 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hierarchical Relation-Guided Type-Sentence Alignment for Long-Tail Relation Extraction with Distant Supervision
Sep 19, 2021
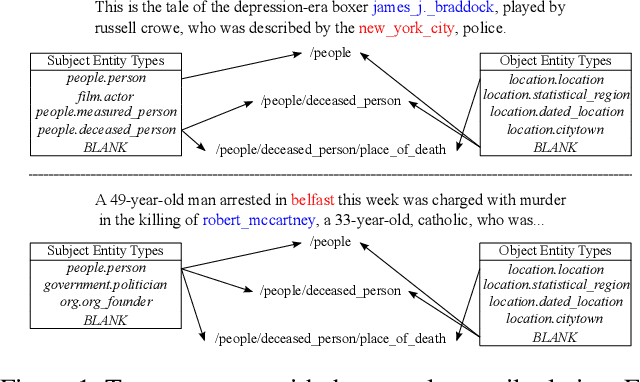
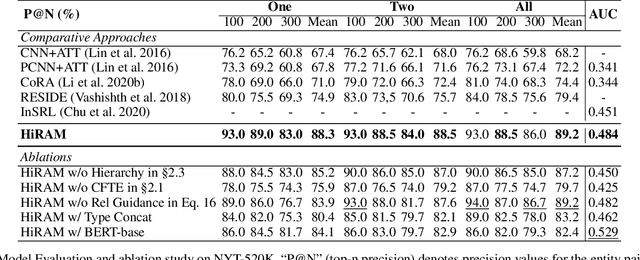
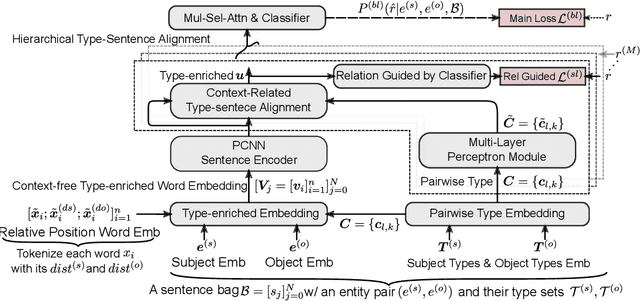
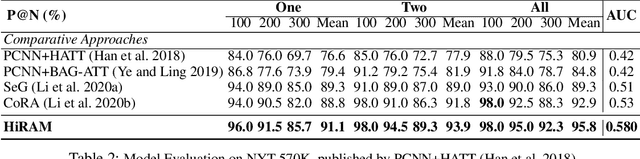
Distant supervision uses triple facts in knowledge graphs to label a corpus for relation extraction, leading to wrong labeling and long-tail problems. Some works use the hierarchy of relations for knowledge transfer to long-tail relations. However, a coarse-grained relation often implies only an attribute (e.g., domain or topic) of the distant fact, making it hard to discriminate relations based solely on sentence semantics. One solution is resorting to entity types, but open questions remain about how to fully leverage the information of entity types and how to align multi-granular entity types with sentences. In this work, we propose a novel model to enrich distantly-supervised sentences with entity types. It consists of (1) a pairwise type-enriched sentence encoding module injecting both context-free and -related backgrounds to alleviate sentence-level wrong labeling, and (2) a hierarchical type-sentence alignment module enriching a sentence with the triple fact's basic attributes to support long-tail relations. Our model achieves new state-of-the-art results in overall and long-tail performance on benchmarks.
Deep Random Forest with Ferroelectric Analog Content Addressable Memory
Oct 06, 2021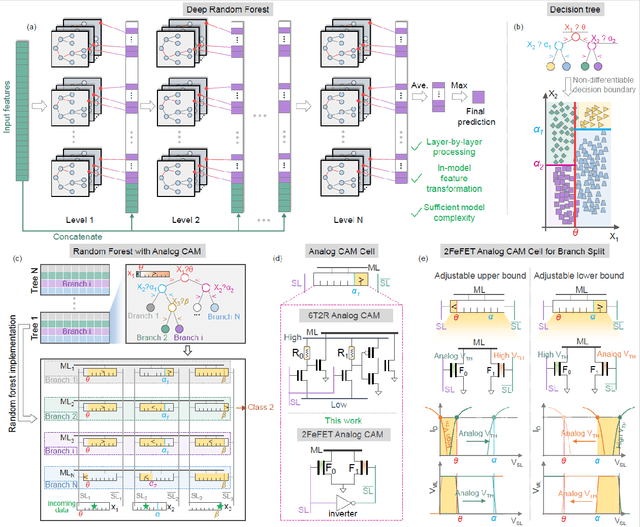
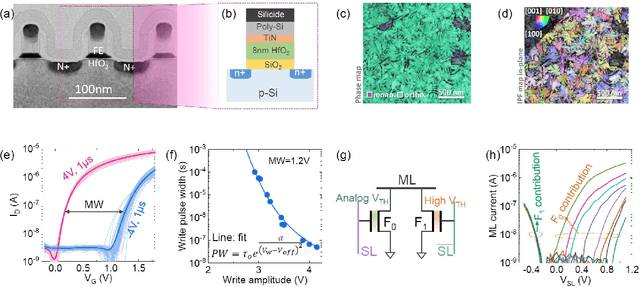
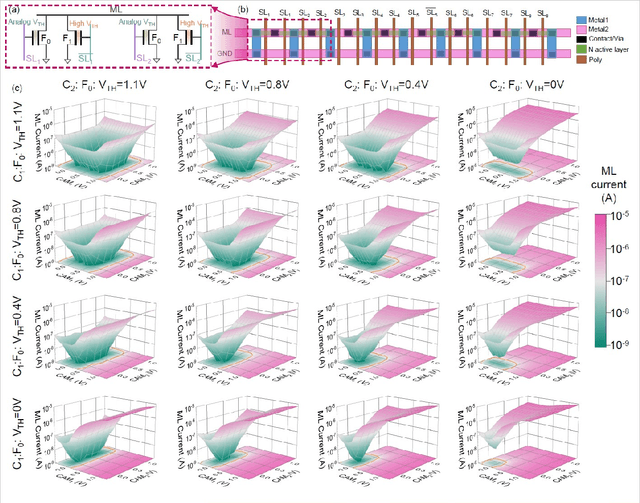
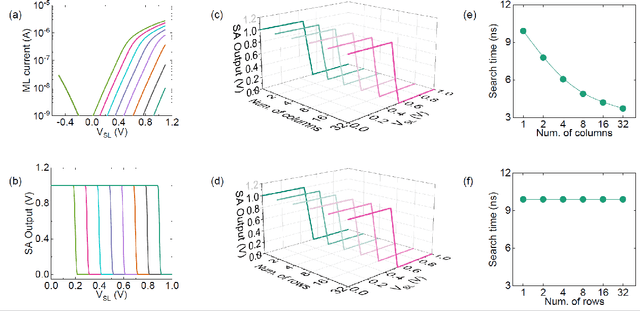
Deep random forest (DRF), which incorporates the core features of deep learning and random forest (RF), exhibits comparable classification accuracy, interpretability, and low memory and computational overhead when compared with deep neural networks (DNNs) in various information processing tasks for edge intelligence. However, the development of efficient hardware to accelerate DRF is lagging behind its DNN counterparts. The key for hardware acceleration of DRF lies in efficiently realizing the branch-split operation at decision nodes when traversing a decision tree. In this work, we propose to implement DRF through simple associative searches realized with ferroelectric analog content addressable memory (ACAM). Utilizing only two ferroelectric field effect transistors (FeFETs), the ultra-compact ACAM cell can perform a branch-split operation with an energy-efficient associative search by storing the decision boundaries as the analog polarization states in an FeFET. The DRF accelerator architecture and the corresponding mapping of the DRF model to the ACAM arrays are presented. The functionality, characteristics, and scalability of the FeFET ACAM based DRF and its robustness against FeFET device non-idealities are validated both in experiments and simulations. Evaluation results show that the FeFET ACAM DRF accelerator exhibits 10^6x/16x and 10^6x/2.5x improvements in terms of energy and latency when compared with other deep random forest hardware implementations on the state-of-the-art CPU/ReRAM, respectively.
Automated Quality Control of Vacuum Insulated Glazing by Convolutional Neural Network Image Classification
Oct 15, 2021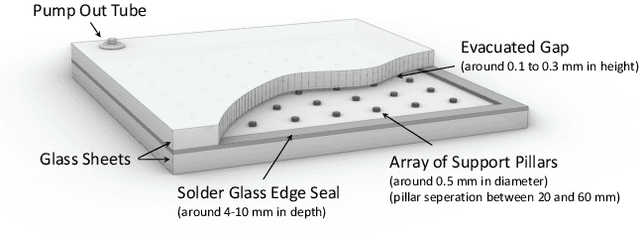


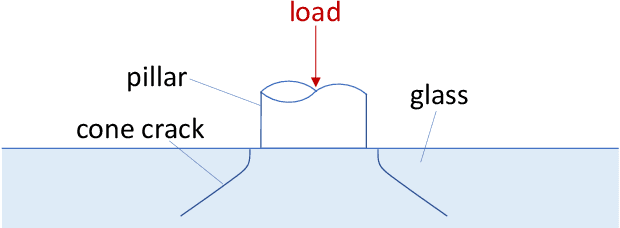
Vacuum Insulated Glazing (VIG) is a highly thermally insulating window technology, which boasts an extremely thin profile and lower weight as compared to gas-filled insulated glazing units of equivalent performance. The VIG is a double-pane configuration with a submillimeter vacuum gap between the panes and therefore under constant atmospheric pressure over their service life. Small pillars are positioned between the panes to maintain the gap, which can damage the glass reducing the lifetime of the VIG unit. To efficiently assess any surface damage on the glass, an automated damage detection system is highly desirable. For the purpose of classifying the damage, we have developed, trained, and tested a deep learning computer vision system using convolutional neural networks. The classification model flawlessly classified the test dataset with an area under the curve (AUC) for the receiver operating characteristic (ROC) of 100%. We have automatically cropped the images down to their relevant information by using Faster-RCNN to locate the position of the pillars. We employ the state-of-the-art methods Grad-CAM and Score-CAM of explainable Artificial Intelligence (XAI) to provide an understanding of the internal mechanisms and were able to show that our classifier outperforms ResNet50V2 for identification of crack locations and geometry. The proposed methods can therefore be used to detect systematic defects even without large amounts of training data. Further analyses of our model's predictive capabilities demonstrates its superiority over state-of-the-art models (ResNet50V2, ResNet101V2 and ResNet152V2) in terms of convergence speed, accuracy, precision at 100% recall and AUC for ROC.
Inference under Information Constraints I: Lower Bounds from Chi-Square Contraction
Dec 30, 2018
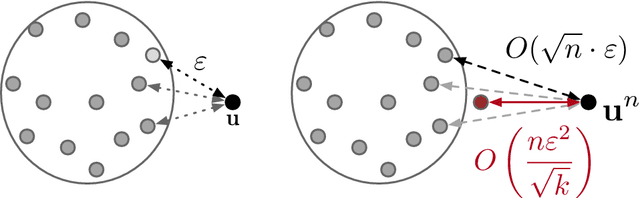

We consider a distributed inference problem where only limited information is allowed from each sample. We present a general framework where multiple players are given one independent sample each about which they can only provide limited information to a central referee. Motivated by important instances of communication and privacy constraints, in our abstraction we allow each player to describe its observed sample to the referee using a channel from a prespecified family of channels $\cal W$. This family $\cal W$ can be instantiated to capture both the communication- and privacy-constrained settings and beyond. The central referee uses the messages from players to solve an inference problem for the unknown underlying distribution that generated samples of the players. We derive lower bounds for sample complexity of learning and testing discrete distributions in this information-constrained setting. Underlying our lower bounds is a quantitative characterization of the contraction in chi-square distances between the observed distributions of the samples when an information constraint is placed. This contraction is captured in a local neighborhood in terms of chi-square and decoupled chi-square fluctuations of a given channel, two quantities we introduce in this work. The former captures the average distance between two product distributions and the latter the distance of a product distribution to a mixture of product distributions. These quantities may be of independent interest. As a corollary, we quantify the sample complexity blow-up in the learning and testing settings when enforcing the corresponding local information constraints. In addition, we systematically study the role of randomness and consider both private- and public-coin protocols.
Instance-dependent Label-noise Learning under a Structural Causal Model
Sep 12, 2021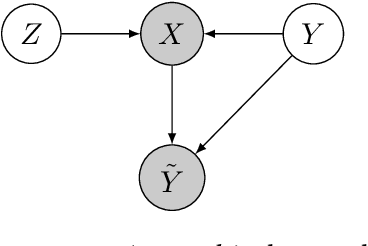
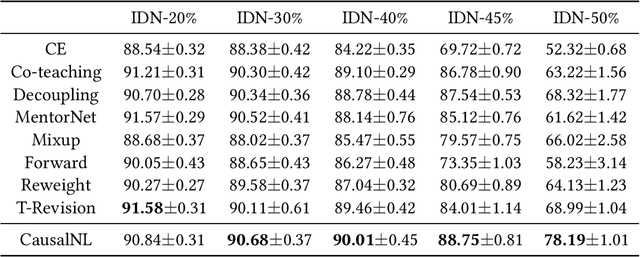
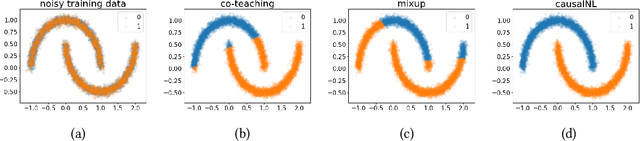
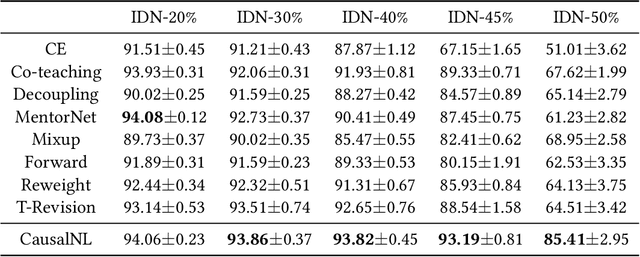
Label noise will degenerate the performance of deep learning algorithms because deep neural networks easily overfit label errors. Let X and Y denote the instance and clean label, respectively. When Y is a cause of X, according to which many datasets have been constructed, e.g., SVHN and CIFAR, the distributions of P(X) and P(Y|X) are entangled. This means that the unsupervised instances are helpful to learn the classifier and thus reduce the side effect of label noise. However, it remains elusive on how to exploit the causal information to handle the label noise problem. In this paper, by leveraging a structural causal model, we propose a novel generative approach for instance-dependent label-noise learning. In particular, we show that properly modeling the instances will contribute to the identifiability of the label noise transition matrix and thus lead to a better classifier. Empirically, our method outperforms all state-of-the-art methods on both synthetic and real-world label-noise datasets.
An Efficient DP-SGD Mechanism for Large Scale NLP Models
Jul 14, 2021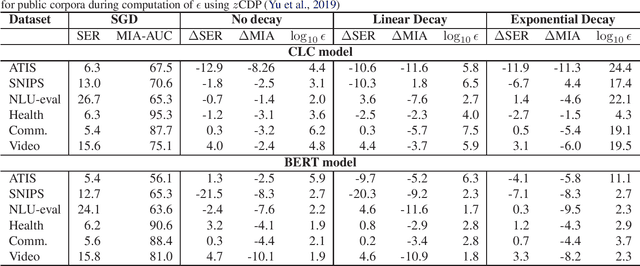
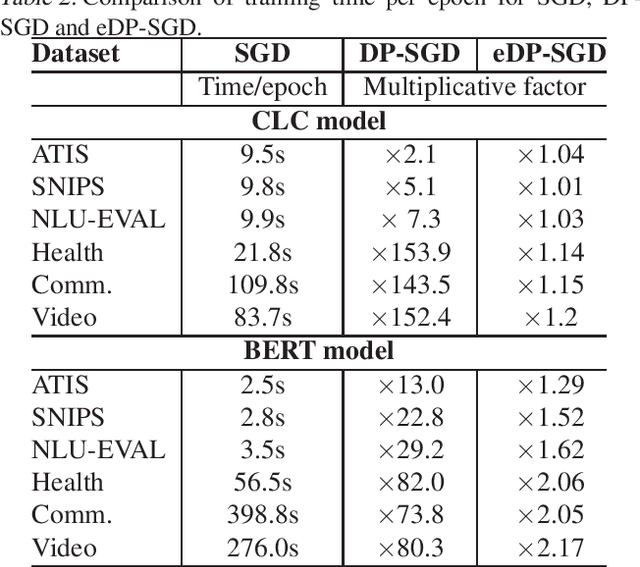
Recent advances in deep learning have drastically improved performance on many Natural Language Understanding (NLU) tasks. However, the data used to train NLU models may contain private information such as addresses or phone numbers, particularly when drawn from human subjects. It is desirable that underlying models do not expose private information contained in the training data. Differentially Private Stochastic Gradient Descent (DP-SGD) has been proposed as a mechanism to build privacy-preserving models. However, DP-SGD can be prohibitively slow to train. In this work, we propose a more efficient DP-SGD for training using a GPU infrastructure and apply it to fine-tuning models based on LSTM and transformer architectures. We report faster training times, alongside accuracy, theoretical privacy guarantees and success of Membership inference attacks for our models and observe that fine-tuning with proposed variant of DP-SGD can yield competitive models without significant degradation in training time and improvement in privacy protection. We also make observations such as looser theoretical $\epsilon, \delta$ can translate into significant practical privacy gains.
Leveraging Multiple Legacy Wi-Fi Links for Human Behavior Sensing
Aug 02, 2021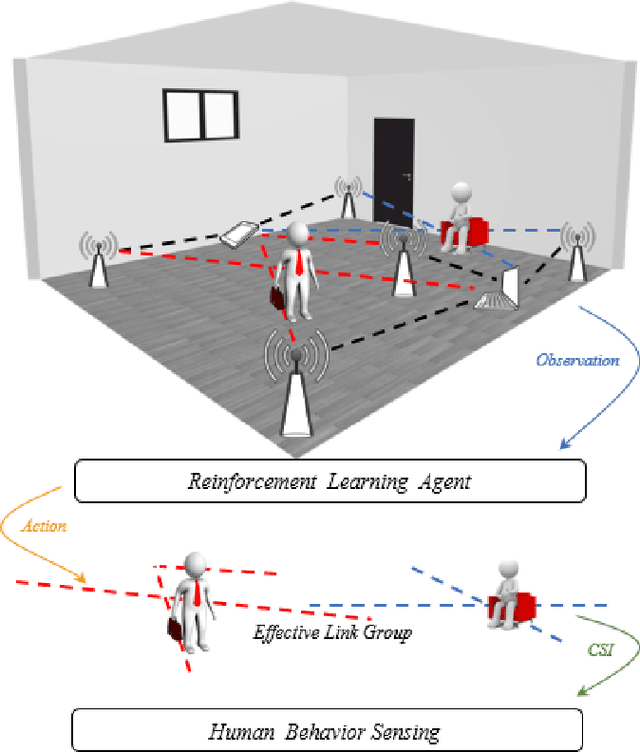
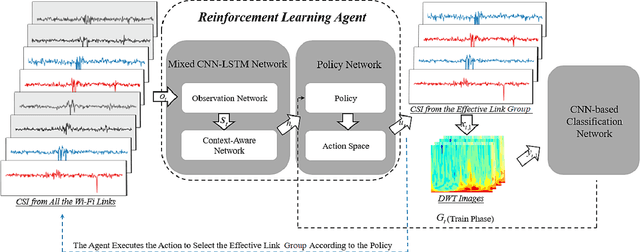

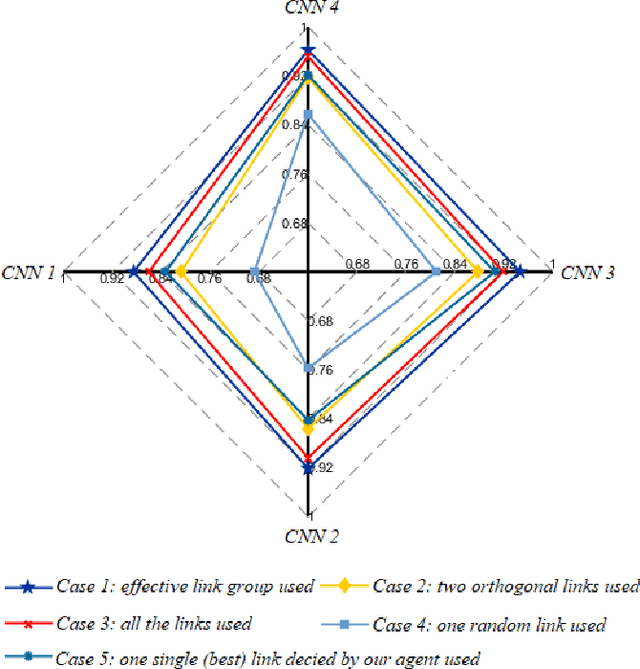
Taking advantage of the rich information provided by Wi-Fi measurement setups, Wi-Fi-based human behavior sensing leveraging Channel State Information (CSI) measurements has received a lot of research attention in recent years. The CSI-based human sensing algorithms typically either rely on an explicit channel propagation model or, more recently, adopt machine learning so as to robustify feature extraction. In most related work, the considered CSI is extracted from a single dedicated Access Point (AP) communication setup. In this paper, we consider a more realistic setting where a legacy network of multiple APs is already deployed for communications purposes and leveraged for sensing benefits using machine learning. The use of legacy network presents challenges and opportunities as many Wi-Fi links can present with richer yet unequally useful data sets. In order to break the curse of dimensionality associated with training over a too large dimensional CSI, we propose a link selection mechanism based on Reinforcement Learning (RL) which allows for dimension reduction while preserving the data that is most relevant for human behavior sensing. The method is based on a sequential state decision-making process in which the CSI is modeled as a part of the state. From actual experiment results, our method is shown to perform better than state-of-the-art approaches in a scenario with multiple available Wi-Fi links.
2nd-order Updates with 1st-order Complexity
May 24, 2021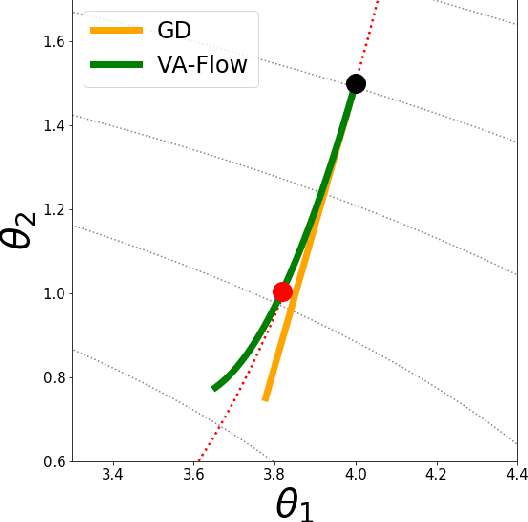
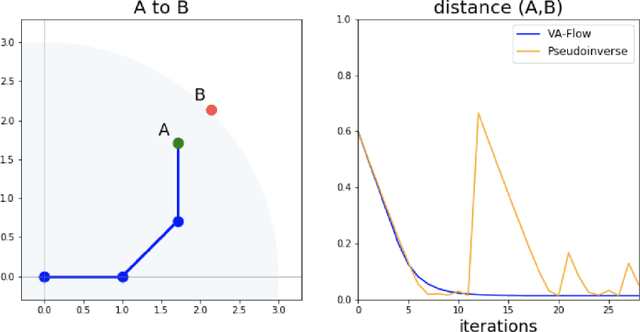
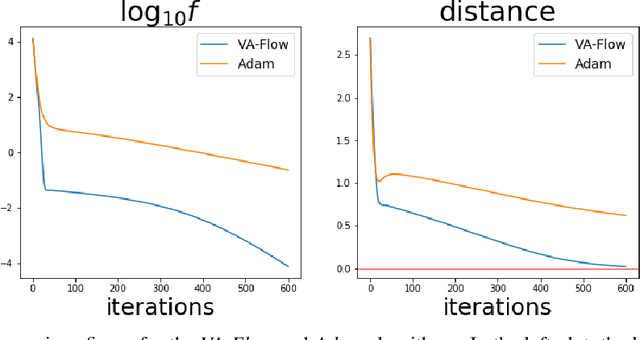
It has long been a goal to efficiently compute and use second order information on a function ($f$) to assist in numerical approximations. Here it is shown how, using only basic physics and a numerical approximation, such information can be accurately obtained at a cost of ${\cal O}(N)$ complexity, where $N$ is the dimensionality of the parameter space of $f$. In this paper, an algorithm ({\em VA-Flow}) is developed to exploit this second order information, and pseudocode is presented. It is applied to two classes of problems, that of inverse kinematics (IK) and gradient descent (GD). In the IK application, the algorithm is fast and robust, and is shown to lead to smooth behavior even near singularities. For GD the algorithm also works very well, provided the cost function is locally well-described by a polynomial.
HybridSVD: When Collaborative Information is Not Enough
Jul 27, 2018
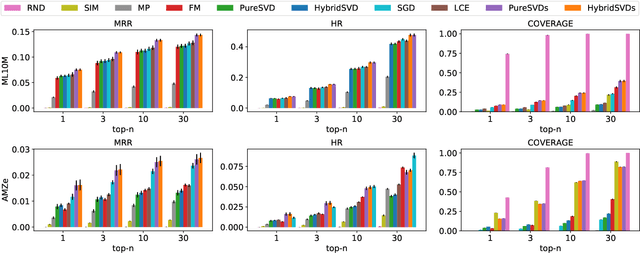
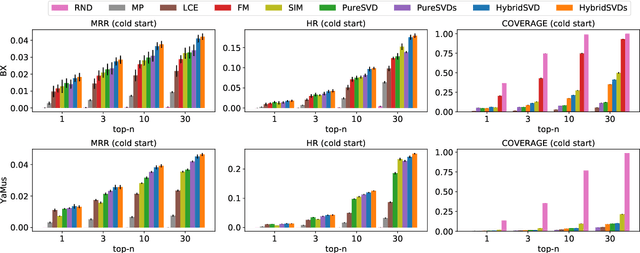
We propose a hybrid algorithm for top-$n$ recommendation task that allows to incorporate both user and item side information within the standard collaborative filtering approach. The algorithm extends PureSVD -- one of the state-of-the-art latent factor models -- by exploiting a generalized formulation of the singular value decomposition. This allows to inherit key advantages of the classical algorithm such as highly efficient Lanczos-based optimization procedure, minimal parameter tuning during a model selection phase and a quick folding-in computation to generate recommendations instantly even in a highly dynamic online environment. Within the generalized formulation itself we provide an efficient scheme for side information fusion which avoids undesirable computational overhead and addresses the scalability question. Evaluation of the model is performed in both standard and cold-start scenarios using the datasets with different sparsity levels. We demonstrate in which cases our approach outperforms conventional methods and also provide some intuition on when it may give no significant improvement.
Neural Contextual Bandits without Regret
Jul 07, 2021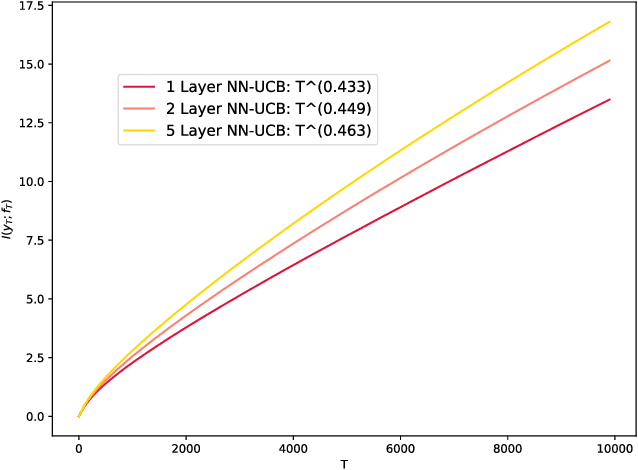
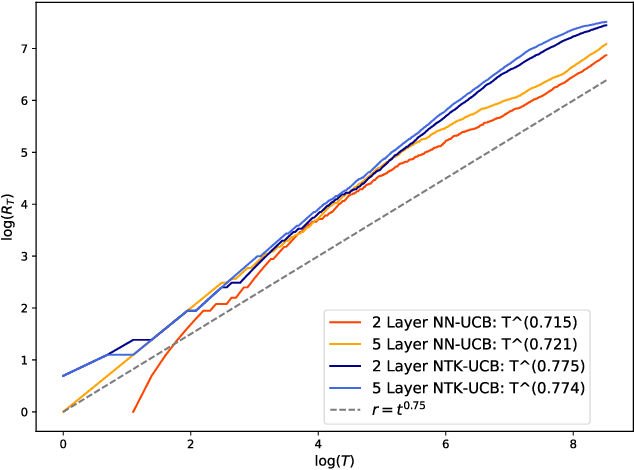
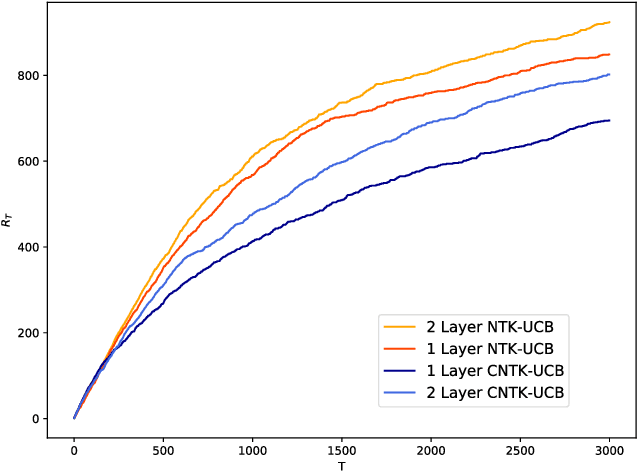
Contextual bandits are a rich model for sequential decision making given side information, with important applications, e.g., in recommender systems. We propose novel algorithms for contextual bandits harnessing neural networks to approximate the unknown reward function. We resolve the open problem of proving sublinear regret bounds in this setting for general context sequences, considering both fully-connected and convolutional networks. To this end, we first analyze NTK-UCB, a kernelized bandit optimization algorithm employing the Neural Tangent Kernel (NTK), and bound its regret in terms of the NTK maximum information gain $\gamma_T$, a complexity parameter capturing the difficulty of learning. Our bounds on $\gamma_T$ for the NTK may be of independent interest. We then introduce our neural network based algorithm NN-UCB, and show that its regret closely tracks that of NTK-UCB. Under broad non-parametric assumptions about the reward function, our approach converges to the optimal policy at a $\tilde{\mathcal{O}}(T^{-1/2d})$ rate, where $d$ is the dimension of the context.