 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fair Representations by Compression
May 28, 2021


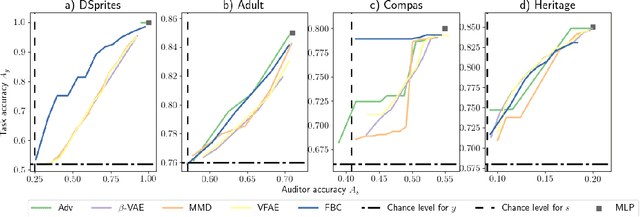
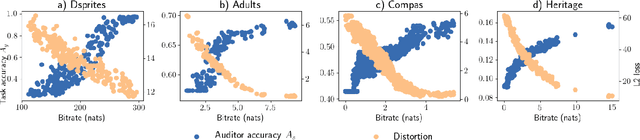
Organizations that collect and sell data face increasing scrutiny for the discriminatory use of data. We propose a novel unsupervised approach to transform data into a compressed binary representation independent of sensitive attributes. We show that in an information bottleneck framework, a parsimonious representation should filter out information related to sensitive attributes if they are provided directly to the decoder. Empirical results show that the proposed method, \textbf{FBC}, achieves state-of-the-art accuracy-fairness trade-off. Explicit control of the entropy of the representation bit stream allows the user to move smoothly and simultaneously along both rate-distortion and rate-fairness curves. \end{abstract}
Stochastic functional analysis with applications to robust machine learning
Oct 04, 2021
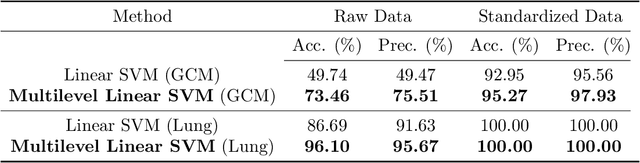
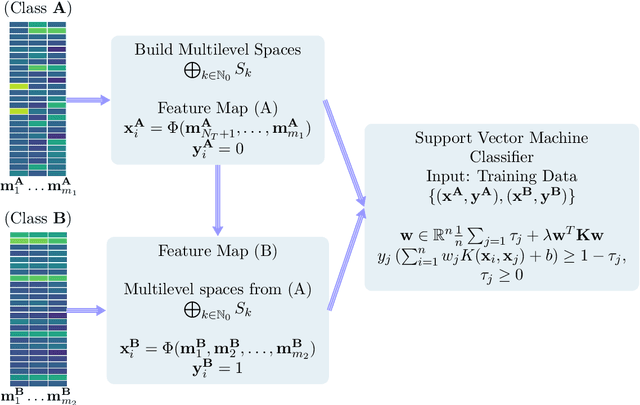
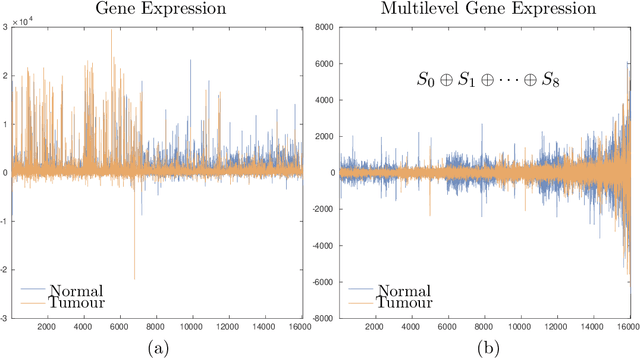
It is well-known that machine learning protocols typically under-utilize information on the probability distributions of feature vectors and related data, and instead directly compute regression or classification functions of feature vectors. In this paper we introduce a set of novel features for identifying underlying stochastic behavior of input data using the Karhunen-Lo\'{e}ve (KL) expansion, where classification is treated as detection of anomalies from a (nominal) signal class. These features are constructed from the recent Functional Data Analysis (FDA) theory for anomaly detection. The related signal decomposition is an exact hierarchical tensor product expansion with known optimality properties for approximating stochastic processes (random fields) with finite dimensional function spaces. In principle these primary low dimensional spaces can capture most of the stochastic behavior of `underlying signals' in a given nominal class, and can reject signals in alternative classes as stochastic anomalies. Using a hierarchical finite dimensional KL expansion of the nominal class, a series of orthogonal nested subspaces is constructed for detecting anomalous signal components. Projection coefficients of input data in these subspaces are then used to train an ML classifier. However, due to the split of the signal into nominal and anomalous projection components, clearer separation surfaces of the classes arise. In fact we show that with a sufficiently accurate estimation of the covariance structure of the nominal class, a sharp classification can be obtained. We carefully formulate this concept and demonstrate it on a number of high-dimensional datasets in cancer diagnostics. This method leads to a significant increase in precision and accuracy over the current top benchmarks for the Global Cancer Map (GCM) gene expression network dataset.
LexSubCon: Integrating Knowledge from Lexical Resources into Contextual Embeddings for Lexical Substitution
Jul 11, 2021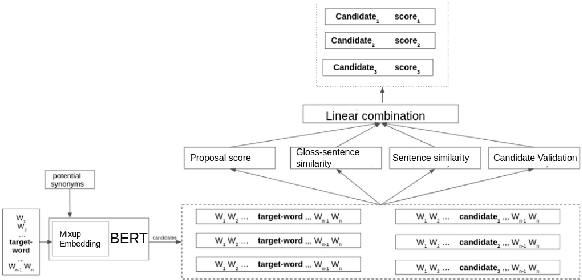
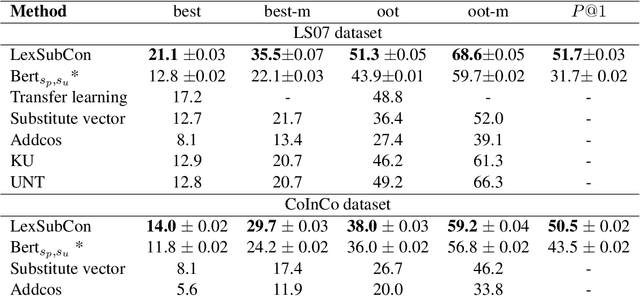
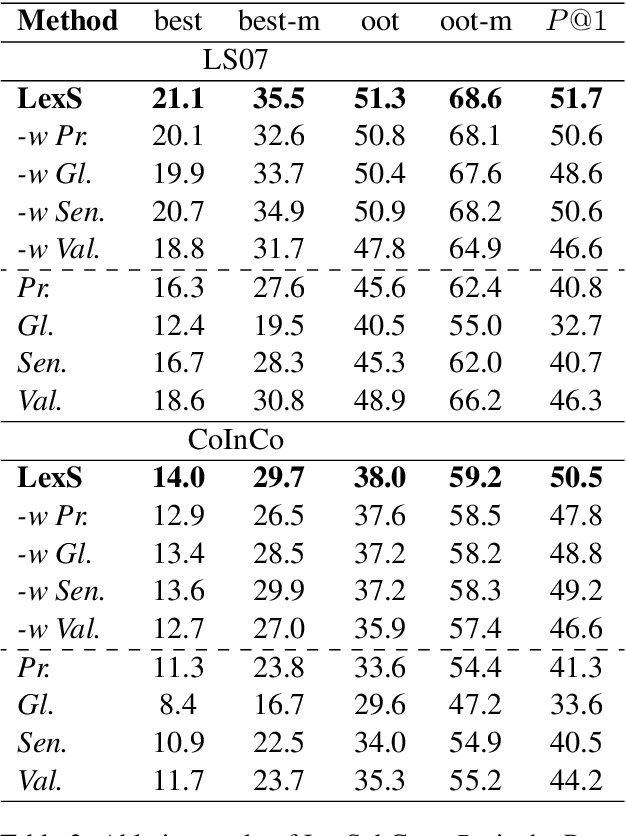
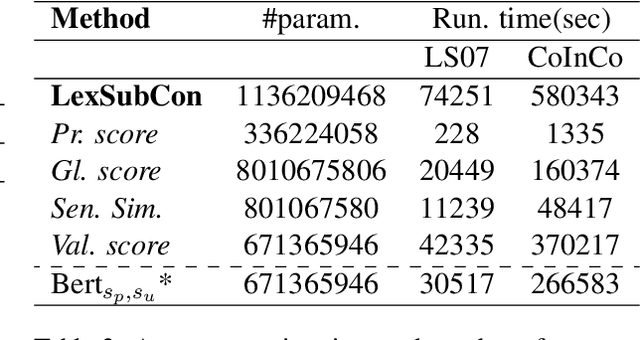
Lexical substitution is the task of generating meaningful substitutes for a word in a given textual context. Contextual word embedding models have achieved state-of-the-art results in the lexical substitution task by relying on contextual information extracted from the replaced word within the sentence. However, such models do not take into account structured knowledge that exists in external lexical databases. We introduce LexSubCon, an end-to-end lexical substitution framework based on contextual embedding models that can identify highly accurate substitute candidates. This is achieved by combining contextual information with knowledge from structured lexical resources. Our approach involves: (i) introducing a novel mix-up embedding strategy in the creation of the input embedding of the target word through linearly interpolating the pair of the target input embedding and the average embedding of its probable synonyms; (ii) considering the similarity of the sentence-definition embeddings of the target word and its proposed candidates; and, (iii) calculating the effect of each substitution in the semantics of the sentence through a fine-tuned sentence similarity model. Our experiments show that LexSubCon outperforms previous state-of-the-art methods on LS07 and CoInCo benchmark datasets that are widely used for lexical substitution tasks.
Fast Wireless Sensor Anomaly Detection based on Data Stream in Edge Computing Enabled Smart Greenhouse
Jul 28, 2021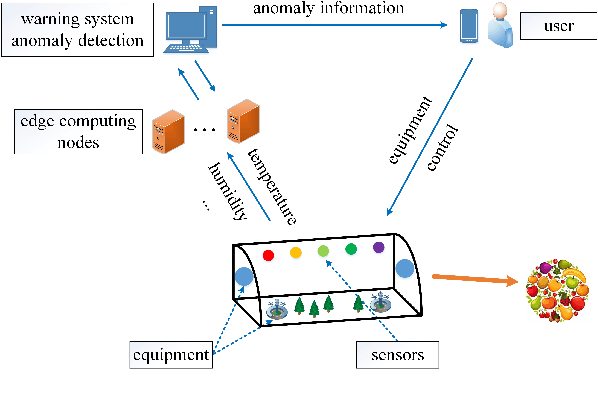
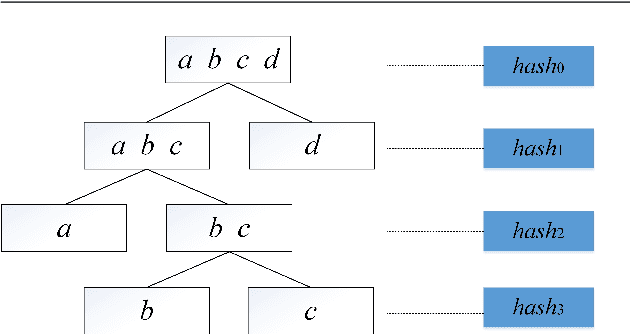

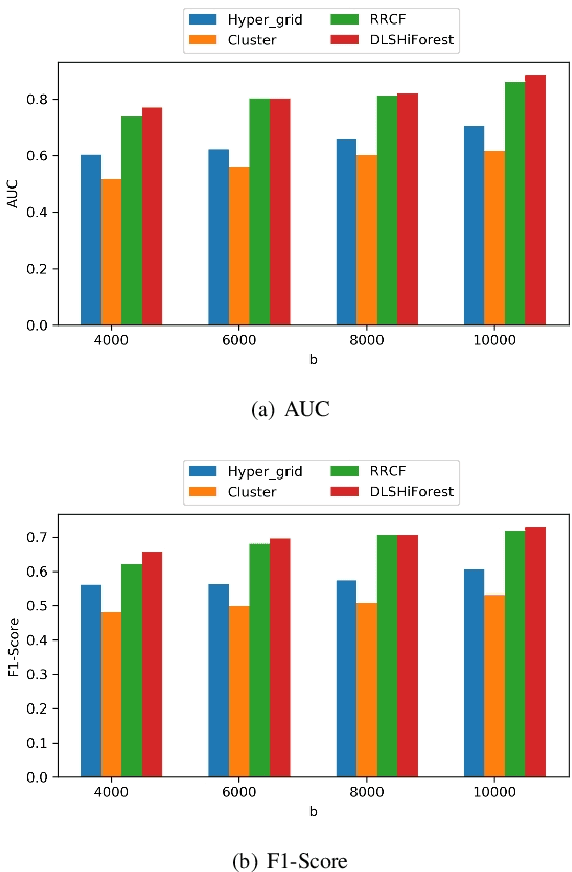
Edge computing enabled smart greenhouse is a representative application of Internet of Things technology, which can monitor the environmental information in real time and employ the information to contribute to intelligent decision-making. In the process, anomaly detection for wireless sensor data plays an important role. However, traditional anomaly detection algorithms originally designed for anomaly detection in static data have not properly considered the inherent characteristics of data stream produced by wireless sensor such as infiniteness, correlations and concept drift, which may pose a considerable challenge on anomaly detection based on data stream, and lead to low detection accuracy and efficiency. First, data stream usually generates quickly which means that it is infinite and enormous, so any traditional off-line anomaly detection algorithm that attempts to store the whole dataset or to scan the dataset multiple times for anomaly detection will run out of memory space. Second, there exist correlations among different data streams, which traditional algorithms hardly consider. Third, the underlying data generation process or data distribution may change over time. Thus, traditional anomaly detection algorithms with no model update will lose their effects. Considering these issues, a novel method (called DLSHiForest) on basis of Locality-Sensitive Hashing and time window technique in this paper is proposed to solve these problems while achieving accurate and efficient detection. Comprehensive experiments are executed using real-world agricultural greenhouse dataset to demonstrate the feasibility of our approach. Experimental results show that our proposal is practicable in addressing challenges of traditional anomaly detection while ensuring accuracy and efficiency.
A Novel CropdocNet for Automated Potato Late Blight Disease Detection from the Unmanned Aerial Vehicle-based Hyperspectral Imagery
Jul 28, 2021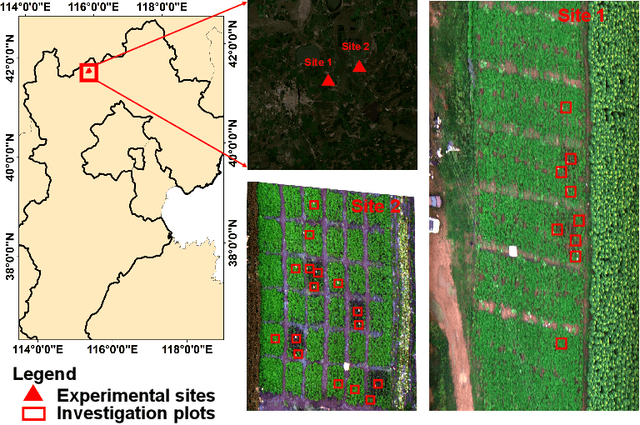

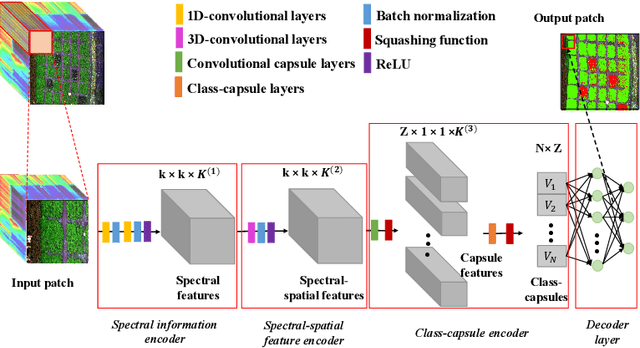
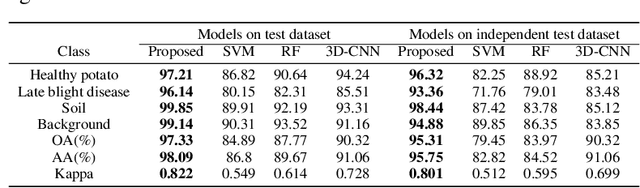
Late blight disease is one of the most destructive diseases in potato crop, leading to serious yield losses globally. Accurate diagnosis of the disease at early stage is critical for precision disease control and management. Current farm practices in crop disease diagnosis are based on manual visual inspection, which is costly, time consuming, subject to individual bias. Recent advances in imaging sensors (e.g. RGB, multiple spectral and hyperspectral cameras), remote sensing and machine learning offer the opportunity to address this challenge. Particularly, hyperspectral imagery (HSI) combining with machine learning/deep learning approaches is preferable for accurately identifying specific plant diseases because the HSI consists of a wide range of high-quality reflectance information beyond human vision, capable of capturing both spectral-spatial information. The proposed method considers the potential disease specific reflectance radiation variance caused by the canopy structural diversity, introduces the multiple capsule layers to model the hierarchical structure of the spectral-spatial disease attributes with the encapsulated features to represent the various classes and the rotation invariance of the disease attributes in the feature space. We have evaluated the proposed method with the real UAV-based HSI data under the controlled field conditions. The effectiveness of the hierarchical features has been quantitatively assessed and compared with the existing representative machine learning/deep learning methods. The experiment results show that the proposed model significantly improves the accuracy performance when considering hierarchical-structure of spectral-spatial features, comparing to the existing methods only using spectral, or spatial or spectral-spatial features without consider hierarchical-structure of spectral-spatial features.
Heterogeneous Noisy Short Signal Camouflage in Multi-Domain Environment Decision-Making
Jun 02, 2021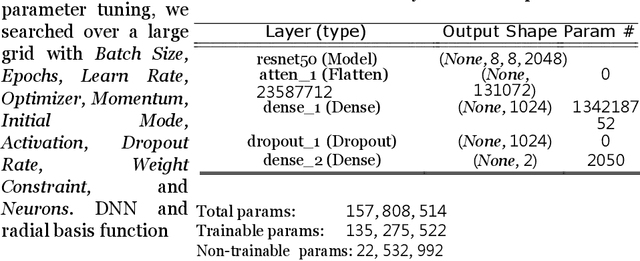
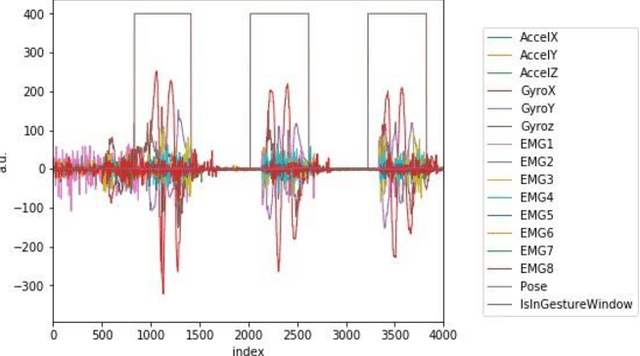
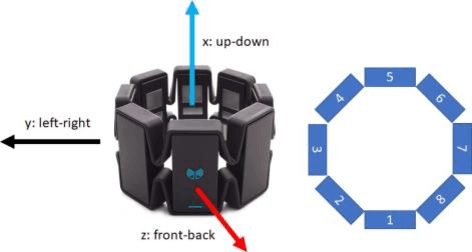
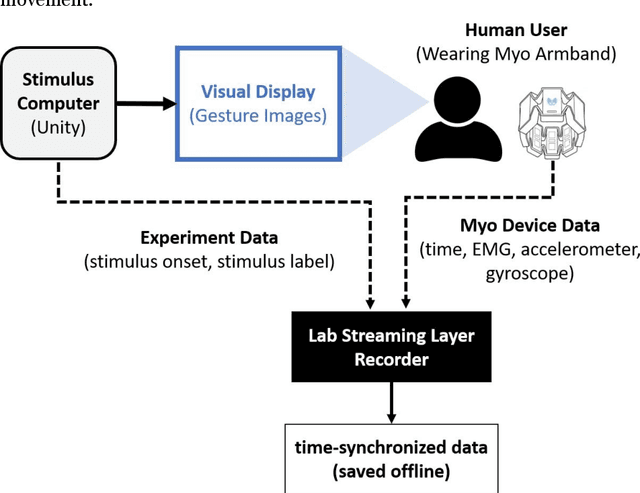
Data transmission between two or more digital devices in industry and government demands secure and agile technology. Digital information distribution often requires deployment of Internet of Things (IoT) devices and Data Fusion techniques which have also gained popularity in both, civilian and military environments, such as, emergence of Smart Cities and Internet of Battlefield Things (IoBT). This usually requires capturing and consolidating data from multiple sources. Because datasets do not necessarily originate from identical sensors, fused data typically results in a complex Big Data problem. Due to potentially sensitive nature of IoT datasets, Blockchain technology is used to facilitate secure sharing of IoT datasets, which allows digital information to be distributed, but not copied. However, blockchain has several limitations related to complexity, scalability, and excessive energy consumption. We propose an approach to hide information (sensor signal) by transforming it to an image or an audio signal. In one of the latest attempts to the military modernization, we investigate sensor fusion approach by investigating the challenges of enabling an intelligent identification and detection operation and demonstrates the feasibility of the proposed Deep Learning and Anomaly Detection models that can support future application for specific hand gesture alert system from wearable devices.
* Published at: http://www.ibai-publishing.org/journal/issue_massdata/2020_september/massdata_11_1_3_26.php. arXiv admin note: substantial text overlap with arXiv:2106.01497
Goal-Aware Neural SAT Solver
Jun 14, 2021Modern neural networks obtain information about the problem and calculate the output solely from the input values. We argue that it is not always optimal, and the network's performance can be significantly improved by augmenting it with a query mechanism that allows the network to make several solution trials at run time and get feedback on the loss value on each trial. To demonstrate the capabilities of the query mechanism, we formulate an unsupervised (not dependant on labels) loss function for Boolean Satisfiability Problem (SAT) and theoretically show that it allows the network to extract rich information about the problem. We then propose a neural SAT solver with a query mechanism called QuerySAT and show that it outperforms the neural baseline on a wide range of SAT tasks and the classical baselines on SHA-1 preimage attack and 3-SAT task.
Disrupting Adversarial Transferability in Deep Neural Networks
Aug 27, 2021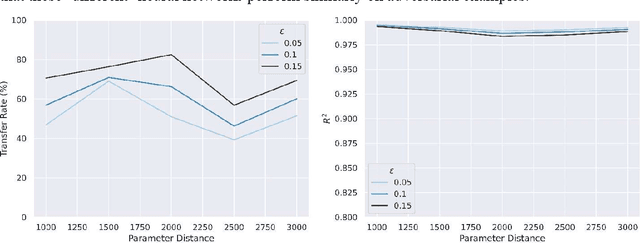
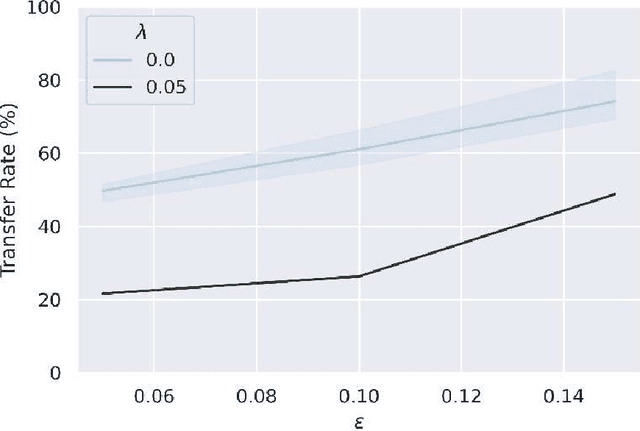
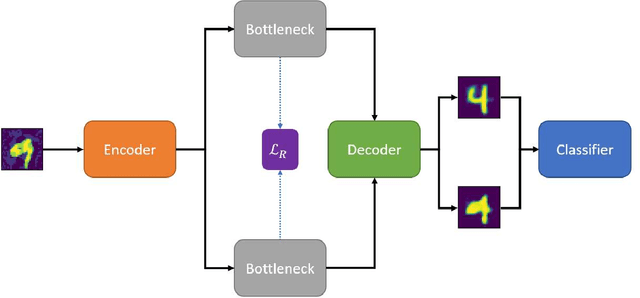
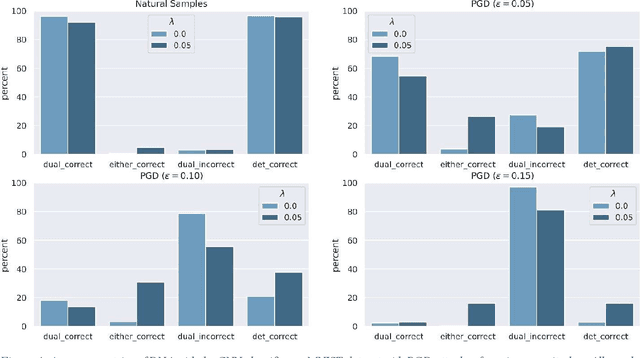
Adversarial attack transferability is a well-recognized phenomenon in deep learning. Prior work has partially explained transferability by recognizing common adversarial subspaces and correlations between decision boundaries, but we have found little explanation in the literature beyond this. In this paper, we propose that transferability between seemingly different models is due to a high linear correlation between features that different deep neural networks extract. In other words, two models trained on the same task that are seemingly distant in the parameter space likely extract features in the same fashion, just with trivial shifts and rotations between the latent spaces. Furthermore, we show how applying a feature correlation loss, which decorrelates the extracted features in a latent space, can drastically reduce the transferability of adversarial attacks between models, suggesting that the models complete tasks in semantically different ways. Finally, we propose a Dual Neck Autoencoder (DNA), which leverages this feature correlation loss to create two meaningfully different encodings of input information with reduced transferability.
A Mathematical Approach to Constraining Neural Abstraction and the Mechanisms Needed to Scale to Higher-Order Cognition
Aug 12, 2021
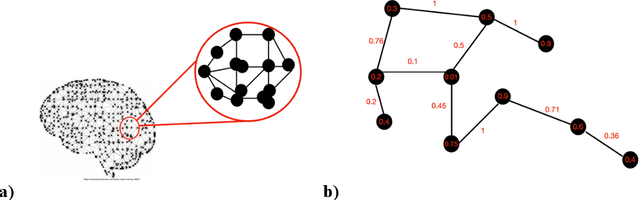

Artificial intelligence has made great strides in the last decade but still falls short of the human brain, the best-known example of intelligence. Not much is known of the neural processes that allow the brain to make the leap to achieve so much from so little beyond its ability to create knowledge structures that can be flexibly and dynamically combined, recombined, and applied in new and novel ways. This paper proposes a mathematical approach using graph theory and spectral graph theory, to hypothesize how to constrain these neural clusters of information based on eigen-relationships. This same hypothesis is hierarchically applied to scale up from the smallest to the largest clusters of knowledge that eventually lead to model building and reasoning.
Locality Relationship Constrained Multi-view Clustering Framework
Jul 11, 2021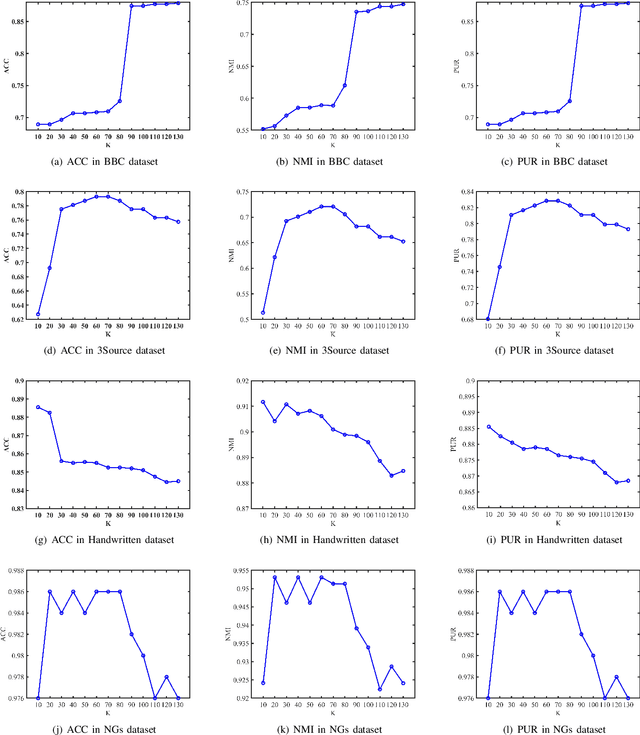
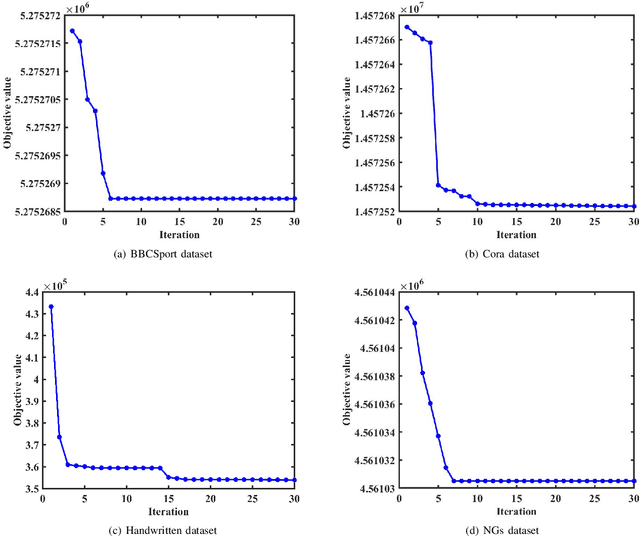
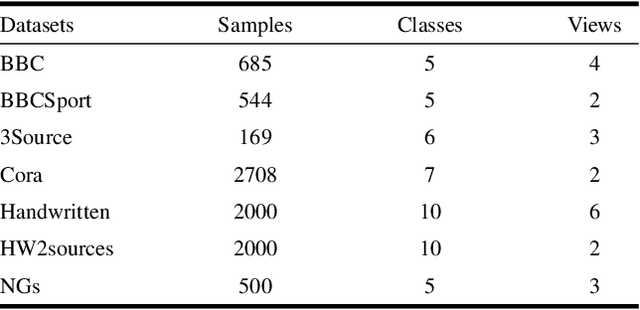
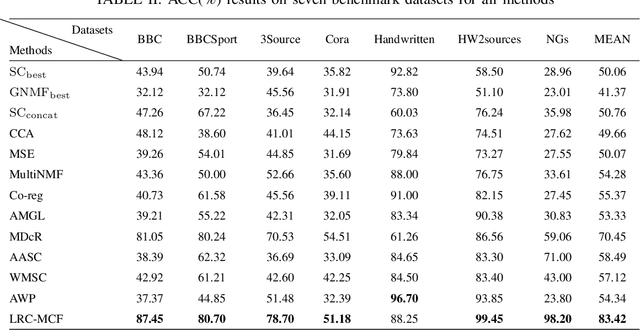
In most practical applications, it's common to utilize multiple features from different views to represent one object. Among these works, multi-view subspace-based clustering has gained extensive attention from many researchers, which aims to provide clustering solutions to multi-view data. However, most existing methods fail to take full use of the locality geometric structure and similarity relationship among samples under the multi-view scenario. To solve these issues, we propose a novel multi-view learning method with locality relationship constraint to explore the problem of multi-view clustering, called Locality Relationship Constrained Multi-view Clustering Framework (LRC-MCF). LRC-MCF aims to explore the diversity, geometric, consensus and complementary information among different views, by capturing the locality relationship information and the common similarity relationships among multiple views. Moreover, LRC-MCF takes sufficient consideration to weights of different views in finding the common-view locality structure and straightforwardly produce the final clusters. To effectually reduce the redundancy of the learned representations, the low-rank constraint on the common similarity matrix is considered additionally. To solve the minimization problem of LRC-MCF, an Alternating Direction Minimization (ADM) method is provided to iteratively calculate all variables LRC-MCF. Extensive experimental results on seven benchmark multi-view datasets validate the effectiveness of the LRC-MCF method.