 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generating Master Faces for Dictionary Attacks with a Network-Assisted Latent Space Evolution
Aug 19, 2021
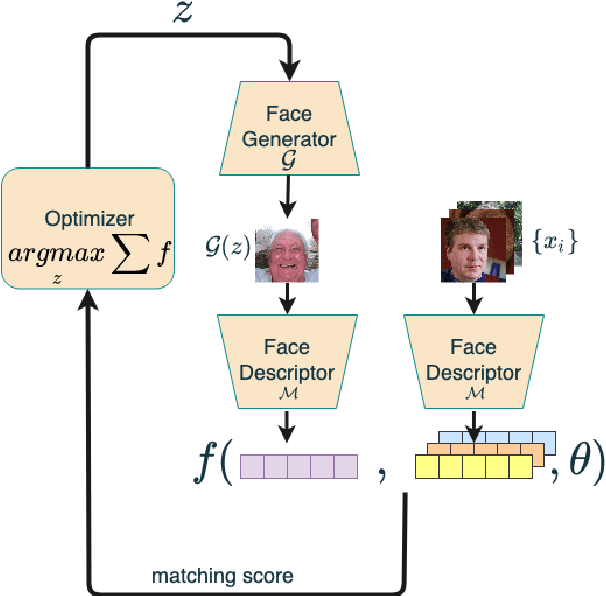


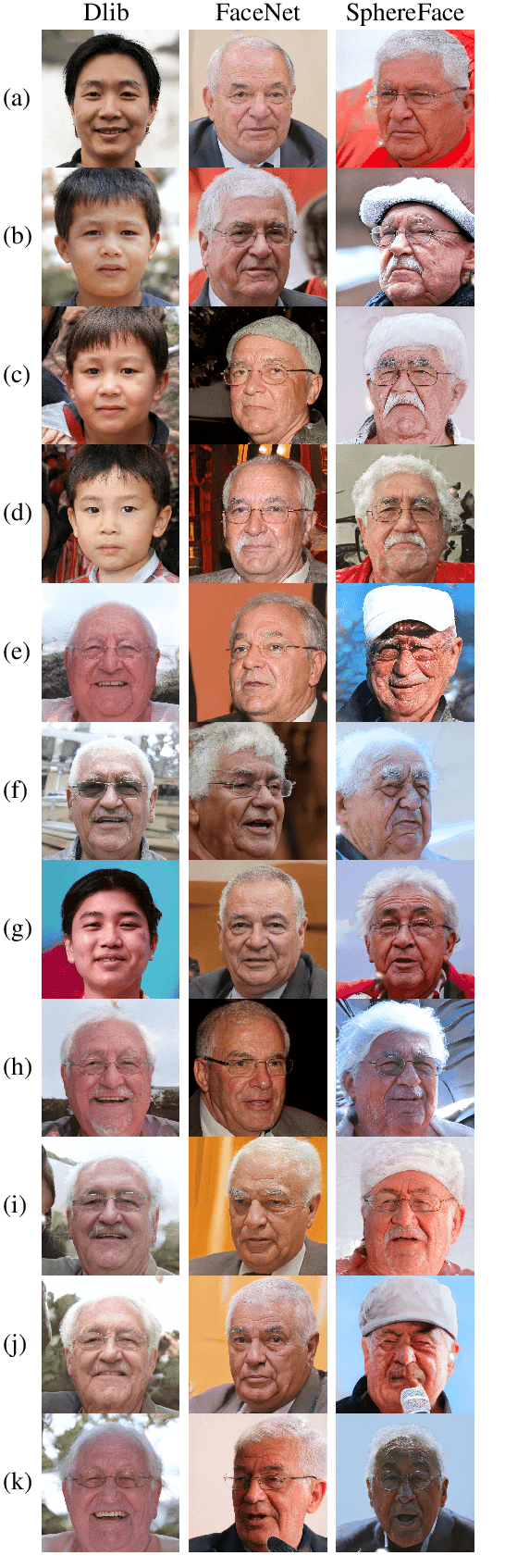
A master face is a face image that passes face-based identity-authentication for a large portion of the population. These faces can be used to impersonate, with a high probability of success, any user, without having access to any user-information. We optimize these faces, by using an evolutionary algorithm in the latent embedding space of the StyleGAN face generator. Multiple evolutionary strategies are compared, and we propose a novel approach that employs a neural network in order to direct the search in the direction of promising samples, without adding fitness evaluations. The results we present demonstrate that it is possible to obtain a high coverage of the LFW identities (over 40%) with less than 10 master faces, for three leading deep face recognition systems.
Model-Constrained Deep Learning Approaches for Inverse Problems
May 25, 2021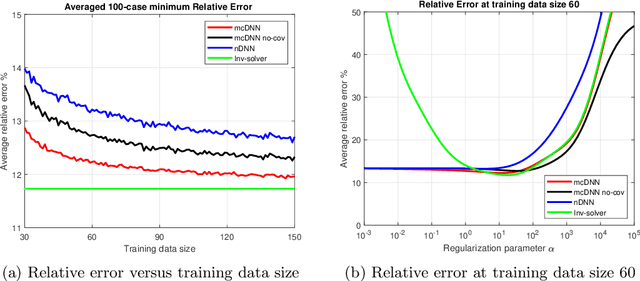
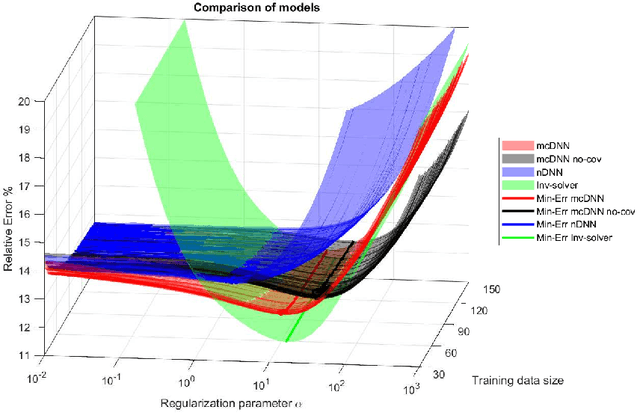
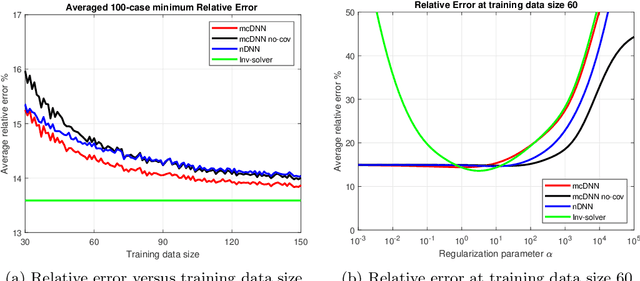
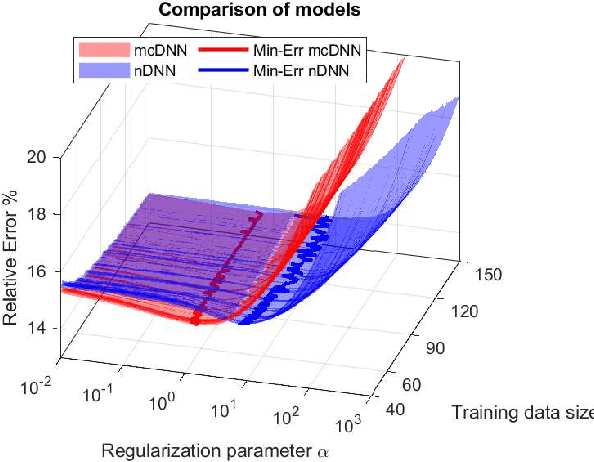
Deep Learning (DL), in particular deep neural networks (DNN), by design is purely data-driven and in general does not require physics. This is the strength of DL but also one of its key limitations when applied to science and engineering problems in which underlying physical properties (such as stability, conservation, and positivity) and desired accuracy need to be achieved. DL methods in their original forms are not capable of respecting the underlying mathematical models or achieving desired accuracy even in big-data regimes. On the other hand, many data-driven science and engineering problems, such as inverse problems, typically have limited experimental or observational data, and DL would overfit the data in this case. Leveraging information encoded in the underlying mathematical models, we argue, not only compensates missing information in low data regimes but also provides opportunities to equip DL methods with the underlying physics and hence obtaining higher accuracy. This short communication introduces several model-constrained DL approaches (including both feed-forward DNN and autoencoders) that are capable of learning not only information hidden in the training data but also in the underlying mathematical models to solve inverse problems. We present and provide intuitions for our formulations for general nonlinear problems. For linear inverse problems and linear networks, the first order optimality conditions show that our model-constrained DL approaches can learn information encoded in the underlying mathematical models, and thus can produce consistent or equivalent inverse solutions, while naive purely data-based counterparts cannot.
Few-Sample Named Entity Recognition for Security Vulnerability Reports by Fine-Tuning Pre-Trained Language Models
Aug 14, 2021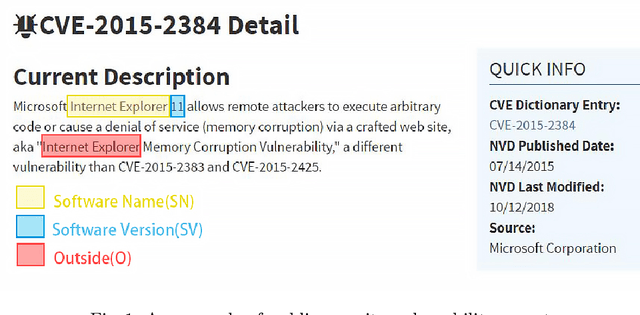

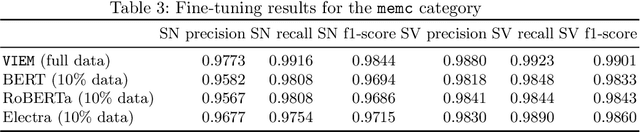
Public security vulnerability reports (e.g., CVE reports) play an important role in the maintenance of computer and network systems. Security companies and administrators rely on information from these reports to prioritize tasks on developing and deploying patches to their customers. Since these reports are unstructured texts, automatic information extraction (IE) can help scale up the processing by converting the unstructured reports to structured forms, e.g., software names and versions and vulnerability types. Existing works on automated IE for security vulnerability reports often rely on a large number of labeled training samples. However, creating massive labeled training set is both expensive and time consuming. In this work, for the first time, we propose to investigate this problem where only a small number of labeled training samples are available. In particular, we investigate the performance of fine-tuning several state-of-the-art pre-trained language models on our small training dataset. The results show that with pre-trained language models and carefully tuned hyperparameters, we have reached or slightly outperformed the state-of-the-art system on this task. Consistent with previous two-step process of first fine-tuning on main category and then transfer learning to others as in [7], if otherwise following our proposed approach, the number of required labeled samples substantially decrease in both stages: 90% reduction in fine-tuning from 5758 to 576,and 88.8% reduction in transfer learning with 64 labeled samples per category. Our experiments thus demonstrate the effectiveness of few-sample learning on NER for security vulnerability report. This result opens up multiple research opportunities for few-sample learning for security vulnerability reports, which is discussed in the paper. Code: https://github.com/guanqun-yang/FewVulnerability.
Imposing Relation Structure in Language-Model Embeddings Using Contrastive Learning
Sep 04, 2021
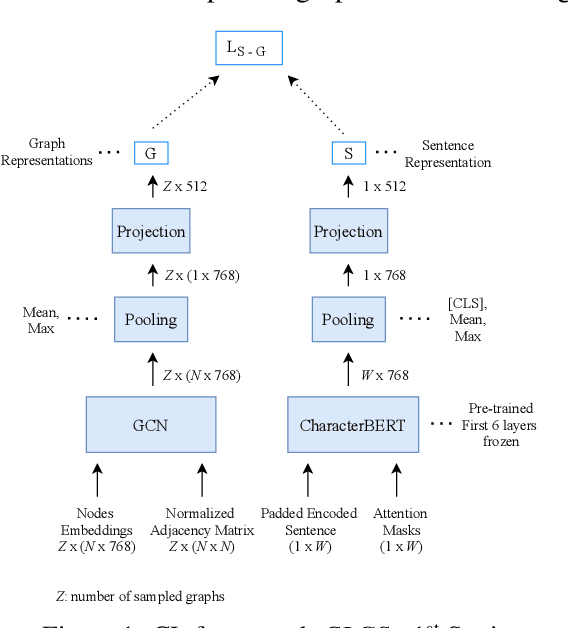
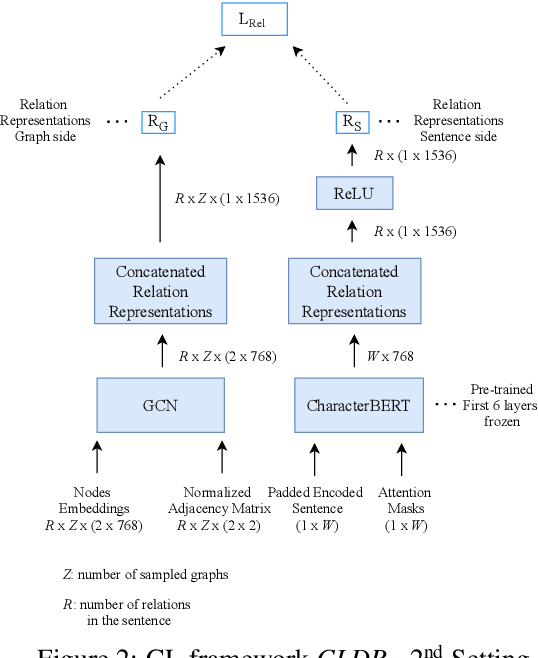
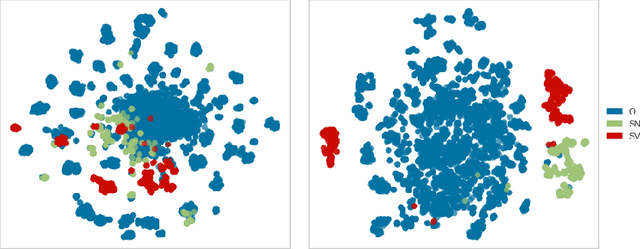
Though language model text embeddings have revolutionized NLP research, their ability to capture high-level semantic information, such as relations between entities in text, is limited. In this paper, we propose a novel contrastive learning framework that trains sentence embeddings to encode the relations in a graph structure. Given a sentence (unstructured text) and its graph, we use contrastive learning to impose relation-related structure on the token-level representations of the sentence obtained with a CharacterBERT (El Boukkouri et al.,2020) model. The resulting relation-aware sentence embeddings achieve state-of-the-art results on the relation extraction task using only a simple KNN classifier, thereby demonstrating the success of the proposed method. Additional visualization by a tSNE analysis shows the effectiveness of the learned representation space compared to baselines. Furthermore, we show that we can learn a different space for named entity recognition, again using a contrastive learning objective, and demonstrate how to successfully combine both representation spaces in an entity-relation task.
Direct information transfer rate optimisation for SSVEP-based BCI
Jul 19, 2019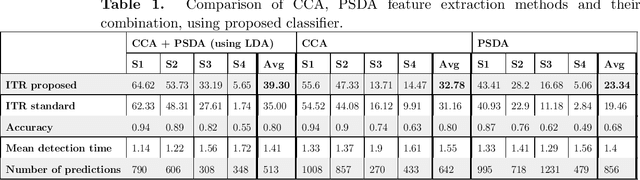
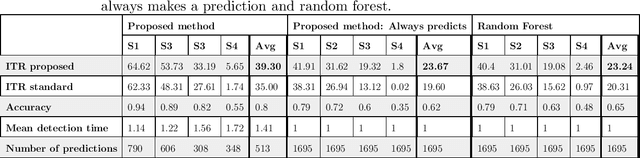
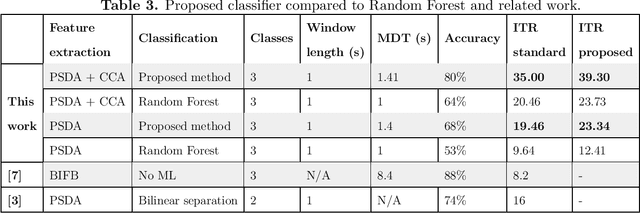
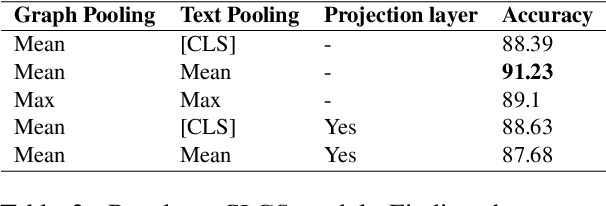
In this work, a classification method for SSVEP-based BCI is proposed. The classification method uses features extracted by traditional SSVEP-based BCI methods and finds optimal discrimination thresholds for each feature to classify the targets. Optimising the thresholds is formalised as a maximisation task of a performance measure of BCIs called information transfer rate (ITR). However, instead of the standard method of calculating ITR, which makes certain assumptions about the data, a more general formula is derived to avoid incorrect ITR calculation when the standard assumptions are not met. This allows the optimal discrimination thresholds to be automatically calculated and thus eliminates the need for manual parameter selection or performing computationally expensive grid searches. The proposed method shows good performance in classifying targets of a BCI, outperforming previously reported results on the same dataset by a factor of 2 in terms of ITR. The highest achieved ITR on the used dataset was 62 bit/min. The proposed method also provides a way to reduce false classifications, which is important in real-world applications.
Using Social Media Background to Improve Cold-start Recommendation Deep Models
Jun 04, 2021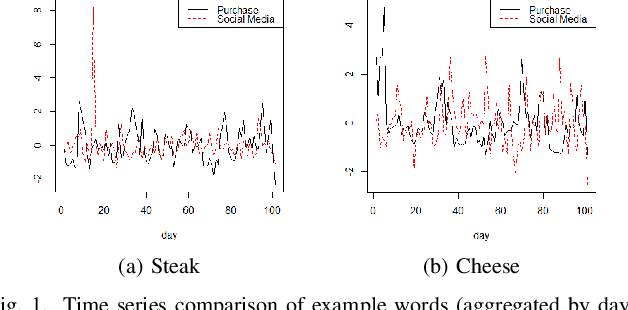
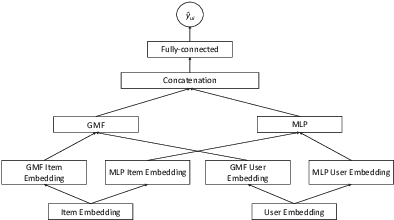
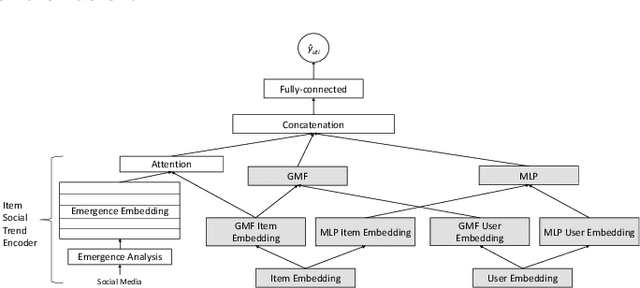
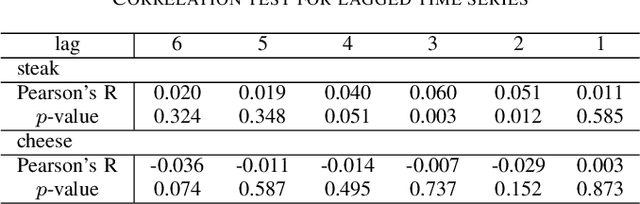
In recommender systems, a cold-start problem occurs when there is no past interaction record associated with the user or item. Typical solutions to the cold-start problem make use of contextual information, such as user demographic attributes or product descriptions. A group of works have shown that social media background can help predicting temporal phenomenons such as product sales and stock price movements. In this work, our goal is to investigate whether social media background can be used as extra contextual information to improve recommendation models. Based on an existing deep neural network model, we proposed a method to represent temporal social media background as embeddings and fuse them as an extra component in the model. We conduct experimental evaluations on a real-world e-commerce dataset and a Twitter dataset. The results show that our method of fusing social media background with the existing model does generally improve recommendation performance. In some cases the recommendation accuracy measured by hit-rate@K doubles after fusing with social media background. Our findings can be beneficial for future recommender system designs that consider complex temporal information representing social interests.
Single-Server Private Linear Transformation: The Joint Privacy Case
Jun 10, 2021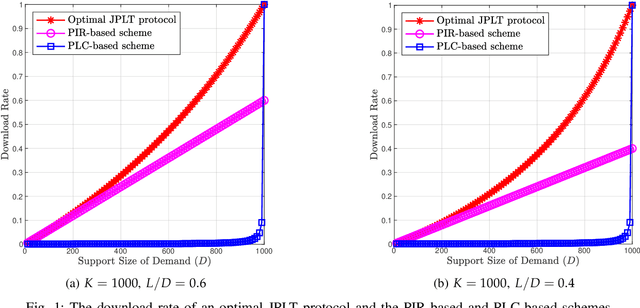
This paper introduces the problem of Private Linear Transformation (PLT) which generalizes the problems of private information retrieval and private linear computation. The PLT problem includes one or more remote server(s) storing (identical copies of) $K$ messages and a user who wants to compute $L$ independent linear combinations of a $D$-subset of messages. The objective of the user is to perform the computation by downloading minimum possible amount of information from the server(s), while protecting the identities of the $D$ messages required for the computation. In this work, we focus on the single-server setting of the PLT problem when the identities of the $D$ messages required for the computation must be protected jointly. We consider two different models, depending on whether the coefficient matrix of the required $L$ linear combinations generates a Maximum Distance Separable (MDS) code. We prove that the capacity for both models is given by $L/(K-D+L)$, where the capacity is defined as the supremum of all achievable download rates. Our converse proofs are based on linear-algebraic and information-theoretic arguments that establish connections between PLT schemes and linear codes. We also present an achievability scheme for each of the models being considered.
OFDM-guided Deep Joint Source Channel Coding for Wireless Multipath Fading Channels
Sep 11, 2021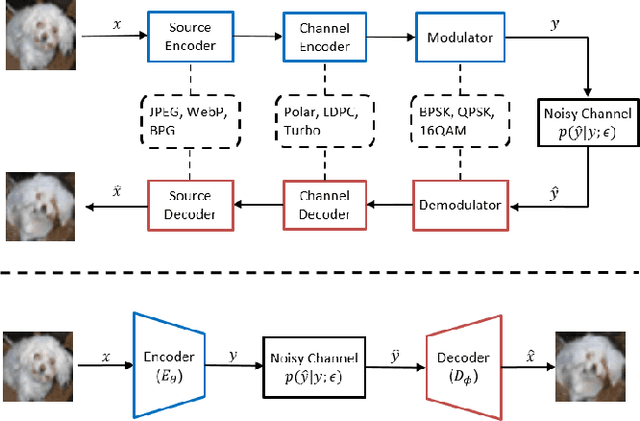
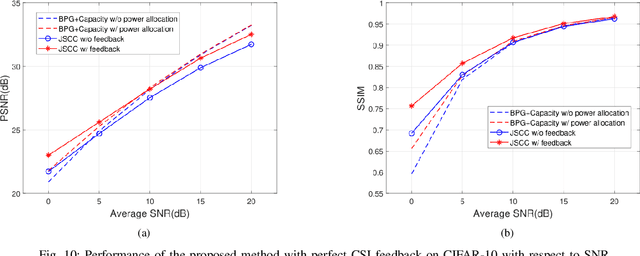

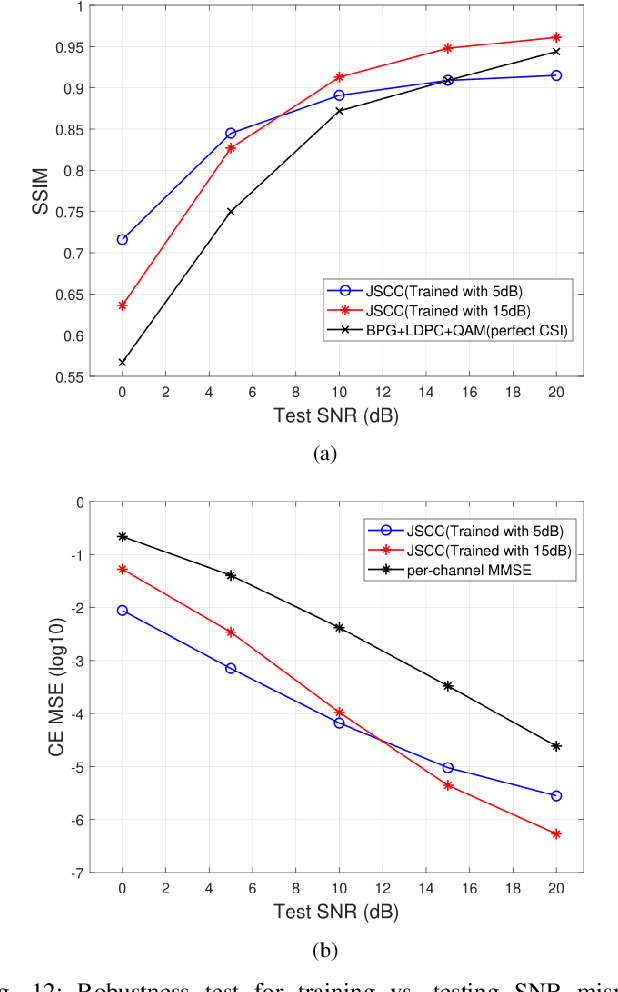
We investigate joint source channel coding (JSCC) for wireless image transmission over multipath fading channels. Inspired by recent works on deep learning based JSCC and model-based learning methods, we combine an autoencoder with orthogonal frequency division multiplexing (OFDM) to cope with multipath fading. The proposed encoder and decoder use convolutional neural networks (CNNs) and directly map the source images to complex-valued baseband samples for OFDM transmission. The multipath channel and OFDM are represented by non-trainable (deterministic) but differentiable layers so that the system can be trained end-to-end. Furthermore, our JSCC decoder further incorporates explicit channel estimation, equalization, and additional subnets to enhance the performance. The proposed method exhibits 2.5 -- 4 dB SNR gain for the equivalent image quality compared to conventional schemes that employ state-of-the-art but separate source and channel coding such as BPG and LDPC. The performance further improves when the system incorporates the channel state information (CSI) feedback. The proposed scheme is robust against OFDM signal clipping and parameter mismatch for the channel model used in training and evaluation.
HCGR: Hyperbolic Contrastive Graph Representation Learning for Session-based Recommendation
Jul 06, 2021

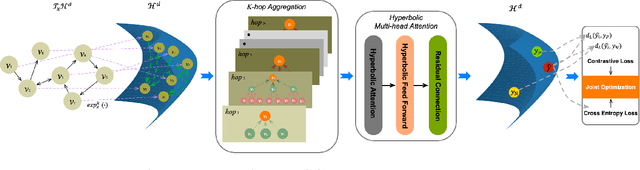
Session-based recommendation (SBR) learns users' preferences by capturing the short-term and sequential patterns from the evolution of user behaviors. Among the studies in the SBR field, graph-based approaches are a relatively powerful kind of way, which generally extract item information by message aggregation under Euclidean space. However, such methods can't effectively extract the hierarchical information contained among consecutive items in a session, which is critical to represent users' preferences. In this paper, we present a hyperbolic contrastive graph recommender (HCGR), a principled session-based recommendation framework involving Lorentz hyperbolic space to adequately capture the coherence and hierarchical representations of the items. Within this framework, we design a novel adaptive hyperbolic attention computation to aggregate the graph message of each user's preference in a session-based behavior sequence. In addition, contrastive learning is leveraged to optimize the item representation by considering the geodesic distance between positive and negative samples in hyperbolic space. Extensive experiments on four real-world datasets demonstrate that HCGR consistently outperforms state-of-the-art baselines by 0.43$\%$-28.84$\%$ in terms of $HitRate$, $NDCG$ and $MRR$.
Rapid detection and recognition of whole brain activity in a freely behaving Caenorhabditis elegans
Sep 23, 2021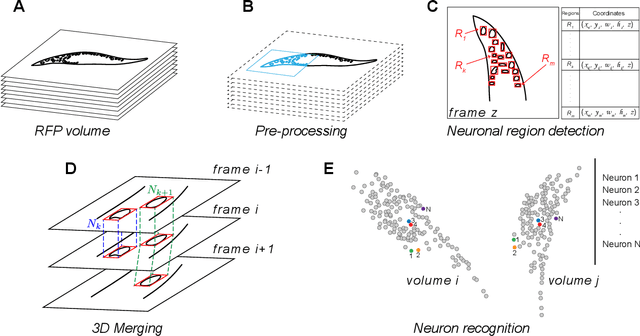

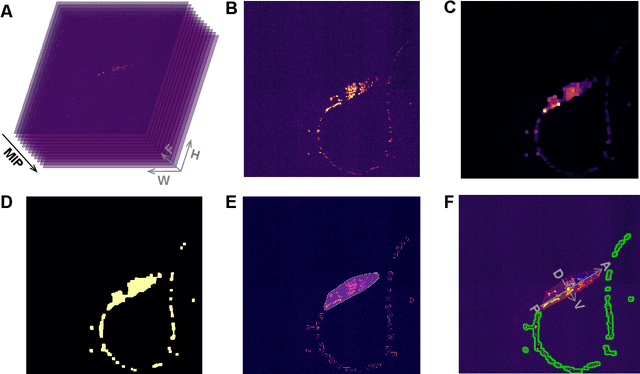
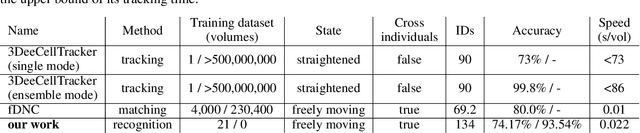
Advanced volumetric imaging methods and genetically encoded activity indicators have permitted a comprehensive characterization of whole brain activity at single neuron resolution in \textit{Caenorhabditis elegans}. The constant motion and deformation of the mollusc nervous system, however, impose a great challenge for a consistent identification of densely packed neurons in a behaving animal. Here, we propose a cascade solution for long-term and rapid recognition of head ganglion neurons in a freely moving \textit{C. elegans}. First, potential neuronal regions from a stack of fluorescence images are detected by a deep learning algorithm. Second, 2 dimensional neuronal regions are fused into 3 dimensional neuron entities. Third, by exploiting the neuronal density distribution surrounding a neuron and relative positional information between neurons, a multi-class artificial neural network transforms engineered neuronal feature vectors into digital neuronal identities. Under the constraint of a small number (20-40 volumes) of training samples, our bottom-up approach is able to process each volume - $1024 \times 1024 \times 18$ in voxels - in less than 1 second and achieves an accuracy of $91\%$ in neuronal detection and $74\%$ in neuronal recognition. Our work represents an important development towards a rapid and fully automated algorithm for decoding whole brain activity underlying natural animal behaviors.