 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-Supervised Graph Representation Learning via Topology Transformations
May 25, 2021
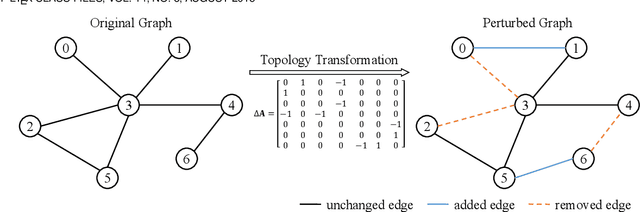
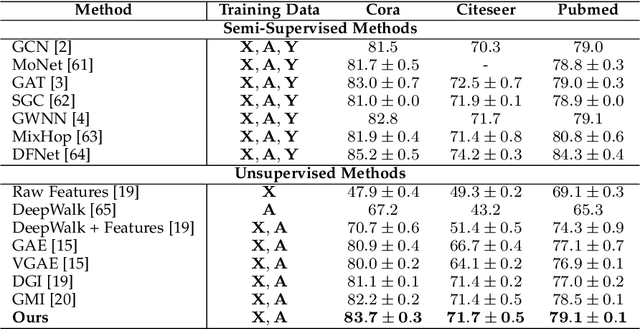
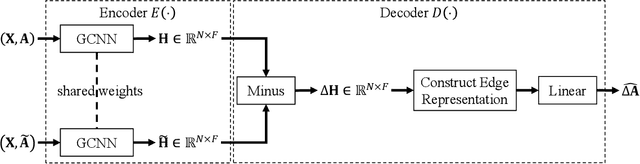
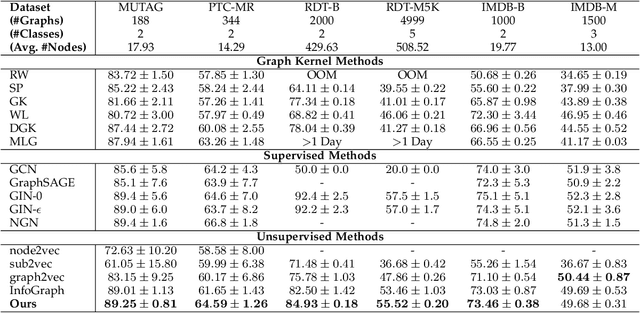
We present the Topology Transformation Equivariant Representation learning, a general paradigm of self-supervised learning for node representations of graph data to enable the wide applicability of Graph Convolutional Neural Networks (GCNNs). We formalize the proposed model from an information-theoretic perspective, by maximizing the mutual information between topology transformations and node representations before and after the transformations. We derive that maximizing such mutual information can be relaxed to minimizing the cross entropy between the applied topology transformation and its estimation from node representations. In particular, we seek to sample a subset of node pairs from the original graph and flip the edge connectivity between each pair to transform the graph topology. Then, we self-train a representation encoder to learn node representations by reconstructing the topology transformations from the feature representations of the original and transformed graphs. In experiments, we apply the proposed model to the downstream node and graph classification tasks, and results show that the proposed method outperforms the state-of-the-art unsupervised approaches.
Can Language Models Encode Perceptual Structure Without Grounding? A Case Study in Color
Sep 14, 2021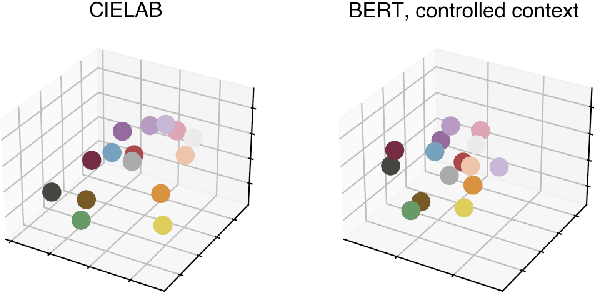

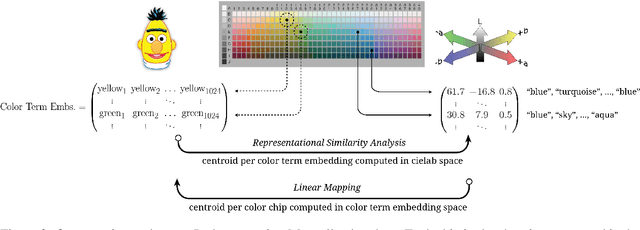
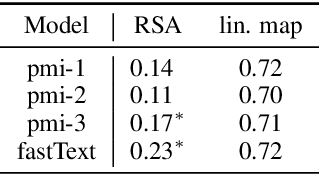
Pretrained language models have been shown to encode relational information, such as the relations between entities or concepts in knowledge-bases -- (Paris, Capital, France). However, simple relations of this type can often be recovered heuristically and the extent to which models implicitly reflect topological structure that is grounded in world, such as perceptual structure, is unknown. To explore this question, we conduct a thorough case study on color. Namely, we employ a dataset of monolexemic color terms and color chips represented in CIELAB, a color space with a perceptually meaningful distance metric. Using two methods of evaluating the structural alignment of colors in this space with text-derived color term representations, we find significant correspondence. Analyzing the differences in alignment across the color spectrum, we find that warmer colors are, on average, better aligned to the perceptual color space than cooler ones, suggesting an intriguing connection to findings from recent work on efficient communication in color naming. Further analysis suggests that differences in alignment are, in part, mediated by collocationality and differences in syntactic usage, posing questions as to the relationship between color perception and usage and context.
Tensor-based framework for training flexible neural networks
Jun 25, 2021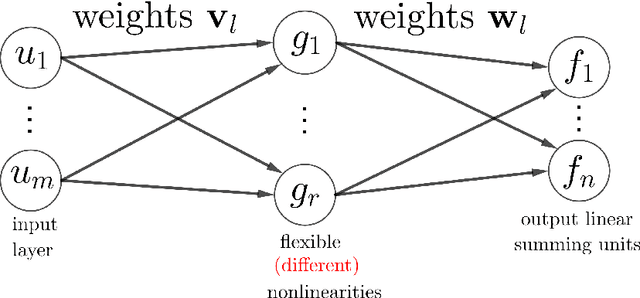
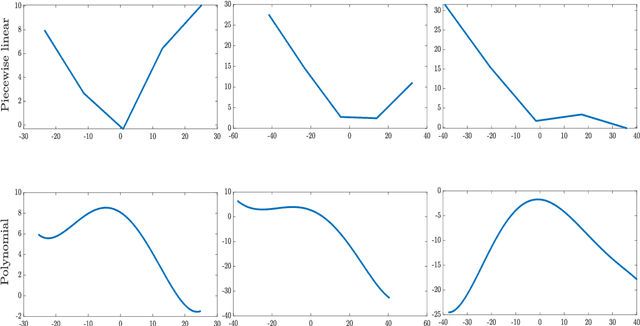
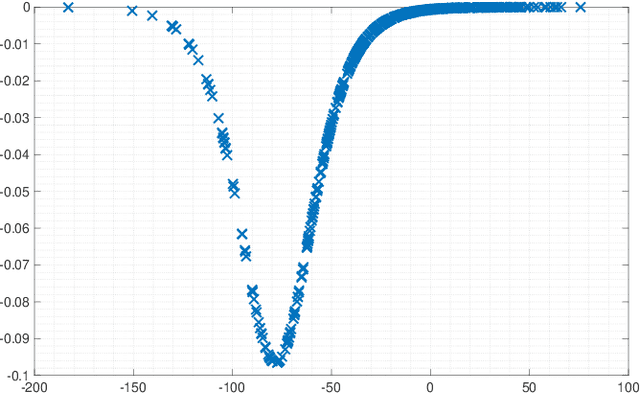
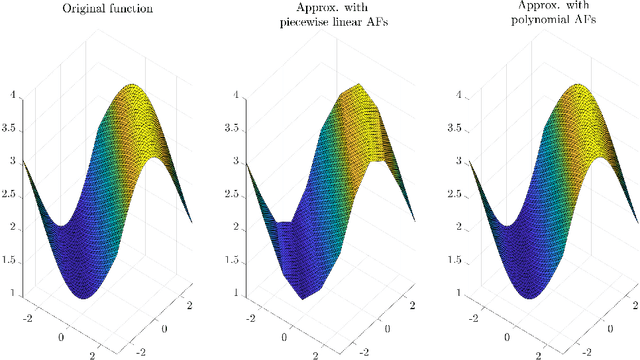
Activation functions (AFs) are an important part of the design of neural networks (NNs), and their choice plays a predominant role in the performance of a NN. In this work, we are particularly interested in the estimation of flexible activation functions using tensor-based solutions, where the AFs are expressed as a weighted sum of predefined basis functions. To do so, we propose a new learning algorithm which solves a constrained coupled matrix-tensor factorization (CMTF) problem. This technique fuses the first and zeroth order information of the NN, where the first-order information is contained in a Jacobian tensor, following a constrained canonical polyadic decomposition (CPD). The proposed algorithm can handle different decomposition bases. The goal of this method is to compress large pretrained NN models, by replacing subnetworks, {\em i.e.,} one or multiple layers of the original network, by a new flexible layer. The approach is applied to a pretrained convolutional neural network (CNN) used for character classification.
Unbiased Asymmetric Actor-Critic for Partially Observable Reinforcement Learning
May 25, 2021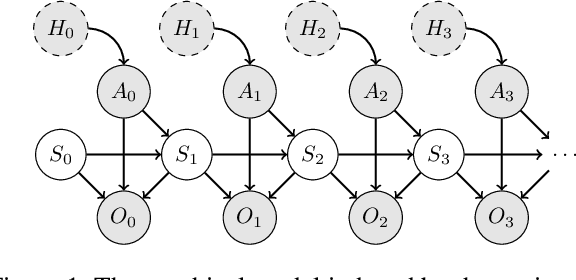
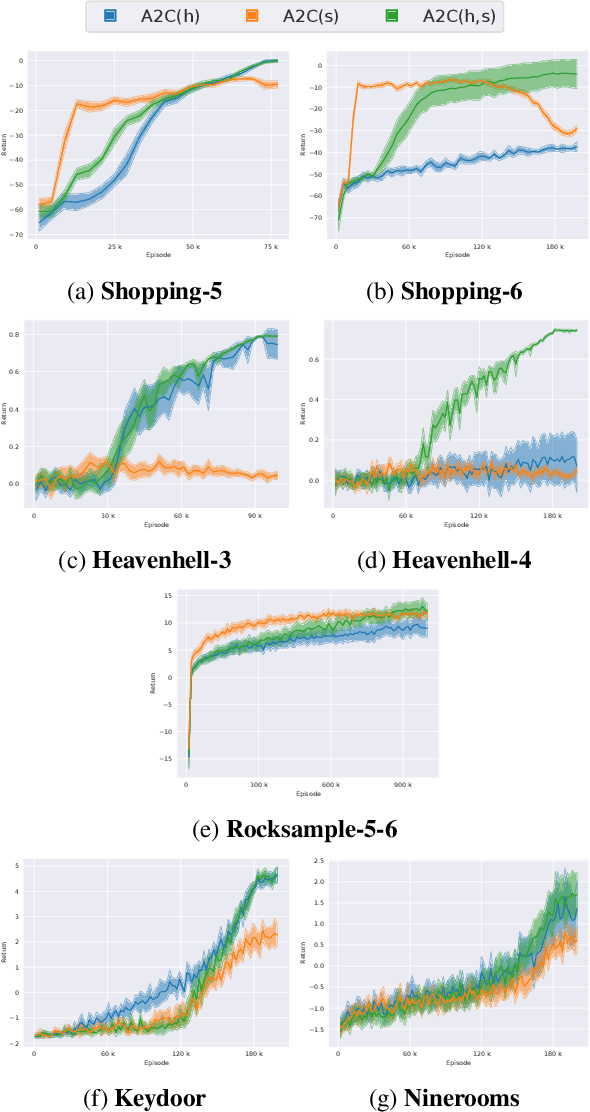
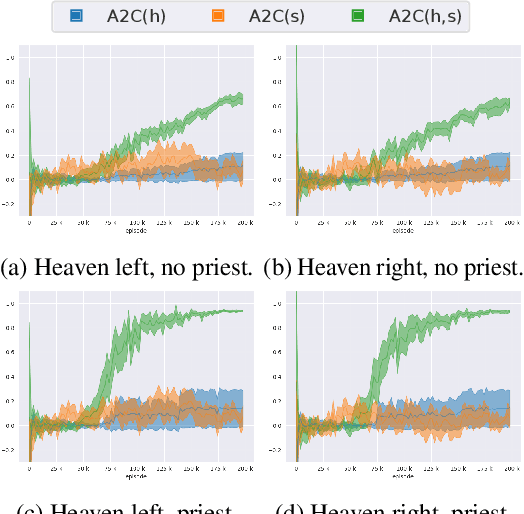
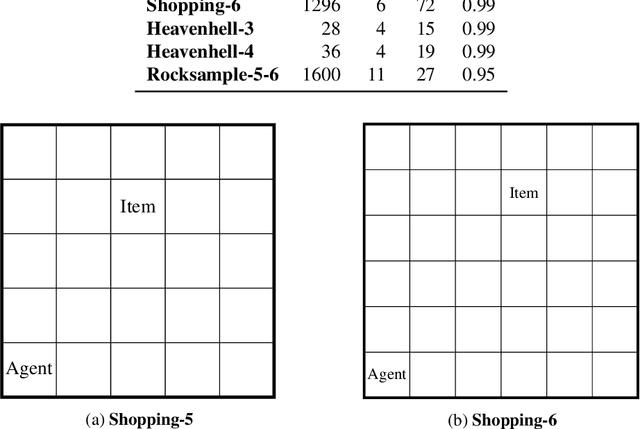
In partially observable reinforcement learning, offline training gives access to latent information which is not available during online training and/or execution, such as the system state. Asymmetric actor-critic methods exploit such information by training a history-based policy via a state-based critic. However, many asymmetric methods lack theoretical foundation, and are only evaluated on limited domains. We examine the theory of asymmetric actor-critic methods which use state-based critics, and expose fundamental issues which undermine the validity of a common variant, and its ability to address high partial observability. We propose an unbiased asymmetric actor-critic variant which is able to exploit state information while remaining theoretically sound, maintaining the validity of the policy gradient theorem, and introducing no bias and relatively low variance into the training process. An empirical evaluation performed on domains which exhibit significant partial observability confirms our analysis, and shows the unbiased asymmetric actor-critic converges to better policies and/or faster than symmetric actor-critic and standard asymmetric actor-critic baselines.
Generative Adversarial Nets for Information Retrieval: Fundamentals and Advances
Jun 10, 2018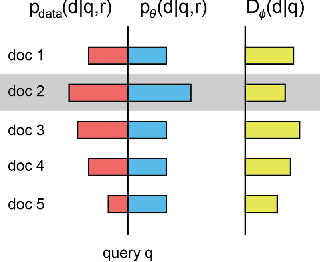
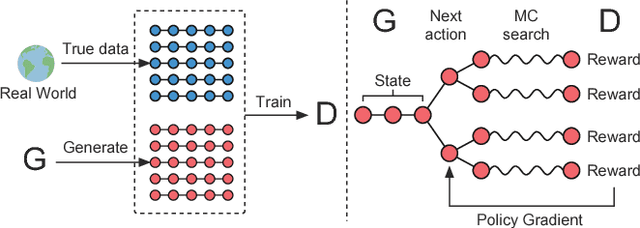
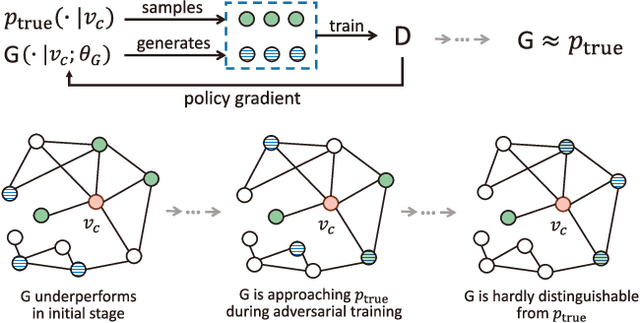
Generative adversarial nets (GANs) have been widely studied during the recent development of deep learning and unsupervised learning. With an adversarial training mechanism, GAN manages to train a generative model to fit the underlying unknown real data distribution under the guidance of the discriminative model estimating whether a data instance is real or generated. Such a framework is originally proposed for fitting continuous data distribution such as images, thus it is not straightforward to be directly applied to information retrieval scenarios where the data is mostly discrete, such as IDs, text and graphs. In this tutorial, we focus on discussing the GAN techniques and the variants on discrete data fitting in various information retrieval scenarios. (i) We introduce the fundamentals of GAN framework and its theoretic properties; (ii) we carefully study the promising solutions to extend GAN onto discrete data generation; (iii) we introduce IRGAN, the fundamental GAN framework of fitting single ID data distribution and the direct application on information retrieval; (iv) we further discuss the task of sequential discrete data generation tasks, e.g., text generation, and the corresponding GAN solutions; (v) we present the most recent work on graph/network data fitting with node embedding techniques by GANs. Meanwhile, we also introduce the relevant open-source platforms such as IRGAN and Texygen to help audience conduct research experiments on GANs in information retrieval. Finally, we conclude this tutorial with a comprehensive summarization and a prospect of further research directions for GANs in information retrieval.
The Backpropagation Algorithm Implemented on Spiking Neuromorphic Hardware
Jun 13, 2021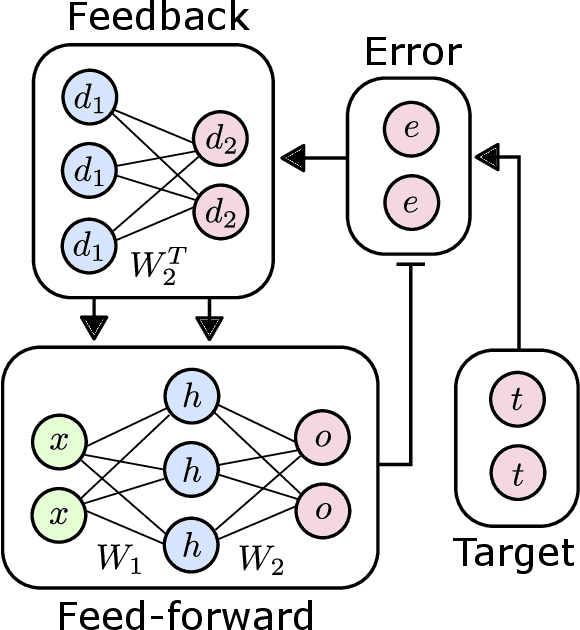
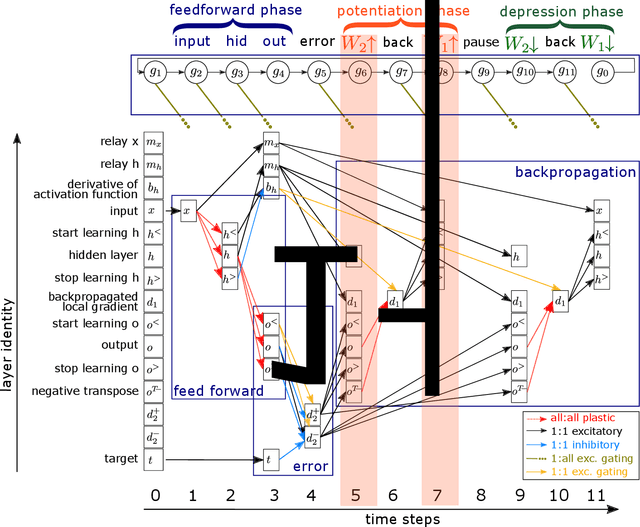
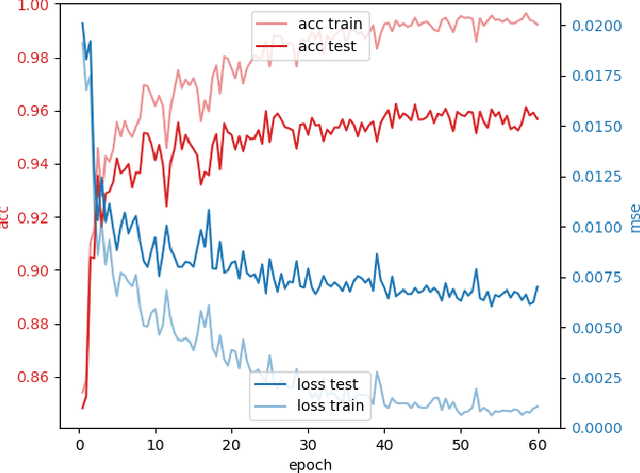
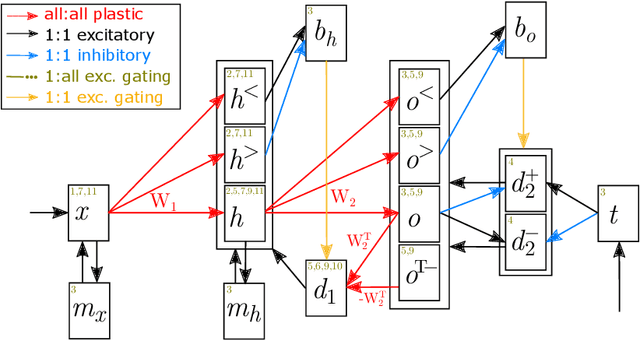
The capabilities of natural neural systems have inspired new generations of machine learning algorithms as well as neuromorphic very large-scale integrated (VLSI) circuits capable of fast, low-power information processing. However, most modern machine learning algorithms are not neurophysiologically plausible and thus are not directly implementable in neuromorphic hardware. In particular, the workhorse of modern deep learning, the backpropagation algorithm, has proven difficult to translate to neuromorphic hardware. In this study, we present a neuromorphic, spiking backpropagation algorithm based on pulse-gated dynamical information coordination and processing, implemented on Intel's Loihi neuromorphic research processor. We demonstrate a proof-of-principle three-layer circuit that learns to classify digits from the MNIST dataset. This implementation shows a path for using massively parallel, low-power, low-latency neuromorphic processors in modern deep learning applications.
A Reinforcement Learning Approach for Scheduling in mmWave Networks
Aug 01, 2021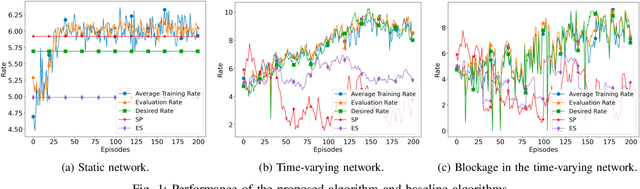
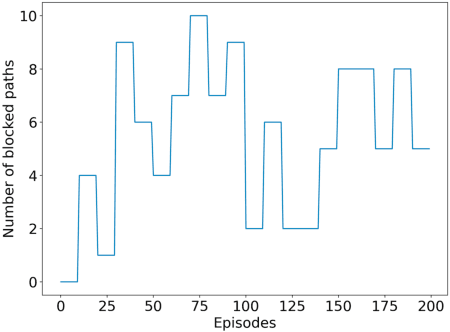
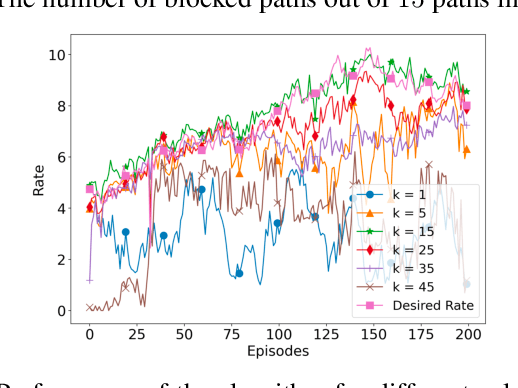
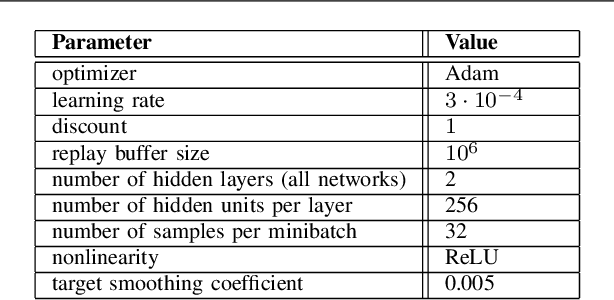
We consider a source that wishes to communicate with a destination at a desired rate, over a mmWave network where links are subject to blockage and nodes to failure (e.g., in a hostile military environment). To achieve resilience to link and node failures, we here explore a state-of-the-art Soft Actor-Critic (SAC) deep reinforcement learning algorithm, that adapts the information flow through the network, without using knowledge of the link capacities or network topology. Numerical evaluations show that our algorithm can achieve the desired rate even in dynamic environments and it is robust against blockage.
RoR: Read-over-Read for Long Document Machine Reading Comprehension
Sep 14, 2021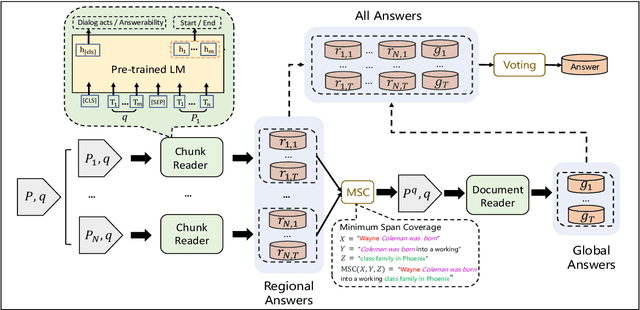
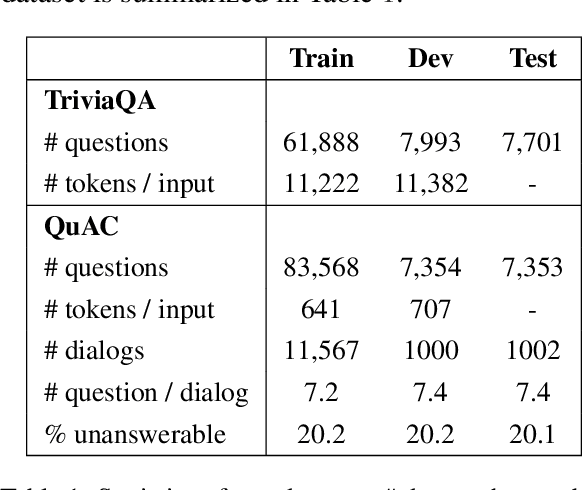
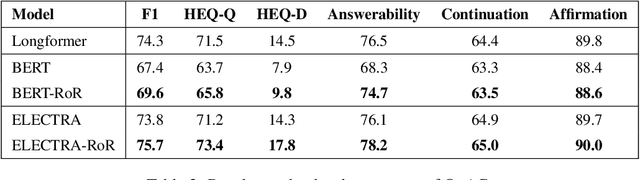
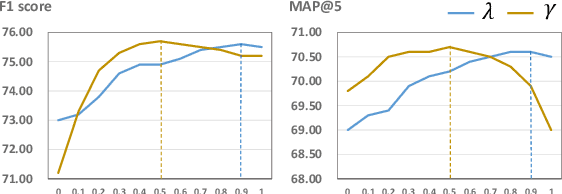
Transformer-based pre-trained models, such as BERT, have achieved remarkable results on machine reading comprehension. However, due to the constraint of encoding length (e.g., 512 WordPiece tokens), a long document is usually split into multiple chunks that are independently read. It results in the reading field being limited to individual chunks without information collaboration for long document machine reading comprehension. To address this problem, we propose RoR, a read-over-read method, which expands the reading field from chunk to document. Specifically, RoR includes a chunk reader and a document reader. The former first predicts a set of regional answers for each chunk, which are then compacted into a highly-condensed version of the original document, guaranteeing to be encoded once. The latter further predicts the global answers from this condensed document. Eventually, a voting strategy is utilized to aggregate and rerank the regional and global answers for final prediction. Extensive experiments on two benchmarks QuAC and TriviaQA demonstrate the effectiveness of RoR for long document reading. Notably, RoR ranks 1st place on the QuAC leaderboard (https://quac.ai/) at the time of submission (May 17th, 2021).
Simple Video Generation using Neural ODEs
Sep 07, 2021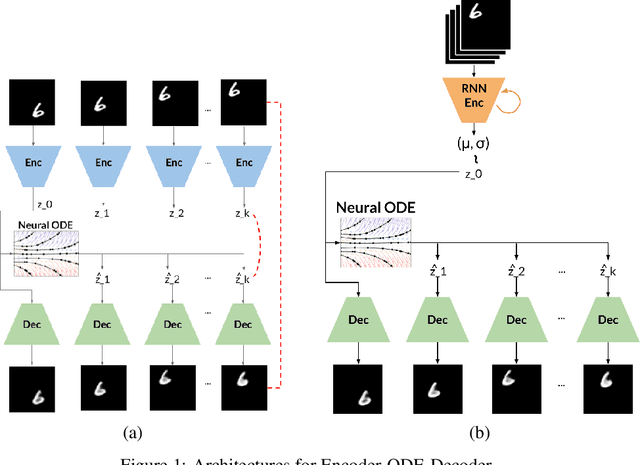
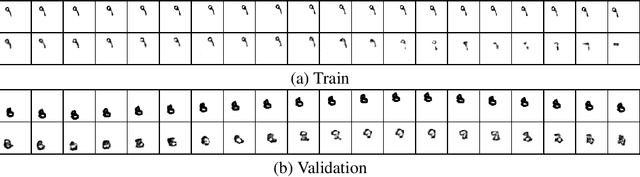
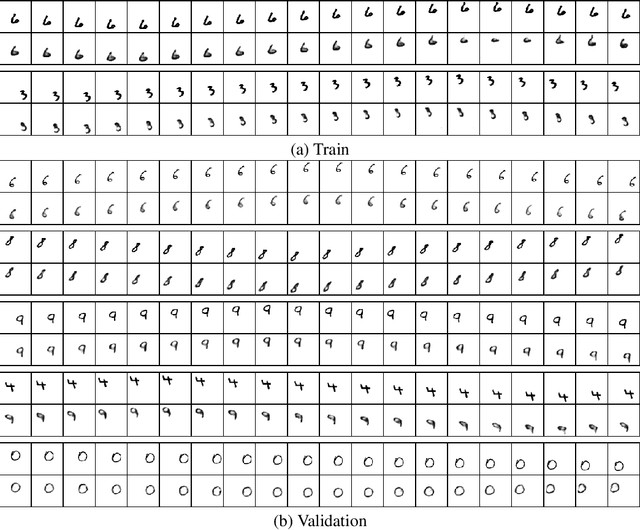
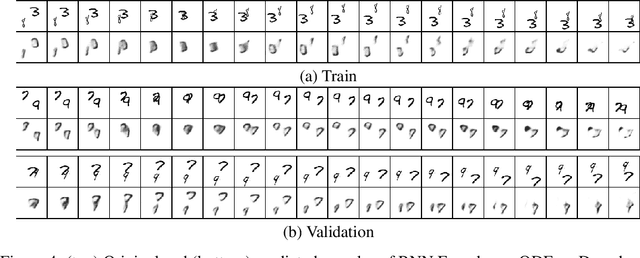
Despite having been studied to a great extent, the task of conditional generation of sequences of frames, or videos, remains extremely challenging. It is a common belief that a key step towards solving this task resides in modelling accurately both spatial and temporal information in video signals. A promising direction to do so has been to learn latent variable models that predict the future in latent space and project back to pixels, as suggested in recent literature. Following this line of work and building on top of a family of models introduced in prior work, Neural ODE, we investigate an approach that models time-continuous dynamics over a continuous latent space with a differential equation with respect to time. The intuition behind this approach is that these trajectories in latent space could then be extrapolated to generate video frames beyond the time steps for which the model is trained. We show that our approach yields promising results in the task of future frame prediction on the Moving MNIST dataset with 1 and 2 digits.
* 8 pages, 4 figures, NeurIPS 2019 workshop
Camera-Tracklet-Aware Contrastive Learning for Unsupervised Vehicle Re-Identification
Sep 14, 2021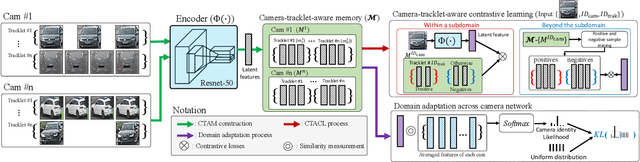
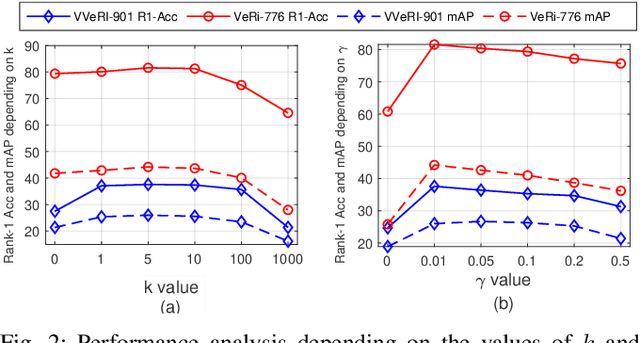
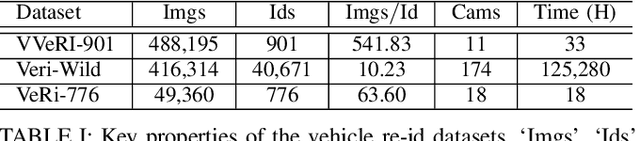
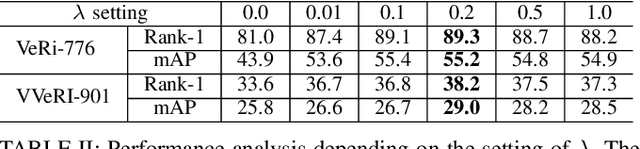
Recently, vehicle re-identification methods based on deep learning constitute remarkable achievement. However, this achievement requires large-scale and well-annotated datasets. In constructing the dataset, assigning globally available identities (Ids) to vehicles captured from a great number of cameras is labour-intensive, because it needs to consider their subtle appearance differences or viewpoint variations. In this paper, we propose camera-tracklet-aware contrastive learning (CTACL) using the multi-camera tracklet information without vehicle identity labels. The proposed CTACL divides an unlabelled domain, i.e., entire vehicle images, into multiple camera-level subdomains and conducts contrastive learning within and beyond the subdomains. The positive and negative samples for contrastive learning are defined using tracklet Ids of each camera. Additionally, the domain adaptation across camera networks is introduced to improve the generalisation performance of learnt representations and alleviate the performance degradation resulted from the domain gap between the subdomains. We demonstrate the effectiveness of our approach on video-based and image-based vehicle Re-ID datasets. Experimental results show that the proposed method outperforms the recent state-of-the-art unsupervised vehicle Re-ID methods. The source code for this paper is publicly available on `https://github.com/andreYoo/CTAM-CTACL-VVReID.git'.