 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fine-tuning Pretrained Language Models with Label Attention for Explainable Biomedical Text Classification
Aug 28, 2021
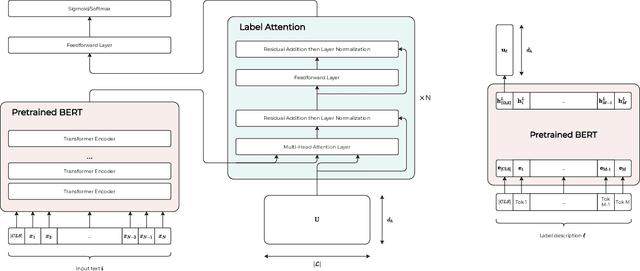

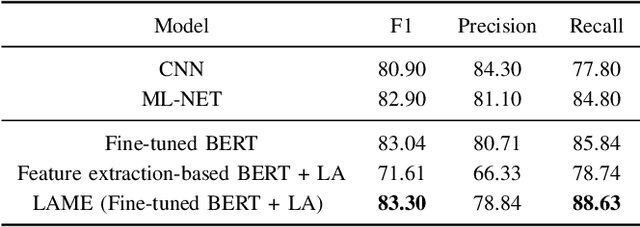

The massive growth of digital biomedical data is making biomedical text indexing and classification increasingly important. Accordingly, previous research has devised numerous deep learning techniques focused on using feedforward, convolutional or recurrent neural architectures. More recently, fine-tuned transformers-based pretrained models (PTMs) have demonstrated superior performance compared to such models in many natural language processing tasks. However, the direct use of PTMs in the biomedical domain is only limited to the target documents, ignoring the rich semantic information in the label descriptions. In this paper, we develop an improved label attention-based architecture to inject semantic label description into the fine-tuning process of PTMs. Results on two public medical datasets show that the proposed fine-tuning scheme outperforms the conventionally fine-tuned PTMs and prior state-of-the-art models. Furthermore, we show that fine-tuning with the label attention mechanism is interpretable in the interpretability study.
Multi-scale Edge-based U-shape Network for Salient Object Detection
Aug 21, 2021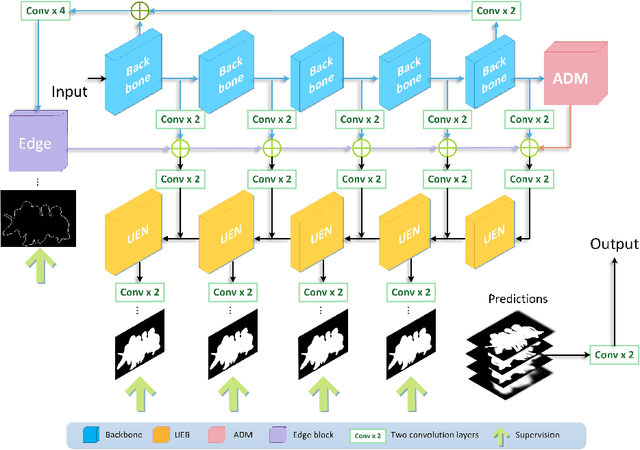
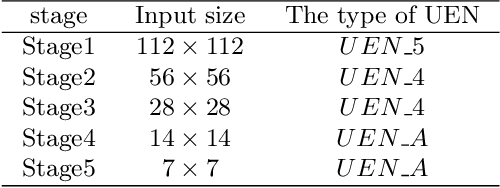
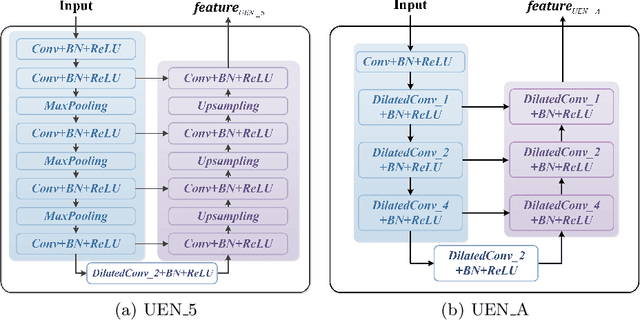
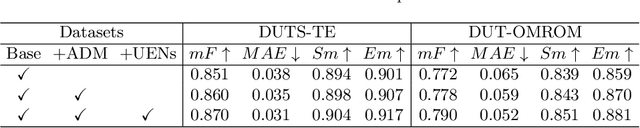
Deep-learning based salient object detection methods achieve great improvements. However, there are still problems existing in the predictions, such as blurry boundary and inaccurate location, which is mainly caused by inadequate feature extraction and integration. In this paper, we propose a Multi-scale Edge-based U-shape Network (MEUN) to integrate various features at different scales to achieve better performance. To extract more useful information for boundary prediction, U-shape Edge Network modules are embedded in each decoder units. Besides, the additional down-sampling module alleviates the location inaccuracy. Experimental results on four benchmark datasets demonstrate the validity and reliability of the proposed method. Multi-scale Edge based U-shape Network also shows its superiority when compared with 15 state-of-the-art salient object detection methods.
Logic-level Evidence Retrieval and Graph-based Verification Network for Table-based Fact Verification
Sep 14, 2021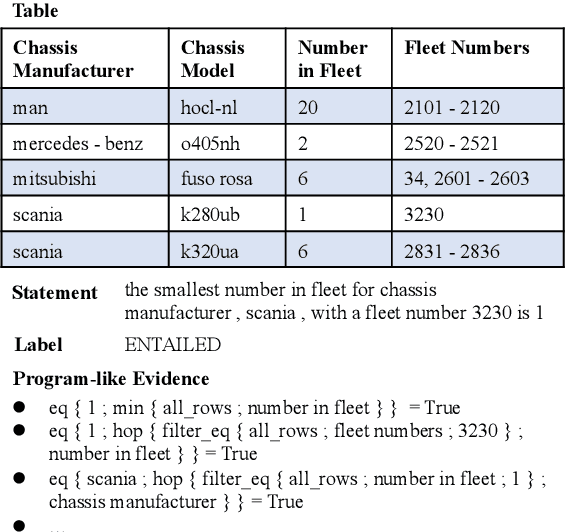
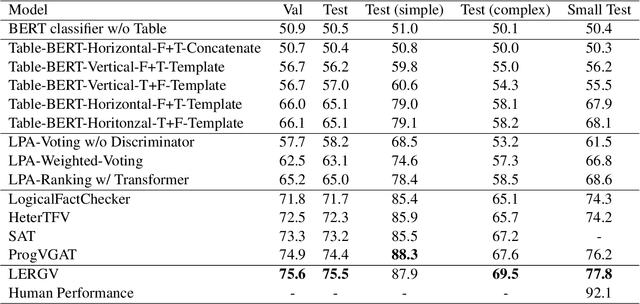
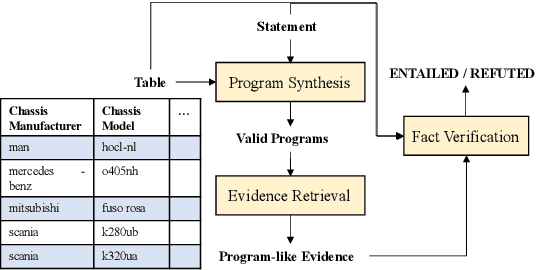

Table-based fact verification task aims to verify whether the given statement is supported by the given semi-structured table. Symbolic reasoning with logical operations plays a crucial role in this task. Existing methods leverage programs that contain rich logical information to enhance the verification process. However, due to the lack of fully supervised signals in the program generation process, spurious programs can be derived and employed, which leads to the inability of the model to catch helpful logical operations. To address the aforementioned problems, in this work, we formulate the table-based fact verification task as an evidence retrieval and reasoning framework, proposing the Logic-level Evidence Retrieval and Graph-based Verification network (LERGV). Specifically, we first retrieve logic-level program-like evidence from the given table and statement as supplementary evidence for the table. After that, we construct a logic-level graph to capture the logical relations between entities and functions in the retrieved evidence, and design a graph-based verification network to perform logic-level graph-based reasoning based on the constructed graph to classify the final entailment relation. Experimental results on the large-scale benchmark TABFACT show the effectiveness of the proposed approach.
Can Language Models Encode Perceptual Structure Without Grounding? A Case Study in Color
Sep 14, 2021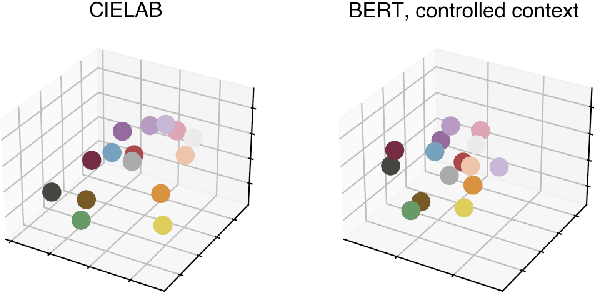

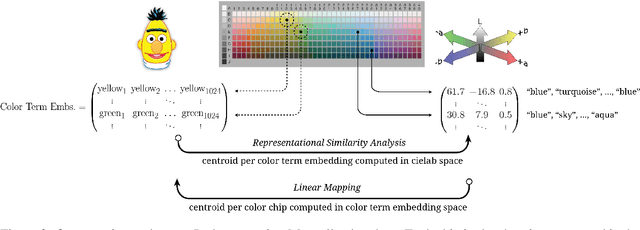
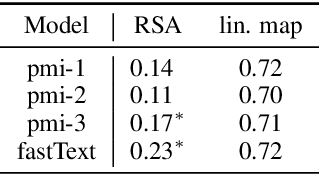
Pretrained language models have been shown to encode relational information, such as the relations between entities or concepts in knowledge-bases -- (Paris, Capital, France). However, simple relations of this type can often be recovered heuristically and the extent to which models implicitly reflect topological structure that is grounded in world, such as perceptual structure, is unknown. To explore this question, we conduct a thorough case study on color. Namely, we employ a dataset of monolexemic color terms and color chips represented in CIELAB, a color space with a perceptually meaningful distance metric. Using two methods of evaluating the structural alignment of colors in this space with text-derived color term representations, we find significant correspondence. Analyzing the differences in alignment across the color spectrum, we find that warmer colors are, on average, better aligned to the perceptual color space than cooler ones, suggesting an intriguing connection to findings from recent work on efficient communication in color naming. Further analysis suggests that differences in alignment are, in part, mediated by collocationality and differences in syntactic usage, posing questions as to the relationship between color perception and usage and context.
Exploiting Pre-Trained ASR Models for Alzheimer's Disease Recognition Through Spontaneous Speech
Oct 04, 2021
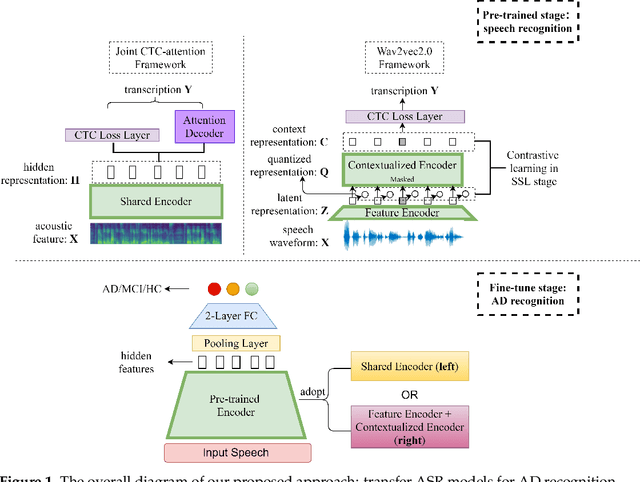
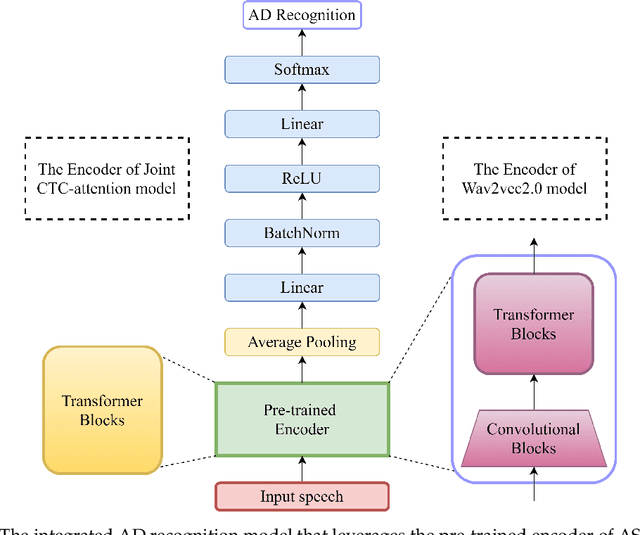
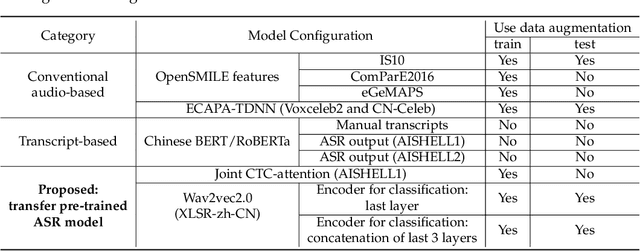
Alzheimer's disease (AD) is a progressive neurodegenerative disease and recently attracts extensive attention worldwide. Speech technology is considered a promising solution for the early diagnosis of AD and has been enthusiastically studied. Most recent works concentrate on the use of advanced BERT-like classifiers for AD detection. Input to these classifiers are speech transcripts produced by automatic speech recognition (ASR) models. The major challenge is that the quality of transcription could degrade significantly under complex acoustic conditions in the real world. The detection performance, in consequence, is largely limited. This paper tackles the problem via tailoring and adapting pre-trained neural-network based ASR model for the downstream AD recognition task. Only bottom layers of the ASR model are retained. A simple fully-connected neural network is added on top of the tailored ASR model for classification. The heavy BERT classifier is discarded. The resulting model is light-weight and can be fine-tuned in an end-to-end manner for AD recognition. Our proposed approach takes only raw speech as input, and no extra transcription process is required. The linguistic information of speech is implicitly encoded in the tailored ASR model and contributes to boosting the performance. Experiments show that our proposed approach outperforms the best manual transcript-based RoBERTa by an absolute margin of 4.6% in terms of accuracy. Our best-performing models achieve the accuracy of 83.2% and 78.0% in the long-audio and short-audio competition tracks of the 2021 NCMMSC Alzheimer's Disease Recognition Challenge, respectively.
Three-stream network for enriched Action Recognition
Apr 27, 2021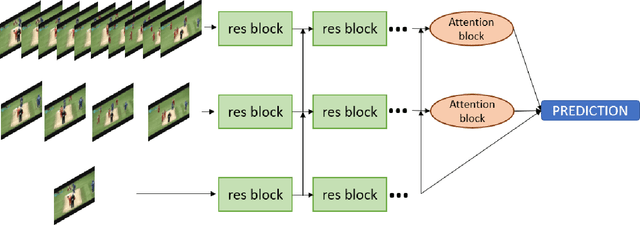
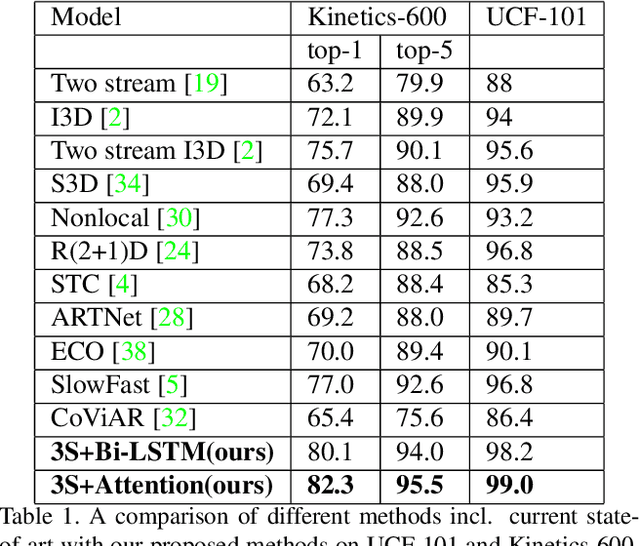
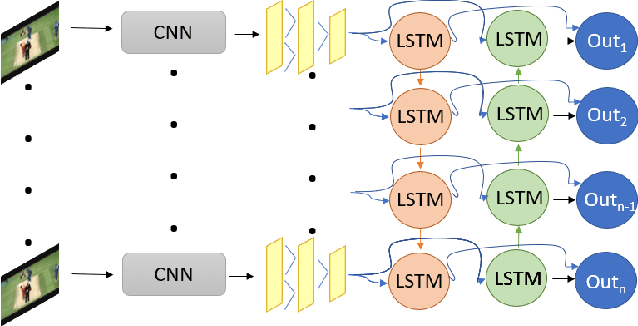
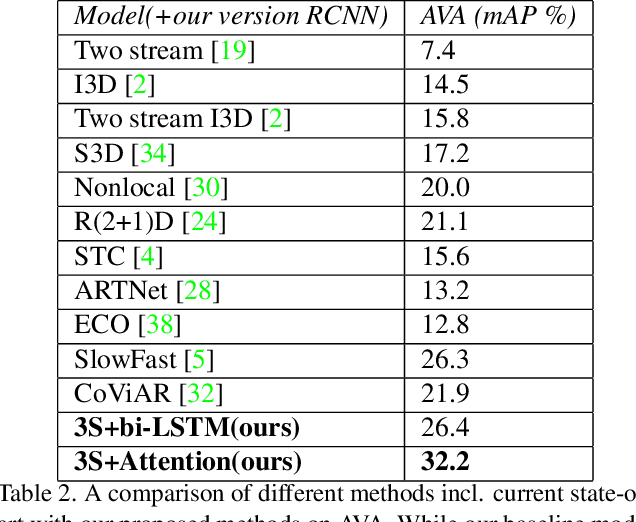
Understanding accurate information on human behaviours is one of the most important tasks in machine intelligence. Human Activity Recognition that aims to understand human activities from a video is a challenging task due to various problems including background, camera motion and dataset variations. This paper proposes two CNN based architectures with three streams which allow the model to exploit the dataset under different settings. The three pathways are differentiated in frame rates. The single pathway, operates at a single frame rate captures spatial information, the slow pathway operates at low frame rates captures the spatial information and the fast pathway operates at high frame rates that capture fine temporal information. Post CNN encoders, we add bidirectional LSTM and attention heads respectively to capture the context and temporal features. By experimenting with various algorithms on UCF-101, Kinetics-600 and AVA dataset, we observe that the proposed models achieve state-of-art performance for human action recognition task.
EventPoint: Self-Supervised Local Descriptor Learning for Event Cameras
Sep 01, 2021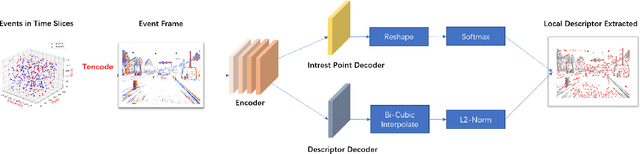

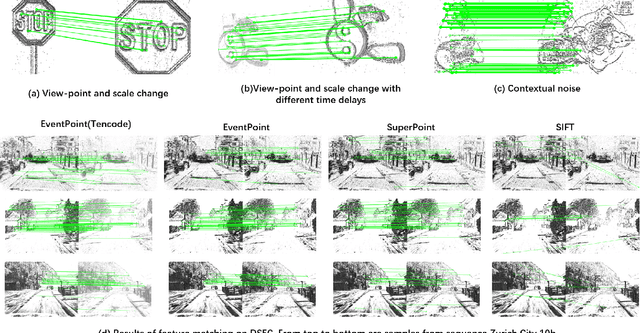
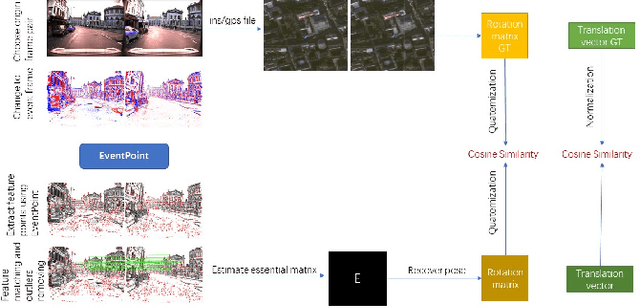
We proposes a method of extracting intrest points and descriptors using self-supervised learning method on frame-based event data, which is called EventPoint. Different from other feature extraction methods on event data, we train our model on real event-form driving dataset--DSEC with the self-supervised learning method we proposed, the training progress fully consider the characteristics of event data.To verify the effectiveness of our work,we conducted several complete evaluations: we emulated DART and carried out feature matching experiments on N-caltech101 dataset, the results shows that the effect of EventPoint is better than DART; We use Vid2e tool provided by UZH to convert Oxford robotcar data into event-based format, and combined with INS information provided to carry out the global pose estimation experiment which is important in SLAM. As far as we know, this is the first work to carry out this challenging task.Sufficient experimental data show that EventPoint can get better results while achieve real time on CPU.
Feedback Network for Mutually Boosted Stereo Image Super-Resolution and Disparity Estimation
Jun 02, 2021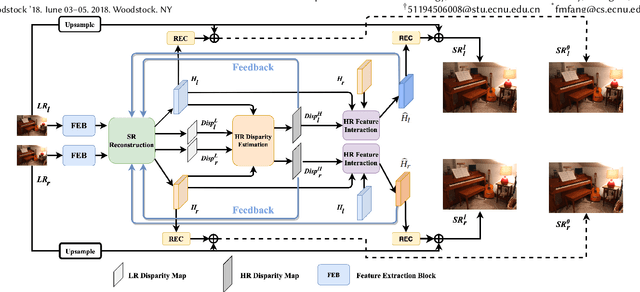
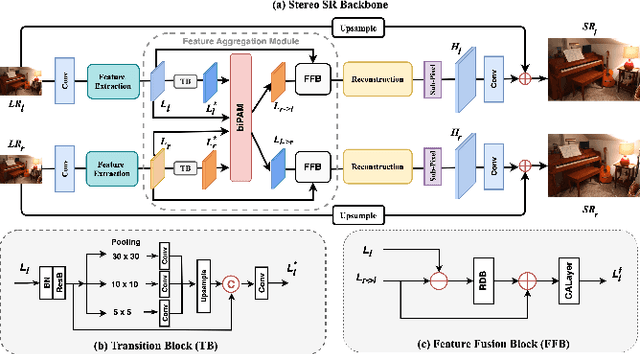

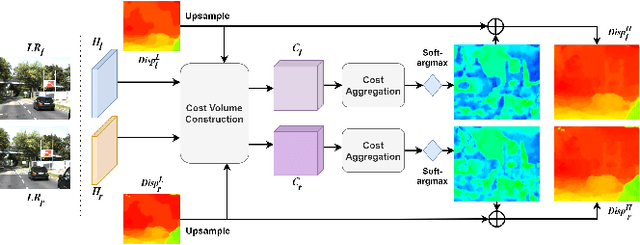
Under stereo settings, the problem of image super-resolution (SR) and disparity estimation are interrelated that the result of each problem could help to solve the other. The effective exploitation of correspondence between different views facilitates the SR performance, while the high-resolution (HR) features with richer details benefit the correspondence estimation. According to this motivation, we propose a Stereo Super-Resolution and Disparity Estimation Feedback Network (SSRDE-FNet), which simultaneously handles the stereo image super-resolution and disparity estimation in a unified framework and interact them with each other to further improve their performance. Specifically, the SSRDE-FNet is composed of two dual recursive sub-networks for left and right views. Besides the cross-view information exploitation in the low-resolution (LR) space, HR representations produced by the SR process are utilized to perform HR disparity estimation with higher accuracy, through which the HR features can be aggregated to generate a finer SR result. Afterward, the proposed HR Disparity Information Feedback (HRDIF) mechanism delivers information carried by HR disparity back to previous layers to further refine the SR image reconstruction. Extensive experiments demonstrate the effectiveness and advancement of SSRDE-FNet.
Detecting race and gender bias in visual representation of AI on web search engines
Jun 26, 2021
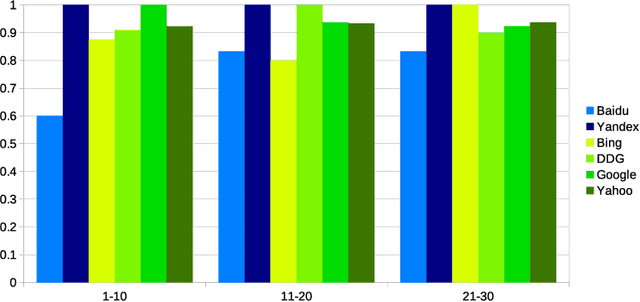
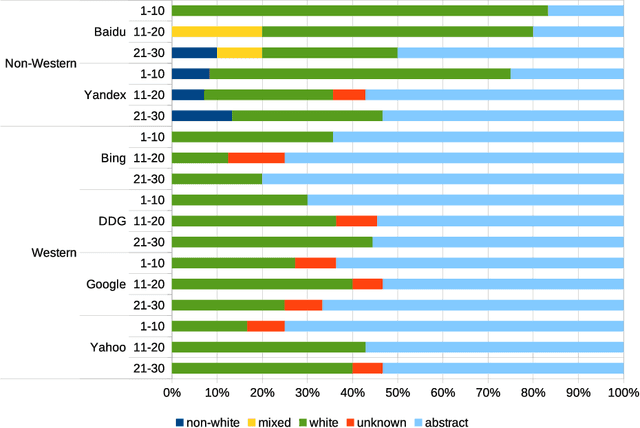
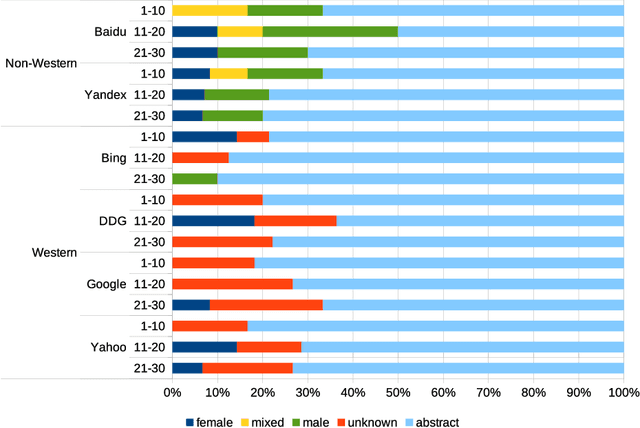
Web search engines influence perception of social reality by filtering and ranking information. However, their outputs are often subjected to bias that can lead to skewed representation of subjects such as professional occupations or gender. In our paper, we use a mixed-method approach to investigate presence of race and gender bias in representation of artificial intelligence (AI) in image search results coming from six different search engines. Our findings show that search engines prioritize anthropomorphic images of AI that portray it as white, whereas non-white images of AI are present only in non-Western search engines. By contrast, gender representation of AI is more diverse and less skewed towards a specific gender that can be attributed to higher awareness about gender bias in search outputs. Our observations indicate both the the need and the possibility for addressing bias in representation of societally relevant subjects, such as technological innovation, and emphasize the importance of designing new approaches for detecting bias in information retrieval systems.
* 16 pages, 3 figures
RoR: Read-over-Read for Long Document Machine Reading Comprehension
Sep 14, 2021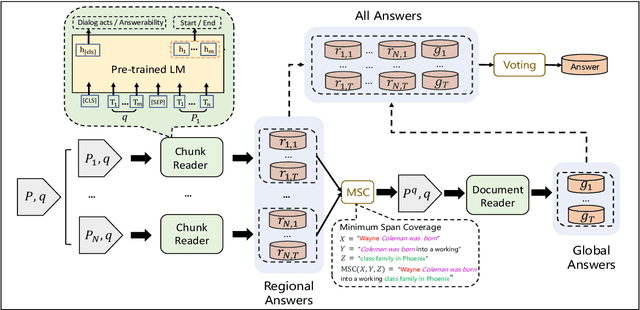
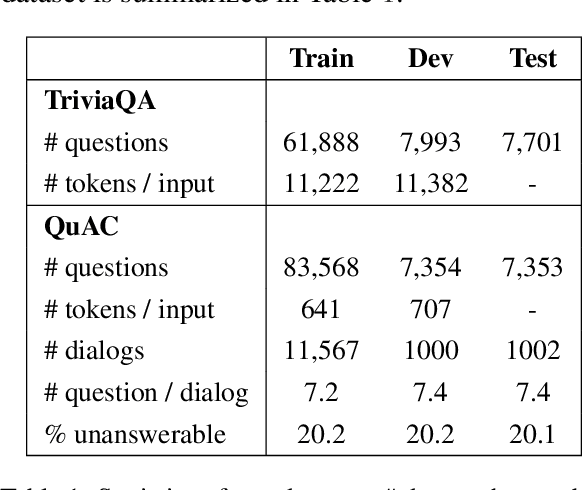
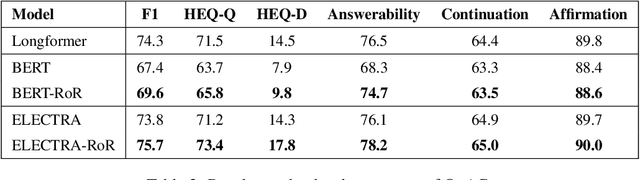
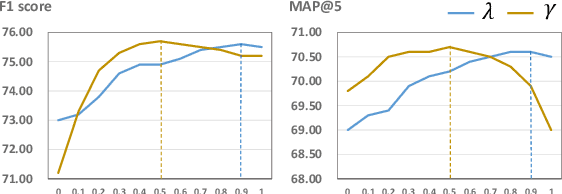
Transformer-based pre-trained models, such as BERT, have achieved remarkable results on machine reading comprehension. However, due to the constraint of encoding length (e.g., 512 WordPiece tokens), a long document is usually split into multiple chunks that are independently read. It results in the reading field being limited to individual chunks without information collaboration for long document machine reading comprehension. To address this problem, we propose RoR, a read-over-read method, which expands the reading field from chunk to document. Specifically, RoR includes a chunk reader and a document reader. The former first predicts a set of regional answers for each chunk, which are then compacted into a highly-condensed version of the original document, guaranteeing to be encoded once. The latter further predicts the global answers from this condensed document. Eventually, a voting strategy is utilized to aggregate and rerank the regional and global answers for final prediction. Extensive experiments on two benchmarks QuAC and TriviaQA demonstrate the effectiveness of RoR for long document reading. Notably, RoR ranks 1st place on the QuAC leaderboard (https://quac.ai/) at the time of submission (May 17th, 2021).