 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ZFlow: Gated Appearance Flow-based Virtual Try-on with 3D Priors
Sep 14, 2021

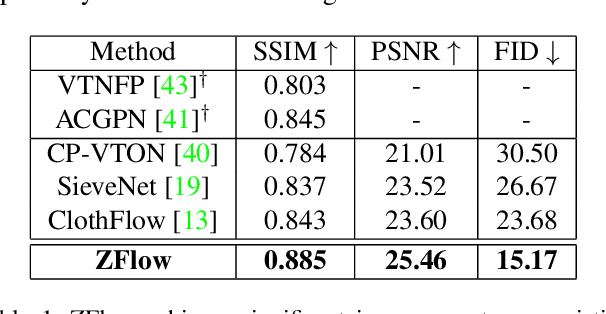
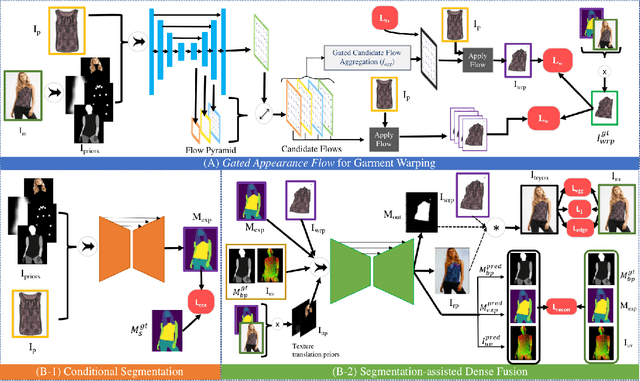
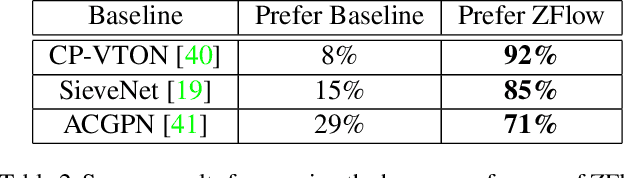
Image-based virtual try-on involves synthesizing perceptually convincing images of a model wearing a particular garment and has garnered significant research interest due to its immense practical applicability. Recent methods involve a two stage process: i) warping of the garment to align with the model ii) texture fusion of the warped garment and target model to generate the try-on output. Issues arise due to the non-rigid nature of garments and the lack of geometric information about the model or the garment. It often results in improper rendering of granular details. We propose ZFlow, an end-to-end framework, which seeks to alleviate these concerns regarding geometric and textural integrity (such as pose, depth-ordering, skin and neckline reproduction) through a combination of gated aggregation of hierarchical flow estimates termed Gated Appearance Flow, and dense structural priors at various stage of the network. ZFlow achieves state-of-the-art results as observed qualitatively, and on quantitative benchmarks of image quality (PSNR, SSIM, and FID). The paper presents extensive comparisons with other existing solutions including a detailed user study and ablation studies to gauge the effect of each of our contributions on multiple datasets.
Multi-scale Edge-based U-shape Network for Salient Object Detection
Aug 21, 2021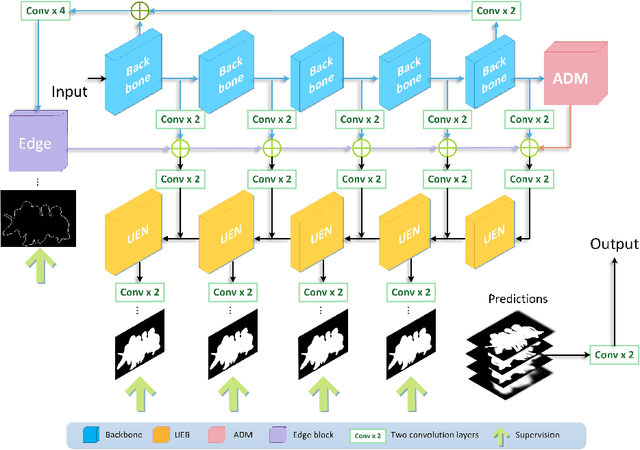
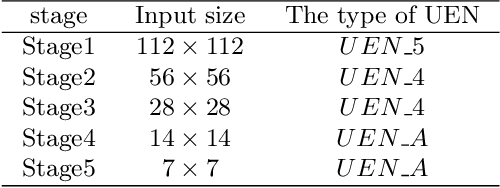
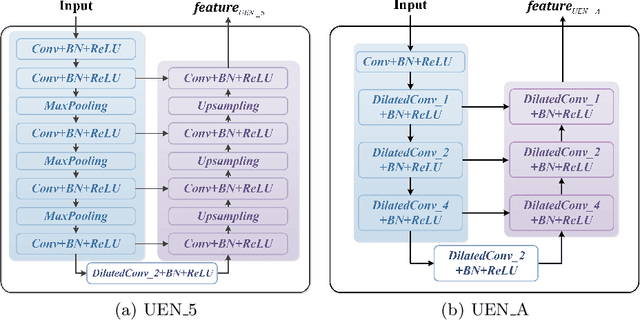
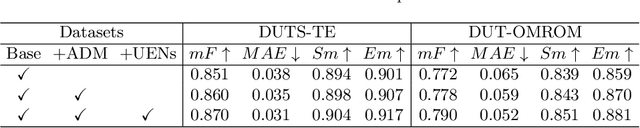
Deep-learning based salient object detection methods achieve great improvements. However, there are still problems existing in the predictions, such as blurry boundary and inaccurate location, which is mainly caused by inadequate feature extraction and integration. In this paper, we propose a Multi-scale Edge-based U-shape Network (MEUN) to integrate various features at different scales to achieve better performance. To extract more useful information for boundary prediction, U-shape Edge Network modules are embedded in each decoder units. Besides, the additional down-sampling module alleviates the location inaccuracy. Experimental results on four benchmark datasets demonstrate the validity and reliability of the proposed method. Multi-scale Edge based U-shape Network also shows its superiority when compared with 15 state-of-the-art salient object detection methods.
Hypergraph-of-Entity: A General Model for Entity-Oriented Search
Sep 01, 2021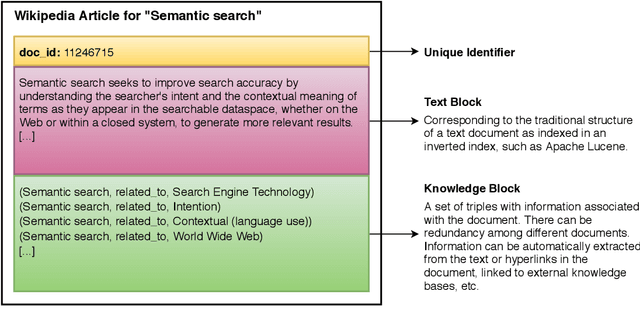

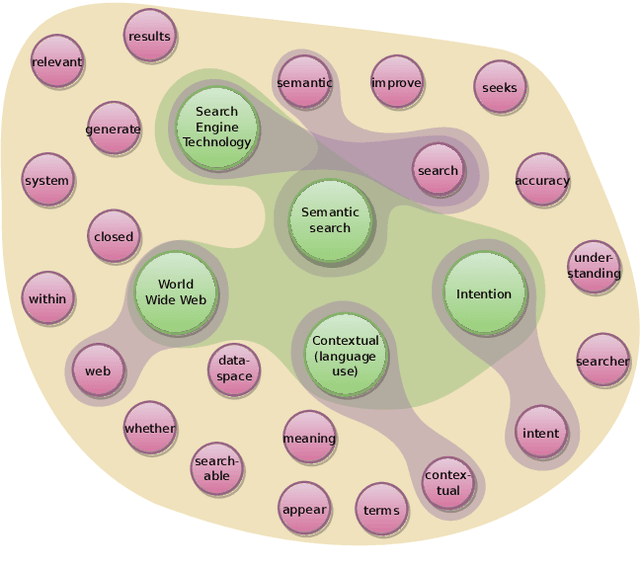
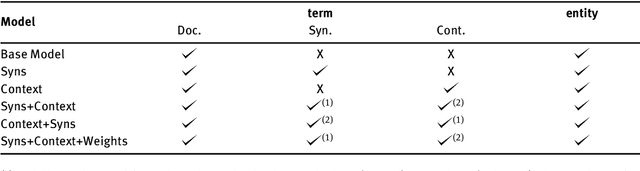
The hypergraph-of-entity was conceptually proposed as a general model for entity-oriented search. However, only the performance for ad hoc document retrieval had been assessed. We continue this line of research by also evaluating ad hoc entity retrieval, and entity list completion. We also attempt to scale the model, so that it can support the complete INEX 2009 Wikipedia collection. We do this by indexing the top keywords for each document, reducing complexity by partially lowering the number of nodes and, indirectly, the number of hyperedges linking terms to entities. This enables us to compare the effectiveness of the hypergraph-of-entity with the results obtained by the participants of the INEX tracks for the considered tasks. We find this to be a viable model that is, to our knowledge, the first attempt at a generalization in information retrieval, in particular by supporting a universal ranking function for multiple entity-oriented search tasks.
Multi-modal Wound Classification using Wound Image and Location by Deep Neural Network
Sep 14, 2021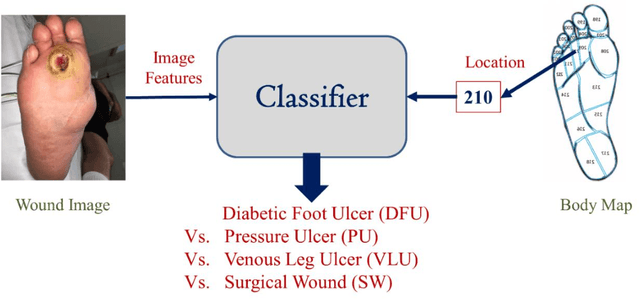
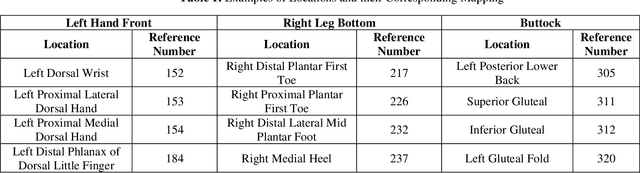
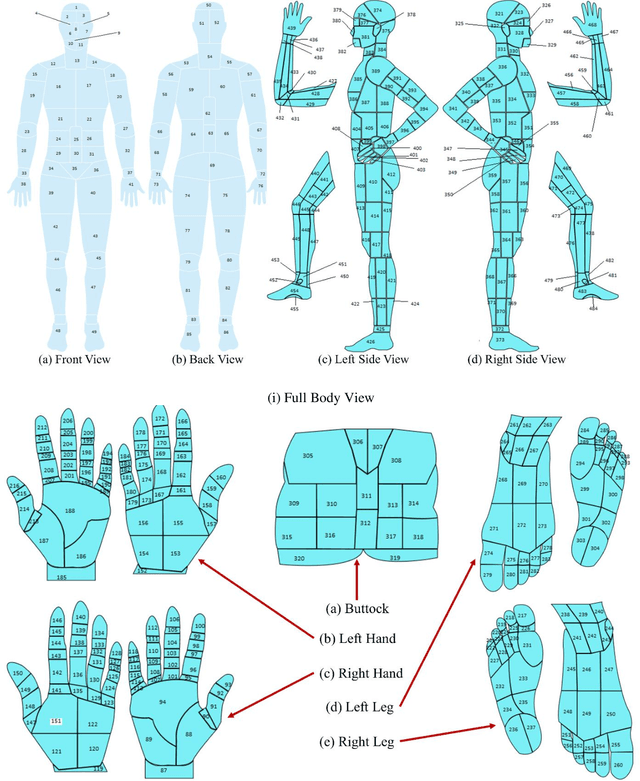
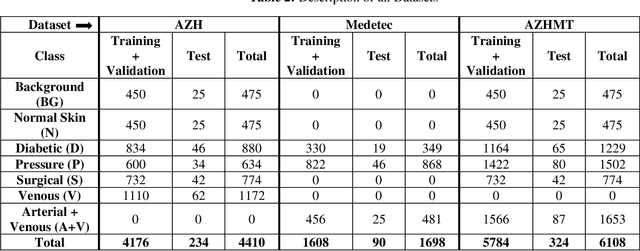
Wound classification is an essential step of wound diagnosis. An efficient classifier can assist wound specialists in classifying wound types with less financial and time costs and help them decide an optimal treatment procedure. This study developed a deep neural network-based multi-modal classifier using wound images and their corresponding locations to categorize wound images into multiple classes, including diabetic, pressure, surgical, and venous ulcers. A body map is also developed to prepare the location data, which can help wound specialists tag wound locations more efficiently. Three datasets containing images and their corresponding location information are designed with the help of wound specialists. The multi-modal network is developed by concatenating the image-based and location-based classifier's outputs with some other modifications. The maximum accuracy on mixed-class classifications (containing background and normal skin) varies from 77.33% to 100% on different experiments. The maximum accuracy on wound-class classifications (containing only diabetic, pressure, surgical, and venous) varies from 72.95% to 98.08% on different experiments. The proposed multi-modal network also shows a significant improvement in results from the previous works of literature.
Collaborative Variational Bandwidth Auto-encoder for Recommender Systems
May 17, 2021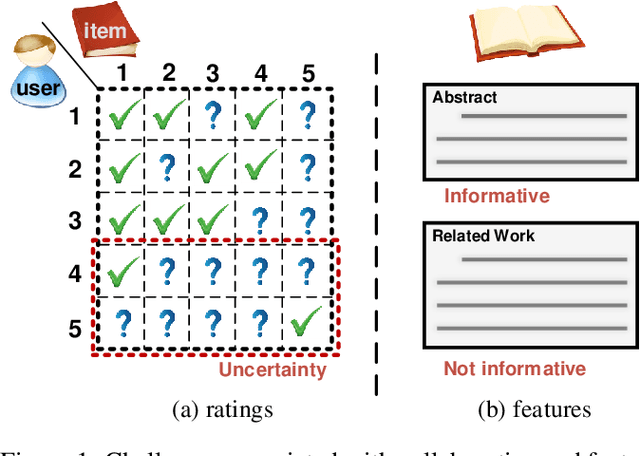
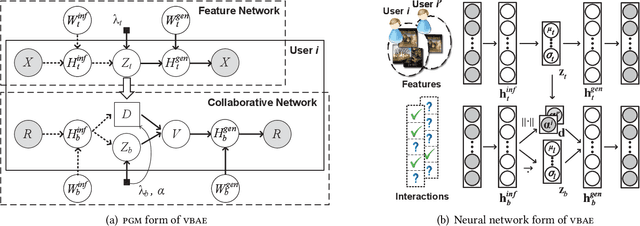
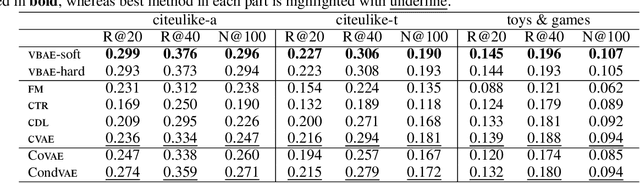
Collaborative filtering has been widely adopted by modern recommender systems to discover user preferences based on their past behaviors. However, the observed interactions for different users are usually unbalanced, which leads to high uncertainty in the collaborative embeddings of users with sparse ratings, thereby severely degenerating the recommendation performance. Consequently, more efforts have been dedicated to the hybrid recommendation strategy where user/item features are utilized as auxiliary information to address the sparsity problem. However, since these features contain rich multimodal patterns and most of them are irrelevant to the recommendation purpose, excessive reliance on these features will make the model difficult to generalize. To address the above two challenges, we propose a VBAE for recommendation. VBAE models both the collaborative and the user feature embeddings as Gaussian random variables inferred via deep neural networks to capture non-linear similarities between users based on their ratings and features. Furthermore, VBAE establishes an information regulation mechanism by introducing a user-dependent channel variable where the bandwidth is determined by the information already contained in the observed ratings to dynamically control the amount of information allowed to be accessed from the corresponding user features. The user-dependent channel variable alleviates the uncertainty problem when the ratings are sparse while avoids unnecessary dependence of the model on noisy user features simultaneously. Codes and datasets are released at https://github.com/yaochenzhu/vbae.
Tactile Image-to-Image Disentanglement of Contact Geometry from Motion-Induced Shear
Sep 08, 2021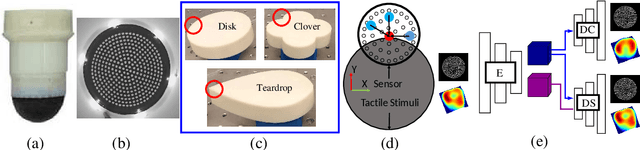
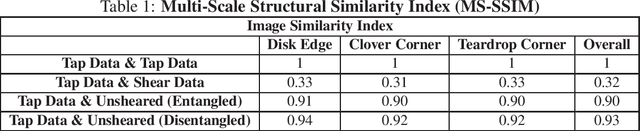
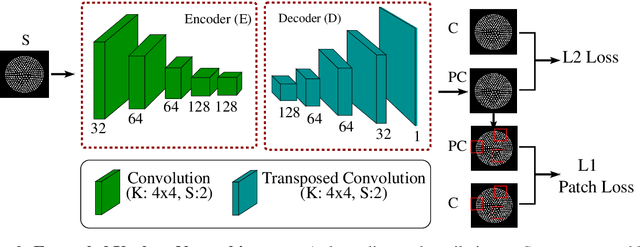
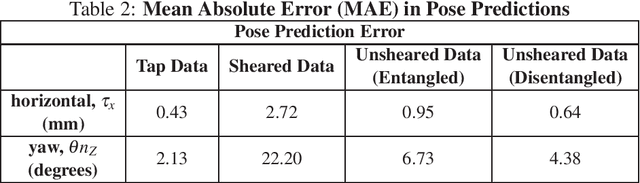
Robotic touch, particularly when using soft optical tactile sensors, suffers from distortion caused by motion-dependent shear. The manner in which the sensor contacts a stimulus is entangled with the tactile information about the geometry of the stimulus. In this work, we propose a supervised convolutional deep neural network model that learns to disentangle, in the latent space, the components of sensor deformations caused by contact geometry from those due to sliding-induced shear. The approach is validated by reconstructing unsheared tactile images from sheared images and showing they match unsheared tactile images collected with no sliding motion. In addition, the unsheared tactile images give a faithful reconstruction of the contact geometry that is not possible from the sheared data, and robust estimation of the contact pose that can be used for servo control sliding around various 2D shapes. Finally, the contact geometry reconstruction in conjunction with servo control sliding were used for faithful full object reconstruction of various 2D shapes. The methods have broad applicability to deep learning models for robots with a shear-sensitive sense of touch.
Free Gap Information from the Differentially Private Sparse Vector and Noisy Max Mechanisms
May 02, 2019
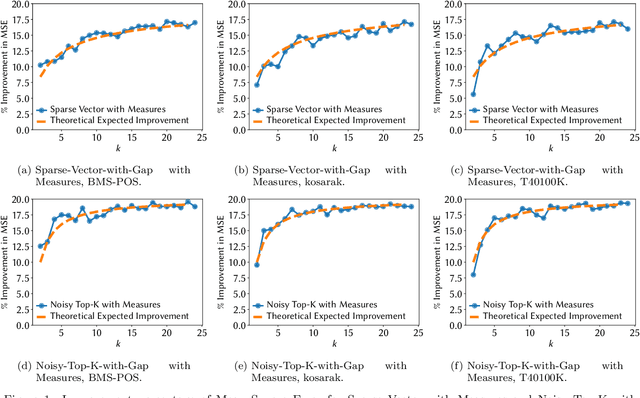
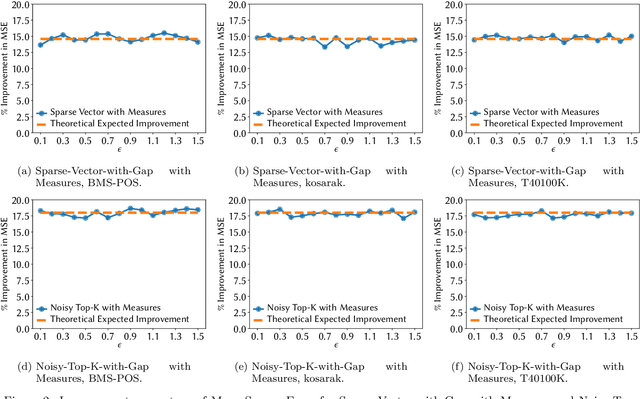
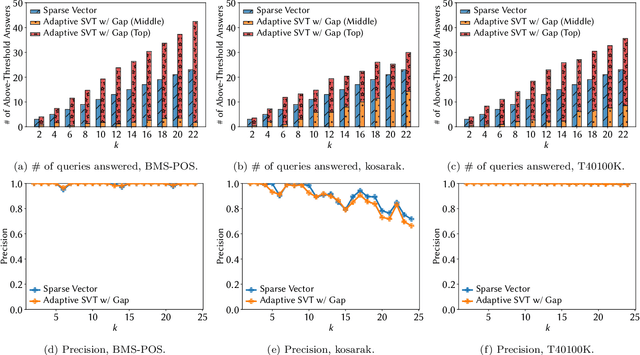
Noisy Max and Sparse Vector are selection algorithms for differential privacy and serve as building blocks for more complex algorithms. In this paper we show that both algorithms can release additional information for free (i.e., at no additional privacy cost). Noisy Max is used to return the approximate maximizer among a set of queries. We show that it can also release for free the noisy gap between the approximate maximizer and runner-up. Sparse Vector is used to return a set of queries that are approximately larger than a fixed threshold. We show that it can adaptively control its privacy budget (use less budget for queries that are likely to be much larger than the threshold) and simultaneously release for free a noisy gap between the selected queries and the threshold. It has long been suspected that Sparse Vector can release additional information, but prior attempts had incorrect proofs. Our version is proved using randomness alignment, a proof template framework borrowed from the program verification literature. We show how the free extra information in both mechanisms can be used to improve the utility of differentially private algorithms.
Graph Autoencoders for Embedding Learning in Brain Networks and Major Depressive Disorder Identification
Jul 27, 2021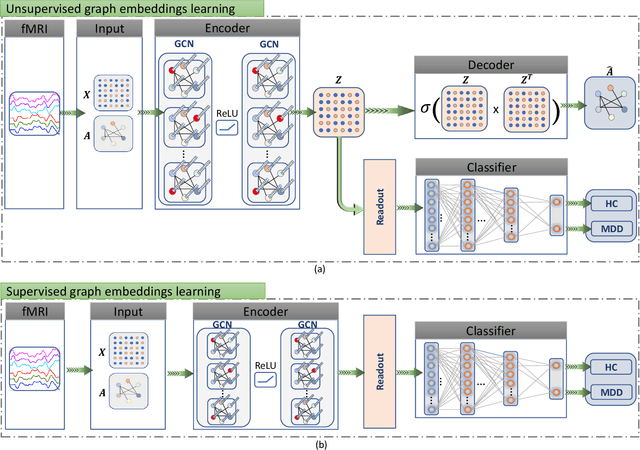
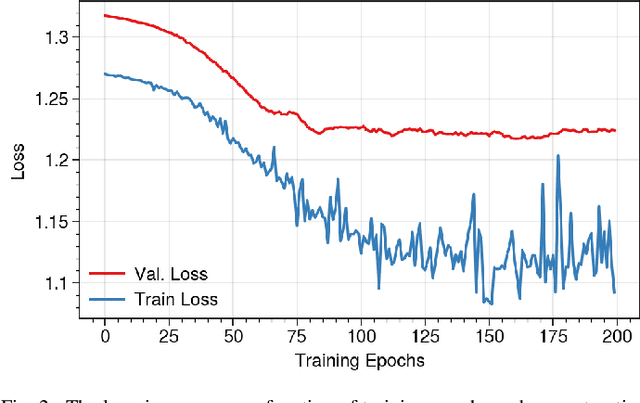
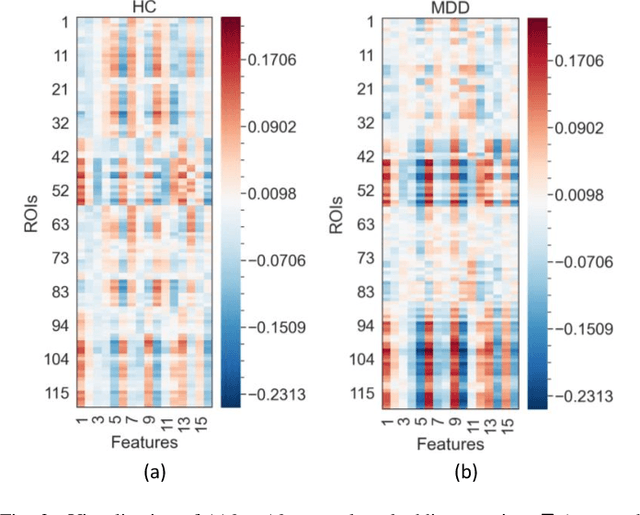
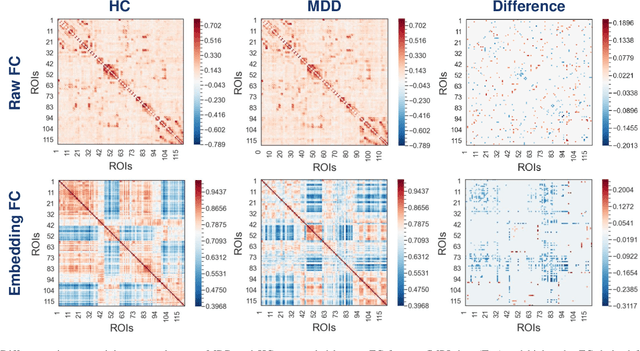
Brain functional connectivity (FC) reveals biomarkers for identification of various neuropsychiatric disorders. Recent application of deep neural networks (DNNs) to connectome-based classification mostly relies on traditional convolutional neural networks using input connectivity matrices on a regular Euclidean grid. We propose a graph deep learning framework to incorporate the non-Euclidean information about graph structure for classifying functional magnetic resonance imaging (fMRI)- derived brain networks in major depressive disorder (MDD). We design a novel graph autoencoder (GAE) architecture based on the graph convolutional networks (GCNs) to embed the topological structure and node content of large-sized fMRI networks into low-dimensional latent representations. In network construction, we employ the Ledoit-Wolf (LDW) shrinkage method to estimate the high-dimensional FC metrics efficiently from fMRI data. We consider both supervised and unsupervised approaches for the graph embedded learning. The learned embeddings are then used as feature inputs for a deep fully-connected neural network (FCNN) to discriminate MDD from healthy controls. Evaluated on a resting-state fMRI MDD dataset with 43 subjects, results show that the proposed GAE-FCNN model significantly outperforms several state-of-the-art DNN methods for brain connectome classification, achieving accuracy of 72.50% using the LDW-FC metrics as node features. The graph embeddings of fMRI FC networks learned by the GAE also reveal apparent group differences between MDD and HC. Our new framework demonstrates feasibility of learning graph embeddings on brain networks to provide discriminative information for diagnosis of brain disorders.
Chronic Pain and Language: A Topic Modelling Approach to Personal Pain Descriptions
Sep 01, 2021
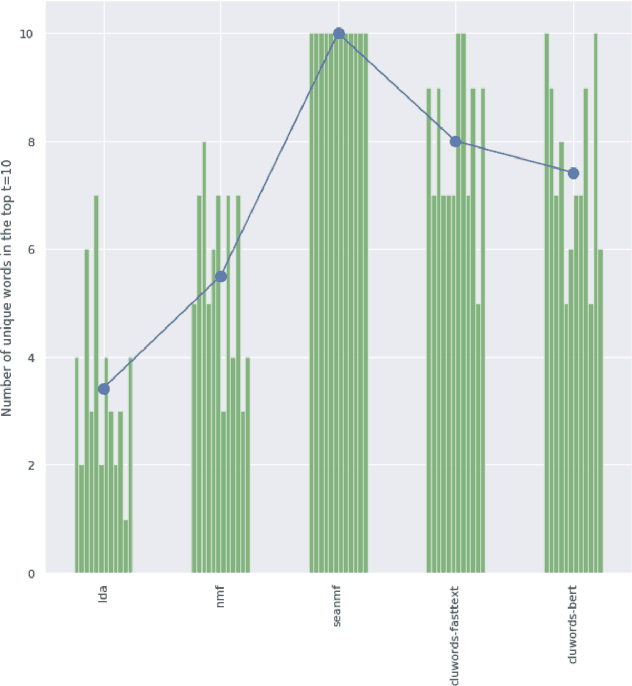
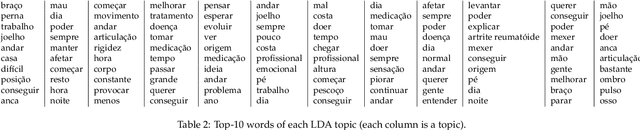
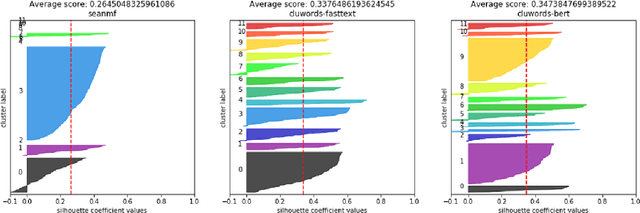
Chronic pain is recognized as a major health problem, with impacts not only at the economic, but also at the social, and individual levels. Being a private and subjective experience, it is impossible to externally and impartially experience, describe, and interpret chronic pain as a purely noxious stimulus that would directly point to a causal agent and facilitate its mitigation, contrary to acute pain, the assessment of which is usually straightforward. Verbal communication is, thus, key to convey relevant information to health professionals that would otherwise not be accessible to external entities, namely, intrinsic qualities about the painful experience and the patient. We propose and discuss a topic modelling approach to recognize patterns in verbal descriptions of chronic pain, and use these patterns to quantify and qualify experiences of pain. Our approaches allow for the extraction of novel insights on chronic pain experiences from the obtained topic models and latent spaces. We argue that our results are clinically relevant for the assessment and management of chronic pain.
Audio-Visual Speech Recognition is Worth 32$\times$32$\times$8 Voxels
Sep 20, 2021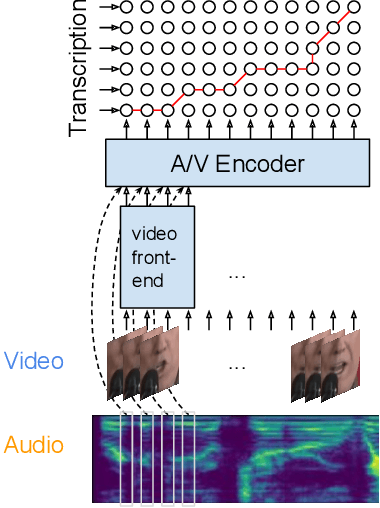

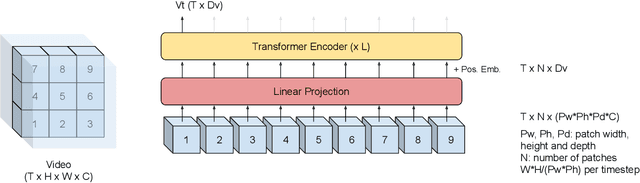
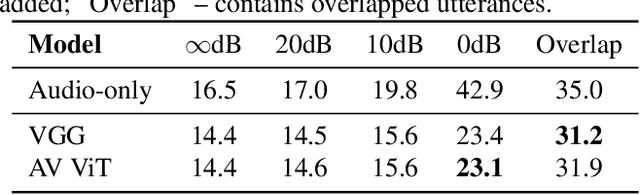
Audio-visual automatic speech recognition (AV-ASR) introduces the video modality into the speech recognition process, often by relying on information conveyed by the motion of the speaker's mouth. The use of the video signal requires extracting visual features, which are then combined with the acoustic features to build an AV-ASR system [1]. This is traditionally done with some form of 3D convolutional network (e.g. VGG) as widely used in the computer vision community. Recently, image transformers [2] have been introduced to extract visual features useful for image classification tasks. In this work, we propose to replace the 3D convolutional visual front-end with a video transformer front-end. We train our systems on a large-scale dataset composed of YouTube videos and evaluate performance on the publicly available LRS3-TED set, as well as on a large set of YouTube videos. On a lip-reading task, the transformer-based front-end shows superior performance compared to a strong convolutional baseline. On an AV-ASR task, the transformer front-end performs as well as (or better than) the convolutional baseline. Fine-tuning our model on the LRS3-TED training set matches previous state of the art. Thus, we experimentally show the viability of the convolution-free model for AV-ASR.