 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fast Wireless Sensor Anomaly Detection based on Data Stream in Edge Computing Enabled Smart Greenhouse
Jul 28, 2021
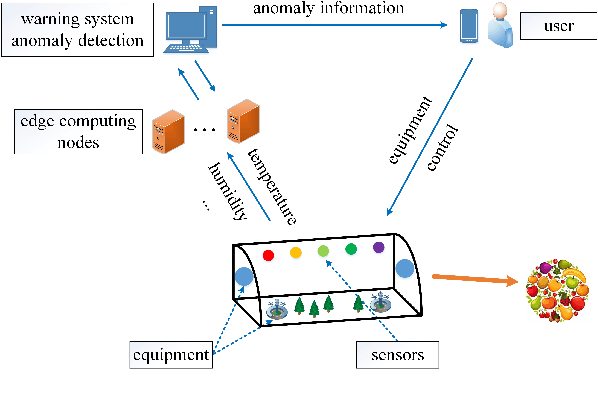
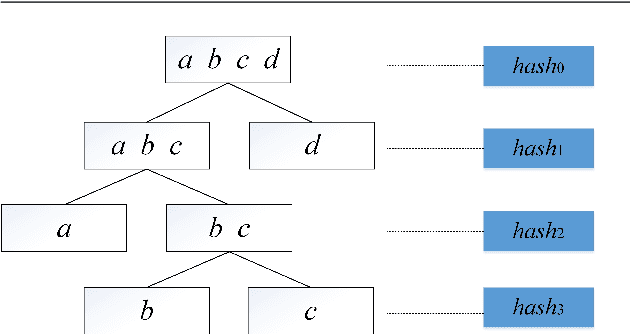

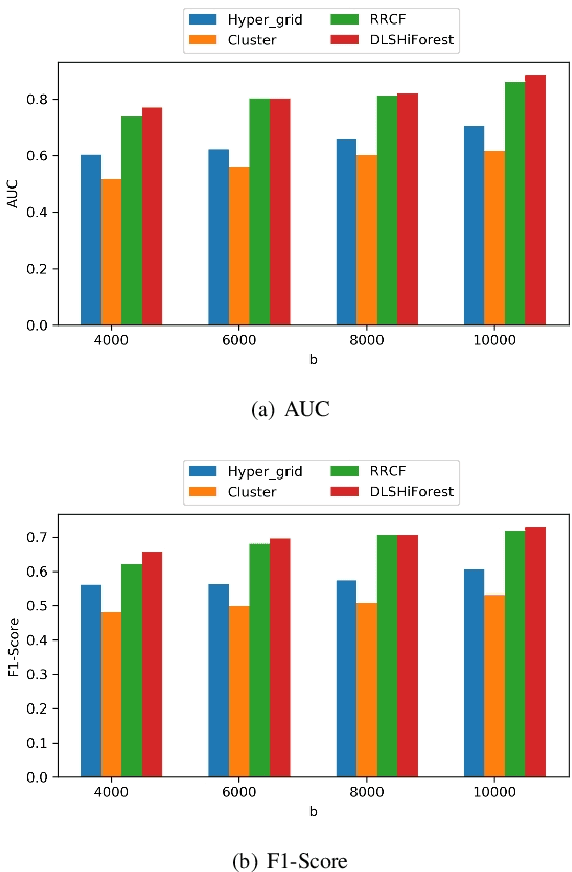
Edge computing enabled smart greenhouse is a representative application of Internet of Things technology, which can monitor the environmental information in real time and employ the information to contribute to intelligent decision-making. In the process, anomaly detection for wireless sensor data plays an important role. However, traditional anomaly detection algorithms originally designed for anomaly detection in static data have not properly considered the inherent characteristics of data stream produced by wireless sensor such as infiniteness, correlations and concept drift, which may pose a considerable challenge on anomaly detection based on data stream, and lead to low detection accuracy and efficiency. First, data stream usually generates quickly which means that it is infinite and enormous, so any traditional off-line anomaly detection algorithm that attempts to store the whole dataset or to scan the dataset multiple times for anomaly detection will run out of memory space. Second, there exist correlations among different data streams, which traditional algorithms hardly consider. Third, the underlying data generation process or data distribution may change over time. Thus, traditional anomaly detection algorithms with no model update will lose their effects. Considering these issues, a novel method (called DLSHiForest) on basis of Locality-Sensitive Hashing and time window technique in this paper is proposed to solve these problems while achieving accurate and efficient detection. Comprehensive experiments are executed using real-world agricultural greenhouse dataset to demonstrate the feasibility of our approach. Experimental results show that our proposal is practicable in addressing challenges of traditional anomaly detection while ensuring accuracy and efficiency.
Cellular traffic offloading via Opportunistic Networking with Reinforcement Learning
Oct 01, 2021
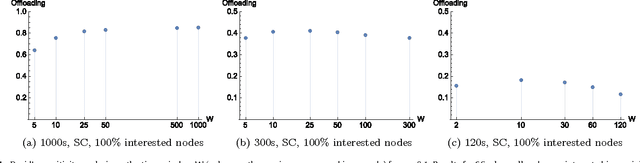

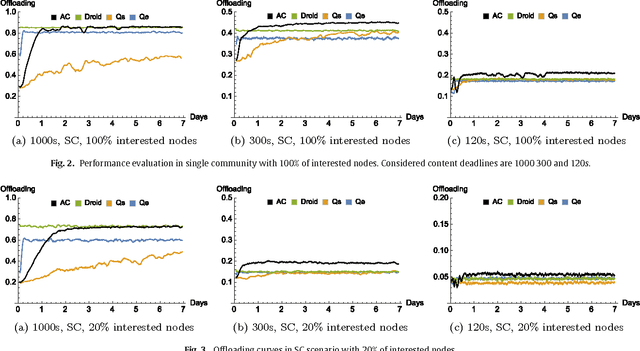
The widespread diffusion of mobile phones is triggering an exponential growth of mobile data traffic that is likely to cause, in the near future, considerable traffic overload issues even in last-generation cellular networks. Offloading part of the traffic to other networks is considered a very promising approach and, in particular, in this paper, we consider offloading through opportunistic networks of users' devices. However, the performance of this solution strongly depends on the pattern of encounters between mobile nodes, which should therefore be taken into account when designing offloading control algorithms. In this paper, we propose an adaptive offloading solution based on the Reinforcement Learning framework and we evaluate and compare the performance of two well-known learning algorithms: Actor-Critic and Q-Learning. More precisely, in our solution the controller of the dissemination process, once trained, is able to select a proper number of content replicas to be injected into the opportunistic network to guarantee the timely delivery of contents to all interested users. We show that our system based on Reinforcement Learning is able to automatically learn a very efficient strategy to reduce the traffic on the cellular network, without relying on any additional context information about the opportunistic network. Our solution achieves a higher level of offloading with respect to other state-of-the-art approaches, in a range of different mobility settings. Moreover, we show that a more refined learning solution, based on the Actor-Critic algorithm, is significantly more efficient than a simpler solution based on Q-learning.
GAN-based Reactive Motion Synthesis with Class-aware Discriminators for Human-human Interaction
Oct 01, 2021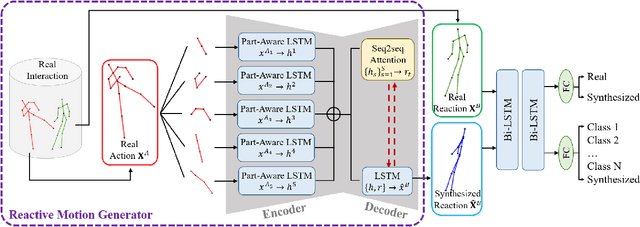
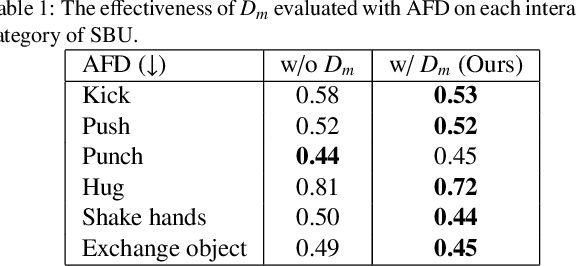
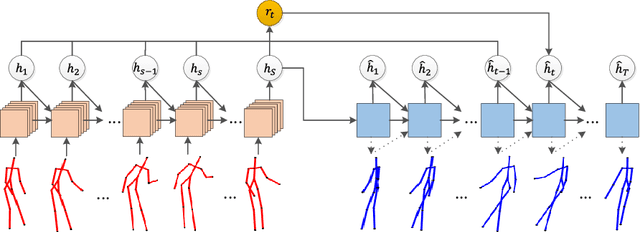
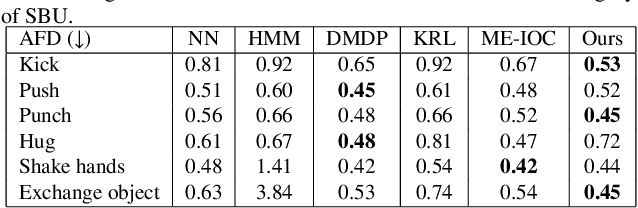
Creating realistic characters that can react to the users' or another character's movement can benefit computer graphics, games and virtual reality hugely. However, synthesizing such reactive motions in human-human interactions is a challenging task due to the many different ways two humans can interact. While there are a number of successful researches in adapting the generative adversarial network (GAN) in synthesizing single human actions, there are very few on modelling human-human interactions. In this paper, we propose a semi-supervised GAN system that synthesizes the reactive motion of a character given the active motion from another character. Our key insights are two-fold. First, to effectively encode the complicated spatial-temporal information of a human motion, we empower the generator with a part-based long short-term memory (LSTM) module, such that the temporal movement of different limbs can be effectively modelled. We further include an attention module such that the temporal significance of the interaction can be learned, which enhances the temporal alignment of the active-reactive motion pair. Second, as the reactive motion of different types of interactions can be significantly different, we introduce a discriminator that not only tells if the generated movement is realistic or not, but also tells the class label of the interaction. This allows the use of such labels in supervising the training of the generator. We experiment with the SBU and the HHOI datasets. The high quality of the synthetic motion demonstrates the effective design of our generator, and the discriminability of the synthesis also demonstrates the strength of our discriminator.
An optimized Capsule-LSTM model for facial expression recognition with video sequences
May 27, 2021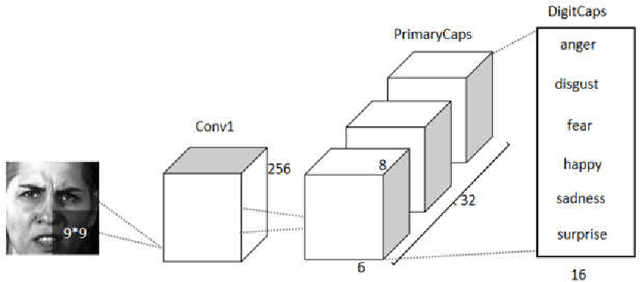
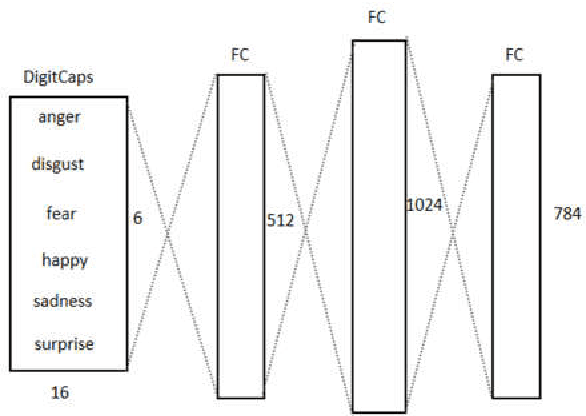
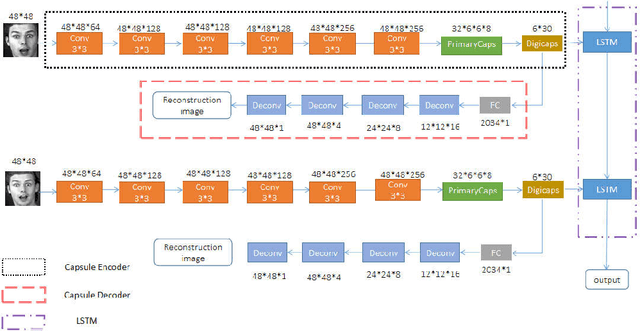

To overcome the limitations of convolutional neural network in the process of facial expression recognition, a facial expression recognition model Capsule-LSTM based on video frame sequence is proposed. This model is composed of three networks includingcapsule encoders, capsule decoders and LSTM network. The capsule encoder extracts the spatial information of facial expressions in video frames. Capsule decoder reconstructs the images to optimize the network. LSTM extracts the temporal information between video frames and analyzes the differences in expression changes between frames. The experimental results from the MMI dataset show that the Capsule-LSTM model proposed in this paper can effectively improve the accuracy of video expression recognition.
A Novel CropdocNet for Automated Potato Late Blight Disease Detection from the Unmanned Aerial Vehicle-based Hyperspectral Imagery
Jul 28, 2021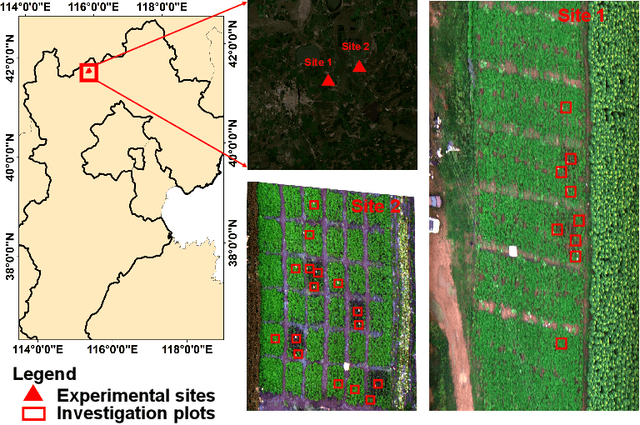

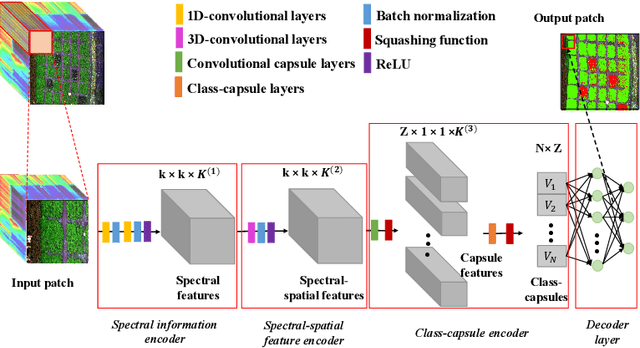
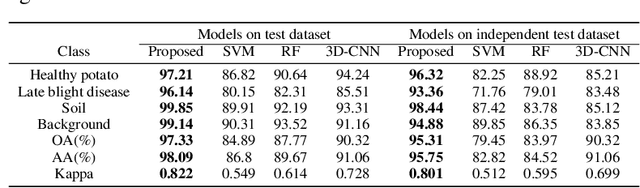
Late blight disease is one of the most destructive diseases in potato crop, leading to serious yield losses globally. Accurate diagnosis of the disease at early stage is critical for precision disease control and management. Current farm practices in crop disease diagnosis are based on manual visual inspection, which is costly, time consuming, subject to individual bias. Recent advances in imaging sensors (e.g. RGB, multiple spectral and hyperspectral cameras), remote sensing and machine learning offer the opportunity to address this challenge. Particularly, hyperspectral imagery (HSI) combining with machine learning/deep learning approaches is preferable for accurately identifying specific plant diseases because the HSI consists of a wide range of high-quality reflectance information beyond human vision, capable of capturing both spectral-spatial information. The proposed method considers the potential disease specific reflectance radiation variance caused by the canopy structural diversity, introduces the multiple capsule layers to model the hierarchical structure of the spectral-spatial disease attributes with the encapsulated features to represent the various classes and the rotation invariance of the disease attributes in the feature space. We have evaluated the proposed method with the real UAV-based HSI data under the controlled field conditions. The effectiveness of the hierarchical features has been quantitatively assessed and compared with the existing representative machine learning/deep learning methods. The experiment results show that the proposed model significantly improves the accuracy performance when considering hierarchical-structure of spectral-spatial features, comparing to the existing methods only using spectral, or spatial or spectral-spatial features without consider hierarchical-structure of spectral-spatial features.
Using Bi-Directional Information Exchange to Improve Decentralized Schedule-Driven Traffic Control
Jul 03, 2019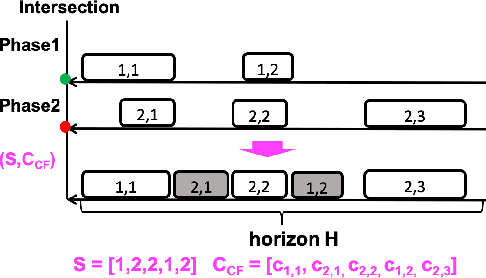
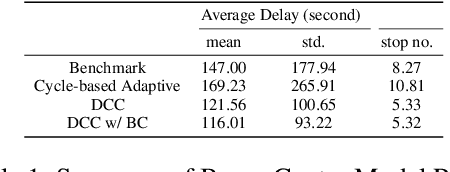
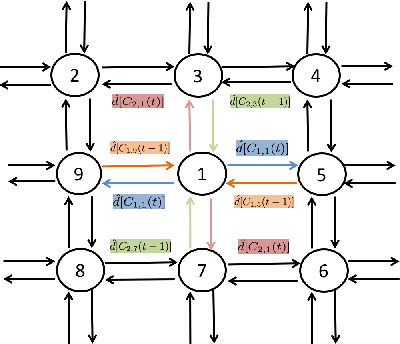
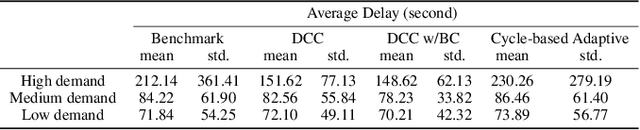
Recent work in decentralized, schedule-driven traffic control has demonstrated the ability to improve the efficiency of traffic flow in complex urban road networks. In this approach, a scheduling agent is associated with each intersection. Each agent senses the traffic approaching its intersection and in real-time constructs a schedule that minimizes the cumulative wait time of vehicles approaching the intersection over the current look-ahead horizon. In order to achieve network level coordination in a scalable manner, scheduling agents communicate only with their direct neighbors. Each time an agent generates a new intersection schedule it communicates its expected outflows to its downstream neighbors as a prediction of future demand and these outflows are appended to the downstream agent's locally perceived demand. In this paper, we extend this basic coordination algorithm to additionally incorporate the complementary flow of information reflective of an intersection's current congestion level to its upstream neighbors. We present an asynchronous decentralized algorithm for updating intersection schedules and congestion level estimates based on these bi-directional information flows. By relating this algorithm to the self-optimized decision making of the basic operation, we are able to approach network-wide optimality and reduce inefficiency due to strictly self-interested intersection control decisions.
What can phylogenetic metrics tell us about useful diversity in evolutionary algorithms?
Aug 28, 2021
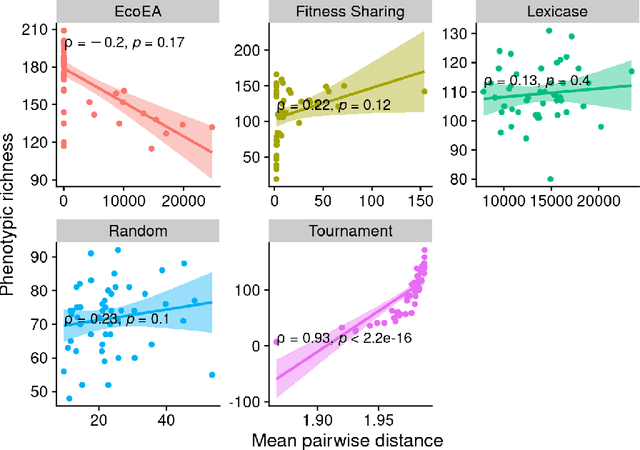
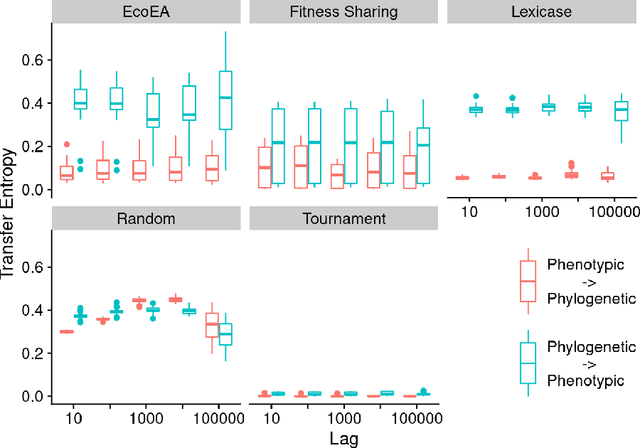
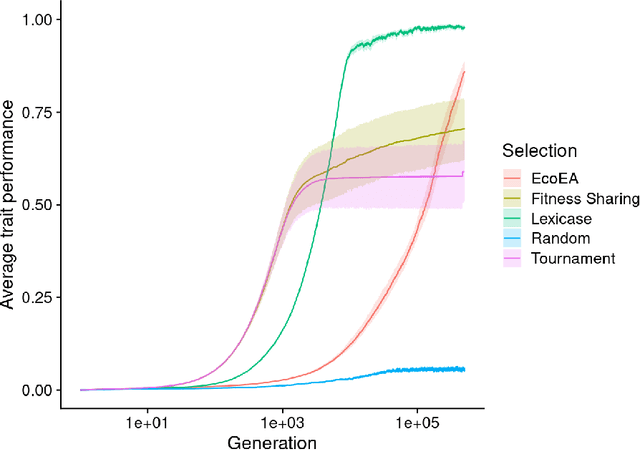
It is generally accepted that "diversity" is associated with success in evolutionary algorithms. However, diversity is a broad concept that can be measured and defined in a multitude of ways. To date, most evolutionary computation research has measured diversity using the richness and/or evenness of a particular genotypic or phenotypic property. While these metrics are informative, we hypothesize that other diversity metrics are more strongly predictive of success. Phylogenetic diversity metrics are a class of metrics popularly used in biology, which take into account the evolutionary history of a population. Here, we investigate the extent to which 1) these metrics provide different information than those traditionally used in evolutionary computation, and 2) these metrics better predict the long-term success of a run of evolutionary computation. We find that, in most cases, phylogenetic metrics behave meaningfully differently from other diversity metrics. Moreover, our results suggest that phylogenetic diversity is indeed a better predictor of success.
Negative Sample Matters: A Renaissance of Metric Learning for Temporal Grounding
Sep 10, 2021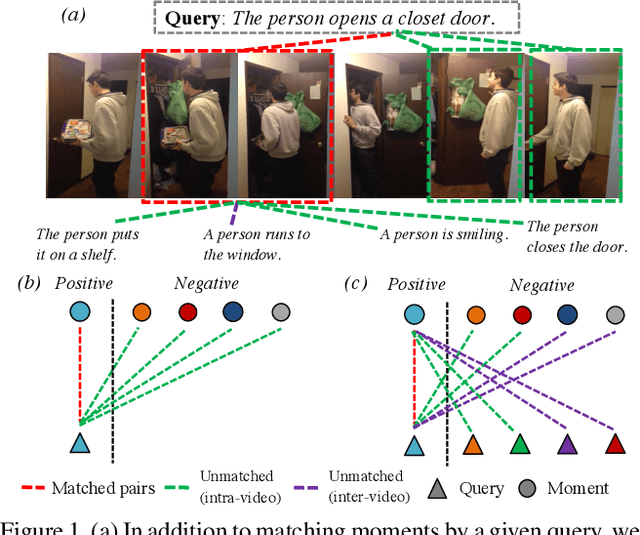

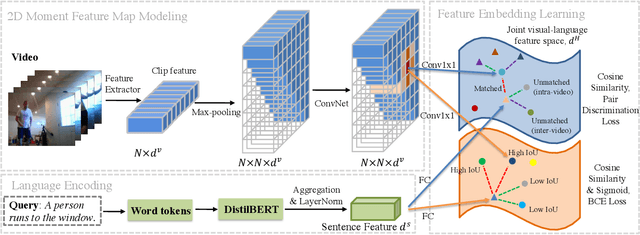
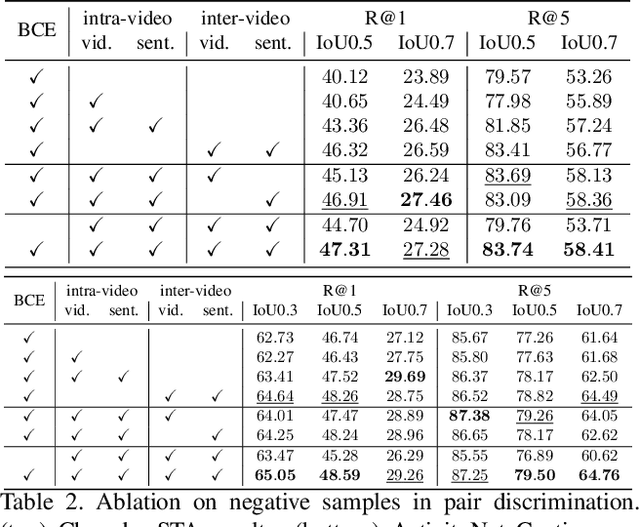
Temporal grounding aims to temporally localize a video moment in the video whose semantics are related to a given natural language query. Existing methods typically apply a detection or regression pipeline on the fused representation with a focus on designing complicated heads and fusion strategies. Instead, from a perspective on temporal grounding as a metric-learning problem, we present a Dual Matching Network (DMN), to directly model the relations between language queries and video moments in a joint embedding space. This new metric-learning framework enables fully exploiting negative samples from two new aspects: constructing negative cross-modal pairs from a dual matching scheme and mining negative pairs across different videos. These new negative samples could enhance the joint representation learning of two modalities via cross-modal pair discrimination to maximize their mutual information. Experiments show that DMN achieves highly competitive performance compared with state-of-the-art methods on four video grounding benchmarks. Based on DMN, we present a winner solution for STVG challenge of the 3rd PIC workshop. This suggests that metric-learning is still a promising method for temporal grounding via capturing the essential cross-modal correlation in a joint embedding space.
Spatio-Temporal Recurrent Networks for Event-Based Optical Flow Estimation
Sep 10, 2021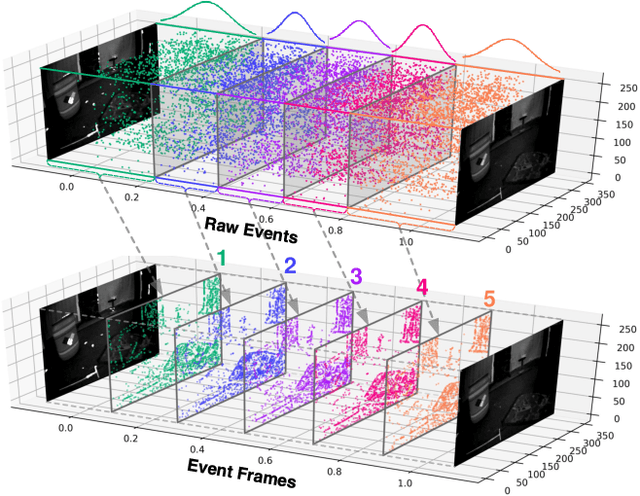
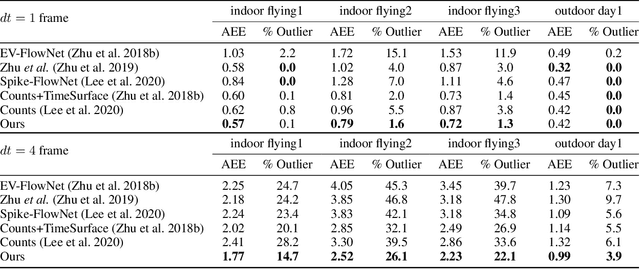
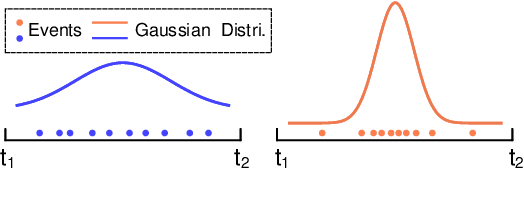
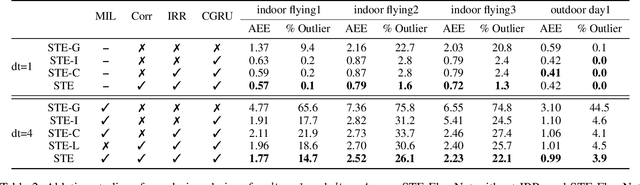
Event camera has offered promising alternative for visual perception, especially in high speed and high dynamic range scenes. Recently, many deep learning methods have shown great success in providing model-free solutions to many event-based problems, such as optical flow estimation. However, existing deep learning methods did not address the importance of temporal information well from the perspective of architecture design and cannot effectively extract spatio-temporal features. Another line of research that utilizes Spiking Neural Network suffers from training issues for deeper architecture. To address these points, a novel input representation is proposed that captures the events temporal distribution for signal enhancement. Moreover, we introduce a spatio-temporal recurrent encoding-decoding neural network architecture for event-based optical flow estimation, which utilizes Convolutional Gated Recurrent Units to extract feature maps from a series of event images. Besides, our architecture allows some traditional frame-based core modules, such as correlation layer and iterative residual refine scheme, to be incorporated. The network is end-to-end trained with self-supervised learning on the Multi-Vehicle Stereo Event Camera dataset. We have shown that it outperforms all the existing state-of-the-art methods by a large margin.
PlaTe: Visually-Grounded Planning with Transformers in Procedural Tasks
Sep 10, 2021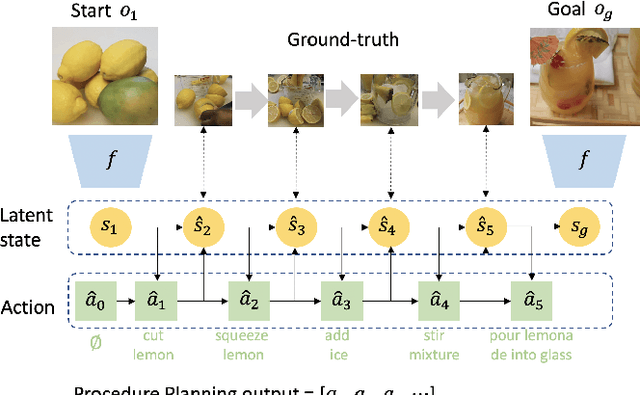
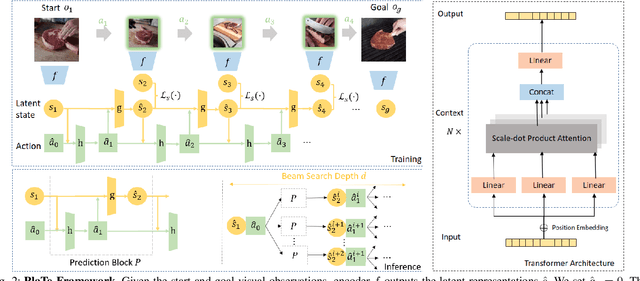
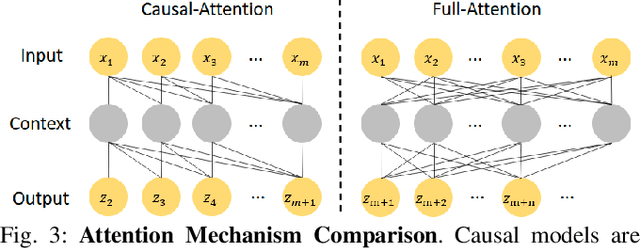

In this work, we study the problem of how to leverage instructional videos to facilitate the understanding of human decision-making processes, focusing on training a model with the ability to plan a goal-directed procedure from real-world videos. Learning structured and plannable state and action spaces directly from unstructured videos is the key technical challenge of our task. There are two problems: first, the appearance gap between the training and validation datasets could be large for unstructured videos; second, these gaps lead to decision errors that compound over the steps. We address these limitations with Planning Transformer (PlaTe), which has the advantage of circumventing the compounding prediction errors that occur with single-step models during long model-based rollouts. Our method simultaneously learns the latent state and action information of assigned tasks and the representations of the decision-making process from human demonstrations. Experiments conducted on real-world instructional videos and an interactive environment show that our method can achieve a better performance in reaching the indicated goal than previous algorithms. We also validated the possibility of applying procedural tasks on a UR-5 platform.