 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Graph Meta Embeddings for Cold-Start Ads in Click-Through Rate Prediction
May 19, 2021
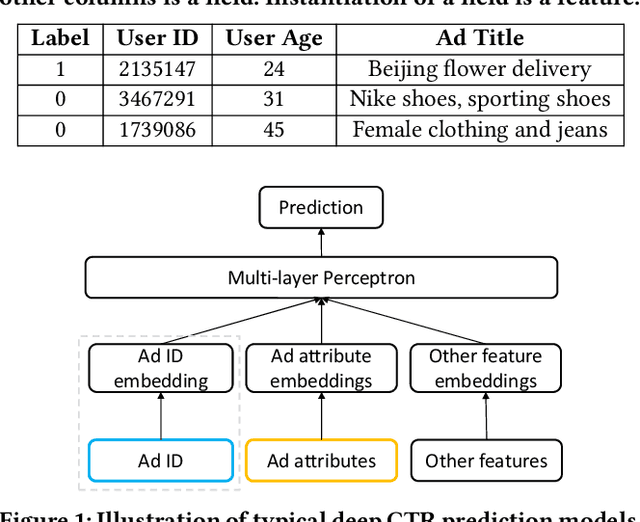
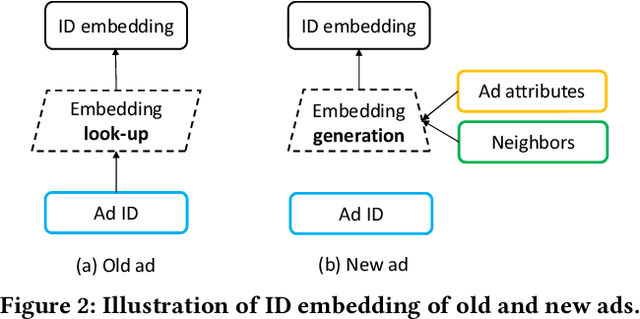
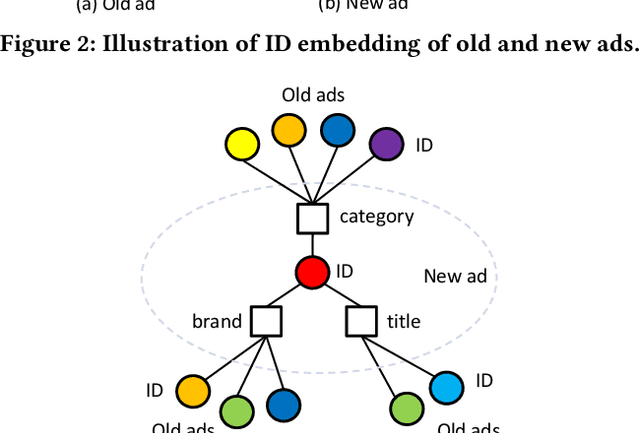
Click-through rate (CTR) prediction is one of the most central tasks in online advertising systems. Recent deep learning-based models that exploit feature embedding and high-order data nonlinearity have shown dramatic successes in CTR prediction. However, these models work poorly on cold-start ads with new IDs, whose embeddings are not well learned yet. In this paper, we propose Graph Meta Embedding (GME) models that can rapidly learn how to generate desirable initial embeddings for new ad IDs based on graph neural networks and meta learning. Previous works address this problem from the new ad itself, but ignore possibly useful information contained in existing old ads. In contrast, GMEs simultaneously consider two information sources: the new ad and existing old ads. For the new ad, GMEs exploit its associated attributes. For existing old ads, GMEs first build a graph to connect them with new ads, and then adaptively distill useful information. We propose three specific GMEs from different perspectives to explore what kind of information to use and how to distill information. In particular, GME-P uses Pre-trained neighbor ID embeddings, GME-G uses Generated neighbor ID embeddings and GME-A uses neighbor Attributes. Experimental results on three real-world datasets show that GMEs can significantly improve the prediction performance in both cold-start (i.e., no training data is available) and warm-up (i.e., a small number of training samples are collected) scenarios over five major deep learning-based CTR prediction models. GMEs can be applied to conversion rate (CVR) prediction as well.
Deep Learning for Channel Coding via Neural Mutual Information Estimation
Mar 07, 2019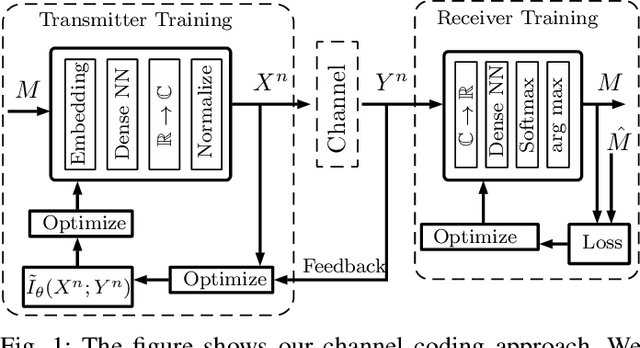
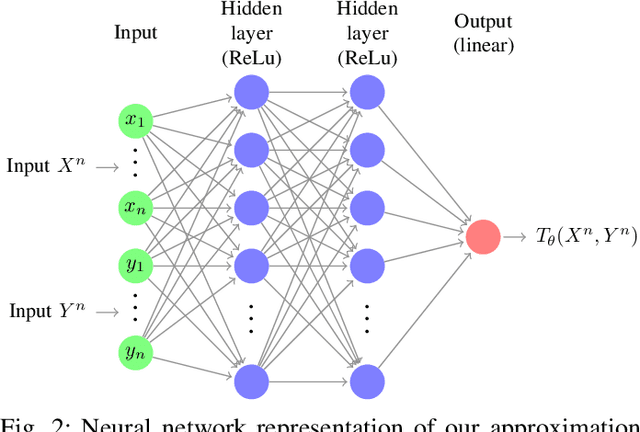
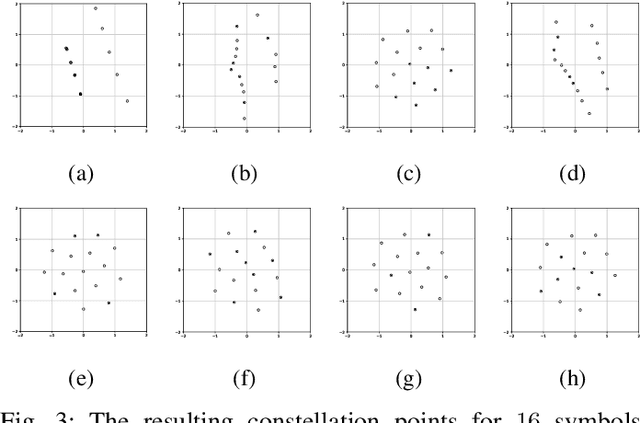
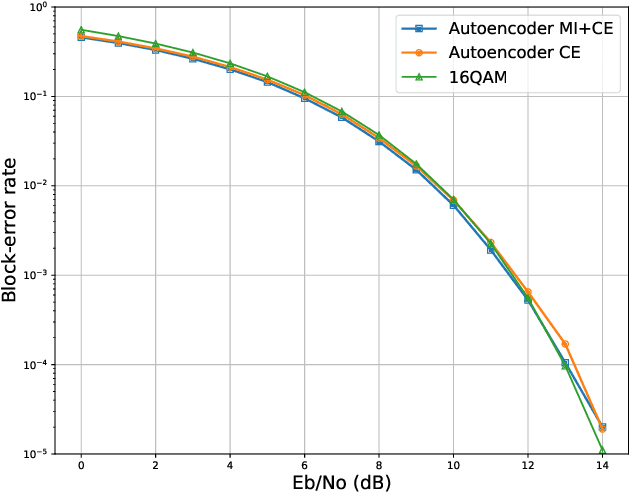
End-to-end deep learning for communication systems, i.e., systems whose encoder and decoder are learned, has attracted significant interest recently, due to its performance which comes close to well-developed classical encoder-decoder designs. However, one of the drawbacks of current learning approaches is that a differentiable channel model is needed for the training of the underlying neural networks. In real-world scenarios, such a channel model is hardly available and often the channel density is not even known at all. Some works, therefore, focus on a generative approach, i.e., generating the channel from samples, or rely on reinforcement learning to circumvent this problem. We present a novel approach which utilizes a recently proposed neural estimator of mutual information. We use this estimator to optimize the encoder for a maximized mutual information, only relying on channel samples. Moreover, we show that our approach achieves the same performance as state-of-the-art end-to-end learning with perfect channel model knowledge.
Examining convolutional feature extraction using Maximum Entropy (ME) and Signal-to-Noise Ratio (SNR) for image classification
May 10, 2021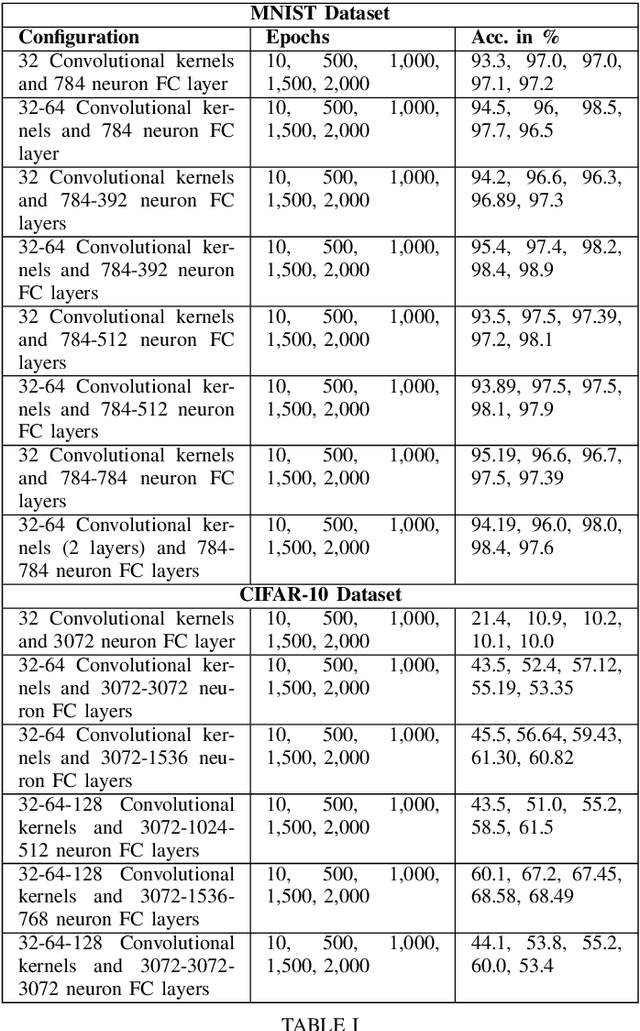
Convolutional Neural Networks (CNNs) specialize in feature extraction rather than function mapping. In doing so they form complex internal hierarchical feature representations, the complexity of which gradually increases with a corresponding increment in neural network depth. In this paper, we examine the feature extraction capabilities of CNNs using Maximum Entropy (ME) and Signal-to-Noise Ratio (SNR) to validate the idea that, CNN models should be tailored for a given task and complexity of the input data. SNR and ME measures are used as they can accurately determine in the input dataset, the relative amount of signal information to the random noise and the maximum amount of information respectively. We use two well known benchmarking datasets, MNIST and CIFAR-10 to examine the information extraction and abstraction capabilities of CNNs. Through our experiments, we examine convolutional feature extraction and abstraction capabilities in CNNs and show that the classification accuracy or performance of CNNs is greatly dependent on the amount, complexity and quality of the signal information present in the input data. Furthermore, we show the effect of information overflow and underflow on CNN classification accuracies. Our hypothesis is that the feature extraction and abstraction capabilities of convolutional layers are limited and therefore, CNN models should be tailored to the input data by using appropriately sized CNNs based on the SNR and ME measures of the input dataset.
* Conference paper, 6 pages, 1 table
Meta-Reinforcement Learning for Heuristic Planning
Jul 06, 2021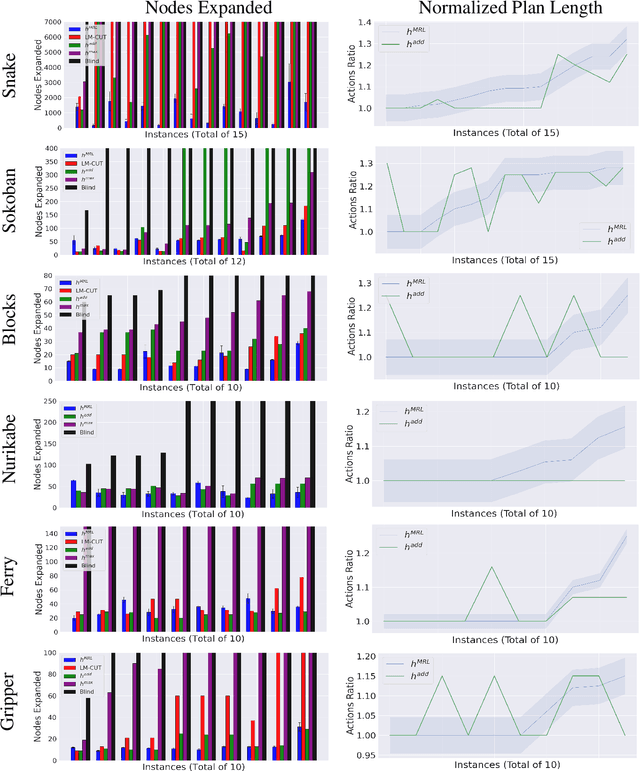
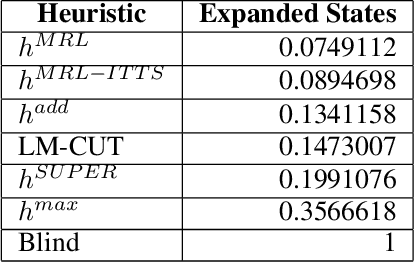
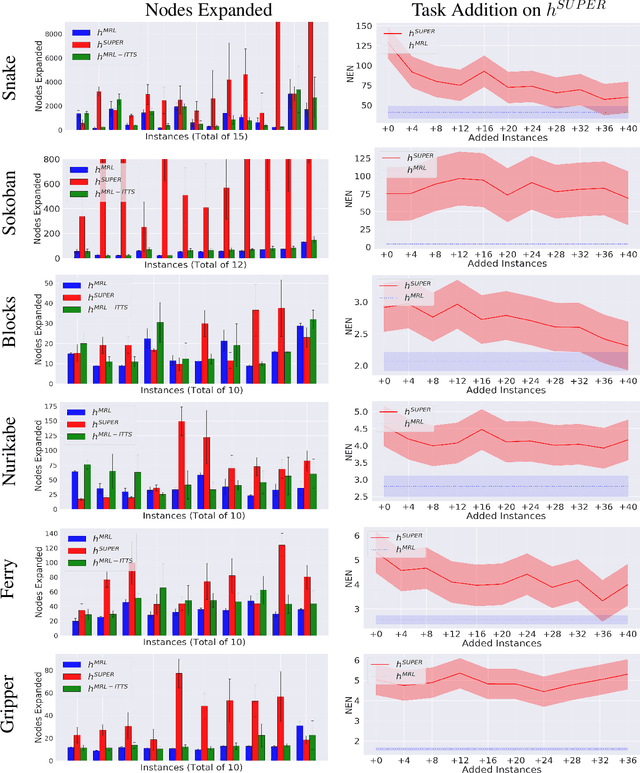
In Meta-Reinforcement Learning (meta-RL) an agent is trained on a set of tasks to prepare for and learn faster in new, unseen, but related tasks. The training tasks are usually hand-crafted to be representative of the expected distribution of test tasks and hence all used in training. We show that given a set of training tasks, learning can be both faster and more effective (leading to better performance in the test tasks), if the training tasks are appropriately selected. We propose a task selection algorithm, Information-Theoretic Task Selection (ITTS), based on information theory, which optimizes the set of tasks used for training in meta-RL, irrespectively of how they are generated. The algorithm establishes which training tasks are both sufficiently relevant for the test tasks, and different enough from one another. We reproduce different meta-RL experiments from the literature and show that ITTS improves the final performance in all of them.
POSSCORE: A Simple Yet Effective Evaluation of Conversational Search with Part of Speech Labelling
Sep 07, 2021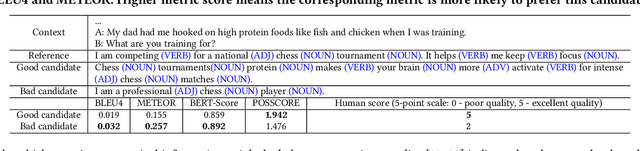
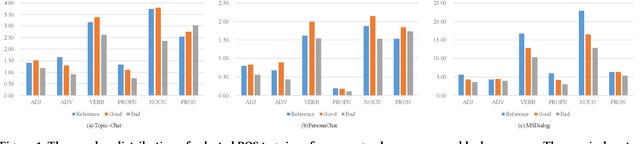
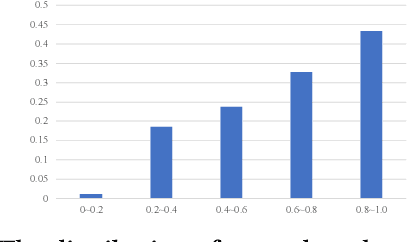
Conversational search systems, such as Google Assistant and Microsoft Cortana, provide a new search paradigm where users are allowed, via natural language dialogues, to communicate with search systems. Evaluating such systems is very challenging since search results are presented in the format of natural language sentences. Given the unlimited number of possible responses, collecting relevance assessments for all the possible responses is infeasible. In this paper, we propose POSSCORE, a simple yet effective automatic evaluation method for conversational search. The proposed embedding-based metric takes the influence of part of speech (POS) of the terms in the response into account. To the best knowledge, our work is the first to systematically demonstrate the importance of incorporating syntactic information, such as POS labels, for conversational search evaluation. Experimental results demonstrate that our metrics can correlate with human preference, achieving significant improvements over state-of-the-art baseline metrics.
Analysis of the relation between smartphone usage changes during the COVID-19 pandemic and usage preferences on apps
Oct 05, 2021
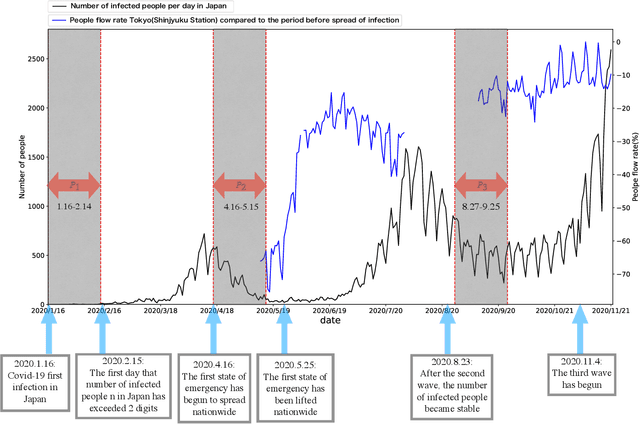

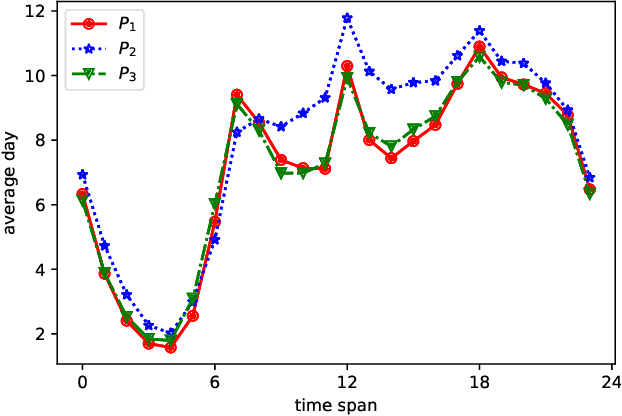
Since the World Health Organization announced the COVID-19 pandemic in March 2020, curbing the spread of the virus has become an international priority. It has greatly affected people's lifestyles. In this article, we observe and analyze the impact of the pandemic on people's lives using changes in smartphone application usage. First, through observing the daily usage change trends of all users during the pandemic, we can understand and analyze the effects of restrictive measures and policies during the pandemic on people's lives. In addition, it is also helpful for the government and health departments to take more appropriate restrictive measures in the case of future pandemics. Second, we defined the usage change features and found 9 different usage change patterns during the pandemic according to clusters of users and show the diversity of daily usage changes. It helps to understand and analyze the different impacts of the pandemic and restrictive measures on different types of people in more detail. Finally, according to prediction models, we discover the main related factors of each usage change type from user preferences and demographic information. It helps to predict changes in smartphone activity during future pandemics or when other restrictive measures are implemented, which may become a new indicator to judge and manage the risks of measures or events.
A 3D Mesh-based Lifting-and-Projection Network for Human Pose Transfer
Sep 24, 2021
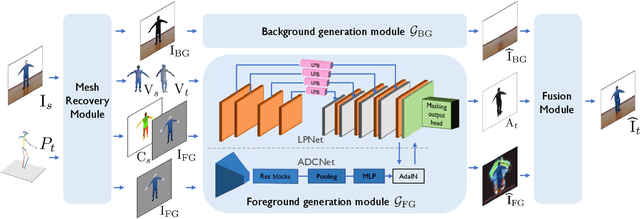
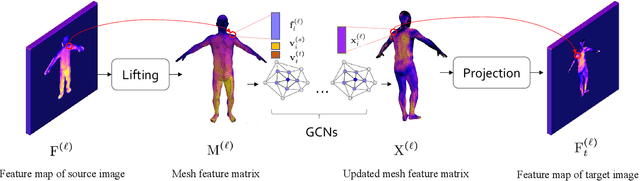

Human pose transfer has typically been modeled as a 2D image-to-image translation problem. This formulation ignores the human body shape prior in 3D space and inevitably causes implausible artifacts, especially when facing occlusion. To address this issue, we propose a lifting-and-projection framework to perform pose transfer in the 3D mesh space. The core of our framework is a foreground generation module, that consists of two novel networks: a lifting-and-projection network (LPNet) and an appearance detail compensating network (ADCNet). To leverage the human body shape prior, LPNet exploits the topological information of the body mesh to learn an expressive visual representation for the target person in the 3D mesh space. To preserve texture details, ADCNet is further introduced to enhance the feature produced by LPNet with the source foreground image. Such design of the foreground generation module enables the model to better handle difficult cases such as those with occlusions. Experiments on the iPER and Fashion datasets empirically demonstrate that the proposed lifting-and-projection framework is effective and outperforms the existing image-to-image-based and mesh-based methods on human pose transfer task in both self-transfer and cross-transfer settings.
N15News: A New Dataset for Multimodal News Classification
Aug 30, 2021
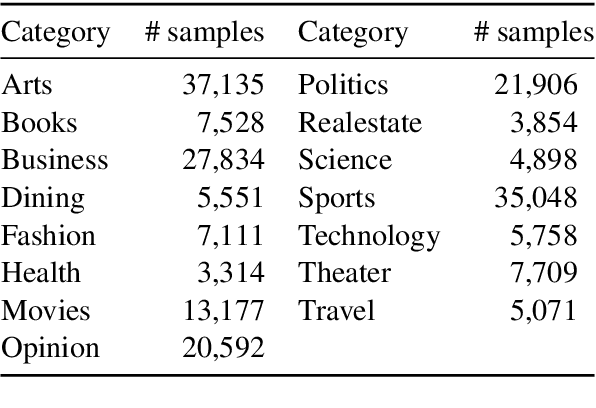
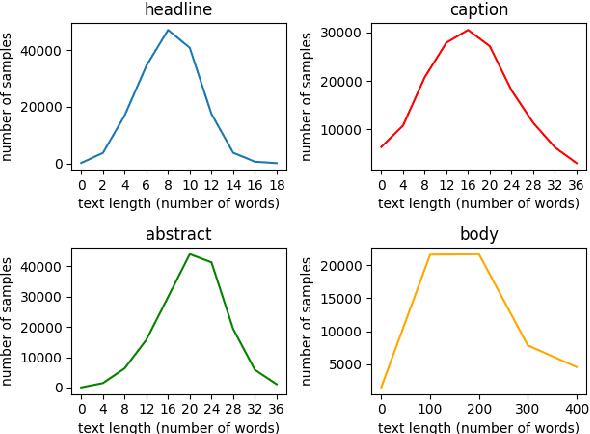

Current news datasets merely focus on text features on the news and rarely leverage the feature of images, excluding numerous essential features for news classification. In this paper, we propose a new dataset, N15News, which is generated from New York Times with 15 categories and contains both text and image information in each news. We design a novel multitask multimodal network with different fusion methods, and experiments show multimodal news classification performs better than text-only news classification. Depending on the length of the text, the classification accuracy can be increased by up to 5.8%. Our research reveals the relationship between the performance of a multimodal classifier and its sub-classifiers, and also the possible improvements when applying multimodal in news classification. N15News is shown to have great potential to prompt the multimodal news studies.
Gap-Dependent Unsupervised Exploration for Reinforcement Learning
Aug 11, 2021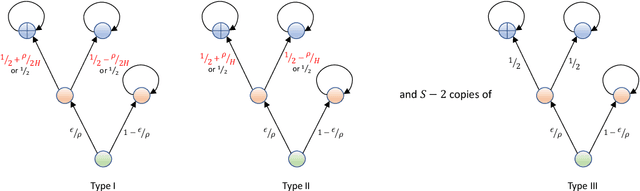
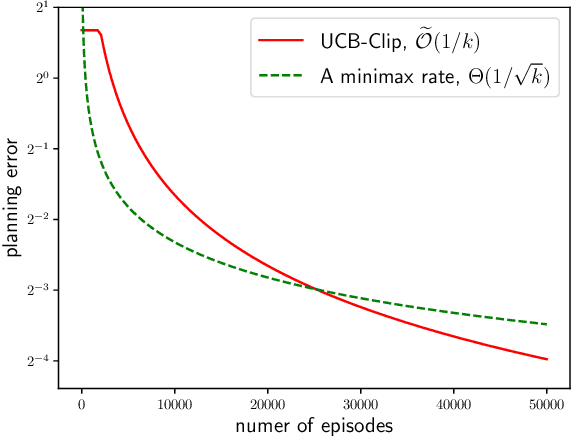
For the problem of task-agnostic reinforcement learning (RL), an agent first collects samples from an unknown environment without the supervision of reward signals, then is revealed with a reward and is asked to compute a corresponding near-optimal policy. Existing approaches mainly concern the worst-case scenarios, in which no structural information of the reward/transition-dynamics is utilized. Therefore the best sample upper bound is $\propto\widetilde{\mathcal{O}}(1/\epsilon^2)$, where $\epsilon>0$ is the target accuracy of the obtained policy, and can be overly pessimistic. To tackle this issue, we provide an efficient algorithm that utilizes a gap parameter, $\rho>0$, to reduce the amount of exploration. In particular, for an unknown finite-horizon Markov decision process, the algorithm takes only $\widetilde{\mathcal{O}} (1/\epsilon \cdot (H^3SA / \rho + H^4 S^2 A) )$ episodes of exploration, and is able to obtain an $\epsilon$-optimal policy for a post-revealed reward with sub-optimality gap at least $\rho$, where $S$ is the number of states, $A$ is the number of actions, and $H$ is the length of the horizon, obtaining a nearly \emph{quadratic saving} in terms of $\epsilon$. We show that, information-theoretically, this bound is nearly tight for $\rho < \Theta(1/(HS))$ and $H>1$. We further show that $\propto\widetilde{\mathcal{O}}(1)$ sample bound is possible for $H=1$ (i.e., multi-armed bandit) or with a sampling simulator, establishing a stark separation between those settings and the RL setting.
Leveraging Pre-trained Language Model for Speech Sentiment Analysis
Jun 11, 2021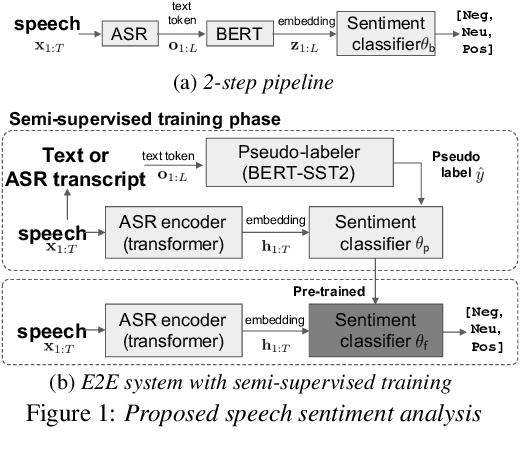
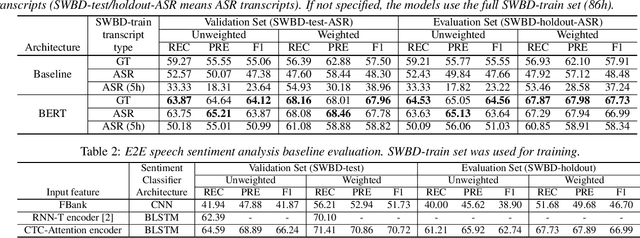
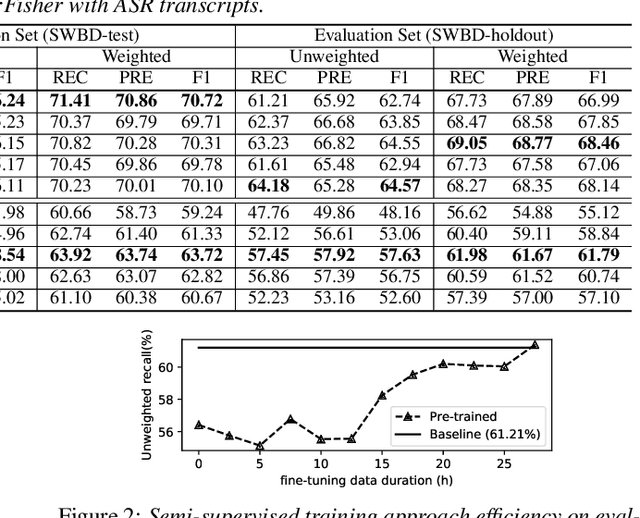
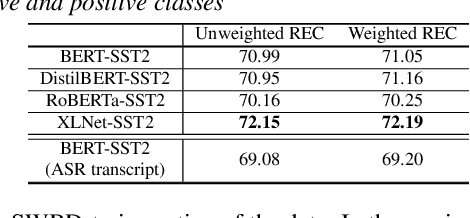
In this paper, we explore the use of pre-trained language models to learn sentiment information of written texts for speech sentiment analysis. First, we investigate how useful a pre-trained language model would be in a 2-step pipeline approach employing Automatic Speech Recognition (ASR) and transcripts-based sentiment analysis separately. Second, we propose a pseudo label-based semi-supervised training strategy using a language model on an end-to-end speech sentiment approach to take advantage of a large, but unlabeled speech dataset for training. Although spoken and written texts have different linguistic characteristics, they can complement each other in understanding sentiment. Therefore, the proposed system can not only model acoustic characteristics to bear sentiment-specific information in speech signals, but learn latent information to carry sentiments in the text representation. In these experiments, we demonstrate the proposed approaches improve F1 scores consistently compared to systems without a language model. Moreover, we also show that the proposed framework can reduce 65% of human supervision by leveraging a large amount of data without human sentiment annotation and boost performance in a low-resource condition where the human sentiment annotation is not available enough.