 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dynamic Gesture Recognition by Using CNNs and Star RGB: a Temporal Information Condensation
Apr 10, 2019


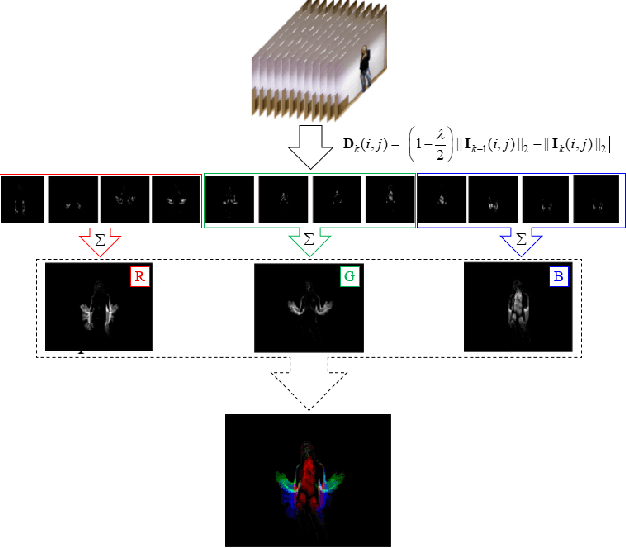
With the advance of technologies, machines are increasingly present in people's daily lives. Thus, there has been more and more effort for developing interfaces, such as dynamic gestures, that provide an intuitive way of interaction. Currently, the most common trend is to use multimodal data, as depth and skeleton information, to try to recognize dynamic gestures. However, the use of only color information would be more interesting, once RGB cameras are usually found in almost every public place, and could be used for gesture recognition without the need to install other equipment. The main problem with this approach is the difficulty of representing spatio-temporal information using just color. With this in mind, we propose a technique that we called Star RGB, capable of describing a videoclip containing a dynamic gesture as an RGB image. This image is then passed to a classifier formed by two Resnet CNN's, a soft-attention ensemble, and a multilayer perceptron, which returns the predicted class label that indicates to which type of gesture the input video belongs. Experiments were carried out using the Montalbano and GRIT datasets. On the Montalbano dataset, the proposed approach achieved an accuracy of 94.58%, this result reaches the state-of-the-art using this dataset, considering only color information. On the GRIT dataset, our proposal achieves more than 98% of accuracy, recall, precision, and F1-score, outperforming the reference approach in more than 6%.
Quantifying multivariate redundancy with maximum entropy decompositions of mutual information
Apr 03, 2018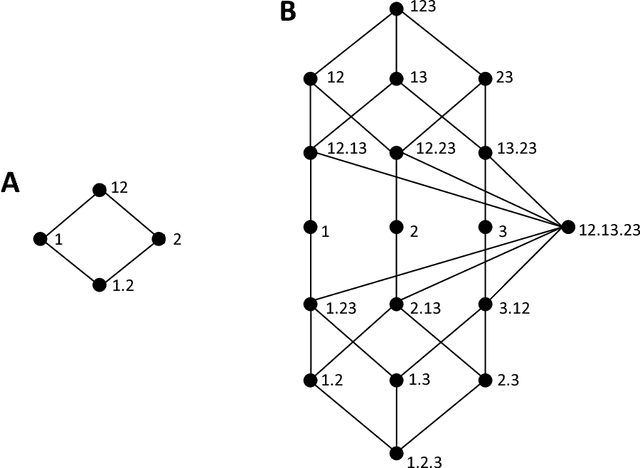

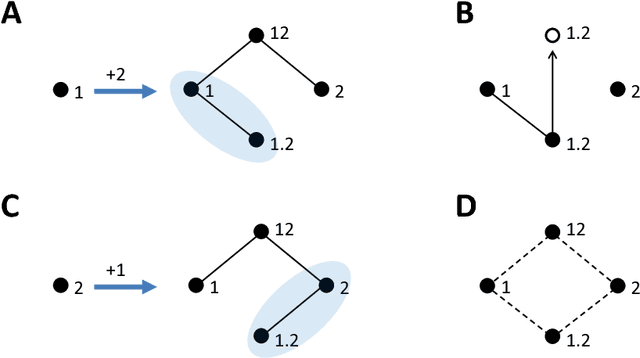
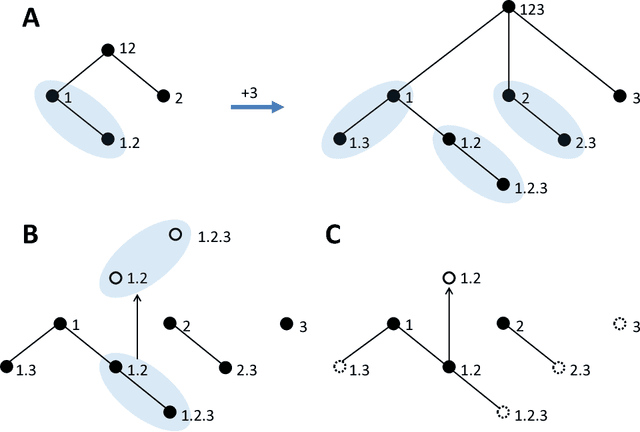
Williams and Beer (2010) proposed a nonnegative mutual information decomposition, based on the construction of redundancy lattices, which allows separating the information that a set of variables contains about a target variable into nonnegative components interpretable as the unique information of some variables not provided by others as well as redundant and synergistic components. However, the definition of multivariate measures of redundancy that comply with nonnegativity and conform to certain axioms that capture conceptually desirable properties of redundancy has proven to be elusive. We here present a procedure to determine nonnegative multivariate redundancy measures, within the maximum entropy framework. In particular, we generalize existing bivariate maximum entropy measures of redundancy and unique information, defining measures of the redundant information that a group of variables has about a target, and of the unique redundant information that a group of variables has about a target that is not redundant with information from another group. The two key ingredients for this approach are: First, the identification of a type of constraints on entropy maximization that allows isolating components of redundancy and unique redundancy by mirroring them to synergy components. Second, the construction of rooted tree-based decompositions of the mutual information, which conform to the axioms of the redundancy lattice by the local implementation at each tree node of binary unfoldings of the information using hierarchically related maximum entropy constraints. Altogether, the proposed measures quantify the different multivariate redundancy contributions of a nonnegative mutual information decomposition consistent with the redundancy lattice.
Detecting race and gender bias in visual representation of AI on web search engines
Jun 26, 2021
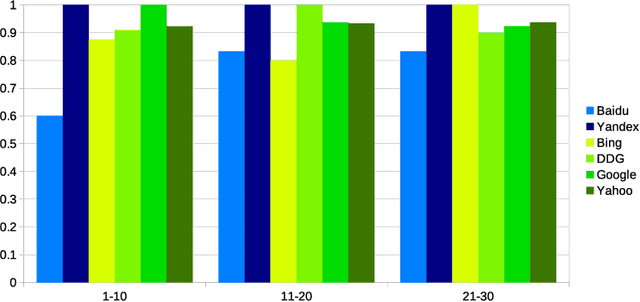
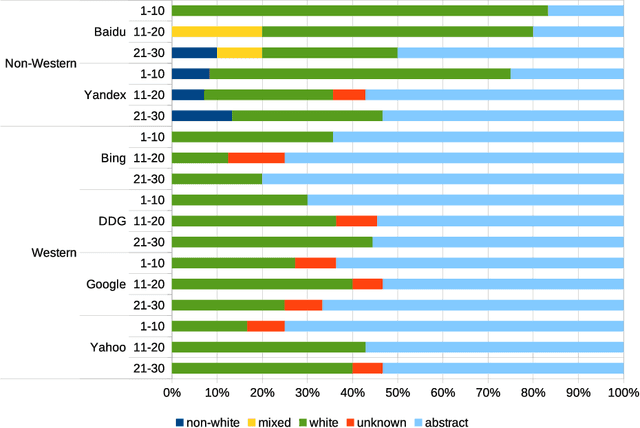
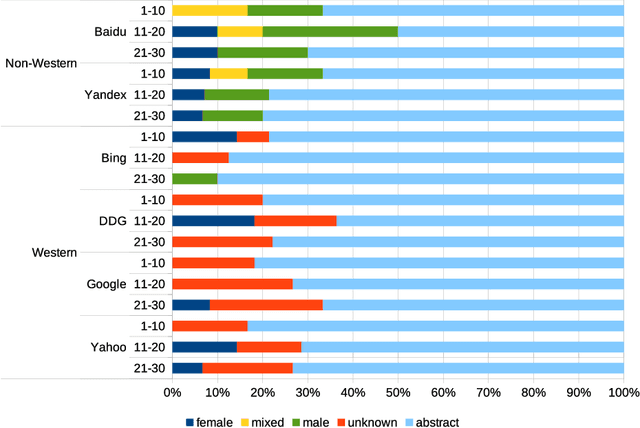
Web search engines influence perception of social reality by filtering and ranking information. However, their outputs are often subjected to bias that can lead to skewed representation of subjects such as professional occupations or gender. In our paper, we use a mixed-method approach to investigate presence of race and gender bias in representation of artificial intelligence (AI) in image search results coming from six different search engines. Our findings show that search engines prioritize anthropomorphic images of AI that portray it as white, whereas non-white images of AI are present only in non-Western search engines. By contrast, gender representation of AI is more diverse and less skewed towards a specific gender that can be attributed to higher awareness about gender bias in search outputs. Our observations indicate both the the need and the possibility for addressing bias in representation of societally relevant subjects, such as technological innovation, and emphasize the importance of designing new approaches for detecting bias in information retrieval systems.
* 16 pages, 3 figures
Multi-modal Entity Alignment in Hyperbolic Space
Jun 07, 2021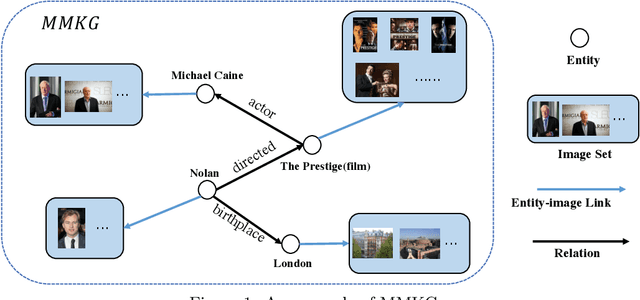
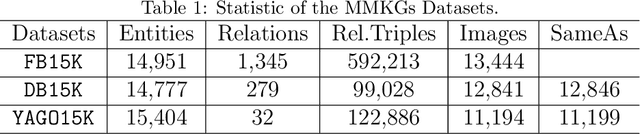
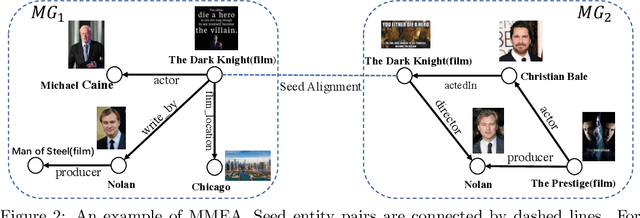
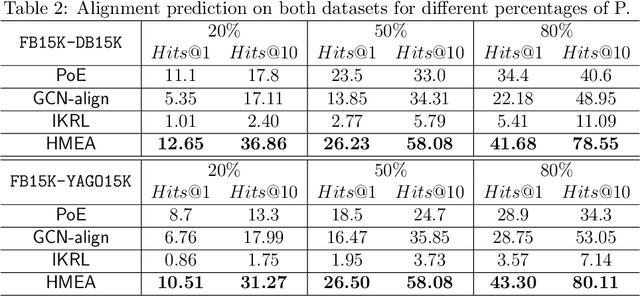
Many AI-related tasks involve the interactions of data in multiple modalities. It has been a new trend to merge multi-modal information into knowledge graph(KG), resulting in multi-modal knowledge graphs (MMKG). However, MMKGs usually suffer from low coverage and incompleteness. To mitigate this problem, a viable approach is to integrate complementary knowledge from other MMKGs. To this end, although existing entity alignment approaches could be adopted, they operate in the Euclidean space, and the resulting Euclidean entity representations can lead to large distortion of KG's hierarchical structure. Besides, the visual information has yet not been well exploited. In response to these issues, in this work, we propose a novel multi-modal entity alignment approach, Hyperbolic multi-modal entity alignment(HMEA), which extends the Euclidean representation to hyperboloid manifold. We first adopt the Hyperbolic Graph Convolutional Networks (HGCNs) to learn structural representations of entities. Regarding the visual information, we generate image embeddings using the densenet model, which are also projected into the hyperbolic space using HGCNs. Finally, we combine the structure and visual representations in the hyperbolic space and use the aggregated embeddings to predict potential alignment results. Extensive experiments and ablation studies demonstrate the effectiveness of our proposed model and its components.
Reinforcement Learning for Systematic FX Trading
Oct 10, 2021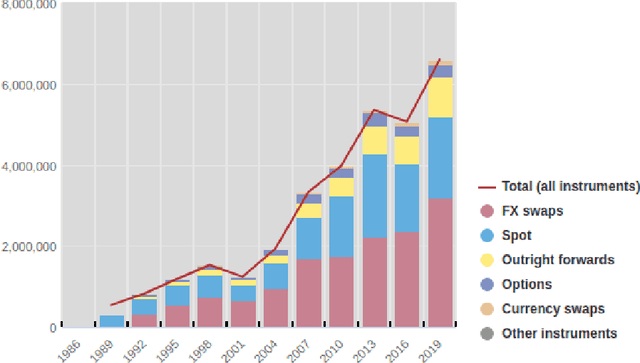
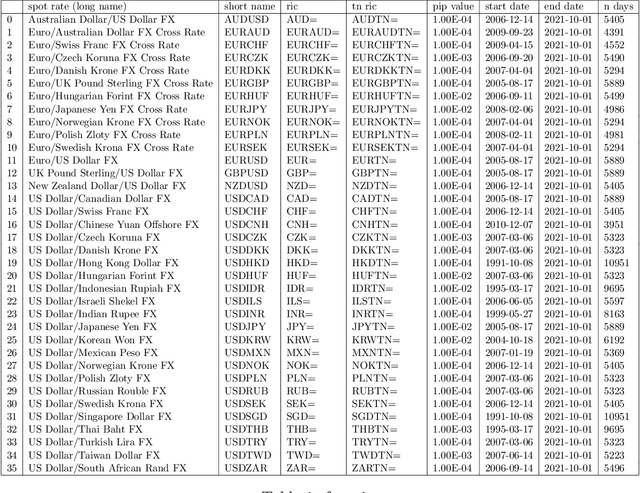
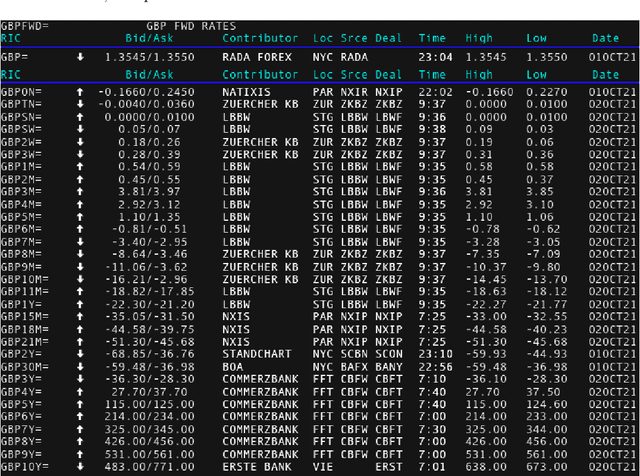
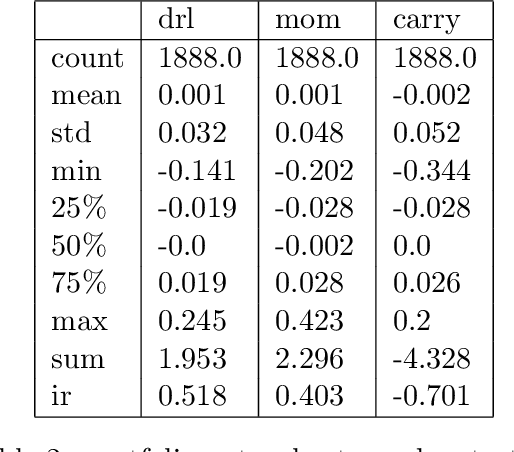
We conduct a detailed experiment on major cash fx pairs, accurately accounting for transaction and funding costs. These sources of profit and loss, including the price trends that occur in the currency markets, are made available to our recurrent reinforcement learner via a quadratic utility, which learns to target a position directly. We improve upon earlier work, by casting the problem of learning to target a risk position, in an online learning context. This online learning occurs sequentially in time, but also in the form of transfer learning. We transfer the output of radial basis function hidden processing units, whose means, covariances and overall size are determined by Gaussian mixture models, to the recurrent reinforcement learner and baseline momentum trader. Thus the intrinsic nature of the feature space is learnt and made available to the upstream models. The recurrent reinforcement learning trader achieves an annualised portfolio information ratio of 0.52 with compound return of 9.3%, net of execution and funding cost, over a 7 year test set. This is despite forcing the model to trade at the close of the trading day 5pm EST, when trading costs are statistically the most expensive. These results are comparable with the momentum baseline trader, reflecting the low interest differential environment since the the 2008 financial crisis, and very obvious currency trends since then. The recurrent reinforcement learner does nevertheless maintain an important advantage, in that the model's weights can be adapted to reflect the different sources of profit and loss variation. This is demonstrated visually by a USDRUB trading agent, who learns to target different positions, that reflect trading in the absence or presence of cost.
Multi-view Clustering via Deep Matrix Factorization and Partition Alignment
May 01, 2021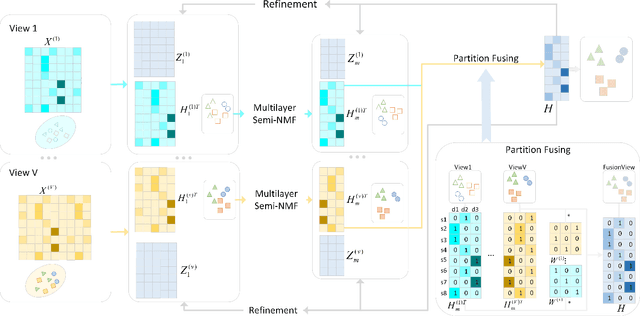
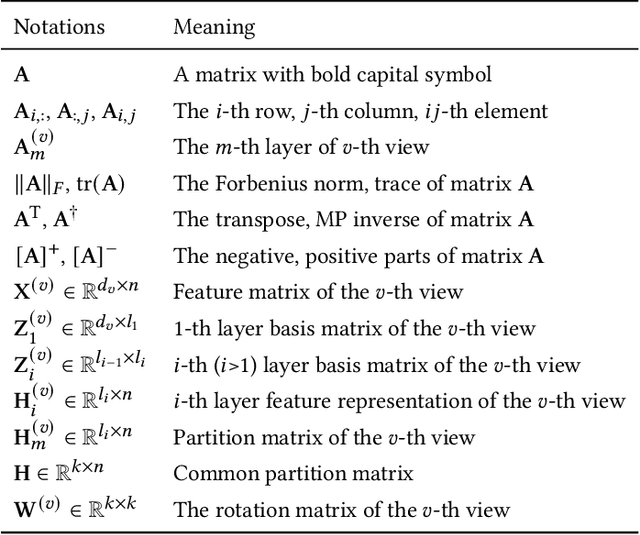
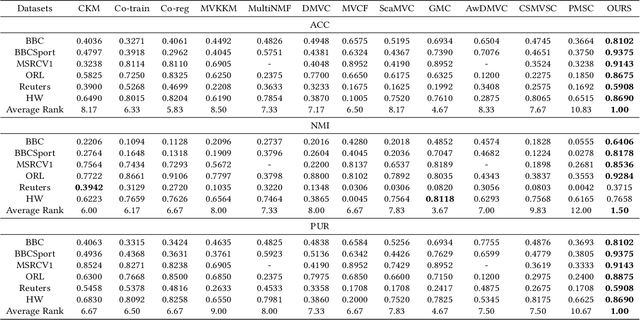
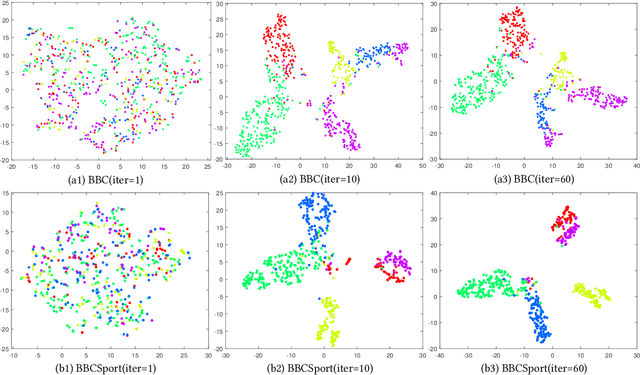
Multi-view clustering (MVC) has been extensively studied to collect multiple source information in recent years. One typical type of MVC methods is based on matrix factorization to effectively perform dimension reduction and clustering. However, the existing approaches can be further improved with following considerations: i) The current one-layer matrix factorization framework cannot fully exploit the useful data representations. ii) Most algorithms only focus on the shared information while ignore the view-specific structure leading to suboptimal solutions. iii) The partition level information has not been utilized in existing work. To solve the above issues, we propose a novel multi-view clustering algorithm via deep matrix decomposition and partition alignment. To be specific, the partition representations of each view are obtained through deep matrix decomposition, and then are jointly utilized with the optimal partition representation for fusing multi-view information. Finally, an alternating optimization algorithm is developed to solve the optimization problem with proven convergence. The comprehensive experimental results conducted on six benchmark multi-view datasets clearly demonstrates the effectiveness of the proposed algorithm against the SOTA methods.
Enhancing user creativity: Semantic measures for idea generation
Jun 18, 2021Human creativity generates novel ideas to solve real-world problems. This thereby grants us the power to transform the surrounding world and extend our human attributes beyond what is currently possible. Creative ideas are not just new and unexpected, but are also successful in providing solutions that are useful, efficient and valuable. Thus, creativity optimizes the use of available resources and increases wealth. The origin of human creativity, however, is poorly understood, and semantic measures that could predict the success of generated ideas are currently unknown. Here, we analyze a dataset of design problem-solving conversations in real-world settings by using 49 semantic measures based on WordNet 3.1 and demonstrate that a divergence of semantic similarity, an increased information content, and a decreased polysemy predict the success of generated ideas. The first feedback from clients also enhances information content and leads to a divergence of successful ideas in creative problem solving. These results advance cognitive science by identifying real-world processes in human problem solving that are relevant to the success of produced solutions and provide tools for real-time monitoring of problem solving, student training and skill acquisition. A selected subset of information content (IC S\'anchez-Batet) and semantic similarity (Lin/S\'anchez-Batet) measures, which are both statistically powerful and computationally fast, could support the development of technologies for computer-assisted enhancements of human creativity or for the implementation of creativity in machines endowed with general artificial intelligence.
* 42 pages, 10 figures, 2 tables
Balancing detectability and performance of attacks on the control channel of Markov Decision Processes
Sep 15, 2021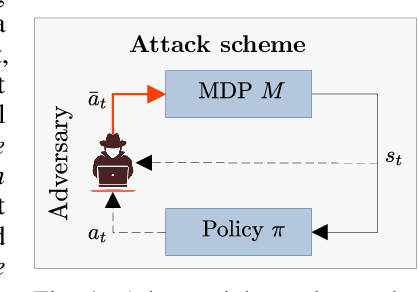
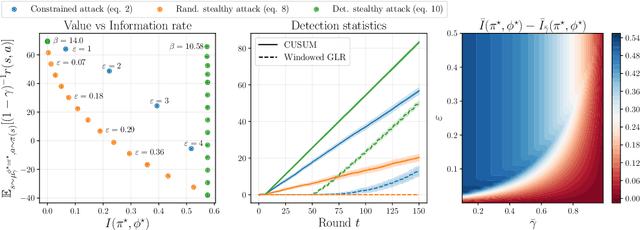
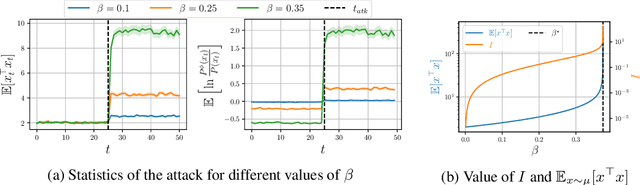
We investigate the problem of designing optimal stealthy poisoning attacks on the control channel of Markov decision processes (MDPs). This research is motivated by the recent interest of the research community for adversarial and poisoning attacks applied to MDPs, and reinforcement learning (RL) methods. The policies resulting from these methods have been shown to be vulnerable to attacks perturbing the observations of the decision-maker. In such an attack, drawing inspiration from adversarial examples used in supervised learning, the amplitude of the adversarial perturbation is limited according to some norm, with the hope that this constraint will make the attack imperceptible. However, such constraints do not grant any level of undetectability and do not take into account the dynamic nature of the underlying Markov process. In this paper, we propose a new attack formulation, based on information-theoretical quantities, that considers the objective of minimizing the detectability of the attack as well as the performance of the controlled process. We analyze the trade-off between the efficiency of the attack and its detectability. We conclude with examples and numerical simulations illustrating this trade-off.
Open source tools for management and archiving of digital microscopy data to allow integration with patient pathology and treatment information
Aug 16, 2020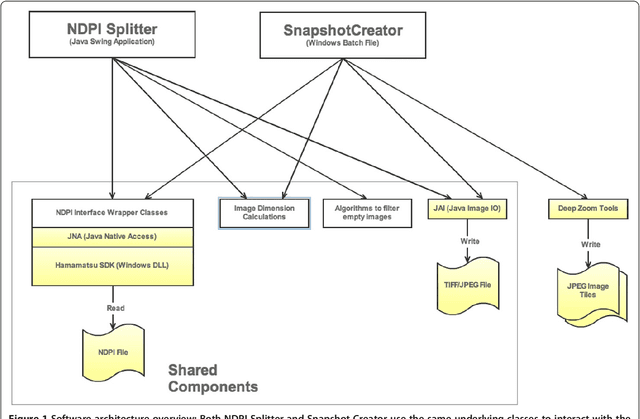
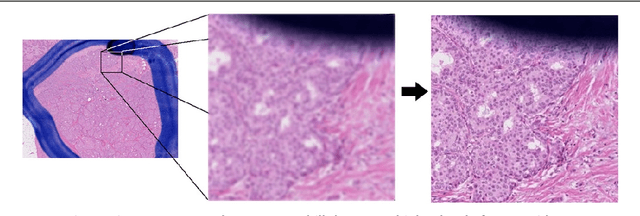
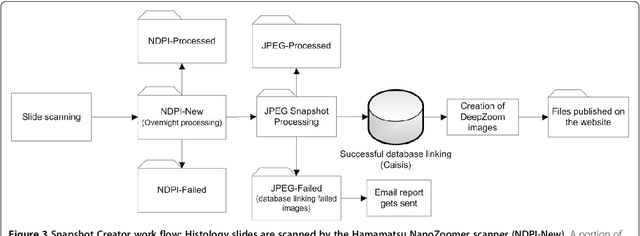
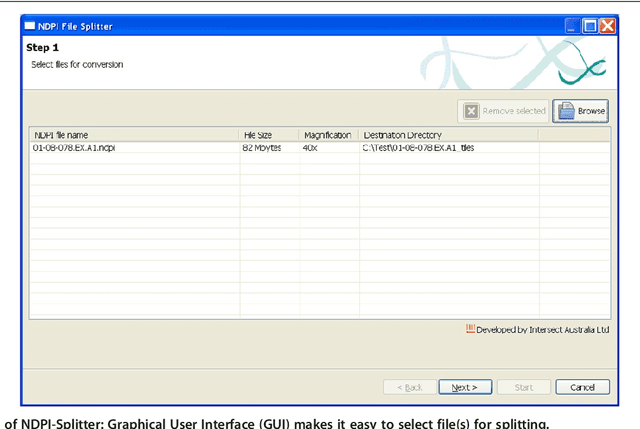
Virtual microscopy includes digitisation of histology slides and the use of computer technologies for complex investigation of diseases such as cancer. However, automated image analysis, or website publishing of such digital images, is hampered by their large file sizes. We have developed two Java based open source tools: Snapshot Creator and NDPI-Splitter. Snapshot Creator converts a portion of a large digital slide into a desired quality JPEG image. The image is linked to the patients clinical and treatment information in a customised open source cancer data management software (Caisis) in use at the Australian Breast Cancer Tissue Bank (ABCTB) and then published on the ABCTB website www.abctb.org.au using Deep Zoom open source technology. Using the ABCTB online search engine, digital images can be searched by defining various criteria such as cancer type, or biomarkers expressed. NDPI-Splitter splits a large image file into smaller sections of TIFF images so that they can be easily analysed by image analysis software such as Metamorph or Matlab. NDPI-Splitter also has the capacity to filter out empty images. Snapshot Creator and NDPI-Splitter are novel open source Java tools. They convert digital slides into files of smaller size for further processing. In conjunction with other open source tools such as Deep Zoom and Caisis, this suite of tools is used for the management and archiving of digital microscopy images, enabling digitised images to be explored and zoomed online. Our online image repository also has the capacity to be used as a teaching resource. These tools also enable large files to be sectioned for image analysis.
CADA: Multi-scale Collaborative Adversarial Domain Adaptation for Unsupervised Optic Disc and Cup Segmentation
Oct 05, 2021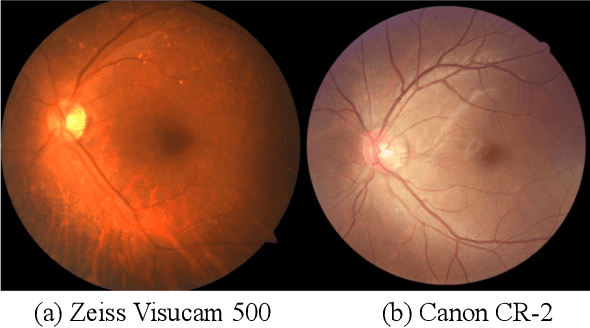

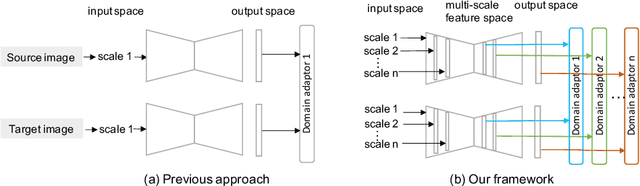
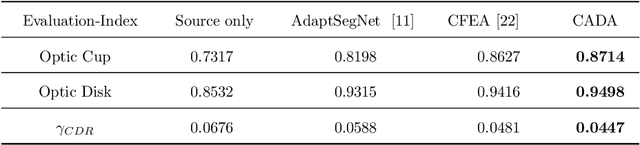
The diversity of retinal imaging devices poses a significant challenge: domain shift, which leads to performance degradation when applying the deep learning models trained on one domain to new testing domains. In this paper, we propose a multi-scale input along with multiple domain adaptors applied hierarchically in both feature and output spaces. The proposed training strategy and novel unsupervised domain adaptation framework, called Collaborative Adversarial Domain Adaptation (CADA), can effectively overcome the challenge. Multi-scale inputs can reduce the information loss due to the pooling layers used in the network for feature extraction, while our proposed CADA is an interactive paradigm that presents an exquisite collaborative adaptation through both adversarial learning and ensembling weights at different network layers. In particular, to produce a better prediction for the unlabeled target domain data, we simultaneously achieve domain invariance and model generalizability via adversarial learning at multi-scale outputs from different levels of network layers and maintaining an exponential moving average (EMA) of the historical weights during training. Without annotating any sample from the target domain, multiple adversarial losses in encoder and decoder layers guide the extraction of domain-invariant features to confuse the domain classifier. Meanwhile, the ensembling of weights via EMA reduces the uncertainty of adapting multiple discriminator learning. Comprehensive experimental results demonstrate that our CADA model incorporating multi-scale input training can overcome performance degradation and outperform state-of-the-art domain adaptation methods in segmenting retinal optic disc and cup from fundus images stemming from the REFUGE, Drishti-GS, and Rim-One-r3 datasets.