 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Joint Intent Detection and Slot Filling via Higher-order Attention
Sep 22, 2021

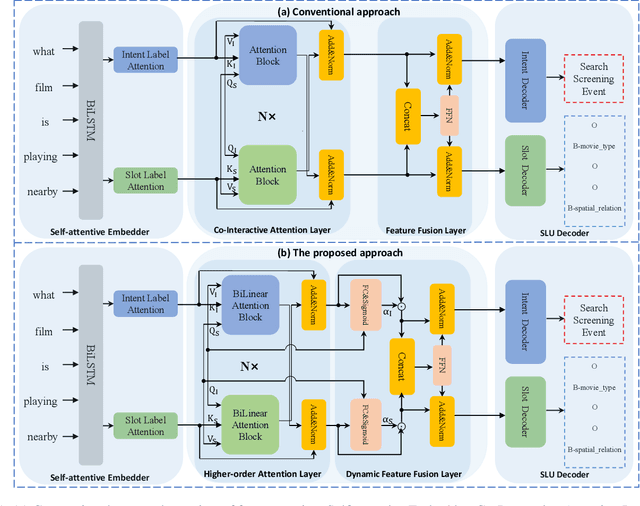
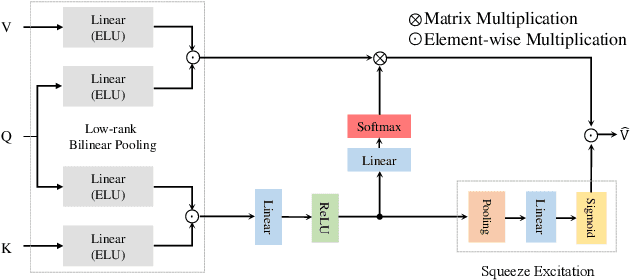
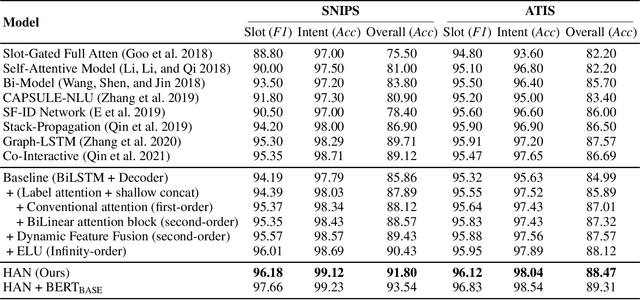
Intent detection (ID) and Slot filling (SF) are two major tasks in spoken language understanding (SLU). Recently, attention mechanism has been shown to be effective in jointly optimizing these two tasks in an interactive manner. However, latest attention-based works concentrated only on the first-order attention design, while ignoring the exploration of higher-order attention mechanisms. In this paper, we propose a BiLinear attention block, which leverages bilinear pooling to simultaneously exploit both the contextual and channel-wise bilinear attention distributions to capture the second-order interactions between the input intent or slot features. Higher and even infinity order interactions are built by stacking numerous blocks and assigning Exponential Linear Unit (ELU) to blocks. Before the decoding stage, we introduce the Dynamic Feature Fusion Layer to implicitly fuse intent and slot information in a more effective way. Technically, instead of simply concatenating intent and slot features, we first compute two correlation matrices to weight on two features. Furthermore, we present Higher-order Attention Network for the SLU tasks. Experiments on two benchmark datasets show that our approach yields improvements compared with the state-of-the-art approach. We also provide discussion to demonstrate the effectiveness of the proposed approach.
Learning to Discriminate Noises for Incorporating External Information in Neural Machine Translation
Oct 24, 2018
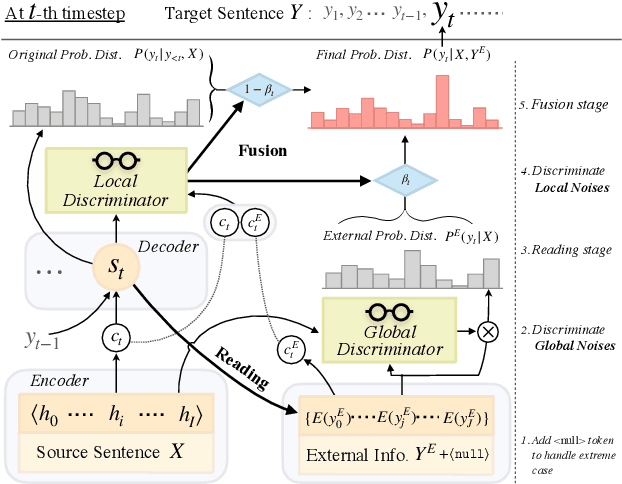
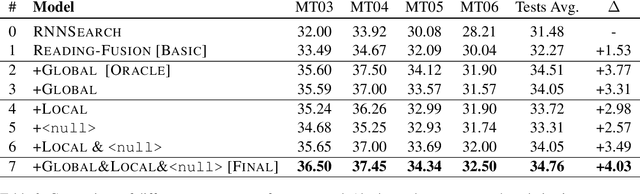
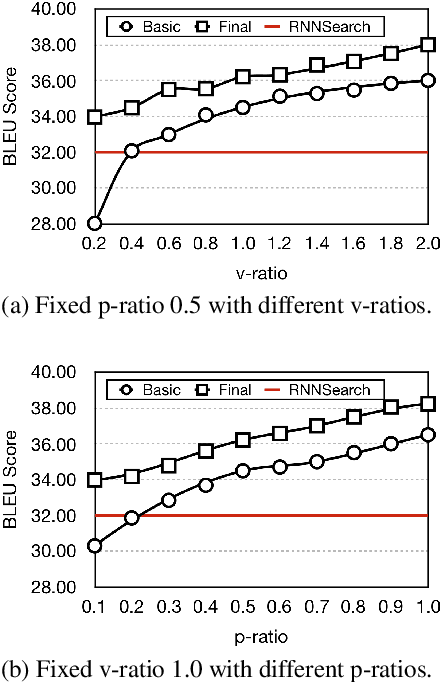
Previous studies show that incorporating external information could improve the translation quality of Neural Machine Translation (NMT) systems. However, these methods will inevitably suffer from the noises in the external information, which may severely reduce the benefit. We argue that there exist two kinds of noise in this external information, i.e. global noise and local noise, which affect the translation of the whole sentence and for some specific words, respectively. To tackle the problem, this study pays special attention to the discrimination of noises during the incorporation. We propose a general framework with two separate word discriminators for the global and local noises, respectively, so that the external information could be better leveraged. Empirical evaluation shows that being trained by the dataset sampled from the original parallel corpus without any extra labeled data or annotation, our model could make better use of external information in different real-world scenarios, language pairs, and neural architectures, leading to significant improvements over the original translation.
A Sociotechnical View of Algorithmic Fairness
Sep 27, 2021
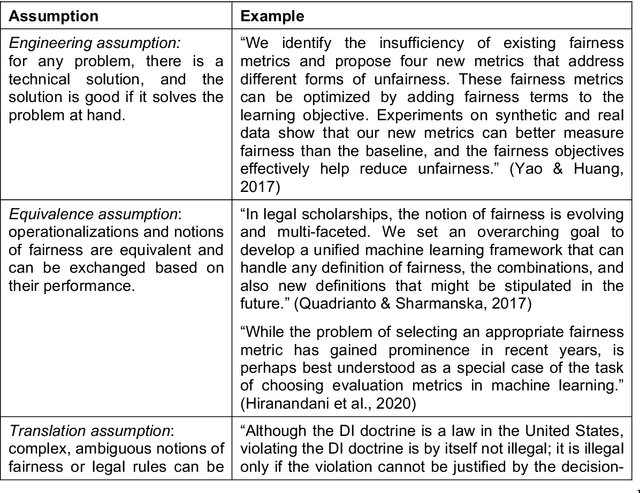
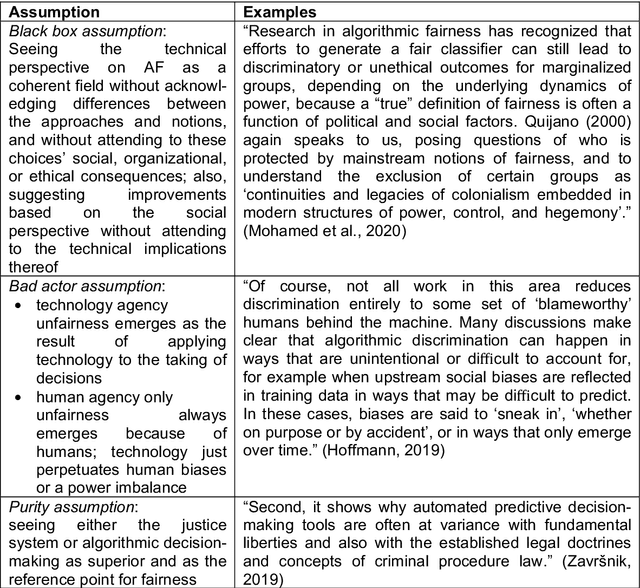
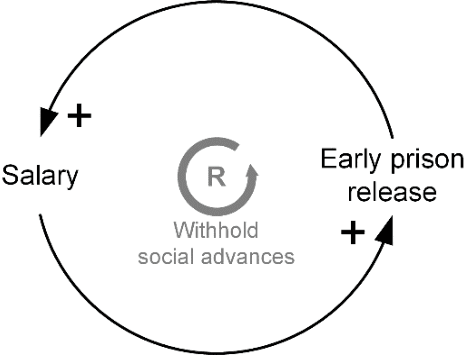
Algorithmic fairness has been framed as a newly emerging technology that mitigates systemic discrimination in automated decision-making, providing opportunities to improve fairness in information systems (IS). However, based on a state-of-the-art literature review, we argue that fairness is an inherently social concept and that technologies for algorithmic fairness should therefore be approached through a sociotechnical lens. We advance the discourse on algorithmic fairness as a sociotechnical phenomenon. Our research objective is to embed AF in the sociotechnical view of IS. Specifically, we elaborate on why outcomes of a system that uses algorithmic means to assure fairness depends on mutual influences between technical and social structures. This perspective can generate new insights that integrate knowledge from both technical fields and social studies. Further, it spurs new directions for IS debates. We contribute as follows: First, we problematize fundamental assumptions in the current discourse on algorithmic fairness based on a systematic analysis of 310 articles. Second, we respond to these assumptions by theorizing algorithmic fairness as a sociotechnical construct. Third, we propose directions for IS researchers to enhance their impacts by pursuing a unique understanding of sociotechnical algorithmic fairness. We call for and undertake a holistic approach to AF. A sociotechnical perspective on algorithmic fairness can yield holistic solutions to systemic biases and discrimination.
Ontology-driven Knowledge Graph for Android Malware
Sep 03, 2021
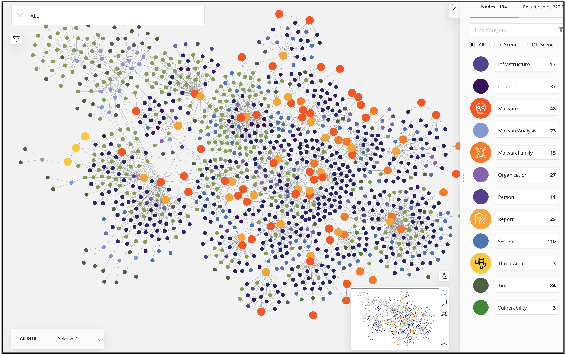
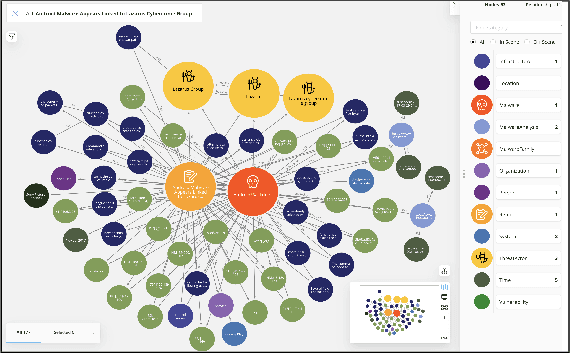
We present MalONT2.0 -- an ontology for malware threat intelligence \cite{rastogi2020malont}. New classes (attack patterns, infrastructural resources to enable attacks, malware analysis to incorporate static analysis, and dynamic analysis of binaries) and relations have been added following a broadened scope of core competency questions. MalONT2.0 allows researchers to extensively capture all requisite classes and relations that gather semantic and syntactic characteristics of an android malware attack. This ontology forms the basis for the malware threat intelligence knowledge graph, MalKG, which we exemplify using three different, non-overlapping demonstrations. Malware features have been extracted from CTI reports on android threat intelligence shared on the Internet and written in the form of unstructured text. Some of these sources are blogs, threat intelligence reports, tweets, and news articles. The smallest unit of information that captures malware features is written as triples comprising head and tail entities, each connected with a relation. In the poster and demonstration, we discuss MalONT2.0, MalKG, as well as the dynamically growing knowledge graph, TINKER.
ReFormer: The Relational Transformer for Image Captioning
Jul 29, 2021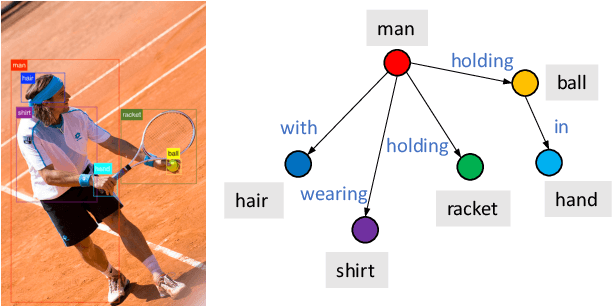
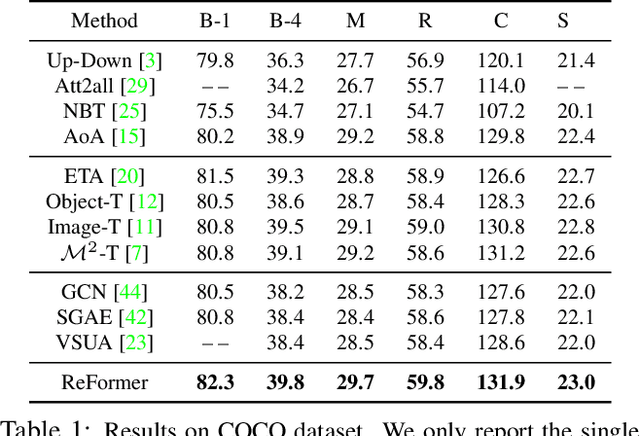
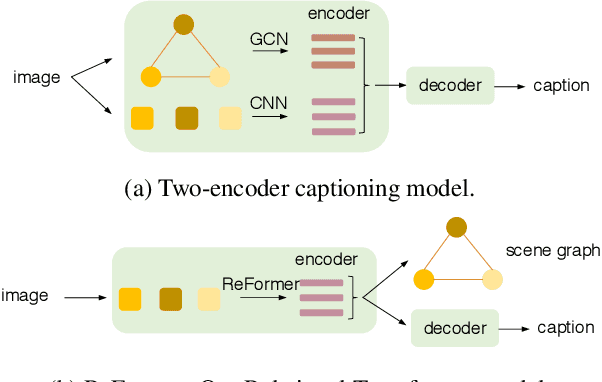
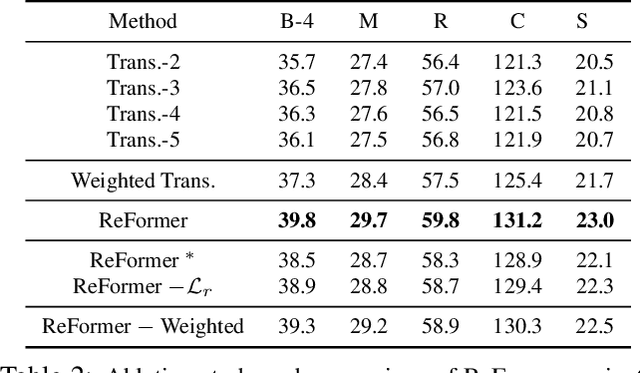
Image captioning is shown to be able to achieve a better performance by using scene graphs to represent the relations of objects in the image. The current captioning encoders generally use a Graph Convolutional Net (GCN) to represent the relation information and merge it with the object region features via concatenation or convolution to get the final input for sentence decoding. However, the GCN-based encoders in the existing methods are less effective for captioning due to two reasons. First, using the image captioning as the objective (i.e., Maximum Likelihood Estimation) rather than a relation-centric loss cannot fully explore the potential of the encoder. Second, using a pre-trained model instead of the encoder itself to extract the relationships is not flexible and cannot contribute to the explainability of the model. To improve the quality of image captioning, we propose a novel architecture ReFormer -- a RElational transFORMER to generate features with relation information embedded and to explicitly express the pair-wise relationships between objects in the image. ReFormer incorporates the objective of scene graph generation with that of image captioning using one modified Transformer model. This design allows ReFormer to generate not only better image captions with the bene-fit of extracting strong relational image features, but also scene graphs to explicitly describe the pair-wise relation-ships. Experiments on publicly available datasets show that our model significantly outperforms state-of-the-art methods on image captioning and scene graph generation
TANet: A new Paradigm for Global Face Super-resolution via Transformer-CNN Aggregation Network
Sep 16, 2021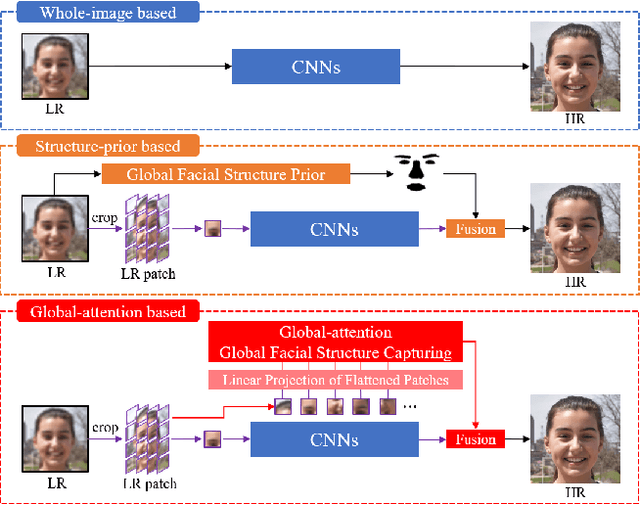
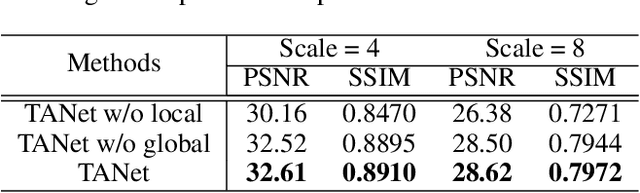
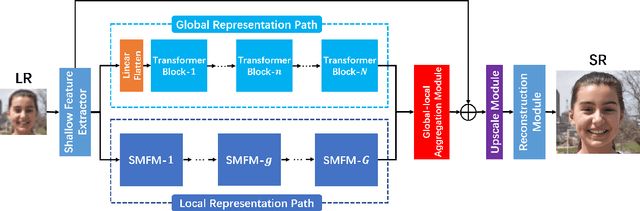
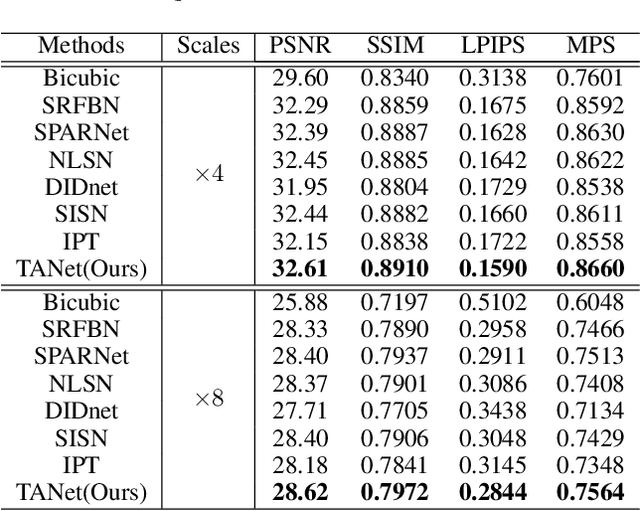
Recently, face super-resolution (FSR) methods either feed whole face image into convolutional neural networks (CNNs) or utilize extra facial priors (e.g., facial parsing maps, facial landmarks) to focus on facial structure, thereby maintaining the consistency of the facial structure while restoring facial details. However, the limited receptive fields of CNNs and inaccurate facial priors will reduce the naturalness and fidelity of the reconstructed face. In this paper, we propose a novel paradigm based on the self-attention mechanism (i.e., the core of Transformer) to fully explore the representation capacity of the facial structure feature. Specifically, we design a Transformer-CNN aggregation network (TANet) consisting of two paths, in which one path uses CNNs responsible for restoring fine-grained facial details while the other utilizes a resource-friendly Transformer to capture global information by exploiting the long-distance visual relation modeling. By aggregating the features from the above two paths, the consistency of global facial structure and fidelity of local facial detail restoration are strengthened simultaneously. Experimental results of face reconstruction and recognition verify that the proposed method can significantly outperform the state-of-the-art methods.
Improving Gender Fairness of Pre-Trained Language Models without Catastrophic Forgetting
Oct 11, 2021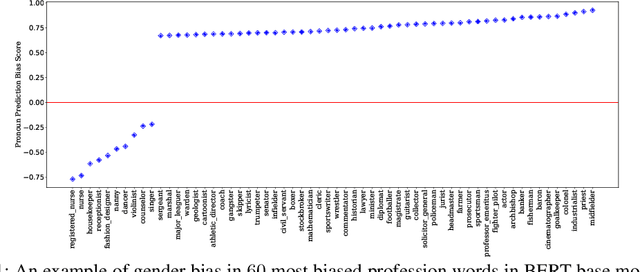

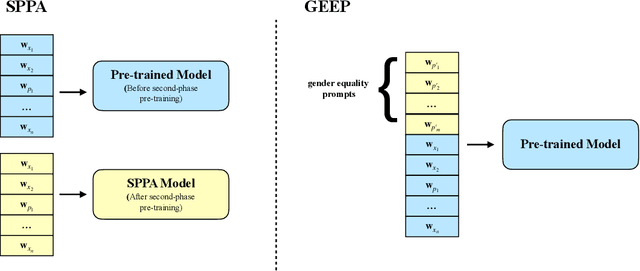
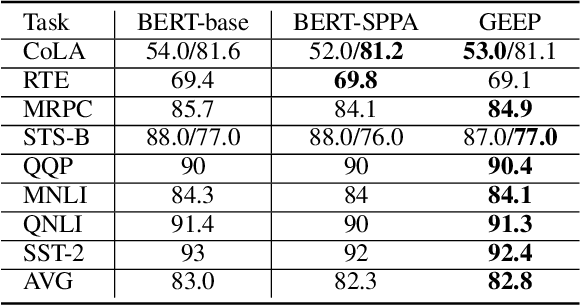
Although pre-trained language models, such as BERT, achieve state-of-art performance in many language understanding tasks, they have been demonstrated to inherit strong gender bias from its training data. Existing studies addressing the gender bias issue of pre-trained models, usually recollect and build gender-neutral data on their own and conduct a second phase pre-training on the released pre-trained model with such data. However, given the limited size of the gender-neutral data and its potential distributional mismatch with the original pre-training data, catastrophic forgetting would occur during the second-phase pre-training. Forgetting on the original training data may damage the model's downstream performance to a large margin. In this work, we first empirically show that even if the gender-neutral data for second-phase pre-training comes from the original training data, catastrophic forgetting still occurs if the size of gender-neutral data is smaller than that of original training data. Then, we propose a new method, GEnder Equality Prompt (GEEP), to improve gender fairness of pre-trained models without forgetting. GEEP learns gender-related prompts to reduce gender bias, conditioned on frozen language models. Since all pre-trained parameters are frozen, forgetting on information from the original training data can be alleviated to the most extent. Then GEEP trains new embeddings of profession names as gender equality prompts conditioned on the frozen model. Empirical results show that GEEP not only achieves state-of-the-art performances on gender debiasing in various applications such as pronoun predicting and coreference resolution, but also achieves comparable results on general downstream tasks such as GLUE with original pre-trained models without much forgetting.
A Longitudinal Multi-modal Dataset for Dementia Monitoring and Diagnosis
Sep 03, 2021
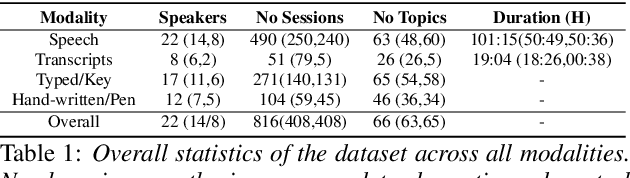
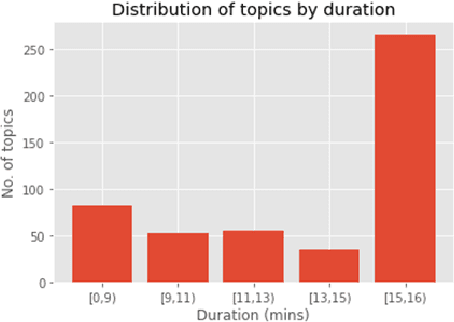
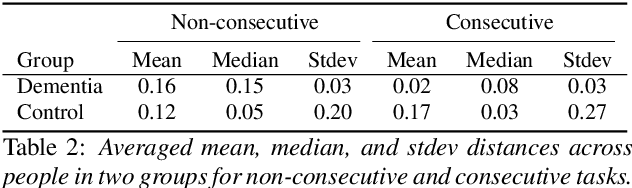
Dementia is a family of neurogenerative conditions affecting memory and cognition in an increasing number of individuals in our globally aging population. Automated analysis of language, speech and paralinguistic indicators have been gaining popularity as potential indicators of cognitive decline. Here we propose a novel longitudinal multi-modal dataset collected from people with mild dementia and age matched controls over a period of several months in a natural setting. The multi-modal data consists of spoken conversations, a subset of which are transcribed, as well as typed and written thoughts and associated extra-linguistic information such as pen strokes and keystrokes. We describe the dataset in detail and proceed to focus on a task using the speech modality. The latter involves distinguishing controls from people with dementia by exploiting the longitudinal nature of the data. Our experiments showed significant differences in how the speech varied from session to session in the control and dementia groups.
Improving Multilingual Translation by Representation and Gradient Regularization
Sep 10, 2021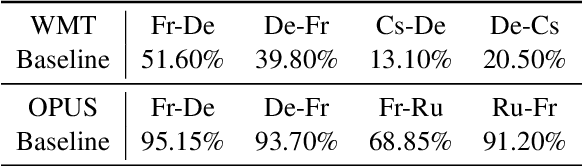
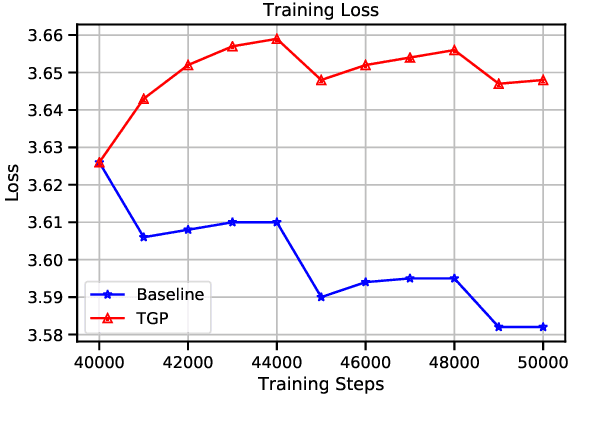
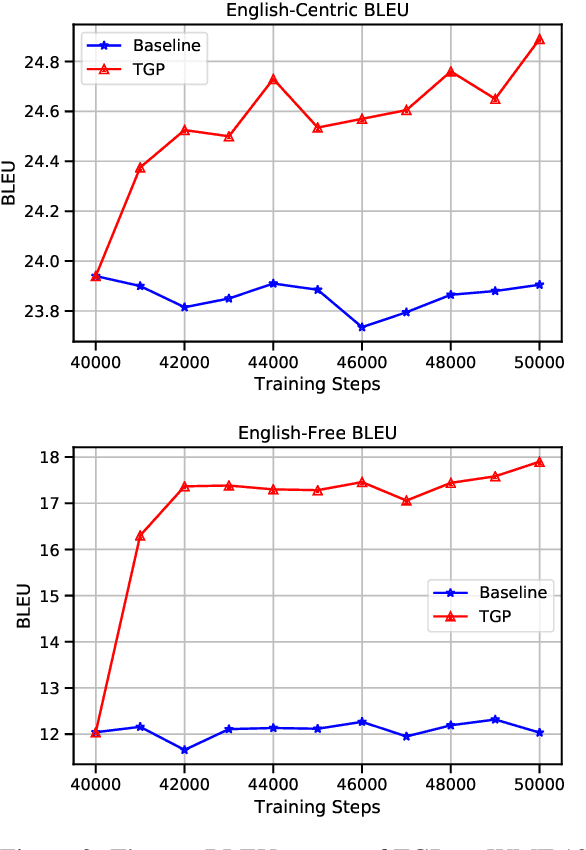
Multilingual Neural Machine Translation (NMT) enables one model to serve all translation directions, including ones that are unseen during training, i.e. zero-shot translation. Despite being theoretically attractive, current models often produce low quality translations -- commonly failing to even produce outputs in the right target language. In this work, we observe that off-target translation is dominant even in strong multilingual systems, trained on massive multilingual corpora. To address this issue, we propose a joint approach to regularize NMT models at both representation-level and gradient-level. At the representation level, we leverage an auxiliary target language prediction task to regularize decoder outputs to retain information about the target language. At the gradient level, we leverage a small amount of direct data (in thousands of sentence pairs) to regularize model gradients. Our results demonstrate that our approach is highly effective in both reducing off-target translation occurrences and improving zero-shot translation performance by +5.59 and +10.38 BLEU on WMT and OPUS datasets respectively. Moreover, experiments show that our method also works well when the small amount of direct data is not available.
Three-stream network for enriched Action Recognition
Apr 27, 2021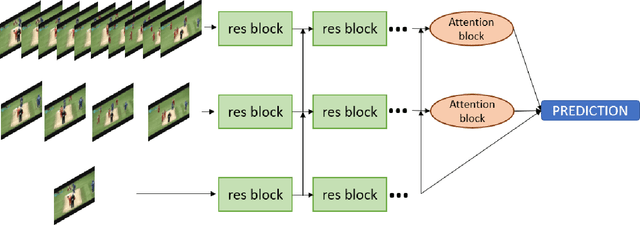
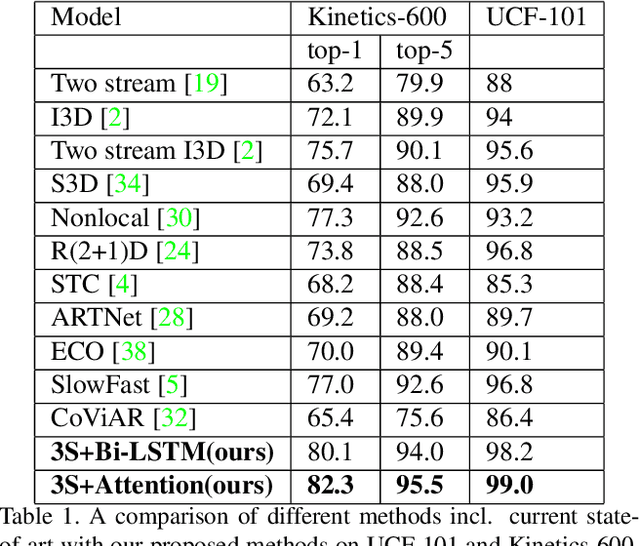
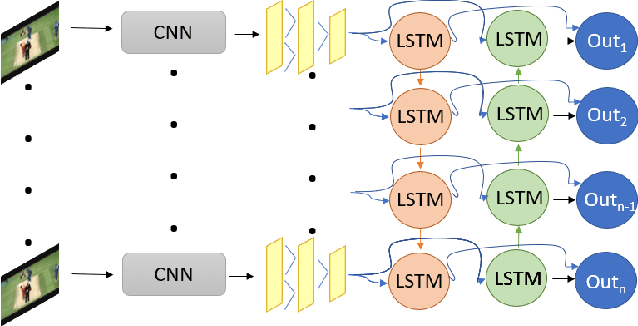
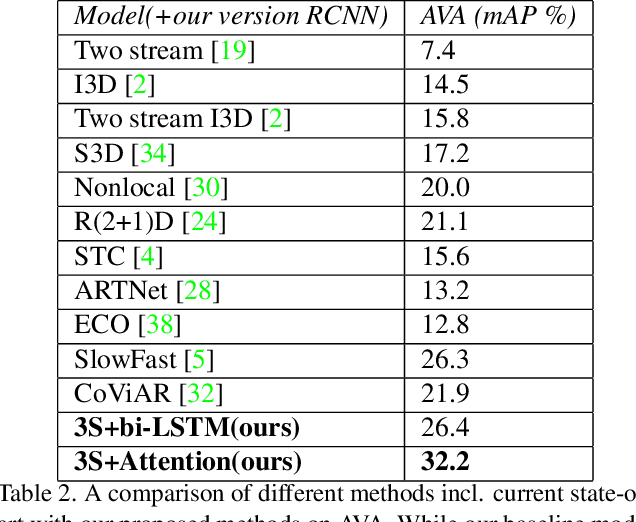
Understanding accurate information on human behaviours is one of the most important tasks in machine intelligence. Human Activity Recognition that aims to understand human activities from a video is a challenging task due to various problems including background, camera motion and dataset variations. This paper proposes two CNN based architectures with three streams which allow the model to exploit the dataset under different settings. The three pathways are differentiated in frame rates. The single pathway, operates at a single frame rate captures spatial information, the slow pathway operates at low frame rates captures the spatial information and the fast pathway operates at high frame rates that capture fine temporal information. Post CNN encoders, we add bidirectional LSTM and attention heads respectively to capture the context and temporal features. By experimenting with various algorithms on UCF-101, Kinetics-600 and AVA dataset, we observe that the proposed models achieve state-of-art performance for human action recognition task.