 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dilated Inception U-Net (DIU-Net) for Brain Tumor Segmentation
Aug 15, 2021
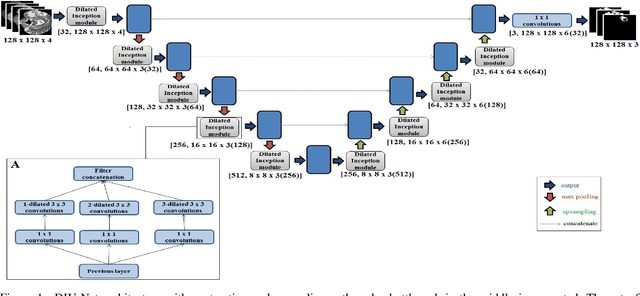
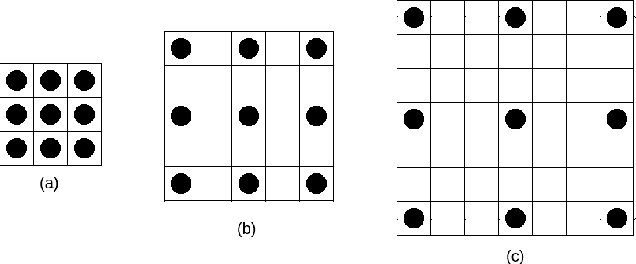
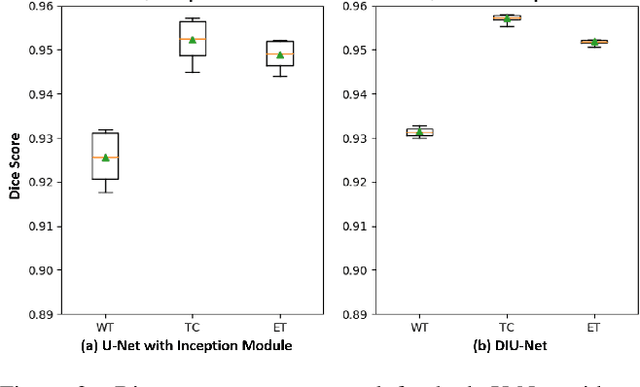
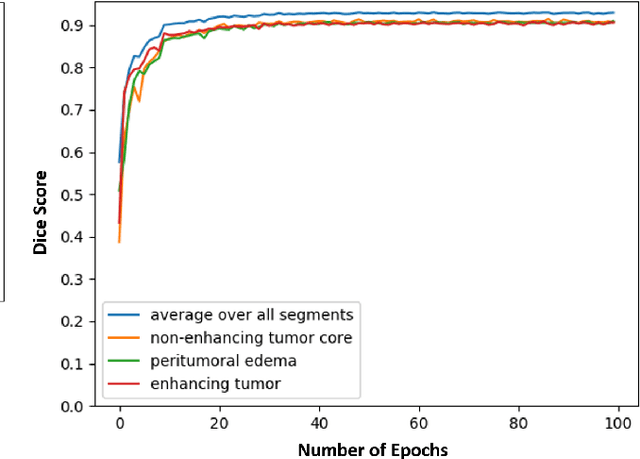
Magnetic resonance imaging (MRI) is routinely used for brain tumor diagnosis, treatment planning, and post-treatment surveillance. Recently, various models based on deep neural networks have been proposed for the pixel-level segmentation of tumors in brain MRIs. However, the structural variations, spatial dissimilarities, and intensity inhomogeneity in MRIs make segmentation a challenging task. We propose a new end-to-end brain tumor segmentation architecture based on U-Net that integrates Inception modules and dilated convolutions into its contracting and expanding paths. This allows us to extract local structural as well as global contextual information. We performed segmentation of glioma sub-regions, including tumor core, enhancing tumor, and whole tumor using Brain Tumor Segmentation (BraTS) 2018 dataset. Our proposed model performed significantly better than the state-of-the-art U-Net-based model ($p<0.05$) for tumor core and whole tumor segmentation.
Information Processing by Networks of Quantum Decision Makers
Dec 15, 2017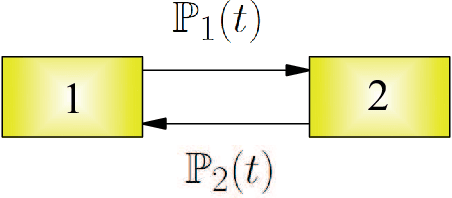

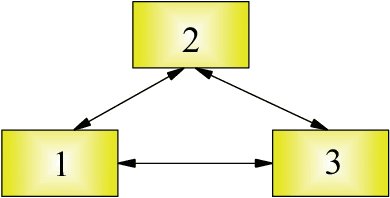
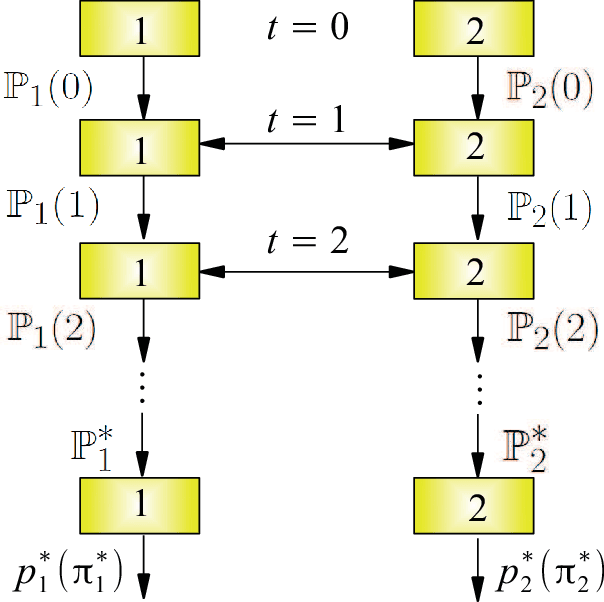
We suggest a model of a multi-agent society of decision makers taking decisions being based on two criteria, one is the utility of the prospects and the other is the attractiveness of the considered prospects. The model is the generalization of quantum decision theory, developed earlier for single decision makers realizing one-step decisions, in two principal aspects. First, several decision makers are considered simultaneously, who interact with each other through information exchange. Second, a multistep procedure is treated, when the agents exchange information many times. Several decision makers exchanging information and forming their judgement, using quantum rules, form a kind of a quantum information network, where collective decisions develop in time as a result of information exchange. In addition to characterizing collective decisions that arise in human societies, such networks can describe dynamical processes occurring in artificial quantum intelligence composed of several parts or in a cluster of quantum computers. The practical usage of the theory is illustrated on the dynamic disjunction effect for which three quantitative predictions are made: (i) the probabilistic behavior of decision makers at the initial stage of the process is described; (ii) the decrease of the difference between the initial prospect probabilities and the related utility factors is proved; (iii) the existence of a common consensus after multiple exchange of information is predicted. The predicted numerical values are in very good agreement with empirical data.
Efficient-FedRec: Efficient Federated Learning Framework for Privacy-Preserving News Recommendation
Sep 16, 2021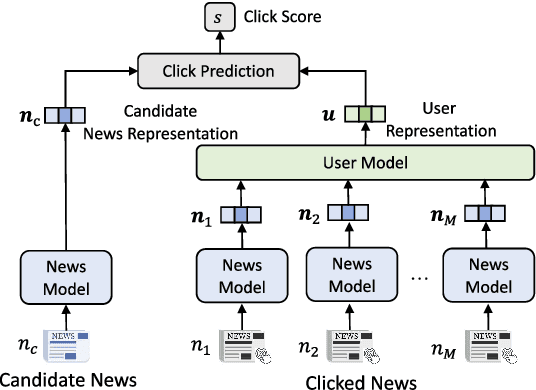
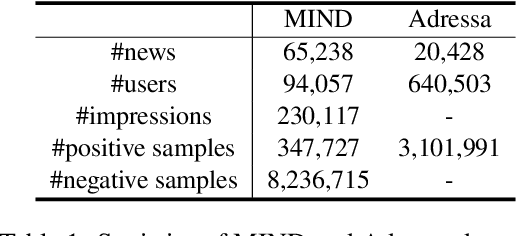
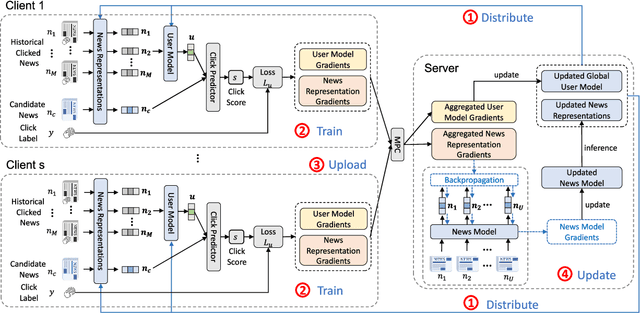
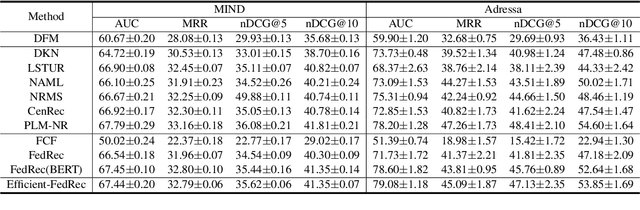
News recommendation is critical for personalized news access. Most existing news recommendation methods rely on centralized storage of users' historical news click behavior data, which may lead to privacy concerns and hazards. Federated Learning is a privacy-preserving framework for multiple clients to collaboratively train models without sharing their private data. However, the computation and communication cost of directly learning many existing news recommendation models in a federated way are unacceptable for user clients. In this paper, we propose an efficient federated learning framework for privacy-preserving news recommendation. Instead of training and communicating the whole model, we decompose the news recommendation model into a large news model maintained in the server and a light-weight user model shared on both server and clients, where news representations and user model are communicated between server and clients. More specifically, the clients request the user model and news representations from the server, and send their locally computed gradients to the server for aggregation. The server updates its global user model with the aggregated gradients, and further updates its news model to infer updated news representations. Since the local gradients may contain private information, we propose a secure aggregation method to aggregate gradients in a privacy-preserving way. Experiments on two real-world datasets show that our method can reduce the computation and communication cost on clients while keep promising model performance.
SegMix: Co-occurrence Driven Mixup for Semantic Segmentation and Adversarial Robustness
Aug 23, 2021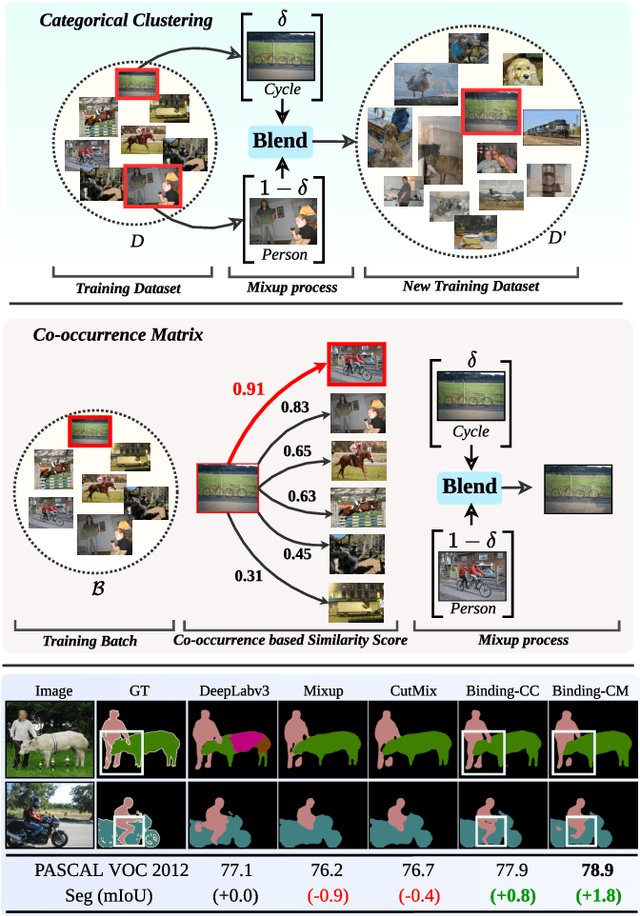
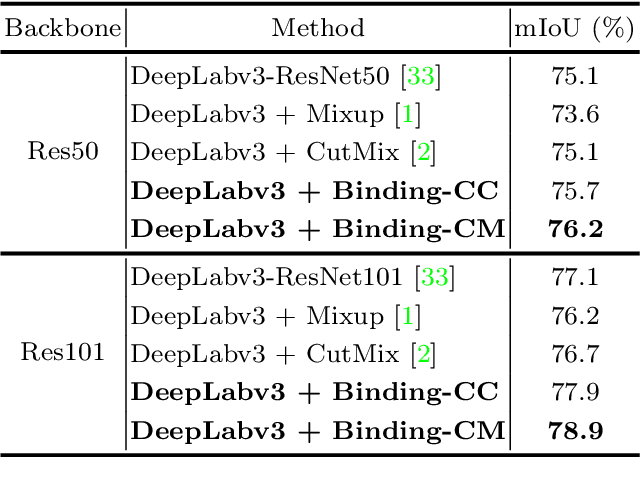
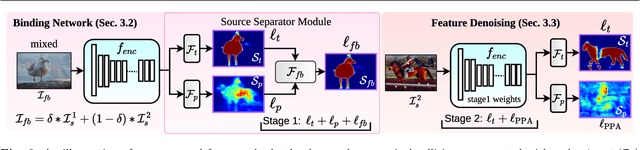

In this paper, we present a strategy for training convolutional neural networks to effectively resolve interference arising from competing hypotheses relating to inter-categorical information throughout the network. The premise is based on the notion of feature binding, which is defined as the process by which activations spread across space and layers in the network are successfully integrated to arrive at a correct inference decision. In our work, this is accomplished for the task of dense image labelling by blending images based on (i) categorical clustering or (ii) the co-occurrence likelihood of categories. We then train a feature binding network which simultaneously segments and separates the blended images. Subsequent feature denoising to suppress noisy activations reveals additional desirable properties and high degrees of successful predictions. Through this process, we reveal a general mechanism, distinct from any prior methods, for boosting the performance of the base segmentation and saliency network while simultaneously increasing robustness to adversarial attacks.
Guiding Teacher Forcing with Seer Forcing for Neural Machine Translation
Jun 12, 2021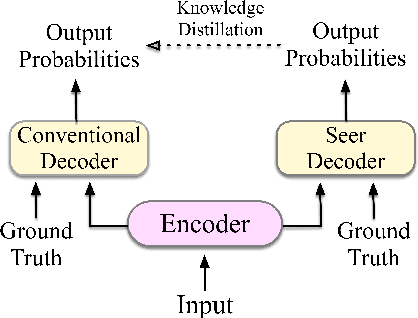
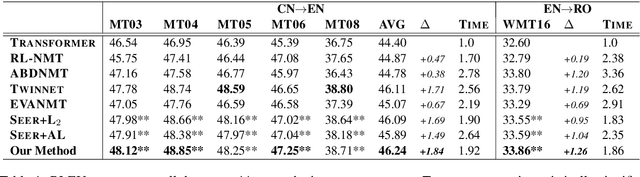
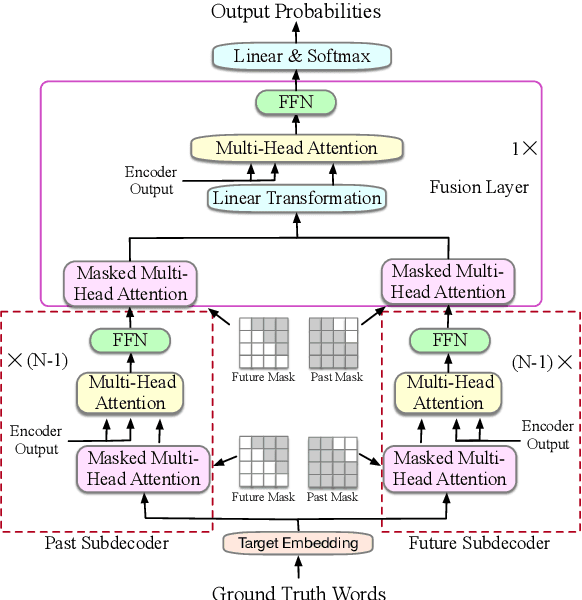
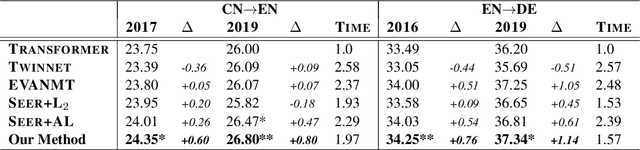
Although teacher forcing has become the main training paradigm for neural machine translation, it usually makes predictions only conditioned on past information, and hence lacks global planning for the future. To address this problem, we introduce another decoder, called seer decoder, into the encoder-decoder framework during training, which involves future information in target predictions. Meanwhile, we force the conventional decoder to simulate the behaviors of the seer decoder via knowledge distillation. In this way, at test the conventional decoder can perform like the seer decoder without the attendance of it. Experiment results on the Chinese-English, English-German and English-Romanian translation tasks show our method can outperform competitive baselines significantly and achieves greater improvements on the bigger data sets. Besides, the experiments also prove knowledge distillation the best way to transfer knowledge from the seer decoder to the conventional decoder compared to adversarial learning and L2 regularization.
Learnable Multi-level Frequency Decomposition and Hierarchical Attention Mechanism for Generalized Face Presentation Attack Detection
Sep 16, 2021
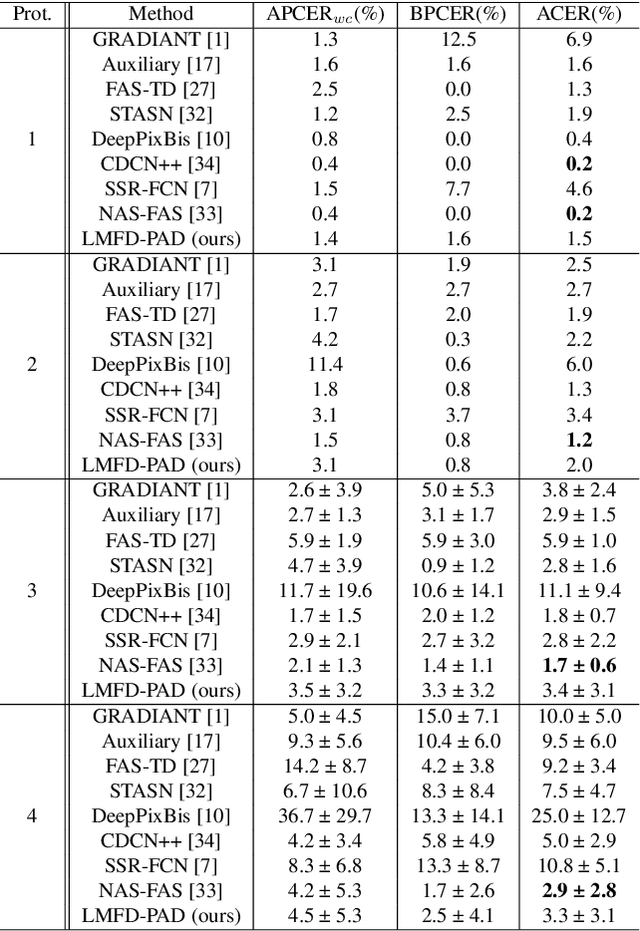
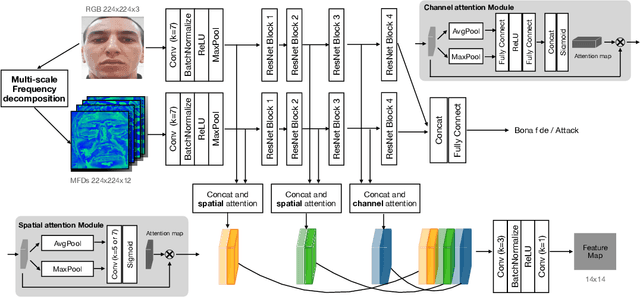
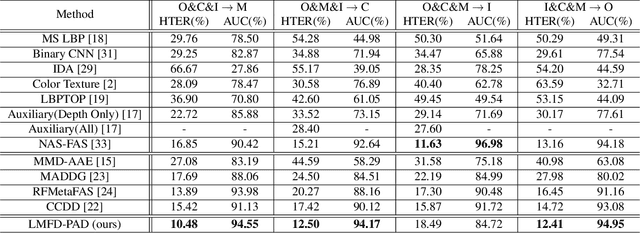
With the increased deployment of face recognition systems in our daily lives, face presentation attack detection (PAD) is attracting a lot of attention and playing a key role in securing face recognition systems. Despite the great performance achieved by the hand-crafted and deep learning based methods in intra-dataset evaluations, the performance drops when dealing with unseen scenarios. In this work, we propose a dual-stream convolution neural networks (CNNs) framework. One stream adapts four learnable frequency filters to learn features in the frequency domain, which are less influenced variations in sensors/illuminations. The other stream leverage the RGB images to complement the features of the frequency domain. Moreover, we propose a hierarchical attention module integration to join the information from the two streams at different stages by considering the nature of deep features in different layers of the CNN. The proposed method is evaluated in the intra-dataset and cross-dataset setups and the results demonstrates that our proposed approach enhances the generalizability in most experimental setups in comparison to state-of-the-art, including the methods designed explicitly for domain adaption/shift problem. We successfully prove the design of our proposed PAD solution in a step-wise ablation study that involves our proposed learnable frequency decomposition, our hierarchical attention module design, and the used loss function. Training codes and pre-trained models are publicly released.
Weighing Features of Lung and Heart Regions for Thoracic Disease Classification
May 26, 2021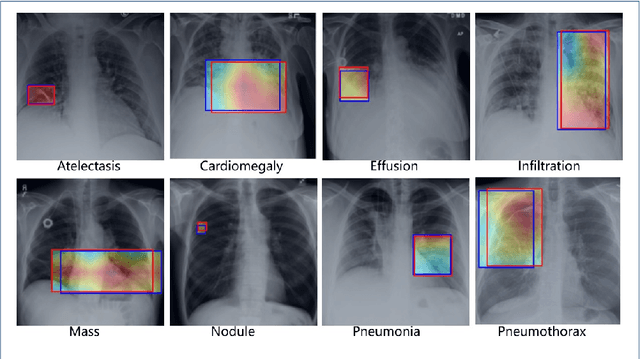
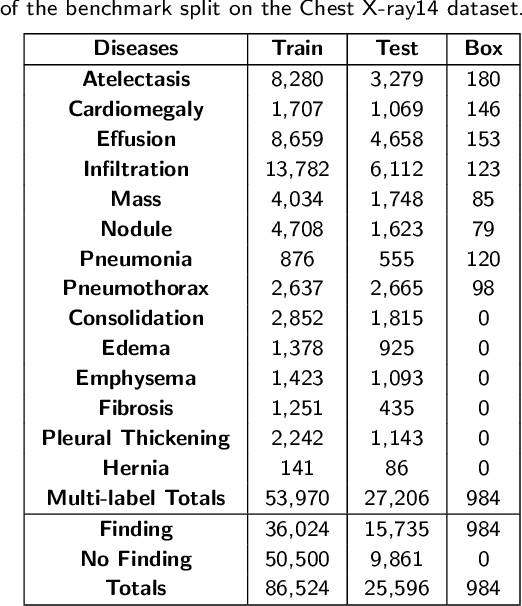
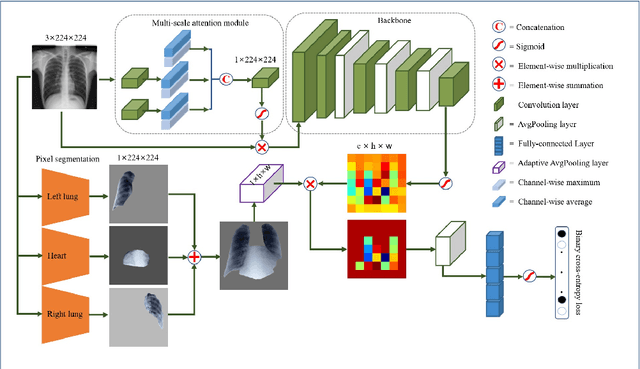
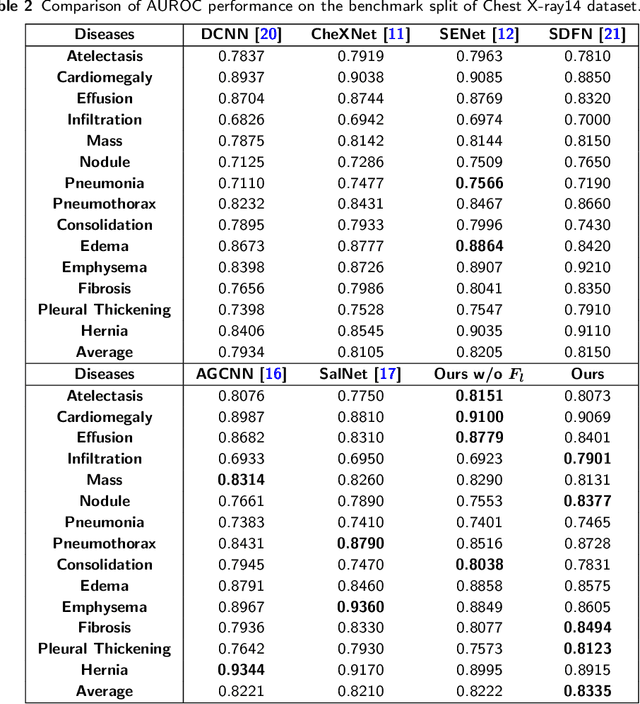
Chest X-rays are the most commonly available and affordable radiological examination for screening thoracic diseases. According to the domain knowledge of screening chest X-rays, the pathological information usually lay on the lung and heart regions. However, it is costly to acquire region-level annotation in practice, and model training mainly relies on image-level class labels in a weakly supervised manner, which is highly challenging for computer-aided chest X-ray screening. To address this issue, some methods have been proposed recently to identify local regions containing pathological information, which is vital for thoracic disease classification. Inspired by this, we propose a novel deep learning framework to explore discriminative information from lung and heart regions. We design a feature extractor equipped with a multi-scale attention module to learn global attention maps from global images. To exploit disease-specific cues effectively, we locate lung and heart regions containing pathological information by a well-trained pixel-wise segmentation model to generate binarization masks. By introducing element-wise logical AND operator on the learned global attention maps and the binarization masks, we obtain local attention maps in which pixels are $1$ for lung and heart region and $0$ for other regions. By zeroing features of non-lung and heart regions in attention maps, we can effectively exploit their disease-specific cues in lung and heart regions. Compared to existing methods fusing global and local features, we adopt feature weighting to avoid weakening visual cues unique to lung and heart regions. Evaluated by the benchmark split on the publicly available chest X-ray14 dataset, the comprehensive experiments show that our method achieves superior performance compared to the state-of-the-art methods.
MogFace: Rethinking Scale Augmentation on the Face Detector
Mar 29, 2021
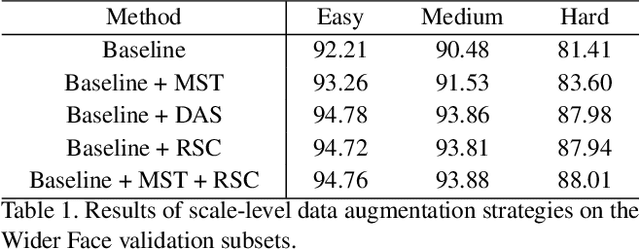

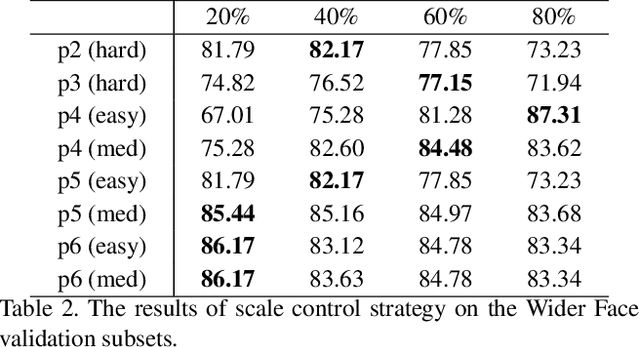
Face detector frequently confronts extreme scale variance challenge. The famous solutions are Multi-scale training, Data-anchor-sampling and Random crop strategy. In this paper, we indicate 2 significant elements to resolve extreme scale variance problem by investigating the difference among the previous solutions, including the fore-ground and back-ground information of an image and the scale information. However, current excellent solutions can only utilize the former information while neglecting to absorb the latter one effectively. In order to help the detector utilize the scale information efficiently, we analyze the relationship between the detector performance and the scale distribution of the training data. Based on this analysis, we propose a Selective Scale Enhancement (SSE) strategy which can assimilate these two information efficiently and simultaneously. Finally, our method achieves state-of-the-art detection performance on all common face detection benchmarks, including AFW, PASCAL face, FDDB and Wider Face datasets. Note that our result achieves six champions on the Wider Face dataset.
Retrieval and Localization with Observation Constraints
Aug 19, 2021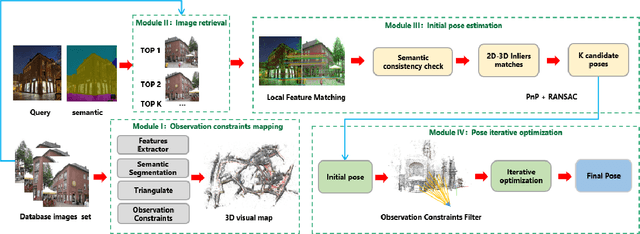
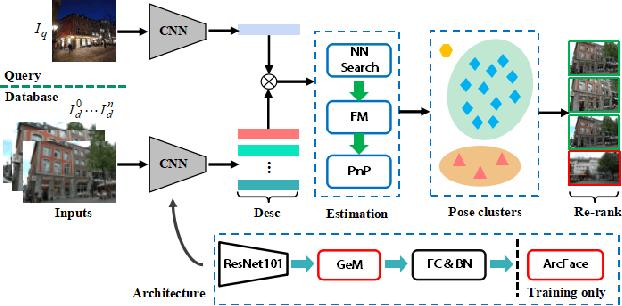
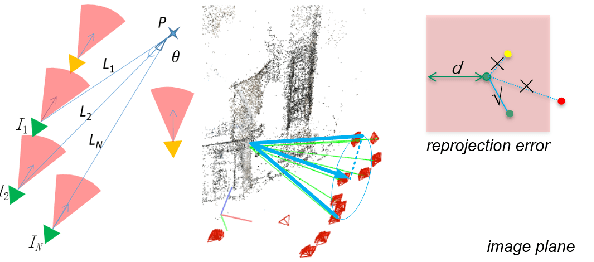
Accurate visual re-localization is very critical to many artificial intelligence applications, such as augmented reality, virtual reality, robotics and autonomous driving. To accomplish this task, we propose an integrated visual re-localization method called RLOCS by combining image retrieval, semantic consistency and geometry verification to achieve accurate estimations. The localization pipeline is designed as a coarse-to-fine paradigm. In the retrieval part, we cascade the architecture of ResNet101-GeM-ArcFace and employ DBSCAN followed by spatial verification to obtain a better initial coarse pose. We design a module called observation constraints, which combines geometry information and semantic consistency for filtering outliers. Comprehensive experiments are conducted on open datasets, including retrieval on R-Oxford5k and R-Paris6k, semantic segmentation on Cityscapes, localization on Aachen Day-Night and InLoc. By creatively modifying separate modules in the total pipeline, our method achieves many performance improvements on the challenging localization benchmarks.
A Qualitative Evaluation of User Preference for Link-based vs. Text-based Recommendations of Wikipedia Articles
Sep 16, 2021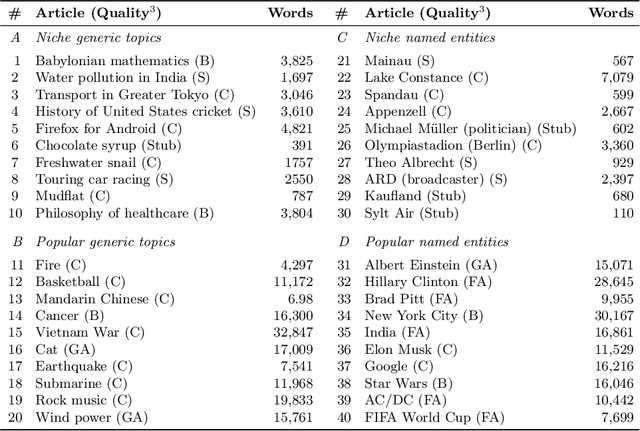
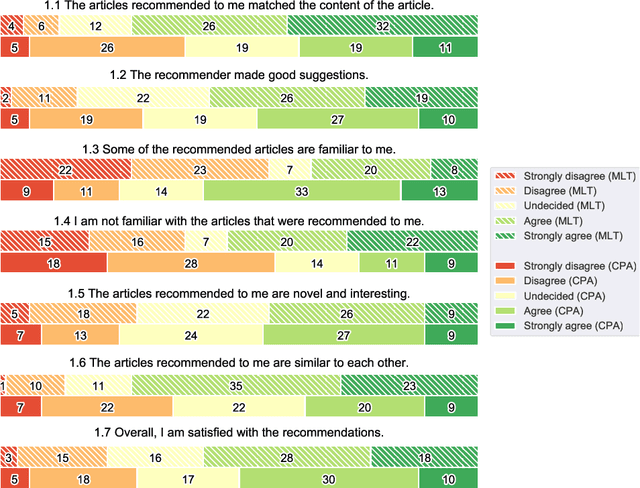
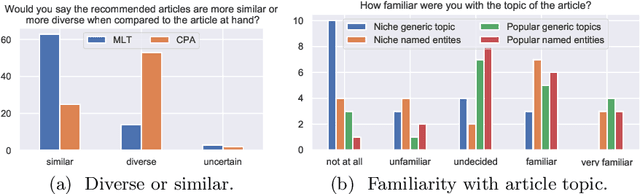
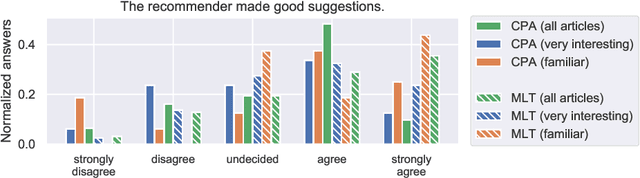
Literature recommendation systems (LRS) assist readers in the discovery of relevant content from the overwhelming amount of literature available. Despite the widespread adoption of LRS, there is a lack of research on the user-perceived recommendation characteristics for fundamentally different approaches to content-based literature recommendation. To complement existing quantitative studies on literature recommendation, we present qualitative study results that report on users' perceptions for two contrasting recommendation classes: (1) link-based recommendation represented by the Co-Citation Proximity (CPA) approach, and (2) text-based recommendation represented by Lucene's MoreLikeThis (MLT) algorithm. The empirical data analyzed in our study with twenty users and a diverse set of 40 Wikipedia articles indicate a noticeable difference between text- and link-based recommendation generation approaches along several key dimensions. The text-based MLT method receives higher satisfaction ratings in terms of user-perceived similarity of recommended articles. In contrast, the CPA approach receives higher satisfaction scores in terms of diversity and serendipity of recommendations. We conclude that users of literature recommendation systems can benefit most from hybrid approaches that combine both link- and text-based approaches, where the user's information needs and preferences should control the weighting for the approaches used. The optimal weighting of multiple approaches used in a hybrid recommendation system is highly dependent on a user's shifting needs.