 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spatio-Temporal Context for Action Detection
Jun 29, 2021

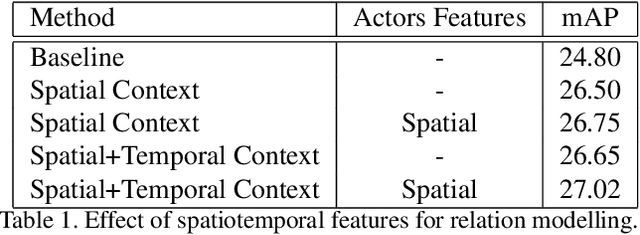
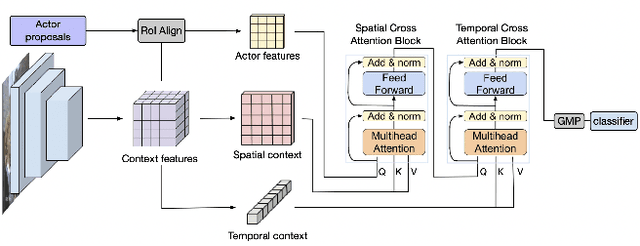
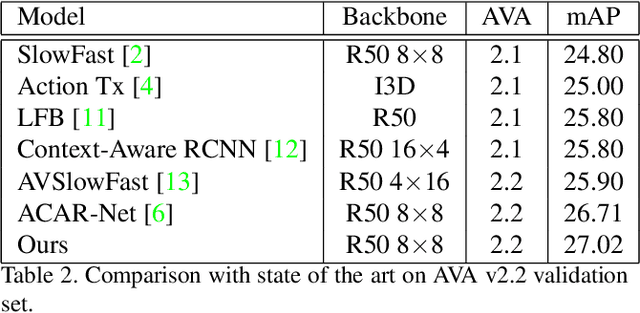
Research in action detection has grown in the recentyears, as it plays a key role in video understanding. Modelling the interactions (either spatial or temporal) between actors and their context has proven to be essential for this task. While recent works use spatial features with aggregated temporal information, this work proposes to use non-aggregated temporal information. This is done by adding an attention based method that leverages spatio-temporal interactions between elements in the scene along the clip.The main contribution of this work is the introduction of two cross attention blocks to effectively model the spatial relations and capture short range temporal interactions.Experiments on the AVA dataset show the advantages of the proposed approach that models spatio-temporal relations between relevant elements in the scene, outperforming other methods that model actor interactions with their context by +0.31 mAP.
End-to-end Waveform Learning Through Joint Optimization of Pulse and Constellation Shaping
Jun 29, 2021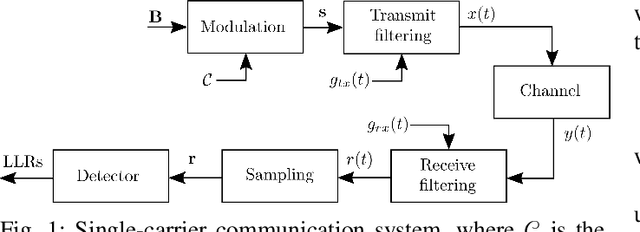

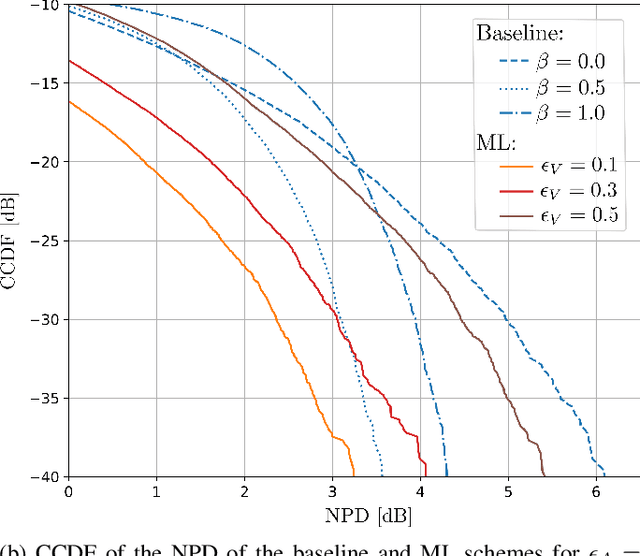
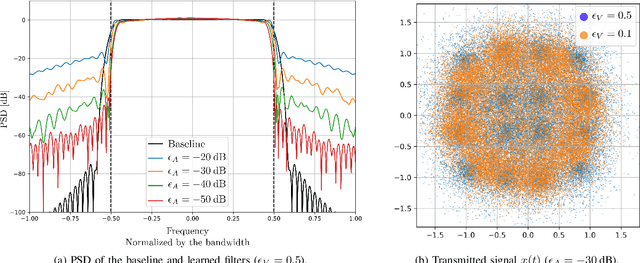
As communication systems are foreseen to enable new services such as joint communication and sensing and utilize parts of the sub-THz spectrum, the design of novel waveforms that can support these emerging applications becomes increasingly challenging. We present in this work an end-to-end learning approach to design waveforms through joint learning of pulse shaping and constellation geometry, together with a neural network (NN)-based receiver. Optimization is performed to maximize an achievable information rate, while satisfying constraints on out-of-band emission and power envelope. Our results show that the proposed approach enables up to orders of magnitude smaller adjacent channel leakage ratios (ACLRs) with peak-to-average power ratios (PAPRs) competitive with traditional filters, without significant loss of information rate on an additive white Gaussian noise (AWGN) channel, and no additional complexity at the transmitter.
Learning Dual Dynamic Representations on Time-Sliced User-Item Interaction Graphs for Sequential Recommendation
Sep 24, 2021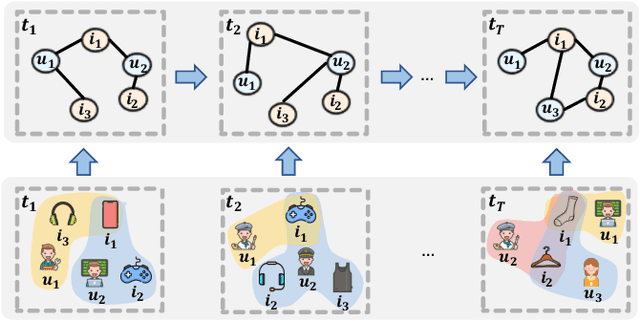
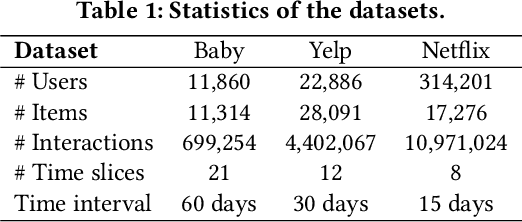
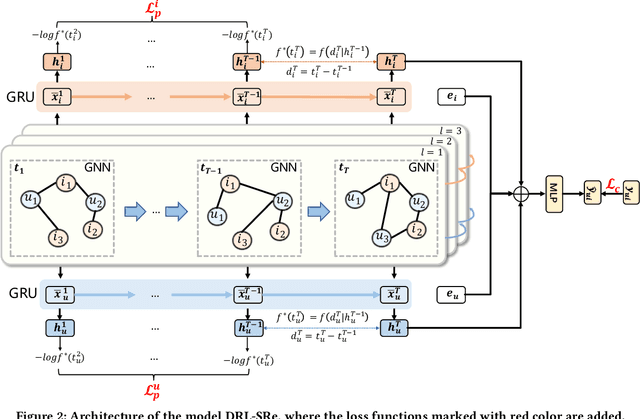
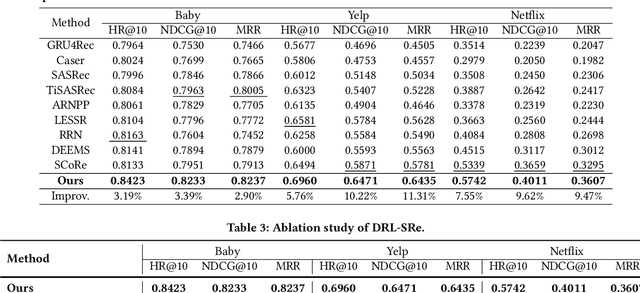
Sequential Recommendation aims to recommend items that a target user will interact with in the near future based on the historically interacted items. While modeling temporal dynamics is crucial for sequential recommendation, most of the existing studies concentrate solely on the user side while overlooking the sequential patterns existing in the counterpart, i.e., the item side. Although a few studies investigate the dynamics involved in the dual sides, the complex user-item interactions are not fully exploited from a global perspective to derive dynamic user and item representations. In this paper, we devise a novel Dynamic Representation Learning model for Sequential Recommendation (DRL-SRe). To better model the user-item interactions for characterizing the dynamics from both sides, the proposed model builds a global user-item interaction graph for each time slice and exploits time-sliced graph neural networks to learn user and item representations. Moreover, to enable the model to capture fine-grained temporal information, we propose an auxiliary temporal prediction task over consecutive time slices based on temporal point process. Comprehensive experiments on three public real-world datasets demonstrate DRL-SRe outperforms the state-of-the-art sequential recommendation models with a large margin.
Truth-Conditional Captioning of Time Series Data
Oct 05, 2021
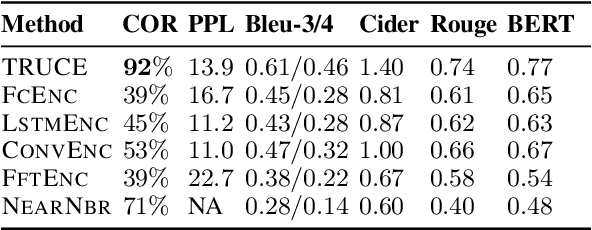
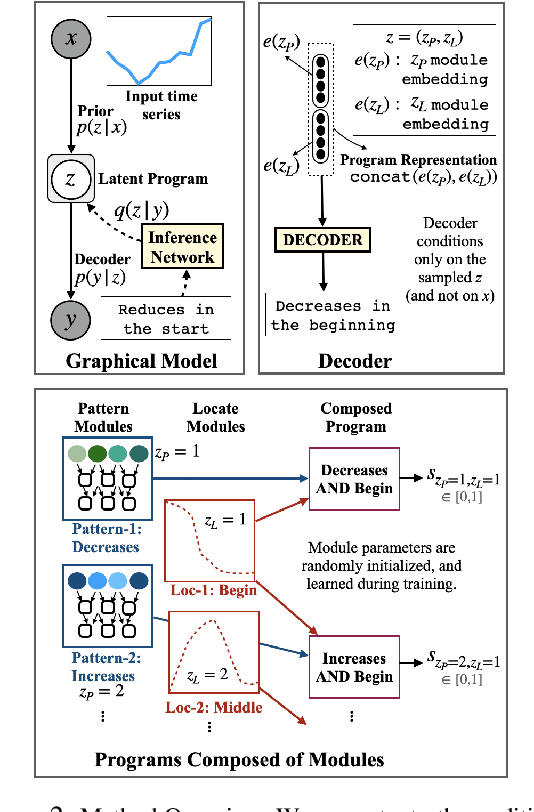
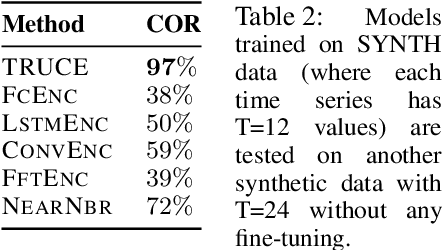
In this paper, we explore the task of automatically generating natural language descriptions of salient patterns in a time series, such as stock prices of a company over a week. A model for this task should be able to extract high-level patterns such as presence of a peak or a dip. While typical contemporary neural models with attention mechanisms can generate fluent output descriptions for this task, they often generate factually incorrect descriptions. We propose a computational model with a truth-conditional architecture which first runs small learned programs on the input time series, then identifies the programs/patterns which hold true for the given input, and finally conditions on only the chosen valid program (rather than the input time series) to generate the output text description. A program in our model is constructed from modules, which are small neural networks that are designed to capture numerical patterns and temporal information. The modules are shared across multiple programs, enabling compositionality as well as efficient learning of module parameters. The modules, as well as the composition of the modules, are unobserved in data, and we learn them in an end-to-end fashion with the only training signal coming from the accompanying natural language text descriptions. We find that the proposed model is able to generate high-precision captions even though we consider a small and simple space of module types.
Multi-Task Learning for Scalable and Dense Multi-Layer Bayesian Map Inference
Jun 28, 2021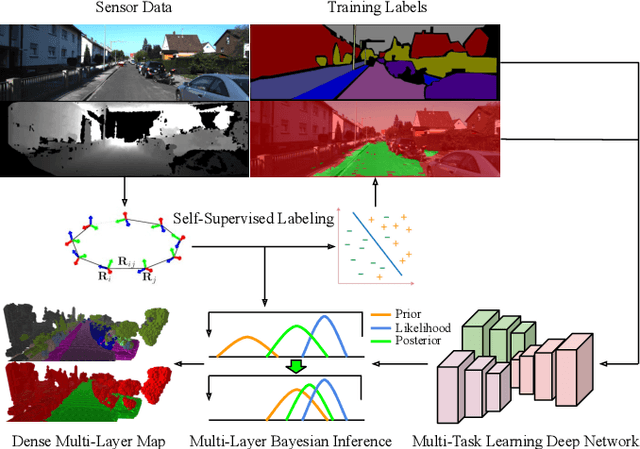
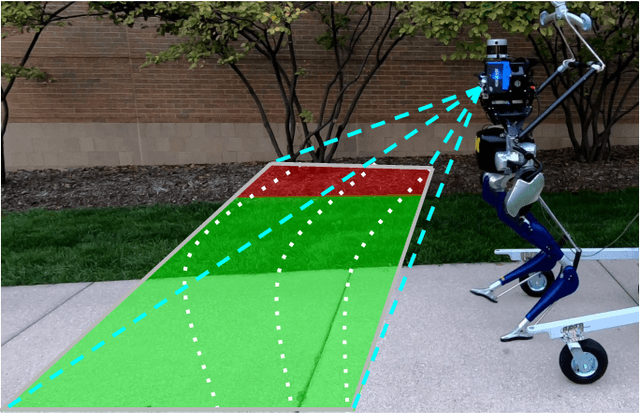


This paper presents a novel and flexible multi-task multi-layer Bayesian mapping framework with readily extendable attribute layers. The proposed framework goes beyond modern metric-semantic maps to provide even richer environmental information for robots in a single mapping formalism while exploiting existing inter-layer correlations. It removes the need for a robot to access and process information from many separate maps when performing a complex task and benefits from the correlation between map layers, advancing the way robots interact with their environments. To this end, we design a multi-task deep neural network with attention mechanisms as our front-end to provide multiple observations for multiple map layers simultaneously. Our back-end runs a scalable closed-form Bayesian inference with only logarithmic time complexity. We apply the framework to build a dense robotic map including metric-semantic occupancy and traversability layers. Traversability ground truth labels are automatically generated from exteroceptive sensory data in a self-supervised manner. We present extensive experimental results on publicly available data sets and data collected by a 3D bipedal robot platform on the University of Michigan North Campus and show reliable mapping performance in different environments. Finally, we also discuss how the current framework can be extended to incorporate more information such as friction, signal strength, temperature, and physical quantity concentration using Gaussian map layers. The software for reproducing the presented results or running on customized data is made publicly available.
High-Power and High-Capacity Mobile Optical SWIPT
Jul 20, 2021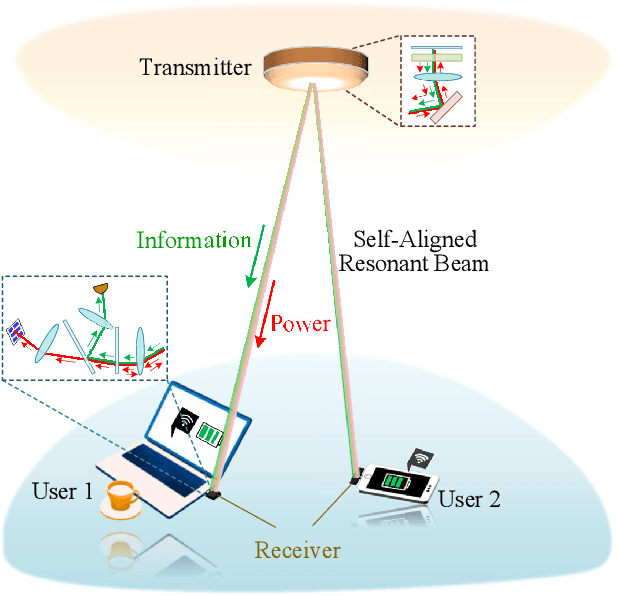
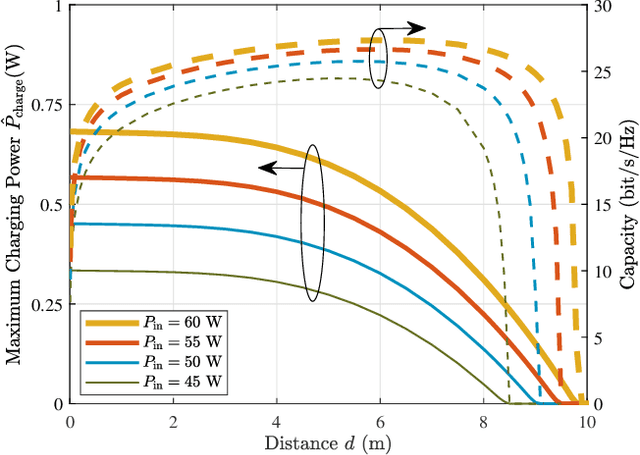
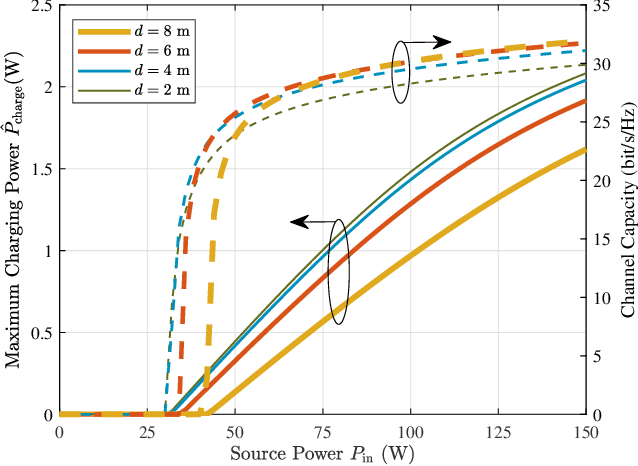
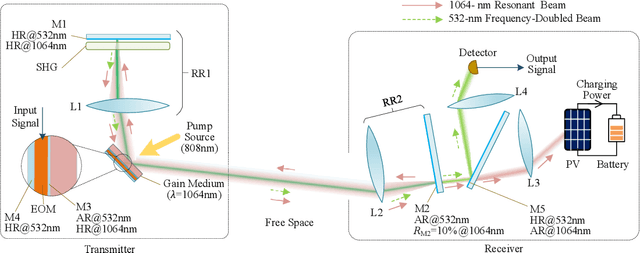
The increasing demands of power supply and data rate for mobile devices promote the research of simultaneous information and power transfer (SWIPT). Optical SWIPT, as known as simultaneous light information and power transfer (SLIPT), can provide high-capacity communication and high-power charging. However, light emitting diodes (LEDs)-based SLIPT technologies have low efficiency due to energy dissipation over the air. Laser-based SLIPT technologies face the challenge in mobility, as it needs accurate positioning, fast beam steering, and real-time tracking. In this paper, we propose a mobile SLIPT scheme based on spatially separated laser resonator (SSLR) and intra-cavity second harmonic generation (SHG). The power and data are transferred via separated frequencies, while they share the same self-aligned resonant beam path, without the needs of receiver positioning and beam steering. We establish the analysis model of the resonant beam power and its second harmonic power. We also evaluate the system performance on deliverable power and channel capacity. Numerical results show that the proposed system can achieve watt-level battery charging power and above 20-bit/s/Hz communication capacity over 8-m distance, which satisfies the requirements of most indoor mobile devices.
HybridSVD: When Collaborative Information is Not Enough
Jul 27, 2018
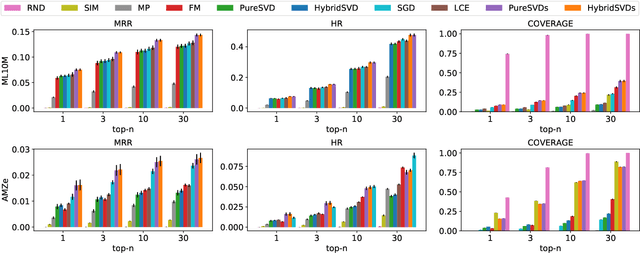
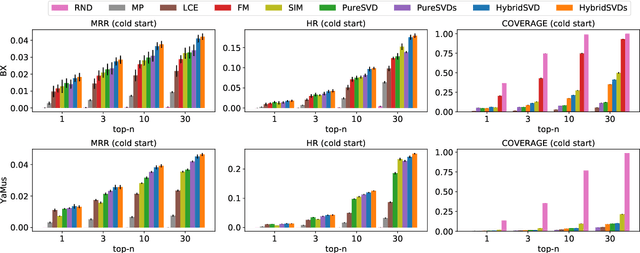
We propose a hybrid algorithm for top-$n$ recommendation task that allows to incorporate both user and item side information within the standard collaborative filtering approach. The algorithm extends PureSVD -- one of the state-of-the-art latent factor models -- by exploiting a generalized formulation of the singular value decomposition. This allows to inherit key advantages of the classical algorithm such as highly efficient Lanczos-based optimization procedure, minimal parameter tuning during a model selection phase and a quick folding-in computation to generate recommendations instantly even in a highly dynamic online environment. Within the generalized formulation itself we provide an efficient scheme for side information fusion which avoids undesirable computational overhead and addresses the scalability question. Evaluation of the model is performed in both standard and cold-start scenarios using the datasets with different sparsity levels. We demonstrate in which cases our approach outperforms conventional methods and also provide some intuition on when it may give no significant improvement.
Analysis of the relation between smartphone usage changes during the COVID-19 pandemic and usage preferences on apps
Oct 05, 2021
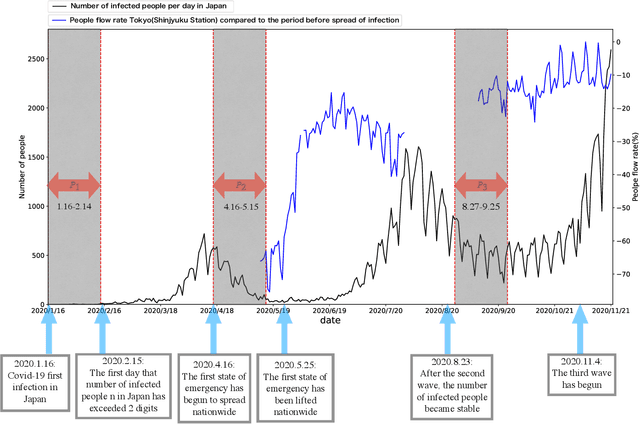

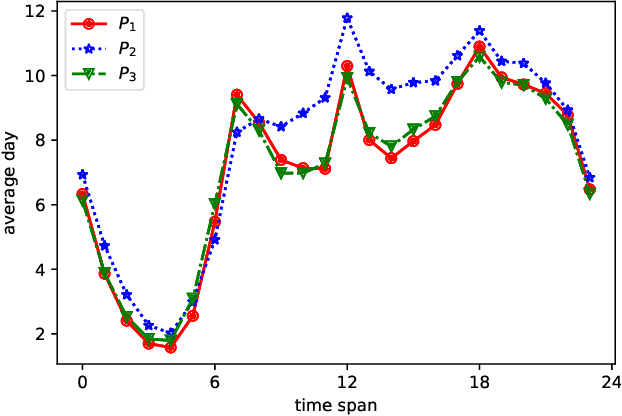
Since the World Health Organization announced the COVID-19 pandemic in March 2020, curbing the spread of the virus has become an international priority. It has greatly affected people's lifestyles. In this article, we observe and analyze the impact of the pandemic on people's lives using changes in smartphone application usage. First, through observing the daily usage change trends of all users during the pandemic, we can understand and analyze the effects of restrictive measures and policies during the pandemic on people's lives. In addition, it is also helpful for the government and health departments to take more appropriate restrictive measures in the case of future pandemics. Second, we defined the usage change features and found 9 different usage change patterns during the pandemic according to clusters of users and show the diversity of daily usage changes. It helps to understand and analyze the different impacts of the pandemic and restrictive measures on different types of people in more detail. Finally, according to prediction models, we discover the main related factors of each usage change type from user preferences and demographic information. It helps to predict changes in smartphone activity during future pandemics or when other restrictive measures are implemented, which may become a new indicator to judge and manage the risks of measures or events.
POSSCORE: A Simple Yet Effective Evaluation of Conversational Search with Part of Speech Labelling
Sep 07, 2021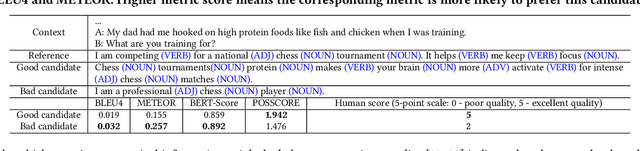
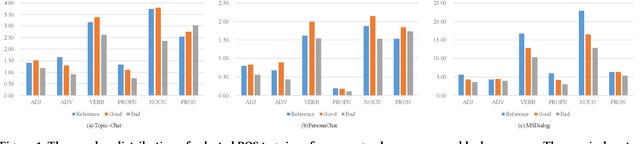
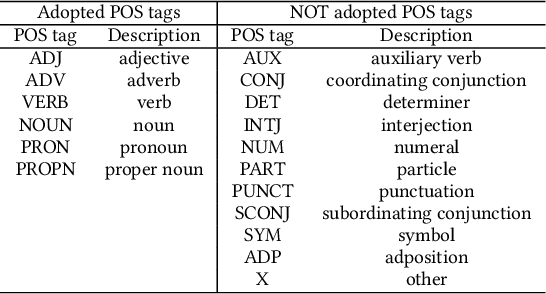
Conversational search systems, such as Google Assistant and Microsoft Cortana, provide a new search paradigm where users are allowed, via natural language dialogues, to communicate with search systems. Evaluating such systems is very challenging since search results are presented in the format of natural language sentences. Given the unlimited number of possible responses, collecting relevance assessments for all the possible responses is infeasible. In this paper, we propose POSSCORE, a simple yet effective automatic evaluation method for conversational search. The proposed embedding-based metric takes the influence of part of speech (POS) of the terms in the response into account. To the best knowledge, our work is the first to systematically demonstrate the importance of incorporating syntactic information, such as POS labels, for conversational search evaluation. Experimental results demonstrate that our metrics can correlate with human preference, achieving significant improvements over state-of-the-art baseline metrics.
A 3D Mesh-based Lifting-and-Projection Network for Human Pose Transfer
Sep 24, 2021
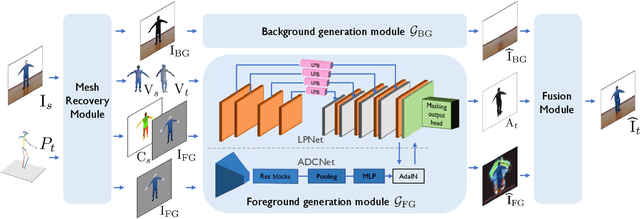
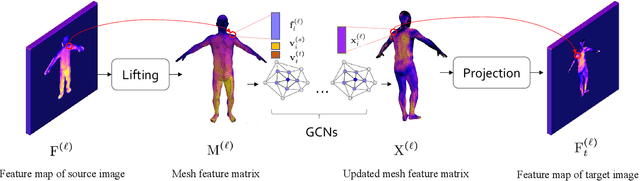

Human pose transfer has typically been modeled as a 2D image-to-image translation problem. This formulation ignores the human body shape prior in 3D space and inevitably causes implausible artifacts, especially when facing occlusion. To address this issue, we propose a lifting-and-projection framework to perform pose transfer in the 3D mesh space. The core of our framework is a foreground generation module, that consists of two novel networks: a lifting-and-projection network (LPNet) and an appearance detail compensating network (ADCNet). To leverage the human body shape prior, LPNet exploits the topological information of the body mesh to learn an expressive visual representation for the target person in the 3D mesh space. To preserve texture details, ADCNet is further introduced to enhance the feature produced by LPNet with the source foreground image. Such design of the foreground generation module enables the model to better handle difficult cases such as those with occlusions. Experiments on the iPER and Fashion datasets empirically demonstrate that the proposed lifting-and-projection framework is effective and outperforms the existing image-to-image-based and mesh-based methods on human pose transfer task in both self-transfer and cross-transfer settings.