 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multimodal Entity Linking for Tweets
Apr 07, 2021


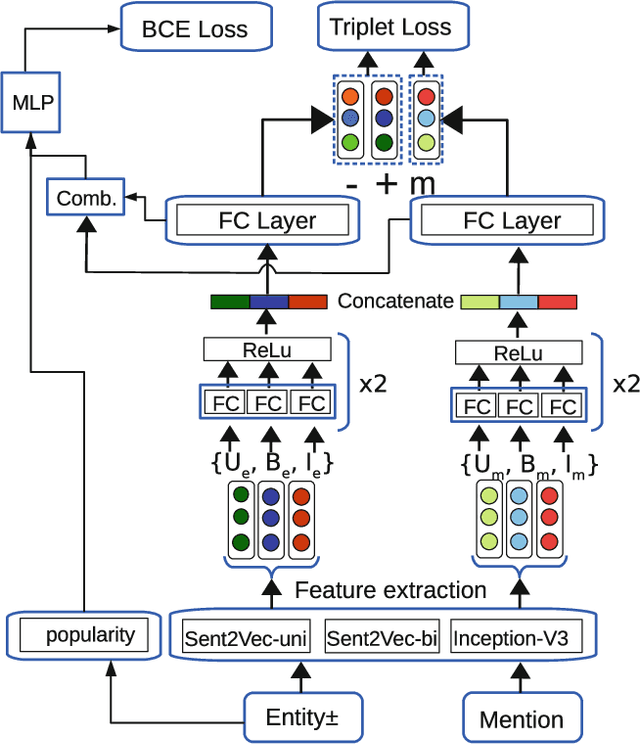

In many information extraction applications, entity linking (EL) has emerged as a crucial task that allows leveraging information about named entities from a knowledge base. In this paper, we address the task of multimodal entity linking (MEL), an emerging research field in which textual and visual information is used to map an ambiguous mention to an entity in a knowledge base (KB). First, we propose a method for building a fully annotated Twitter dataset for MEL, where entities are defined in a Twitter KB. Then, we propose a model for jointly learning a representation of both mentions and entities from their textual and visual contexts. We demonstrate the effectiveness of the proposed model by evaluating it on the proposed dataset and highlight the importance of leveraging visual information when it is available.
Temporal Knowledge Consistency for Unsupervised Visual Representation Learning
Aug 24, 2021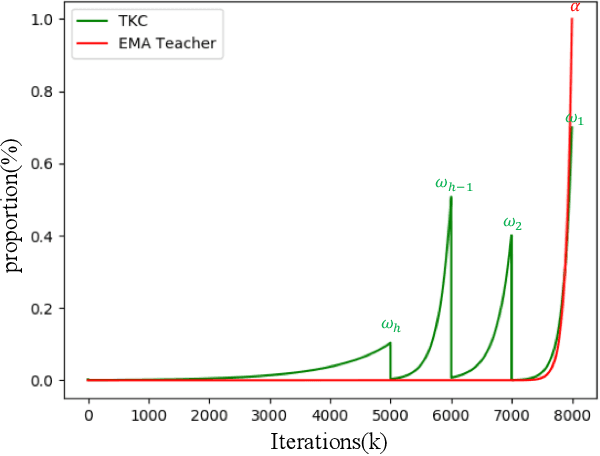
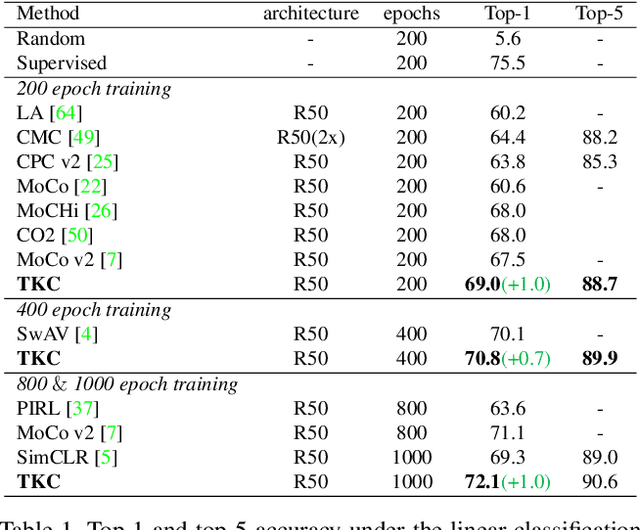
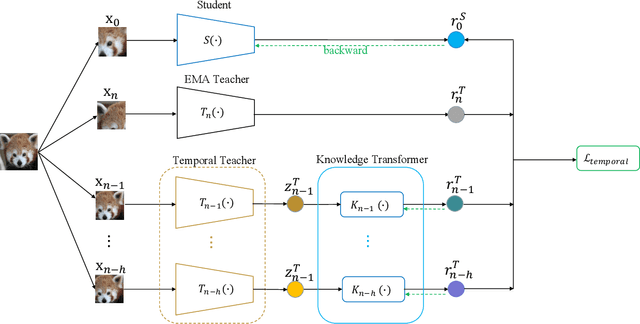

The instance discrimination paradigm has become dominant in unsupervised learning. It always adopts a teacher-student framework, in which the teacher provides embedded knowledge as a supervision signal for the student. The student learns meaningful representations by enforcing instance spatial consistency with the views from the teacher. However, the outputs of the teacher can vary dramatically on the same instance during different training stages, introducing unexpected noise and leading to catastrophic forgetting caused by inconsistent objectives. In this paper, we first integrate instance temporal consistency into current instance discrimination paradigms, and propose a novel and strong algorithm named Temporal Knowledge Consistency (TKC). Specifically, our TKC dynamically ensembles the knowledge of temporal teachers and adaptively selects useful information according to its importance to learning instance temporal consistency. Experimental result shows that TKC can learn better visual representations on both ResNet and AlexNet on linear evaluation protocol while transfer well to downstream tasks. All experiments suggest the good effectiveness and generalization of our method.
* To appear in ICCV 2021
Joint Multi-User Communication and Sensing Exploiting Both Signal and Environment Sparsity
Sep 06, 2021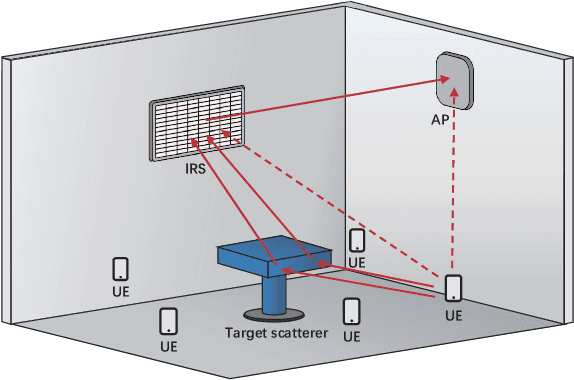
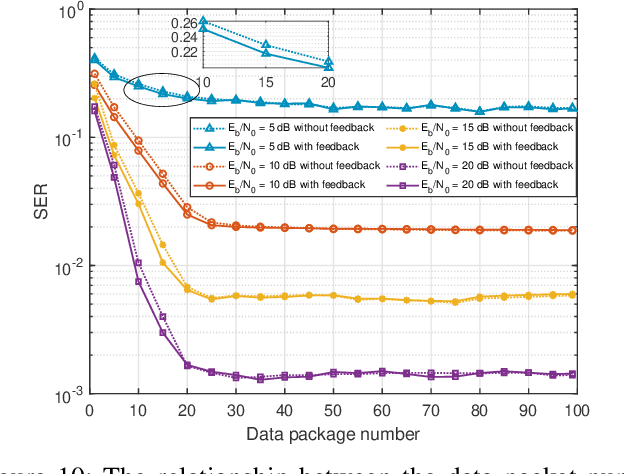
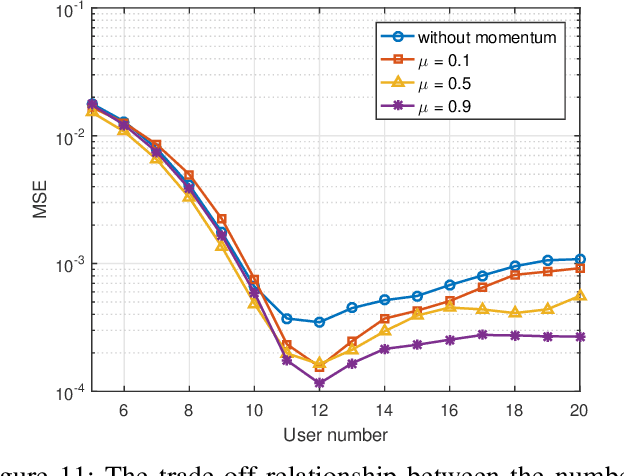
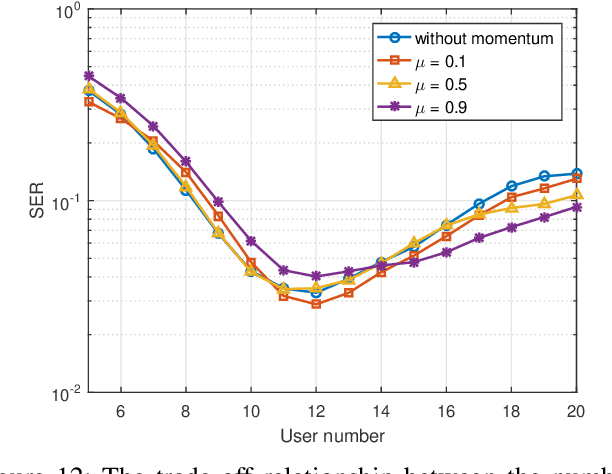
As a potential technology feature for 6G wireless networks, the idea of sensing-communication integration requires the system not only to complete reliable multi-user communication but also to achieve accurate environment sensing. In this paper, we consider such a joint communication and sensing (JCAS) scenario, in which multiple users use the sparse code multiple access (SCMA) scheme to communicate with the wireless access point (AP). Part of the user signals are scattered by the environment object and reflected by an intelligent reflective surface (IRS) before they arrive at the AP. We exploit the sparsity of both the structured user signals and the unstructured environment and propose an iterative and incremental joint multi-user communication and environment sensing scheme, in which the two processes, i.e., multi-user information detection and environment object detection, interweave with each other thanks to their intrinsic mutual dependence. The proposed algorithm is sliding-window based and also graph based, which can keep on sensing the environment as long as there are illuminating user signals. The trade-off relationship between the key system parameters is analyzed, and the simulation result validates the convergence and effectiveness of the proposed algorithm.
* Paper accepted for publication on IEEE Journal of Selected Topics in Signal Processing
On-Demand and Lightweight Knowledge Graph Generation -- a Demonstration with DBpedia
Jul 02, 2021

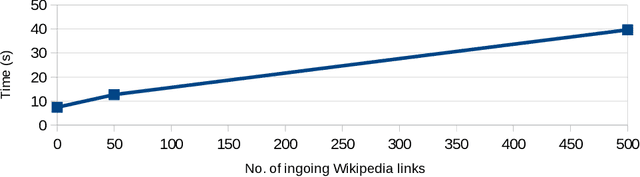
Modern large-scale knowledge graphs, such as DBpedia, are datasets which require large computational resources to serve and process. Moreover, they often have longer release cycles, which leads to outdated information in those graphs. In this paper, we present DBpedia on Demand -- a system which serves DBpedia resources on demand without the need to materialize and store the entire graph, and which even provides limited querying functionality.
Robust Deep Multi-modal Learning Based on Gated Information Fusion Network
Nov 02, 2018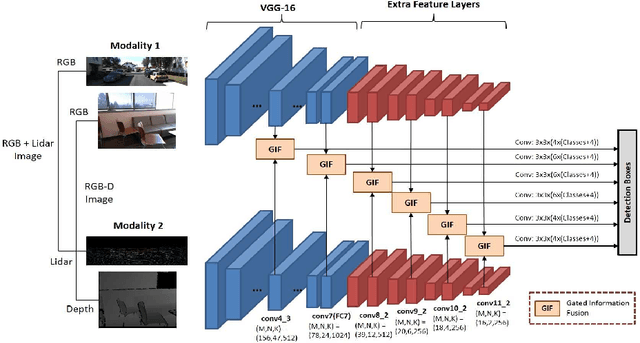

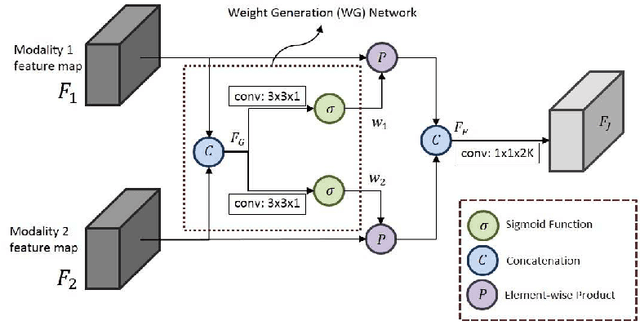

The goal of multi-modal learning is to use complimentary information on the relevant task provided by the multiple modalities to achieve reliable and robust performance. Recently, deep learning has led significant improvement in multi-modal learning by allowing for the information fusion in the intermediate feature levels. This paper addresses a problem of designing robust deep multi-modal learning architecture in the presence of imperfect modalities. We introduce deep fusion architecture for object detection which processes each modality using the separate convolutional neural network (CNN) and constructs the joint feature map by combining the intermediate features from the CNNs. In order to facilitate the robustness to the degraded modalities, we employ the gated information fusion (GIF) network which weights the contribution from each modality according to the input feature maps to be fused. The weights are determined through the convolutional layers followed by a sigmoid function and trained along with the information fusion network in an end-to-end fashion. Our experiments show that the proposed GIF network offers the additional architectural flexibility to achieve robust performance in handling some degraded modalities, and show a significant performance improvement based on Single Shot Detector (SSD) for KITTI dataset using the proposed fusion network and data augmentation schemes.
Review of Visual Saliency Detection with Comprehensive Information
Sep 14, 2018



Visual saliency detection model simulates the human visual system to perceive the scene, and has been widely used in many vision tasks. With the acquisition technology development, more comprehensive information, such as depth cue, inter-image correspondence, or temporal relationship, is available to extend image saliency detection to RGBD saliency detection, co-saliency detection, or video saliency detection. RGBD saliency detection model focuses on extracting the salient regions from RGBD images by combining the depth information. Co-saliency detection model introduces the inter-image correspondence constraint to discover the common salient object in an image group. The goal of video saliency detection model is to locate the motion-related salient object in video sequences, which considers the motion cue and spatiotemporal constraint jointly. In this paper, we review different types of saliency detection algorithms, summarize the important issues of the existing methods, and discuss the existent problems and future works. Moreover, the evaluation datasets and quantitative measurements are briefly introduced, and the experimental analysis and discission are conducted to provide a holistic overview of different saliency detection methods.
Frustratingly Easy Transferability Estimation
Jun 17, 2021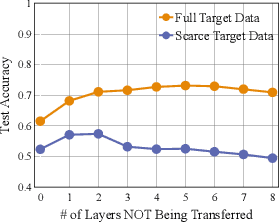
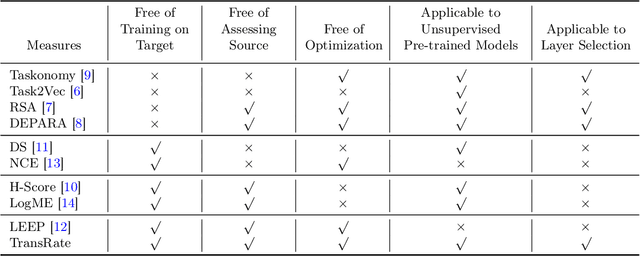
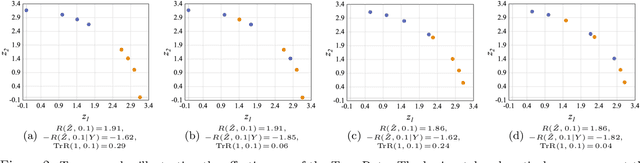
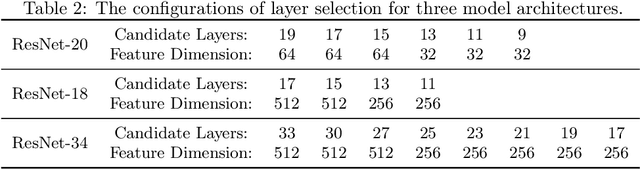
Transferability estimation has been an essential tool in selecting a pre-trained model and the layers of it to transfer, so as to maximize the performance on a target task and prevent negative transfer. Existing estimation algorithms either require intensive training on target tasks or have difficulties in evaluating the transferability between layers. We propose a simple, efficient, and effective transferability measure named TransRate. With single pass through the target data, TransRate measures the transferability as the mutual information between the features of target examples extracted by a pre-trained model and labels of them. We overcome the challenge of efficient mutual information estimation by resorting to coding rate that serves as an effective alternative to entropy. TransRate is theoretically analyzed to be closely related to the performance after transfer learning. Despite its extraordinary simplicity in 10 lines of codes, TransRate performs remarkably well in extensive evaluations on 22 pre-trained models and 16 downstream tasks.
Energy Minimization for IRS-aided WPCNs with Non-linear Energy Harvesting Model
Aug 31, 2021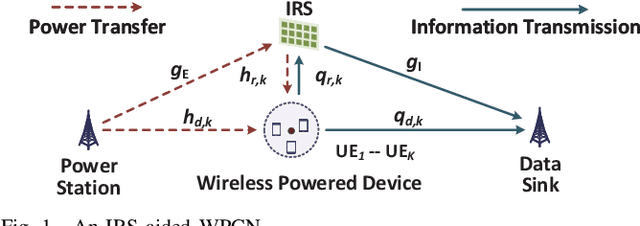
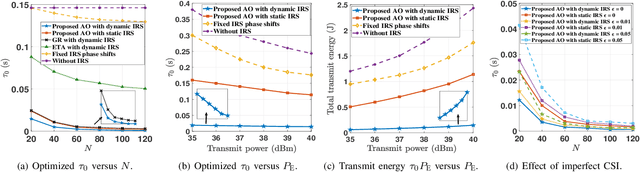
This paper considers an intelligent reflecting surface(IRS)-aided wireless powered communication network (WPCN), where devices first harvest energy from a power station (PS) in the downlink (DL) and then transmit information using non-orthogonal multiple access (NOMA) to a data sink in the uplink (UL). However, most existing works on WPCNs adopted the simplified linear energy-harvesting model and also cannot guarantee strict user quality-of-service requirements. To address these issues, we aim to minimize the total transmit energy consumption at the PS by jointly optimizing the resource allocation and IRS phase shifts over time, subject to the minimum throughput requirements of all devices. The formulated problem is decomposed into two subproblems, and solved iteratively in an alternative manner by employing difference of convex functions programming, successive convex approximation, and penalty-based algorithm. Numerical results demonstrate the significant performance gains achieved by the proposed algorithm over benchmark schemes and reveal the benefits of integrating IRS into WPCNs. In particular, employing different IRS phase shifts over UL and DL outperforms the case with static IRS beamforming.
CAN3D: Fast 3D Medical Image Segmentation via Compact Context Aggregation
Sep 22, 2021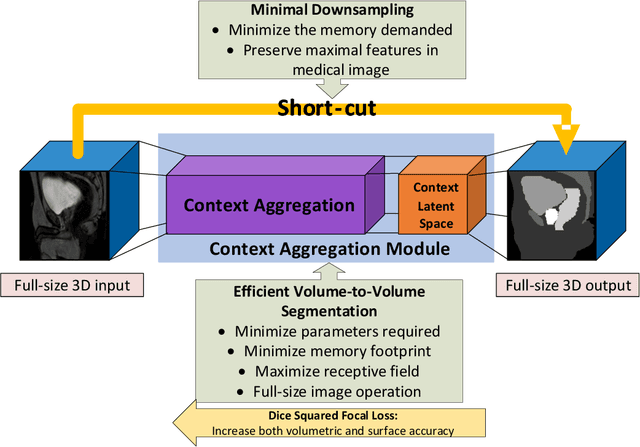

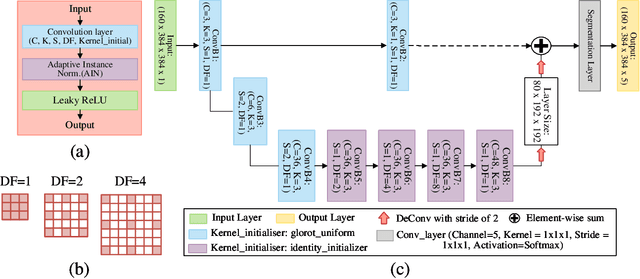
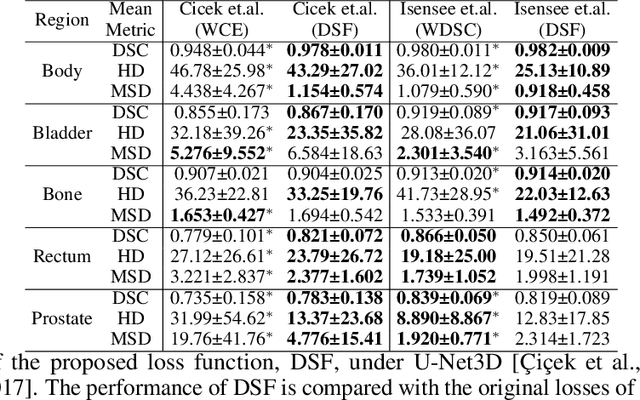
Direct automatic segmentation of objects from 3D medical imaging, such as magnetic resonance (MR) imaging, is challenging as it often involves accurately identifying a number of individual objects with complex geometries within a large volume under investigation. To address these challenges, most deep learning approaches typically enhance their learning capability by substantially increasing the complexity or the number of trainable parameters within their models. Consequently, these models generally require long inference time on standard workstations operating clinical MR systems and are restricted to high-performance computing hardware due to their large memory requirement. Further, to fit 3D dataset through these large models using limited computer memory, trade-off techniques such as patch-wise training are often used which sacrifice the fine-scale geometric information from input images which could be clinically significant for diagnostic purposes. To address these challenges, we present a compact convolutional neural network with a shallow memory footprint to efficiently reduce the number of model parameters required for state-of-art performance. This is critical for practical employment as most clinical environments only have low-end hardware with limited computing power and memory. The proposed network can maintain data integrity by directly processing large full-size 3D input volumes with no patches required and significantly reduces the computational time required for both training and inference. We also propose a novel loss function with extra shape constraint to improve the accuracy for imbalanced classes in 3D MR images.
Partial Gradient Optimal Thresholding Algorithms for a Class of Sparse Optimization Problems
Jul 19, 2021
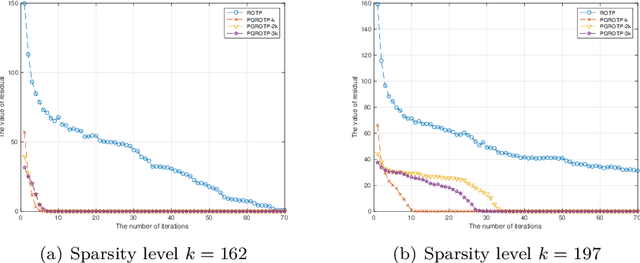
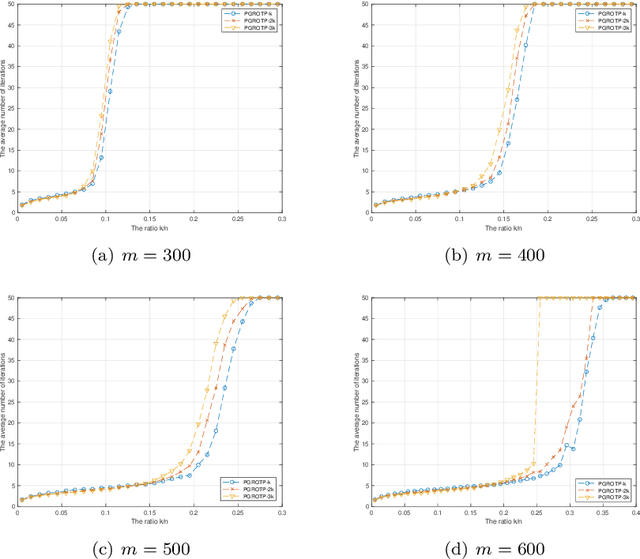
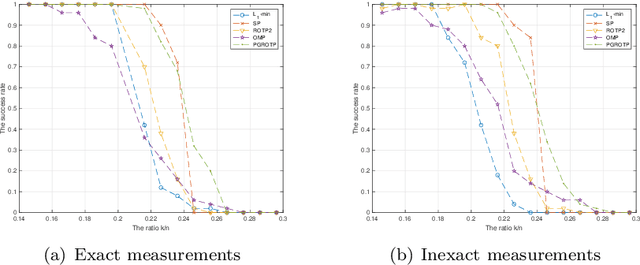
The optimization problems with a sparsity constraint is a class of important global optimization problems. A typical type of thresholding algorithms for solving such a problem adopts the traditional full steepest descent direction or Newton-like direction as a search direction to generate an iterate on which a certain thresholding is performed. Traditional hard thresholding discards a large part of a vector when the vector is dense. Thus a large part of important information contained in a dense vector has been lost in such a thresholding process. Recent study [Zhao, SIAM J Optim, 30(1), pp. 31-55, 2020] shows that the hard thresholding should be applied to a compressible vector instead of a dense vector to avoid a big loss of information. On the other hand, the optimal $k$-thresholding as a novel thresholding technique may overcome the intrinsic drawback of hard thresholding, and performs thresholding and objective function minimization simultaneously. This motivates us to propose the so-called partial gradient optimal thresholding method in this paper, which is an integration of the partial gradient and the optimal $k$-thresholding technique. The solution error bound and convergence for the proposed algorithms have been established in this paper under suitable conditions. Application of our results to the sparse optimization problems arising from signal recovery is also discussed. Experiment results from synthetic data indicate that the proposed algorithm called PGROTP is efficient and comparable to several existing algorithms.