 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Asking Questions Like Educational Experts: Automatically Generating Question-Answer Pairs on Real-World Examination Data
Sep 17, 2021
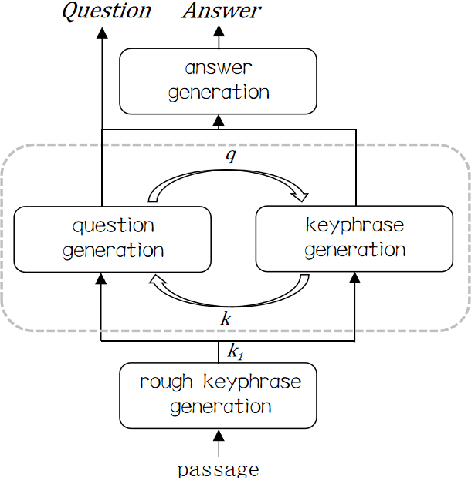

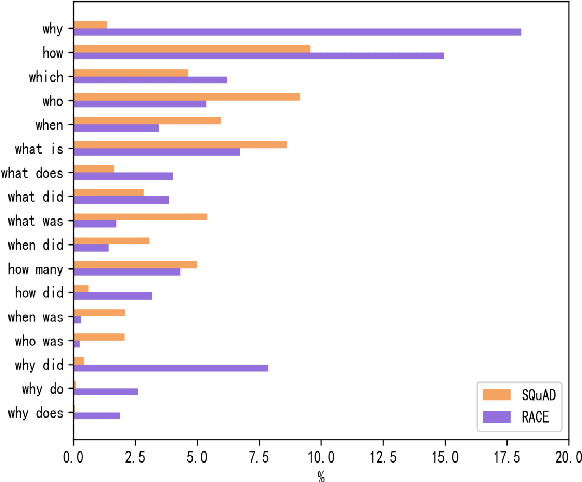
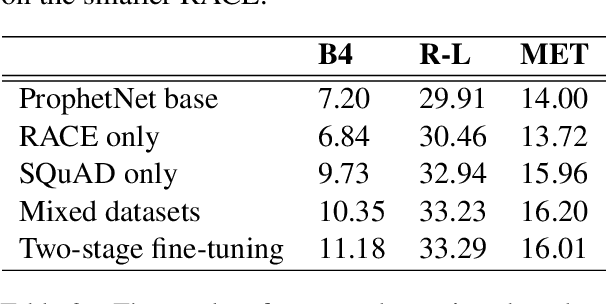
Generating high quality question-answer pairs is a hard but meaningful task. Although previous works have achieved great results on answer-aware question generation, it is difficult to apply them into practical application in the education field. This paper for the first time addresses the question-answer pair generation task on the real-world examination data, and proposes a new unified framework on RACE. To capture the important information of the input passage we first automatically generate(rather than extracting) keyphrases, thus this task is reduced to keyphrase-question-answer triplet joint generation. Accordingly, we propose a multi-agent communication model to generate and optimize the question and keyphrases iteratively, and then apply the generated question and keyphrases to guide the generation of answers. To establish a solid benchmark, we build our model on the strong generative pre-training model. Experimental results show that our model makes great breakthroughs in the question-answer pair generation task. Moreover, we make a comprehensive analysis on our model, suggesting new directions for this challenging task.
Using Uncertainty in Deep Learning Reconstruction for Cone-Beam CT of the Brain
Aug 20, 2021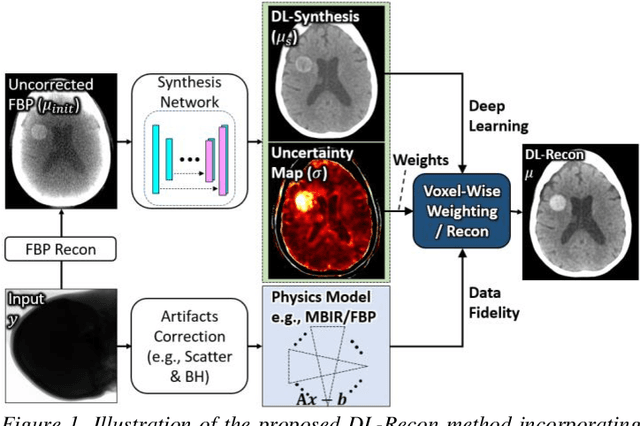
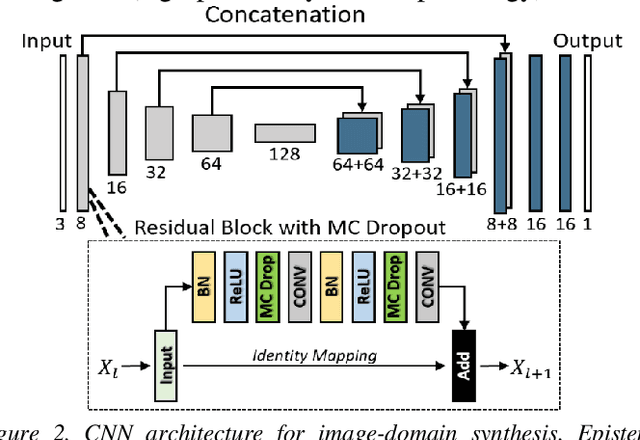
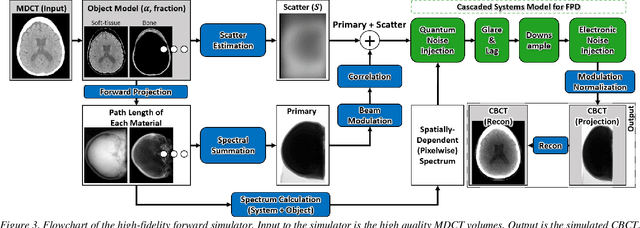
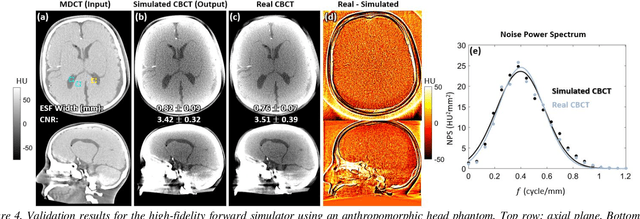
Contrast resolution beyond the limits of conventional cone-beam CT (CBCT) systems is essential to high-quality imaging of the brain. We present a deep learning reconstruction method (dubbed DL-Recon) that integrates physically principled reconstruction models with DL-based image synthesis based on the statistical uncertainty in the synthesis image. A synthesis network was developed to generate a synthesized CBCT image (DL-Synthesis) from an uncorrected filtered back-projection (FBP) image. To improve generalizability (including accurate representation of lesions not seen in training), voxel-wise epistemic uncertainty of DL-Synthesis was computed using a Bayesian inference technique (Monte-Carlo dropout). In regions of high uncertainty, the DL-Recon method incorporates information from a physics-based reconstruction model and artifact-corrected projection data. Two forms of the DL-Recon method are proposed: (i) image-domain fusion of DL-Synthesis and FBP (DL-FBP) weighted by DL uncertainty; and (ii) a model-based iterative image reconstruction (MBIR) optimization using DL-Synthesis to compute a spatially varying regularization term based on DL uncertainty (DL-MBIR). The error in DL-Synthesis images was correlated with the uncertainty in the synthesis estimate. Compared to FBP and PWLS, the DL-Recon methods (both DL-FBP and DL-MBIR) showed ~50% reduction in noise (at matched spatial resolution) and ~40-70% improvement in image uniformity. Conventional DL-Synthesis alone exhibited ~10-60% under-estimation of lesion contrast and ~5-40% reduction in lesion segmentation accuracy (Dice coefficient) in simulated and real brain lesions, suggesting a lack of reliability / generalizability for structures unseen in the training data. DL-FBP and DL-MBIR improved the accuracy of reconstruction by directly incorporating information from the measurements in regions of high uncertainty.
Ethics Sheet for Automatic Emotion Recognition and Sentiment Analysis
Sep 17, 2021The importance and pervasiveness of emotions in our lives makes affective computing a tremendously important and vibrant line of work. Systems for automatic emotion recognition (AER) and sentiment analysis can be facilitators of enormous progress (e.g., in improving public health and commerce) but also enablers of great harm (e.g., for suppressing dissidents and manipulating voters). Thus, it is imperative that the affective computing community actively engage with the ethical ramifications of their creations. In this paper, I have synthesized and organized information from AI Ethics and Emotion Recognition literature to present fifty ethical considerations relevant to AER. Notably, the sheet fleshes out assumptions hidden in how AER is commonly framed, and in the choices often made regarding the data, method, and evaluation. Special attention is paid to the implications of AER on privacy and social groups. The objective of the sheet is to facilitate and encourage more thoughtfulness on why to automate, how to automate, and how to judge success well before the building of AER systems. Additionally, the sheet acts as a useful introductory document on emotion recognition (complementing survey articles).
Decentralised Person Re-Identification with Selective Knowledge Aggregation
Oct 21, 2021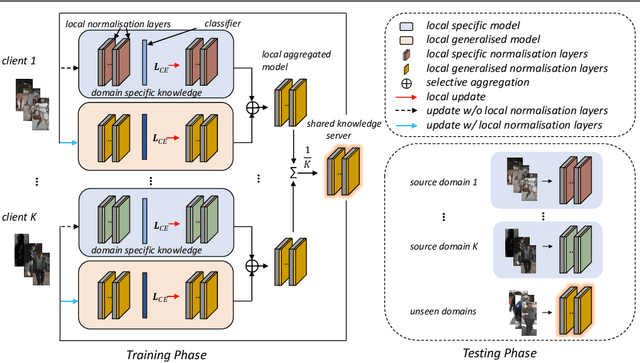
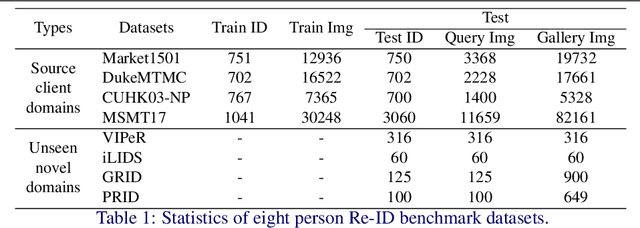
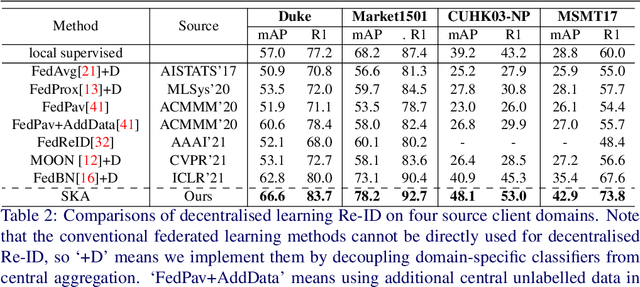
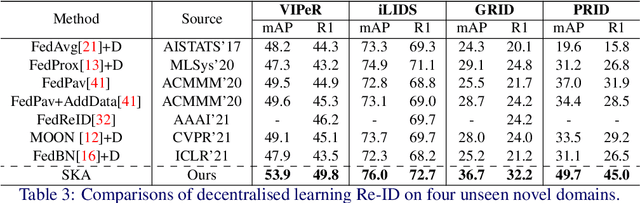
Existing person re-identification (Re-ID) methods mostly follow a centralised learning paradigm which shares all training data to a collection for model learning. This paradigm is limited when data from different sources cannot be shared due to privacy concerns. To resolve this problem, two recent works have introduced decentralised (federated) Re-ID learning for constructing a globally generalised model (server)without any direct access to local training data nor shared data across different source domains (clients). However, these methods are poor on how to adapt the generalised model to maximise its performance on individual client domain Re-ID tasks having different Re-ID label spaces, due to a lack of understanding of data heterogeneity across domains. We call this poor 'model personalisation'. In this work, we present a new Selective Knowledge Aggregation approach to decentralised person Re-ID to optimise the trade-off between model personalisation and generalisation. Specifically, we incorporate attentive normalisation into the normalisation layers in a deep ReID model and propose to learn local normalisation layers specific to each domain, which are decoupled from the global model aggregation in federated Re-ID learning. This helps to preserve model personalisation knowledge on each local client domain and learn instance-specific information. Further, we introduce a dual local normalisation mechanism to learn generalised normalisation layers in each local model, which are then transmitted to the global model for central aggregation. This facilitates selective knowledge aggregation on the server to construct a global generalised model for out-of-the-box deployment on unseen novel domains. Extensive experiments on eight person Re-ID datasets show that the proposed approach to decentralised Re-ID significantly outperforms the state-of-the-art decentralised methods.
Vision-based Navigation for a Small-scale Quadruped Robot Pegasus-Mini
Oct 09, 2021
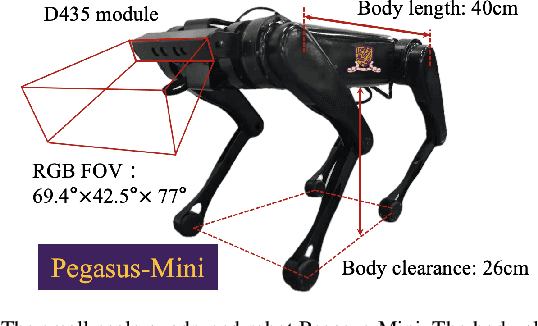
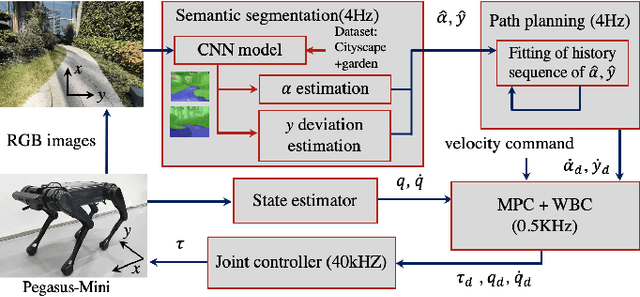
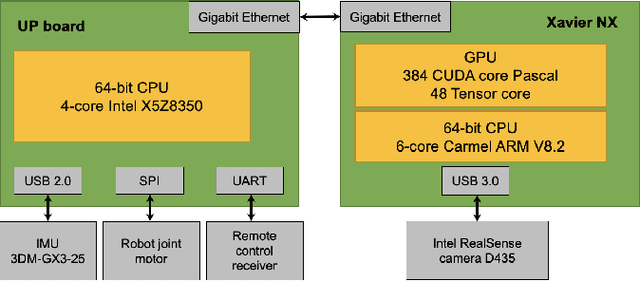
Quadruped locomotion is currently a vibrant research area, which has reached a level of maturity and performance that enables some of the most advanced real-world applications with autonomous quadruped robots both in academia and industry. Blind robust quadruped locomotion has been pushed forward in control and technology aspects within recent decades. However, in the complicated environment, the capability including terrain perception and path planning is still required. Visual perception is an indispensable ability in legged locomotion for such a demand. This study explores a vision-based navigation method for a small-scale quadruped robot Pegasus-Mini, aiming to propose a method that enables efficient and reliable navigation for the small-scale quadruped locomotion. The vision-based navigation method proposed in this study is applicable in such a small-scale quadruped robot platform in which the computation resources and space are limited. The semantic segmentation based on a CNN model is adopted for the real-time path segmentation in the outdoor environment. The desired traverse trajectory is generated through real-time updating the middle line, which is calculated from the edge position of the segmented path in the images. To enhance the stability of the path planning directly based on the semantic segmentation method, a trajectory compensation method is supplemented considering the temporal information to revise the untrustworthy planned path. Experiments of semantic segmentation and navigation in a garden scene are demonstrated to verify the effectiveness of the proposed method.
Ensuring the Inclusive Use of Natural Language Processing in the Global Response to COVID-19
Aug 11, 2021Natural language processing (NLP) plays a significant role in tools for the COVID-19 pandemic response, from detecting misinformation on social media to helping to provide accurate clinical information or summarizing scientific research. However, the approaches developed thus far have not benefited all populations, regions or languages equally. We discuss ways in which current and future NLP approaches can be made more inclusive by covering low-resource languages, including alternative modalities, leveraging out-of-the-box tools and forming meaningful partnerships. We suggest several future directions for researchers interested in maximizing the positive societal impacts of NLP.
Entity Recognition at First Sight: Improving NER with Eye Movement Information
Mar 28, 2019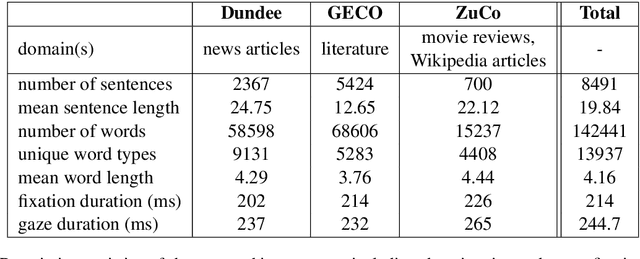
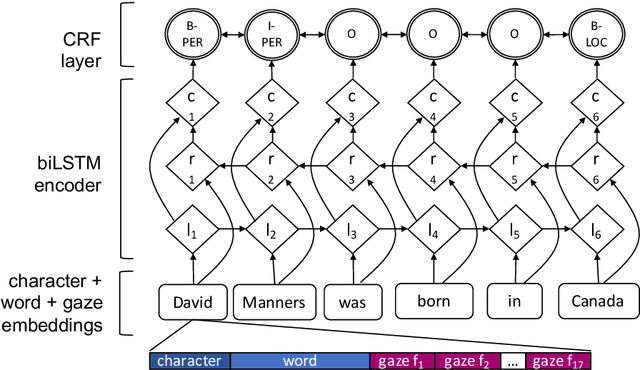
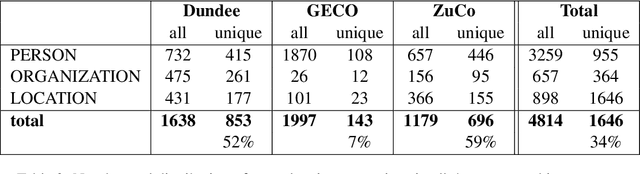
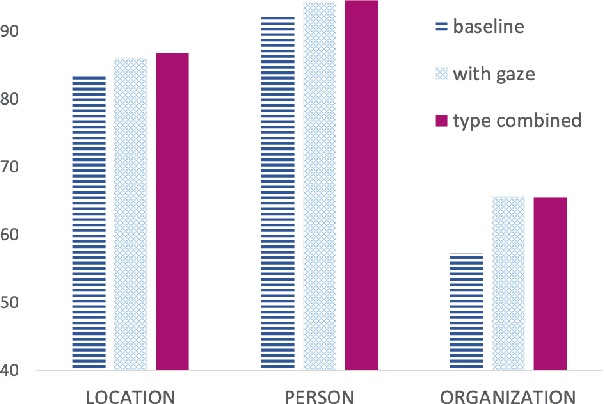
Previous research shows that eye-tracking data contains information about the lexical and syntactic properties of text, which can be used to improve natural language processing models. In this work, we leverage eye movement features from three corpora with recorded gaze information to augment a state-of-the-art neural model for named entity recognition (NER) with gaze embeddings. These corpora were manually annotated with named entity labels. Moreover, we show how gaze features, generalized on word type level, eliminate the need for recorded eye-tracking data at test time. The gaze-augmented models for NER using token-level and type-level features outperform the baselines. We present the benefits of eye-tracking features by evaluating the NER models on both individual datasets as well as in cross-domain settings.
ReLU Regression with Massart Noise
Sep 10, 2021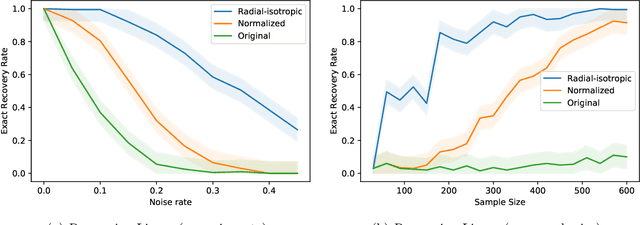
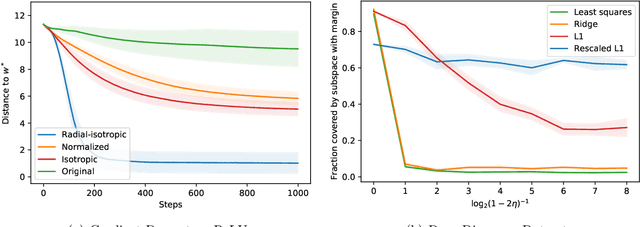
We study the fundamental problem of ReLU regression, where the goal is to fit Rectified Linear Units (ReLUs) to data. This supervised learning task is efficiently solvable in the realizable setting, but is known to be computationally hard with adversarial label noise. In this work, we focus on ReLU regression in the Massart noise model, a natural and well-studied semi-random noise model. In this model, the label of every point is generated according to a function in the class, but an adversary is allowed to change this value arbitrarily with some probability, which is {\em at most} $\eta < 1/2$. We develop an efficient algorithm that achieves exact parameter recovery in this model under mild anti-concentration assumptions on the underlying distribution. Such assumptions are necessary for exact recovery to be information-theoretically possible. We demonstrate that our algorithm significantly outperforms naive applications of $\ell_1$ and $\ell_2$ regression on both synthetic and real data.
Efficiently Identifying Task Groupings for Multi-Task Learning
Sep 10, 2021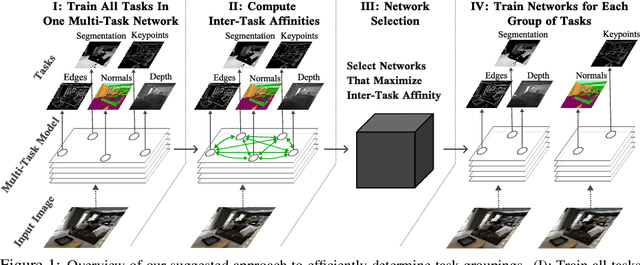
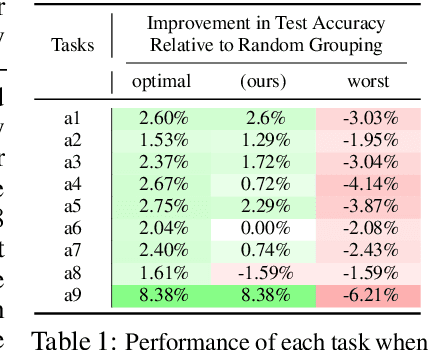
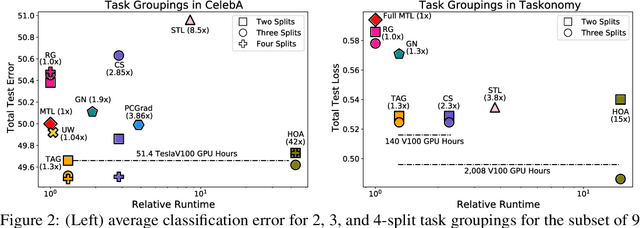
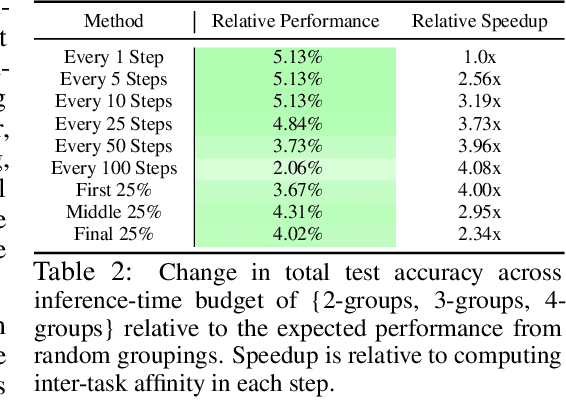
Multi-task learning can leverage information learned by one task to benefit the training of other tasks. Despite this capacity, naively training all tasks together in one model often degrades performance, and exhaustively searching through combinations of task groupings can be prohibitively expensive. As a result, efficiently identifying the tasks that would benefit from co-training remains a challenging design question without a clear solution. In this paper, we suggest an approach to select which tasks should train together in multi-task learning models. Our method determines task groupings in a single training run by co-training all tasks together and quantifying the effect to which one task's gradient would affect another task's loss. On the large-scale Taskonomy computer vision dataset, we find this method can decrease test loss by 10.0\% compared to simply training all tasks together while operating 11.6 times faster than a state-of-the-art task grouping method.
Text Simplification for Comprehension-based Question-Answering
Sep 28, 2021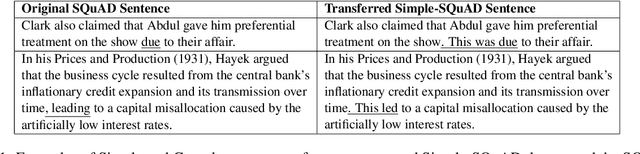
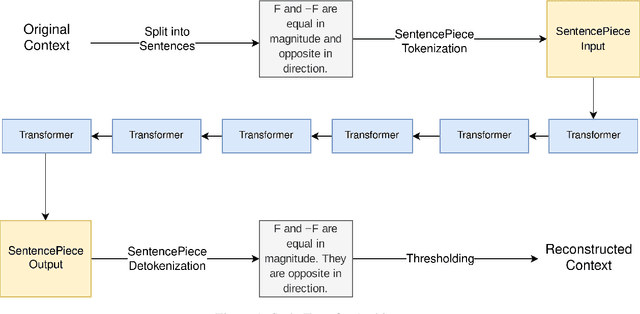
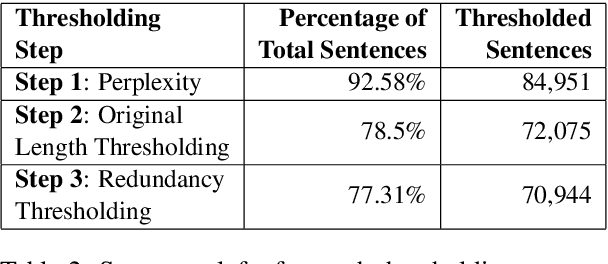
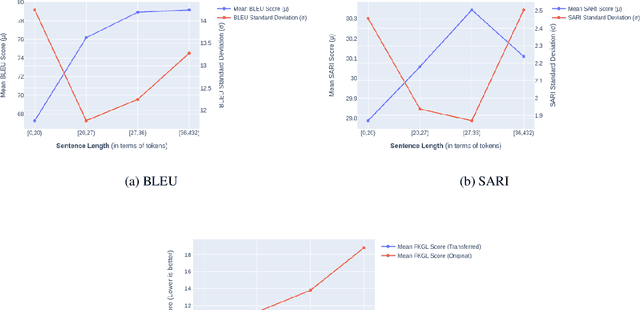
Text simplification is the process of splitting and rephrasing a sentence to a sequence of sentences making it easier to read and understand while preserving the content and approximating the original meaning. Text simplification has been exploited in NLP applications like machine translation, summarization, semantic role labeling, and information extraction, opening a broad avenue for its exploitation in comprehension-based question-answering downstream tasks. In this work, we investigate the effect of text simplification in the task of question-answering using a comprehension context. We release Simple-SQuAD, a simplified version of the widely-used SQuAD dataset. Firstly, we outline each step in the dataset creation pipeline, including style transfer, thresholding of sentences showing correct transfer, and offset finding for each answer. Secondly, we verify the quality of the transferred sentences through various methodologies involving both automated and human evaluation. Thirdly, we benchmark the newly created corpus and perform an ablation study for examining the effect of the simplification process in the SQuAD-based question answering task. Our experiments show that simplification leads to up to 2.04% and 1.74% increase in Exact Match and F1, respectively. Finally, we conclude with an analysis of the transfer process, investigating the types of edits made by the model, and the effect of sentence length on the transfer model.