 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
System Optimization in Synchronous Federated Training: A Survey
Sep 09, 2021
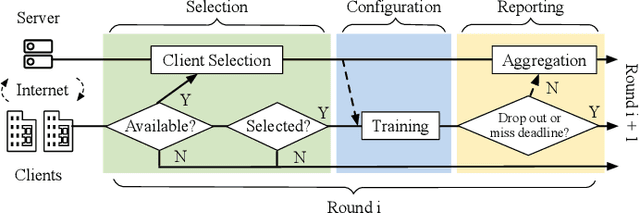
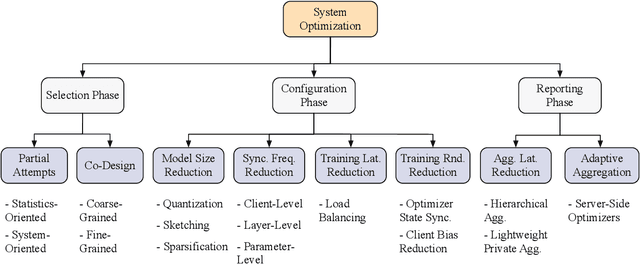
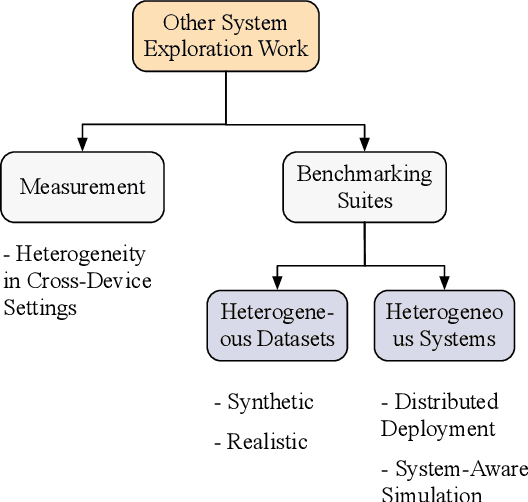
The unprecedented demand for collaborative machine learning in a privacy-preserving manner gives rise to a novel machine learning paradigm called federated learning (FL). Given a sufficient level of privacy guarantees, the practicality of an FL system mainly depends on its time-to-accuracy performance during the training process. Despite bearing some resemblance with traditional distributed training, FL has four distinct challenges that complicate the optimization towards shorter time-to-accuracy: information deficiency, coupling for contrasting factors, client heterogeneity, and huge configuration space. Motivated by the need for inspiring related research, in this paper we survey highly relevant attempts in the FL literature and organize them by the related training phases in the standard workflow: selection, configuration, and reporting. We also review exploratory work including measurement studies and benchmarking tools to friendly support FL developers. Although a few survey articles on FL already exist, our work differs from them in terms of the focus, classification, and implications.
Salient Positions based Attention Network for Image Classification
Jun 09, 2021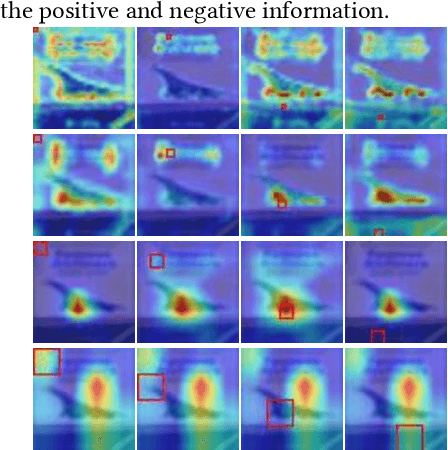
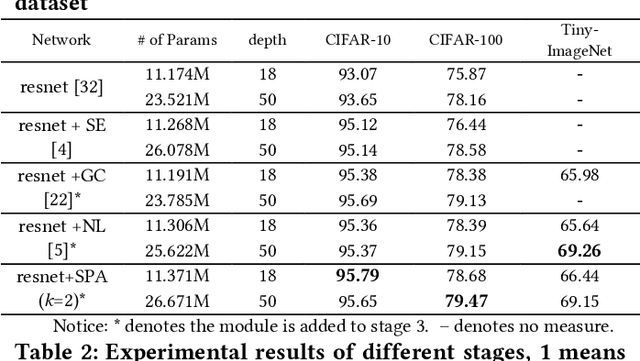
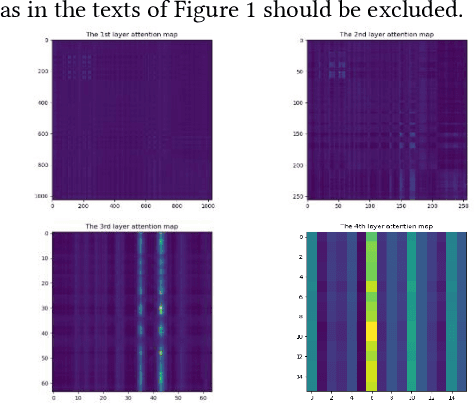
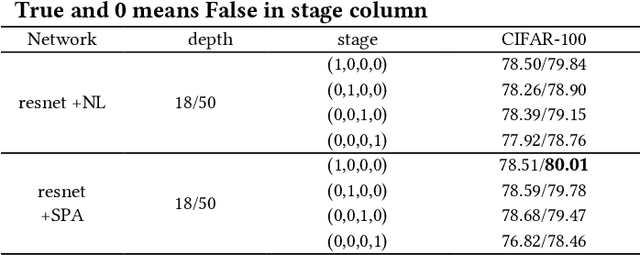
The self-attention mechanism has attracted wide publicity for its most important advantage of modeling long dependency, and its variations in computer vision tasks, the non-local block tries to model the global dependency of the input feature maps. Gathering global contextual information will inevitably need a tremendous amount of memory and computing resources, which has been extensively studied in the past several years. However, there is a further problem with the self-attention scheme: is all information gathered from the global scope helpful for the contextual modelling? To our knowledge, few studies have focused on the problem. Aimed at both questions this paper proposes the salient positions-based attention scheme SPANet, which is inspired by some interesting observations on the attention maps and affinity matrices generated in self-attention scheme. We believe these observations are beneficial for better understanding of the self-attention. SPANet uses the salient positions selection algorithm to select only a limited amount of salient points to attend in the attention map computing. This approach will not only spare a lot of memory and computing resources, but also try to distill the positive information from the transformation of the input feature maps. In the implementation, considering the feature maps with channel high dimensions, which are completely different from the general visual image, we take the squared power of the feature maps along the channel dimension as the saliency metric of the positions. In general, different from the non-local block method, SPANet models the contextual information using only the selected positions instead of all, along the channel dimension instead of space dimension. Our source code is available at https://github.com/likyoo/SPANet.
A Novel Method to Estimate the Coordinates of LEDs in Wireless Optical Positioning Systems
Sep 09, 2021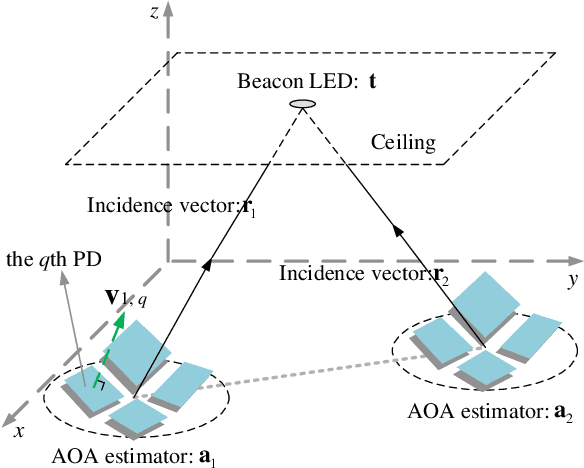
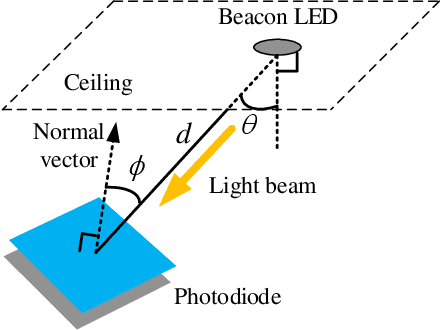
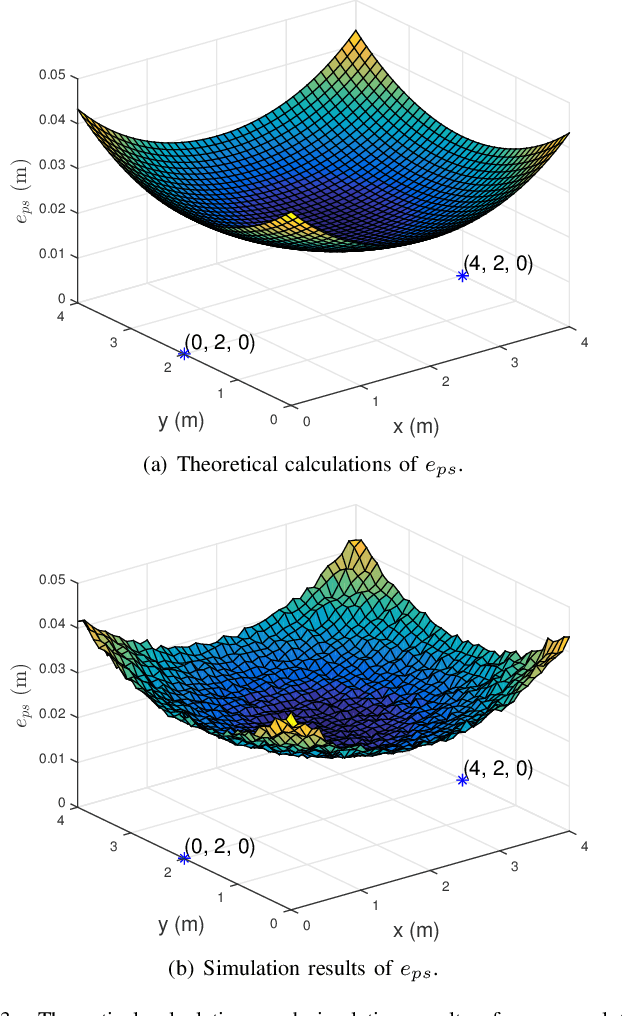
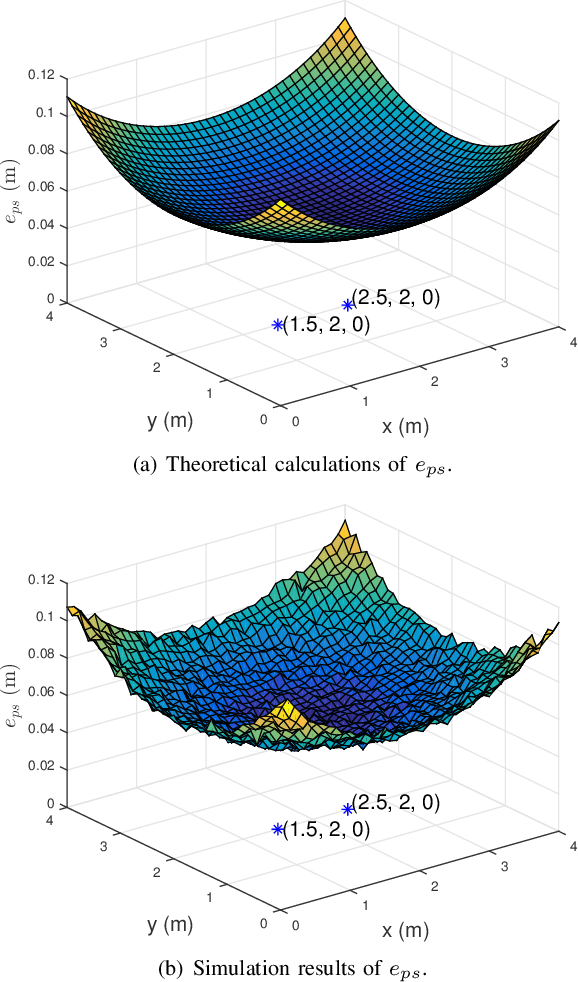
Traditional visible light positioning (VLP) systems estimate receivers' coordinates based on the known light-emitting diode (LED) coordinates. However, the LED coordinates are not always known accurately. Because of the structural changes of the buildings due to temperature, humidity or material aging, even measured by highly accurate laser range finders, the LED coordinates may change unpredictably. In this paper, we propose an easy and low-cost method to update the position information of the LEDs. We use two optical angle-of-arrival (AOA) estimators to detect the beam directions of the LEDs. Each AOA estimator has four differently oriented photodiodes (PDs). Considering the additive noises of the PDs, we derive the closed-form error expression for the proposed LED coordinates estimator. Both analytical and Monte Carlo experimental results show that the layout of the AOA estimators could affect the estimation error. These results may provide intuitive insights for the design of the optical indoor positioning systems.
A Framework for Multisensory Foresight for Embodied Agents
Sep 15, 2021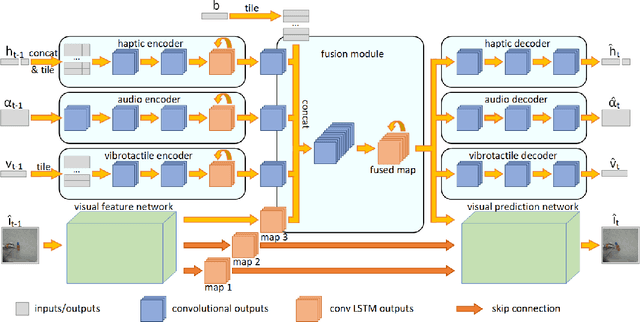
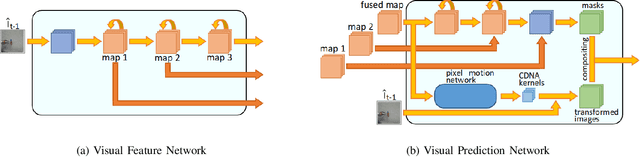
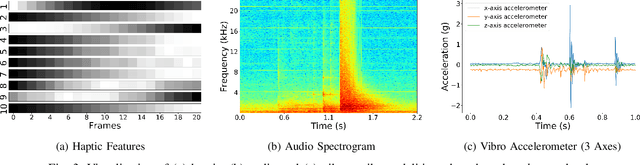
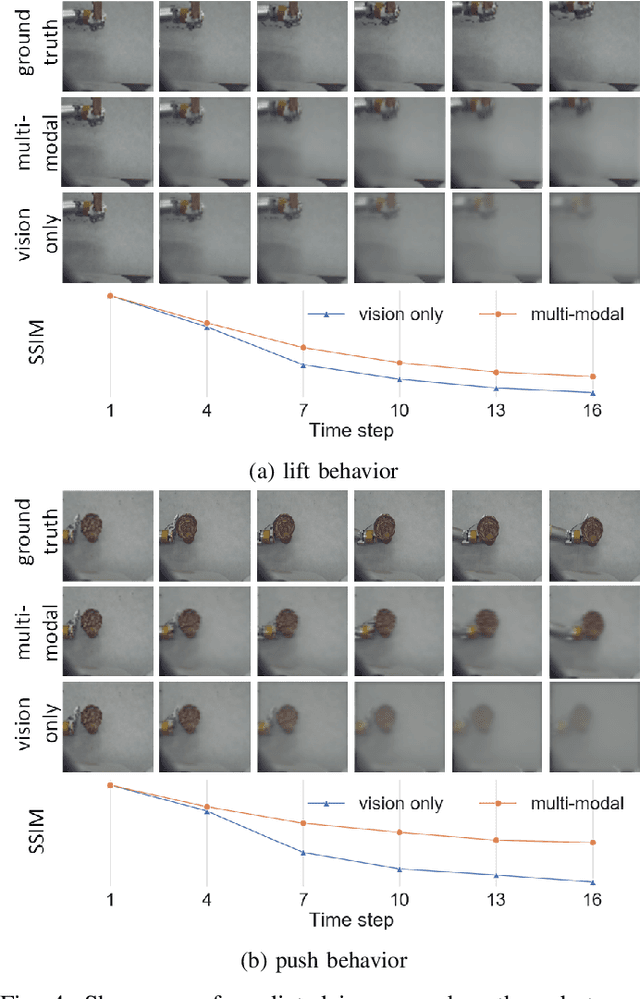
Predicting future sensory states is crucial for learning agents such as robots, drones, and autonomous vehicles. In this paper, we couple multiple sensory modalities with exploratory actions and propose a predictive neural network architecture to address this problem. Most existing approaches rely on large, manually annotated datasets, or only use visual data as a single modality. In contrast, the unsupervised method presented here uses multi-modal perceptions for predicting future visual frames. As a result, the proposed model is more comprehensive and can better capture the spatio-temporal dynamics of the environment, leading to more accurate visual frame prediction. The other novelty of our framework is the use of sub-networks dedicated to anticipating future haptic, audio, and tactile signals. The framework was tested and validated with a dataset containing 4 sensory modalities (vision, haptic, audio, and tactile) on a humanoid robot performing 9 behaviors multiple times on a large set of objects. While the visual information is the dominant modality, utilizing the additional non-visual modalities improves the accuracy of predictions.
ArtGraph: Towards an Artistic Knowledge Graph
May 31, 2021

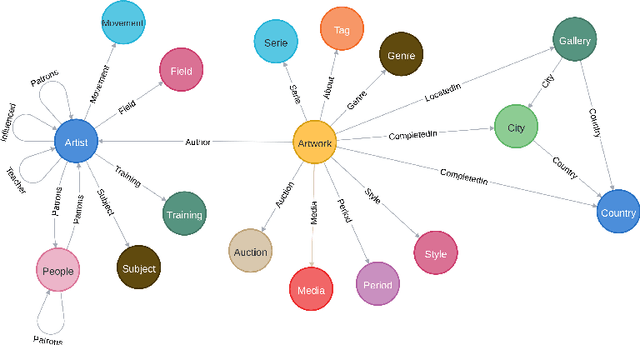
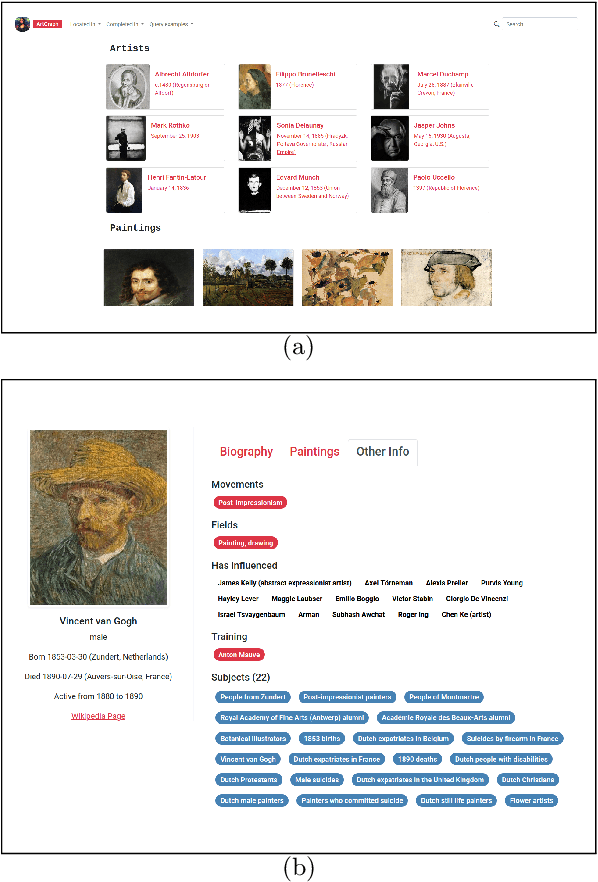
This paper presents our ongoing work towards ArtGraph: an artistic knowledge graph based on WikiArt and DBpedia. Automatic art analysis has seen an ever-increasing interest from the pattern recognition and computer vision community. However, most of the current work is mainly based solely on digitized artwork images, sometimes supplemented with some metadata and textual comments. A knowledge graph that integrates a rich body of information about artworks, artists, painting schools, etc., in a unified structured framework can provide a valuable resource for more powerful information retrieval and knowledge discovery tools in the artistic domain.
Salience-Aware Event Chain Modeling for Narrative Understanding
Sep 22, 2021
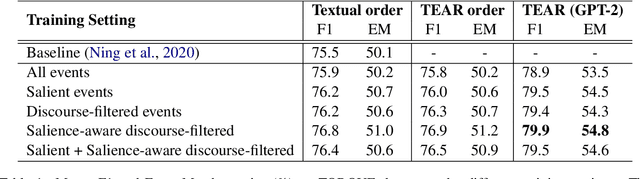
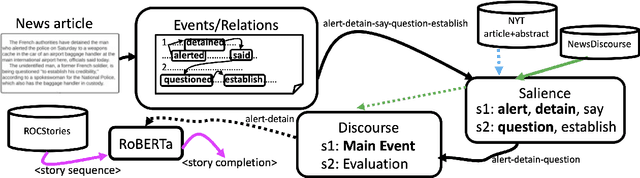
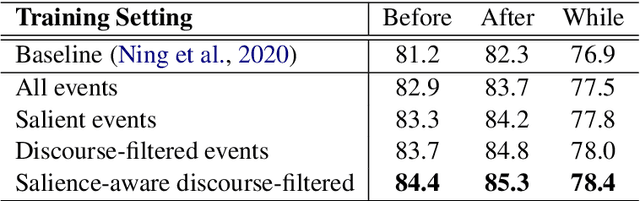
Storytelling, whether via fables, news reports, documentaries, or memoirs, can be thought of as the communication of interesting and related events that, taken together, form a concrete process. It is desirable to extract the event chains that represent such processes. However, this extraction remains a challenging problem. We posit that this is due to the nature of the texts from which chains are discovered. Natural language text interleaves a narrative of concrete, salient events with background information, contextualization, opinion, and other elements that are important for a variety of necessary discourse and pragmatics acts but are not part of the principal chain of events being communicated. We introduce methods for extracting this principal chain from natural language text, by filtering away non-salient events and supportive sentences. We demonstrate the effectiveness of our methods at isolating critical event chains by comparing their effect on downstream tasks. We show that by pre-training large language models on our extracted chains, we obtain improvements in two tasks that benefit from a clear understanding of event chains: narrative prediction and event-based temporal question answering. The demonstrated improvements and ablative studies confirm that our extraction method isolates critical event chains.
MVM3Det: A Novel Method for Multi-view Monocular 3D Detection
Sep 22, 2021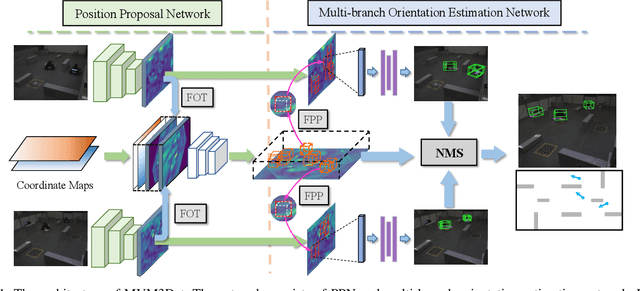
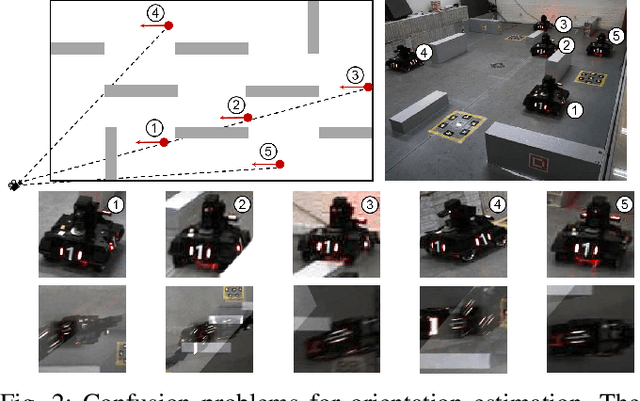

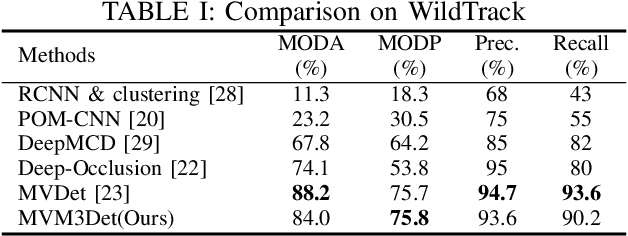
Monocular 3D object detection encounters occlusion problems in many application scenarios, such as traffic monitoring, pedestrian monitoring, etc., which leads to serious false negative. Multi-view object detection effectively solves this problem by combining data from different perspectives. However, due to label confusion and feature confusion, the orientation estimation of multi-view 3D object detection is intractable, which is important for object tracking and intention prediction. In this paper, we propose a novel multi-view 3D object detection method named MVM3Det which simultaneously estimates the 3D position and orientation of the object according to the multi-view monocular information. The method consists of two parts: 1) Position proposal network, which integrates the features from different perspectives into consistent global features through feature orthogonal transformation to estimate the position. 2) Multi-branch orientation estimation network, which introduces feature perspective pooling to overcome the two confusion problems during the orientation estimation. In addition, we present a first dataset for multi-view 3D object detection named MVM3D. Comparing with State-Of-The-Art (SOTA) methods on our dataset and public dataset WildTrack, our method achieves very competitive results.
AtrialJSQnet: A New Framework for Joint Segmentation and Quantification of Left Atrium and Scars Incorporating Spatial and Shape Information
Aug 11, 2020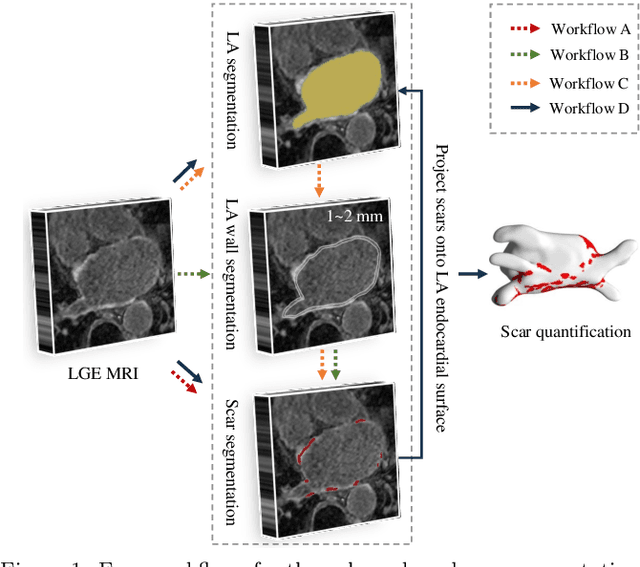
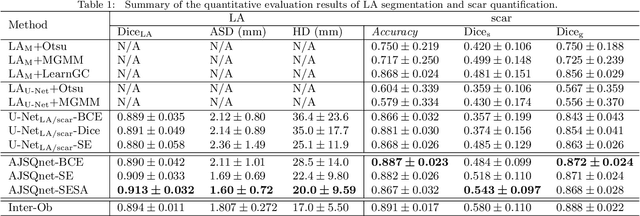
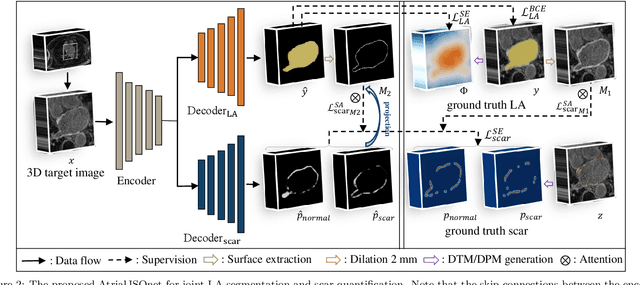
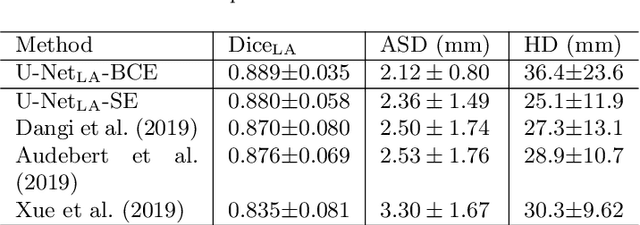
Left atrial (LA) and atrial scar segmentation from late gadolinium enhanced magnetic resonance imaging (LGE MRI) is an important task in clinical practice. %, to guide ablation therapy and predict treatment results for atrial fibrillation (AF) patients. The automatic segmentation is however still challenging, due to the poor image quality, the various LA shapes, the thin wall, and the surrounding enhanced regions. Previous methods normally solved the two tasks independently and ignored the intrinsic spatial relationship between LA and scars. In this work, we develop a new framework, namely AtrialJSQnet, where LA segmentation, scar projection onto the LA surface, and scar quantification are performed simultaneously in an end-to-end style. We propose a mechanism of shape attention (SA) via an explicit surface projection, to utilize the inherent correlation between LA and LA scars. In specific, the SA scheme is embedded into a multi-task architecture to perform joint LA segmentation and scar quantification. Besides, a spatial encoding (SE) loss is introduced to incorporate continuous spatial information of the target, in order to reduce noisy patches in the predicted segmentation. We evaluated the proposed framework on 60 LGE MRIs from the MICCAI2018 LA challenge. Extensive experiments on a public dataset demonstrated the effect of the proposed AtrialJSQnet, which achieved competitive performance over the state-of-the-art. The relatedness between LA segmentation and scar quantification was explicitly explored and has shown significant performance improvements for both tasks. The code and results will be released publicly once the manuscript is accepted for publication via https://zmiclab.github.io/projects.html.
TSM: Temporal Shift Module for Efficient and Scalable Video Understanding on Edge Device
Sep 27, 2021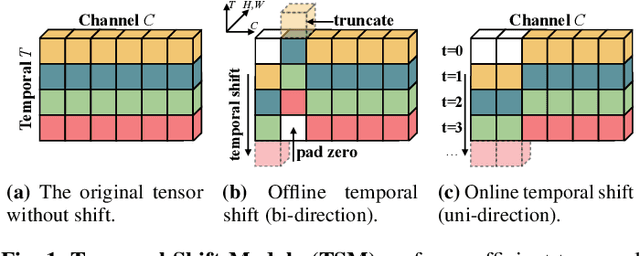
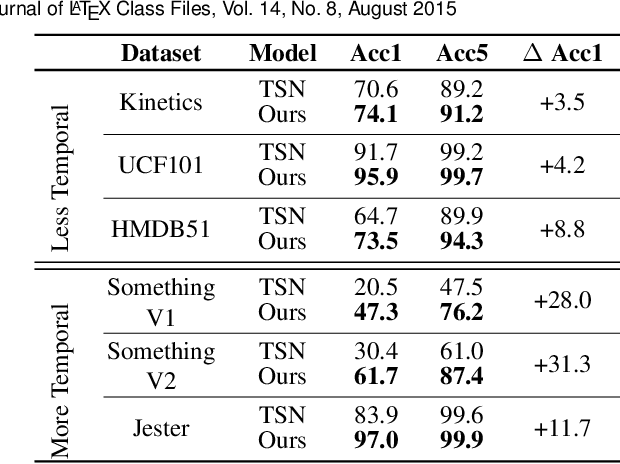

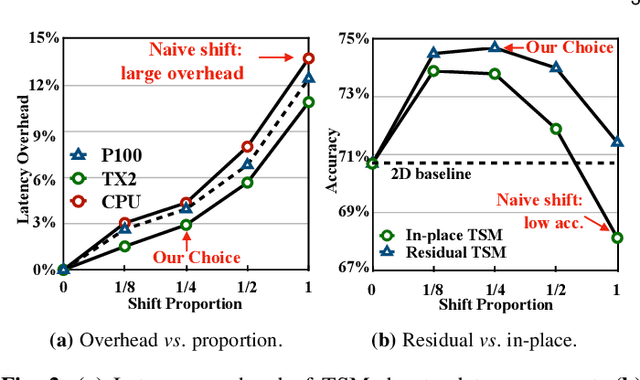
The explosive growth in video streaming requires video understanding at high accuracy and low computation cost. Conventional 2D CNNs are computationally cheap but cannot capture temporal relationships; 3D CNN-based methods can achieve good performance but are computationally intensive. In this paper, we propose a generic and effective Temporal Shift Module (TSM) that enjoys both high efficiency and high performance. The key idea of TSM is to shift part of the channels along the temporal dimension, thus facilitate information exchanged among neighboring frames. It can be inserted into 2D CNNs to achieve temporal modeling at zero computation and zero parameters. TSM offers several unique advantages. Firstly, TSM has high performance; it ranks the first on the Something-Something leaderboard upon submission. Secondly, TSM has high efficiency; it achieves a high frame rate of 74fps and 29fps for online video recognition on Jetson Nano and Galaxy Note8. Thirdly, TSM has higher scalability compared to 3D networks, enabling large-scale Kinetics training on 1,536 GPUs in 15 minutes. Lastly, TSM enables action concepts learning, which 2D networks cannot model; we visualize the category attention map and find that spatial-temporal action detector emerges during the training of classification tasks. The code is publicly available at https://github.com/mit-han-lab/temporal-shift-module.
A Hierarchical Network-Oriented Analysis of User Participation in Misinformation Spread on WhatsApp
Sep 22, 2021



WhatsApp emerged as a major communication platform in many countries in the recent years. Despite offering only one-to-one and small group conversations, WhatsApp has been shown to enable the formation of a rich underlying network, crossing the boundaries of existing groups, and with structural properties that favor information dissemination at large. Indeed, WhatsApp has reportedly been used as a forum of misinformation campaigns with significant social, political and economic consequences in several countries. In this article, we aim at complementing recent studies on misinformation spread on WhatsApp, mostly focused on content properties and propagation dynamics, by looking into the network that connects users sharing the same piece of content. Specifically, we present a hierarchical network-oriented characterization of the users engaged in misinformation spread by focusing on three perspectives: individuals, WhatsApp groups and user communities, i.e., groupings of users who, intentionally or not, share the same content disproportionately often. By analyzing sharing and network topological properties, our study offers valuable insights into how WhatsApp users leverage the underlying network connecting different groups to gain large reach in the spread of misinformation on the platform.