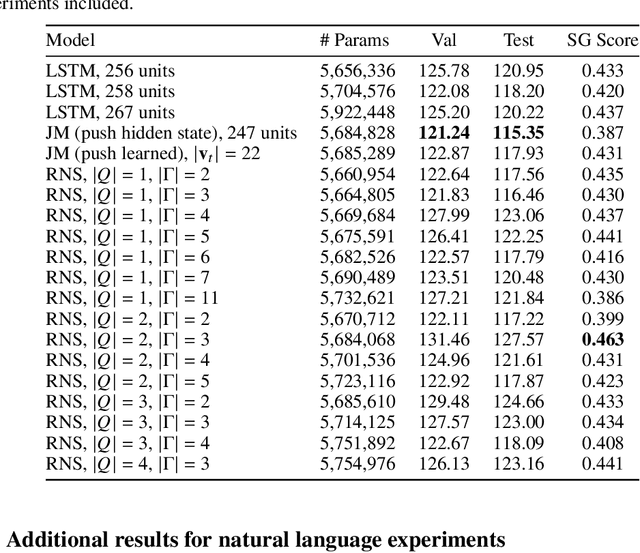

Learning hierarchical structures in sequential data -- from simple algorithmic patterns to natural language -- in a reliable, generalizable way remains a challenging problem for neural language models. Past work has shown that recurrent neural networks (RNNs) struggle to generalize on held-out algorithmic or syntactic patterns without supervision or some inductive bias. To remedy this, many papers have explored augmenting RNNs with various differentiable stacks, by analogy with finite automata and pushdown automata. In this paper, we present a stack RNN model based on the recently proposed Nondeterministic Stack RNN (NS-RNN) that achieves lower cross-entropy than all previous stack RNNs on five context-free language modeling tasks (within 0.05 nats of the information-theoretic lower bound), including a task in which the NS-RNN previously failed to outperform a deterministic stack RNN baseline. Our model assigns arbitrary positive weights instead of probabilities to stack actions, and we provide an analysis of why this improves training. We also propose a restricted version of the NS-RNN that makes it practical to use for language modeling on natural language and present results on the Penn Treebank corpus.
tFold-TR: Combining Deep Learning Enhanced Hybrid Potential Energy for Template-Based Modelling Structure Refinement
May 20, 2021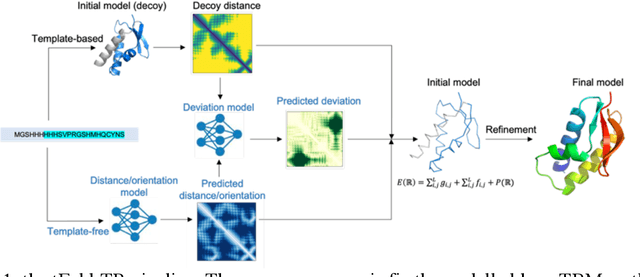


Proteins structure prediction has long been a grand challenge over the past 50 years, owing to its board scientific and application interests. There are two major types of modelling algorithm, template-free modelling and template-based modelling, which is suitable for easy prediction tasks, and is widely adopted in computer aided drug discoveries for drug design and screening. Although it has been several decades since its first edition, the current template-based modeling approach suffers from two important problems: 1) there are many missing regions in the template-query sequence alignment, and 2) the accuracy of the distance pairs from different regions of the template varies, and this information is not well introduced into the modeling. To solve the two problems, we propose a structural optimization process based on template modelling, introducing two neural network models predict the distance information of the missing regions and the accuracy of the distance pairs of different regions in the template modeling structure. The predicted distances and residue pairwise specific accuracy information are incorporated into the potential energy function for structural optimization, which significantly improves the qualities of the original template modelling decoys.
Path classification by stochastic linear recurrent neural networks
Aug 06, 2021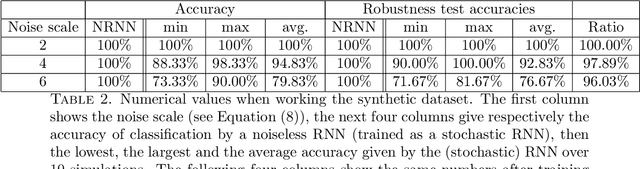
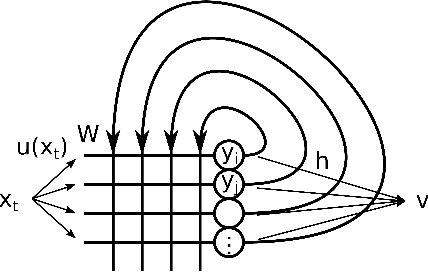
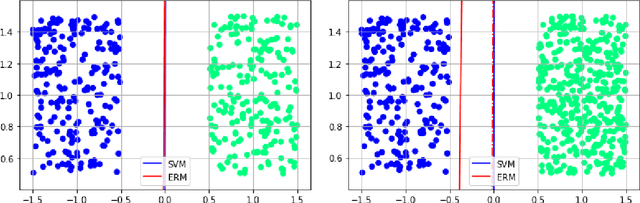
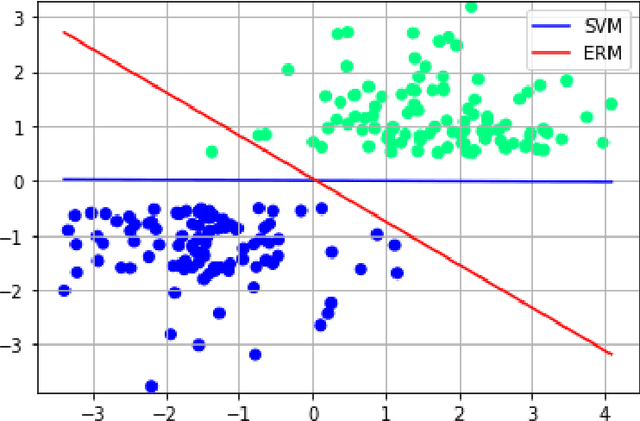
We investigate the functioning of a classifying biological neural network from the perspective of statistical learning theory, modelled, in a simplified setting, as a continuous-time stochastic recurrent neural network (RNN) with identity activation function. In the purely stochastic (robust) regime, we give a generalisation error bound that holds with high probability, thus showing that the empirical risk minimiser is the best-in-class hypothesis. We show that RNNs retain a partial signature of the paths they are fed as the unique information exploited for training and classification tasks. We argue that these RNNs are easy to train and robust and back these observations with numerical experiments on both synthetic and real data. We also exhibit a trade-off phenomenon between accuracy and robustness.
CoDERT: Distilling Encoder Representations with Co-learning for Transducer-based Speech Recognition
Jun 14, 2021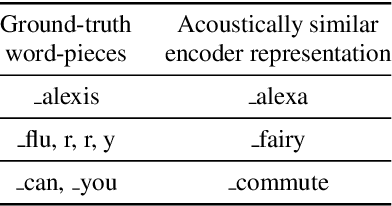
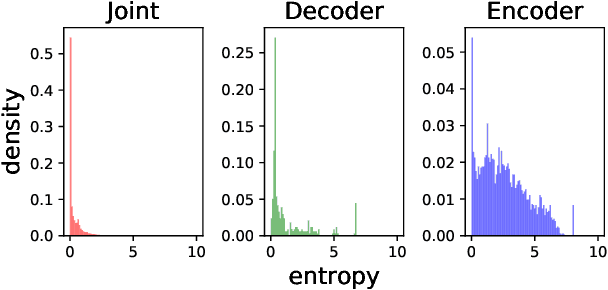
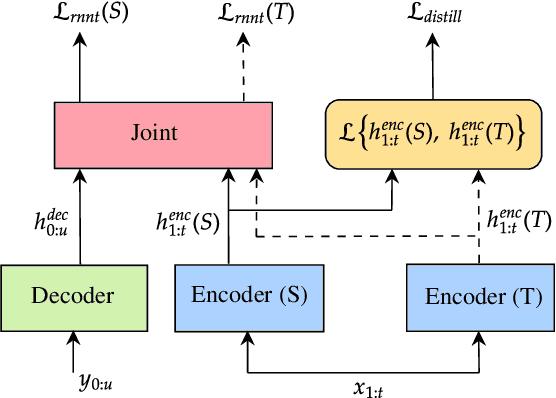
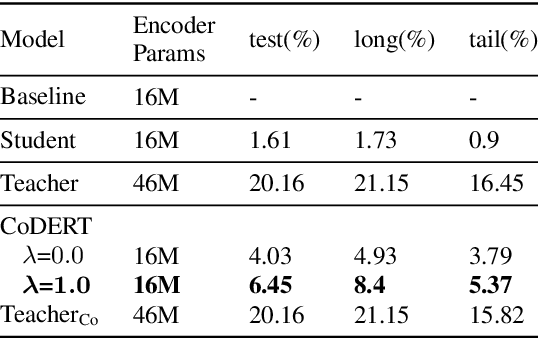
We propose a simple yet effective method to compress an RNN-Transducer (RNN-T) through the well-known knowledge distillation paradigm. We show that the transducer's encoder outputs naturally have a high entropy and contain rich information about acoustically similar word-piece confusions. This rich information is suppressed when combined with the lower entropy decoder outputs to produce the joint network logits. Consequently, we introduce an auxiliary loss to distill the encoder logits from a teacher transducer's encoder, and explore training strategies where this encoder distillation works effectively. We find that tandem training of teacher and student encoders with an inplace encoder distillation outperforms the use of a pre-trained and static teacher transducer. We also report an interesting phenomenon we refer to as implicit distillation, that occurs when the teacher and student encoders share the same decoder. Our experiments show 5.37-8.4% relative word error rate reductions (WERR) on in-house test sets, and 5.05-6.18% relative WERRs on LibriSpeech test sets.
A Multimodal Framework for Video Ads Understanding
Aug 29, 2021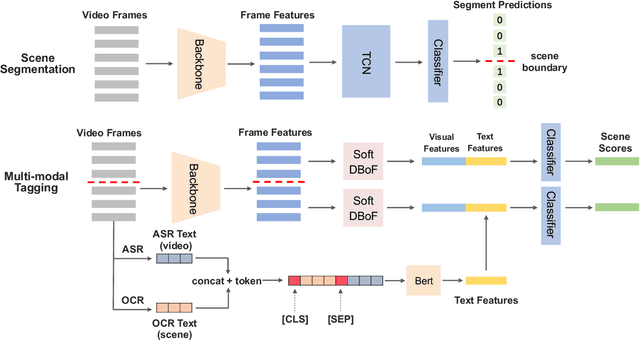


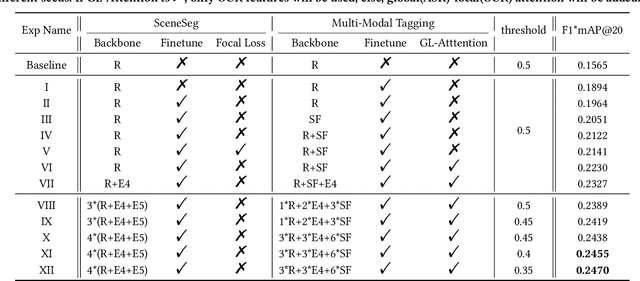
There is a growing trend in placing video advertisements on social platforms for online marketing, which demands automatic approaches to understand the contents of advertisements effectively. Taking the 2021 TAAC competition as an opportunity, we developed a multimodal system to improve the ability of structured analysis of advertising video content. In our framework, we break down the video structuring analysis problem into two tasks, i.e., scene segmentation and multi-modal tagging. In scene segmentation, we build upon a temporal convolution module for temporal modeling to predict whether adjacent frames belong to the same scene. In multi-modal tagging, we first compute clip-level visual features by aggregating frame-level features with NeXt-SoftDBoF. The visual features are further complemented with textual features that are derived using a global-local attention mechanism to extract useful information from OCR (Optical Character Recognition) and ASR (Audio Speech Recognition) outputs. Our solution achieved a score of 0.2470 measured in consideration of localization and prediction accuracy, ranking fourth in the 2021 TAAC final leaderboard.
Image Inpainting via Conditional Texture and Structure Dual Generation
Aug 22, 2021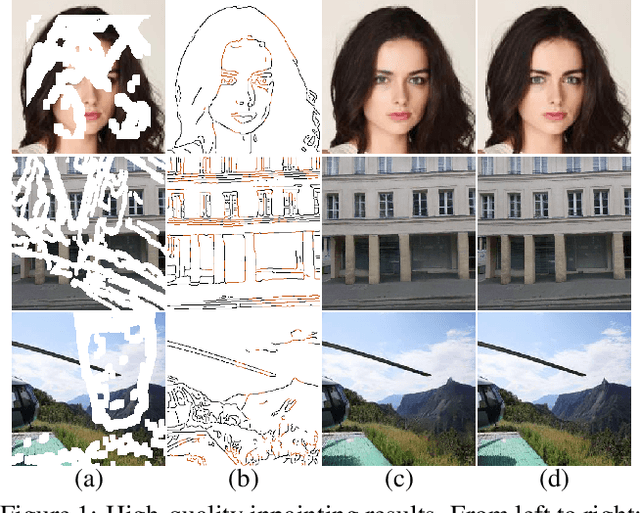
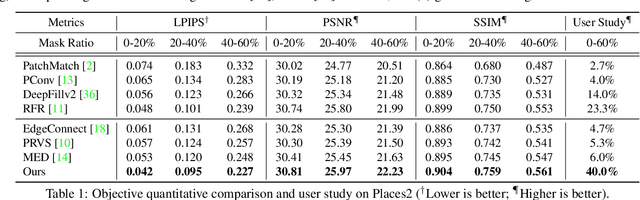
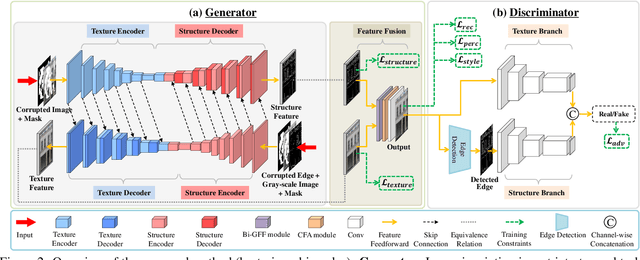
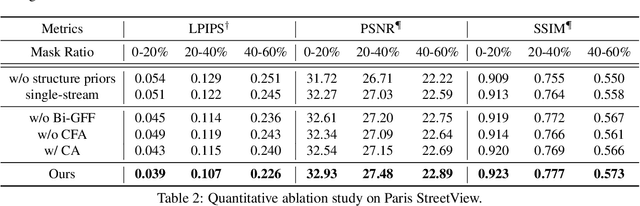
Deep generative approaches have recently made considerable progress in image inpainting by introducing structure priors. Due to the lack of proper interaction with image texture during structure reconstruction, however, current solutions are incompetent in handling the cases with large corruptions, and they generally suffer from distorted results. In this paper, we propose a novel two-stream network for image inpainting, which models the structure-constrained texture synthesis and texture-guided structure reconstruction in a coupled manner so that they better leverage each other for more plausible generation. Furthermore, to enhance the global consistency, a Bi-directional Gated Feature Fusion (Bi-GFF) module is designed to exchange and combine the structure and texture information and a Contextual Feature Aggregation (CFA) module is developed to refine the generated contents by region affinity learning and multi-scale feature aggregation. Qualitative and quantitative experiments on the CelebA, Paris StreetView and Places2 datasets demonstrate the superiority of the proposed method. Our code is available at https://github.com/Xiefan-Guo/CTSDG.
MBDF-Net: Multi-Branch Deep Fusion Network for 3D Object Detection
Aug 29, 2021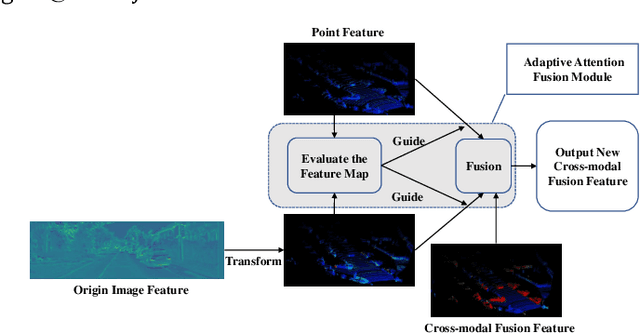
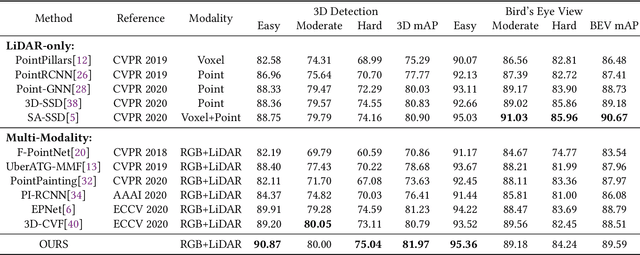
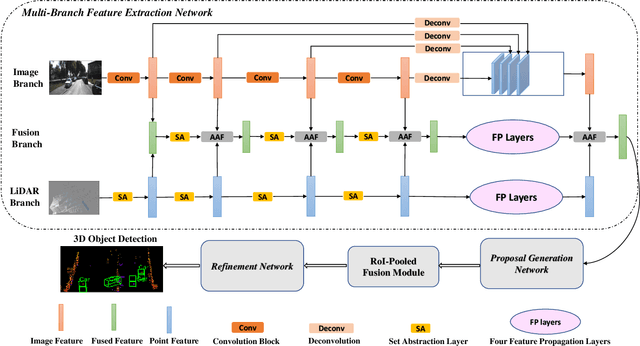
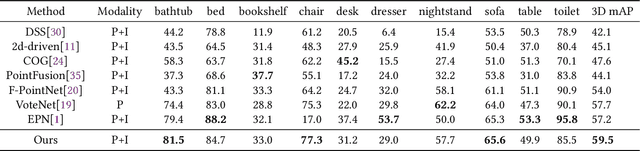
Point clouds and images could provide complementary information when representing 3D objects. Fusing the two kinds of data usually helps to improve the detection results. However, it is challenging to fuse the two data modalities, due to their different characteristics and the interference from the non-interest areas. To solve this problem, we propose a Multi-Branch Deep Fusion Network (MBDF-Net) for 3D object detection. The proposed detector has two stages. In the first stage, our multi-branch feature extraction network utilizes Adaptive Attention Fusion (AAF) modules to produce cross-modal fusion features from single-modal semantic features. In the second stage, we use a region of interest (RoI) -pooled fusion module to generate enhanced local features for refinement. A novel attention-based hybrid sampling strategy is also proposed for selecting key points in the downsampling process. We evaluate our approach on two widely used benchmark datasets including KITTI and SUN-RGBD. The experimental results demonstrate the advantages of our method over state-of-the-art approaches.