 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Tailed, Multi-Headed, Spatial Dynamic Memory refined Text-to-Image Synthesis
Oct 15, 2021
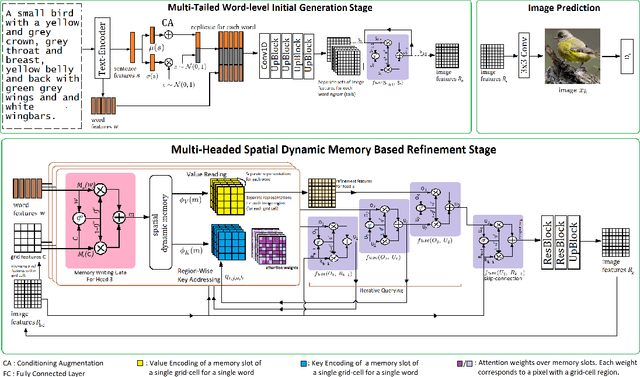


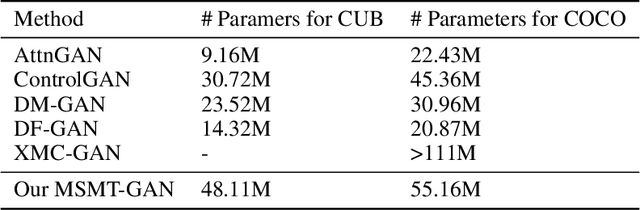
Synthesizing high-quality, realistic images from text-descriptions is a challenging task, and current methods synthesize images from text in a multi-stage manner, typically by first generating a rough initial image and then refining image details at subsequent stages. However, existing methods that follow this paradigm suffer from three important limitations. Firstly, they synthesize initial images without attempting to separate image attributes at a word-level. As a result, object attributes of initial images (that provide a basis for subsequent refinement) are inherently entangled and ambiguous in nature. Secondly, by using common text-representations for all regions, current methods prevent us from interpreting text in fundamentally different ways at different parts of an image. Different image regions are therefore only allowed to assimilate the same type of information from text at each refinement stage. Finally, current methods generate refinement features only once at each refinement stage and attempt to address all image aspects in a single shot. This single-shot refinement limits the precision with which each refinement stage can learn to improve the prior image. Our proposed method introduces three novel components to address these shortcomings: (1) An initial generation stage that explicitly generates separate sets of image features for each word n-gram. (2) A spatial dynamic memory module for refinement of images. (3) An iterative multi-headed mechanism to make it easier to improve upon multiple image aspects. Experimental results demonstrate that our Multi-Headed Spatial Dynamic Memory image refinement with our Multi-Tailed Word-level Initial Generation (MSMT-GAN) performs favourably against the previous state of the art on the CUB and COCO datasets.
Enabling Plug-and-Play and Crowdsourcing SLAM in Wireless Communication Systems
Aug 08, 2021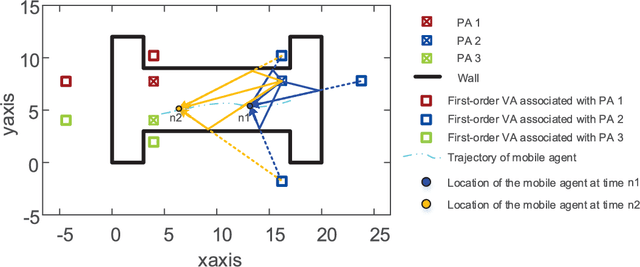
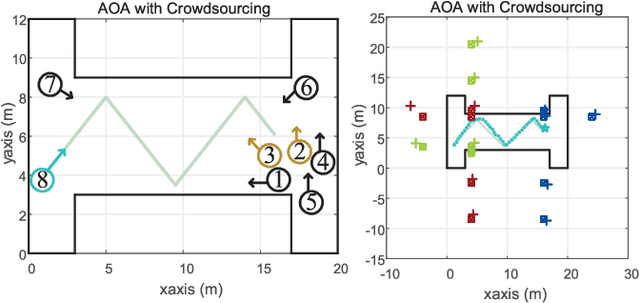
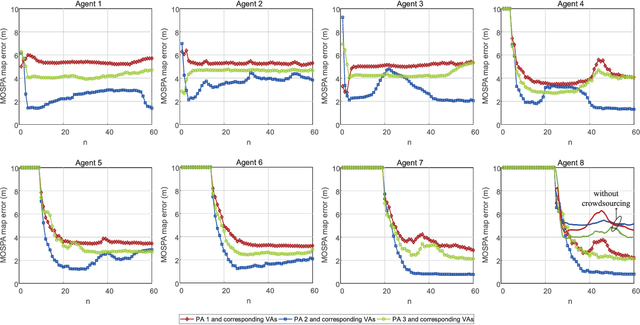
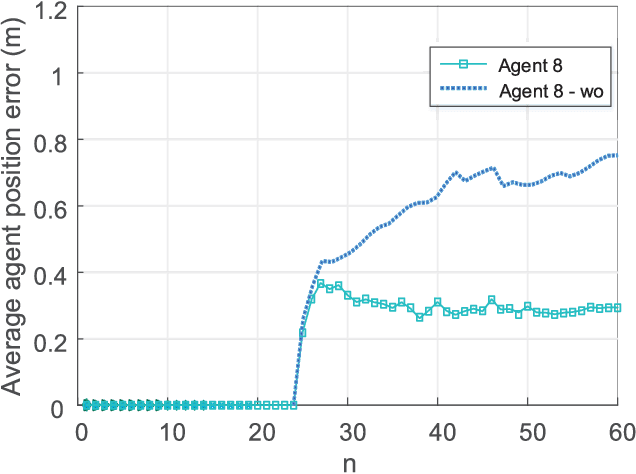
Simultaneous localization and mapping (SLAM) during communication is emerging. This technology promises to provide information on propagation environments and transceivers' location, thus creating several new services and applications for the Internet of Things and environment-aware communication. Using crowdsourcing data collected by multiple agents appears to be much potential for enhancing SLAM performance. However, the measurement uncertainties in practice and biased estimations from multiple agents may result in serious errors. This study develops a robust SLAM method with measurement plug-and-play and crowdsourcing mechanisms to address the above problems. First, we divide measurements into different categories according to their unknown biases and realize a measurement plug-and-play mechanism by extending the classic belief propagation (BP)-based SLAM method. The proposed mechanism can obtain the time-varying agent location, radio features, and corresponding measurement biases (such as clock bias, orientation bias, and received signal strength model parameters), with high accuracy and robustness in challenging scenarios without any prior information on anchors and agents. Next, we establish a probabilistic crowdsourcing-based SLAM mechanism, in which multiple agents cooperate to construct and refine the radio map in a decentralized manner. Our study presents the first BP-based crowdsourcing that resolves the "double count" and "data reliability" problems through the flexible application of probabilistic data association methods. Numerical results reveal that the crowdsourcing mechanism can further improve the accuracy of the mapping result, which, in turn, ensures the decimeter-level localization accuracy of each agent in a challenging propagation environment.
In-Vehicle False Information Attack Detection and Mitigation Framework using Machine Learning and Software Defined Networking
Jun 24, 2019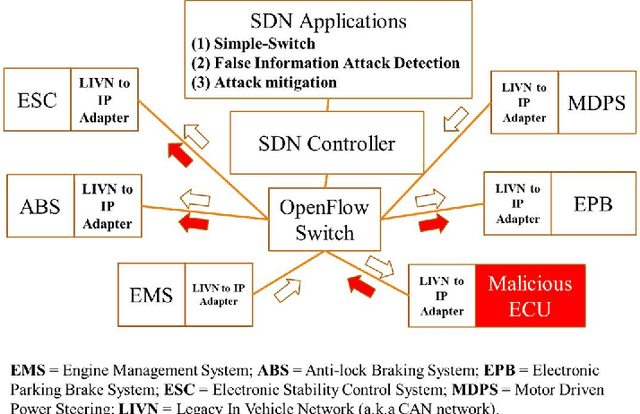
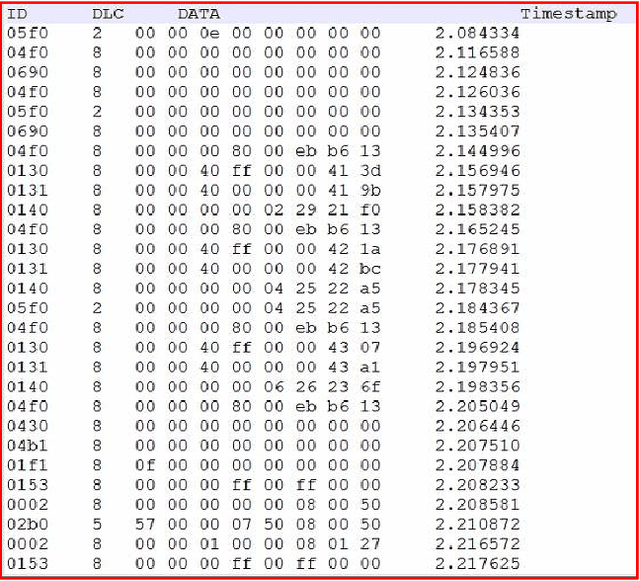
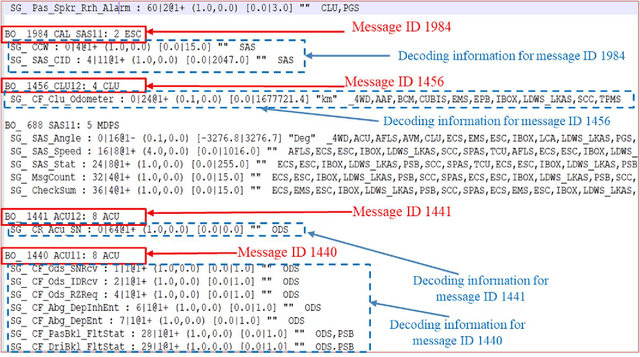
A modern vehicle contains many electronic control units (ECUs), which communicate with each other through the Controller Area Network (CAN) bus to ensure vehicle safety and performance. Emerging Connected and Automated Vehicles (CAVs) will have more ECUs and coupling between them due to the vast array of additional sensors, advanced driving features (such as lane keeping and navigation) and Vehicle-to-Everything (V2X) connectivity. As a result, CAVs will have more vulnerabilities within the in-vehicle network. In this study, we develop a software defined networking (SDN) based in-vehicle networking framework for security against false information attacks on CAN frames. We then created an attack model and attack datasets for false information attacks on brake-related ECUs in an SDN based in-vehicle network. We subsequently developed a machine-learning based false information attack/anomaly detection model for the real-time detection of anomalies within the in-vehicle network. Specifically, we utilized the concept of time-series classification and developed a Long Short-Term Memory (LSTM) based model that detects false information within the CAN data traffic. Additionally, based on our research, we highlighted policies for mitigating the effect of cyber-attacks using the SDN framework. The SDN-based attack detection model can detect false information with an accuracy, precision and recall of 95%, 95% and 87%, respectively, while satisfying the real-time communication and computational requirements.
Reinforcement Learning for Systematic FX Trading
Oct 15, 2021
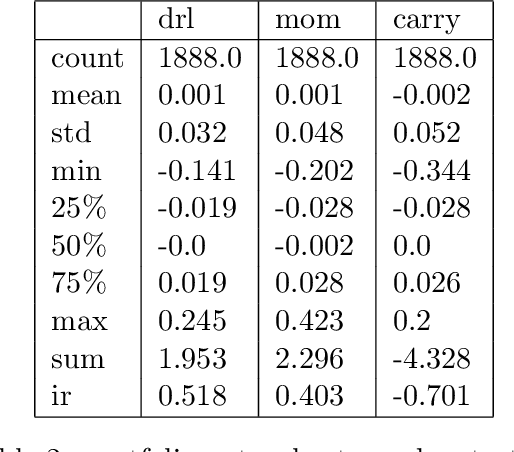
We conduct a detailed experiment on major cash fx pairs, accurately accounting for transaction and funding costs. These sources of profit and loss, including the price trends that occur in the currency markets, are made available to our recurrent reinforcement learner via a quadratic utility, which learns to target a position directly. We improve upon earlier work, by casting the problem of learning to target a risk position, in an online learning context. This online learning occurs sequentially in time, but also in the form of transfer learning. We transfer the output of radial basis function hidden processing units, whose means, covariances and overall size are determined by Gaussian mixture models, to the recurrent reinforcement learner and baseline momentum trader. Thus the intrinsic nature of the feature space is learnt and made available to the upstream models. The recurrent reinforcement learning trader achieves an annualised portfolio information ratio of 0.52 with compound return of 9.3%, net of execution and funding cost, over a 7 year test set. This is despite forcing the model to trade at the close of the trading day 5pm EST, when trading costs are statistically the most expensive. These results are comparable with the momentum baseline trader, reflecting the low interest differential environment since the the 2008 financial crisis, and very obvious currency trends since then. The recurrent reinforcement learner does nevertheless maintain an important advantage, in that the model's weights can be adapted to reflect the different sources of profit and loss variation. This is demonstrated visually by a USDRUB trading agent, who learns to target different positions, that reflect trading in the absence or presence of cost.
Deep Learning Based Hybrid Precoding in Dual-Band Communication Systems
Jul 16, 2021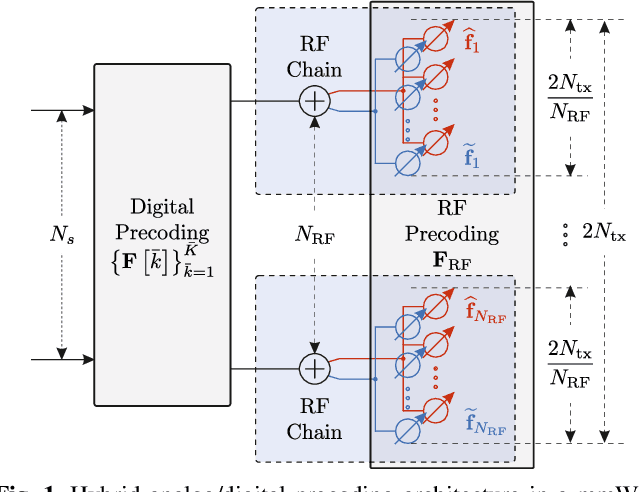
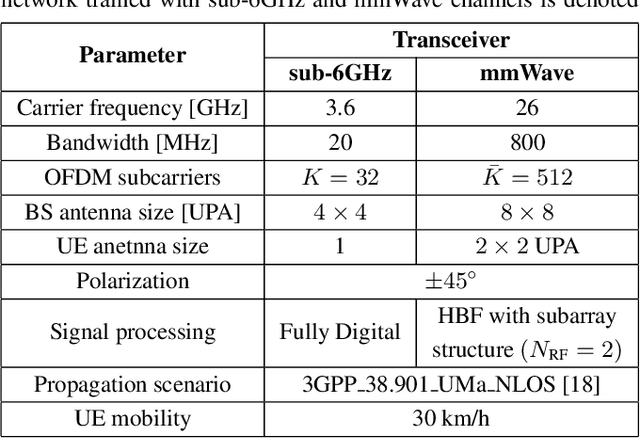
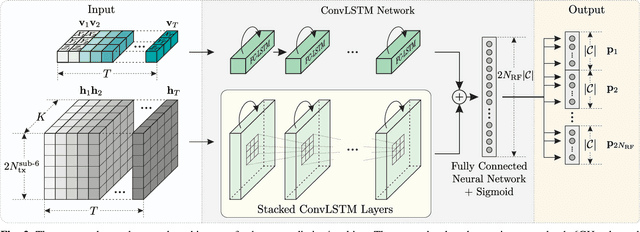
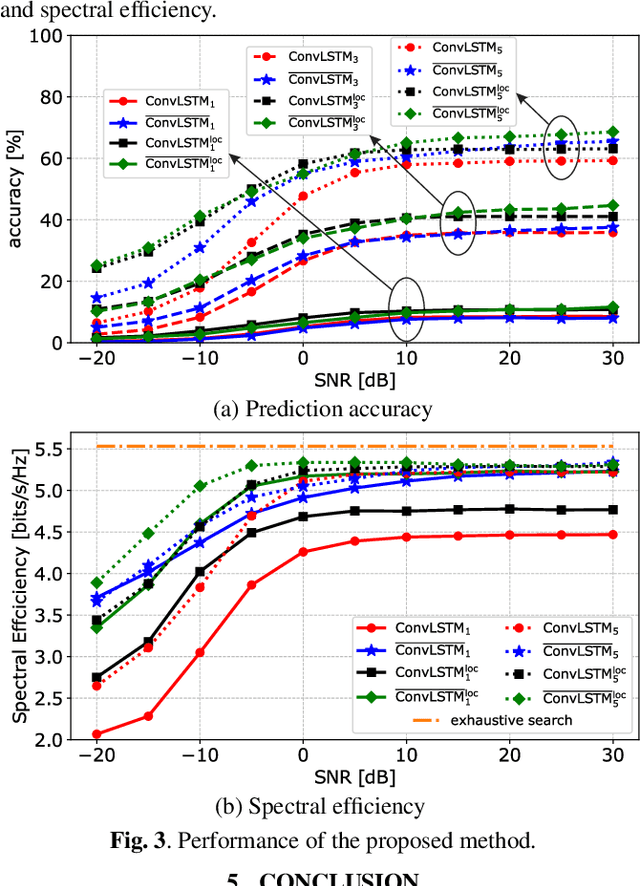
We propose a deep learning-based method that uses spatial and temporal information extracted from the sub-6GHz band to predict/track beams in the millimeter-wave (mmWave) band. In more detail, we consider a dual-band communication system operating in both the sub-6GHz and mmWave bands. The objective is to maximize the achievable mutual information in the mmWave band with a hybrid analog/digital architecture where analog precoders (RF precoders) are taken from a finite codebook. Finding a RF precoder using conventional search methods incurs large signalling overhead, and the signalling scales with the number of RF chains and the resolution of the phase shifters. To overcome the issue of large signalling overhead in the mmWave band, the proposed method exploits the spatiotemporal correlation between sub-6GHz and mmWave bands, and it predicts/tracks the RF precoders in the mmWave band from sub-6GHz channel measurements. The proposed method provides a smaller candidate set so that performing a search over that set significantly reduces the signalling overhead compared with conventional search heuristics. Simulations show that the proposed method can provide reasonable achievable rates while significantly reducing the signalling overhead.
Unsupervised clothing change adaptive person ReID
Sep 14, 2021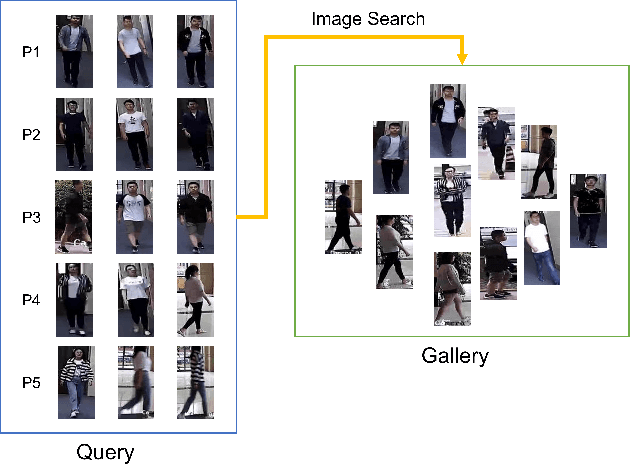
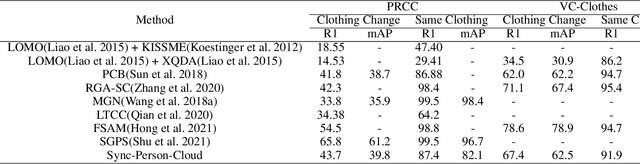
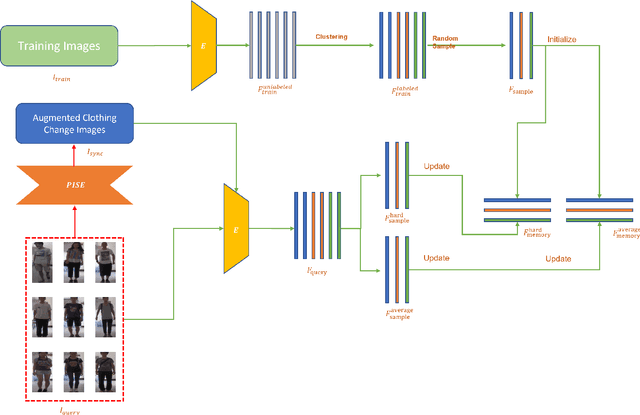
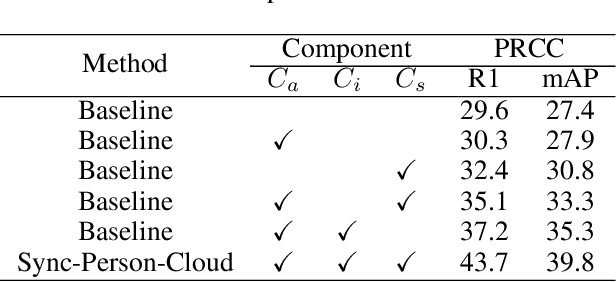
Clothing changes and lack of data labels are both crucial challenges in person ReID. For the former challenge, people may occur multiple times at different locations wearing different clothing. However, most of the current person ReID research works focus on the benchmarks in which a person's clothing is kept the same all the time. For the last challenge, some researchers try to make model learn information from a labeled dataset as a source to an unlabeled dataset. Whereas purely unsupervised training is less used. In this paper, we aim to solve both problems at the same time. We design a novel unsupervised model, Sync-Person-Cloud ReID, to solve the unsupervised clothing change person ReID problem. We developer a purely unsupervised clothing change person ReID pipeline with person sync augmentation operation and same person feature restriction. The person sync augmentation is to supply additional same person resources. These same person's resources can be used as part supervised input by same person feature restriction. The extensive experiments on clothing change ReID datasets show the out-performance of our methods.
MuCoMiD: A Multitask Convolutional Learning Framework for miRNA-Disease Association Prediction
Aug 08, 2021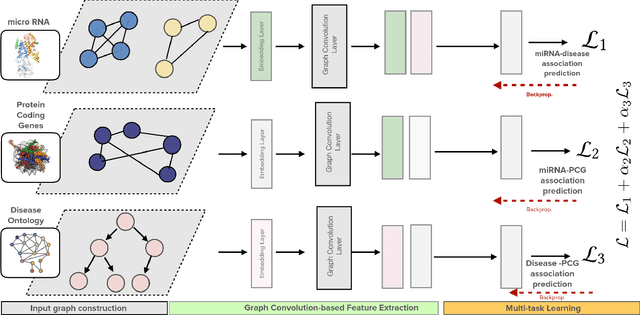


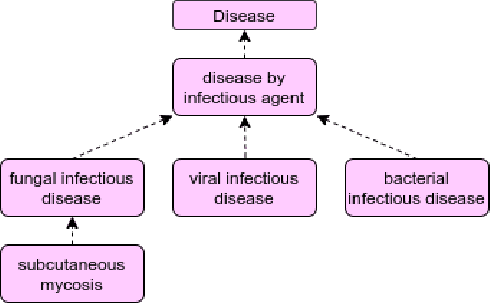
Growing evidence from recent studies implies that microRNA or miRNA could serve as biomarkers in various complex human diseases. Since wet-lab experiments are expensive and time-consuming, computational techniques for miRNA-disease association prediction have attracted a lot of attention in recent years. Data scarcity is one of the major challenges in building reliable machine learning models. Data scarcity combined with the use of pre-calculated hand-crafted input features has led to problems of overfitting and data leakage. We overcome the limitations of existing works by proposing a novel multi-tasking convolution-based approach, which we refer to as MuCoMiD. MuCoMiD allows automatic feature extraction while incorporating knowledge from 4 heterogeneous biological information sources (interactions between miRNA/diseases and protein-coding genes (PCG), miRNA family information, and disease ontology) in a multi-task setting which is a novel perspective and has not been studied before. The use of multi-channel convolutions allows us to extract expressive representations while keeping the model linear and, therefore, simple. To effectively test the generalization capability of our model, we construct large-scale experiments on standard benchmark datasets as well as our proposed larger independent test sets and case studies. MuCoMiD shows an improvement of at least 5% in 5-fold CV evaluation on HMDDv2.0 and HMDDv3.0 datasets and at least 49% on larger independent test sets with unseen miRNA and diseases over state-of-the-art approaches. We share our code for reproducibility and future research at https://git.l3s.uni-hannover.de/dong/cmtt.
Weak Signals in the Mobility Landscape: Car Sharing in Ten European Cities
Sep 20, 2021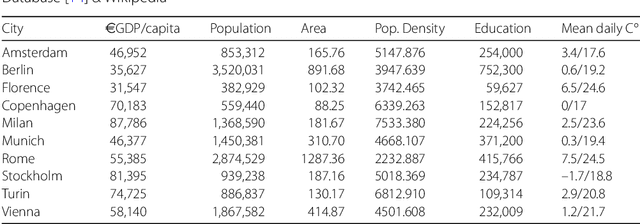

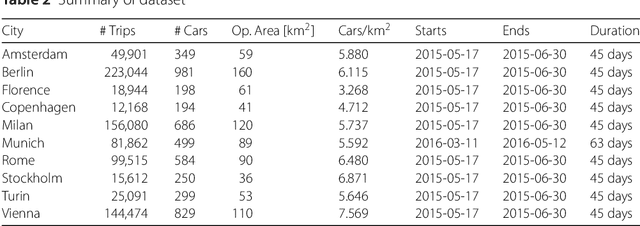
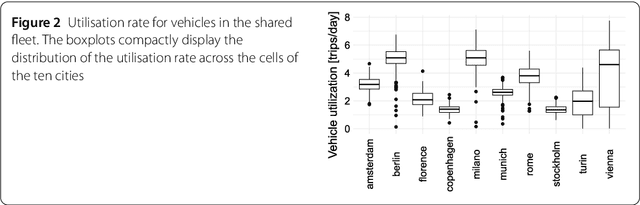
Car sharing is one the pillars of a smart transportation infrastructure, as it is expected to reduce traffic congestion, parking demands and pollution in our cities. From the point of view of demand modelling, car sharing is a weak signal in the city landscape: only a small percentage of the population uses it, and thus it is difficult to study reliably with traditional techniques such as households travel diaries. In this work, we depart from these traditional approaches and we leverage web-based, digital records about vehicle availability in 10 European cities for one of the major active car sharing operators. We discuss which sociodemographic and urban activity indicators are associated with variations in car sharing demand, which forecasting approach (among the most popular in the related literature) is better suited to predict pickup and drop-off events, and how the spatio-temporal information about vehicle availability can be used to infer how different zones in a city are used by customers. We conclude the paper by presenting a direct application of the analysis of the dataset, aimed at identifying where to locate maintenance facilities within the car sharing operation area.
* This work was partially funded by the ESPRIT, REPLICATE and SoBigData projects, which have received funding from the European Union's Horizon 2020 research and innovation programme under grant agreements No 653395, No 691735, and No 654024, respectively. arXiv admin note: text overlap with arXiv:1708.00497
A Digital Smart City for Emerging Mobility Systems
Sep 14, 2021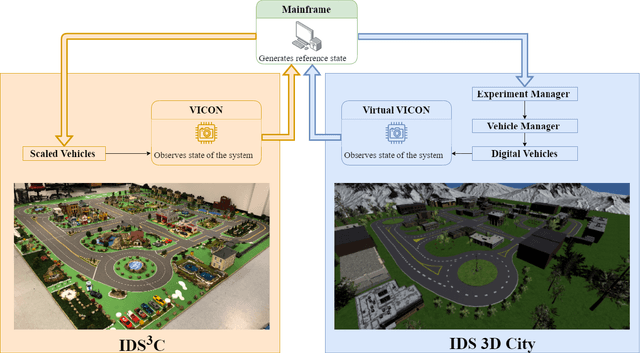
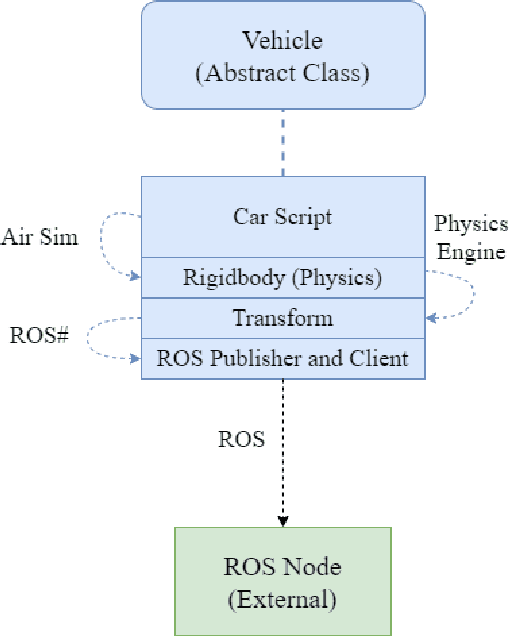
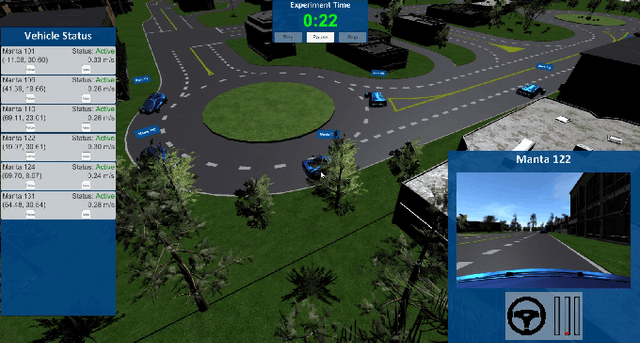
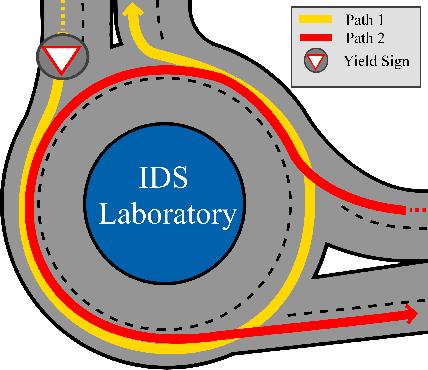
The increasing demand for emerging mobility systems with connected and automated vehicles has imposed the necessity for quality testing environments to support their development. In this paper, we introduce a Unity-based virtual simulation environment for emerging mobility systems, called the Information and Decision Science Lab's Scaled Smart Digital City (IDS $3$D City), intended to operate alongside its physical peer and its established control framework. By utilizing the Robot Operation System, AirSim, and Unity, we constructed a simulation environment capable of iteratively designing experiments significantly faster than it is possible in a physical testbed. This environment provides an intermediate step to validate the effectiveness of our control algorithms prior to their implementation in the physical testbed. The IDS $3$D City also enables us to demonstrate that our control algorithms work independently of the underlying vehicle dynamics, as the vehicle dynamics introduced by AirSim operate at a different scale than our scaled smart city. Finally, we demonstrate the behavior of our digital environment by performing an experiment in both the virtual and physical environments and compare their outputs.
Towards optimized actions in critical situations of soccer games with deep reinforcement learning
Sep 14, 2021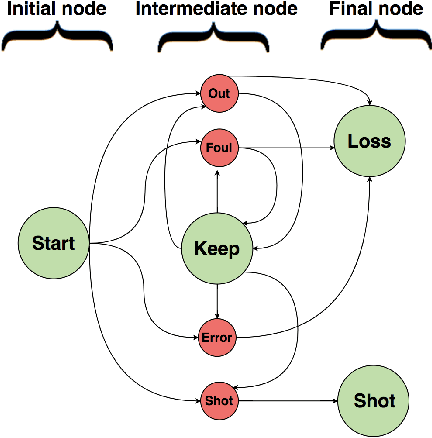
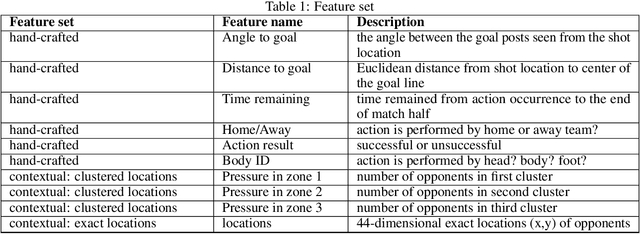
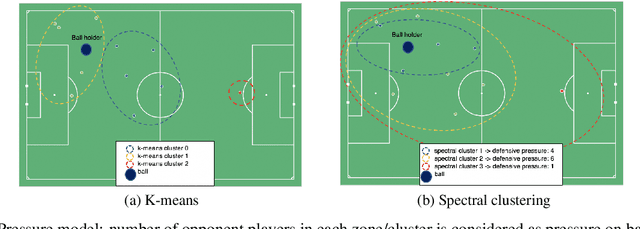
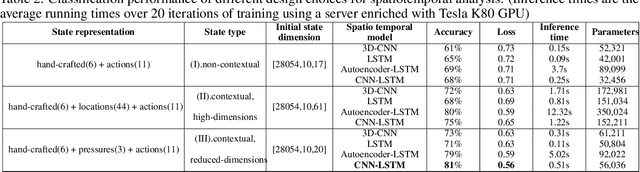
Soccer is a sparse rewarding game: any smart or careless action in critical situations can change the result of the match. Therefore players, coaches, and scouts are all curious about the best action to be performed in critical situations, such as the times with a high probability of losing ball possession or scoring a goal. This work proposes a new state representation for the soccer game and a batch reinforcement learning to train a smart policy network. This network gets the contextual information of the situation and proposes the optimal action to maximize the expected goal for the team. We performed extensive numerical experiments on the soccer logs made by InStat for 104 European soccer matches. The results show that in all 104 games, the optimized policy obtains higher rewards than its counterpart in the behavior policy. Besides, our framework learns policies that are close to the expected behavior in the real world. For instance, in the optimized policy, we observe that some actions such as foul, or ball out can be sometimes more rewarding than a shot in specific situations.