 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GA-NET: Global Attention Network for Point Cloud Semantic Segmentation
Jul 07, 2021

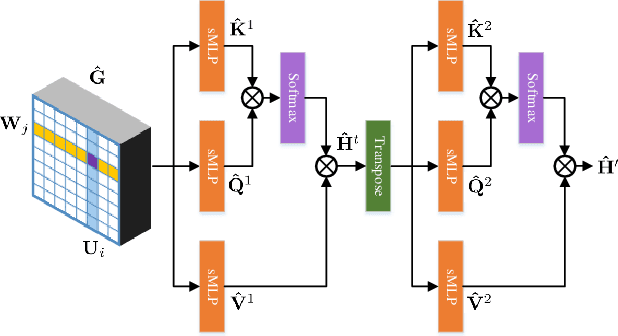


How to learn long-range dependencies from 3D point clouds is a challenging problem in 3D point cloud analysis. Addressing this problem, we propose a global attention network for point cloud semantic segmentation, named as GA-Net, consisting of a point-independent global attention module and a point-dependent global attention module for obtaining contextual information of 3D point clouds in this paper. The point-independent global attention module simply shares a global attention map for all 3D points. In the point-dependent global attention module, for each point, a novel random cross attention block using only two randomly sampled subsets is exploited to learn the contextual information of all the points. Additionally, we design a novel point-adaptive aggregation block to replace linear skip connection for aggregating more discriminate features. Extensive experimental results on three 3D public datasets demonstrate that our method outperforms state-of-the-art methods in most cases.
Moving Object Detection for Event-based vision using Graph Spectral Clustering
Sep 30, 2021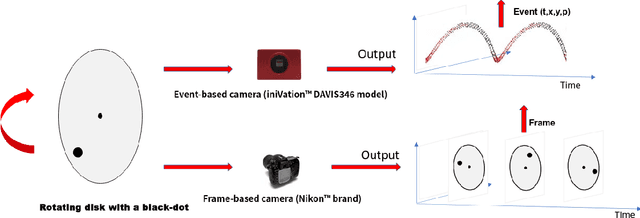
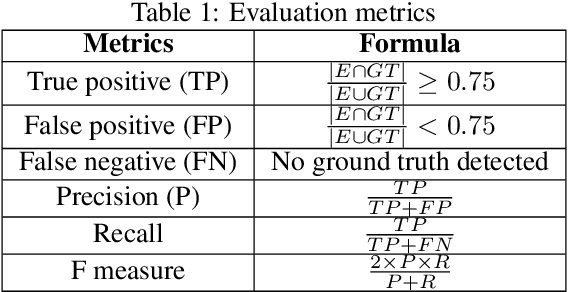
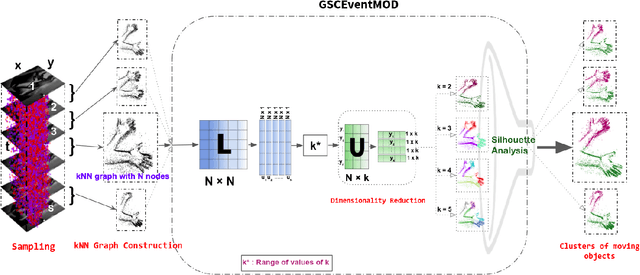

Moving object detection has been a central topic of discussion in computer vision for its wide range of applications like in self-driving cars, video surveillance, security, and enforcement. Neuromorphic Vision Sensors (NVS) are bio-inspired sensors that mimic the working of the human eye. Unlike conventional frame-based cameras, these sensors capture a stream of asynchronous 'events' that pose multiple advantages over the former, like high dynamic range, low latency, low power consumption, and reduced motion blur. However, these advantages come at a high cost, as the event camera data typically contains more noise and has low resolution. Moreover, as event-based cameras can only capture the relative changes in brightness of a scene, event data do not contain usual visual information (like texture and color) as available in video data from normal cameras. So, moving object detection in event-based cameras becomes an extremely challenging task. In this paper, we present an unsupervised Graph Spectral Clustering technique for Moving Object Detection in Event-based data (GSCEventMOD). We additionally show how the optimum number of moving objects can be automatically determined. Experimental comparisons on publicly available datasets show that the proposed GSCEventMOD algorithm outperforms a number of state-of-the-art techniques by a maximum margin of 30%.
Do sound event representations generalize to other audio tasks? A case study in audio transfer learning
Jun 21, 2021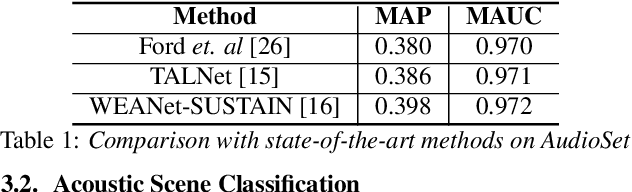
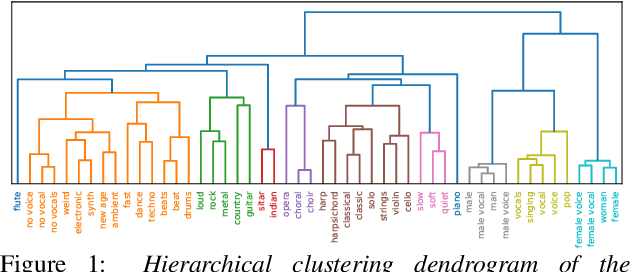
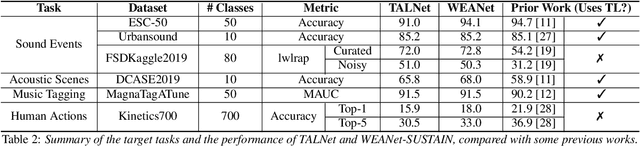
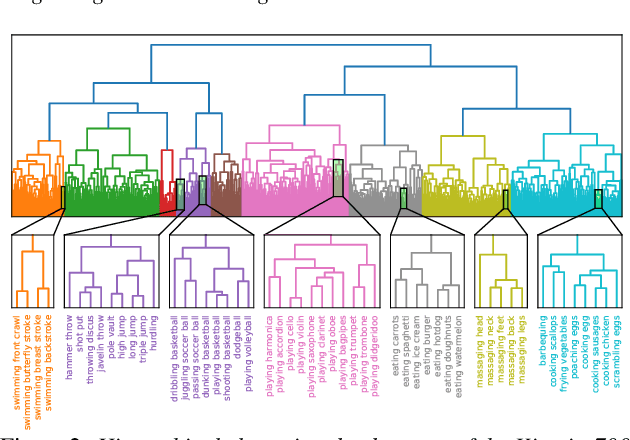
Transfer learning is critical for efficient information transfer across multiple related learning problems. A simple, yet effective transfer learning approach utilizes deep neural networks trained on a large-scale task for feature extraction. Such representations are then used to learn related downstream tasks. In this paper, we investigate transfer learning capacity of audio representations obtained from neural networks trained on a large-scale sound event detection dataset. We build and evaluate these representations across a wide range of other audio tasks, via a simple linear classifier transfer mechanism. We show that such simple linear transfer is already powerful enough to achieve high performance on the downstream tasks. We also provide insights into the attributes of sound event representations that enable such efficient information transfer.
Prediction of butt rot volume in Norway spruce forest stands using harvester, remotely sensed and environmental data
Jul 09, 2021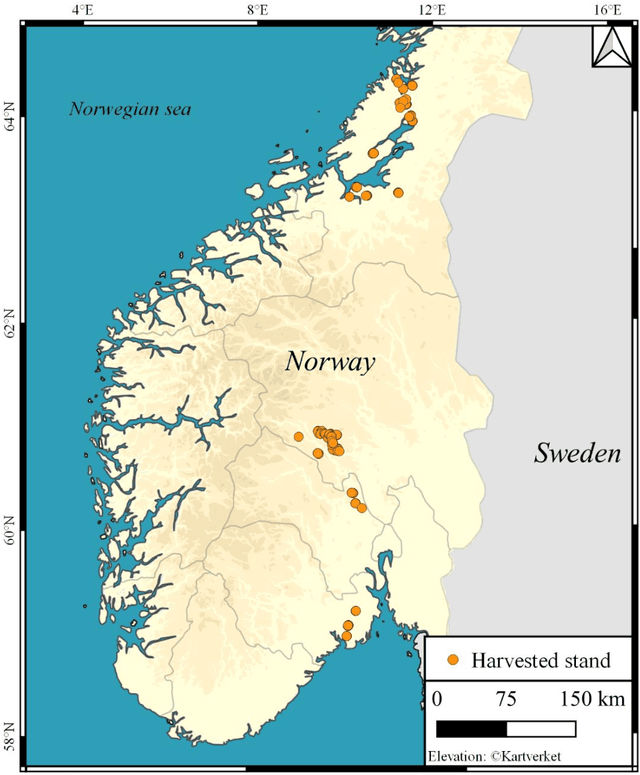
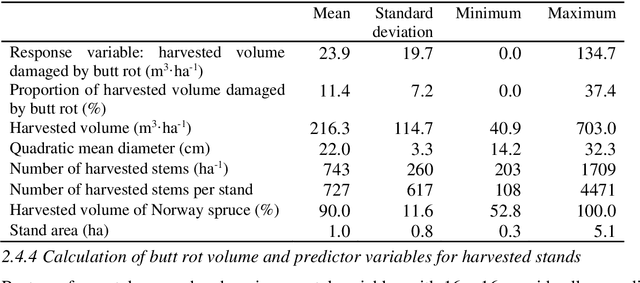
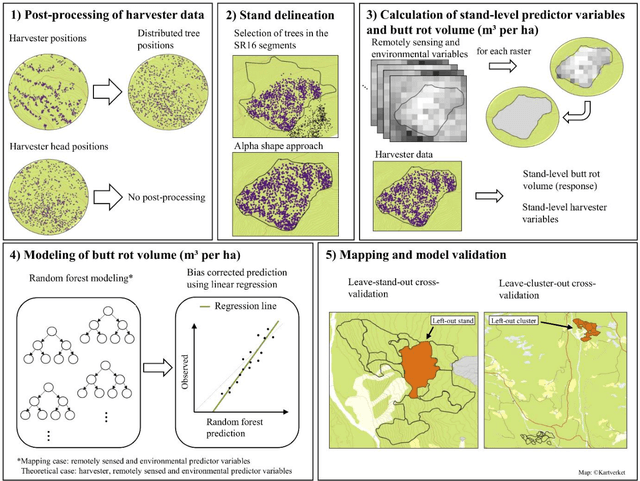
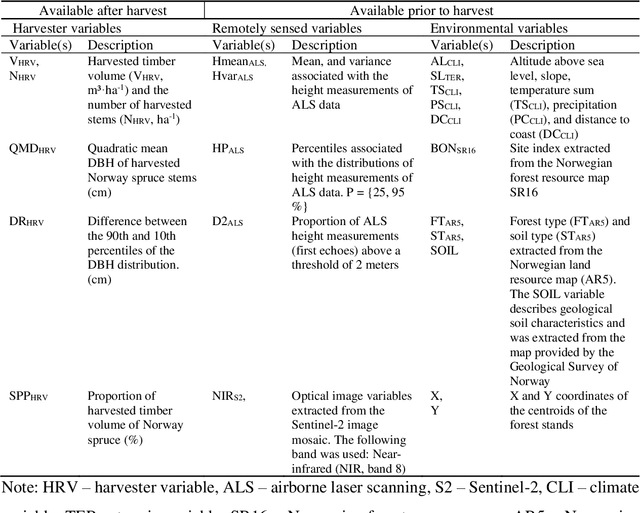
Butt rot (BR) damages associated with Norway spruce (Picea abies [L.] Karst.) account for considerable economic losses in timber production across the northern hemisphere. While information on BR damages is critical for optimal decision-making in forest management, the maps of BR damages are typically lacking in forest information systems. We predicted timber volume damaged by BR at the stand-level in Norway using harvester information of 186,026 stems (clear-cuts), remotely sensed, and environmental data (e.g. climate and terrain characteristics). We utilized random forest (RF) models with two sets of predictor variables: (1) predictor variables available after harvest (theoretical case) and (2) predictor variables available prior to harvest (mapping case). We found that forest attributes characterizing the maturity of forest, such as remote sensing-based height, harvested timber volume and quadratic mean diameter at breast height, were among the most important predictor variables. Remotely sensed predictor variables obtained from airborne laser scanning data and Sentinel-2 imagery were more important than the environmental variables. The theoretical case with a leave-stand-out cross-validation achieved an RMSE of 11.4 $m^3ha^{-1}$ (pseudo $R^2$: 0.66) whereas the mapping case resulted in a pseudo $R^2$ of 0.60. When the spatially distinct k-means clusters of harvested forest stands were used as units in the cross-validation, the RMSE value and pseudo $R^2$ associated with the mapping case were 15.6 $m^3ha^{-1}$ and 0.37, respectively. This indicates that the knowledge about the BR status of spatially close stands is of high importance for obtaining satisfactory error rates in the mapping of BR damages.
RuleBert: Teaching Soft Rules to Pre-trained Language Models
Sep 24, 2021
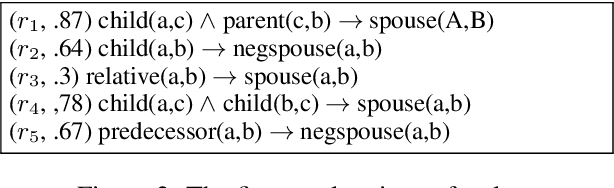
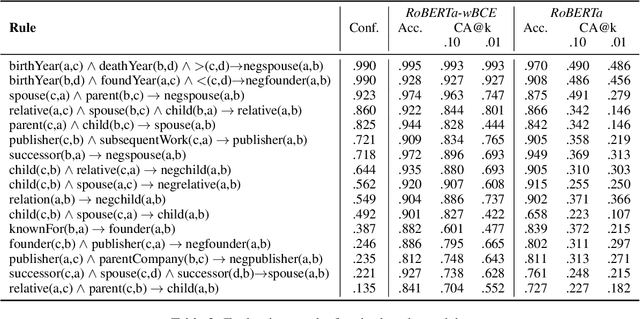
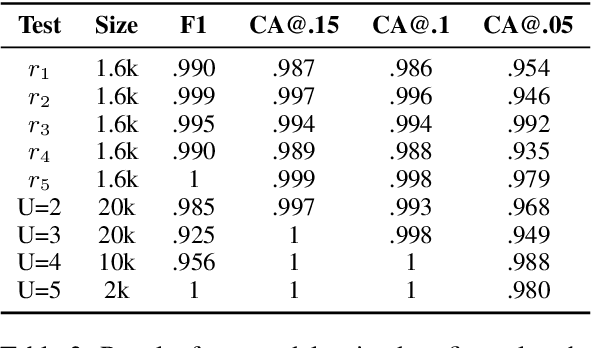
While pre-trained language models (PLMs) are the go-to solution to tackle many natural language processing problems, they are still very limited in their ability to capture and to use common-sense knowledge. In fact, even if information is available in the form of approximate (soft) logical rules, it is not clear how to transfer it to a PLM in order to improve its performance for deductive reasoning tasks. Here, we aim to bridge this gap by teaching PLMs how to reason with soft Horn rules. We introduce a classification task where, given facts and soft rules, the PLM should return a prediction with a probability for a given hypothesis. We release the first dataset for this task, and we propose a revised loss function that enables the PLM to learn how to predict precise probabilities for the task. Our evaluation results show that the resulting fine-tuned models achieve very high performance, even on logical rules that were unseen at training. Moreover, we demonstrate that logical notions expressed by the rules are transferred to the fine-tuned model, yielding state-of-the-art results on external datasets.
* Logical reasoning, soft Horn rules, Transformers, pre-trained language models, combining symbolic and probabilistic methods, BERT
The Animation Transformer: Visual Correspondence via Segment Matching
Sep 08, 2021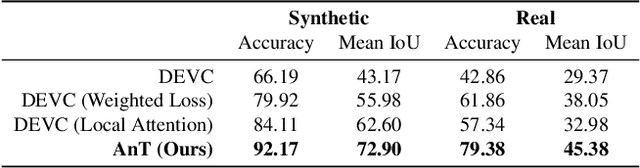
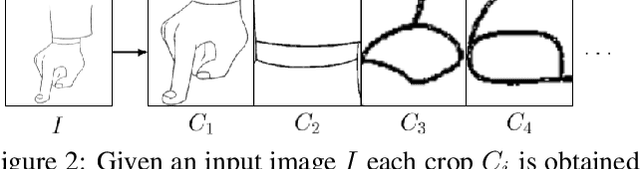
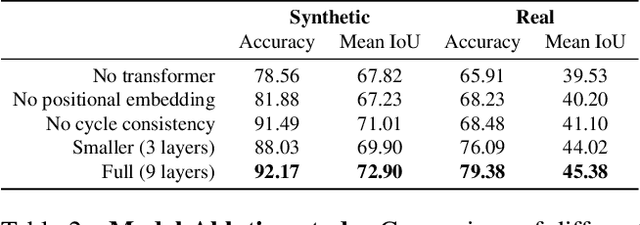
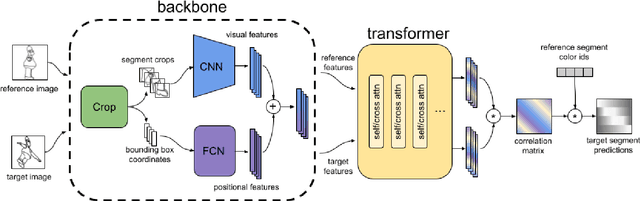
Visual correspondence is a fundamental building block on the way to building assistive tools for hand-drawn animation. However, while a large body of work has focused on learning visual correspondences at the pixel-level, few approaches have emerged to learn correspondence at the level of line enclosures (segments) that naturally occur in hand-drawn animation. Exploiting this structure in animation has numerous benefits: it avoids the intractable memory complexity of attending to individual pixels in high resolution images and enables the use of real-world animation datasets that contain correspondence information at the level of per-segment colors. To that end, we propose the Animation Transformer (AnT) which uses a transformer-based architecture to learn the spatial and visual relationships between segments across a sequence of images. AnT enables practical ML-assisted colorization for professional animation workflows and is publicly accessible as a creative tool in Cadmium.
Resolving gas bubbles ascending in liquid metal from low-SNR neutron radiography images
Sep 08, 2021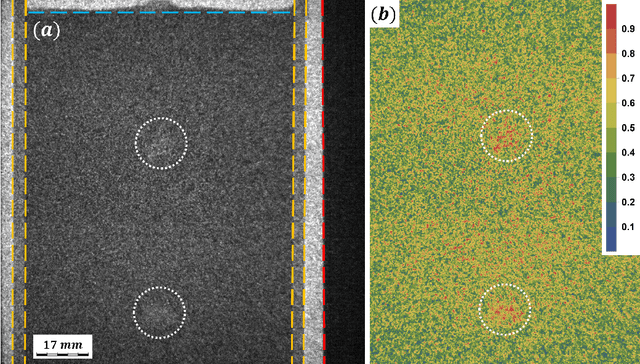
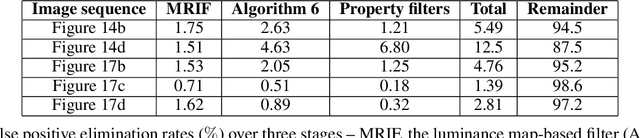
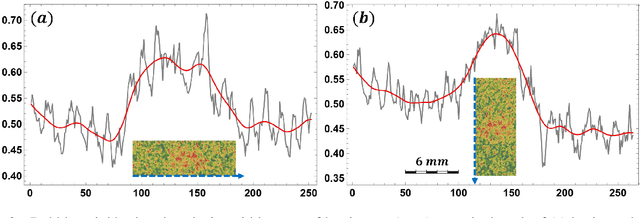

We demonstrate a new image processing methodology for resolving gas bubbles travelling through liquid metal from dynamic neutron radiography images with intrinsically low signal-to-noise ratio. Image pre-processing, denoising and bubble segmentation are described in detail, with practical recommendations. Experimental validation is presented - stationary and moving reference bodies with neutron-transparent cavities are radiographed with imaging conditions similar to the cases with bubbles in liquid metal. The new methods are applied to our experimental data from previous and recent imaging campaigns, and the performance of the methods proposed in this paper is compared against our previously developed methods. Significant improvements are observed as well as the capacity to reliably extract physically meaningful information from measurements performed under highly adverse imaging conditions. The showcased image processing solution and separate elements thereof are readily extendable beyond the present application, and have been made open-source.
Artificial Intelligence-Driven Customized Manufacturing Factory: Key Technologies, Applications, and Challenges
Aug 07, 2021
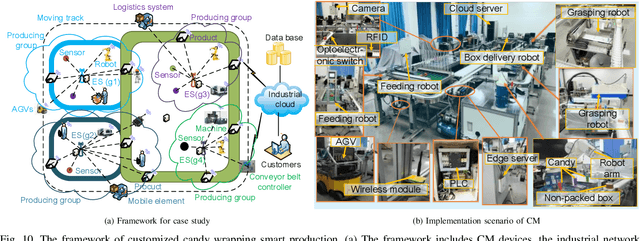
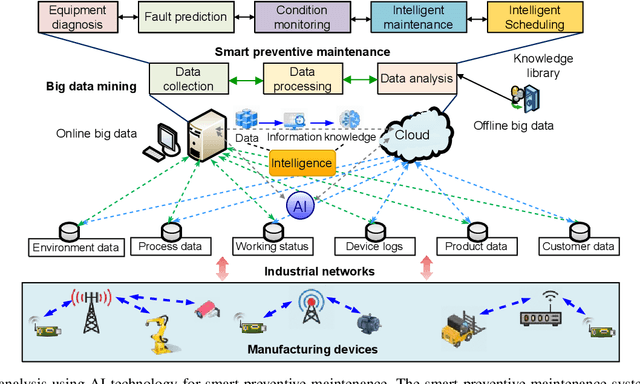
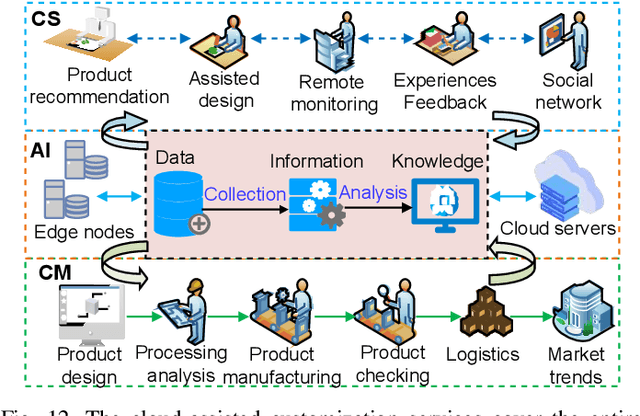
The traditional production paradigm of large batch production does not offer flexibility towards satisfying the requirements of individual customers. A new generation of smart factories is expected to support new multi-variety and small-batch customized production modes. For that, Artificial Intelligence (AI) is enabling higher value-added manufacturing by accelerating the integration of manufacturing and information communication technologies, including computing, communication, and control. The characteristics of a customized smart factory are to include self-perception, operations optimization, dynamic reconfiguration, and intelligent decision-making. The AI technologies will allow manufacturing systems to perceive the environment, adapt to the external needs, and extract the process knowledge, including business models, such as intelligent production, networked collaboration, and extended service models. This paper focuses on the implementation of AI in customized manufacturing (CM). The architecture of an AI-driven customized smart factory is presented. Details of intelligent manufacturing devices, intelligent information interaction, and construction of a flexible manufacturing line are showcased. The state-of-the-art AI technologies of potential use in CM, i.e., machine learning, multi-agent systems, Internet of Things, big data, and cloud-edge computing are surveyed. The AI-enabled technologies in a customized smart factory are validated with a case study of customized packaging. The experimental results have demonstrated that the AI-assisted CM offers the possibility of higher production flexibility and efficiency. Challenges and solutions related to AI in CM are also discussed.
* 21 pages, 12 figures
Multi-modal AsynDGAN: Learn From Distributed Medical Image Data without Sharing Private Information
Dec 15, 2020As deep learning technologies advance, increasingly more data is necessary to generate general and robust models for various tasks. In the medical domain, however, large-scale and multi-parties data training and analyses are infeasible due to the privacy and data security concerns. In this paper, we propose an extendable and elastic learning framework to preserve privacy and security while enabling collaborative learning with efficient communication. The proposed framework is named distributed Asynchronized Discriminator Generative Adversarial Networks (AsynDGAN), which consists of a centralized generator and multiple distributed discriminators. The advantages of our proposed framework are five-fold: 1) the central generator could learn the real data distribution from multiple datasets implicitly without sharing the image data; 2) the framework is applicable for single-modality or multi-modality data; 3) the learned generator can be used to synthesize samples for down-stream learning tasks to achieve close-to-real performance as using actual samples collected from multiple data centers; 4) the synthetic samples can also be used to augment data or complete missing modalities for one single data center; 5) the learning process is more efficient and requires lower bandwidth than other distributed deep learning methods.
Can Edge Probing Tasks Reveal Linguistic Knowledge in QA Models?
Sep 18, 2021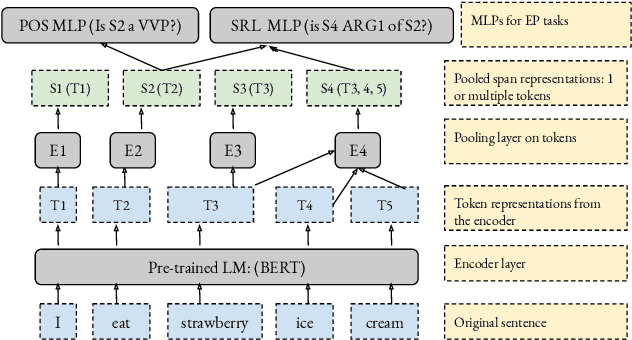
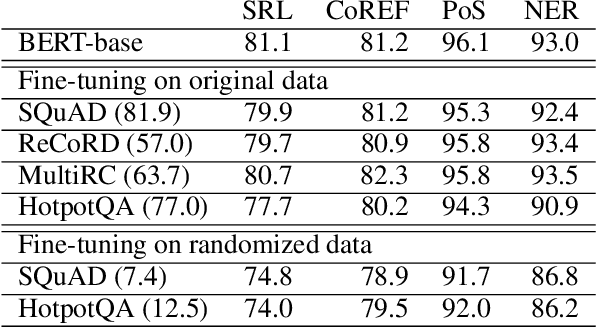
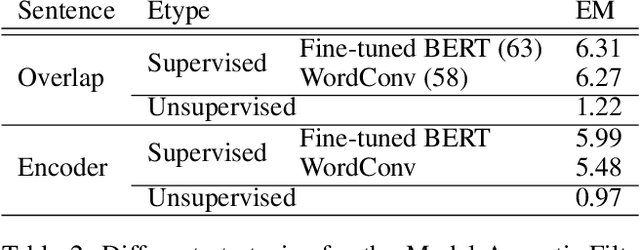
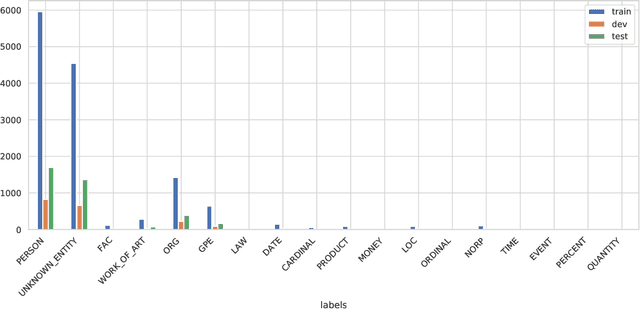
There have been many efforts to try to understand what gram-matical knowledge (e.g., ability to understand the part of speech of a token) is encoded in large pre-trained language models (LM). This is done through 'Edge Probing' (EP) tests: simple ML models that predict the grammatical properties ofa span (whether it has a particular part of speech) using only the LM's token representations. However, most NLP applications use fine-tuned LMs. Here, we ask: if a LM is fine-tuned, does the encoding of linguistic information in it change, as measured by EP tests? Conducting experiments on multiple question-answering (QA) datasets, we answer that question negatively: the EP test results do not change significantly when the fine-tuned QA model performs well or in adversarial situations where the model is forced to learn wrong correlations. However, a critical analysis of the EP task datasets reveals that EP models may rely on spurious correlations to make predictions. This indicates even if fine-tuning changes the encoding of such knowledge, the EP tests might fail to measure it.