 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Chronic Pain and Language: A Topic Modelling Approach to Personal Pain Descriptions
Sep 01, 2021
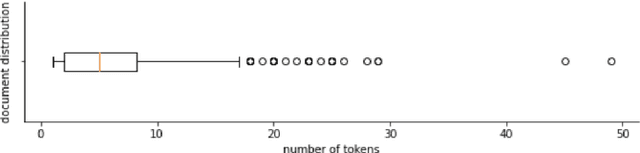
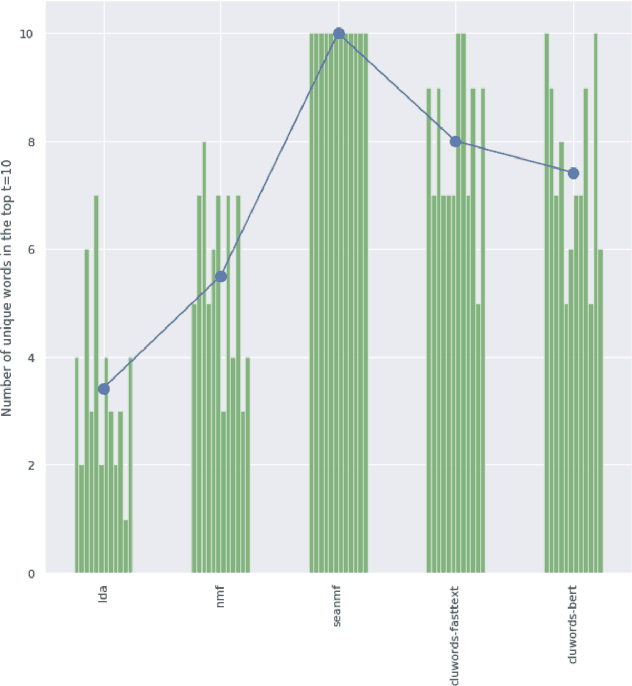
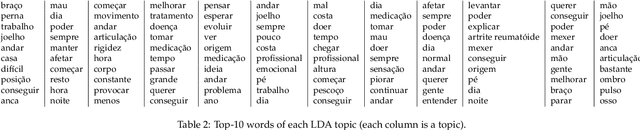
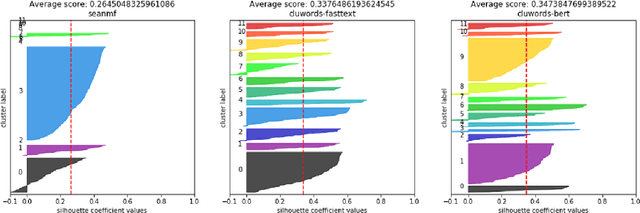
Chronic pain is recognized as a major health problem, with impacts not only at the economic, but also at the social, and individual levels. Being a private and subjective experience, it is impossible to externally and impartially experience, describe, and interpret chronic pain as a purely noxious stimulus that would directly point to a causal agent and facilitate its mitigation, contrary to acute pain, the assessment of which is usually straightforward. Verbal communication is, thus, key to convey relevant information to health professionals that would otherwise not be accessible to external entities, namely, intrinsic qualities about the painful experience and the patient. We propose and discuss a topic modelling approach to recognize patterns in verbal descriptions of chronic pain, and use these patterns to quantify and qualify experiences of pain. Our approaches allow for the extraction of novel insights on chronic pain experiences from the obtained topic models and latent spaces. We argue that our results are clinically relevant for the assessment and management of chronic pain.
Audio-Visual Speech Recognition is Worth 32$\times$32$\times$8 Voxels
Sep 20, 2021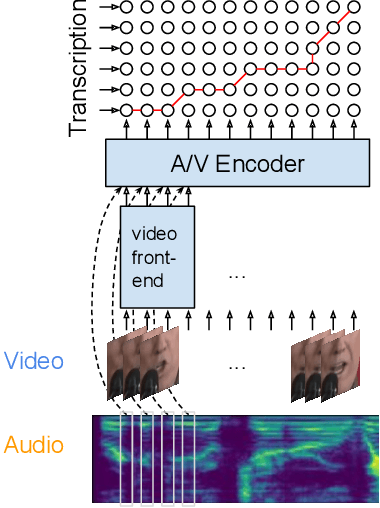

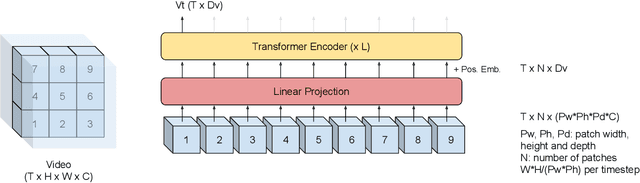
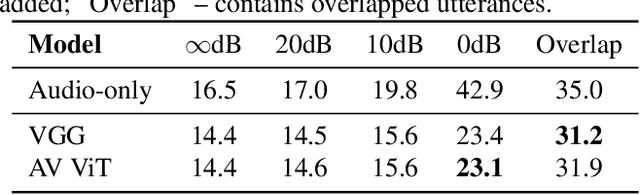
Audio-visual automatic speech recognition (AV-ASR) introduces the video modality into the speech recognition process, often by relying on information conveyed by the motion of the speaker's mouth. The use of the video signal requires extracting visual features, which are then combined with the acoustic features to build an AV-ASR system [1]. This is traditionally done with some form of 3D convolutional network (e.g. VGG) as widely used in the computer vision community. Recently, image transformers [2] have been introduced to extract visual features useful for image classification tasks. In this work, we propose to replace the 3D convolutional visual front-end with a video transformer front-end. We train our systems on a large-scale dataset composed of YouTube videos and evaluate performance on the publicly available LRS3-TED set, as well as on a large set of YouTube videos. On a lip-reading task, the transformer-based front-end shows superior performance compared to a strong convolutional baseline. On an AV-ASR task, the transformer front-end performs as well as (or better than) the convolutional baseline. Fine-tuning our model on the LRS3-TED training set matches previous state of the art. Thus, we experimentally show the viability of the convolution-free model for AV-ASR.
Graph Autoencoders for Embedding Learning in Brain Networks and Major Depressive Disorder Identification
Jul 27, 2021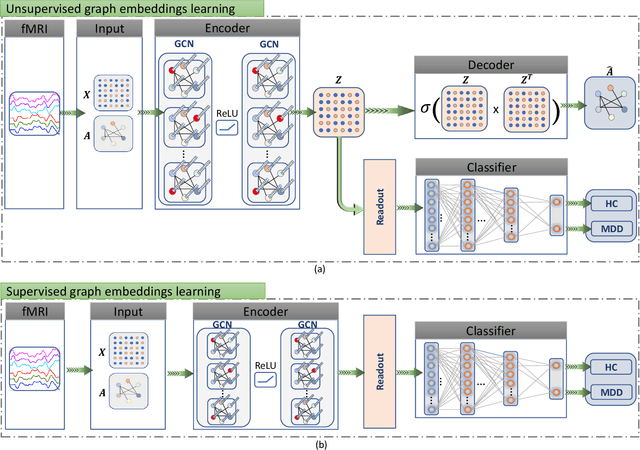
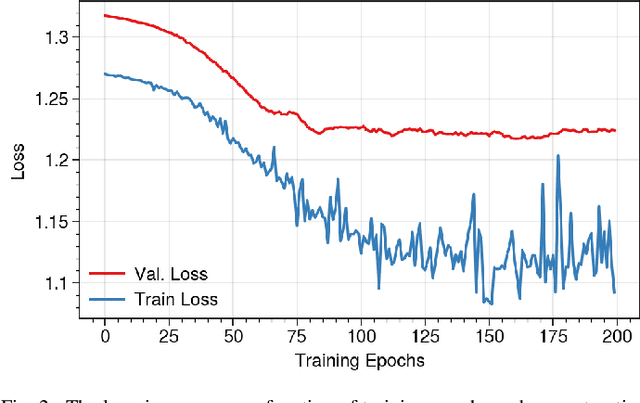
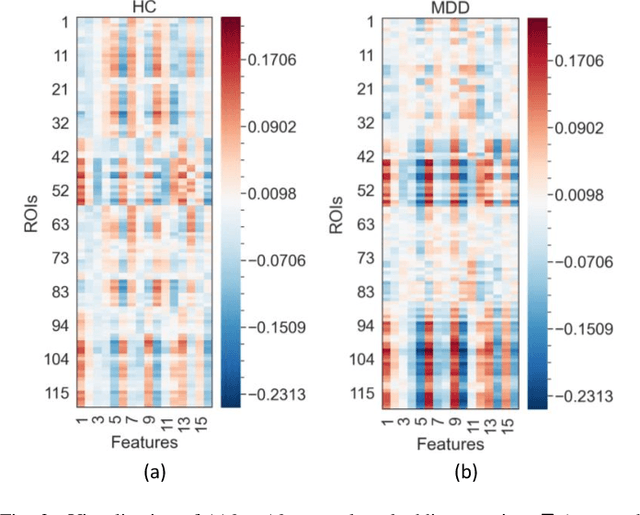
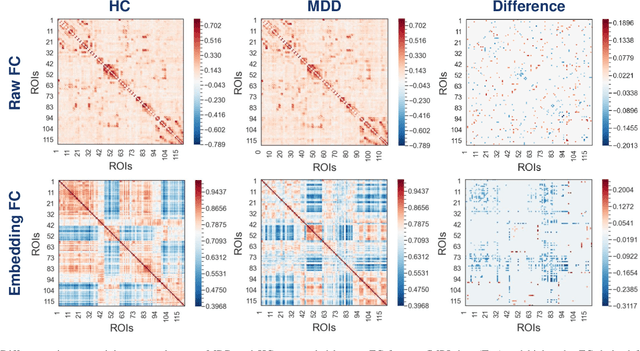
Brain functional connectivity (FC) reveals biomarkers for identification of various neuropsychiatric disorders. Recent application of deep neural networks (DNNs) to connectome-based classification mostly relies on traditional convolutional neural networks using input connectivity matrices on a regular Euclidean grid. We propose a graph deep learning framework to incorporate the non-Euclidean information about graph structure for classifying functional magnetic resonance imaging (fMRI)- derived brain networks in major depressive disorder (MDD). We design a novel graph autoencoder (GAE) architecture based on the graph convolutional networks (GCNs) to embed the topological structure and node content of large-sized fMRI networks into low-dimensional latent representations. In network construction, we employ the Ledoit-Wolf (LDW) shrinkage method to estimate the high-dimensional FC metrics efficiently from fMRI data. We consider both supervised and unsupervised approaches for the graph embedded learning. The learned embeddings are then used as feature inputs for a deep fully-connected neural network (FCNN) to discriminate MDD from healthy controls. Evaluated on a resting-state fMRI MDD dataset with 43 subjects, results show that the proposed GAE-FCNN model significantly outperforms several state-of-the-art DNN methods for brain connectome classification, achieving accuracy of 72.50% using the LDW-FC metrics as node features. The graph embeddings of fMRI FC networks learned by the GAE also reveal apparent group differences between MDD and HC. Our new framework demonstrates feasibility of learning graph embeddings on brain networks to provide discriminative information for diagnosis of brain disorders.
Object Shell Reconstruction: Camera-centric Object Representation for Robotic Grasping
Sep 14, 2021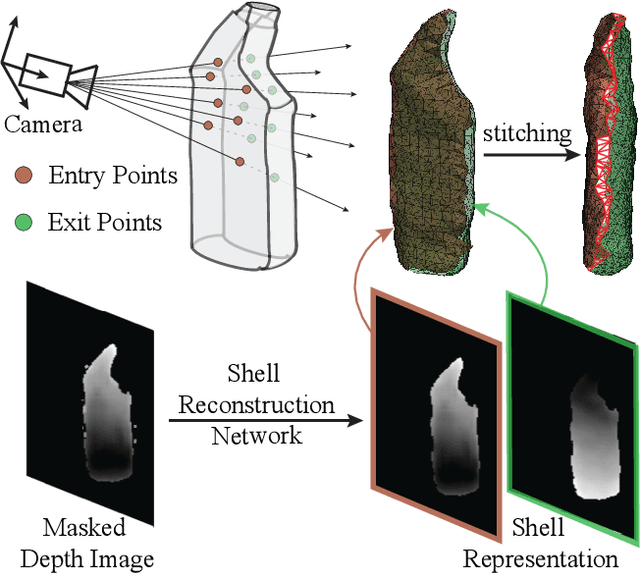
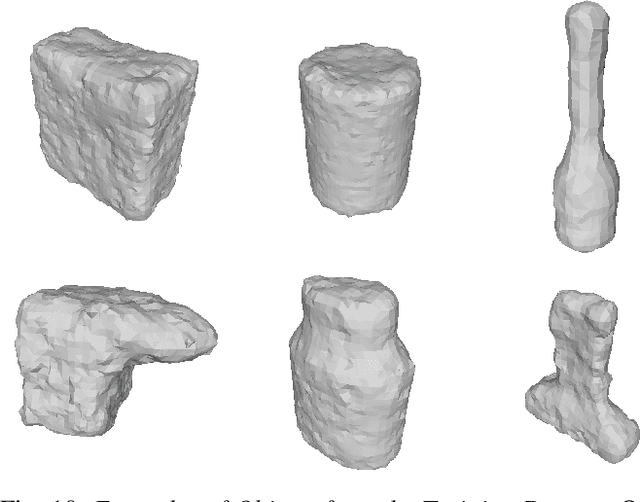

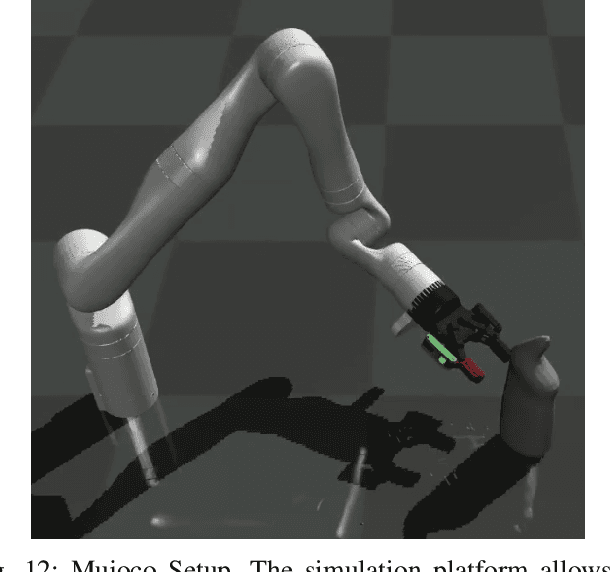
Robots can effectively grasp and manipulate objects using their 3D models. In this paper, we propose a simple shape representation and a reconstruction method that outperforms state-of-the-art methods in terms of geometric metrics and enables grasp generation with high precision and success. Our reconstruction method models the object geometry as a pair of depth images, composing the "shell" of the object. This representation allows using image-to-image residual ConvNet architectures for 3D reconstruction, generates object reconstruction directly in the camera frame, and generalizes well to novel object types. Moreover, an object shell can be converted into an object mesh in a fraction of a second, providing time and memory efficient alternative to voxel or implicit representations. We explore the application of shell representation for grasp planning. With rigorous experimental validation, both in simulation and on a real setup, we show that shell reconstruction encapsulates sufficient geometric information to generate precise grasps and the associated grasp quality with over 90% accuracy. Diverse grasps computed on shell reconstructions allow the robot to select and execute grasps in cluttered scenes with more than 93% success rate.
Blind Interference Alignment in 6G Optical Wireless Communications
Sep 25, 2021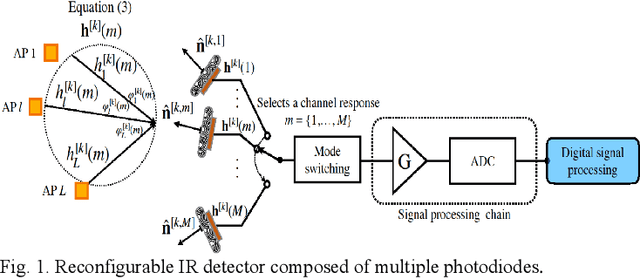
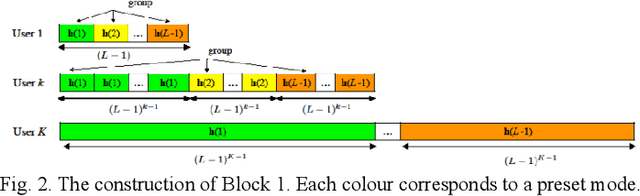
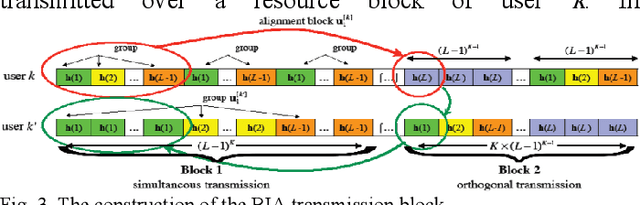

In recent years, the demand for high speed wireless networking has increased considerably due to the enormous number of devices connected to the Internet. In this context, optical wireless communication (OWC) has received tremendous interest in the context of next generation wireless networks where OWC offers a huge unlicensed bandwidth using optical bands. OWC systems are directional and can naturally provide multiple-input and multiple-output (MIMO) configurations serving multiple users using a high number of transmitters in the indoor environment to ensure coverage. Therefore, multiuser interference must be managed efficiently to enhance the performance of OWC networks considering different metrics. A transmission scheme referred to as blind interference alignment (BIA) is proposed for OWC systems to maximize the multiplexing gain without the need for channel state information (CSI) at the transmitters, which is difficult to achieve in MIMO scenarios. However, standard BIA avoids the need for CSI at the cost of requiring channel coherence time large enough for transmitting the whole transmission block. Moreover, the methodology of BIA results in increased noise with increase in the number of transmitters and users. Therefore, various network topologies such as network centric (NC) and user centric (UC) designs are proposed to relax the limitations of BIA where these topologies divide the receiving area into multiple clusters. The results show a significant enhancement in the performance of topological BIA compared with standard BIA.
Fine-tuning Pretrained Language Models with Label Attention for Explainable Biomedical Text Classification
Aug 28, 2021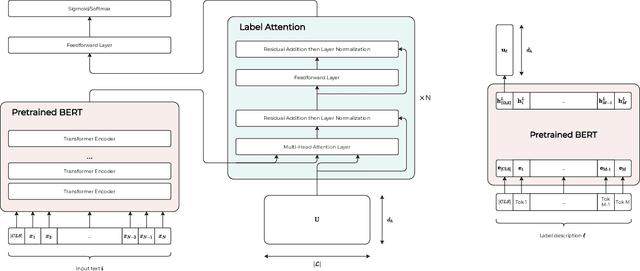

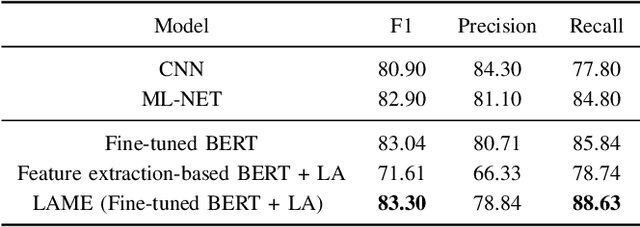

The massive growth of digital biomedical data is making biomedical text indexing and classification increasingly important. Accordingly, previous research has devised numerous deep learning techniques focused on using feedforward, convolutional or recurrent neural architectures. More recently, fine-tuned transformers-based pretrained models (PTMs) have demonstrated superior performance compared to such models in many natural language processing tasks. However, the direct use of PTMs in the biomedical domain is only limited to the target documents, ignoring the rich semantic information in the label descriptions. In this paper, we develop an improved label attention-based architecture to inject semantic label description into the fine-tuning process of PTMs. Results on two public medical datasets show that the proposed fine-tuning scheme outperforms the conventionally fine-tuned PTMs and prior state-of-the-art models. Furthermore, we show that fine-tuning with the label attention mechanism is interpretable in the interpretability study.
Pose-guided Inter- and Intra-part Relational Transformer for Occluded Person Re-Identification
Sep 08, 2021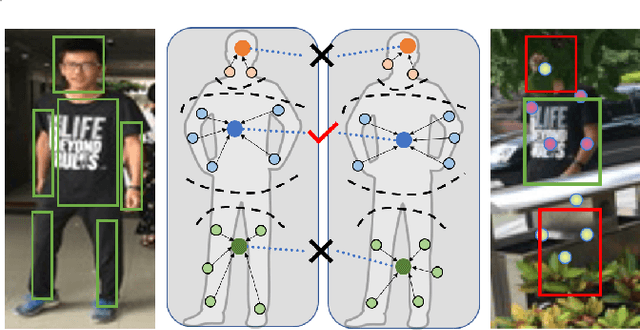
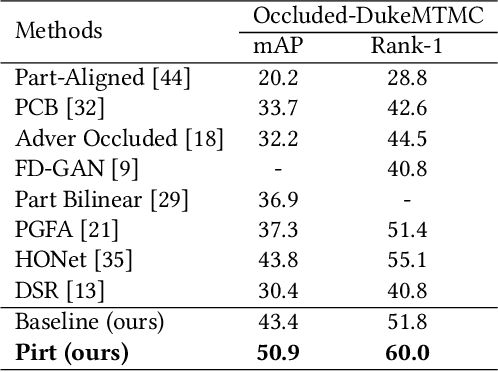
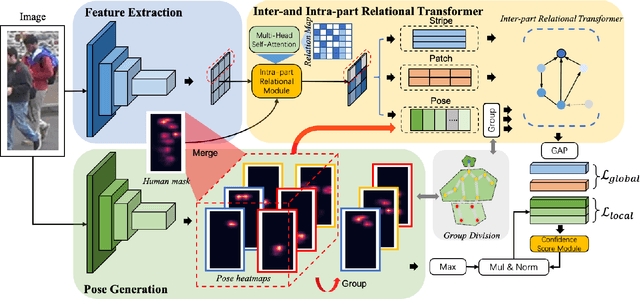
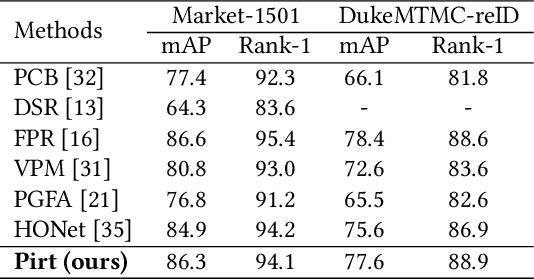
Person Re-Identification (Re-Id) in occlusion scenarios is a challenging problem because a pedestrian can be partially occluded. The use of local information for feature extraction and matching is still necessary. Therefore, we propose a Pose-guided inter-and intra-part relational transformer (Pirt) for occluded person Re-Id, which builds part-aware long-term correlations by introducing transformers. In our framework, we firstly develop a pose-guided feature extraction module with regional grouping and mask construction for robust feature representations. The positions of a pedestrian in the image under surveillance scenarios are relatively fixed, hence we propose an intra-part and inter-part relational transformer. The intra-part module creates local relations with mask-guided features, while the inter-part relationship builds correlations with transformers, to develop cross relationships between part nodes. With the collaborative learning inter- and intra-part relationships, experiments reveal that our proposed Pirt model achieves a new state of the art on the public occluded dataset, and further extensions on standard non-occluded person Re-Id datasets also reveal our comparable performances.
Collaborative Variational Bandwidth Auto-encoder for Recommender Systems
May 17, 2021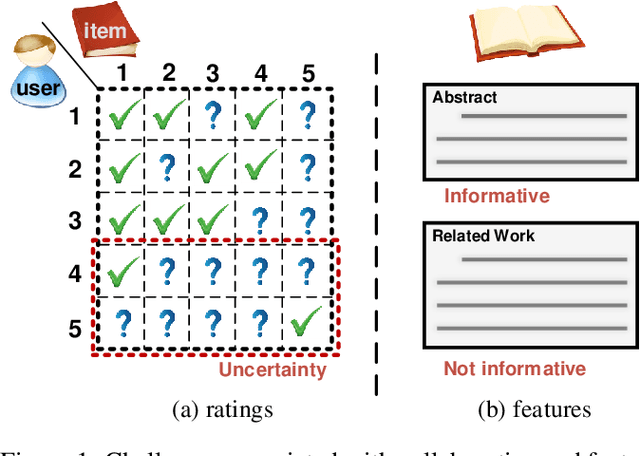
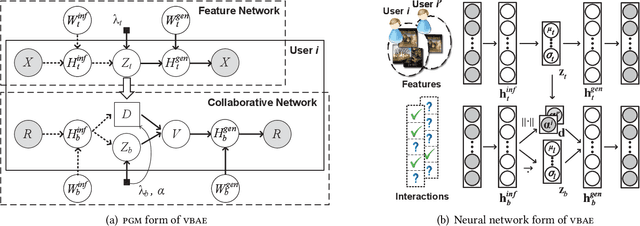
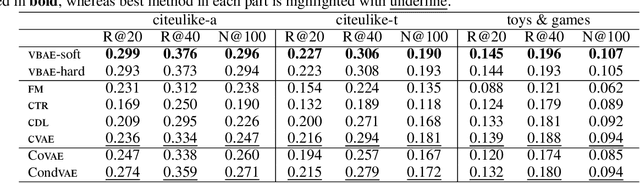
Collaborative filtering has been widely adopted by modern recommender systems to discover user preferences based on their past behaviors. However, the observed interactions for different users are usually unbalanced, which leads to high uncertainty in the collaborative embeddings of users with sparse ratings, thereby severely degenerating the recommendation performance. Consequently, more efforts have been dedicated to the hybrid recommendation strategy where user/item features are utilized as auxiliary information to address the sparsity problem. However, since these features contain rich multimodal patterns and most of them are irrelevant to the recommendation purpose, excessive reliance on these features will make the model difficult to generalize. To address the above two challenges, we propose a VBAE for recommendation. VBAE models both the collaborative and the user feature embeddings as Gaussian random variables inferred via deep neural networks to capture non-linear similarities between users based on their ratings and features. Furthermore, VBAE establishes an information regulation mechanism by introducing a user-dependent channel variable where the bandwidth is determined by the information already contained in the observed ratings to dynamically control the amount of information allowed to be accessed from the corresponding user features. The user-dependent channel variable alleviates the uncertainty problem when the ratings are sparse while avoids unnecessary dependence of the model on noisy user features simultaneously. Codes and datasets are released at https://github.com/yaochenzhu/vbae.
Provident Vehicle Detection at Night for Advanced Driver Assistance Systems
Aug 11, 2021

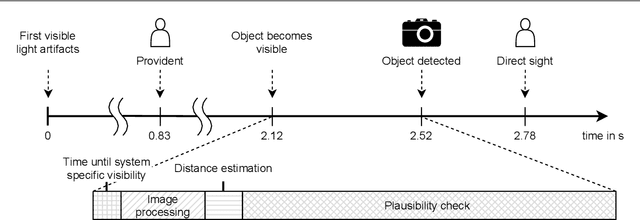

In recent years, computer vision algorithms have become more and more powerful, which enabled technologies such as autonomous driving to evolve with rapid pace. However, current algorithms mainly share one limitation: They rely on directly visible objects. This is a major drawback compared to human behavior, where indirect visual cues caused by the actual object (e.g., shadows) are already used intuitively to retrieve information or anticipate occurring objects. While driving at night, this performance deficit becomes even more obvious: Humans already process the light artifacts caused by oncoming vehicles to assume their future appearance, whereas current object detection systems rely on the oncoming vehicle's direct visibility. Based on previous work in this subject, we present with this paper a complete system capable of solving the task to providently detect oncoming vehicles at nighttime based on their caused light artifacts. For that, we outline the full algorithm architecture ranging from the detection of light artifacts in the image space, localizing the objects in the three-dimensional space, and verifying the objects over time. To demonstrate the applicability, we deploy the system in a test vehicle and use the information of providently detected vehicles to control the glare-free high beam system proactively. Using this experimental setting, we quantify the time benefit that the provident vehicle detection system provides compared to an in-production computer vision system. Additionally, the glare-free high beam use case provides a real-time and real-world visualization interface of the detection results. With this contribution, we want to put awareness on the unconventional sensing task of provident object detection and further close the performance gap between human behavior and computer vision algorithms in order to bring autonomous and automated driving a step forward.
A formal model for ledger management systems based on contracts and temporal logic
Sep 30, 2021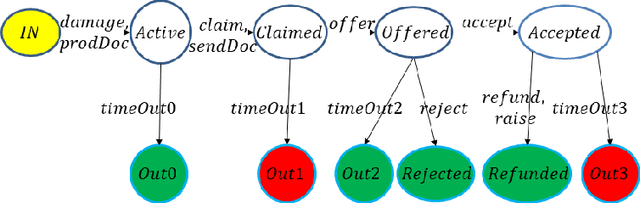
A key component of blockchain technology is the ledger, viz., a database that, unlike standard databases, keeps in memory the complete history of past transactions as in a notarial archive for the benefit of any future test. In second-generation blockchains such as Ethereum the ledger is coupled with smart contracts, which enable the automation of transactions associated with agreements between the parties of a financial or commercial nature. The coupling of smart contracts and ledgers provides the technological background for very innovative application areas, such as Decentralized Autonomous Organizations (DAOs), Initial Coin Offerings (ICOs) and Decentralized Finance (DeFi), which propelled blockchains beyond cryptocurrencies that were the only focus of first generation blockchains such as the Bitcoin. However, the currently used implementation of smart contracts as arbitrary programming constructs has made them susceptible to dangerous bugs that can be exploited maliciously and has moved their semantics away from that of legal contracts. We propose here to recompose the split and recover the reliability of databases by formalizing a notion of contract modelled as a finite-state automaton with well-defined computational characteristics derived from an encoding in terms of allocations of resources to actors, as an alternative to the approach based on programming. To complete the work, we use temporal logic as the basis for an abstract query language that is effectively suited to the historical nature of the information kept in the ledger.