 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Energy Minimization for IRS-aided WPCNs with Non-linear Energy Harvesting Model
Sep 02, 2021
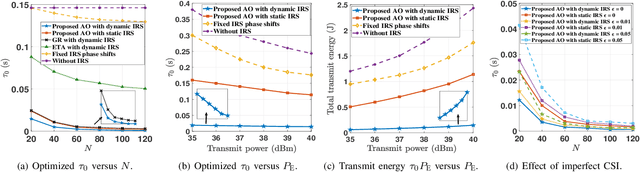
This paper considers an intelligent reflecting surface(IRS)-aided wireless powered communication network (WPCN), where devices first harvest energy from a power station (PS) in the downlink (DL) and then transmit information using non-orthogonal multiple access (NOMA) to a data sink in the uplink (UL). However, most existing works on WPCNs adopted the simplified linear energy-harvesting model and also cannot guarantee strict user quality-of-service requirements. To address these issues, we aim to minimize the total transmit energy consumption at the PS by jointly optimizing the resource allocation and IRS phase shifts over time, subject to the minimum throughput requirements of all devices. The formulated problem is decomposed into two subproblems, and solved iteratively in an alternative manner by employing difference of convex functions programming, successive convex approximation, and penalty-based algorithm. Numerical results demonstrate the significant performance gains achieved by the proposed algorithm over benchmark schemes and reveal the benefits of integrating IRS into WPCNs. In particular, employing different IRS phase shifts over UL and DL outperforms the case with static IRS beamforming.
CODA: Constructivism Learning for Instance-Dependent Dropout Architecture Construction
Jun 15, 2021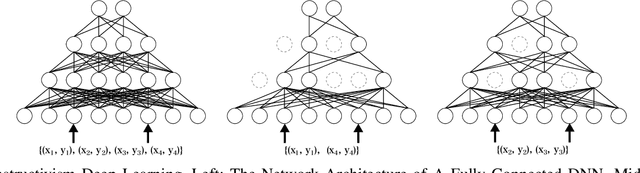

Dropout is attracting intensive research interest in deep learning as an efficient approach to prevent overfitting. Recently incorporating structural information when deciding which units to drop out produced promising results comparing to methods that ignore the structural information. However, a major issue of the existing work is that it failed to differentiate among instances when constructing the dropout architecture. This can be a significant deficiency for many applications. To solve this issue, we propose Constructivism learning for instance-dependent Dropout Architecture (CODA), which is inspired from a philosophical theory, constructivism learning. Specially, based on the theory we have designed a better drop out technique, Uniform Process Mixture Models, using a Bayesian nonparametric method Uniform process. We have evaluated our proposed method on 5 real-world datasets and compared the performance with other state-of-the-art dropout techniques. The experimental results demonstrated the effectiveness of CODA.
Trans4E: Link Prediction on Scholarly Knowledge Graphs
Jul 03, 2021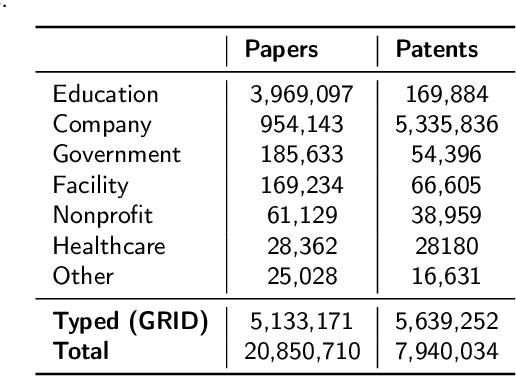
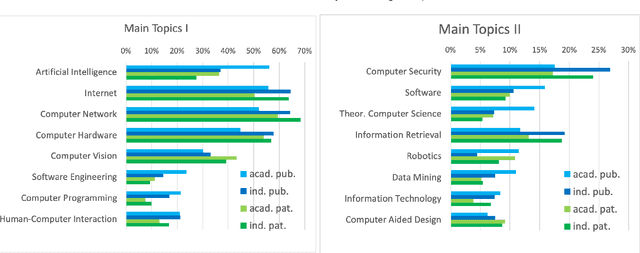
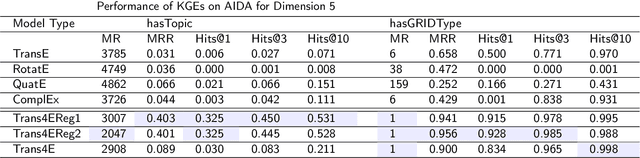
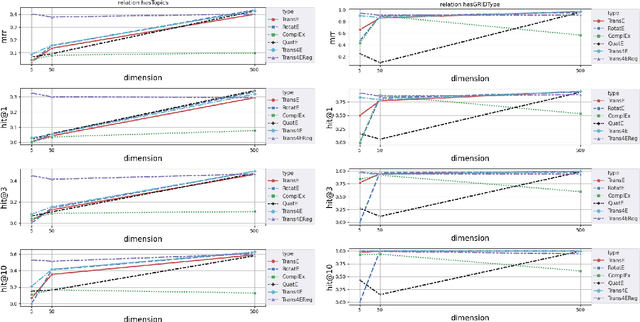
The incompleteness of Knowledge Graphs (KGs) is a crucial issue affecting the quality of AI-based services. In the scholarly domain, KGs describing research publications typically lack important information, hindering our ability to analyse and predict research dynamics. In recent years, link prediction approaches based on Knowledge Graph Embedding models became the first aid for this issue. In this work, we present Trans4E, a novel embedding model that is particularly fit for KGs which include N to M relations with N$\gg$M. This is typical for KGs that categorize a large number of entities (e.g., research articles, patents, persons) according to a relatively small set of categories. Trans4E was applied on two large-scale knowledge graphs, the Academia/Industry DynAmics (AIDA) and Microsoft Academic Graph (MAG), for completing the information about Fields of Study (e.g., 'neural networks', 'machine learning', 'artificial intelligence'), and affiliation types (e.g., 'education', 'company', 'government'), improving the scope and accuracy of the resulting data. We evaluated our approach against alternative solutions on AIDA, MAG, and four other benchmarks (FB15k, FB15k-237, WN18, and WN18RR). Trans4E outperforms the other models when using low embedding dimensions and obtains competitive results in high dimensions.
InfoBot: Transfer and Exploration via the Information Bottleneck
Apr 04, 2019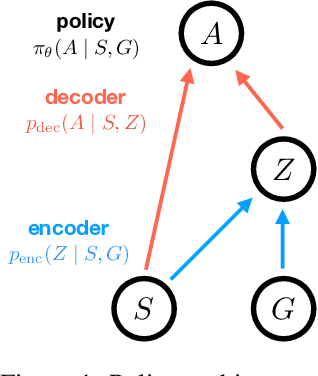



A central challenge in reinforcement learning is discovering effective policies for tasks where rewards are sparsely distributed. We postulate that in the absence of useful reward signals, an effective exploration strategy should seek out {\it decision states}. These states lie at critical junctions in the state space from where the agent can transition to new, potentially unexplored regions. We propose to learn about decision states from prior experience. By training a goal-conditioned policy with an information bottleneck, we can identify decision states by examining where the model actually leverages the goal state. We find that this simple mechanism effectively identifies decision states, even in partially observed settings. In effect, the model learns the sensory cues that correlate with potential subgoals. In new environments, this model can then identify novel subgoals for further exploration, guiding the agent through a sequence of potential decision states and through new regions of the state space.
HANet: Hierarchical Alignment Networks for Video-Text Retrieval
Jul 26, 2021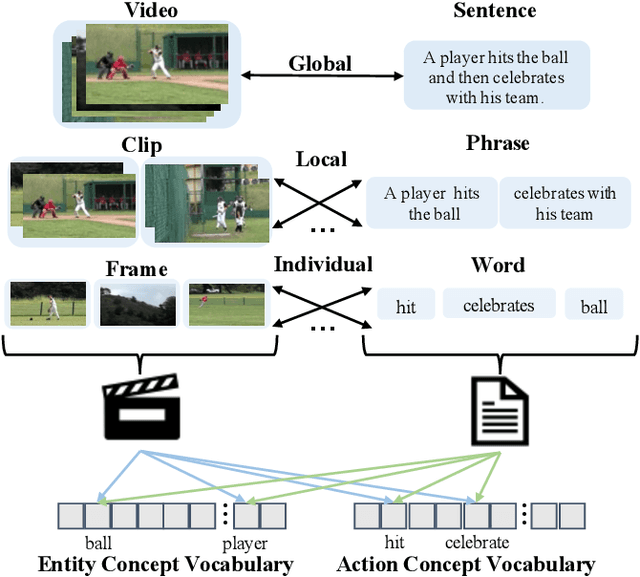
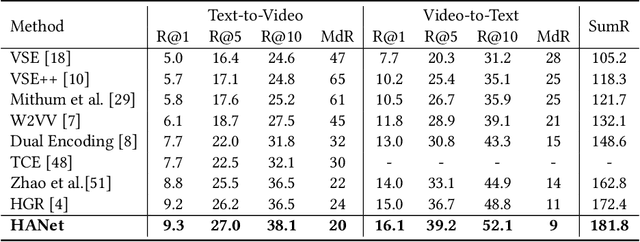
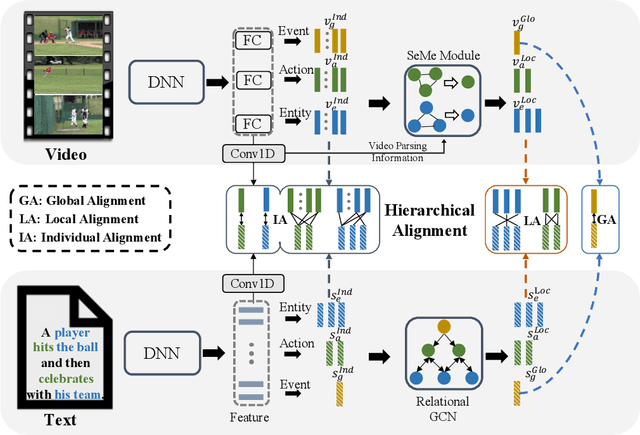
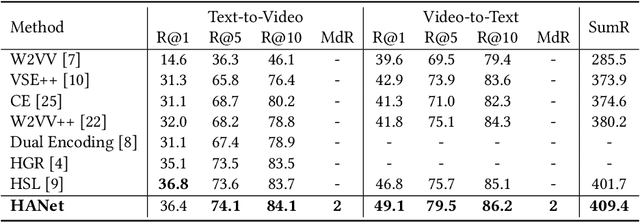
Video-text retrieval is an important yet challenging task in vision-language understanding, which aims to learn a joint embedding space where related video and text instances are close to each other. Most current works simply measure the video-text similarity based on video-level and text-level embeddings. However, the neglect of more fine-grained or local information causes the problem of insufficient representation. Some works exploit the local details by disentangling sentences, but overlook the corresponding videos, causing the asymmetry of video-text representation. To address the above limitations, we propose a Hierarchical Alignment Network (HANet) to align different level representations for video-text matching. Specifically, we first decompose video and text into three semantic levels, namely event (video and text), action (motion and verb), and entity (appearance and noun). Based on these, we naturally construct hierarchical representations in the individual-local-global manner, where the individual level focuses on the alignment between frame and word, local level focuses on the alignment between video clip and textual context, and global level focuses on the alignment between the whole video and text. Different level alignments capture fine-to-coarse correlations between video and text, as well as take the advantage of the complementary information among three semantic levels. Besides, our HANet is also richly interpretable by explicitly learning key semantic concepts. Extensive experiments on two public datasets, namely MSR-VTT and VATEX, show the proposed HANet outperforms other state-of-the-art methods, which demonstrates the effectiveness of hierarchical representation and alignment. Our code is publicly available.
A Dual-Decoder Conformer for Multilingual Speech Recognition
Aug 22, 2021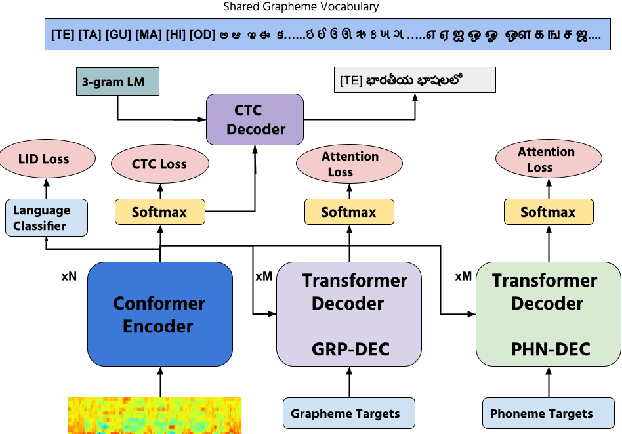
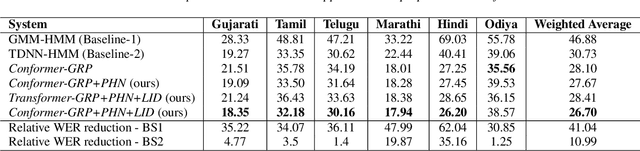


Transformer-based models have recently become very popular for sequence-to-sequence applications such as machine translation and speech recognition. This work proposes a dual-decoder transformer model for low-resource multilingual speech recognition for Indian languages. Our proposed model consists of a Conformer [1] encoder, two parallel transformer decoders, and a language classifier. We use a phoneme decoder (PHN-DEC) for the phoneme recognition task and a grapheme decoder (GRP-DEC) to predict grapheme sequence along with language information. We consider phoneme recognition and language identification as auxiliary tasks in the multi-task learning framework. We jointly optimize the network for phoneme recognition, grapheme recognition, and language identification tasks with Joint CTC-Attention [2] training. Our experiments show that we can obtain a significant reduction in WER over the baseline approaches. We also show that our dual-decoder approach obtains significant improvement over the single decoder approach.
HeteSpaceyWalk: A Heterogeneous Spacey Random Walk for Heterogeneous Information Network Embedding
Sep 07, 2019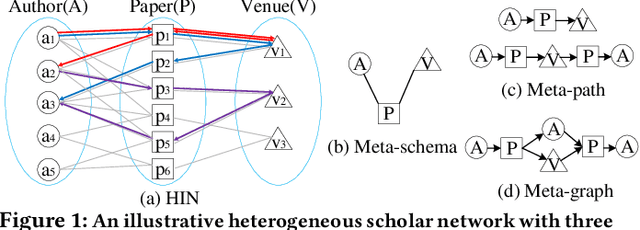
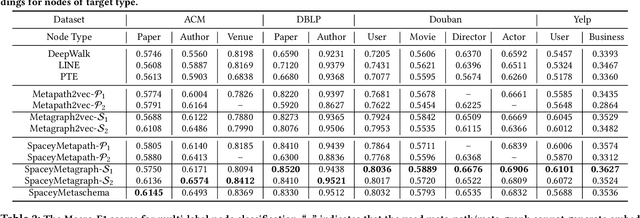
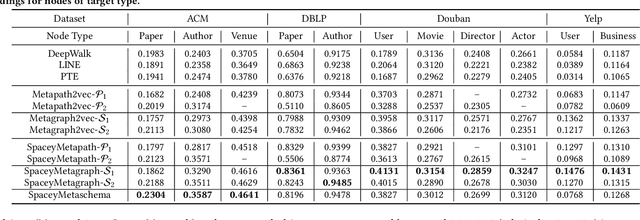
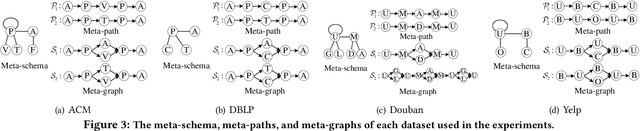
Heterogeneous information network (HIN) embedding has gained increasing interests recently. However, the current way of random-walk based HIN embedding methods have paid few attention to the higher-order Markov chain nature of meta-path guided random walks, especially to the stationarity issue. In this paper, we systematically formalize the meta-path guided random walk as a higher-order Markov chain process, and present a heterogeneous personalized spacey random walk to efficiently and effectively attain the expected stationary distribution among nodes. Then we propose a generalized scalable framework to leverage the heterogeneous personalized spacey random walk to learn embeddings for multiple types of nodes in an HIN guided by a meta-path, a meta-graph, and a meta-schema respectively. We conduct extensive experiments in several heterogeneous networks and demonstrate that our methods substantially outperform the existing state-of-the-art network embedding algorithms.
Well Googled is Half Done: Multimodal Forecasting of New Fashion Product Sales with Image-based Google Trends
Sep 24, 2021
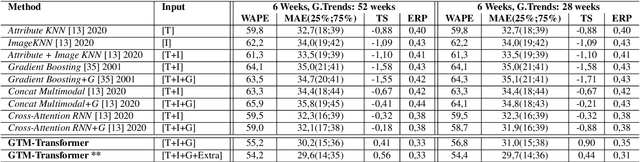
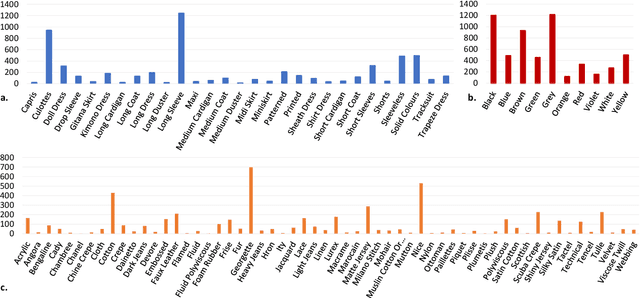
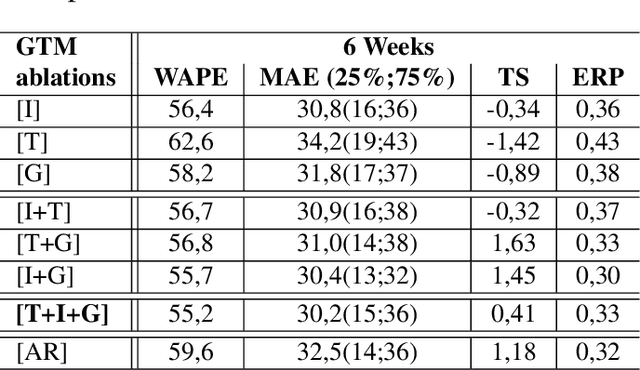
This paper investigates the effectiveness of systematically probing Google Trendsagainst textual translations of visual aspects as exogenous knowledge to predict the sales of brand-new fashion items, where past sales data is not available, but only an image and few metadata are available. In particular, we propose GTM-Transformer, standing for Google Trends Multimodal Transformer, whose encoder works on the representation of the exogenous time series, while the decoder forecasts the sales using the Google Trends encoding, and the available visual and metadata information. Our model works in a non-autoregressive manner, avoiding the compounding effect of the first-step errors. As a second contribution, we present the VISUELLE dataset, which is the first publicly available dataset for the task of new fashion product sales forecasting, containing the sales of 5577 new products sold between 2016-2019, derived from genuine historical data ofNunalie, an Italian fast-fashion company. Our dataset is equipped with images of products, metadata, related sales, and associated Google Trends. We use VISUELLE to compare our approach against state-of-the-art alternatives and numerous baselines, showing that GTM-Transformer is the most accurate in terms of both percentage and absolute error. It is worth noting that the addition of exogenous knowledge boosts the forecasting accuracy by 1.5% WAPE wise, showing the importance of exploiting Google Trends. The code and dataset are both available at https://github.com/HumaticsLAB/GTM-Transformer.
Old BERT, New Tricks: Artificial Language Learning for Pre-Trained Language Models
Sep 13, 2021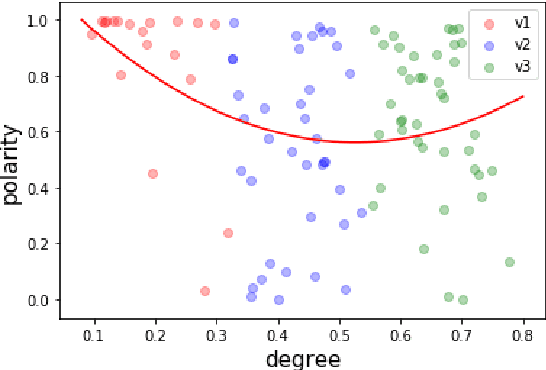
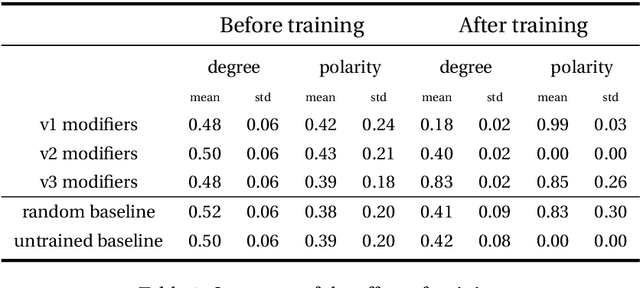
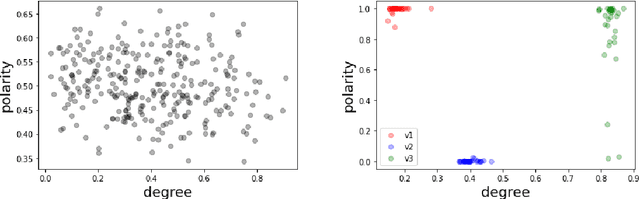
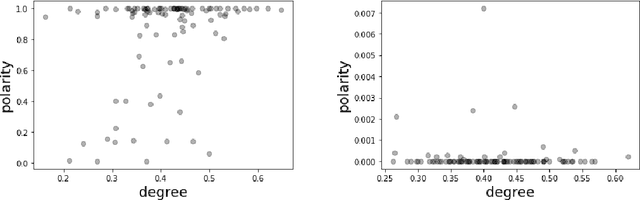
We extend the artificial language learning experimental paradigm from psycholinguistics and apply it to pre-trained language models -- specifically, BERT (Devlin et al., 2019). We treat the model as a subject in an artificial language learning experimental setting: in order to learn the relation between two linguistic properties A and B, we introduce a set of new, non-existent, linguistic items, give the model information about their variation along property A, then measure to what extent the model learns property B for these items as a result of training. We show this method at work for degree modifiers (expressions like "slightly", "very", "rather", "extremely") and test the hypothesis that the degree expressed by modifiers (low, medium or high degree) is related to their sensitivity to sentence polarity (whether they show preference for affirmative or negative sentences or neither). Our experimental results are compatible with existing linguistic observations that relate degree semantics to polarity-sensitivity, including the main one: low degree semantics leads to positive polarity sensitivity (that is, to preference towards affirmative contexts). The method can be used in linguistics to elaborate on hypotheses and interpret experimental results, as well as for more insightful evaluation of linguistic representations in language models.
Dual-stream Network for Visual Recognition
May 31, 2021
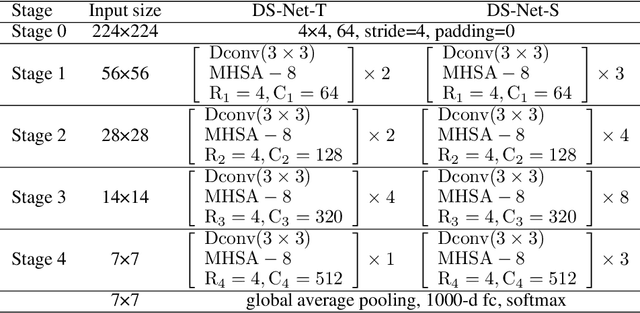
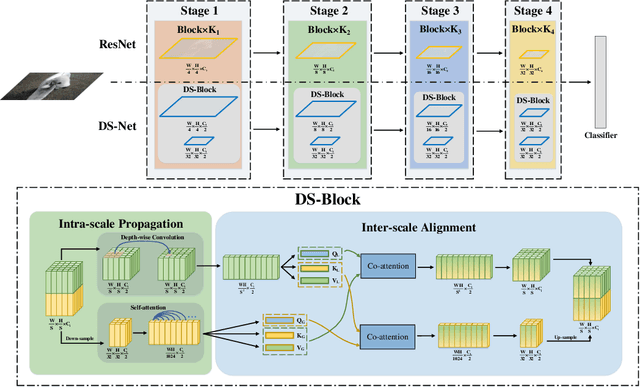
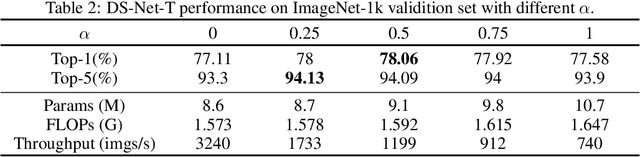
Transformers with remarkable global representation capacities achieve competitive results for visual tasks, but fail to consider high-level local pattern information in input images. In this paper, we present a generic Dual-stream Network (DS-Net) to fully explore the representation capacity of local and global pattern features for image classification. Our DS-Net can simultaneously calculate fine-grained and integrated features and efficiently fuse them. Specifically, we propose an Intra-scale Propagation module to process two different resolutions in each block and an Inter-Scale Alignment module to perform information interaction across features at dual scales. Besides, we also design a Dual-stream FPN (DS-FPN) to further enhance contextual information for downstream dense predictions. Without bells and whistles, the propsed DS-Net outperforms Deit-Small by 2.4% in terms of top-1 accuracy on ImageNet-1k and achieves state-of-the-art performance over other Vision Transformers and ResNets. For object detection and instance segmentation, DS-Net-Small respectively outperforms ResNet-50 by 6.4% and 5.5 % in terms of mAP on MSCOCO 2017, and surpasses the previous state-of-the-art scheme, which significantly demonstrates its potential to be a general backbone in vision tasks. The code will be released soon.