 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FCM: A Fine-grained Comparison Model for Multi-turn Dialogue Reasoning
Sep 23, 2021

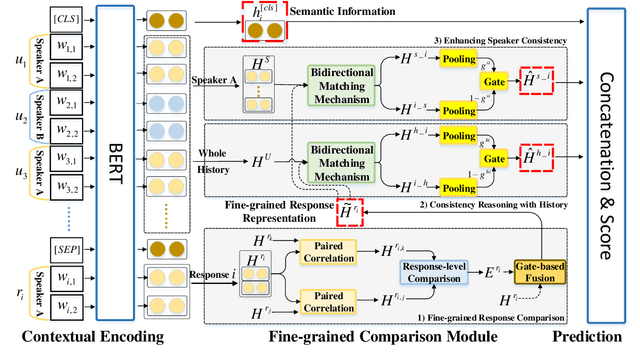
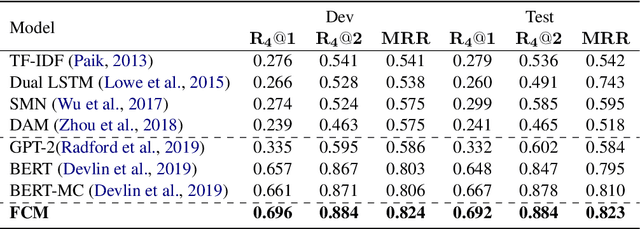
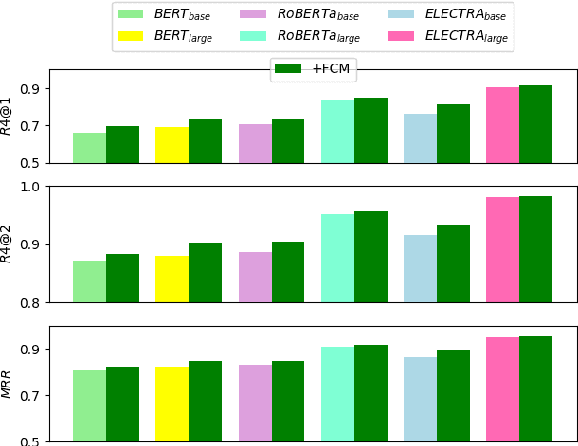
Despite the success of neural dialogue systems in achieving high performance on the leader-board, they cannot meet users' requirements in practice, due to their poor reasoning skills. The underlying reason is that most neural dialogue models only capture the syntactic and semantic information, but fail to model the logical consistency between the dialogue history and the generated response. Recently, a new multi-turn dialogue reasoning task has been proposed, to facilitate dialogue reasoning research. However, this task is challenging, because there are only slight differences between the illogical response and the dialogue history. How to effectively solve this challenge is still worth exploring. This paper proposes a Fine-grained Comparison Model (FCM) to tackle this problem. Inspired by human's behavior in reading comprehension, a comparison mechanism is proposed to focus on the fine-grained differences in the representation of each response candidate. Specifically, each candidate representation is compared with the whole history to obtain a history consistency representation. Furthermore, the consistency signals between each candidate and the speaker's own history are considered to drive a model to prefer a candidate that is logically consistent with the speaker's history logic. Finally, the above consistency representations are employed to output a ranking list of the candidate responses for multi-turn dialogue reasoning. Experimental results on two public dialogue datasets show that our method obtains higher ranking scores than the baseline models.
Co-learning: Learning from Noisy Labels with Self-supervision
Aug 30, 2021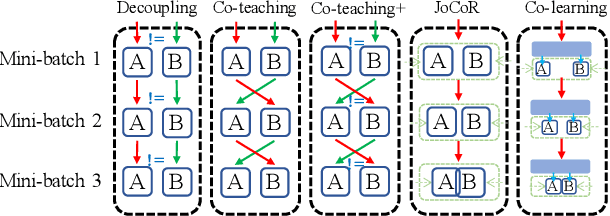

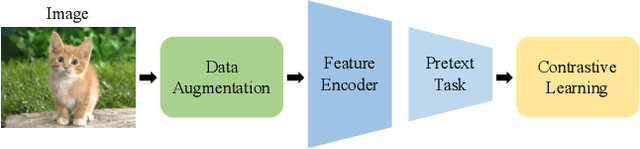

Noisy labels, resulting from mistakes in manual labeling or webly data collecting for supervised learning, can cause neural networks to overfit the misleading information and degrade the generalization performance. Self-supervised learning works in the absence of labels and thus eliminates the negative impact of noisy labels. Motivated by co-training with both supervised learning view and self-supervised learning view, we propose a simple yet effective method called Co-learning for learning with noisy labels. Co-learning performs supervised learning and self-supervised learning in a cooperative way. The constraints of intrinsic similarity with the self-supervised module and the structural similarity with the noisily-supervised module are imposed on a shared common feature encoder to regularize the network to maximize the agreement between the two constraints. Co-learning is compared with peer methods on corrupted data from benchmark datasets fairly, and extensive results are provided which demonstrate that Co-learning is superior to many state-of-the-art approaches.
Spectral Temporal Graph Neural Network for Trajectory Prediction
Jun 05, 2021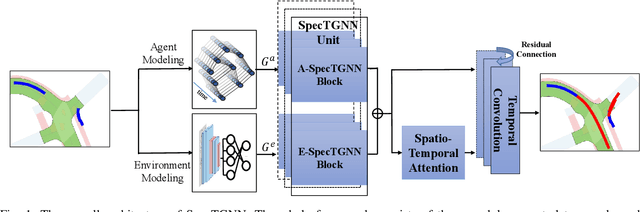
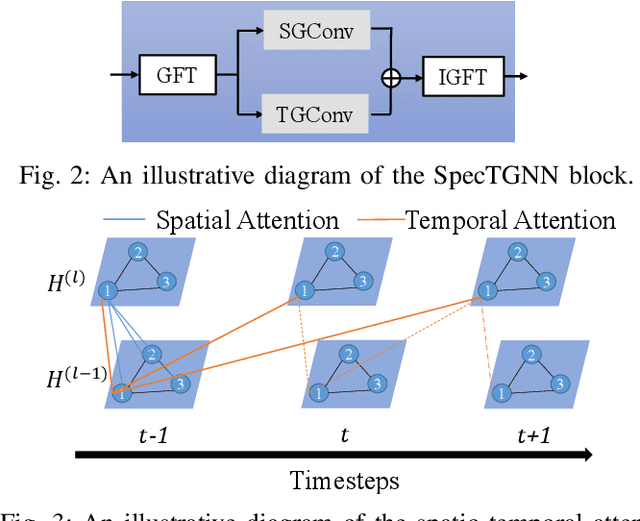
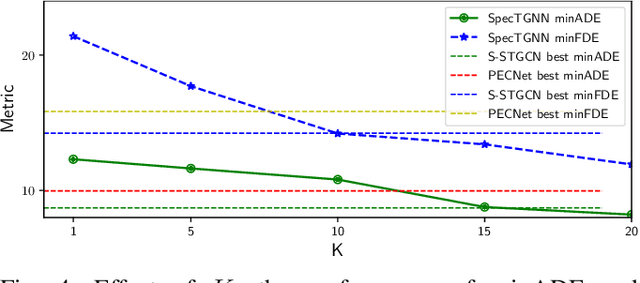
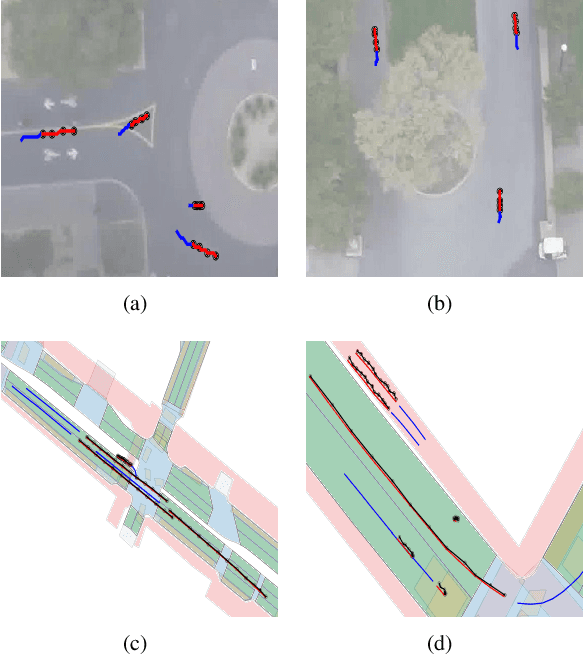
An effective understanding of the contextual environment and accurate motion forecasting of surrounding agents is crucial for the development of autonomous vehicles and social mobile robots. This task is challenging since the behavior of an autonomous agent is not only affected by its own intention, but also by the static environment and surrounding dynamically interacting agents. Previous works focused on utilizing the spatial and temporal information in time domain while not sufficiently taking advantage of the cues in frequency domain. To this end, we propose a Spectral Temporal Graph Neural Network (SpecTGNN), which can capture inter-agent correlations and temporal dependency simultaneously in frequency domain in addition to time domain. SpecTGNN operates on both an agent graph with dynamic state information and an environment graph with the features extracted from context images in two streams. The model integrates graph Fourier transform, spectral graph convolution and temporal gated convolution to encode history information and forecast future trajectories. Moreover, we incorporate a multi-head spatio-temporal attention mechanism to mitigate the effect of error propagation in a long time horizon. We demonstrate the performance of SpecTGNN on two public trajectory prediction benchmark datasets, which achieves state-of-the-art performance in terms of prediction accuracy.
Semantic Extractor-Paraphraser based Abstractive Summarization
May 04, 2021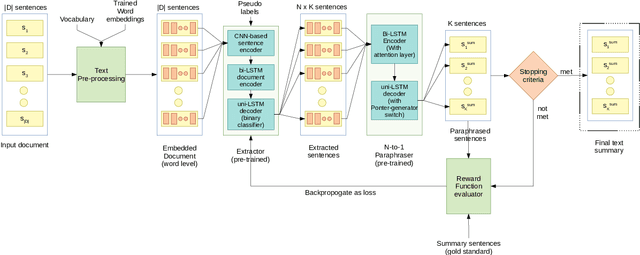
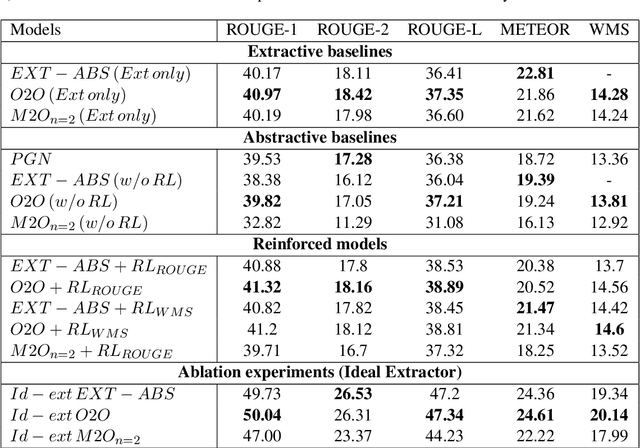
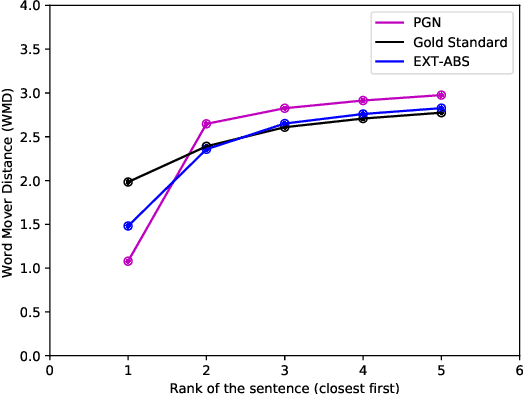

The anthology of spoken languages today is inundated with textual information, necessitating the development of automatic summarization models. In this manuscript, we propose an extractor-paraphraser based abstractive summarization system that exploits semantic overlap as opposed to its predecessors that focus more on syntactic information overlap. Our model outperforms the state-of-the-art baselines in terms of ROUGE, METEOR and word mover similarity (WMS), establishing the superiority of the proposed system via extensive ablation experiments. We have also challenged the summarization capabilities of the state of the art Pointer Generator Network (PGN), and through thorough experimentation, shown that PGN is more of a paraphraser, contrary to the prevailing notion of a summarizer; illustrating it's incapability to accumulate information across multiple sentences.
SSC: Semantic Scan Context for Large-Scale Place Recognition
Jul 01, 2021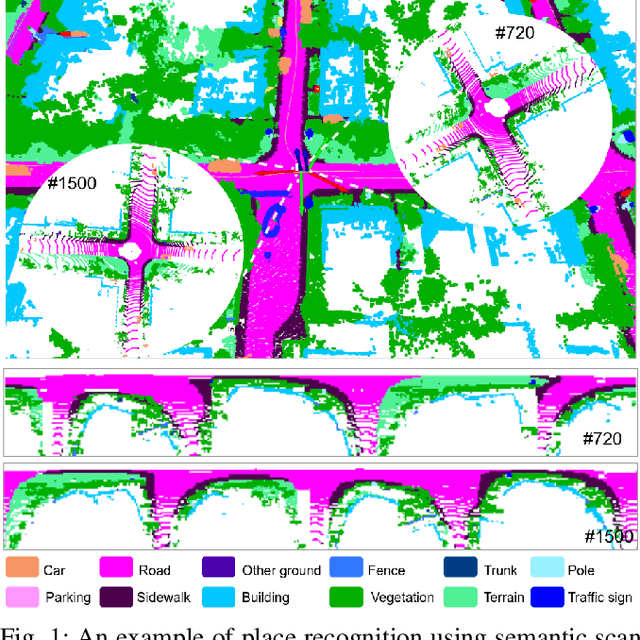
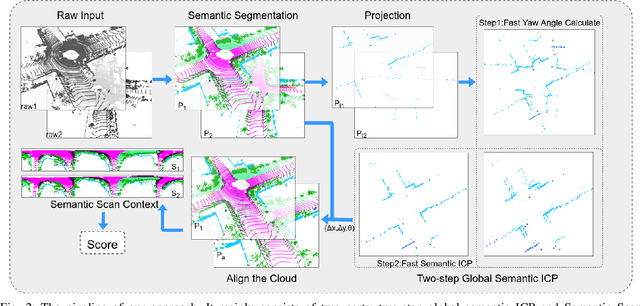
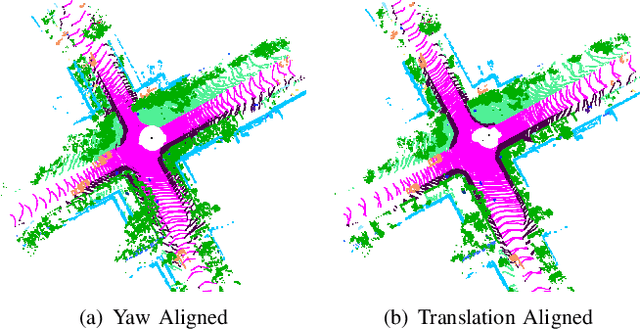
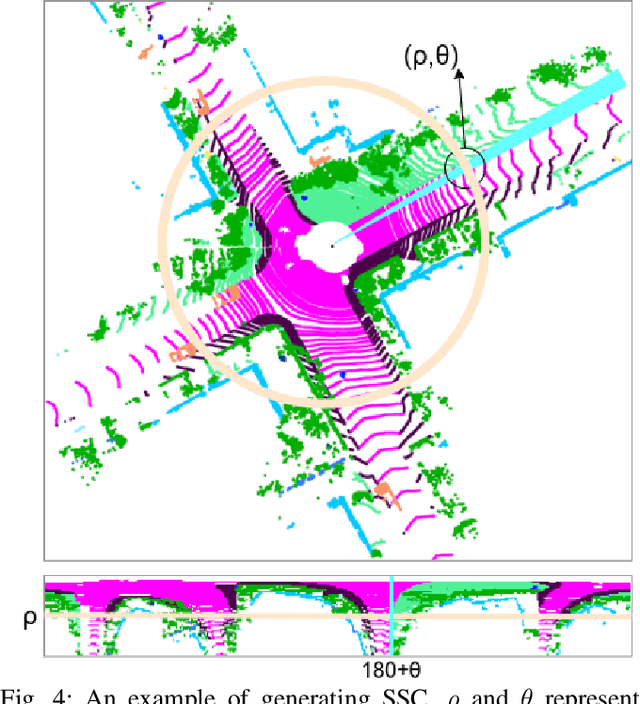
Place recognition gives a SLAM system the ability to correct cumulative errors. Unlike images that contain rich texture features, point clouds are almost pure geometric information which makes place recognition based on point clouds challenging. Existing works usually encode low-level features such as coordinate, normal, reflection intensity, etc., as local or global descriptors to represent scenes. Besides, they often ignore the translation between point clouds when matching descriptors. Different from most existing methods, we explore the use of high-level features, namely semantics, to improve the descriptor's representation ability. Also, when matching descriptors, we try to correct the translation between point clouds to improve accuracy. Concretely, we propose a novel global descriptor, Semantic Scan Context, which explores semantic information to represent scenes more effectively. We also present a two-step global semantic ICP to obtain the 3D pose (x, y, yaw) used to align the point cloud to improve matching performance. Our experiments on the KITTI dataset show that our approach outperforms the state-of-the-art methods with a large margin. Our code is available at: https://github.com/lilin-hitcrt/SSC.
Graph Pooling via Coarsened Graph Infomax
May 04, 2021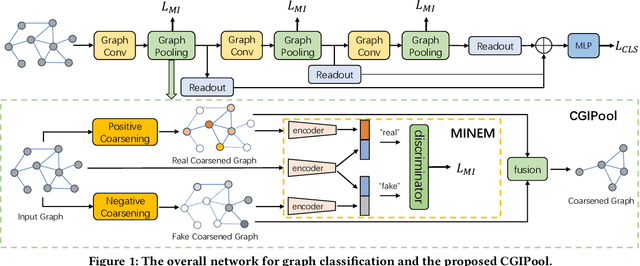
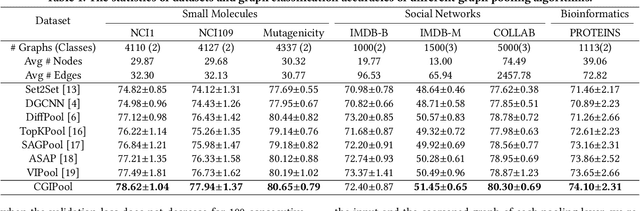
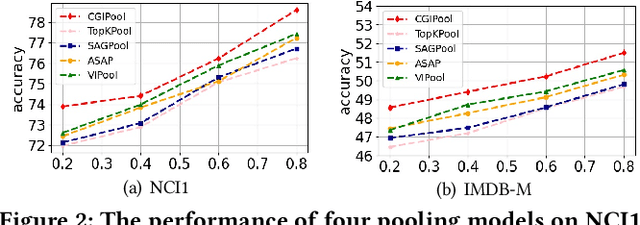
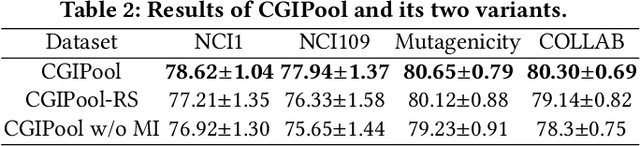
Graph pooling that summaries the information in a large graph into a compact form is essential in hierarchical graph representation learning. Existing graph pooling methods either suffer from high computational complexity or cannot capture the global dependencies between graphs before and after pooling. To address the problems of existing graph pooling methods, we propose Coarsened Graph Infomax Pooling (CGIPool) that maximizes the mutual information between the input and the coarsened graph of each pooling layer to preserve graph-level dependencies. To achieve mutual information neural maximization, we apply contrastive learning and propose a self-attention-based algorithm for learning positive and negative samples. Extensive experimental results on seven datasets illustrate the superiority of CGIPool comparing to the state-of-the-art methods.
Sketches for Time-Dependent Machine Learning
Aug 26, 2021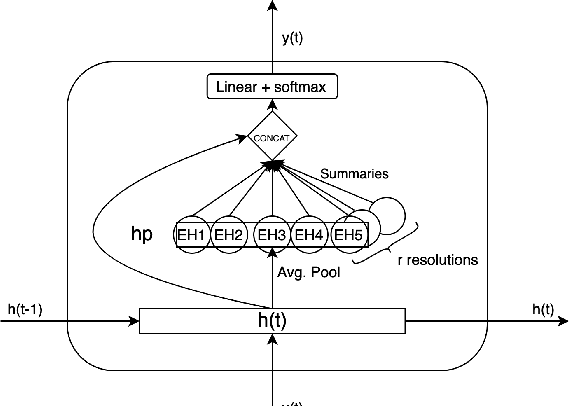
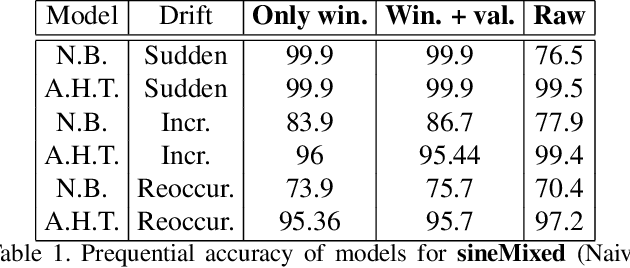
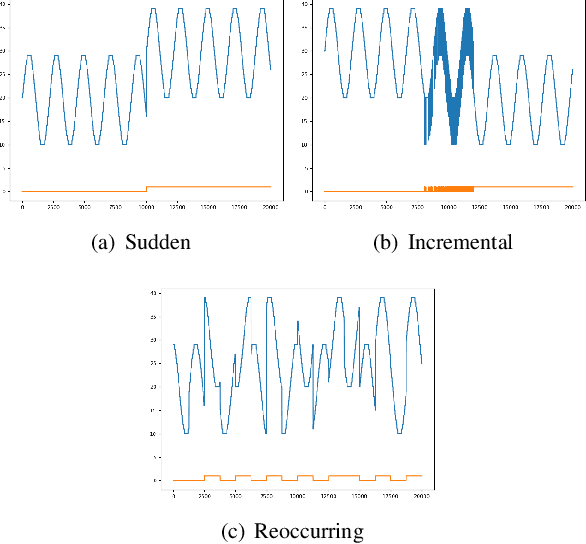
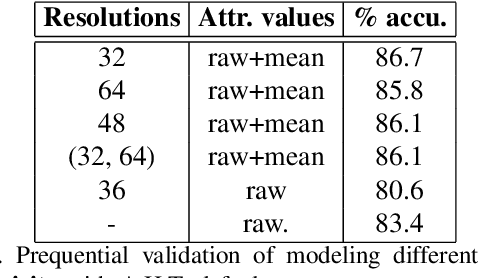
Time series data can be subject to changes in the underlying process that generates them and, because of these changes, models built on old samples can become obsolete or perform poorly. In this work, we present a way to incorporate information about the current data distribution and its evolution across time into machine learning algorithms. Our solution is based on efficiently maintaining statistics, particularly the mean and the variance, of data features at different time resolutions. These data summarisations can be performed over the input attributes, in which case they can then be fed into the model as additional input features, or over latent representations learned by models, such as those of Recurrent Neural Networks. In classification tasks, the proposed techniques can significantly outperform the prediction capabilities of equivalent architectures with no feature / latent summarisations. Furthermore, these modifications do not introduce notable computational and memory overhead when properly adjusted.
Denoising ECG by Adaptive Filter with Empirical Mode Decomposition
Aug 18, 2021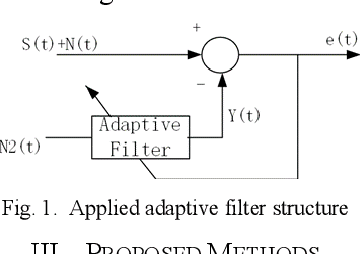
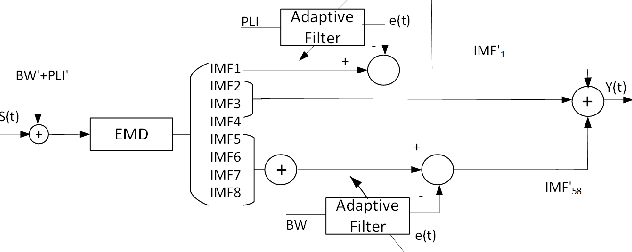
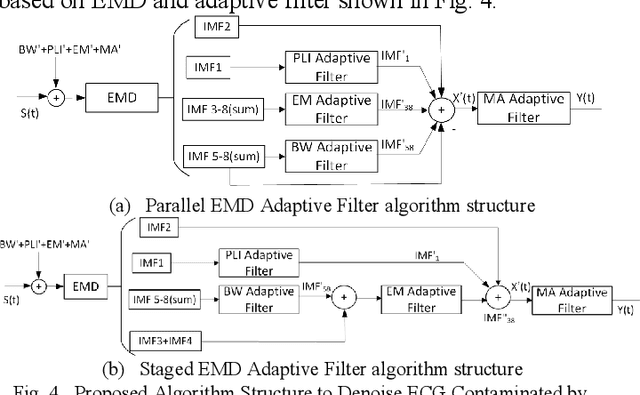
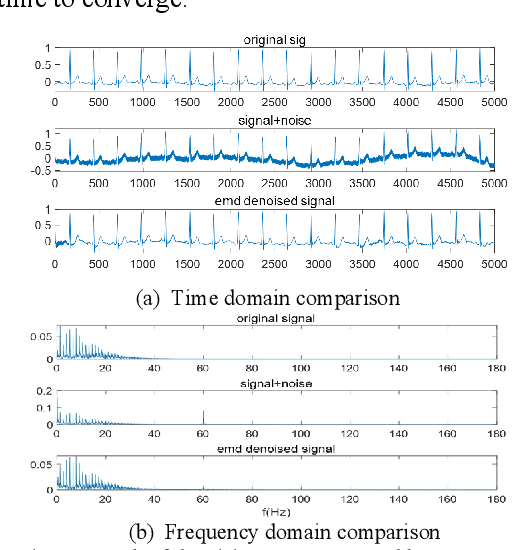
Electrocardiogram (ECG) signal is an important physiological signal which contains cardiac information and is the basis to diagnosis cardiac related diseases. In this paper, several innovative and efficient methods based on adaptive filter and empirical mode decomposition (EMD) to denoise ECG signal contaminated by various kinds of noise, including baseline wander (BW), power line interference (PLI), electrode motion artifact (EM) and muscle artifact (MA), are proposed. We first present a novel method based on EMD and adaptive filter for the removal of BW and PLI in ECG signal. We then extend the method to the complex scenario where four most common noises, PLI, BW, EM and MA are present. The proposed Parallel EMD adaptive filter structure yields the best SNR improvement on the MIT-BIH arrhythmia database, corrupted by the four types of noises.
Shatter: An Efficient Transformer Encoder with Single-Headed Self-Attention and Relative Sequence Partitioning
Aug 30, 2021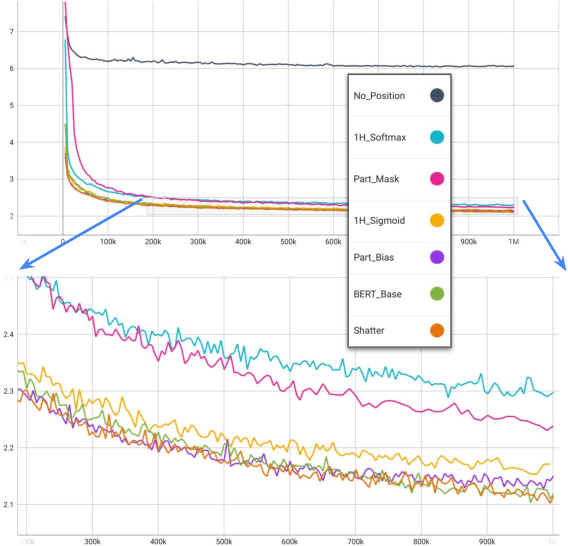
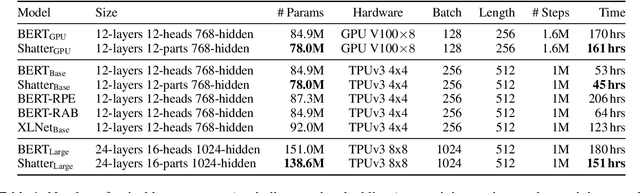

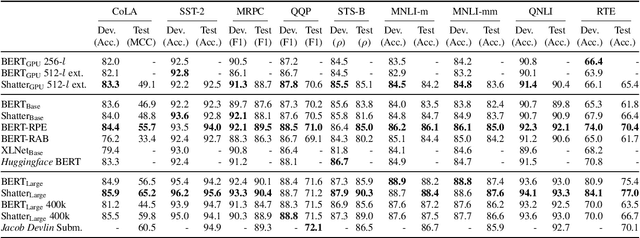
The highly popular Transformer architecture, based on self-attention, is the foundation of large pretrained models such as BERT, that have become an enduring paradigm in NLP. While powerful, the computational resources and time required to pretrain such models can be prohibitive. In this work, we present an alternative self-attention architecture, Shatter, that more efficiently encodes sequence information by softly partitioning the space of relative positions and applying different value matrices to different parts of the sequence. This mechanism further allows us to simplify the multi-headed attention in Transformer to single-headed. We conduct extensive experiments showing that Shatter achieves better performance than BERT, with pretraining being faster per step (15% on TPU), converging in fewer steps, and offering considerable memory savings (>50%). Put together, Shatter can be pretrained on 8 V100 GPUs in 7 days, and match the performance of BERT_Base -- making the cost of pretraining much more affordable.
Quantifying multivariate redundancy with maximum entropy decompositions of mutual information
Apr 03, 2018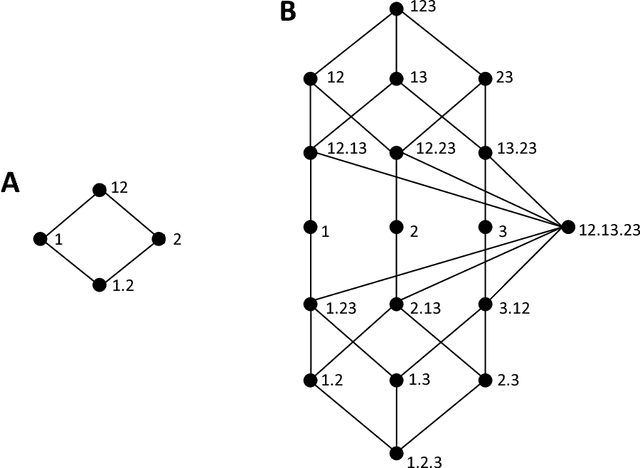

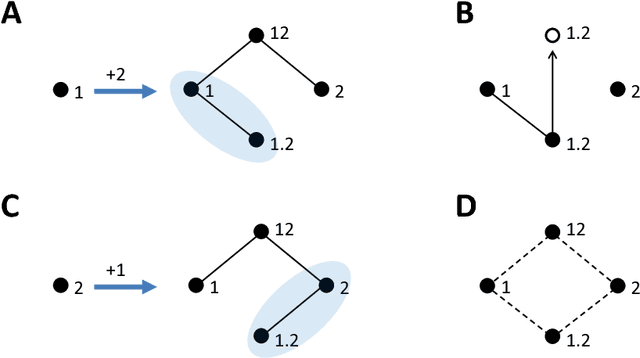
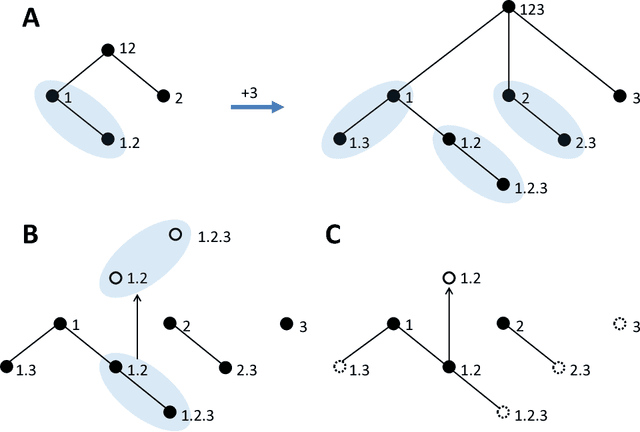
Williams and Beer (2010) proposed a nonnegative mutual information decomposition, based on the construction of redundancy lattices, which allows separating the information that a set of variables contains about a target variable into nonnegative components interpretable as the unique information of some variables not provided by others as well as redundant and synergistic components. However, the definition of multivariate measures of redundancy that comply with nonnegativity and conform to certain axioms that capture conceptually desirable properties of redundancy has proven to be elusive. We here present a procedure to determine nonnegative multivariate redundancy measures, within the maximum entropy framework. In particular, we generalize existing bivariate maximum entropy measures of redundancy and unique information, defining measures of the redundant information that a group of variables has about a target, and of the unique redundant information that a group of variables has about a target that is not redundant with information from another group. The two key ingredients for this approach are: First, the identification of a type of constraints on entropy maximization that allows isolating components of redundancy and unique redundancy by mirroring them to synergy components. Second, the construction of rooted tree-based decompositions of the mutual information, which conform to the axioms of the redundancy lattice by the local implementation at each tree node of binary unfoldings of the information using hierarchically related maximum entropy constraints. Altogether, the proposed measures quantify the different multivariate redundancy contributions of a nonnegative mutual information decomposition consistent with the redundancy lattice.