 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep auxiliary learning for visual localization using colorization task
Jul 01, 2021
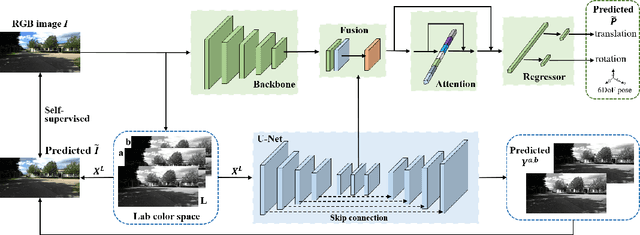
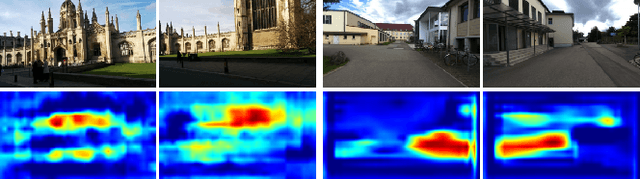
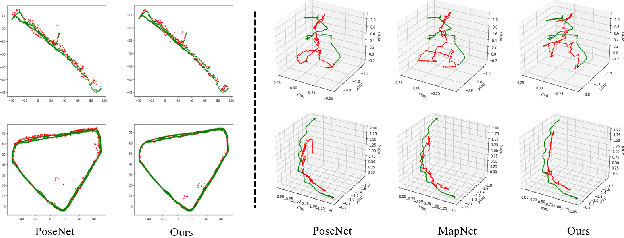

Visual localization is one of the most important components for robotics and autonomous driving. Recently, inspiring results have been shown with CNN-based methods which provide a direct formulation to end-to-end regress 6-DoF absolute pose. Additional information like geometric or semantic constraints is generally introduced to improve performance. Especially, the latter can aggregate high-level semantic information into localization task, but it usually requires enormous manual annotations. To this end, we propose a novel auxiliary learning strategy for camera localization by introducing scene-specific high-level semantics from self-supervised representation learning task. Viewed as a powerful proxy task, image colorization task is chosen as complementary task that outputs pixel-wise color version of grayscale photograph without extra annotations. In our work, feature representations from colorization network are embedded into localization network by design to produce discriminative features for pose regression. Meanwhile an attention mechanism is introduced for the benefit of localization performance. Extensive experiments show that our model significantly improve localization accuracy over state-of-the-arts on both indoor and outdoor datasets.
Neural Mode Decomposition based on Fourier neural network and frequency clustering
Aug 26, 2021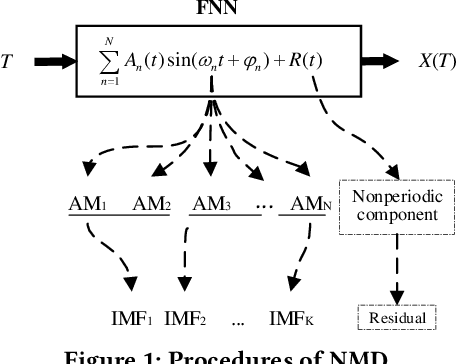
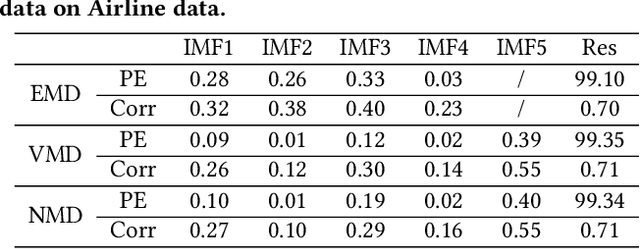
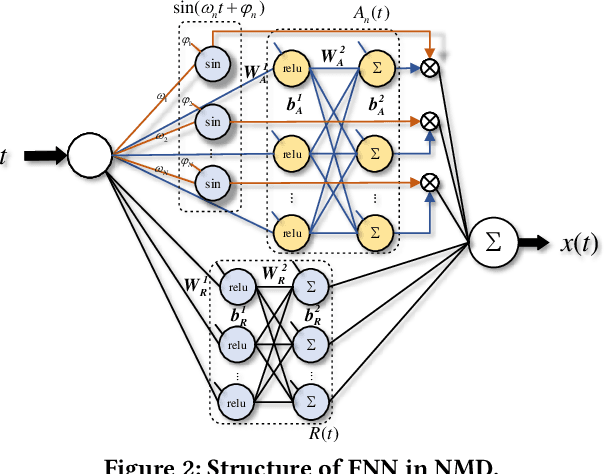
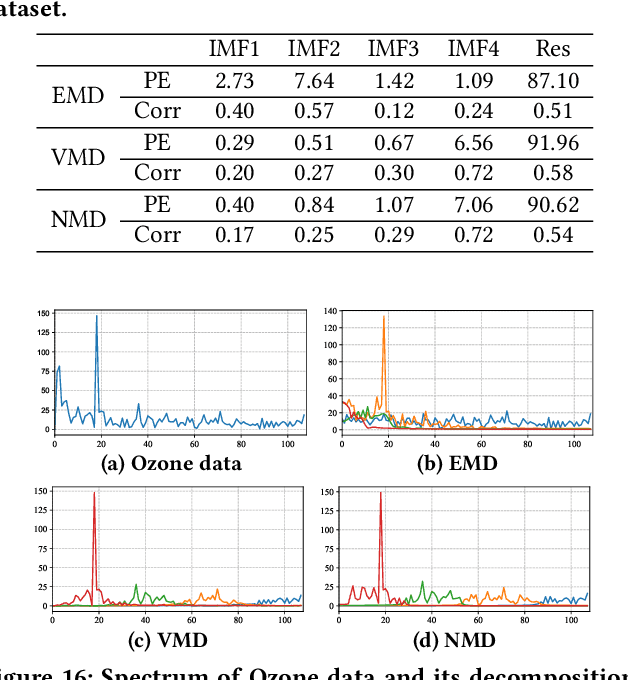
Since Huang proposed the Empirical Mode Decomposition (EMD) in 1998, mode decomposition has been widely studied, but EMD and relative developed algorithms are still generally lack of adaptability and mathematical theory. This paper propose a new mode decomposition algorithm called Neural Mode Decomposition (NMD) based on Fourier neural network (FNN) and frequency clustering. Firstly, a FNN is constructed to decompose and learn the information of each amplitude modulation frequency component and non-periodic component in the raw data. Secondly, the frequency components obtained by the FNN are clustered into multiple Intrinsic Mode Functions (IMF) with separated spectrum based on the energy of each frequency component learned by FNN. Practical decomposition results on a series of artificial and real data show that NMD algorithm can effectively implement mode decomposition, better reflect the characteristics of raw data than EMD, and has higher adaptability than Variational Mode Decomposition (VMD).
DocOIE: A Document-level Context-Aware Dataset for OpenIE
May 11, 2021
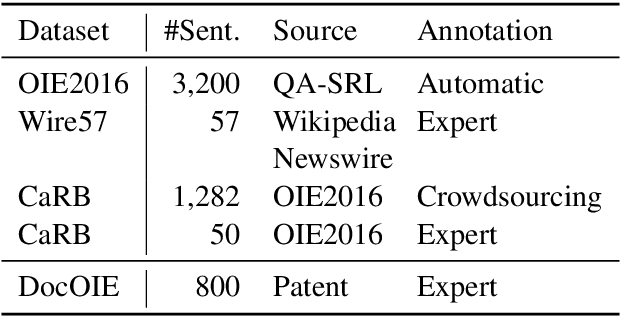
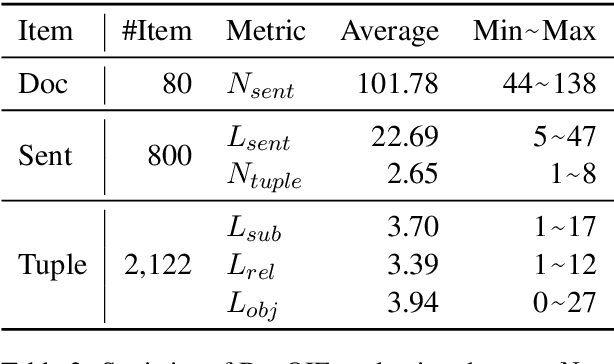
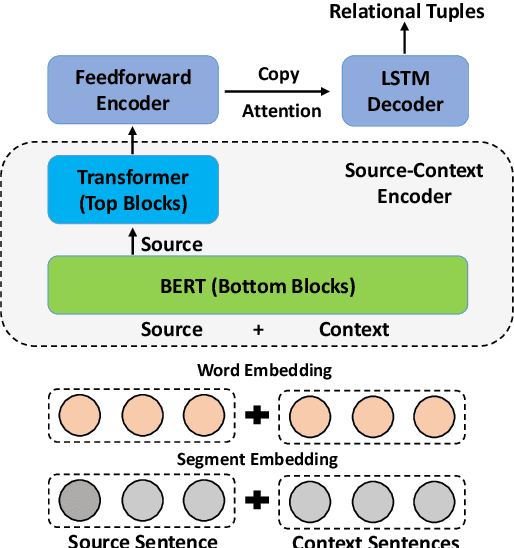
Open Information Extraction (OpenIE) aims to extract structured relational tuples (subject, relation, object) from sentences and plays critical roles for many downstream NLP applications. Existing solutions perform extraction at sentence level, without referring to any additional contextual information. In reality, however, a sentence typically exists as part of a document rather than standalone; we often need to access relevant contextual information around the sentence before we can accurately interpret it. As there is no document-level context-aware OpenIE dataset available, we manually annotate 800 sentences from 80 documents in two domains (Healthcare and Transportation) to form a DocOIE dataset for evaluation. In addition, we propose DocIE, a novel document-level context-aware OpenIE model. Our experimental results based on DocIE demonstrate that incorporating document-level context is helpful in improving OpenIE performance. Both DocOIE dataset and DocIE model are released for public.
Distiller: A Systematic Study of Model Distillation Methods in Natural Language Processing
Sep 23, 2021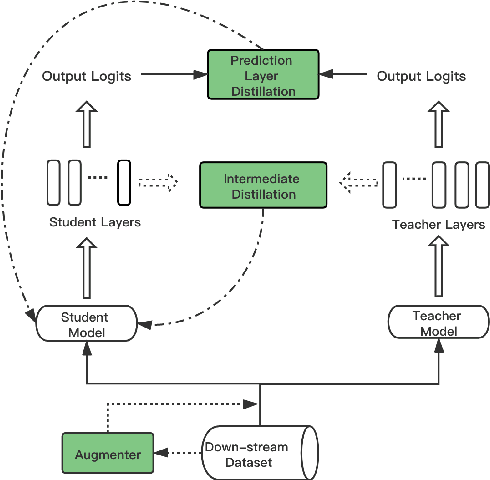
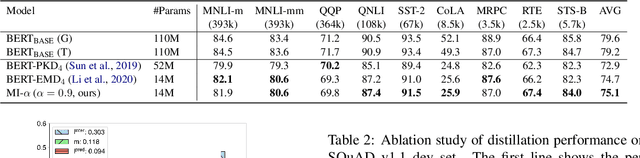
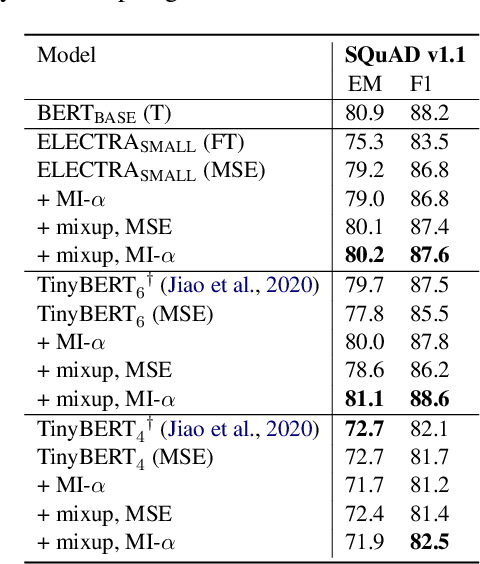
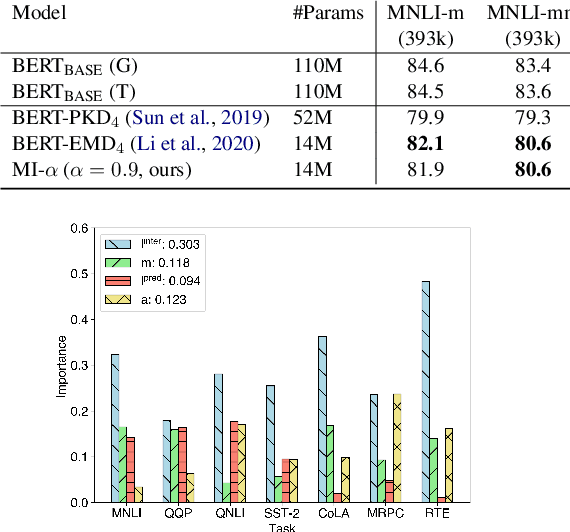
We aim to identify how different components in the KD pipeline affect the resulting performance and how much the optimal KD pipeline varies across different datasets/tasks, such as the data augmentation policy, the loss function, and the intermediate representation for transferring the knowledge between teacher and student. To tease apart their effects, we propose Distiller, a meta KD framework that systematically combines a broad range of techniques across different stages of the KD pipeline, which enables us to quantify each component's contribution. Within Distiller, we unify commonly used objectives for distillation of intermediate representations under a universal mutual information (MI) objective and propose a class of MI-$\alpha$ objective functions with better bias/variance trade-off for estimating the MI between the teacher and the student. On a diverse set of NLP datasets, the best Distiller configurations are identified via large-scale hyperparameter optimization. Our experiments reveal the following: 1) the approach used to distill the intermediate representations is the most important factor in KD performance, 2) among different objectives for intermediate distillation, MI-$\alpha$ performs the best, and 3) data augmentation provides a large boost for small training datasets or small student networks. Moreover, we find that different datasets/tasks prefer different KD algorithms, and thus propose a simple AutoDistiller algorithm that can recommend a good KD pipeline for a new dataset.
Time-Frequency Localization Using Deep Convolutional Maxout Neural Network in Persian Speech Recognition
Aug 09, 2021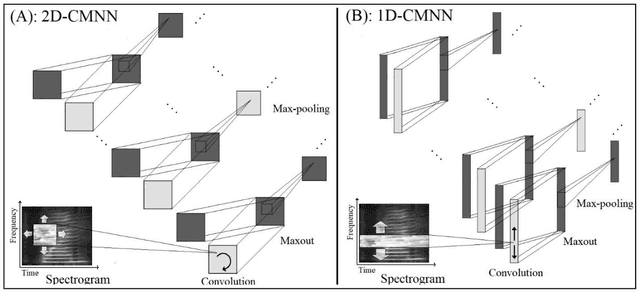
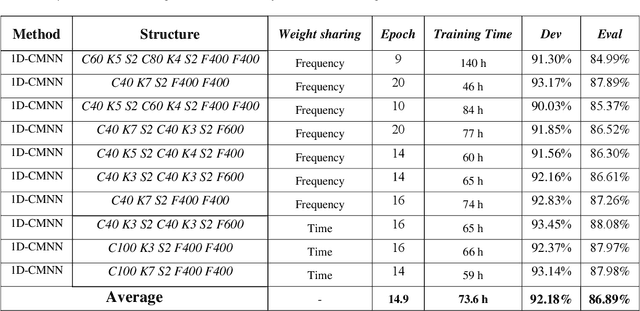
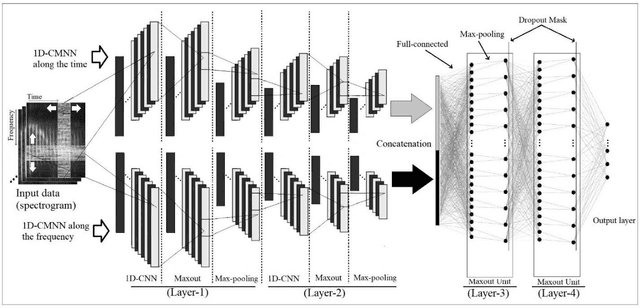
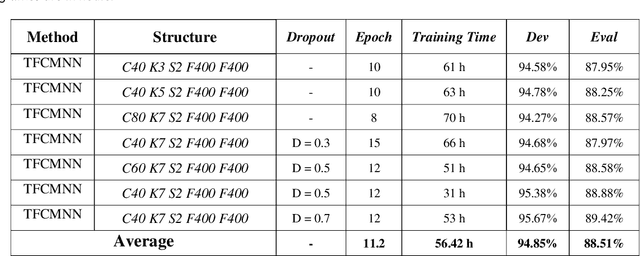
In this paper, a CNN-based structure for time-frequency localization of audio signal information in the ASR acoustic model is proposed for Persian speech recognition. Research has shown that the receptive fields' time-frequency flexibility in some mammals' auditory neurons system improves recognition performance. Biosystems have inspired many artificial systems because of their high efficiency and performance, so time-frequency localization has been used extensively to improve system performance. In the last few years, much work has been done to localize time-frequency information in ASR systems, which has used the spatial immutability properties of methods such as TDNN, CNN and LSTM-RNN. However, most of these models have large parameter volumes and are challenging to train. In the structure we have designed, called Time-Frequency Convolutional Maxout Neural Network (TFCMNN), two parallel blocks consisting of 1D-CMNN each have weight sharing in one dimension, are applied simultaneously but independently to the feature vectors. Then their output is concatenated and applied to a fully connected Maxout network for classification. To improve the performance of this structure, we have used newly developed methods and models such as the maxout, Dropout, and weight normalization. Two experimental sets were designed and implemented on the Persian FARSDAT speech data set to evaluate the performance of this model compared to conventional 1D-CMNN models. According to the experimental results, the average recognition score of TFCMNN models is about 1.6% higher than the average of conventional models. In addition, the average training time of the TFCMNN models is about 17 hours lower than the average training time of traditional models. As a result, as mentioned in other references, time-frequency localization in ASR systems increases system accuracy and speeds up the model training process.
Deep Bayesian inference for seismic imaging with tasks
Oct 10, 2021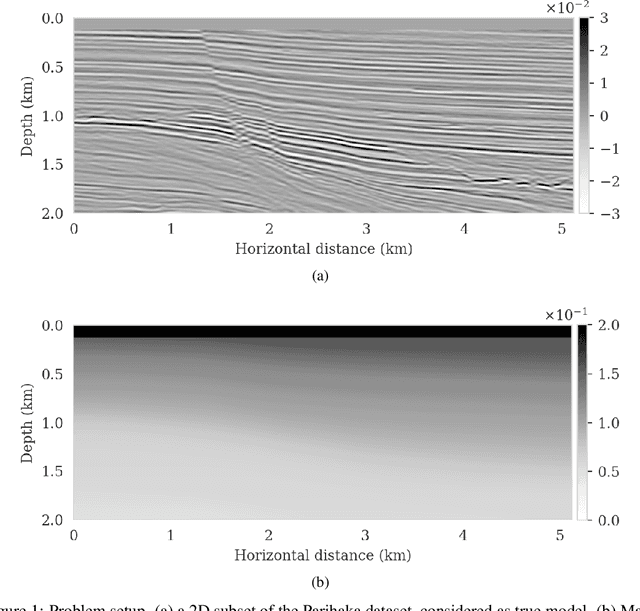
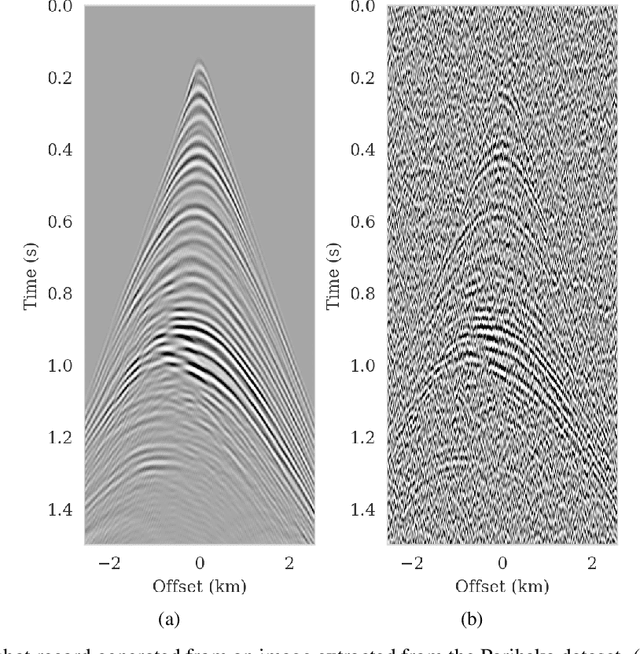
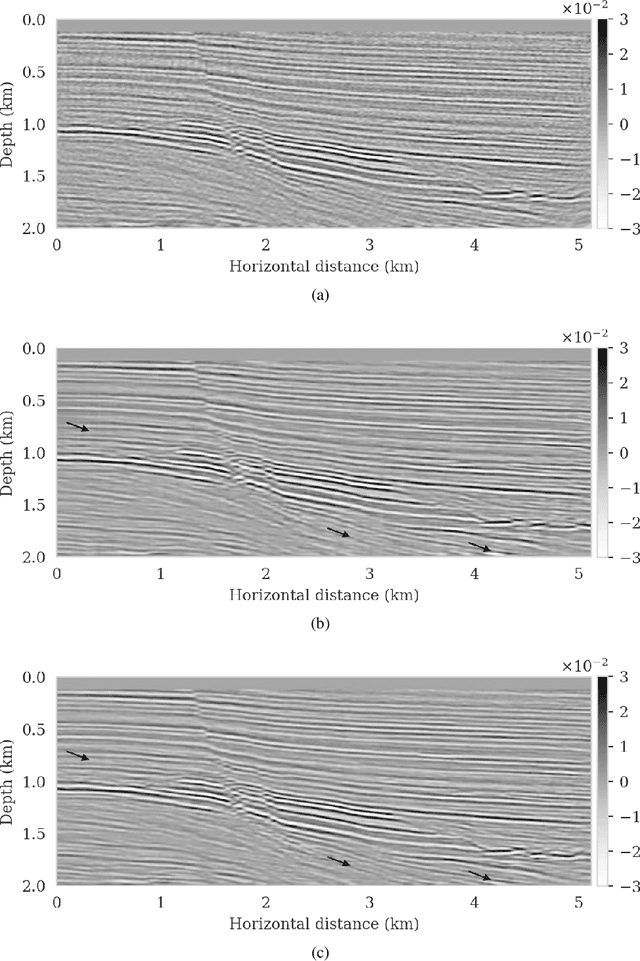
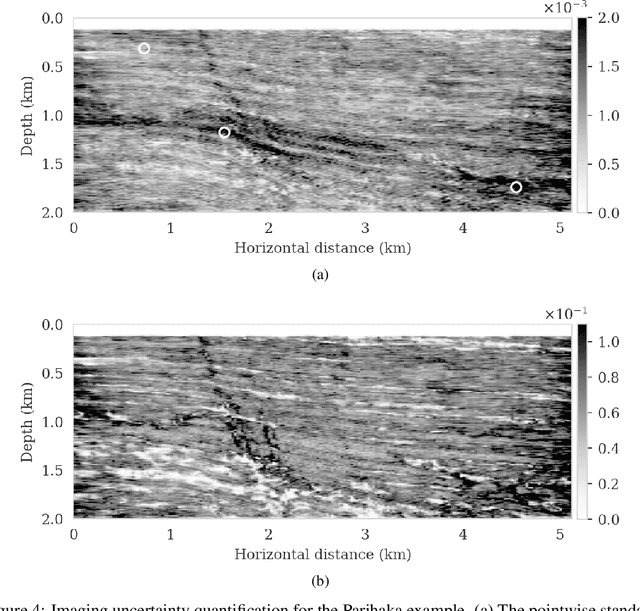
We propose to use techniques from Bayesian inference and deep neural networks to translate uncertainty in seismic imaging to uncertainty in tasks performed on the image, such as horizon tracking. Seismic imaging is an ill-posed inverse problem because of unavoidable bandwidth and aperture limitations, which that is hampered by the presence of noise and linearization errors. Many regularization methods, such as transform-domain sparsity promotion, have been designed to deal with the adverse effects of these errors, however, these methods run the risk of biasing the solution and do not provide information on uncertainty in the image space and how this uncertainty impacts certain tasks on the image. A systematic approach is proposed to translate uncertainty due to noise in the data to confidence intervals of automatically tracked horizons in the image. The uncertainty is characterized by a convolutional neural network (CNN) and to assess these uncertainties, samples are drawn from the posterior distribution of the CNN weights, used to parameterize the image. Compared to traditional priors, in the literature it is argued that these CNNs introduce a flexible inductive bias that is a surprisingly good fit for many diverse domains in imaging. The method of stochastic gradient Langevin dynamics is employed to sample from the posterior distribution. This method is designed to handle large scale Bayesian inference problems with computationally expensive forward operators as in seismic imaging. Aside from offering a robust alternative to maximum a posteriori estimate that is prone to overfitting, access to these samples allow us to translate uncertainty in the image, due to noise in the data, to uncertainty on the tracked horizons. For instance, it admits estimates for the pointwise standard deviation on the image and for confidence intervals on its automatically tracked horizons.
Is News Recommendation a Sequential Recommendation Task?
Aug 26, 2021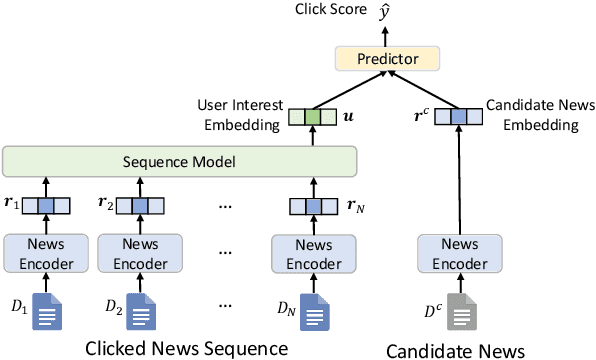
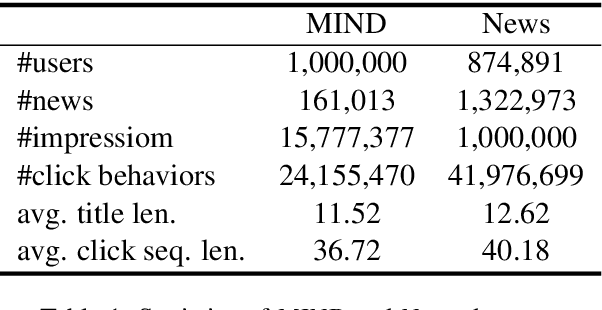
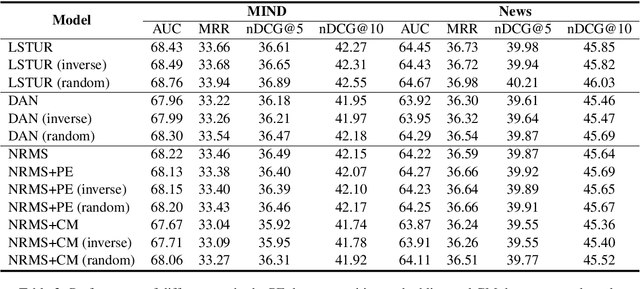
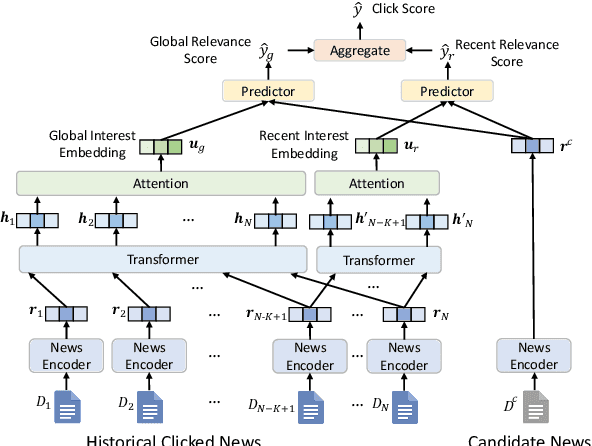
News recommendation is often modeled as a sequential recommendation task, which assumes that there are rich short-term dependencies over historical clicked news. However, in news recommendation scenarios users usually have strong preferences on the temporal diversity of news information and may not tend to click similar news successively, which is very different from many sequential recommendation scenarios such as e-commerce recommendation. In this paper, we study whether news recommendation can be regarded as a standard sequential recommendation problem. Through extensive experiments on two real-world datasets, we find that modeling news recommendation as a sequential recommendation problem is suboptimal. To handle this challenge, we further propose a temporal diversity-aware news recommendation method that can promote candidate news that are diverse from recently clicked news, which can help predict future clicks more accurately. Experiments show that our approach can consistently improve various news recommendation methods.
Spike-inspired Rank Coding for Fast and Accurate Recurrent Neural Networks
Oct 06, 2021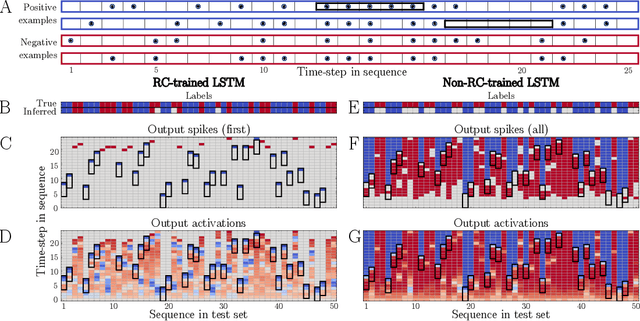
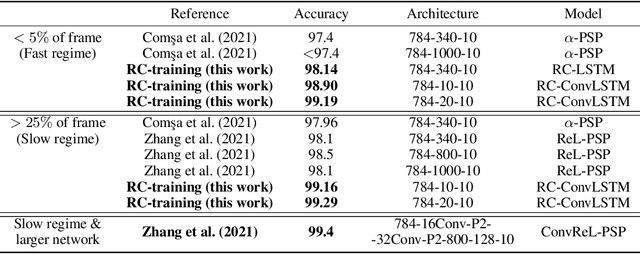

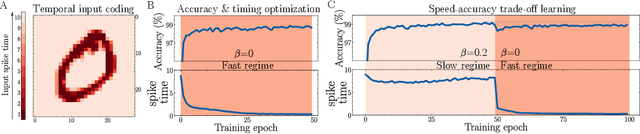
Biological spiking neural networks (SNNs) can temporally encode information in their outputs, e.g. in the rank order in which neurons fire, whereas artificial neural networks (ANNs) conventionally do not. As a result, models of SNNs for neuromorphic computing are regarded as potentially more rapid and efficient than ANNs when dealing with temporal input. On the other hand, ANNs are simpler to train, and usually achieve superior performance. Here we show that temporal coding such as rank coding (RC) inspired by SNNs can also be applied to conventional ANNs such as LSTMs, and leads to computational savings and speedups. In our RC for ANNs, we apply backpropagation through time using the standard real-valued activations, but only from a strategically early time step of each sequential input example, decided by a threshold-crossing event. Learning then incorporates naturally also _when_ to produce an output, without other changes to the model or the algorithm. Both the forward and the backward training pass can be significantly shortened by skipping the remaining input sequence after that first event. RC-training also significantly reduces time-to-insight during inference, with a minimal decrease in accuracy. The desired speed-accuracy trade-off is tunable by varying the threshold or a regularization parameter that rewards output entropy. We demonstrate these in two toy problems of sequence classification, and in a temporally-encoded MNIST dataset where our RC model achieves 99.19% accuracy after the first input time-step, outperforming the state of the art in temporal coding with SNNs, as well as in spoken-word classification of Google Speech Commands, outperforming non-RC-trained early inference with LSTMs.
Stochastic Neural Radiance Fields:Quantifying Uncertainty in Implicit 3D Representations
Sep 05, 2021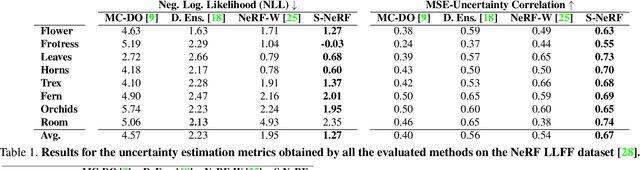
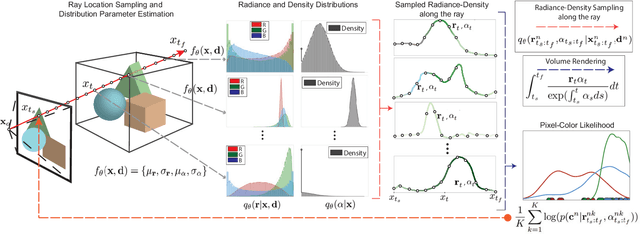
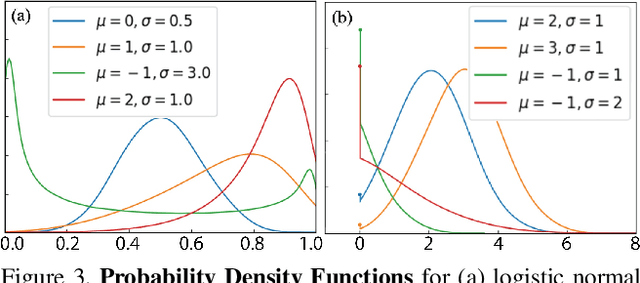
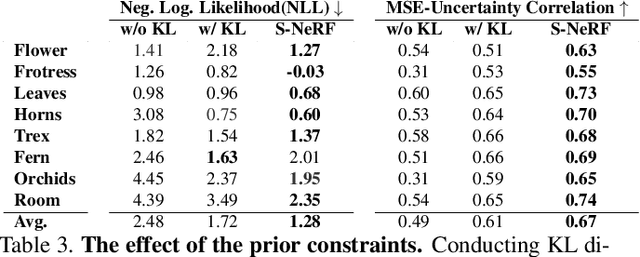
Neural Radiance Fields (NeRF) has become a popular framework for learning implicit 3D representations and addressing different tasks such as novel-view synthesis or depth-map estimation. However, in downstream applications where decisions need to be made based on automatic predictions, it is critical to leverage the confidence associated with the model estimations. Whereas uncertainty quantification is a long-standing problem in Machine Learning, it has been largely overlooked in the recent NeRF literature. In this context, we propose Stochastic Neural Radiance Fields (S-NeRF), a generalization of standard NeRF that learns a probability distribution over all the possible radiance fields modeling the scene. This distribution allows to quantify the uncertainty associated with the scene information provided by the model. S-NeRF optimization is posed as a Bayesian learning problem which is efficiently addressed using the Variational Inference framework. Exhaustive experiments over benchmark datasets demonstrate that S-NeRF is able to provide more reliable predictions and confidence values than generic approaches previously proposed for uncertainty estimation in other domains.
Image Fusion Transformer
Jul 19, 2021
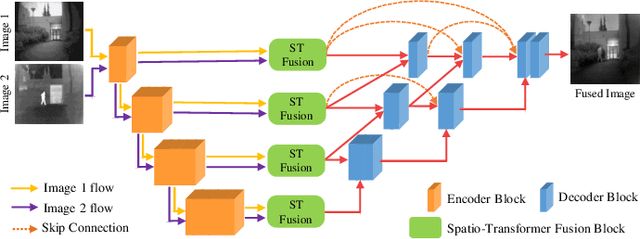
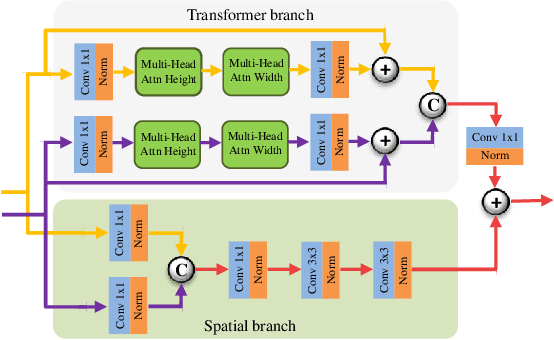
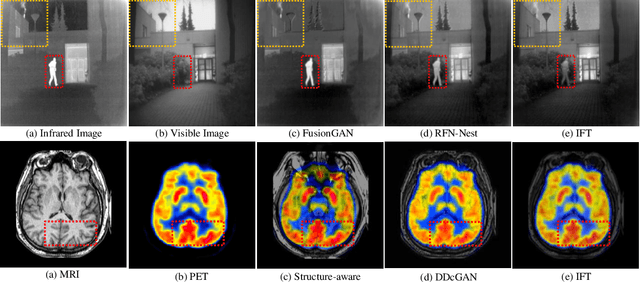
In image fusion, images obtained from different sensors are fused to generate a single image with enhanced information. In recent years, state-of-the-art methods have adopted Convolution Neural Networks (CNNs) to encode meaningful features for image fusion. Specifically, CNN-based methods perform image fusion by fusing local features. However, they do not consider long-range dependencies that are present in the image. Transformer-based models are designed to overcome this by modeling the long-range dependencies with the help of self-attention mechanism. This motivates us to propose a novel Image Fusion Transformer (IFT) where we develop a transformer-based multi-scale fusion strategy that attends to both local and long-range information (or global context). The proposed method follows a two-stage training approach. In the first stage, we train an auto-encoder to extract deep features at multiple scales. In the second stage, multi-scale features are fused using a Spatio-Transformer (ST) fusion strategy. The ST fusion blocks are comprised of a CNN and a transformer branch which capture local and long-range features, respectively. Extensive experiments on multiple benchmark datasets show that the proposed method performs better than many competitive fusion algorithms. Furthermore, we show the effectiveness of the proposed ST fusion strategy with an ablation analysis. The source code is available at: https://github.com/Vibashan/Image-Fusion-Transformer}{https://github.com/Vibashan/Image-Fusion-Transformer.