 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Memory semantization through perturbed and adversarial dreaming
Sep 09, 2021
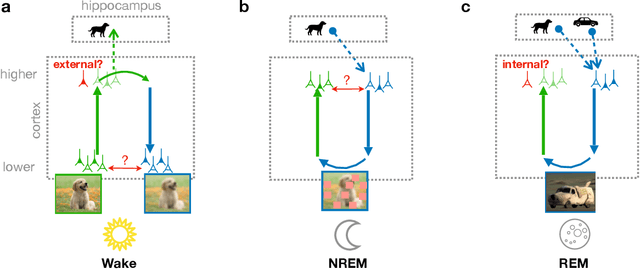

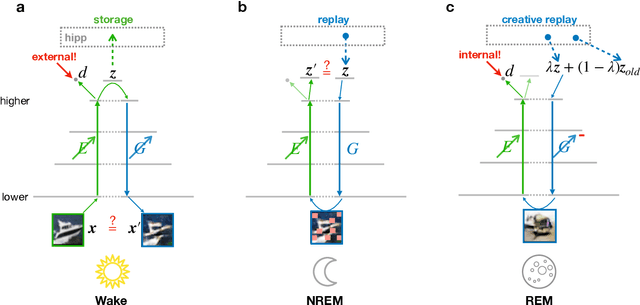
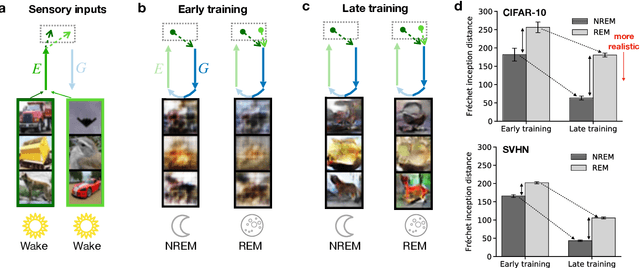
Classical theories of memory consolidation emphasize the importance of replay in extracting semantic information from episodic memories. However, the characteristic creative nature of dreams suggests that memory semantization may go beyond merely replaying previous experiences. We propose that rapid-eye-movement (REM) dreaming is essential for efficient memory semantization by randomly combining episodic memories to create new, virtual sensory experiences. We support this hypothesis by implementing a cortical architecture with hierarchically organized feedforward and feedback pathways, inspired by generative adversarial networks (GANs). Learning in our model is organized across three different global brain states mimicking wakefulness, non-REM (NREM) and REM sleep, optimizing different, but complementary objective functions. We train the model in an unsupervised fashion on standard datasets of natural images and evaluate the quality of the learned representations. Our results suggest that adversarial dreaming during REM sleep is essential for extracting memory contents, while perturbed dreaming during NREM sleep improves robustness of the latent representation to noisy sensory inputs. The model provides a new computational perspective on sleep states, memory replay and dreams and suggests a cortical implementation of GANs.
Conditionally Parameterized, Discretization-Aware Neural Networks for Mesh-Based Modeling of Physical Systems
Sep 15, 2021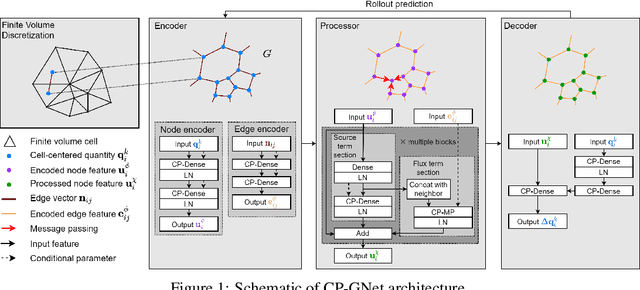
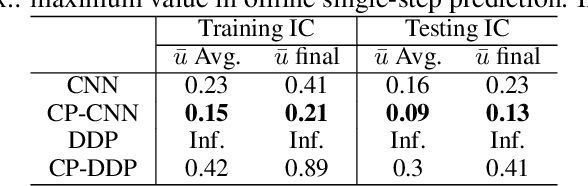
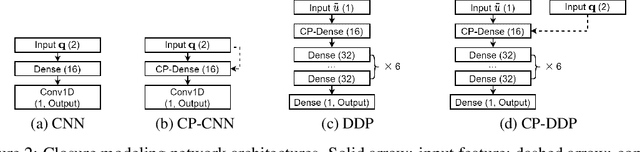

The numerical simulations of physical systems are heavily dependent on mesh-based models. While neural networks have been extensively explored to assist such tasks, they often ignore the interactions or hierarchical relations between input features, and process them as concatenated mixtures. In this work, we generalize the idea of conditional parametrization -- using trainable functions of input parameters to generate the weights of a neural network, and extend them in a flexible way to encode information critical to the numerical simulations. Inspired by discretized numerical methods, choices of the parameters include physical quantities and mesh topology features. The functional relation between the modeled features and the parameters are built into the network architecture. The method is implemented on different networks, which are applied to several frontier scientific machine learning tasks, including the discovery of unmodeled physics, super-resolution of coarse fields, and the simulation of unsteady flows with chemical reactions. The results show that the conditionally parameterized networks provide superior performance compared to their traditional counterparts. A network architecture named CP-GNet is also proposed as the first deep learning model capable of standalone prediction of reacting flows on irregular meshes.
Safe, Deterministic Trajectory Planning for Unstructured and Partially Occluded Environments
Sep 09, 2021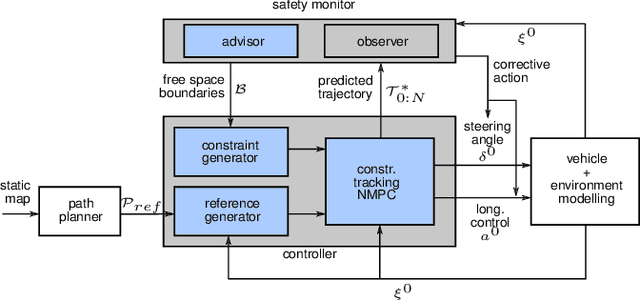

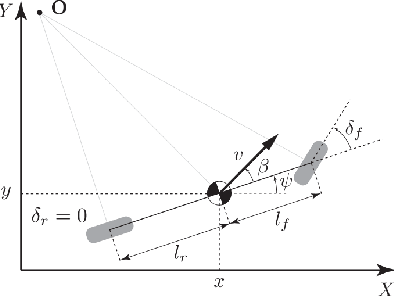
Ensuring safe behavior for automated vehicles in unregulated traffic areas poses a complex challenge for the industry. It is an open problem to provide scalable and certifiable solutions to this challenge. We derive a trajectory planner based on model predictive control which interoperates with a monitoring system for pedestrian safety based on cellular automata. The combined planner-monitor system is demonstrated on the example of a narrow indoor parking environment. The system features deterministic behavior, mitigating the immanent risk of black boxes and offering full certifiability. By using fundamental and conservative prediction models of pedestrians the monitor is able to determine a safe drivable area in the partially occluded and unstructured parking environment. The information is fed to the trajectory planner which ensures the vehicle remains in the safe drivable area at any time through constrained optimization. We show how the approach enables solving plenty of situations in tight parking garage scenarios. Even though conservative prediction models are applied, evaluations indicate a performant system for the tested low-speed navigation.
Semantic segmentation of multispectral photoacoustic images using deep learning
May 20, 2021


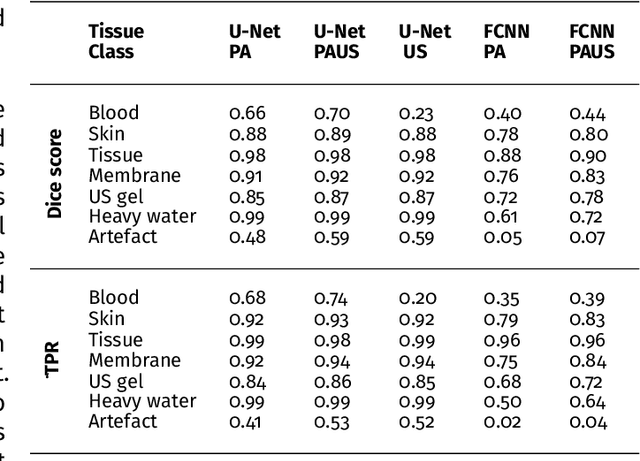
Photoacoustic imaging has the potential to revolutionise healthcare due to the valuable information on tissue physiology that is contained in multispectral photoacoustic measurements. Clinical translation of the technology requires conversion of the high-dimensional acquired data into clinically relevant and interpretable information. In this work, we present a deep learning-based approach to semantic segmentation of multispectral photoacoustic images to facilitate the interpretability of recorded images. Manually annotated multispectral photoacoustic imaging data are used as gold standard reference annotations and enable the training of a deep learning-based segmentation algorithm in a supervised manner. Based on a validation study with experimentally acquired data of healthy human volunteers, we show that automatic tissue segmentation can be used to create powerful analyses and visualisations of multispectral photoacoustic images. Due to the intuitive representation of high-dimensional information, such a processing algorithm could be a valuable means to facilitate the clinical translation of photoacoustic imaging.
Cross-Register Projection for Headline Part of Speech Tagging
Sep 15, 2021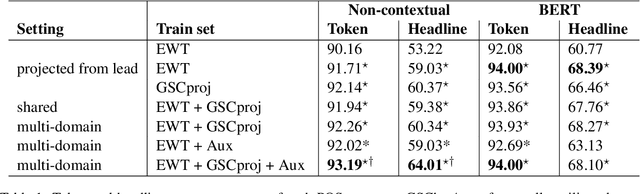
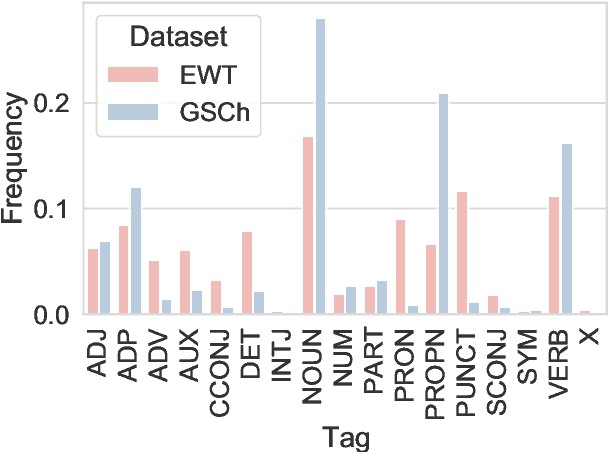
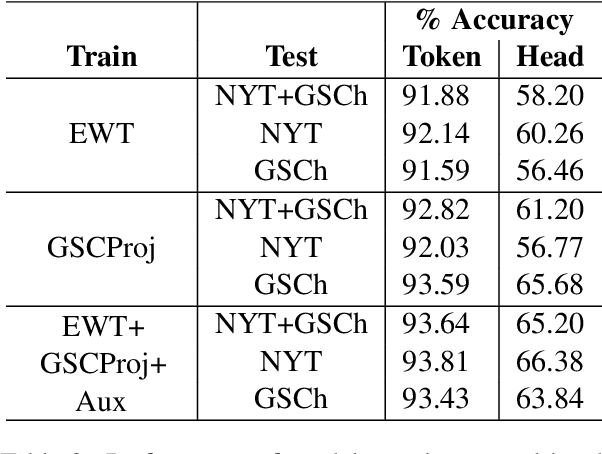
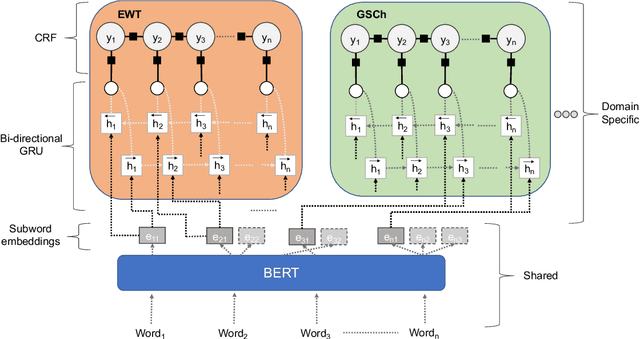
Part of speech (POS) tagging is a familiar NLP task. State of the art taggers routinely achieve token-level accuracies of over 97% on news body text, evidence that the problem is well understood. However, the register of English news headlines, "headlinese", is very different from the register of long-form text, causing POS tagging models to underperform on headlines. In this work, we automatically annotate news headlines with POS tags by projecting predicted tags from corresponding sentences in news bodies. We train a multi-domain POS tagger on both long-form and headline text and show that joint training on both registers improves over training on just one or naively concatenating training sets. We evaluate on a newly-annotated corpus of over 5,248 English news headlines from the Google sentence compression corpus, and show that our model yields a 23% relative error reduction per token and 19% per headline. In addition, we demonstrate that better headline POS tags can improve the performance of a syntax-based open information extraction system. We make POSH, the POS-tagged Headline corpus, available to encourage research in improved NLP models for news headlines.
SPEC: Seeing People in the Wild with an Estimated Camera
Oct 01, 2021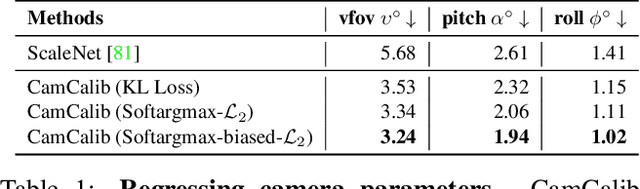
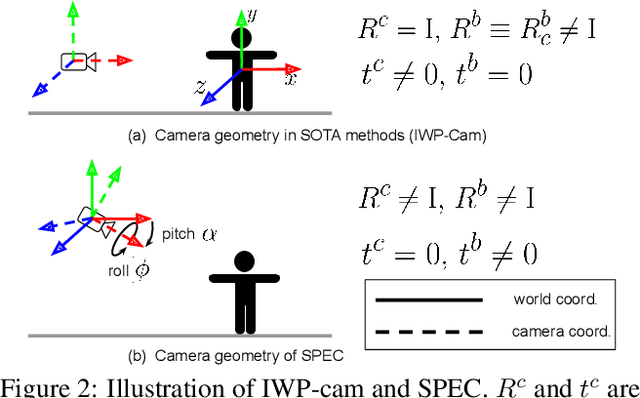
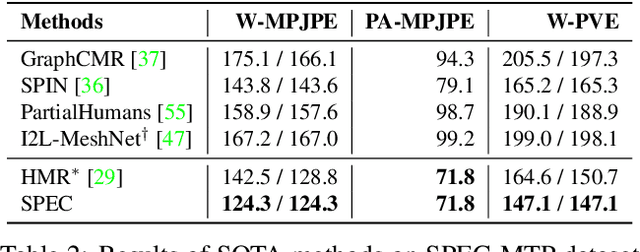
Due to the lack of camera parameter information for in-the-wild images, existing 3D human pose and shape (HPS) estimation methods make several simplifying assumptions: weak-perspective projection, large constant focal length, and zero camera rotation. These assumptions often do not hold and we show, quantitatively and qualitatively, that they cause errors in the reconstructed 3D shape and pose. To address this, we introduce SPEC, the first in-the-wild 3D HPS method that estimates the perspective camera from a single image and employs this to reconstruct 3D human bodies more accurately. %regress 3D human bodies. First, we train a neural network to estimate the field of view, camera pitch, and roll given an input image. We employ novel losses that improve the calibration accuracy over previous work. We then train a novel network that concatenates the camera calibration to the image features and uses these together to regress 3D body shape and pose. SPEC is more accurate than the prior art on the standard benchmark (3DPW) as well as two new datasets with more challenging camera views and varying focal lengths. Specifically, we create a new photorealistic synthetic dataset (SPEC-SYN) with ground truth 3D bodies and a novel in-the-wild dataset (SPEC-MTP) with calibration and high-quality reference bodies. Both qualitative and quantitative analysis confirm that knowing camera parameters during inference regresses better human bodies. Code and datasets are available for research purposes at https://spec.is.tue.mpg.de.
Detecting race and gender bias in visual representation of AI on web search engines
Jun 26, 2021
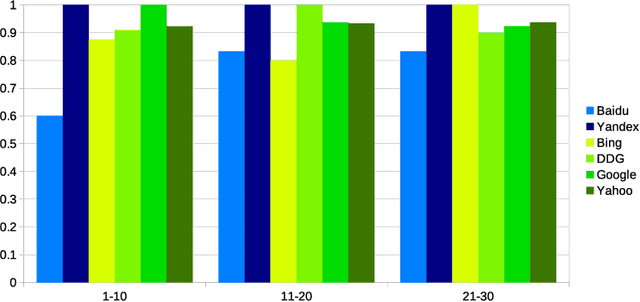
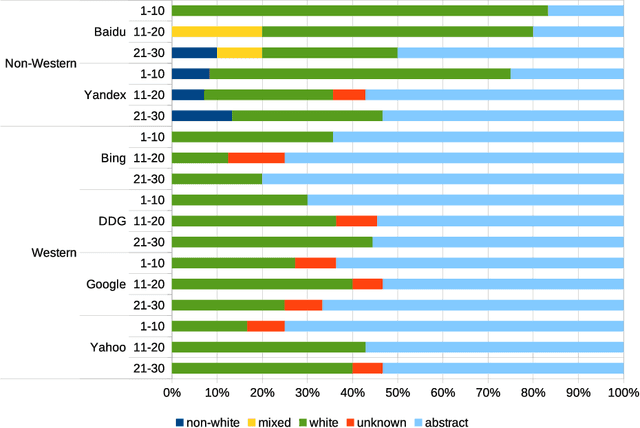
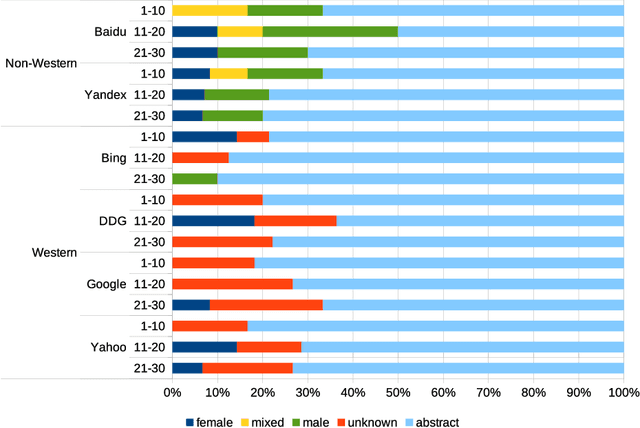
Web search engines influence perception of social reality by filtering and ranking information. However, their outputs are often subjected to bias that can lead to skewed representation of subjects such as professional occupations or gender. In our paper, we use a mixed-method approach to investigate presence of race and gender bias in representation of artificial intelligence (AI) in image search results coming from six different search engines. Our findings show that search engines prioritize anthropomorphic images of AI that portray it as white, whereas non-white images of AI are present only in non-Western search engines. By contrast, gender representation of AI is more diverse and less skewed towards a specific gender that can be attributed to higher awareness about gender bias in search outputs. Our observations indicate both the the need and the possibility for addressing bias in representation of societally relevant subjects, such as technological innovation, and emphasize the importance of designing new approaches for detecting bias in information retrieval systems.
* 16 pages, 3 figures
Reinforcement Learning for Systematic FX Trading
Oct 10, 2021
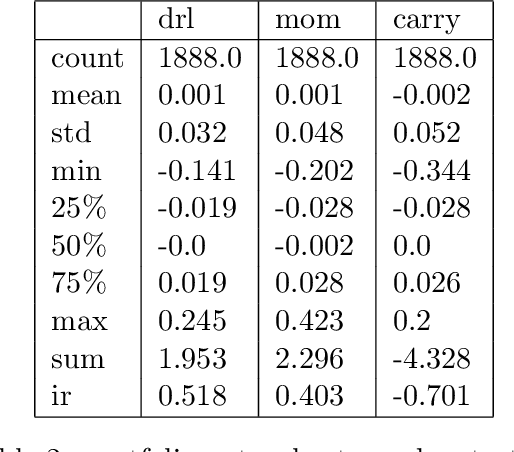
We conduct a detailed experiment on major cash fx pairs, accurately accounting for transaction and funding costs. These sources of profit and loss, including the price trends that occur in the currency markets, are made available to our recurrent reinforcement learner via a quadratic utility, which learns to target a position directly. We improve upon earlier work, by casting the problem of learning to target a risk position, in an online learning context. This online learning occurs sequentially in time, but also in the form of transfer learning. We transfer the output of radial basis function hidden processing units, whose means, covariances and overall size are determined by Gaussian mixture models, to the recurrent reinforcement learner and baseline momentum trader. Thus the intrinsic nature of the feature space is learnt and made available to the upstream models. The recurrent reinforcement learning trader achieves an annualised portfolio information ratio of 0.52 with compound return of 9.3%, net of execution and funding cost, over a 7 year test set. This is despite forcing the model to trade at the close of the trading day 5pm EST, when trading costs are statistically the most expensive. These results are comparable with the momentum baseline trader, reflecting the low interest differential environment since the the 2008 financial crisis, and very obvious currency trends since then. The recurrent reinforcement learner does nevertheless maintain an important advantage, in that the model's weights can be adapted to reflect the different sources of profit and loss variation. This is demonstrated visually by a USDRUB trading agent, who learns to target different positions, that reflect trading in the absence or presence of cost.
Balancing detectability and performance of attacks on the control channel of Markov Decision Processes
Sep 15, 2021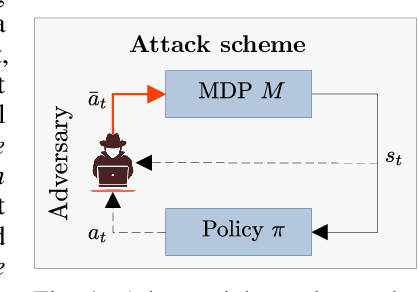
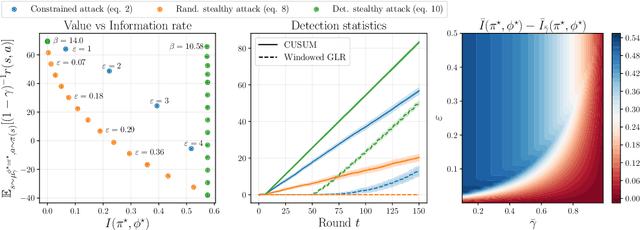
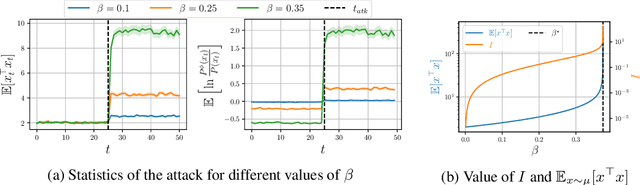
We investigate the problem of designing optimal stealthy poisoning attacks on the control channel of Markov decision processes (MDPs). This research is motivated by the recent interest of the research community for adversarial and poisoning attacks applied to MDPs, and reinforcement learning (RL) methods. The policies resulting from these methods have been shown to be vulnerable to attacks perturbing the observations of the decision-maker. In such an attack, drawing inspiration from adversarial examples used in supervised learning, the amplitude of the adversarial perturbation is limited according to some norm, with the hope that this constraint will make the attack imperceptible. However, such constraints do not grant any level of undetectability and do not take into account the dynamic nature of the underlying Markov process. In this paper, we propose a new attack formulation, based on information-theoretical quantities, that considers the objective of minimizing the detectability of the attack as well as the performance of the controlled process. We analyze the trade-off between the efficiency of the attack and its detectability. We conclude with examples and numerical simulations illustrating this trade-off.
Multi-modal Entity Alignment in Hyperbolic Space
Jun 07, 2021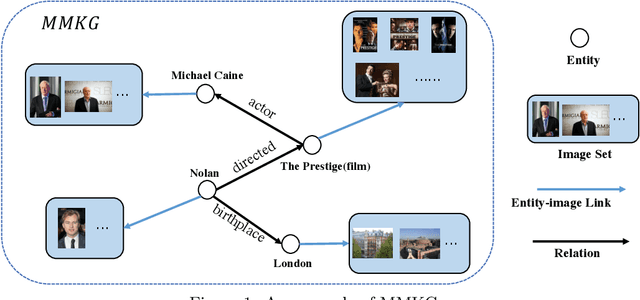
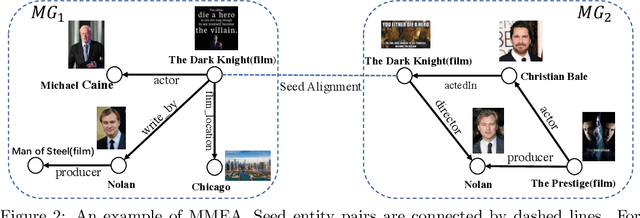
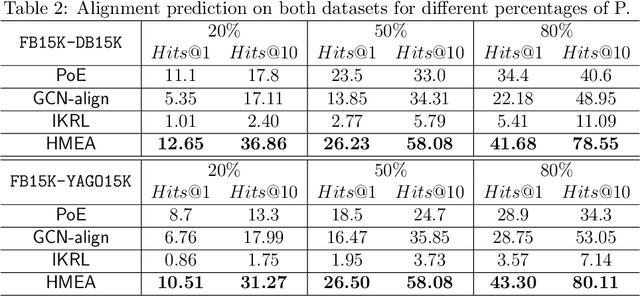
Many AI-related tasks involve the interactions of data in multiple modalities. It has been a new trend to merge multi-modal information into knowledge graph(KG), resulting in multi-modal knowledge graphs (MMKG). However, MMKGs usually suffer from low coverage and incompleteness. To mitigate this problem, a viable approach is to integrate complementary knowledge from other MMKGs. To this end, although existing entity alignment approaches could be adopted, they operate in the Euclidean space, and the resulting Euclidean entity representations can lead to large distortion of KG's hierarchical structure. Besides, the visual information has yet not been well exploited. In response to these issues, in this work, we propose a novel multi-modal entity alignment approach, Hyperbolic multi-modal entity alignment(HMEA), which extends the Euclidean representation to hyperboloid manifold. We first adopt the Hyperbolic Graph Convolutional Networks (HGCNs) to learn structural representations of entities. Regarding the visual information, we generate image embeddings using the densenet model, which are also projected into the hyperbolic space using HGCNs. Finally, we combine the structure and visual representations in the hyperbolic space and use the aggregated embeddings to predict potential alignment results. Extensive experiments and ablation studies demonstrate the effectiveness of our proposed model and its components.